LLM之高性能向量检索库
LLM向量数据库
- 高性能向量检索库
- milvus
- 简介
- 安装
- 调用
- faiss
- 简介
- 安装
- 调用
高性能向量检索库
milvus
简介
Milvus 是一个开源的向量数据库引擎,旨在提供高效的向量存储、检索和分析能力。它被设计用于处理大规模的高维向量数据,常用于机器学习、计算机视觉、自然语言处理和推荐系统等领域。
Milvus 提供了多种功能和特性,使其成为处理向量数据的理想选择。以下是一些 Milvus 的主要特点:
- 高性能:Milvus 使用了高度优化的数据结构和索引算法,以实现快速的向量检索。它支持多种索引类型,如平面索引、倒排索引和 HNSW(Hierarchical Navigable Small World)等,这些索引能够加速向量的相似度搜索。
- 可扩展性:Milvus 具备良好的可扩展性,可以轻松地扩展到大规模的向量数据集。它支持分布式部署,可以在多个节点上进行数据存储和查询操作,实现高吞吐量和低延迟。
- 多样化的向量类型:Milvus 支持多种向量类型,包括浮点型向量、二进制向量和文本向量等。这使得它可以适应不同领域和应用中的向量数据需求。
- 多语言支持:Milvus 提供了多种编程语言的 SDK(软件开发工具包),包括 Python、Java、Go 和 C++ 等,使开发者可以方便地集成 Milvus 到他们的应用程序中。
- 可视化管理界面:Milvus 提供了一个易于使用的 Web 界面,用于管理和监控向量数据库。开发者可以通过该界面进行数据导入、索引构建和查询优化等操作,同时还能够查看系统状态和性能指标。
总之,Milvus 是一个功能强大的向量数据库引擎,通过其高性能、可扩展性和多样化的特性,能够有效地存储和检索大规模的高维向量数据。它在许多领域的应用中发挥着重要作用,帮助开发者加速向量相关任务的开发和部署。
安装
-
docker 安装镜像:docker pull milvusdb/milvus:cpu-latest
-
创建工作目录:
mkdir milvus
cd milvus
mkdir congf
mkdir db
mkdir logs
mkdir wal
我的目录结构是:
milvus│├─conf //配置文件目录│ server_config.yaml //配置文件 搜索引擎配置都在这里修改│├─db //数据库存储目录 你的索引与向量存储的位置│└─logs //日志存储目录 │└─wal // 预写式日志相关配置
server_config.yaml
docker run -it milvusdb/milvus:cpu-latest bash
docker cp 74c20a680091:/var/lib/milvus/conf/server_config.yaml milvus/conf/
-
启动容器
docker run -td --name mymilvus -e "TZ=Asia/Shanghai" -p 19530:19530 -p 19121:19121 -v /work/lnn_workspace/chatgpt/search/milvus/conf:/var/lib/milvus/conf -v /work/lnn_workspace/chatgpt/search/milvus/db:/var/lib/milvus/db -v /work/lnn_workspace/chatgpt/search/milvus/logs:/var/lib/milvus/logs milvusdb/milvus:cpu-latestdocker ps | grep mymilvus
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-orhH8dlK-1685346967888)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230519105321396.png)]
- 安装pymilvus
pip install pymilvus==1.1.2
ps:注意这里安装最新版本可以会无法正常调用,1.1.2经过测试可正常使用
调用
# -*- coding: utf-8 -*- # 导入相应的包
import numpy as np
from milvus import Milvus, MetricType # 初始化一个Milvus类,以后所有的操作都是通过milvus来的
milvus = Milvus(host='localhost', port='19530') # 向量个数
num_vec = 5000
# 向量维度
vec_dim = 768
# name
collection_name = "test_collection"
# 创建collection,可理解为mongo的collection
collection_param = { 'collection_name': collection_name, 'dimension': vec_dim, 'index_file_size': 32, 'metric_type': MetricType.IP # 使用内积作为度量值
}
milvus.create_collection(collection_param) # 随机生成一批向量数据
# 支持ndarray,也支持list
vectors_array = np.random.rand(num_vec, vec_dim) # 把向量添加到刚才建立的collection中
status, ids = milvus.insert(collection_name=collection_name, records=vectors_array) # 返回 状态和这一组向量的ID
milvus.flush([collection_name]) # 输出统计信息
print(milvus.get_collection_stats(collection_name)) # 创建查询向量
query_vec_array = np.random.rand(1, vec_dim)
# 进行查询,
status, results = milvus.search(collection_name=collection_name, query_records=query_vec_array, top_k=5)
print(status)
print(results) # 如果不用可以删掉
status = milvus.drop_collection(collection_name) # 断开、关闭连接
milvus.close()
collection_name = "test_collection"
- 定义集合名称为test_collection
collection_param = {'collection_name': collection_name,'dimension': vec_dim,'index_file_size': 32,'metric_type': MetricType.IP
}
milvus.create_collection(collection_param) - collection_name 指定集合名称为test_collection
- dimension 表示集合中向量的维度,由vec_dim变量赋值
- index_file_size 设置索引文件大小为32MB
- metric_type 设置度量类型为IP,表示使用向量内积作为相似度度量
所以,这段代码定义了集合名称和相关参数,用于在Milvus服务上创建一个新的集合。
在Milvus中,集合相当于关系数据库的表,是存储向量的基本单元。在创建集合时,我们需要指定:
1. 集合名称:唯一标识一个集合
2. 向量维度:集合中向量的特征数量
3. 度量类型:测量向量之间相似度的算法,如IP(内积)、L2(欧氏距离)等
4. 索引文件大小:用于提高搜索性能,索引文件会存储向量的索引信息
faiss
简介
Faiss是Facebook开源的一个向量检索库,用于大规模向量集合的索引和搜索。主要功能包括:
- 支持多种索引结构: IVF, IVFFlat, HNSW, etc。这些索引结构可以实现高精度和高召回的向量搜索。
- 支持多种度量方式:内积,欧氏距离,cosine 相似度等。可选择合适的度量方式对向量集合建立索引。
- 快速的索引构建与搜索:Faiss使用GPU加速,可以实现亿量级向量的索引构建和搜索。
- 降维与聚类:Faiss提供PCA,IVFFlat等算法进行向量降维,并支持Kmeans算法进行向量聚类。
- 高级特性:Faiss支持在线学习,异构向量检索,索引压缩等高级特性。
Faiss的典型应用有:
图像检索:在大规模图片数据库中找到与输入图片最相似的图片。
文本匹配:快速找到与输入文本最相近的文本内容。
推荐系统:根据用户兴趣对大量商品进行快速检索和推荐。
声纹识别:在海量语音数据中实现语音识别和检索。
Faiss提供C++, Python和Java语言接口,可以轻松构建向量检索系统。如果需要管理和搜索海量高维向量,Faiss是一个非常好的选择。
安装
install faiss-cpu
调用
# 导入库
import numpy as np
import faiss # 向量个数
num_vec = 5000
# 向量维度
vec_dim = 768
# 搜索topk
topk = 10 # 随机生成一批向量数据
vectors = np.random.rand(num_vec, vec_dim) # 创建索引
faiss_index = faiss.IndexFlatL2(vec_dim) # 使用欧式距离作为度量
# 添加数据
faiss_index.add(vectors) # 查询向量 假设有5个
query_vectors = np.random.rand(5, vec_dim)
# 搜索结果
# 分别是 每条记录对应topk的距离和索引
# ndarray类型 。shape:len(query_vectors)*topk
res_distance, res_index = faiss_index.search(query_vectors, topk)
print(res_index)
print(res_distance)
相关文章:

LLM之高性能向量检索库
LLM向量数据库 高性能向量检索库milvus简介安装调用 faiss简介安装调用 高性能向量检索库 milvus 简介 Milvus 是一个开源的向量数据库引擎,旨在提供高效的向量存储、检索和分析能力。它被设计用于处理大规模的高维向量数据,常用于机器学习、计算机视觉…...

实体类注解
目录 一、TableField注解 二、TableId注解 三、Table注解 四、TableLogic注解 五、Getter与Setter注解 六、EqualsAndHashCode注解 七、Accessors注解 一、TableField注解 Data NoArgsConstructor //空参构造方法 AllArgsConstructor //全参构造方法 TableName("t…...

常见数据结构种类
常见数据结构种类 数据存储的常用结构有:栈、队列、数组、链表和红黑树 a.队列(queue) – 先进先出,后进后出。 – 场景:各种排队。叫号系统。 – 有很多集合可以实现队列。 b.栈(stack) – …...
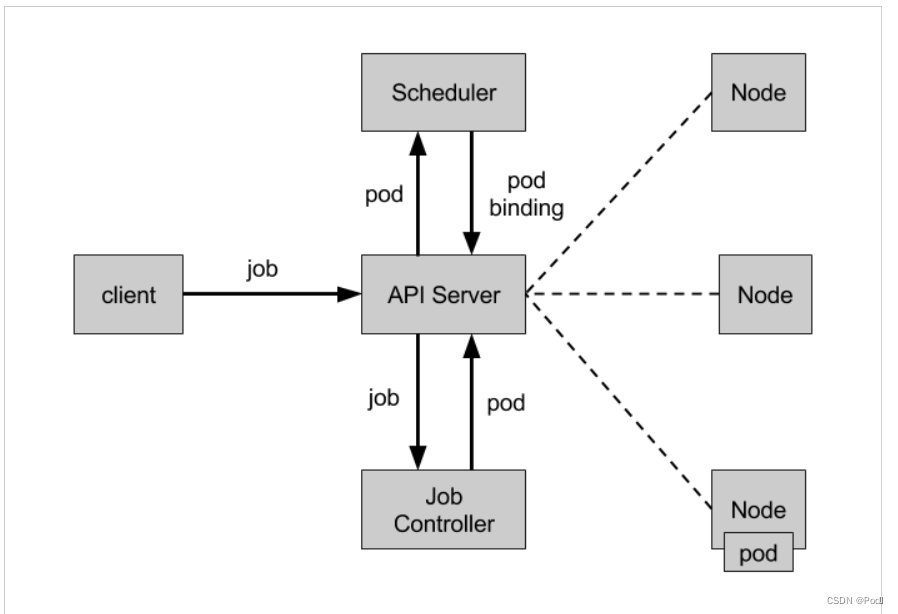
linux高级---k8s中的五种控制器
文章目录 一、k8s的控制器类型二、pod与控制器之间的关系三、状态与无状态化对特点四、Deployment1、Deployment的资源清单文件2、在配置清单中调用deployment控制器3、镜像更新4、金丝雀发布5、删除Deployment 五、Statefulset六、DaemonSet1、daemonset的资源清单文件2、在配…...
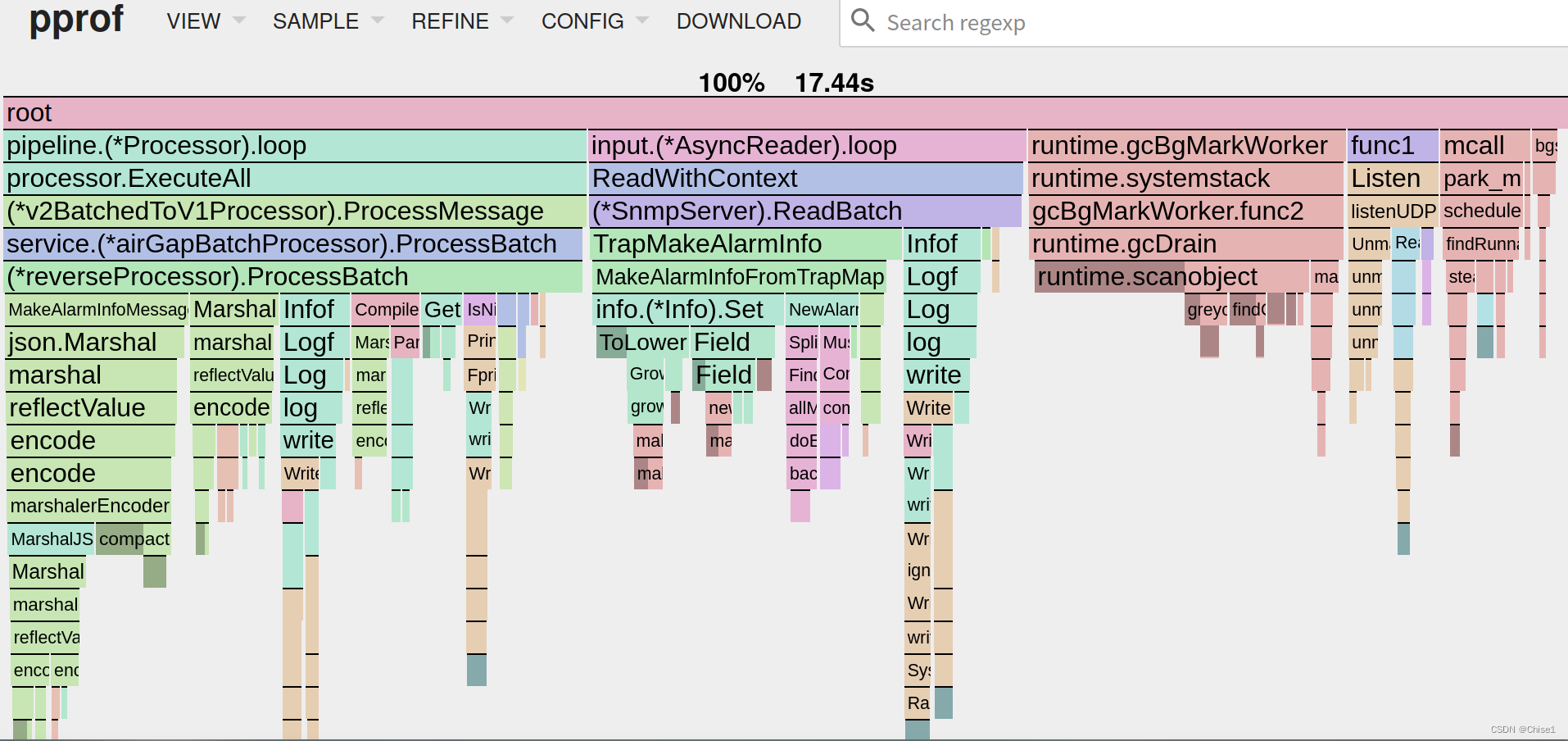
记一次udp服务性能优化经历
目录 概述磁盘io网络io减少重复计算减少内存复制减少互斥锁 概述 手上有个go项目,接收udp信息(主要是syslog和snmp trap)并查询设备信息,将信息结构化(设备ip名称,匹配了什么规则之类的)后发送…...

uniapp和VueI18n多语言H5项目语言国际化功能搭建流程
uniapp多语言项目国家化功能搭建流程 说明:uniapp多语言项目功能搭建分为应用部分和框架部分。 应用部分,即开发者自己的代码里涉及的界面部分的语言翻译。框架部分,即uni-app内置组件和API涉及界面的部分的语言翻译。 功能的搭建是需要un…...
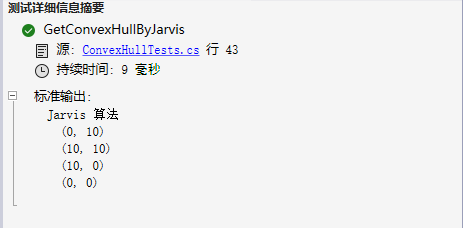
C# | 凸包算法之Jarvis,寻找一组点的边界/轮廓
C#实现凸包算法之Jarvis 文章目录 C#实现凸包算法之Jarvis前言示例代码实现思路测试结果结束语 前言 这篇关于凸包算法的文章,本文使用C#和Jarvis算法来实现凸包算法。 首先消除两个最基本的问题: 什么是凸包呢? 凸包是一个包围一组点的凸多…...
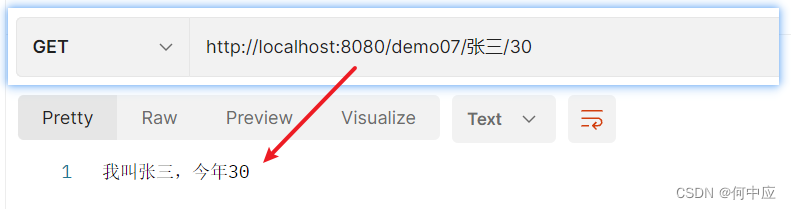
SpringBoot接收请求参数的方式
【方式一】原始方式 因为SpringBoot封装了Servlet,所以也允许使用HttpServletRequest类中的方法来获取 /*** 【方式一】原始方式*/RequestMapping("/demo01")public String demo01(HttpServletRequest request) {// 参数名要与页面提交的参数名一致Strin…...
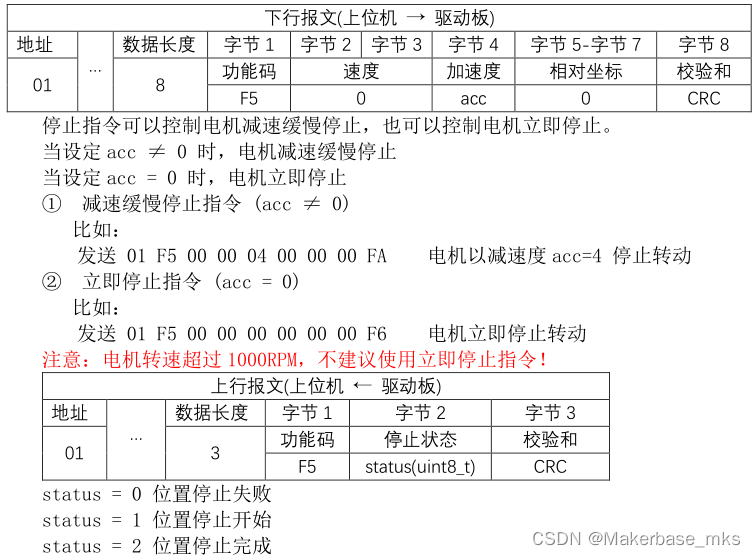
MKS SERVO4257D 闭环步进电机_系列5 CAN指令说明
第1部分 产品介绍 MKS SERVO 28D/35D/42D/57D 系列闭环步进电机是创客基地为满足市场需求而自主研发的一款产品。具备脉冲接口和RS485/CAN串行接口,支持MODBUS-RTU通讯协议,内置高效FOC矢量算法,采用高精度编码器,通过位置反馈&am…...

安捷伦E4440A(Agilent) e4440a 3HZ-26.5G频谱分析仪
Agilent E4440A、Keysight E4440A、HP E4440A频谱分析仪,3 Hz - 26.5 GHz(PSA 系列) Agilent / Keysight PSA 系列 E4440A 高性能频谱分析仪提供强大的一键式测量、多功能功能集和前沿技术,可满足您的项目和需求。选项可供您选…...

华为OD机试真题 Java 实现【最长子字符串的长度】【2022Q4 100分】,附详细解题思路
一、题目描述 给你一个字符串s,字符串s首尾相连组成一个环形,请你在环形中找出‘o’字符出现了偶数次最长子字符串的长度。 二、输入描述 输入一串小写字母组成的字符串。 三、输出描述 输出一个整数。 四、解题思路 题目要求在给定的环形字符串中找出字符’o’出现了…...

【iOS】--对象的底层结构
源码 先转一下源码 //#import <Foundation/Foundation.h> #import <objc/runtime.h>interface LGPerson : NSObject property (nonatomic, strong) NSString *KCName; endimplementation LGPersonendint main(int argc, const char * argv[]) {autoreleasepool {…...

高并发内存池设计_内存池
高并发内存池设计 1. 常用的内存操作函数2. 高性能内存池设计_弊端解决之道弊端一弊端二弊端三弊端四3. 弊端解决之道内存管理维度分析内存管理组件选型4. 高并发内存管理最佳实践内存池技术内存池如何解决弊端?高并发时内存池如何实现?5. 高效内存池设计和实现实现思路 (分而…...

给编程初学者的一封信
提醒:以下内容仅做参考,具体请自行设计。 随着信息技术的快速发展,编程已经成为一个越来越重要的技能。那么,我们该如何入门编程呢?欢迎大家积极讨论 一、自学编程需要注意什么? 要有足够的时间、精力等…...
【无功优化】基于改进教与学算法的配电网无功优化【IEEE33节点】(Matlab代码时候)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

数据在内存中的存储(超详细讲解)
目录 浮点数家族 浮点数类型在内存中的存储 一.为什么说整型和浮点数在内存中存储方式不同(证明) 二.浮点数的存储规则 浮点数在计算机内部的表示方法 1.对于M的存储和取出规则 2.对于E的存储和取出时的规则 对前面代码结果进行解释: …...

log4cplus使用示例
1、l4jlog.h封装头文件 #pragma once#include <iostream> #include <log4cplus/logger.h> #include <log4cplus/loggingmacros.h> #include <log4cplus/fileappender.h> #include <log4cplus/layout.h> #include <log4cplus/configurator.h&…...
人工智能学习07--pytorch20--目标检测:COCO数据集介绍+pycocotools简单使用
如:天空 coco包含pascal voc 的所有类别,并且对每个类别的标注目标个数也比pascal voc的多。 一般使用coco数据集预训练好的权重来迁移学习。 如果仅仅针对目标检测object80类而言,有些图片并没有标注信息,或者有错误标注信息。…...

learnOpenGL-深度测试
深度测试:OpenGL将一个片段的深度值与深度缓冲的内容进行对比。执行一个深度测试,测试通过则深度缓冲将会更新为新的深度值。测试失败则片段被丢弃。 深度测试片段着色器及模版测试之后执行。 片段着色器中内置变量gl_FragCoord的z值即为深度值。 提前深…...

阿里云服务器数据盘是什么?系统盘和数据盘区别
阿里云服务器系统盘和数据盘有什么区别?系统盘类似Windows电脑的C盘,数据盘相当于其他盘符,数据盘可以有多个而系统盘只能有一个,数据盘可有可无而云服务器系统盘是必须要有的。阿里云服务器网来详细说下阿里云服务器数据盘和系统…...

MakeMeAHanzi完整指南:如何免费获取9000+汉字笔画动画数据
MakeMeAHanzi完整指南:如何免费获取9000汉字笔画动画数据 【免费下载链接】makemeahanzi Free, open-source Chinese character data 项目地址: https://gitcode.com/gh_mirrors/ma/makemeahanzi MakeMeAHanzi是一个免费开源的汉字数据项目,为开发…...

私有化 IM vs 公有云 IM:3 个维度告诉你该怎么选
企业在选择即时通讯工具时,常常陷入 “功能越多越好” 的误区。实际上,IM 选型的本质是一次数据治理策略的决策。私有化 IM 和公有云 IM 没有绝对的好坏,只有适合不适合。今天我们从三个核心维度,帮你做出正确的选择。第一个维度&…...
)
中性点不接地系统或中性点经消弧线圈接地系统的小电流接地故障仿真研究(Simulink仿真实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

React Starter Kit 团队协作:如何建立统一的开发规范
React Starter Kit 团队协作:如何建立统一的开发规范 【免费下载链接】react-starter-kit Start your first React App. By using React, Redux, and React-Router. 项目地址: https://gitcode.com/gh_mirrors/reac/react-starter-kit React Starter Kit 是一…...
)
软考 系统架构设计师系列知识点之杂项集萃(155)
接前一篇文章:软考 系统架构设计师系列知识点之杂项集萃(154) 第293题 给定关系R(A1, A2, A3, A4, A5)上的函数依赖集F={A1->A2A5, A2->A3A4, A3->A2},R的候选关键字()。函数依赖()∈F+。 第1空 A. A1 B. A1A2 C. A1A3 D. A1A2A3 正确答案:A。 第2空…...

Qt5 super module网络编程指南:WebSocket、HTTP、MQTT通信实现
Qt5 super module网络编程指南:WebSocket、HTTP、MQTT通信实现 【免费下载链接】qt5 Qt5 super module 项目地址: https://gitcode.com/gh_mirrors/qt/qt5 Qt5 super module是一个功能强大的跨平台应用程序开发框架,提供了丰富的网络编程功能&…...

手把手教你从零搭建 MCP Server:AI 连接万物的保姆级实战教程
为什么要学 MCP? 说实话,最近半年 AI 开发圈最火的协议就是 MCP(Model Context Protocol)了。你可能已经用上了各种 AI 助手,但有没有想过:这些 AI 怎么连接你的数据库?怎么读你的本地文件&…...

【独家首发】DeepSeek-VL与R1双模型事实校验对照实验:1276条权威知识链验证,误差分布首次公开
更多请点击: https://kaifayun.com 第一章:DeepSeek事实准确性测试 为系统评估 DeepSeek-R1 模型在开放域事实性问答中的表现,我们构建了覆盖科学、历史、技术与常识四大领域的 1,200 条人工校验真值(ground-truth)测…...

3分钟搞定B站缓存:这款神器让视频转换超简单
3分钟搞定B站缓存:这款神器让视频转换超简单 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站视频下架而焦虑࿱…...

av1编码--比特流结构
目录 2.2.1 序列头信息 2.2.2 帧头信息 2.2.4 时间分隔符信息 2.2.5 切片组信息 AV1 比特流是由一系列名为开放比特流单元(OBU)的数据单元组成。每个 OBU 由一个可变长度的字节串(Byte String)组成。具体来讲,OBU 包…...