STL库(1)
STL库(1)
- vector
- vector介绍
- vector使用
- 初始化
- 元素访问
- 内存扩容
- 插入删除
- list
- list介绍
- 初始化,元素访问
- 插入
- 删除元素
- vector和list区别
vector
vector介绍
- vector是可以改变大小的数组的容器。
- 其内存结构和数组一样,使用连续的存储空间,也就可以使用指针指向其元素,通过偏移量来访问存储空间中的元素。
- 和数组不同之处在于vector的大小可以动态的变化,容器可以自动扩容存储空间。
- vector使用一个动态分配的连续存储空间来存储元素,在插入新元素的时候也可能需要重新分配存储空间,也就意味着每次扩容都需要将其元素重新移动到新的存储空间中,很显然这效率是非常低的,为此不会每次像容器中添加元素都重新分配。
- 容器可以分配一些额外的存储空间以适应添加的对象,其每次扩容以原本的1.5或2倍来扩容。
- 与其他的容器相比,vector可以更加高效的访问其他元素,并且可以高效的从尾部添加或者删除元素。对于节位意外的位置插入删除效率较低。
vector使用
初始化
int main() {vector<int> iar;vector<double> dar(12,10,0);vector<int> ibr={1,2,3,4,5,6};vector<Int> Iar;//处理自定义类型vector<int*>par;//尽量别这么使用,因为其可能指向动态申请的内存,其不会主动释放。
}
元素访问
1.at访问(返回的是引用,可以进行修改)
2.下标访问
3.data()返回首地址,通过首地址偏移量进行解引用操作。
4.迭代器
5.范围for
int main() {vector<int> iar={1,2,3,4,5};int n=iar.size();for(int i=0;i<n;i++) {ibr.at(i)+=10;cout<<iar.at(i)<<" "<<iar[i]<<endl;}cout<<iar.back()<<endl;cout<<iar.front()<<endlint* p=ibr.data();for(int i=0;i<n;++i) {cout<<p[i]<<endl;//*(p+i);}for(auto &x:iar) {cout<<x<<" ";}vector<int>::iterator it=iar.begin();vector<int>::const_iterator cit=iar.begin();vector<int>::reverse_iterator rit=iar.rbegin();//逆向迭代器for(;rit!=rend();) {cout<<*rit<<endl;}vector<int>::const_reverse_iterator it=iar.rbegin();for(;it!=iar.end();){(*it)-=100;cout<<*it<<endl;}
}
内存扩容
int main() {
vector<int> var ;for (int i = 0; i < 100; i++) {var.push_back(i);cout << "size:" << var.size() << endl;;cout << "capacity:" << var.capacity() << endl;}
}
运行上面代码我们观察输出结果:
其容量分别是:1,2,3,4,6,9,13,19…其扩容分别按照原本的1.5倍扩容,如果其1.5倍和原本一样就对容量进行+1操作。
这里我们用的是内置类型,如果是我们自己定义的类呢,就会发生这样的过程,比如我们定义的是ptr类,类中存在构造,拷贝构造,移动构造,移动赋值,析构等函数此处不做编写。
扩容等操作我们来具体理解以下:
int main() {std::vector<Ptr> ar;for(int i=0;i<100;i++) {ar.push_back(Ptr(i));cout << "size:" << ar.size() << endl;;cout << "capacity:" << ar.capacity() << endl;}
}
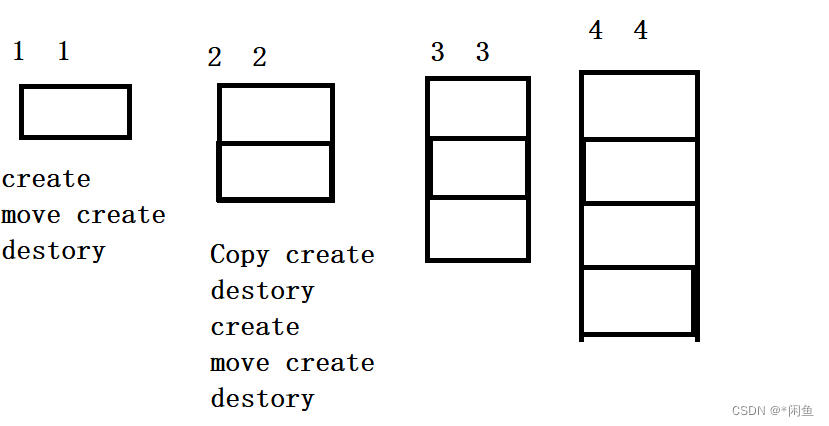
首先观察第一张图,容量为1,大小为1,在首先会调用缺省构造函数来构造ptr的无名对象,其为右值,然后使用移动构造来将无名对象的资源移动到新的对象中,该对象就存在于容器中,然后析构无名对象。紧接着当再次添加对象的时候需要进行扩容处理,其扩容就是重新申请一块内存,将原本内存中的资源拷贝一份放入新的内存中,然后释放旧的资源。为此我们可以看到其调用拷贝构造函数,创建新对象来放入新内存中,然后析构掉原本的对象,然后创建新添加的对象,移动构造来移动无名对象的资源,最后析构无名对象。这就是其扩容的内部操作。很明显效率很低,在不断的构建对象和析构对象。
为此呢我们可以使用reserve()函数。
int main() {std::vector<Ptr> ar;ar.reserve(200);//ar.resize(200);//ar.assign(10,Ptr(10));for(int i=0;i<100;i++) {ar.push_back(Ptr(i));cout << "size:" << ar.size() << endl;;cout << "capacity:" << ar.capacity() << endl;}
}
该函数可以直接申请够200个对象的内存,不会进行反复的扩容和拷贝构造,和这个函数相仿的还存在一个resize()函数,该函数与其不同之处在于,这个函数在申请内存之后会创建100个对象,为此加入对象的时候会从第100个后面进行添加。还存在一个assign()函数,该函数页会创建对新象,不过其需要指定创建的对象。
插入删除
int main() {std::vector<Ptr> ar;ar.reserve(10);ar.push_back(Ptr(1));ar.push_back(Ptr(2));ar.push_back(Ptr(3));ar.push_back(Ptr(4));ar.push_back(Ptr(5));vector<Ptr>::operator it=ar.begin();ar.insert(it,Ptr(6));for(auto &x:ar){x.Print();}ar.pop_back();
}
很明显vector的插入删除一般都是在尾部插入删除,而通过迭代器和插入函数头部插入时,必然将后面所有的元素都要向后移动,效率大幅度降低,当我们使用了迭代器之后然后尾删的时候很明显出现了程序崩掉的现象,这是为什么呢?因为我们对迭代器进行操作之后迭代器失效了。为什么会失效呢?迭代器实际上是和对象绑定的,
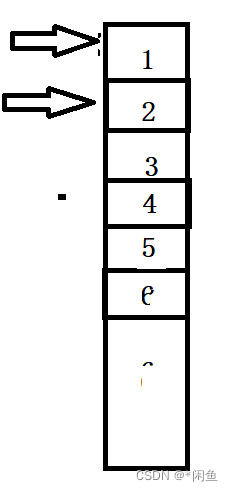
我们的迭代器是和对象绑定的,例如迭代器此时指向首元素1,然后进行了头删,那么头结点内存释放了,对象丢失了为此迭代器也就丢失了。而扩容依然是如此,重新申请了内存,拷贝了资源,那么原本的对象就丢失了,迭代器也就丢失了。
list
list介绍
- list是序列容器,允许在序列中任何位置执行O(1)时间的插入和删除,并在两个方向上进行迭代。
- 其底层结构是双链表,将每个元素存储在不同的存储位置,每个结点通过next,prev指针连结成的顺序表。
- list与其他容器相比,可以在任何位置插入和删除,获得迭代器的情况下时间复杂度为O(1).
- 不能通过下标访问,需要通过迭代器找到位置才可以访问,需要遍历的时间开销。
- 存储密度低,使用一些额外的内存空间(next,prev指针)来保持每个元素的关联性,从而导致存储小元素的列表存储密度低。
初始化,元素访问
数组初始化,范围for遍历
int main() {std::list<int> arlist={1,2,3,4,5,6,7,8};cout<<arlist.back()<<endlcout<<arlist.front()<<endl;for(auto& x:arlist) {cout<<x<<" "; }
}
插入
int main() {std::list<Ptr> arlist;for(int i=0;i<5;i++) {//arlist.push_back(Ptr(i));arlist.emplace_back(i);}for(const auto &x:arlist) {x.Print(); }
}
因为其list容器结构是双链表结构,所以我们进行头插尾插的效率都是一样的,不过push_back插入我们知道是先创建对象,然后进行移动构造来插入数据,效率较低,为此在list中存在emplace_back函数,他和push_back不同之处在于他是原位构造,直接在申请的内存上构造对象,不会进行移动构造然后析构对象。范围for遍历时也最好用常引用,如果不是引用便会调用拷贝构造构造对象来调用Print函数输出,使用引用就可以不在调用拷贝构造函数,大大节省了时间和空间。而加入const可以保证容器中的元素不发生改变。
同vector一样,也list容器中最好不要使用指针,为什么呢?
int main() {std::list<Ptr*> arlist;for(int i=0;i<5;i++) {//arlist.push_back(Ptr(i));arlist.emplace_back(new Ptr(i));}for(const auto &x:arlist) {x->Print(); }
}
我们使用上面代码的时候很明显其没有析构对象,因为容器中是指针,其不能判断内部是不是动态申请了内存而释放他,所以呢就不会进行析构,为此最好不要使用指针,要析构就要在范围for中使用delete析构。或者使用智能指针。
删除元素
- erase():删除指定位置的元素,也可以删除某个区间的多个元素。
- clear():删除所有元素。
- remove(val):删除所有等于val的元素。
- unique():删除容器中相邻的重复元素。
int main() {list<int> ilist={1,2,3,4,5,1,2,3,4,5};ilist.sort();ilist.unique();for(auto &x :ilist) {cout<<x<<" ";}
}
unique()删除通过上面代码就可以展示出来。
list中的sort排序底层是快排,而当数据量足够大的时候呢就会存在一个阈值,高于这个值就会使用归并排序。
vector和list区别
| vector | list | |
|---|---|---|
| 底层实现 | 连续存储的容器,动态数组,对上分配空间 | 动态双向链表,堆上分配空间 |
| 空间利用率 | 连续空间,不易造成内存碎片化,空间利用率高 | 节点不连续,容易造成内存碎片化,小元素使结点密度低,空间利用率低 |
| 查找元素 | 下标,at,find,binary_search() | find O(n) |
| 插入 | push_back(val);O(1)//空间足够 | O(1) |
| 迭代器 | 随机迭代器,检查越界,支持++,–,==,+=,… | 双向迭代器,检查越界,支持++,–,==,!= |
| 迭代器失效 | 插入删除都会导致迭代失效 | 插入元素不会导致迭代器失效,删除会导致迭代器失效,不影响其他迭代器 |
两者适用情况:
- 需要高效得随机存储,不在乎插入删除效率(很少使用插入删除),选用vector
- 需要大量得插入删除,苏哦系取值很少使用,选用list。
相关文章:
STL库(1)
STL库(1) vectorvector介绍vector使用初始化元素访问内存扩容插入删除 listlist介绍初始化,元素访问插入删除元素 vector和list区别 vector vector介绍 vector是可以改变大小的数组的容器。其内存结构和数组一样,使用连续的存储…...
玻璃制品行业丨外贸业务管理难点及解决方案
玻璃作为一种重要的建筑材料,在国际贸易中一直占有一定的份额。随着国外市场需求量的不断增加,对玻璃制品的技术含量要求越来越高,需要在研发方面的投入也逐步加大。由于国际市场竞争激烈,想要做玻璃制品行业的外贸公司࿰…...

Spring Boot如何实现自定义Spring Boot启动器
Spring Boot如何实现自定义Spring Boot启动器 在Spring Boot中,启动器(Starter)是一组依赖项的集合,它们一起提供了某个特定的功能。使用Spring Boot启动器可以让我们更加方便地集成第三方库和框架,并且可以避免版本冲…...
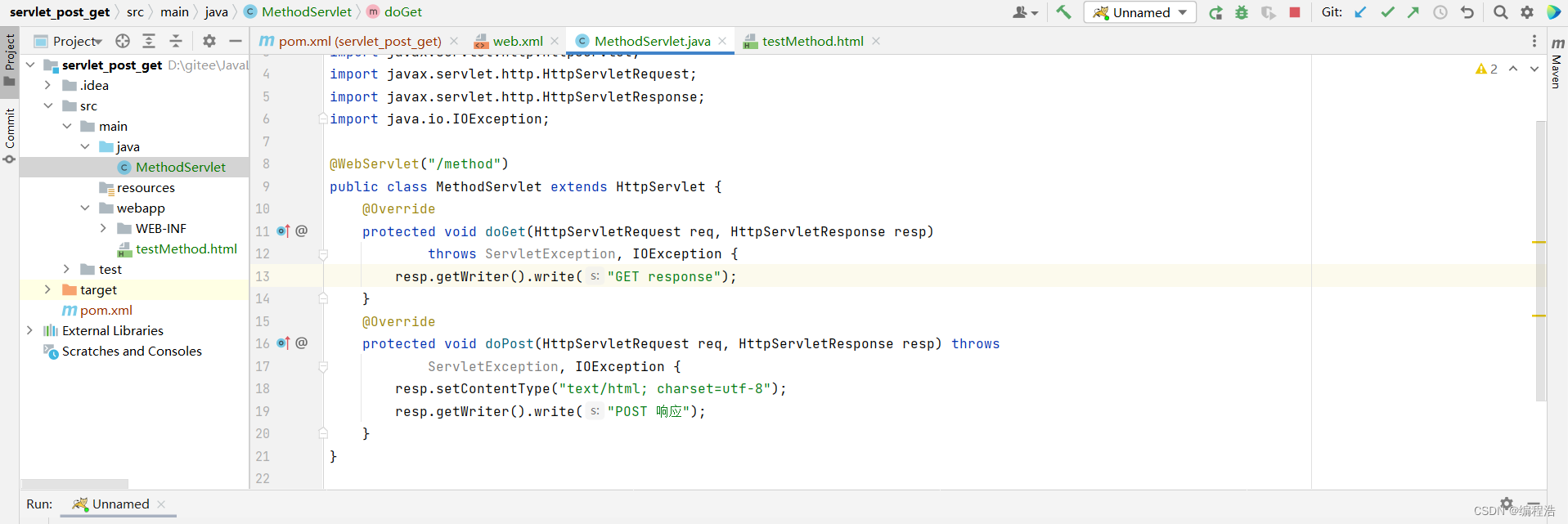
【面试题HTTP中的两种请求方法】GET 和 POST 有什么区别?
GET 和 POST 有什么区别? 1.相同点和最本质的区别1.1 相同点1.2 最本质的区别 2.非本质区别2.1 缓存不同2.2 参数长度限制不同2.3 回退和刷新不同2.4 历史记录不同2.5 书签不同 总结代码示例 GET 和 POST 是 HTTP 请求中最常用的两种请求方法,在日常开发…...
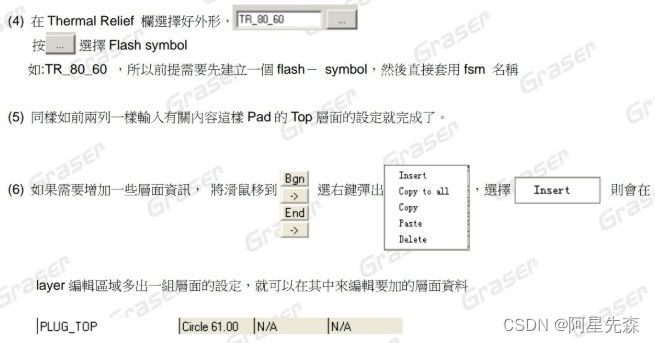
Allegro16.6详细教程(三)
確定Pad的層面 (1)用Single layer mode開關來控制pad type 勾選Single layer mode,則pad為單面孔,比如SMD 不勾選Single layer mode,則pad為通孔,比如:via (2)用滑鼠左鍵點選BEGIN LAYER彈出下面3個欄位 Regular, Thermal Relief, Anti Pad;Regular用於正片,Thermal R…...
离散分布分析示例)
Python3数据分析与挖掘建模(6)离散分布分析示例
1. 离散分布分析示例 相关库: pandas详细用法 numpy详细用法 1.1 引入算法库 # 引入 pandas库 import pandas as pd # 引入 numpy库 import numpy as np# 读取数据 dfpd.read_csv("data/HR.csv")# 查看数据 df Out[6]: satisfaction_level last_eval…...

汇编语言程序设计基础知识二
五、顺序结构 1、程序设计的步骤 1、分析问题 2、建立数据模型 3、设计算法 4、编制程序 5、上机调试 2、流程图的应用 3、程序的基本控制结构 1、顺序结构:程序顺序执行,不发生跳转 2、分支结构:程序在执行过程中发生跳转 3、循环…...

一文详解!Robot Framework Selenium UI自动化测试入门篇
目录 前言: 自动化框架的选择 测试环境的搭建 导入Selenium2Library包 关键字是什么? 创建测试用例 前言: 自动化测试的重要性越来越受到人们的重视,因为它可以提高测试效率、降低测试成本并减少人为错误的出现。为了满足这…...

Java 9 模块化系统详解
Java 9 模块化系统详解 一、简介1. 引入模块化系统原因2. 模块化系统带来的优势和挑战3. 模块化关键概念 二、模块化基础1. 模块化源代码结构规范2. 模块定义与描述符3. 打包可执行模块 三、模块化系统的高级特性1. 模块发现与解决依赖2. 模块化升级与替换3. 模块化动态访问 四…...
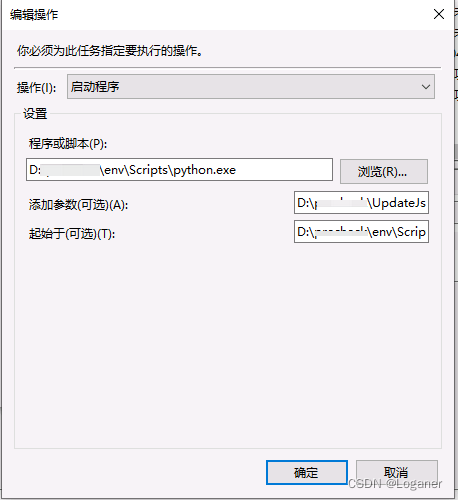
Windows定时执行Python脚本
在Linux环境下我们可以使用crontab工具来定时的执行脚本,可以很轻松的管理各个虚拟环境下的py文件在Windows上可以使用任务计划程序来定时执行我们的脚本 关于这个的基本使用可以查看我前面的博客 https://blog.csdn.net/wyh1618/article/details/125725967?spm10…...

数据科学简介:如何使用 Pandas 库处理 CSV 文件
部分数据来源:ChatGPT 什么是 CSV 文件? CSV ( Comma Separated Values)文件是一种常见的文本文件格式,它通常用于存储结构化数据,因为它可以轻松地转换成电子表格,如Excel。 CSV 文件是以逗号作为分隔符的表格数据。文件中的每行代表一个记录,每列代表一个属性。例如…...
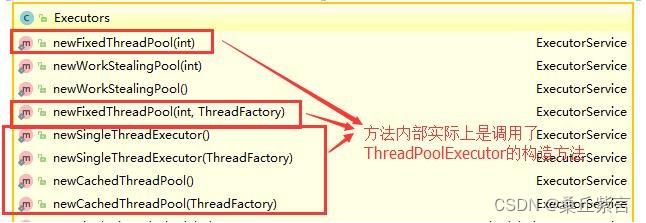
面试专题:java多线程(2)-- 线程池
1.为什么要用线程池? 线程池提供了一种限制和管理资源(包括执行一个任务)。 每个线程池还维护一些基本统计信息,例如已完成任务的数量。 这里借用《Java并发编程的艺术》提到的来说一下使用线程池的好处: 降低资源消…...

Linux文件权限及用户管理
文件权限 在Linux中,每个文件和目录都有一组权限,这些权限决定了哪些用户可以访问文件或目录,以及他们可以进行什么样的操作。权限分为三类: 所有者权限:这些权限适用于文件或目录的所有者。 组权限:这些…...

以AI为灯,照亮医疗放射防护监管盲区
相信绝大部分人都有在医院拍X光片的经历,它能够让医生更方便快速地找出潜在问题,判断病人健康状况,是医疗诊断过程中的常见检查方式。但同时X射线也是一把双刃剑,它的照射量可在体内累积,对人体血液白细胞有杀伤力&…...
:单元测试的基本使用方法)
Golang单元测试详解(一):单元测试的基本使用方法
Golang 单元测试 Golang 中的单元测试是使用标准库 testing 来实现的,编写一个单元测试是很容易的: 创建测试文件:在 Go 项目的源代码目录下创建一个新的文件(和被测代码文件在同一个包),以 _test.go 为后…...

数据库的序列
目录 一、序列是什么 二、序列的用途 二、创建序列 三、查看、修改、删除序列 四、使用序列 (1)在插入语句中使用 (2)不在插入语句中使用 五、使用序列的例子 一、序列是什么 数据库对象分为:用户、视图、索引…...

2022年回顾
年总写完了(已持续多年),顺便写个小的回顾。 寻找属于自己的方向 无论当前干啥,大多数都不是真正适合你的,但是,你又不能不做下去,那么,持续的寻找适合的,就是一种解开…...
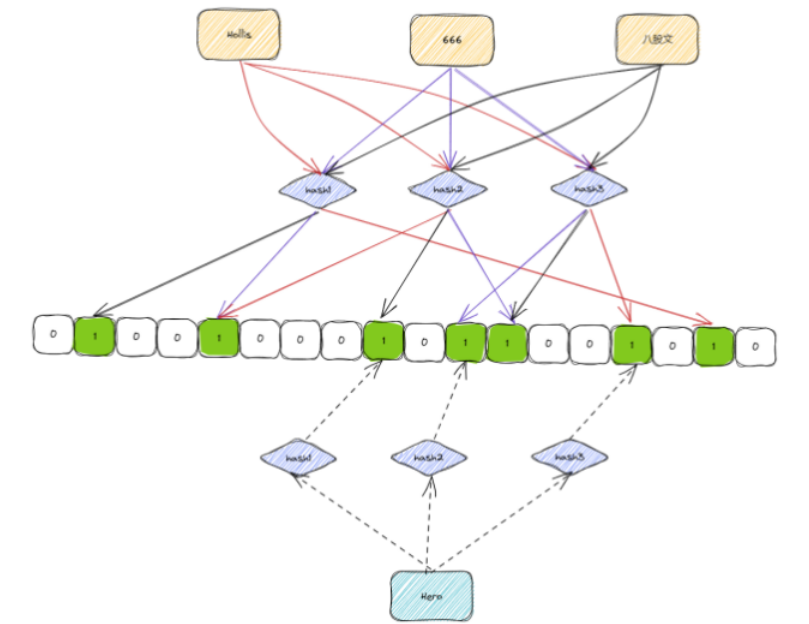
40亿个QQ号,限制1G内存,如何去重?
40亿个unsigned int,如果直接用内存存储的话,需要: 4*4000000000 /1024/1024/1024 14.9G ,考虑到其中有一些重复的话,那1G的空间也基本上是不够用的。 想要实现这个功能,可以借助位图。 使用位图的话&a…...

【django】django的orm的分组查询
前言:django当中分组查询如何实现? annotate from myapp import models from django.db.models.functions import TruncMonth from django.db.models import Count,Avg# 分组 values 就是取值作用 model.Book.objects.values(month).annotate(countCo…...

MySQL5.8在Windows下下载+安装+配置教程
MySQL是一款常用的关系型数据库管理系统,本文将介绍MySQL5.8在Windows下的安装配置教程。 1. 软件下载地址 免安装版下载地址:https://dev.mysql.com/downloads/mysql/安装版下载地址:https://dev.mysql.com/downloads/installer/ 2. 免安…...
了!Python机器学习模型评估的5种实用方法对比)
别再只盯着model.score()了!Python机器学习模型评估的5种实用方法对比
超越model.score():Python机器学习模型评估的五大实战工具 当你的机器学习模型在测试集上表现不佳时,model.score()给出的单一数值往往无法揭示问题的全貌。就像医生不能仅凭体温判断病情一样,数据科学家也需要更丰富的诊断工具来全面评估模型…...
)
面试官:什么是最左前缀匹配?为什么要遵守?(修订版)
在线 Java 面试刷题(持续更新):https://www.quanxiaoha.com/java-interview面试考察点原理理解:面试官不仅仅想知道你会背 "最左前缀原则",更想考察你是否理解联合索引的 B 树存储结构,能否从数据…...

QwQ-32B在自然语言处理中的实战应用
QwQ-32B在自然语言处理中的实战应用 1. 引言:当NLP遇上推理专家 自然语言处理(NLP)领域最近迎来了一位强力选手——QwQ-32B。这不是普通的语言模型,而是一个专门为推理和思考设计的模型。想象一下,你有一个不仅能理解…...

哔哩下载姬downkyi:零基础到专业级的B站视频高效管理指南
哔哩下载姬downkyi:零基础到专业级的B站视频高效管理指南 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&am…...

Phi-3 Forest Lab效果展示:对CI/CD流水线失败日志的因果推理与修复路径推荐
Phi-3 Forest Lab效果展示:对CI/CD流水线失败日志的因果推理与修复路径推荐 1. 引言:当森林智慧遇见工程难题 在软件开发的世界里,CI/CD流水线就像一条永不停歇的生产线。但当这条生产线突然停止运转时,开发团队往往要花费数小时…...

不止是发布:手把手教你用Anolis OS 8.9的KeenTune和Alibaba Cloud Compiler优化云原生应用性能
深度实战:用Anolis OS 8.9的KeenTune与Alibaba Cloud Compiler打造云原生性能引擎 当云原生应用的QPS从5000飙升到20000时,性能调优就不再是选择题而是必答题。Anolis OS 8.9带来的KeenTune和Alibaba Cloud Compiler组合,就像给开发者配备了一…...

3大革新性功能!VoiceFixer全方位语音修复工具让受损音频焕发新生
3大革新性功能!VoiceFixer全方位语音修复工具让受损音频焕发新生 【免费下载链接】voicefixer General Speech Restoration 项目地址: https://gitcode.com/gh_mirrors/vo/voicefixer 你是否遇到过珍贵录音因噪音模糊不清的窘境?是否因会议录音质…...

DanKoe 视频笔记:《百万美元创意者》:如何将你的兴趣货币化 [特殊字符]
在本节课中,我们将学习如何将个人兴趣转化为可持续的收入来源。我们将探讨传统职业路径的局限性,并介绍一种通过创造力和杠杆式工作来实现财务自由与生活满足感的新方法。课程的核心在于理解如何成为一个“价值创造者”,而不仅仅是出售时间。…...

Zotero-GPT:智能文献处理的技术实现与应用指南
Zotero-GPT:智能文献处理的技术实现与应用指南 【免费下载链接】zotero-gpt GPT Meet Zotero. 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-gpt 一、价值定位:重新定义文献管理的智能化范式 1.1 技术架构的革新突破 Zotero-GPT作为Zot…...

别只玩文生图了!手把手教你用Stable Diffusion 1.4的VAE模型,无损压缩和重构你的本地图片
解锁Stable Diffusion VAE的隐藏技能:从AI绘画到专业图像处理实战 你是否曾为海量图片的存储空间发愁?或是苦恼于传统图像处理工具的繁琐流程?今天,我们将颠覆你对Stable Diffusion的认知——它的VAE模型远不止是AI绘画的配角&…...