40亿个QQ号,限制1G内存,如何去重?
40亿个unsigned int,如果直接用内存存储的话,需要:
4*4000000000 /1024/1024/1024 = 14.9G ,考虑到其中有一些重复的话,那1G的空间也基本上是不够用的。
想要实现这个功能,可以借助位图。
使用位图的话,一个数字只需要占用1个bit,那么40亿个数字也就是:
4000000000 * 1 /8 /1024/1024 = 476M
相比于之前的14.9G来说,大大的节省了很多空间。
比如要把我的QQ号"907607222"放到Bitmap中,就需要找到第907607222这个位置,然后把他设置成1就可以了。
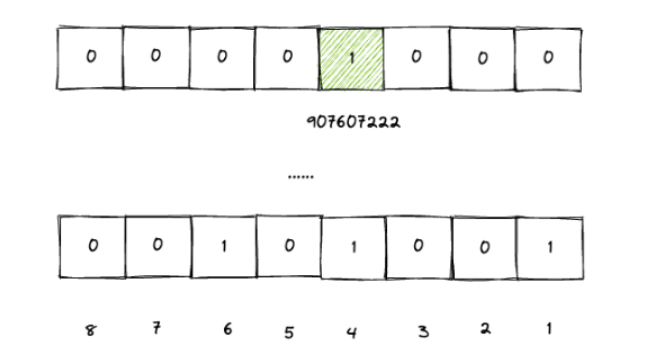
这样,把40亿个数字都放到Bitmap之后,所有位置上是1的表示存在,不为1的表示不存在,相同的QQ号只需要设置一次1就可以了,那么,最终就把所有是1的数字遍历出来就行了。
什么是BitMap?有什么用?
位图(BitMap),基本思想就是用一个bit来标记元素,bit是计算机中最小的单位,也就是我们常说的计算机中的0和1,这种就是用一个位来表示的。
所谓位图,其实就是一个bit数组,即每一个位置都是一个bit,其中的取值可以是0或者1

像上面的这个位图,可以用来表示1,4,6:
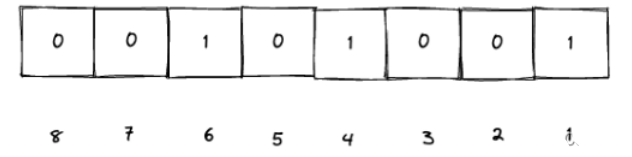
如果不用位图的话,我们想要记录1,4,6 这三个整型的话,就需要用三个unsigned int,已知每个unsigned int占4个字节,那么就是3*4 = 12个字节,一个字节有8 bit,那么就是 12*8 = 96 个bit。
所以,位图最大的好处就是节省空间。
位图有很多种用途,特别适合用在去重、排序等场景中,著名的布隆过滤器就是基于位图实现的。
但是位图也有着一定的限制,那就是他只能表示0和1,无法存储其他的数字。所以他只适合这种能表示ture or false的场景。
什么是布隆过滤器,实现原理是什么?
布隆过滤器是一种数据结构,用于快速检索一个元素是否可能存在于一个集合(bit 数组)中。
它的基本原理是利用多个哈希函数,将一个元素映射成多个位,然后将这些位设置为 1。当查询一个元素时,如果这些位都被设置为 1,则认为元素可能存在于集合中,否则肯定不存在
所以,布隆过滤器可以准确的判断一个元素是否一定不存在,但是因为哈希冲突的存在,所以他没办法判断一个元素一定存在。只能判断可能存在。
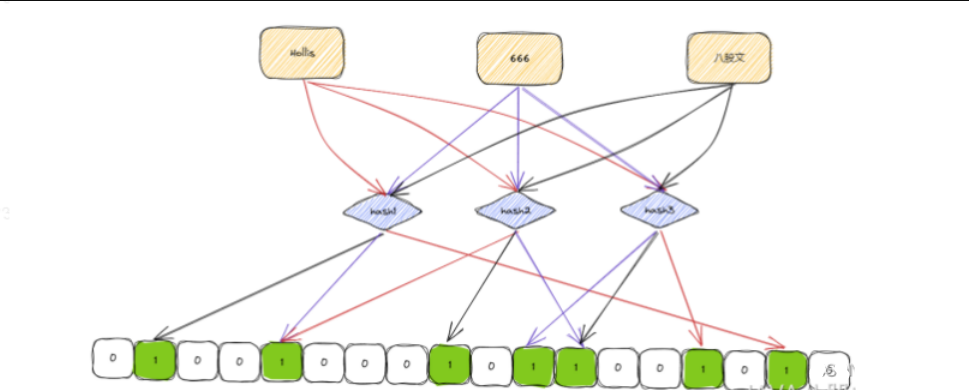
所以,布隆过滤器是存在误判的可能的,也就是当一个不存在的Hero元素,经过hash1、hash2和hash3之后,刚好和其他的值的哈希结果冲突了。那么就会被误判为存在,但是其实他并不存在。
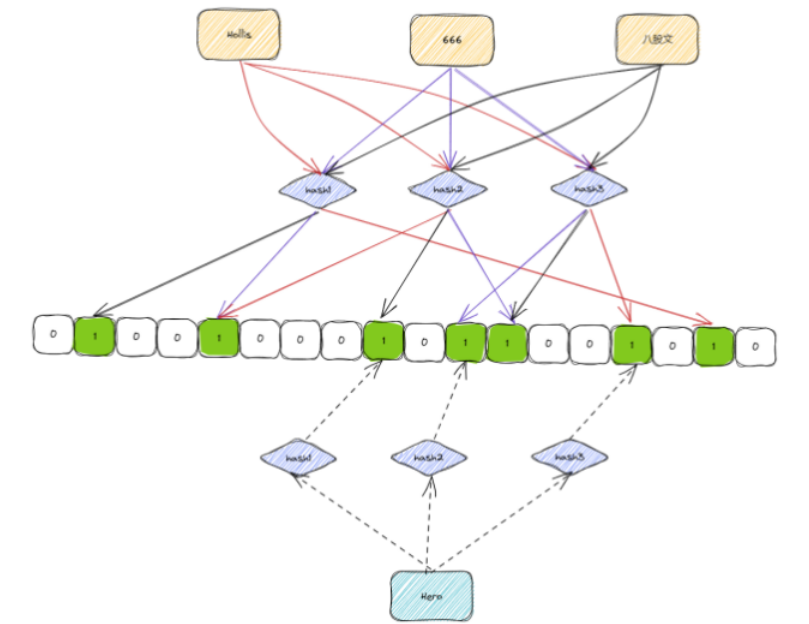
想要降低这种误判的概率,主要的办法就是降低哈希冲突的概率及引入更多的哈希算法。
下面是布隆过滤器的工作过程:
1、初始化布隆过滤器
在初始化布隆过滤器时,需要指定集合的大小和误判率。布隆过滤器内部包含一个bit数组和多个哈希函数,每个哈希函数都会生成一个索引值。
2、添加元素到布隆过滤器
要将一个元素添加到布隆过滤器中,首先需要将该元素通过多个哈希函数生成多个索引值,然后将这些索引值对应的位设置为 1。如果这些索引值已经被设置为 1,则不需要再次设置。
3、查询元素是否存在于布隆过滤器中
要查询一个元素是否存在于布隆过滤器中,需要将该元素通过多个哈希函数生成多个索引值,并判断这些索引值对应的位是否都被设置为 1。如果这些位都被设置为 1,则认为元素可能存在于集合中,否则肯定不存在。
布隆过滤器的主要优点是可以快速判断一个元素是否属于某个集合,并且可以在空间和时间上实现较高的效率。但是,它也存在一些缺点,例如:
-
布隆过滤器在判断元素是否存在时,有一定的误判率。、
-
布隆过滤器删除元素比较困难,因为删除一个元素需要将其对应的多个位设置为 0,但这些位可能被其他元素共享。
应用场景
布隆过滤器因为他的效率非常高,所以被广泛的使用,比较典型的场景有以下几个:
1、网页爬虫: 爬虫程序可以使用布隆过滤器来过滤掉已经爬取过的网页,避免重复爬取和浪费资源。
2、缓存系统: 缓存系统可以使用布隆过滤器来判断一个查询是否可能存在于缓存中,从而减少查询缓存的次数,提高查询效率。布隆过滤器也经常用来解决缓存穿透的问题。
3、分布式系统: 在分布式系统中,可以使用布隆过滤器来判断一个元素是否存在于分布式缓存中,避免在所有节点上进行查询,减少网络负载。
4、垃圾邮件过滤: 布隆过滤器可以用于判断一个邮件地址是否在垃圾邮件列表中,从而过滤掉垃圾邮件。
5、黑名单过滤: 布隆过滤器可以用于判断一个IP地址或手机号码是否在黑名单中,从而阻止恶意请求。
如何使用
Java中可以使用第三方库来实现布隆过滤器,常见的有Google Guava库和Apache Commons库以及Redis。
如Guava:
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterExample {public static void main(String[] args) {// 创建布隆过滤器,预计插入100个元素,误判率为0.01BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(), 100, 0.01);// 插入元素bloomFilter.put("Lynn");bloomFilter.put("666");bloomFilter.put("八股文");// 判断元素是否存在System.out.println(bloomFilter.mightContain("Lynn")); // trueSystem.out.println(bloomFilter.mightContain("张三")); // false}
}
Apache Commons:
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.collections4.BloomFilter;
import org.apache.commons.collections4.functors.HashFunctionIdentity;
public class BloomFilterExample {public static void main(String[] args) {// 创建布隆过滤器,预计插入100个元素,误判率为0.01BloomFilter<String> bloomFilter = new BloomFilter<>(HashFunctionIdentity.hashFunction(StringUtils::hashCode), 100, 0.01);// 插入元素bloomFilter.put("Lynn");bloomFilter.put("666");bloomFilter.put("八股文");// 判断元素是否存在System.out.println(bloomFilter.mightContain("Lynn")); // trueSystem.out.println(bloomFilter.mightContain("张三")); // false}
}
Redis中可以通过Bloom模块来使用,使用Redisson可以:
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("myfilter");
bloomFilter.tryInit(100, 0.01);
bloomFilter.add("Lynn");
bloomFilter.add("666");
bloomFilter.add("八股文");
System.out.println(bloomFilter.contains("Lynn"));
System.out.println(bloomFilter.contains("张三"));
redisson.shutdown();
首先创建一个RedissonClient对象,然后通过该对象获取一个RBloomFilter对象,使用tryInit方法来初始化布隆过滤器,指定了最多能添加的元素数量为100,误判率为0.01。
然后,使用add方法将元素"Hollis"、"666"和"八股文"添加到布隆过滤器中,使用contains方法来检查元素是否存在于布隆过滤器中。
或者Jedis也可以:
Jedis jedis = new Jedis("localhost");
jedis.bfCreate("myfilter", 100, 0.01);
jedis.bfAdd("myfilter", "Lynn");
jedis.bfAdd("myfilter", "666");
jedis.bfAdd("myfilter", "八股文");
System.out.println(jedis.bfExists("myfilter", "Lynn"));
System.out.println(jedis.bfExists("myfilter", "张三"));
jedis.close();相关文章:
40亿个QQ号,限制1G内存,如何去重?
40亿个unsigned int,如果直接用内存存储的话,需要: 4*4000000000 /1024/1024/1024 14.9G ,考虑到其中有一些重复的话,那1G的空间也基本上是不够用的。 想要实现这个功能,可以借助位图。 使用位图的话&a…...

【django】django的orm的分组查询
前言:django当中分组查询如何实现? annotate from myapp import models from django.db.models.functions import TruncMonth from django.db.models import Count,Avg# 分组 values 就是取值作用 model.Book.objects.values(month).annotate(countCo…...

MySQL5.8在Windows下下载+安装+配置教程
MySQL是一款常用的关系型数据库管理系统,本文将介绍MySQL5.8在Windows下的安装配置教程。 1. 软件下载地址 免安装版下载地址:https://dev.mysql.com/downloads/mysql/安装版下载地址:https://dev.mysql.com/downloads/installer/ 2. 免安…...
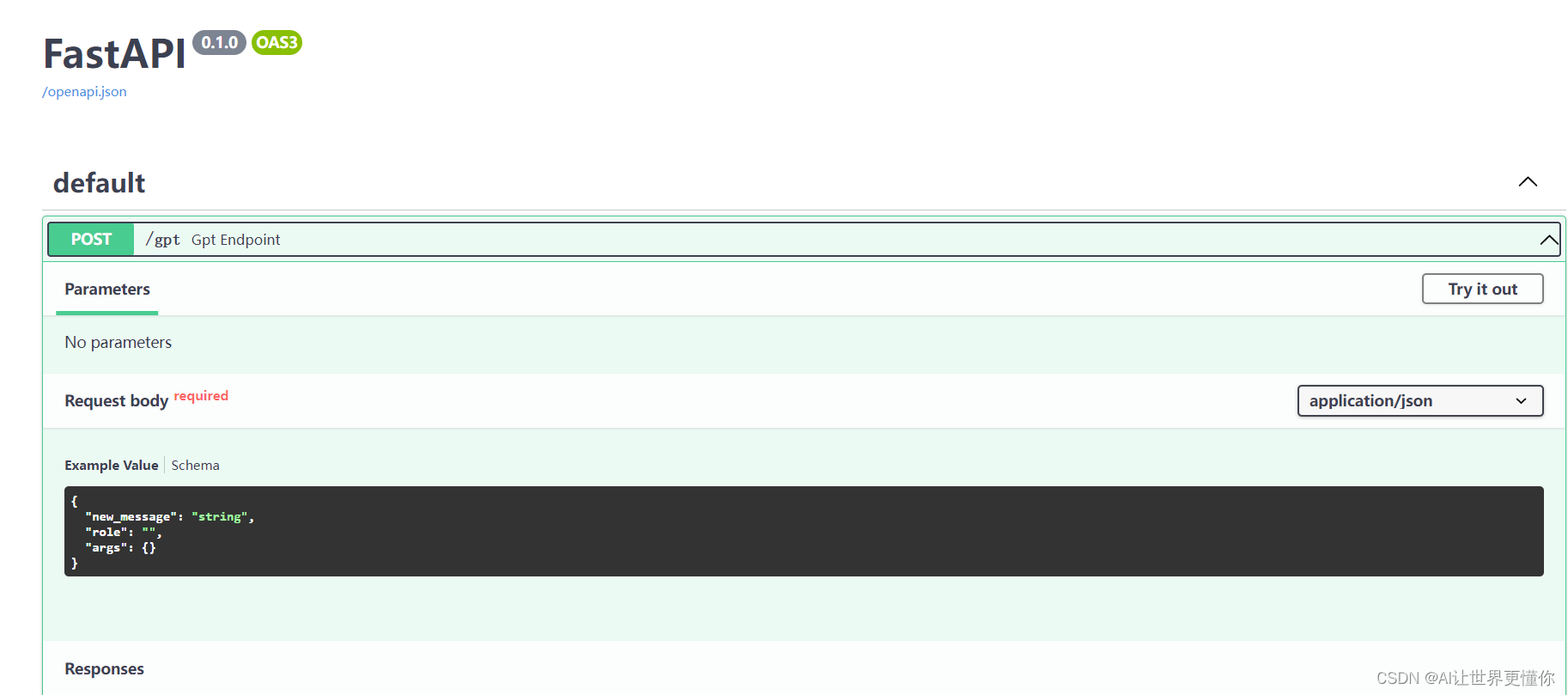
Flask or FastAPI? Python服务端初体验
1. 引言 最近由于工作需要,又去了解了一下简单的python服务搭建的相关工作,主要是为了自己开发的模型或者工具给同组的人使用。之前介绍的针对于数据科学研究比较友好的一个可以展示的前端框架Streamlit可以说是一个利器。不过,随着ChatGPT的…...

《计算机组成原理》唐朔飞 第7章 指令系统 - 学习笔记
写在前面的话:此系列文章为笔者学习计算机组成原理时的个人笔记,分享出来与大家学习交流。使用教材为唐朔飞第3版,笔记目录大体与教材相同。 网课 计算机组成原理(哈工大刘宏伟)135讲(全)高清_…...
Linux:apache网页优化
Linux:apache网页优化 一、Apache 网页优化二、网页压缩2.1 检查是否安装 mod_deflate 模块2.2 如果没有安装mod_deflate 模块,重新编译安装 Apache 添加 mod_deflate 模块2.3 配置 mod_deflate 模块启用2.4 检查安装情况,启动服务2.5 测试 m…...
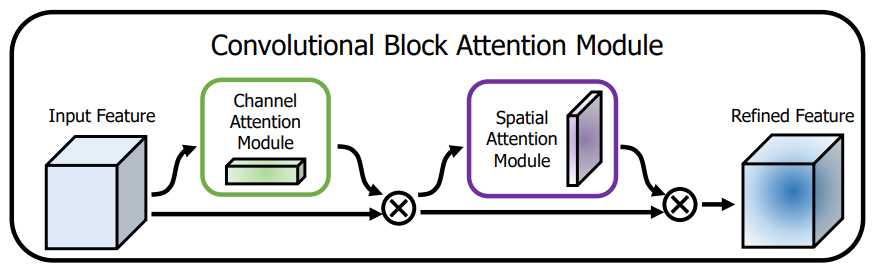
涨点技巧:注意力机制---Yolov8引入Resnet_CBAM,CBAM升级版
1.计算机视觉中的注意力机制 一般来说,注意力机制通常被分为以下基本四大类: 通道注意力 Channel Attention 空间注意力机制 Spatial Attention 时间注意力机制 Temporal Attention 分支注意力机制 Branch Attention 1.1.CBAM:通道注意力和空间注意力的集成者 轻量级…...

solr教程
一:安装配置 下载完成之后,解压solr文件,解压tomcat 1.1 在tomcat安装solr,并且建立solrCore 把solr5.5目录下的server/solr-webapp/webapp 重命名为solr,并且放置到tomcat/webapp的目录下。 打开tomcat/webapp/solr/WEB-INF/web.xml新建…...

基于java语言编写的爬虫程序
Java语言可以使用Jsoup、HttpClient等库进行网络爬虫开发,其中Jsoup提供了HTML解析和DOM操作的功能,HttpClient则提供了HTTP协议的支持。你可以通过使用这些库,构建网络爬虫程序来爬取指定网站的数据。需要注意的是,应该遵守网站的…...
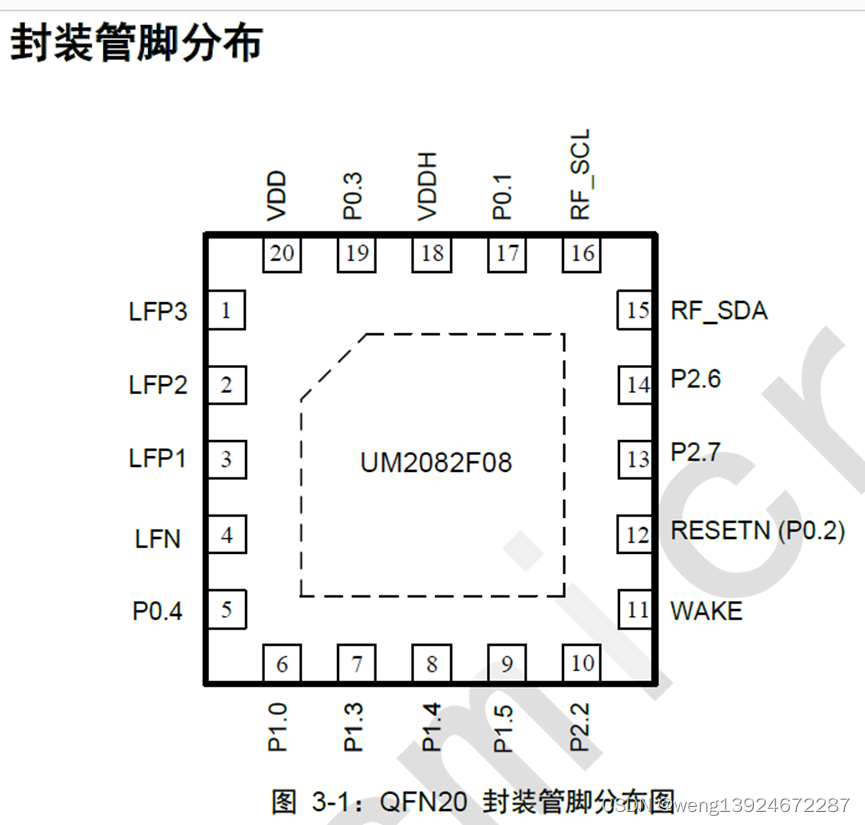
UM2082F08 125k三通道低频无线唤醒ASK接收功能的SOC芯片 汽车PKE钥匙
1产品描述 UM2082F08是基于单周期8051内核的超低功耗8位、具有三通道低频无线唤醒ASK接收功能的SOC芯片。芯片可检测30KHz~300KHz范围的LF (低频)载波频率数据并触发唤醒信号,同时可以调节接收灵敏度,确保在各种应用环境下实现可靠唤醒,其拥…...
【SpringBoot_Project_Actual combat】 Summary of Project experience_需要考虑的问题
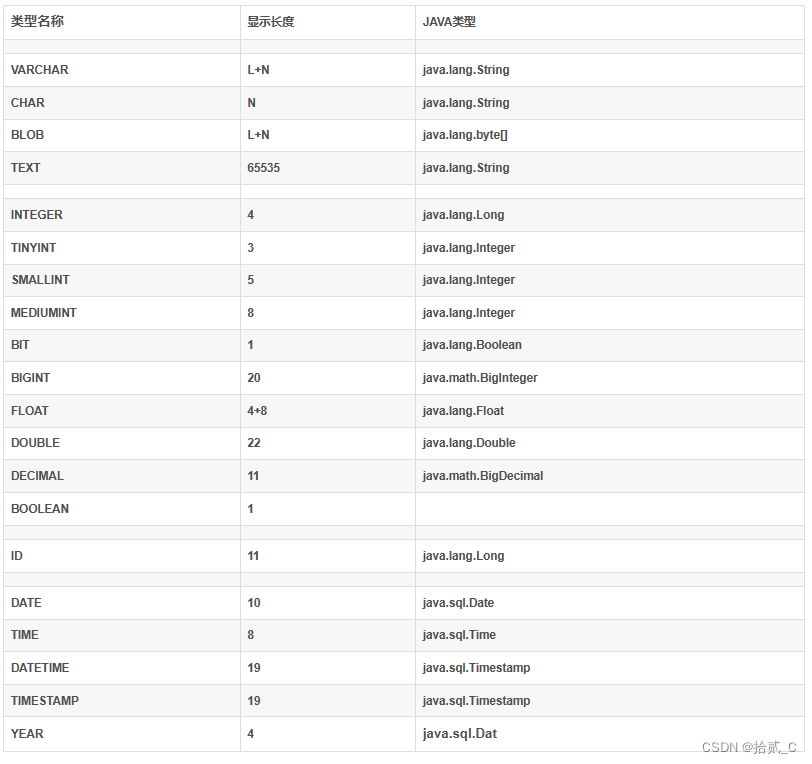
无论是初学者还是有经验的专业人士,在学习一门新的IT技术时,都需要采取一种系统性的学习方法。那么作为一名技术er,你是如何系统的学习it技术的呢。 一、DB Problems 数据库数据类型与java中数据类型对应问题? MySql数据库和java…...

恒容容器放气的瞬时流量的计算与合金氢化物放氢流量曲线的计算
有时候,你会遇到一个问题,该问题的描述如下: 你有一个已知体积的容器,设容器体积为V,里面装有一定压力(初始压力)的气体,如空气或氢气等,设初始压力为1MPa,容器出口连接着一个阀门开…...

网络编程_UDP通信
网络编程_UDP通信 1. TCP与UDP2. 使用UDP通信3. sendto与recvfrom、recv4.实例实例1: 服务器接收、客户端发送实例2:服务器收发、客户方发送、接收。1. TCP与UDP 当使用网络套接字通信时, 套接字的“域”都取AF_INET; 套接字的type: SOCK_STREAM 此时,默认使用TCP协议进行…...
windows修改Pycharm的右键打开方式
title: windows中open floder as Pycharm太长了怎么修改 date: 2023-06-04 author: IoT_H2 tags: windows系统问题 categories: Markdown 问题描述: Pycharm这一栏这么长,长的我实在是很难受,事实上Jetbrains家的软件都是这个鸟模样 导…...
函数(二))
Python入门(十四)函数(二)
函数(二) 1.传递实参1.1 位置实参1.2 关键字实参1.3 默认值 作者:xiou 1.传递实参 函数定义中可能包含多个形参,因此函数调用中也可能包含多个实参。向函数传递实参的方式很多:可使用位置实参,这要求实参…...

Allure测试报告定制全攻略,优化你的Web自动化测试框架!
目录 前言: 1. Allure测试报告简介 2. Web自动化测试框架简介 3. 封装Web自动化框架 3.1 安装Selenium 3.2 封装Selenium 3.3 定制Allure测试报告 3.3.1 适配翻译插件 3.3.2 定制测试报告样式 4. 示例代码 5. 总结 前言: 随着现在Web应用的普…...

推荐系统算法详解
文章目录 基于人口统计学的推荐算法用户画像 基于内容的推荐算法相似度计算基于内容推荐系统的高层次结构特征工程数值型特征处理类别特征处理时间型特征处理统计型特征处理 推荐系统常见反馈数据基于UGC的推荐TF-IDFTF-IDF算法示例1. 引入依赖2. 定义数据和预处理3. 进行词数统…...
企业网站架构部署与优化之LAMP
LAMP LAMP概述1、各组件的主要作用2、各组件安装顺序 编译安装Apache http服务编译安装MySQL服务编译安装PHP解析环境安装论坛 LAMP概述 LAMP架构是目前成熟的企业网站应用模式之一,指的是协同工作的一整套系统和相关软件,能够提供静态和动态Web站点服务…...
攻防世界安卓逆向练习
文章目录 一.easy-so1. jadx分析程序逻辑2. ida查看so文件3. 解题脚本: 二.ezjni1. 程序逻辑分析2. 解题脚本: 三.easyjava1. 主函数逻辑2. getIndex函数3. getChar函数4.解题脚本 四.APK逆向1.程序逻辑分析2.解题脚本3.动态调试 Android2.0app3 一.easy-so 1. jadx分析程序逻…...
)
自然语言处理从入门到应用——自然语言处理的语言模型(Language Model,LM)
分类目录:《自然语言处理从入门到应用》总目录 语言模型(Language Model,LM)(也称统计语言模型)是描述自然语言概率分布的模型,是一个非常基础和重要的自然语言处理任务。利用语言模型ÿ…...
calibre-do-not-translate-my-path技术解析:解决中文路径翻译问题的本地化方案实践指南
calibre-do-not-translate-my-path技术解析:解决中文路径翻译问题的本地化方案实践指南 【免费下载链接】calibre-do-not-translate-my-path Switch my calibre library from ascii path to plain Unicode path. 将我的书库从拼音目录切换至非纯英文(中文…...

救命!2026 转行网络安全值不值?薪资 + 工作 + 前景一篇讲透,不踩坑!
网络安全赛道 1、薪资情况 薪资影响因素 2、工作安排与内容 (1) 工作时间(2) 工作内容 3、网络安全前景展望4、如何提升竞争力5、职业技能总结6、学习资源分享 如果你计划在2025年转行到网络安全领域,以下是一些建议,可以帮助你顺利过渡并打下坚实的…...

Phi-3-Mini-128K惊艳效果:处理含JSON Schema的OpenAPI规范并生成Mock数据
Phi-3-Mini-128K惊艳效果:处理含JSON Schema的OpenAPI规范并生成Mock数据 1. 模型能力概览 Phi-3-Mini-128K是基于微软Phi-3-mini-128k-instruct模型开发的轻量化对话工具,专为处理复杂技术文档和结构化数据而优化。这个128K超长上下文的模型在解析技术…...

短视频创作者必备:Qwen3本地字幕生成工具,5步快速上手
短视频创作者必备:Qwen3本地字幕生成工具,5步快速上手 1. 引言:为什么需要本地字幕生成工具 作为短视频创作者,你是否经常遇到这样的困扰:剪辑完视频后,手动添加字幕耗时费力;使用在线工具又担…...

Fish Speech 1.5保姆级教程:零代码实现Markdown文档转语音
Fish Speech 1.5保姆级教程:零代码实现Markdown文档转语音 1. 为什么选择Fish Speech 1.5? 在日常工作中,我们经常需要处理大量Markdown格式的技术文档。传统的文本转语音工具往往存在几个痛点:声音机械生硬、无法处理Markdown特…...

Unity热力图性能优化实战:如何用ScriptableObject管理数据,让MeshRenderer渲染百个热点不卡顿
Unity热力图性能优化实战:ScriptableObject与GPU加速方案解析 当你在军事模拟系统中需要实时显示数百个单位的活动热点,或在智慧城市平台中可视化人流密度时,传统每帧重算Texture的热力点渲染方案很快就会遇到性能瓶颈。本文将分享一套经过实…...
)
告别fdisk!用parted命令轻松管理4TB以上大硬盘(附实战案例)
告别fdisk!用parted命令轻松管理4TB以上大硬盘(附实战案例) 当你的NAS存储阵列需要扩容到8TB,或是数据库服务器要配置12TB的RAID组时,传统的fdisk工具会在第一个指令就给你泼冷水——它根本不认识超过2TB的磁盘空间。这…...

OpenClaw新手避坑:Qwen3-32B镜像部署的10个常见错误
OpenClaw新手避坑:Qwen3-32B镜像部署的10个常见错误 1. 为什么Qwen3-32B镜像部署容易踩坑? 第一次在本地部署Qwen3-32B镜像对接OpenClaw时,我天真地以为只要按照文档操作就能一帆风顺。结果从环境配置到服务启动,整整折腾了两天…...

低成本硬件在环方案:不用NI/dSPACE如何实现Simulink+Carsim实时仿真
低成本硬件在环方案:不用NI/dSPACE如何实现SimulinkCarsim实时仿真 在汽车电子和自动驾驶研发领域,硬件在环(HIL)测试是验证控制算法可靠性的关键环节。传统方案依赖NI或dSPACE等昂贵设备,动辄数十万的投入让中小团队望…...
工程下的输出质量)
PROJECT MOGFACE效果对比:不同提示词(Prompt)工程下的输出质量
PROJECT MOGFACE效果对比:不同提示词(Prompt)工程下的输出质量 你是不是也遇到过这种情况?用同一个AI模型,别人生成的回答妙语连珠,你得到的却平平无奇。问题可能就出在那几句“悄悄话”——提示词上。 今…...