MySQL 数据库全局变量中文解释
| Name | Value |
|---|---|
| auto_increment_increment | AUTO_INCREMENT 字段值的自增长步长值。 |
| auto_increment_offset | AUTO_INCREMENT 字段值的初始值。 |
| autocommit | 指示新连接的默认提交模式是否启用。 |
| automatic_sp_privileges | 控制是否在存储过程上创建或更改时自动分配特定权限。 |
| back_log | 在开始拒绝新连接之前,等待处理的未完成连接数。 |
| basedir | MySQL 服务器安装的基本目录路径。 |
| binlog_cache_size | 事务性语句在使用存储引擎的引擎日志缓冲区覆盖更新操作期间保留的最大内存大小。 |
| bulk_insert_buffer_size | 在使用 INSERT DELAYED 时撰写到 MyISAM 表中的数据缓冲区大小。 |
| character_set_client | 客户端字符集。 |
| character_set_connection | 当前连接的默认字符集。 |
| character_set_database | 默认数据库字符集。 |
| character_set_filesystem | 文件系统字符集。 |
| character_set_results | 结果字符集。 |
| character_set_server | 服务器字符集。 |
| character_set_system | MySQL 系统字符集。 |
| character_sets_dir | 可用字符集文件的目录名称。 |
| collation_connection | 当前连接的默认排序规则。 |
| collation_database | 默认数据库排序规则。 |
| collation_server | 服务器排序规则。 |
| completion_type | 用于自动完成的方法。可以是 NONE、NO_CHAIN 或 CHAIN。 |
| concurrent_insert | 指示是否启用 CONCURRENT INSERT。 |
| connection_control_failed_connections_threshold | 超出将为连接失败计数器累加的连接失败次数时触发其它限制的值。 |
| connection_control_max_connection_delay | 允许连接的最大延迟时间。 |
| connect_timeout | 在以秒为单位指定的时间内尝试建立到 MySQL 服务器的连接,如果到期,则中止连接尝试。 |
| core_file | 指示将为 MySQL Server 生成核心文件,如果服务器崩溃或遇到致命错误。 |
| create_admin_listener_thread | 如果 TRUE,则针对每个已加入的管理员在 MySQL Server 启动时创建一个专用线程。 |
| daemon_memcached_engine_lib_name | 由 daemon_memcached 指定的内存缓存引擎的库名称。 |
| daemon_memcached_option_disable_blob | 指示是否忽略对 memcached_test 的 BLOB 类型进行所有编码解码。 |
| daemon_memcached_option_no_block | 指示是否在 memcached 向 daemond 进行 IO 操作时启用非阻塞 IO。 |
| datetime_format | 将日期和时间值编码为字符串的格式。 |
| date_format | 将日期值编码为字符串的格式。 |
| default_authentication_plugin | 客户端连接时要使用的默认身份验证插件。 |
| default_password_lifetime | 新用户的默认密码过期值。 |
| default_storage_engine | 新表的默认存储引擎。 |
| default_table_encryption | 新表默认的加密类型。 |
| default_week_format | 规定周的起始日。 |
| delay_key_write | 指示要在执行 MyISAM 表上的批量插入之前推迟索引键写入。 |
| delayed_insert_limit | INSERT DELAYED 中允许等待写入缓冲区的行数的限制。 |
| delayed_insert_timeout | INSERT DELAYED 等待行写入缓冲区的时间限制。 |
| delayed_queue_size | INSERT DELAYED 缓冲区的大小。 |
| disconnect_on_expired_password | 指示是否应在帐户过期时断开连接。 |
| div_precision_increment | DOUBLE 或 FLOAT 类型上的数字计算中较小的增量,以支持数学精度。 |
| end_markers_in_json | 指示是否在 JSON 的内嵌数组和对象结尾处添加符号。如果包含,则启用,否则将禁用。 |
| enforce_gtid_consistency | 指示是否强制所有事务都为 GTID 事务,并且在所有副本上运行时保持一致。 |
| eq_range_index_dive_limit | 搜索过程中在等价范围索引查找之前要查询的树的层数的限制。 |
| event_scheduler | 指示 event scheduler 是否已启用,并且表示当前正在运行的调度程序线程数。 |
| expire_logs_days | 在将二进制日志文件切换到新文件之前,控制可以保留多少天的旧二进制日志文件。 |
| explicit_defaults_for_timestamp | 使用默认 TIMESTAMP 或 DATETIME 值的规则。 |
| external_user | 此变量由 plugin_auth 所使用,以指定可用于计算帐户验证插件数据的用户名称。 |
| flush | 指示触发哪些数据更改将刷新到磁盘。 |
| flush_time | 自动刷新所有 MyISAM 表的间隔时间。 |
| foreign_key_checks | 是否强制实施外键约束。 |
| ft_boolean_syntax | 指定 MATCH ... AGAINST 查询中可以使用的 “和”、“或”、“非” 语法。 |
| ft_max_word_len | 识别为完整词语的最小长度。 |
| ft_min_word_len | 识别为完整词语的最大长度。 |
| ft_query_expansion_limit | 定义用于在扩展以 EXPAND() 为关键字的全文搜索查询中使用的最大单词数。 |
| gtid_executed | 已执行的 GTID 集合。 |
| gtid_mode | 决定 GTID 的使用模式。 |
| gtid_next | GTID 下一个选择,将于事务开始时使用。 |
| gtid_owned | GTID 已拥有的集合。 |
| have_compress | 是否支持压缩。 |
| have_crypt | 是否支持密码函数。 |
| have_dynamic_loading | 是否允许加载共享库。 |
| have_geometry | 是否启用空间数据类型。 |
| have_innodb | 是否启用 InnoDB 存储引擎。 |
| have_ndbcluster | 是否启用 NDB 存储引擎。 |
| host_cache_size | 服务器为来自一个特定主机的连接分配的可用连接的数量。 |
| hostname | 服务器的主机名。 |
| identity | 插件 auth_pam 配置文件中要用于身份验证的 PAM 身份验证模块。 |
| ignore_builtin_innodb | 指示是否禁止计数器和状态变量来自内置的 InnoDB。 |
| ignore_db_dirs | 指定要排除的目录列表的逗号分隔列表。 |
| index_statistics | 是否收集索引统计信息。 |
| init_connect | 初始化连接字符串。 |
| init_file | 在服务器启动时读取的 SQL 文件列表。 |
| init_slave | 如果设置,则 slave 启动时将执行标识的初始化 SQL 语句。 |
| innodb_adaptive_flushing | 在重做日志写入成本太高时,如果启用 adaptive flushing,则系统将自动尝试减少脏页的数量。 |
| innodb_adaptive_flushing_lwm | 当 innodb_adaptive_flushing 启用时,指定透明刷新优先级别的水位标识。 |
| innodb_adaptive_hash_index | 是否启用自适应哈希索引。 |
| innodb_adaptive_hash_index_partitions | 自适应哈希索引分区数。 |
| innodb_adaptive_max_sleep_delay | 自适应 flap 时,指定连续的最大延迟时间。 |
| innodb_autoextend_increment | 增加大小已用尽时自动扩展表空间时的增量。 |
| innodb_autoinc_lock_mode | AUTO_INCREMENT 字段的锁定模式。 |
| innodb_background_scrub_data_check_interval | 后台数据缓存清理期间每个页面检查到上次检查所进行的进度时,每个 Extent 检查的页面数。 |
| innodb_background_scrub_data_compressed | 指示后台步骤是否应概括地检查和更新压缩的表。 |
| innodb_background_scrub_data_interval | 后台数据缓存清理任务之间的检查间隔。 |
| innodb_background_scrub_data_uncompressed | 指示后台步骤是否应块阅读和检查未压缩的数据文件区域。 |
| innodb_bg_check_constraints_interval | 后台线程检查错误约束的时间间隔。 |
| innodb_buffer_pool_chunk_size | 内存池分配缓存空间的大小。 |
| innodb_buffer_pool_dump_at_shutdown | 是否在关闭之前转储缓存池中的页面。 |
| innodb_buffer_pool_dump_now | 是否立即转储缓存池中的页面。 |
| innodb_buffer_pool_dump_pct | 当 innodb_buffer_pool_dump_at_shutdown 设置为 ON 时,用于指定要舍弃的缓存页的百分比。 |
| innodb_buffer_pool_filename | Innodb 缓冲区池文件名。 |
| innodb_buffer_pool_instances | 缓存池的分区数。 |
| innodb_buffer_pool_load_abort | 如果 innodb_buffer_pool_load_at_startup 不为 OFF,并且在从磁盘加载缓存池时出现 I/O 错误,是否停止加载缓存池。 |
| innodb_buffer_pool_load_at_startup | 是否在启动时从磁盘加载缓存池。 |
| innodb_buffer_pool_load_now | 是否立即从磁盘加载缓存池。 |
| innodb_buffer_pool_populate | 指示服务器是否应尝试在将从磁盘加载的缓存池装入到内存前填充 InnoDB 索引和数据文件的 InnoDB 页缓存。 |
| innodb_buffer_pool_size | InnoDB 存储引擎的缓冲池大小。 |
| innodb_change_buffer_max_size | 改变缓冲区的最大大小。 |
| innodb_change_buffering | 指示 InnoDB 是否启用和停用改变缓冲区。 |
| innodb_checkpoint_algorithm | 对于 innodb_buffer_pool_instances 大于 1 的系统,在调度脏页刷新到磁盘之前要使用的算法。 |
| innodb_checkpoint_batch_size | MySQL 向磁盘写入批量脏页的数目。 |
| innodb_checkpoint_max_age | MySQL 保留最旧 LSN(日志序列号)以强制将脏页从数据文件中刷新到磁盘的时间量。 |
| innodb_column_stats | 是否收集列统计信息。 |
| innodb_commit_concurrency | InnoDB 使用的实际并发线程数。 |
| innodb_compression_algorithm | 压缩算法类型。 |
| innodb_compression_default | 将使用的默认压缩算法。 |
| innodb_compression_failure_threshold_pct | 服务器是在累计压缩失败时,停止尝试压缩页或退出表或索引的压缩模式。 |
| innodb_compression_level | 压缩算法的默认压缩等级。 |
| innodb_compression_pad_pct_max | 当整个页压缩后为 filler 的最大页大小时,每个表单元区域中未压缩数据可以填充的填充比例。 |
| innodb_concurrency_tickets | 储存可以解决互斥锁的进程和线程数的一个队列。 |
| innodb_data_file_path | Innodb 数据文件名和大小。 |
| innodb_data_home_dir | InnoDB 数据目录的路径。 |
| innodb_deadlock_detect_interval | 检测死锁的频率。 |
| innodb_default_row_format | 默认的 InnoDB 行格式。 |
| innodb_defragment | 是否开启 Innodb 表在线碎片整理。 |
| innodb_defragment_fill_factor | 指定当重组表正在创建一个新重组版本时,要使用的表访问方法的填充因子。 |
| innodb_defragment_fill_factor_n_recs | 指定填充因子的最小记录数。 |
| innodb_defragment_frequency | 多久运行一次在线碎片整理。 |
| innodb_defragment_n_pages | 是否被挤出缓冲池的页的数量。 |
| innodb_defragment_stats_accuracy | 表示多个实例如何汇总 DBMS_DATAFILE_DEFRAG_STATS 视图的输出。 |
| innodb_disable_sort_file_cache | 是否禁用 InnoDB 文件排序器缓存。 |
| innodb_disallow_writes | 指示是否将 Innodb 存储引擎置于只读模式。 |
| innodb_doublewrite | 是否启用定向写入。 |
| innodb_encrypt_log | 指示是否在以加密表空间启动的表空间上启用重做日志加密。 |
| innodb_encrypt_tables | 是否启用加密表。 |
| innodb_encryption_rotate_key_age | 理想情况下需要轮换表空间密钥的天数。 |
| innodb_encryption_rotation_iops | 从表空间密钥存储区读取密钥以用于表空间加密的数据 IOPS。 |
| innodb_encryption_threads | 在定义了加密表空间的情况下,在执行诸如切换密钥之类的任务时,InnoDB 应该使用的加密线程数。 |
| innodb_fake_changes | 是否将每个更新视为更改,即使存储引擎本身内部没有进行任何更改。 |
| innodb_fast_shutdown | 是否在关闭之前不检查重做日志文件是否被清空,并且只清空缓存池中的缓存页以提高关闭速度。 |
| innodb_fatal_semaphore_wait_threshold | 如果使用 POSIX 信号量并且 Semaphore 队列长度大于该值,那么按常规情况使用 InnoDB 内部时运行线程将使用 sem_timedwait() 而非 sem_wait()。 |
| innodb_file_format | InnoDB 行格式标志。 |
| innodb_file_format_check | 是否要在 MySQL 中启用文件格式检查。 |
| innodb_file_format_max | 最大的 InnoDB 文件格式。 |
| innodb_file_per_table | 是否为 InnoDB 表创建独立的表空间。 |
| innodb_fill_factor | 用于 AVL 树结构的填充因子。 |
| innodb_flush_log_at_timeout | 每个 innodb_lock_wait_timeout 秒强制将所有未同步重做日志写入磁盘。 |
| innodb_flush_log_at_trx_commit | 指示在提交事务时强制将重做日志缓冲区中的所有日志写入磁盘,还是将日志保留在缓冲区中直到缓冲区已填满。 |
| innodb_flush_method | 定义 MySQL 在冲刷日志文件、重做日志和写入 InnoDB 双写缓冲区时使用的 IO 方法类型。 |
| innodb_flush_neighbors | 控制是否将相邻缓冲池页面聚集到同一次缓冲池写入中。 |
| innodb_flush_sync | 每个 fsync() 调用结束时是否完全同步 Innodb 写入。 |
| innodb_flushing_avg_loops | 缓存池刷新时,InnoDB 的估计平均循环数。 |
| innodb_force_load_corrupted | 指示是否必须强制加载已损坏的 InnoDB 页面 |
相关文章:

MySQL 数据库全局变量中文解释
NameValueauto_increment_incrementAUTO_INCREMENT 字段值的自增长步长值。auto_increment_offsetAUTO_INCREMENT 字段值的初始值。autocommit指示新连接的默认提交模式是否启用。automatic_sp_privileges控制是否在存储过程上创建或更改时自动分配特定权限。back_log在开始拒绝…...
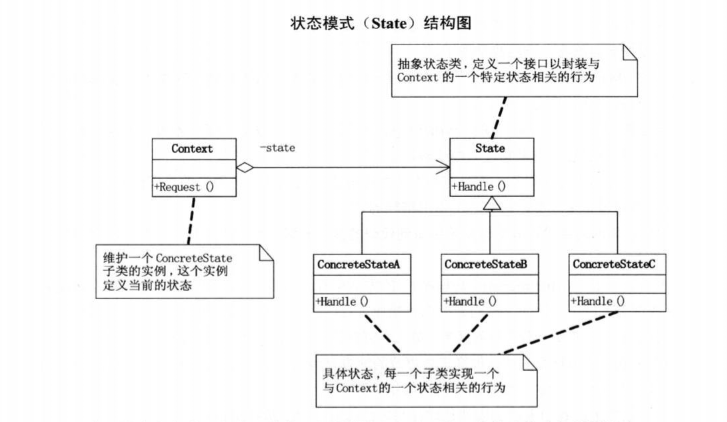
设计模式之~状态模式
状态模式(State),当一个对象的内部状态改变时允许改变其行为,这个对象看起来像是改变了其类。 能够让程序根据不同的外部情况来做出不同的响应,最直接的方法就是在程序中将这些 可能发生的外部情况全部考虑到ÿ…...

【21JavaScript break 和 continue 语句】JavaScript中的break和continue语句:控制循环流程的关键技巧
JavaScript break 和 continue 语句 在JavaScript中,break和continue是两个关键字,用于控制循环结构的执行流程。 break语句 break语句用于中断循环并跳出循环体,使程序执行流程继续到循环之后的下一行代码。 在for循环中使用break for (…...

【SpringBoot】 设置随机数据 用于测试用例
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ 设置随机数据——常用于测试用例 SpringBoot设…...

chatgpt赋能python:Python如何获取微信聊天记录
Python如何获取微信聊天记录 作为世界上最受欢迎的即时通讯工具之一,微信被大量用户使用。然而,微信聊天记录的备份和管理是一个重要的问题,特别是对于那些需要在工作和个人生活中快速查找重要信息的人来说。 幸运的是,Python编…...
 A~D)
VP记录:Codeforces Round 599 (Div. 2) A~D
传送门:CF 前提提要:无 A题:A. Maximum Square 刚开始的第一个想法是排序然后二分答案.但是一看范围才1000,果断直接使用暴力枚举. 考虑枚举最终的答案,然后记录有多少个 a i ai ai大于此值,然后判断能否构成一个正方形即可. #include <bits/stdc.h> using namespace…...

01-项目介绍
1、特色与亮点 千万级流量的大型分布式系统架构设计。 高性能、高并发、高可用场景解决方案。 2、项目安排 架构搭建,使用前后端分离架构。 功能开发,实现基本的选座排队购票功能。 引入高并发技术,实现高性能抢票。 3、项目收获 学习…...

《Python编程从入门到实践》学习笔记06字典
alien_0{color:green,points:5} print(alien_0[color]) print(alien_0[points])green 5 alien_0{color:green,points:5} new_pointsalien_0[points] print(fyou just earned {new_points} points!)you just earned 5 points! #添加键值对 alien_0{color:green,points:5} prin…...
为什么说程序员和产品经理一定要学一学PMP
要回答为什么说程序员和产品经理一定要学一学PMP?我们得先看一下PMP包含的学习内容。PMP新版考纲备考参考资料绝大多数涉及IT项目的敏捷管理理念。主要来源于PMI推荐的10本参考书: 《敏捷实践指南(Agile Practice Guide)》 《项目…...

LearnOpenGL-高级OpenGL-9.几何着色器
本人初学者,文中定有代码、术语等错误,欢迎指正 文章目录 几何着色器使用几何着色器造几个房子爆破物体法向量可视化 几何着色器 简介 在顶点和片段着色器之间有一个可选的几何着色器几何着色器的输入是一个图元(如点或三角形)的一…...

8.视图和用户管理
目录 视图 基本使用 用户管理 用户 用户信息 创建用户 删除用户...

bootstrapvue上传文件并存储到服务器指定路径及从服务器某路径下载文件
前记 第一次接触上传及下载文件,做个总结。 从浏览器上传本地文件 前端 本处直接将input上传放在了button内实现。主要利用了input的type“file” 实现上传框。其中accept可以限制弹出框可选择的文件类型。可限制多种: :accept"[doc, docx]&qu…...

Qt OpenGL(四十二)——Qt OpenGL 核心模式-GLSL(二)
提示:本系列文章的索引目录在下面文章的链接里(点击下面可以跳转查看): Qt OpenGL 核心模式版本文章目录 Qt OpenGL(四十二)——Qt OpenGL 核心模式-GLSL(二) 冯一川注:GLSL其实也是不断迭代的,比如像3.3版本中,基本数据类型浮点型只支持float型,而GLSL4.0版本开始就…...
)
C++基础讲解第八期(智能指针、函数模板、类模板)
C基础讲解第八期 代码中也有对应知识注释,别忘看,一起学习! 一、智能指针二、模板1. 概念2.函数模板1. 函数模板和普通函数 3. 类模板1.类模板的定义2.举个例子3.举例 一、智能指针 举个栗子: 看下面代码, 当我们直接new一个指针时, 忘记dele…...

JMeter 测试 ActiveMq
JMeter 测试 ActiveMq 的资料非常少, 我花了大量的时间才研究出来 关于ActiveMq 的文章请参考我另外的文章。 版本号: ActiveMq 版本号: 5.91 Jmeter 版本号: 1.13 添加ActiveMq 的jar包 将 ActiveMq 下的 "activemq-all-5.9.1.jar" 复制…...
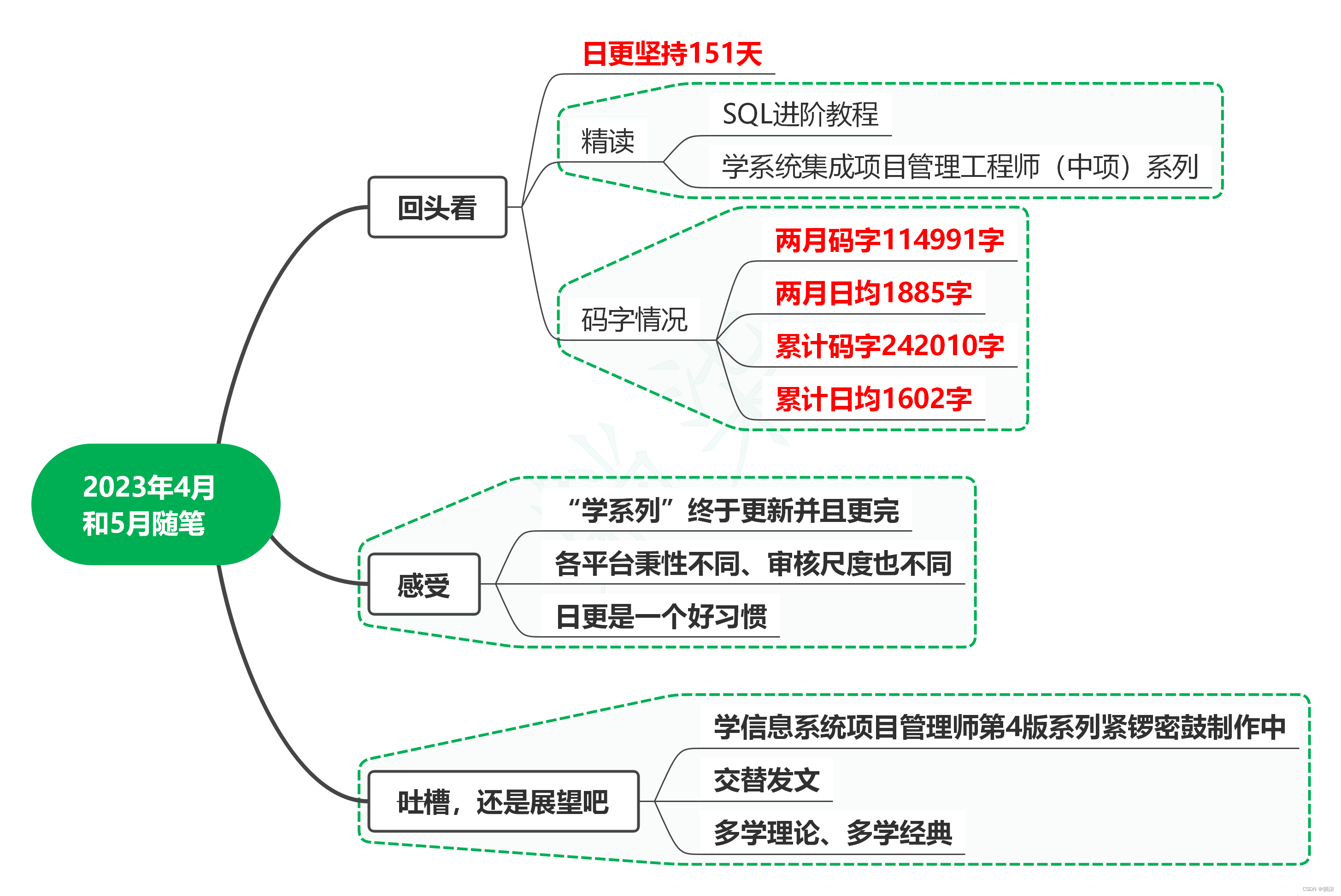
2023年4月和5月随笔
1. 回头看 为了不耽误学系列更新,4月随笔合并到5月。 日更坚持了151天,精读完《SQL进阶教程》,学系统集成项目管理工程师(中项)系列更新完成。 4月和5月两月码字114991字,日均码字数1885字,累…...
新Linux服务器安装Java环境[JDK、Tomcat、MySQL、Nacos、Redis、Nginx]
文章目录 JDK服务Tomcat服务MySQL服务Nacos服务Redis服务Nginx服务 说明:本文不使用宝塔安装 温馨提示宝塔安装命令:yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh JDK服务…...

精简总结:一文说明软件测试基础概念
基础概念-1 基础概念-2 目录 一、什么是软件测试? 二、软件测试的特点 三、软件测试和开发的区别 1、内容: 2、技能区别 3、工作环境 4、薪水 5、发展前景 6、繁忙程度 7、技能要求 四、软件测试与调试的区别 1、角色 2、目的 3、执行的阶…...

通过 Gorilla 入门机器学习
机器学习是一种人工智能领域的技术和方法,旨在让计算机系统能够从数据中学习和改进,而无需显式地进行编程。它涉及构建和训练模型,使其能够自动从数据中提取规律、进行预测或做出决策。 我对于机器学习这方面的了解可以说是一片空白…...

【二叉树】298. 二叉树最长连续序列
文章目录 一、题目1、题目描述2、基础框架3、原题链接 二、解题报告1、思路分析2、时间复杂度3、代码详解 三、本题小知识 一、题目 1、题目描述 给你一棵指定的二叉树的根节点 root ,请你计算其中 最长连续序列路径 的长度。 最长连续序列路径 是依次递增 1 的路…...

OpenRocket全栈实战手册:从仿真引擎到航天教育生态构建
OpenRocket全栈实战手册:从仿真引擎到航天教育生态构建 【免费下载链接】openrocket Model-rocketry aerodynamics and trajectory simulation software 项目地址: https://gitcode.com/GitHub_Trending/op/openrocket 价值定位:重新定义航天工程…...
两个月搞定)
别再到处找模板了!我用这套软著申请材料(含用户手册+源代码模板)两个月搞定
两个月高效拿下软著:零基础开发者的材料准备实战指南 第一次提交软著申请时,我盯着官网模糊的材料要求整整发呆了半小时——"用户手册需图文并茂"到底要多详细?"源代码前30页后30页"该怎么截取?连续三个晚上搜…...

Win10下mitie安装失败:subprocess.CalledProcessError的深度排查与实战修复
1. 问题现象与初步分析 最近在Windows10系统上折腾MITIE这个自然语言处理工具包时,遇到了一个让人头疼的错误。当时按照常规流程,先下载了mitie的源码压缩包,解压后执行python setup.py install,结果命令行突然弹出一堆红色报错&a…...

MIB2 High Toolbox:重新定义车载娱乐系统定制体验
MIB2 High Toolbox:重新定义车载娱乐系统定制体验 【免费下载链接】mib2-toolbox The ultimate MIB2-HIGH toolbox. 项目地址: https://gitcode.com/gh_mirrors/mi/mib2-toolbox 车载娱乐系统是否还停留在出厂设置?想要个性化界面却苦于没有工具&…...

AI持续爆火,相关岗位薪资到底达到了多少,AI大模型岗位薪资真相:多少年包能拿到?普通人如何破局?
“AI相关岗位薪资” 随着AI持续火爆,各大厂也都在招聘相关人才,近日OfferShow专门对AI相关岗位的工资情况进行了一期专题汇总,都是校招岗位年包90W左右年包100W年包80w70W50W左右40W左右54W左右34W左右。 看大家投票可信度还是挺高的…...

保姆级教程:在OrangePi 5 Plus上从SSD启动Ubuntu 22.04,并配置ROS2 Humble环境
OrangePi 5 Plus开发板全栈配置指南:从SSD启动到ROS2 Humble环境搭建 拿到一块OrangePi 5 Plus开发板时,如何快速搭建一个稳定高效的开发环境?本文将手把手带你完成从系统烧录到ROS2环境配置的全过程,特别针对ARM64架构的优化方案…...

OpenClaw 底层原理分析
OpenClaw 底层原理深度分析 OpenClaw 是一个智能体编排平台,它的核心设计哲学是 “模型无关、工具优先、记忆驱动”。让我从架构、数据流、核心机制三个维度为你拆解。 🏗️ 一、整体架构 OpenClaw 采用 分层解耦 架构,可以理解为“AI 操作系统”: text ┌──────…...

超级AI数字员工源码系统,支持贴牌OEM,独立部署交付
温馨提示:文末有资源获取方式最近“龙虾AI”概念很火,到处都在讨论。但说实话,这类技术对普通用户而言存在明显门槛,部署要代码、配置要工程师、日常运行的Token成本也不低——轻度使用每月100-200元,重度甚至单日上千…...

从源码到上架:手把手教你用Android Studio打包绿豆TVBox APK,并修改Logo、启动图和包名
从零打造个性化TV应用:Android Studio深度定制指南 在流媒体内容消费爆发的时代,拥有一个专属的影视聚合平台成为许多技术爱好者的追求。绿豆TVBox这类开源项目为开发者提供了快速入门的跳板,但真正实现个性化部署需要跨越从源码编译到定制化…...

5分钟制作Windows启动盘:Rufus免费工具终极指南
5分钟制作Windows启动盘:Rufus免费工具终极指南 【免费下载链接】rufus The Reliable USB Formatting Utility 项目地址: https://gitcode.com/GitHub_Trending/ru/rufus 还在为系统重装而烦恼吗?Rufus作为一款完全免费的USB格式化工具࿰…...