序列化与反序列化深入理解
序列化与反序列化深入理解
- 1 介绍
- 1.1 概述
- 1.2 序列化实现的需求
- 2 常用序列化实现
- 函数序列化
- 语言内置
- 开源序列化实现
- 3 各序列化实现比较
- 4 各序列化实现概述
- XML
- JSON
- Protobuf
- Java 内置
- TLV
- VLE(Variable Length Encoding)
- 5 flex & bison
- 5.1 介绍
- 应用
- 解释器
- IDL
- 介绍
- IDL编译器
- 参考
1 介绍
1.1 概述
- 数据传输中,双方交互都需要对数据进行序列化和反序列化。也称为编码和解码。
- 网络传输中,传输数据的基本形式就是二进制流,也就是一段一段的1和0。数据读取形式是字节,也就是Byte。具体粘包拆包后,是按字符串、结构体、JSON还是protobuf等形势序列化,看程序设计。
- 结构化的数据与字节流之间的双向转换,将结构化数据转换成字节流的过程,称为序列化,反过来转换,就是反序列化。序列化的用途除了用于在网络上传输数据以外,另外一个重要用途是,将结构化数据保存在文件中。
- 序列化无处不在:
-
- CPU:数据被序列化成 little endian / big endian
-
- GPU:vertex buffer
-
- 内存:字节流
-
- 磁盘/网络:JSON,YAML,MessagePack,protobuf,FlatBuffer,,以及所有的网络协议

- 磁盘/网络:JSON,YAML,MessagePack,protobuf,FlatBuffer,,以及所有的网络协议
1.2 序列化实现的需求
- 可读性:序列化后的数据最好是易于人类阅读的;
- 复杂度:实现的复杂度是否足够低;
- 性能水平:性能包括两个方面,时间复杂度和空间复杂度。序列化和反序列化的速度越快越好;空间开销(Verbosity)和时间开销(Complexity)都越小越好。
- 信息密度:序列化后的信息密度越大越好,也就是说,同样的一个结构化数据,序列化之后占用的存储空间越小越好;
- 通用性:技术层面,序列化协议是否支持跨平台、跨语言;流行程度,是否被大量使用;
- 健壮性:是否稳定。
2 常用序列化实现
函数序列化
函数之间通过栈来交流:调用者把参数序列化到栈上,被调者将其反序列化出来。

语言内置
Java 和 Go 语言都内置了序列化实现。
Java 语言中提供的 Serializable 接口,此外还有 Android 提供的 Parcelable 接口。
开源序列化实现
Google 的 Protobuf、Kryo、Hessian 等;
此外,像 JSON、XML 这些标准的数据格式,也可以作为一种序列化实现来使用。
3 各序列化实现比较
| 序列化实现 | 优点 | 缺点 | 备注 |
|---|---|---|---|
| JSON | 可读性很好,使用简单 | 信息密度很低 | 文本 |
| XML | 可读性很好,使用简单 | 信息密度也很低 | 文本,XML 所产生序列化之后文件比JSON大 |
| SOAP | 可读性很好,使用简单 | 信息密度也很低 | 文本 |
| Kryo | 适用范围广,使用简单 | 信息密度稍高 | 二进制序列化 |
| Hessian | 适用范围广,使用简单 | 信息密度稍高 | 二进制序列化 |
| protobuf | 信息密度高 | 使用更复杂 | 二进制序列化,可伸缩性的数据类型 |
| java | 信息密度高 | 语言内置 | 二进制序列化,数据类型固定长度 |
| TLV(Type-Length-Value) | 信息密度较高,容易解析 | 自定义,通用差 | 二进制序列化 |
4 各序列化实现概述
XML
XML 是一种常用的序列化和反序列化协议,具有跨机器,跨语言等优点。
JSON
JSON 起源于弱类型语言 Javascript, 它的产生来自于一种称之为"Associative array"的概念,其本质是就是采用"Attribute-value"的方式来描述对象。实际上在 Javascript 和 PHP 等弱类型语言中,类的描述方式就是 Associative array。
这是因为 JSON 是上下文极其相关的,在上一个 token 解析完成之前,你无法解析下一个 token,所以效率慢。
Protobuf
- 序列化数据非常简洁,紧凑,与 XML 相比,其序列化之后的数据量约为 1/3 到 1/10。
- 解析速度非常快,比对应的 XML 快约 20-100 倍。
- 提供了非常友好的动态库,使用非常简介,反序列化只需要一行代码。
- Protobuf 是非常高效的序列化协议。
- Protobuf 提供了可伸缩性的数据类型(int 1-5字节)。
Java 内置
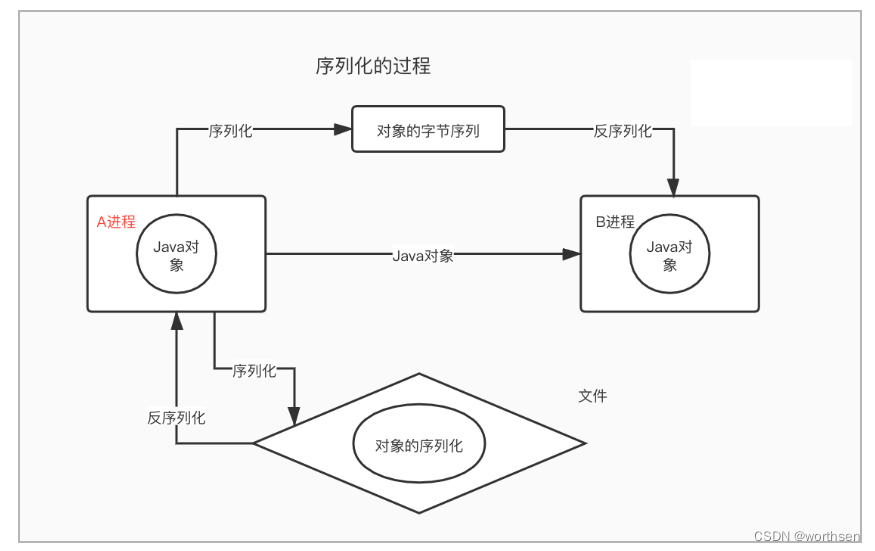
Java是数据类型固定长度的序列化(int 4字节, long 8字节)。
TLV
TLV: TLV是指由数据的类型Tag,数据的长度Length,数据的值Value组成的结构体,几乎可以描任意数据类型,TLV的Value也可以是一个TLV结构,正因为这种嵌套的特性,可以让我们用来包装协议的实现。

VLE(Variable Length Encoding)
Variable Length Encoding(VLE):Type 的长度和 Length 的长度都是可变的,且最常用的我们用最小的比特位为其序列化。比如 protobuf 就采用了 VLE 的方式。
message Person {string user_name = 1;int64 favorite_number = 2;string interests = 3;
}
因为 protobuf 定义的字段是可选的,所以这里光靠 TLV 还不够,还需要每个字段的 tag,这就是为什么 protobuf 需要为每个字段提供序号,并且序号不可重复:

5 flex & bison
5.1 介绍
Flex and bison就是lex and yacc的升级版。Lex 代表 Lexical Analyzar。Yacc 代表 Yet Another Compiler Compiler。
Flex和bison是两个用来生成程序的工具,它们生成的程序分别叫做词法分析器和语法分析器。

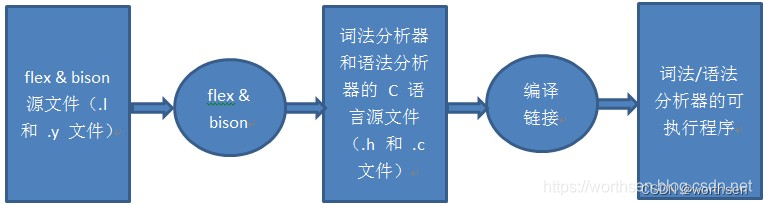
Flex生成的词法分析器将输入拆分成一个个记号(token),bison生成的语法分析器根据已有的规则,分析这些token的组合,是否符合语法规范。

应用
解释器
各行业使用的解释器,如有的协作机械臂图形编程中解释器
IDL
介绍
IDL的全称是Interface Definition Language,即接口定义语言(有时也叫作接口描述语言)。因为RPC通常是跨进程、跨机器、跨系统和跨语言的,IDL是用来解决这个问题的,它与语言无关,借助编译器将它翻译成不同的编程语言。
Google开源的ProtoBuf中的“.proto”文件就是一种IDL文件。
IDL编译器
IDL中定义接口、函数和数据等,需要在发送前编码成字节流,在收到后进行解码。比如将函数名、参数类型和参数值等编码成字节流,然后发送给对端,然后对端进行解码,还原成函数调用。ProtoBuf就是一个非常好的编解码工具。
- protobuf 中底层有用flex & bison
- opensplice DDS中底层有用flex & bison
- RTI DDS中底层有用flex & bison
- Fast DDS中底层有用flex & bison
参考
1、linux–Flex and Bison
2、12 序列化与反序列化:如何通过网络传输结构化的数据?
3、网络传输 | 序列化与反序列化
4、序列化与反序列化:通过网络传输结构化的数据
5、数据传输过程的序列化,你了解吗
6、Protocol Buffer序列化对比Java序列化
7、佛曰:大道至简,序列化之
8、JSON概述
9、网络通信–协议设计
10、数据交换协议–JSON、XML、YAML、TOML、TLV
11、转–全图文分析:如何利用Google的protobuf,来思考、设计、实现自己的RPC框架
12、机器人开发–DDS数据分发服务
13、linux–解释器
14、GOOD–【RPC】RPC的实现—未研读
相关文章:
序列化与反序列化深入理解
序列化与反序列化深入理解 1 介绍1.1 概述1.2 序列化实现的需求 2 常用序列化实现函数序列化语言内置开源序列化实现 3 各序列化实现比较4 各序列化实现概述XMLJSONProtobufJava 内置TLVVLE(Variable Length Encoding) 5 flex & bison5.1 介绍应用解…...

hudi系列-小文件优化
hudi使用mvcc来实现数据的读写一致性和并发控制,基于timeline实现对事务和表服务的管理,会产生大量比较小的数据文件和元数据文件。大量小文件会对存储和查询性能产生不利影响,包括增加文件系统的开销、文件管理的复杂性以及查询性能的下降。对于namenode而言,当整个集群中…...

mysql 是否包含 返回索引 截取字符串
是否包含返回索引 原文链接:https://www.cnblogs.com/shoshana-kong/p/16474175.html 方法1:使用通配符%。 通配符也就是模糊匹配,可以分为前导模糊查询、后导模糊查询和全导匹配查询,适用于查询某个字符串中是否包含另一个模糊…...

【LeetCode】74. 搜索二维矩阵
74. 搜索二维矩阵(中等) 方法一:二分查找 思路 总体思路 由于二维矩阵固定列的「从上到下」或者固定行的「从左到右」都是升序的 因此我们可以使用两次二分来定位到目标位置。 第一次二分: 从第 0 列中的「所有行」开始找&#x…...
Nginx rewrite
一.location 大致可以分为三类: 精准匹配:location / {…}一般匹配:location / {…}正则匹配:location ~ / {…} 1.location 常用的匹配规则: :进行普通字符精确匹配,也就是完全匹配。^~ &am…...
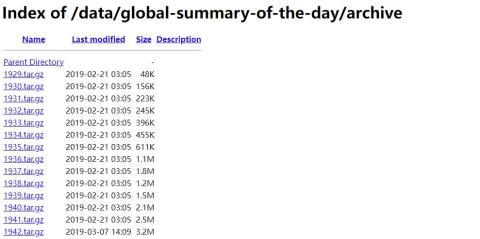
【数据分享】1929-2022年全球站点的逐日降水量(Shp\Excel\12000个站点)
气象数据是在各项研究中都经常使用的数据,气象指标包括气温、风速、降水、湿度等指标,说到常用的降水数据,最详细的降水数据是具体到气象监测站点的降水数据! 有关气象指标的监测站点数据,之前我们分享过1929-2022年全…...
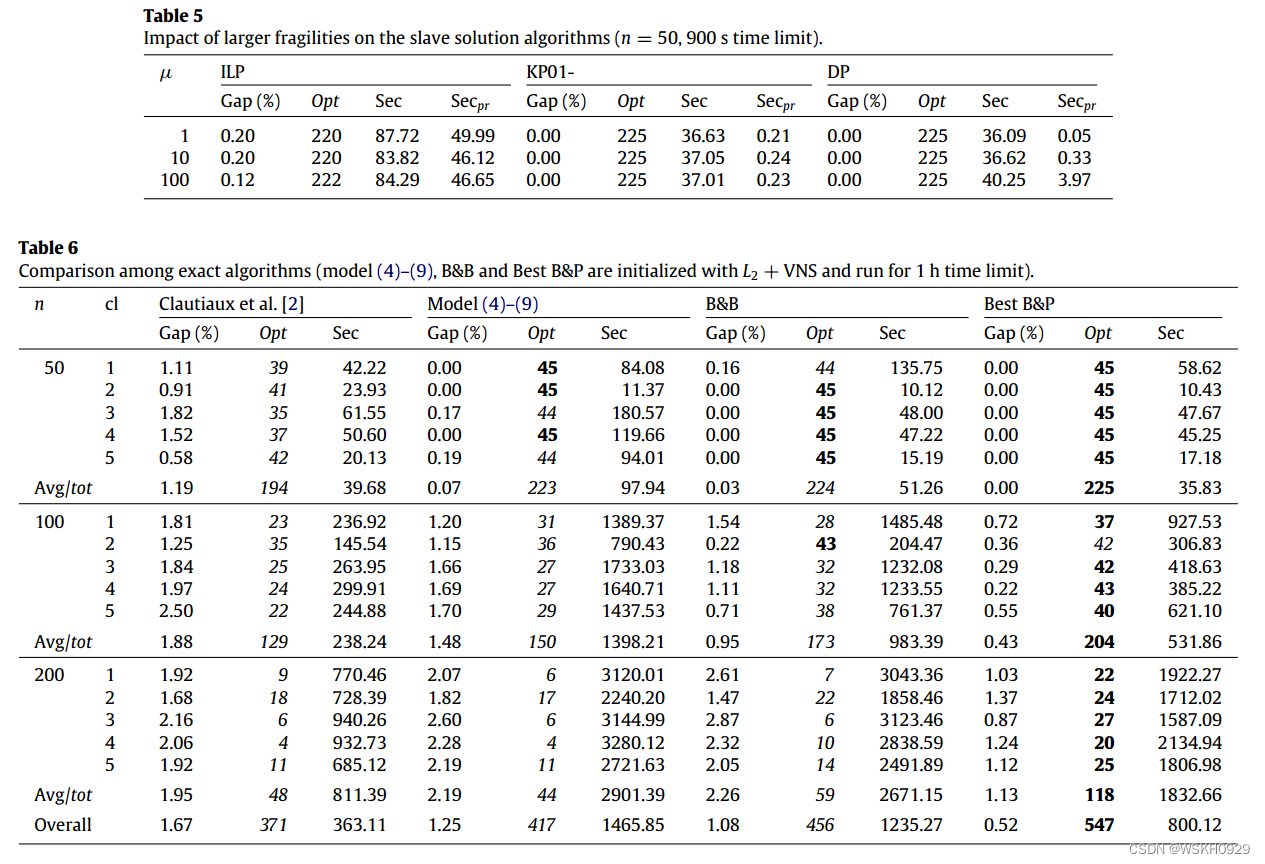
【论文阅读】(2013)Exact algorithms for the bin packing problem with fragile objects
文章目录 一、摘要二、介绍三、之前在这个问题上的工作四、易碎物品背包问题的求解4.1 ILP模型4.2 基于KP01的方法4.3 动态规划 五、二元分支方案5.1 分支方案1(基于决策变量的分支)5.2 分支方案2(基于yj和xji的分支)5.3 将L2嵌入…...

K8S YAML 部署XXLJOB 集群
apiVersion: apps/v1 kind: Deployment metadata: labels: app: xxl-job-admin name: xxl-job-admin namespace: ccetest #根据情况修改namespace spec: replicas: 3 #根据情况修改副本数 selector: matchLabels: app: xxl-job-admin strat…...
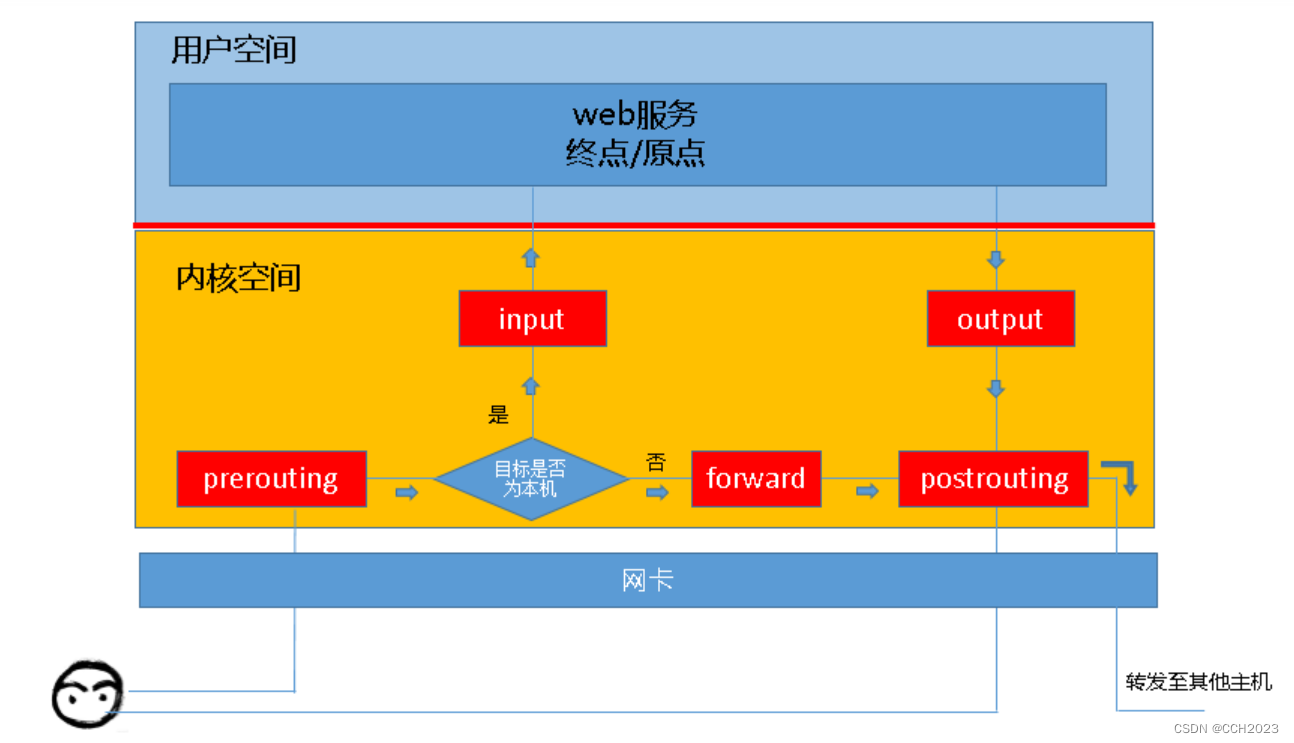
Linux防火墙学习笔记3
iptables链的概念: 当客户端访问服务器端的Web服务的时候,客户端发送请求报文到网卡,而TCP/IP协议栈是属于内核的一部分。客户端的请求报文会通过内核的TCP协议传输到用户空间的Web服务,而客户端报文的目的地址为Web服务器所监听的…...

数仓用户行为数据分析
分层优点:复杂的东西可以简单化、解耦(屏蔽层作用)、提高复用、方便管理 SA 贴源 数据组织结构与源系统保持一致 shm 历史层 针对不同特征的数据做不同算法,目的都是为了得到一份完整的数据 PDM 明细层 做最细粒度的数据明细…...

RK3288 Android5.1添加WiFiBT模块AP6212
CPU:RK3288 系统:Android 5.1 注:RK3288系统,目前 Android 5.0 Kernel 3.10 SDK 支持 Braodcom,Realtek 等 WiFi BT 模块 各个 WiFi BT 模块已经做到动态兼容,Android 上层不再需要像以前一样进 行特定宏的配置 此…...

使用 YApi 管理 API 文档,测试, mock
随着互联网的发展,API变的至关重要。根据统计,目前市面上有上千万的开发者,互联网项目超过10亿,保守统计涉及的 API 数量大约有 100 亿。这么大基数的API,只要解决某些共有的痛点,将会是非常有意义的事情。…...

chatgpt生成【2023高考作文】北京卷二 - 亮相
舞台上,戏曲演员有登场亮相的瞬间。生活中也有许多亮相时刻:国旗下的讲话,研学成果的汇报,新产品的发布……每一次亮相,都受到众人关注;每一次亮相,也会有一段故事。 请以“亮相”为题目&#x…...
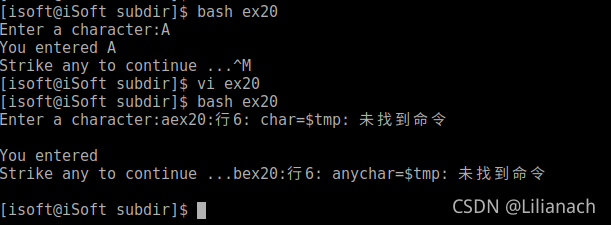
实验四、shell编程
一、实验目的 1.了解shell的特点和主要种类。 2.掌握 shel1 脚本的建立和执行方式。 3.掌握bash的基本语法。 4.学会编写shell 脚本。 二、实验内容 shell 脚本的建立和执行。历史命令和别名定义。shell变量和位置参数、环境变量。bash的特殊字符。一般控制结构。算术运算及…...

【代码随想录】刷题Day51
1.最佳买卖股票时机含冷冻期 309. 最佳买卖股票时机含冷冻期 1.dp数组的含义:dp[i][0]为第i天卖出股票的最大价值;dp[i][1]为第i天持有股票的最大价值 2.dp数组的条件:由于有冷冻期,所以dp数组的条件就变了。第i天卖出股票的最大…...
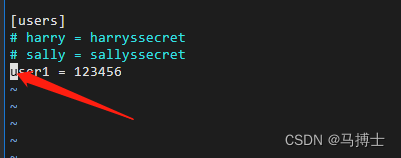
centos7下svnserve方式部署subversion/SVN服务端(实操)
一般来说,subversion服务器可以用两种方式架设: 一种是基于svnserve,svnserve作为服务端; 一种是基于Apache,用apache作为服务端。 这里采用第一种方式部署。 执行如下命令,安装SVN。 yum install sub…...
一款红队批量脆弱点搜集工具
功能 指纹识别:调用“三米前有香蕉皮“前辈工具,他的工具比finger好用 寻找资产中404,403,以及网页中存在的其他薄弱点,以及需要特定路径访问的资产 后续会把nuclei加进来 目前只有windows可以用 使用 第一次使用脚本请运行p…...
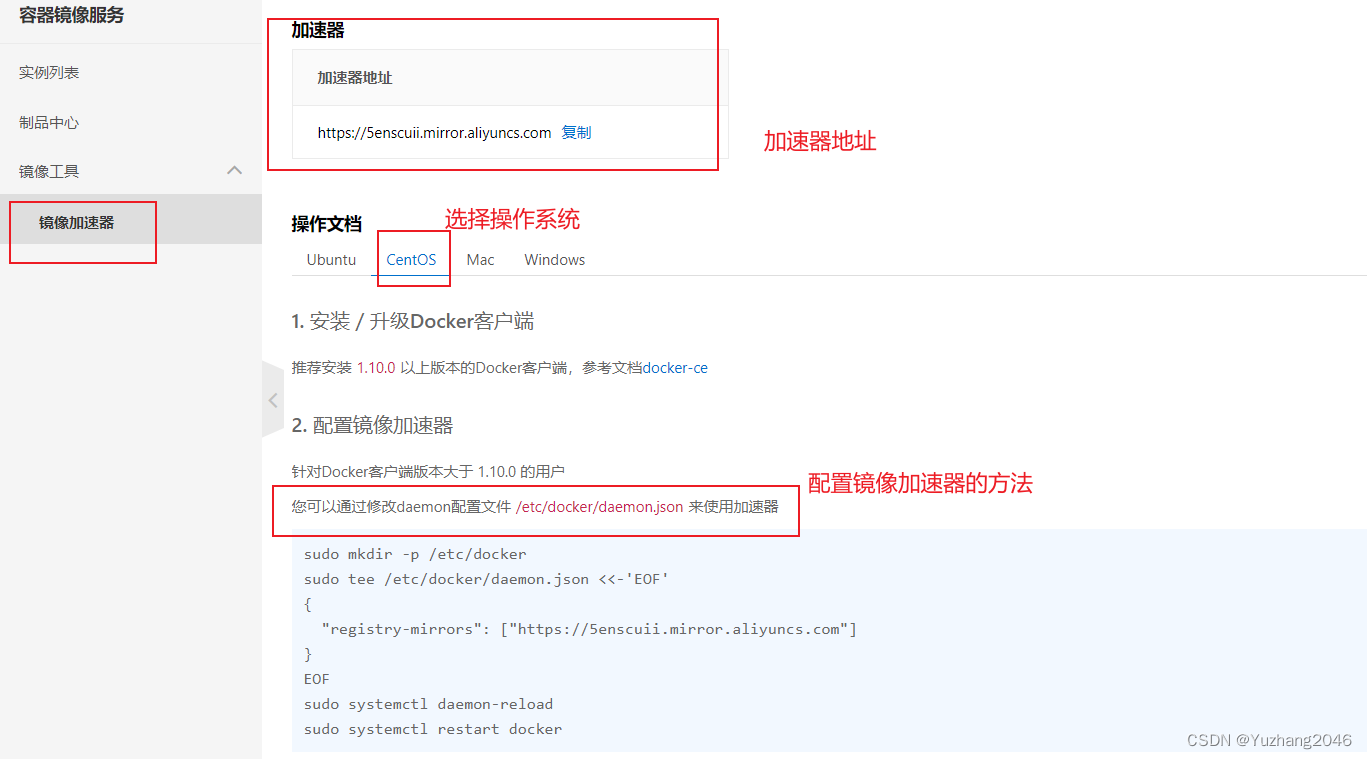
Docker 基本管理
一、Docker 概述 Docker是一个开源的应用容器引擎,基于go语言开发并遵守了apache2.0协议开源。 Docker是在Linux容器里运行应用的开源工具,是一种轻量级的“虚拟机”。 Docker的容器技术可以在一台主机上轻松为任何应用创建一个轻量级的、可移植的、自…...

Debezium系列之:把多张表的数据分发到同一个Kafka Topic,同一张表的数据始终进入Topic相同分区
Debezium系列之:把多张表的数据分发到同一个Kafka Topic,同一张表的数据始终进入Topic相同分区 一、需求背景二、实现思路三、核心参数和参数详解四、创建相关表五、提交Debezium Connector六、插入数据七、消费Kafka Topic八、总结和延展一、需求背景 debezium采集数据库的多…...

雪崩 - 如何重试 - sla和重试风暴的双保证
父文章 异常导致级联雪崩的例子 - 不应该有立即重试._个人渣记录仅为自己搜索用的博客-CSDN博客 一个系统处于稳态临界点 如果立即重试3次, 会导致流量瞬间增大, 哪怕后来系统10s内自愈了, 这个时候, 流量本质上增加了3倍. 如果rpc框架不是fastFail ( 超过 调用方失败timeout上…...

AI 文档工作流里,那道正在被悄然割裂的“思想透明度”
在 AI 辅助的知识库构建、产品规格编写或 Agent 提示工程里,一份长文档从草稿到最终交付的过程,正面临一场隐形断裂。创作者先在纯文本里苦苦打磨思路,AI 却直接吐出一份排版精美、图文并茂的 HTML——看起来分享效率拉满,实际却把…...

光刻热点修复技术:提升芯片良率的关键方法
1. 光刻热点修复技术概述在45nm及更先进工艺节点下,光刻热点(Litho hotspot)已成为制约集成电路良率提升的关键因素之一。这类问题区域在传统设计规则检查(DRC)中往往难以被完全捕捉,因为它们本质上是由复杂…...

AprilTag灵活布局实战:创建自定义标签家族的完整指南
AprilTag灵活布局实战:创建自定义标签家族的完整指南 【免费下载链接】apriltag AprilTag is a visual fiducial system popular for robotics research. 项目地址: https://gitcode.com/gh_mirrors/ap/apriltag AprilTag是一个在机器人研究领域广受欢迎的视…...

如何为Lightnovel-crawler添加新源:ChatGPT辅助开发实战
如何为Lightnovel-crawler添加新源:ChatGPT辅助开发实战 【免费下载链接】lightnovel-crawler Generate and download e-books from online sources. 项目地址: https://gitcode.com/gh_mirrors/li/lightnovel-crawler Lightnovel-crawler是一款强大的轻小说…...

如何让Windows 11界面更顺手:ExplorerPatcher完整配置指南
如何让Windows 11界面更顺手:ExplorerPatcher完整配置指南 【免费下载链接】ExplorerPatcher This project aims to enhance the working environment on Windows 项目地址: https://gitcode.com/GitHub_Trending/ex/ExplorerPatcher 还在为Windows 11的新界…...
)
当点云遇上核技巧:一文搞懂K-PCA为何能处理非线性数据(附Sklearn对比实验)
当点云遇上核技巧:一文搞懂K-PCA为何能处理非线性数据(附Sklearn对比实验) 想象你手中握着一团缠绕的毛线——在三维空间里它呈现出复杂的螺旋结构。如果强行用平面镜去照射这个物体,得到的投影永远是一团混乱的线条。这正是线性P…...

从HIDL到HAL3:手把手拆解Android相机Provider进程的通信与数据流转
Android相机架构深度解析:从HIDL到HAL3的数据流转与性能优化 在移动影像技术快速迭代的今天,Android相机系统的架构设计直接影响着成像质量与用户体验。作为连接应用层与硬件层的核心枢纽,Camera Provider进程通过HIDL接口与Camera Service通…...

淘宝淘金币自动化脚本终极指南:每天节省20分钟的完整解决方案
淘宝淘金币自动化脚本终极指南:每天节省20分钟的完整解决方案 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi …...

华为OD新系统机试真题 2026.5.10 - 美观的灯笼
美观的灯笼(Py/Java/C/C/Js/Go)题解 华为OD新系统机试真题 华为OD新系统上机考试真题 5月10号 100分题型 华为OD新系统机试真题目录点击查看: 华为OD新系统机试真题题库目录|机考题库 算法考点详解 题目描述 春节将至,工人要在古镇老街挂灯笼。街上有…...

Go Web框架ratine:轻量高性能设计、核心功能与生产实践指南
1. 项目概述:一个轻量级、高性能的Web框架 最近在折腾一个内部工具的后端,需要快速搭建一个API服务,性能要求不低,但又不希望引入Spring Boot那种“全家桶”式的重量级框架。在社区里翻找时, goweft/ratine 这个项目…...