在 Transformers 中使用约束波束搜索引导文本生成
引言
本文假设读者已经熟悉文本生成领域波束搜索相关的背景知识,具体可参见博文 如何生成文本: 通过 Transformers 用不同的解码方法生成文本。
与普通的波束搜索不同,约束 波束搜索允许我们控制所生成的文本。这很有用,因为有时我们确切地知道输出中需要包含什么。例如,在机器翻译任务中,我们可能通过查字典已经知道哪些词必须包含在最终的译文中; 而在某些特定的场合中,虽然某几个词对于语言模型而言差不多,但对最终用户而言可能却相差很大。这两种情况都可以通过允许用户告诉模型最终输出中必须包含哪些词来解决。
这事儿为什么这么难
然而,这个事情操作起来并不容易,它要求我们在生成过程中的 某个时刻 在输出文本的 某个位置 强制生成某些特定子序列。
假设我们要生成一个句子 S,它必须按照先 再 的顺序包含短语 。以下定义了我们希望生成的句子 :
期望
问题是波束搜索是逐词输出文本的。我们可以大致将波束搜索视为函数 ,它根据当前生成的序列 预测下一时刻 的输出。但是这个函数在任意时刻 怎么知道,未来的某个时刻 必须生成某个指定词?或者当它在时刻 时,它如何确定当前那个指定词的最佳位置,而不是未来的某一时刻 ?
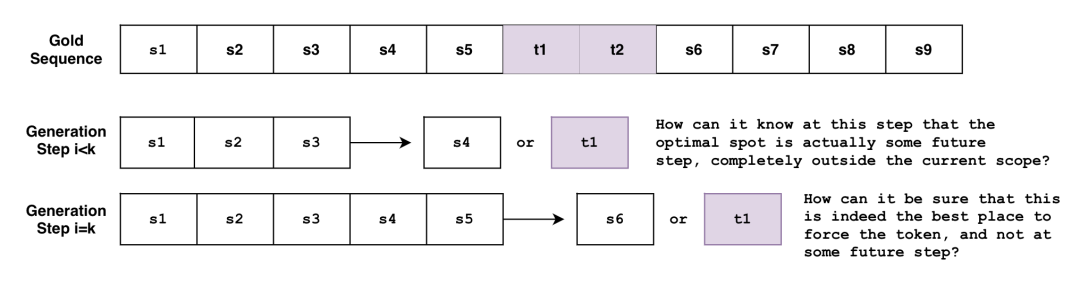
如果你同时有多个不同的约束怎么办?如果你想同时指定使用短语 和 短语 怎么办?如果你希望模型在两个短语之间 任选一个 怎么办?如果你想同时指定使用短语 以及短语列表 中的任一短语怎么办?
上述需求在实际场景中是很合理的需求,下文介绍的新的约束波束搜索功能可以满足所有这些需求!
我们会先简要介绍一下新的 约束波束搜索 可以做些什么,然后再深入介绍其原理。
例 1: 指定包含某词
假设我们要将 "How old are you?" 翻译成德语。它对应两种德语表达,其中 "Wie alt bist du?" 是非正式场合的表达,而 "Wie alt sind Sie?" 是正式场合的表达。
不同的场合,我们可能倾向于不同的表达,但我们如何告诉模型呢?
使用传统波束搜索
我们先看下如何使用 传统波束搜索 来完成翻译。
!pip install -q git+https://github.com/huggingface/transformers.gitfrom transformers import AutoTokenizer, AutoModelForSeq2SeqLMtokenizer = AutoTokenizer.from_pretrained("t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")encoder_input_str = "translate English to German: How old are you?"input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_idsoutputs = model.generate(input_ids,num_beams=10,num_return_sequences=1,no_repeat_ngram_size=1,remove_invalid_values=True,
)print("Output:\n" + 100 *'-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
Wie alt bist du?使用约束波束搜索
但是如果我们想要一个正式的表达而不是非正式的表达呢?如果我们已经先验地知道输出中必须包含什么,我们该如何 将其 注入到输出中呢?
我们可以通过 model.generate() 的 force_words_ids 参数来实现这一功能,代码如下:
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")encoder_input_str = "translate English to German: How old are you?"force_words = ["Sie"]input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_ids
force_words_ids = tokenizer(force_words, add_special_tokens=False).input_idsoutputs = model.generate(input_ids,force_words_ids=force_words_ids,num_beams=5,num_return_sequences=1,no_repeat_ngram_size=1,remove_invalid_values=True,
)print("Output:\n" + 100 *'-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
Wie alt sind Sie?如你所见,现在我们能用我们对输出的先验知识来指导文本的生成。以前我们必须先生成一堆候选输出,然后手动从中挑选出符合我们要求的输出。现在我们可以直接在生成阶段做到这一点。
例 2: 析取式约束
在上面的例子中,我们知道需要在最终输出中包含哪些单词。这方面的一个例子可能是在神经机器翻译过程中结合使用字典。
但是,如果我们不知道要使用哪种 _词形_呢,我们可能希望使用单词 rain 但对其不同的词性没有偏好,即 ["raining", "rained", "rains", ...] 是等概的。更一般地,很多情况下,我们可能并不刻板地希望 逐字母一致 ,此时我们希望划定一个范围由模型去从中选择最合适的。
支持这种行为的约束叫 析取式约束 (Disjunctive Constraints) ,其允许用户输入一个单词列表来引导文本生成,最终输出中仅须包含该列表中的 至少一个 词即可。
下面是一个混合使用上述两类约束的例子:
from transformers import GPT2LMHeadModel, GPT2Tokenizermodel = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")force_word = "scared"
force_flexible = ["scream", "screams", "screaming", "screamed"]force_words_ids = [tokenizer([force_word], add_prefix_space=True, add_special_tokens=False).input_ids,tokenizer(force_flexible, add_prefix_space=True, add_special_tokens=False).input_ids,
]starting_text = ["The soldiers", "The child"]input_ids = tokenizer(starting_text, return_tensors="pt").input_idsoutputs = model.generate(input_ids,force_words_ids=force_words_ids,num_beams=10,num_return_sequences=1,no_repeat_ngram_size=1,remove_invalid_values=True,
)print("Output:\n" + 100 *'-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
print(tokenizer.decode(outputs[1], skip_special_tokens=True))Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.Output:
----------------------------------------------------------------------------------------------------
The soldiers, who were all scared and screaming at each other as they tried to get out of the
The child was taken to a local hospital where she screamed and scared for her life, police said.如你所见,第一个输出里有 "screaming" ,第二个输出里有 "screamed" ,同时它们都原原本本地包含了 "scared" 。注意,其实 ["screaming", "screamed", ...] 列表中不必一定是同一单词的不同词形,它可以是任何单词。使用这种方式,可以满足我们只需要从候选单词列表中选择一个单词的应用场景。
传统波束搜索
以下是传统 波束搜索 的一个例子,摘自之前的 博文:
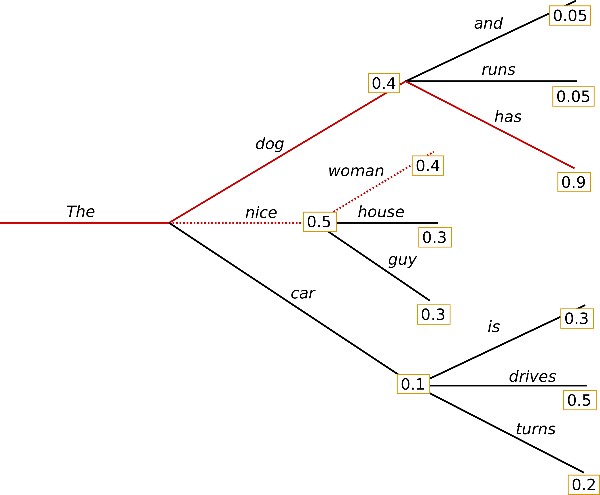
与贪心搜索不同,波束搜索会保留更多的候选词。上图中,我们每一步都展示了 3 个最可能的预测词。
在 num_beams=3 时,我们可以将第 1 步波束搜索表示成下图:
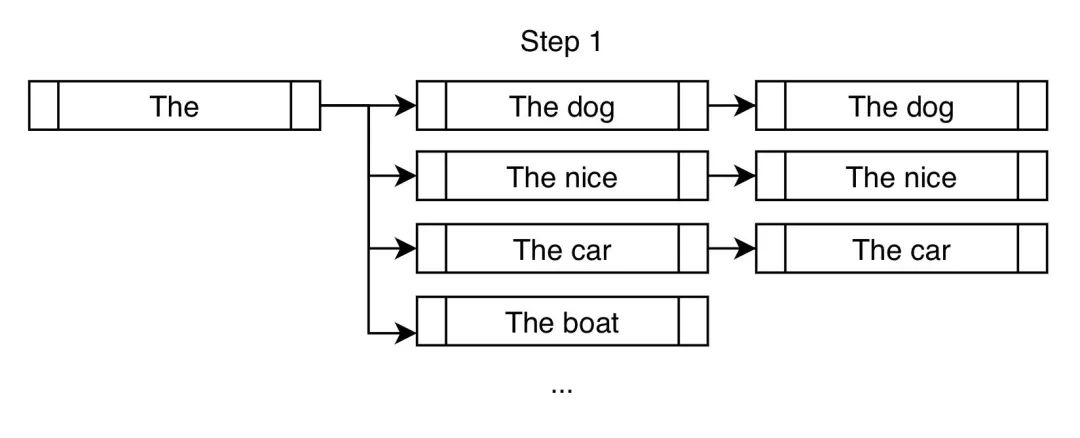
波束搜索不像贪心搜索那样只选择 "The dog" ,而是允许将 "The nice" 和 "The car" 留待进一步考虑 。
下一步,我们会为上一步创建的三个分支分别预测可能的下一个词。
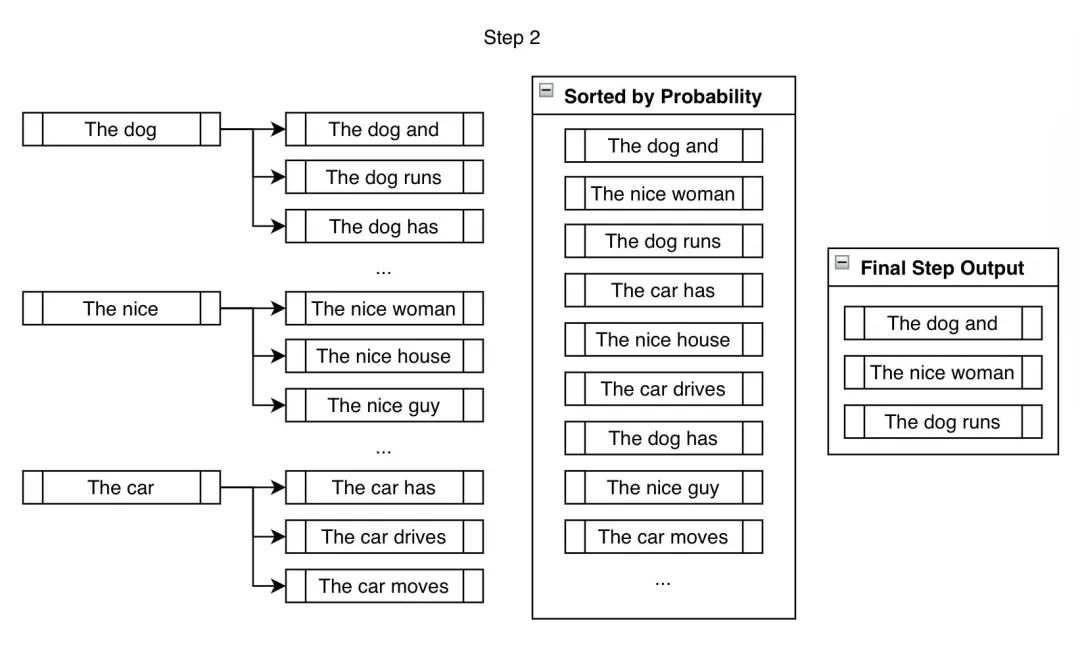
虽然我们 考查 了明显多于 num_beams 个候选词,但在每步结束时,我们只会输出 num_beams 个最终候选词。我们不能一直分叉,那样的话, beams 的数目将在 步后变成 个,最终变成指数级的增长 (当波束数为 时,在 步之后就会变成 个分支!)。
接着,我们重复上述步骤,直到满足中止条件,如生成 <eos> 标记或达到 max_length 。整个过程可以总结为: 分叉、排序、剪枝,如此往复。
约束波束搜索
约束波束搜索试图通过在每一步生成过程中 _注入_所需词来满足约束。
假设我们试图指定输出中须包含短语 "is fast" 。
在传统波束搜索中,我们在每个分支中找到 k 个概率最高的候选词,以供下一步使用。在约束波束搜索中,除了执行与传统波束搜索相同的操作外,我们还会试着把约束词加进去,以 _看看我们是否能尽量满足约束_。图示如下:

上图中,我们最终候选词除了包括像 "dog" 和 "nice" 这样的高概率词之外,我们还把 "is" 塞了进去,以尽量满足生成的句子中须含 "is fast" 的约束。
第二步,每个分支的候选词选择与传统的波束搜索大部分类似。唯一的不同是,与上面第一步一样,约束波束搜索会在每个新分叉上继续强加约束,把满足约束的候选词强加进来,如下图所示:
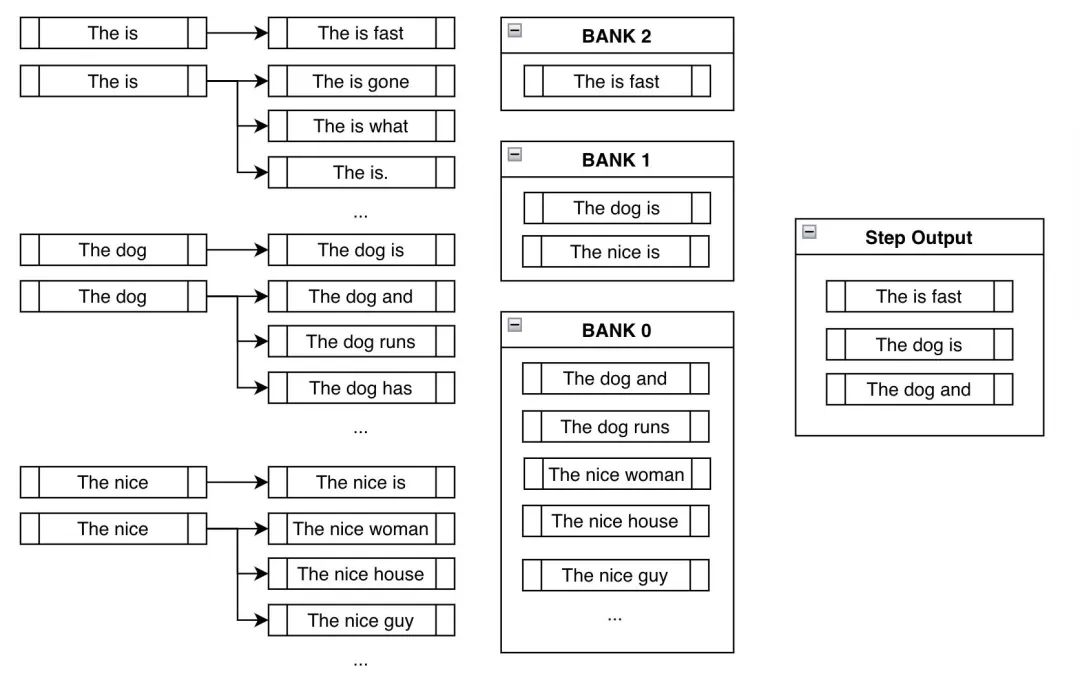
组 (Banks)
在讨论下一步之前,我们停下来思考一下上述方法的缺陷。
在输出中野蛮地强制插入约束短语 is fast 的问题在于,大多数情况下,你最终会得到像上面的 The is fast 这样的无意义输出。我们需要解决这个问题。你可以从 huggingface/transformers 代码库中的这个 问题 中了解更多有关这个问题及其复杂性的深入讨论。
组方法通过在满足约束和产生合理输出两者之间取得平衡来解决这个问题。
我们把所有候选波束按照其 满足了多少步约束分到不同的组中,其中组 里包含的是 满足了 步约束的波束列表 。然后我们按照顺序轮流选择各组的候选波束。在上图中,我们先从组 2 (Bank 2) 中选择概率最大的输出,然后从组 1 (Bank 1) 中选择概率最大的输出,最后从组 0 (Bank 0) 中选择最大的输出; 接着我们从组 2 (Bank 2) 中选择概率次大的输出,从组 1 (Bank 1) 中选择概率次大的输出,依此类推。因为我们使用的是 num_beams=3,所以我们只需执行上述过程三次,就可以得到 ["The is fast", "The dog is", "The dog and"]。
这样,即使我们 强制 模型考虑我们手动添加的约束词分支,我们依然会跟踪其他可能更有意义的高概率序列。尽管 The is fast 完全满足约束,但这并不是一个有意义的短语。幸运的是,我们有 "The dog is" 和 "The dog and" 可以在未来的步骤中使用,希望在将来这会产生更有意义的输出。
图示如下 (以上例的第 3 步为例):
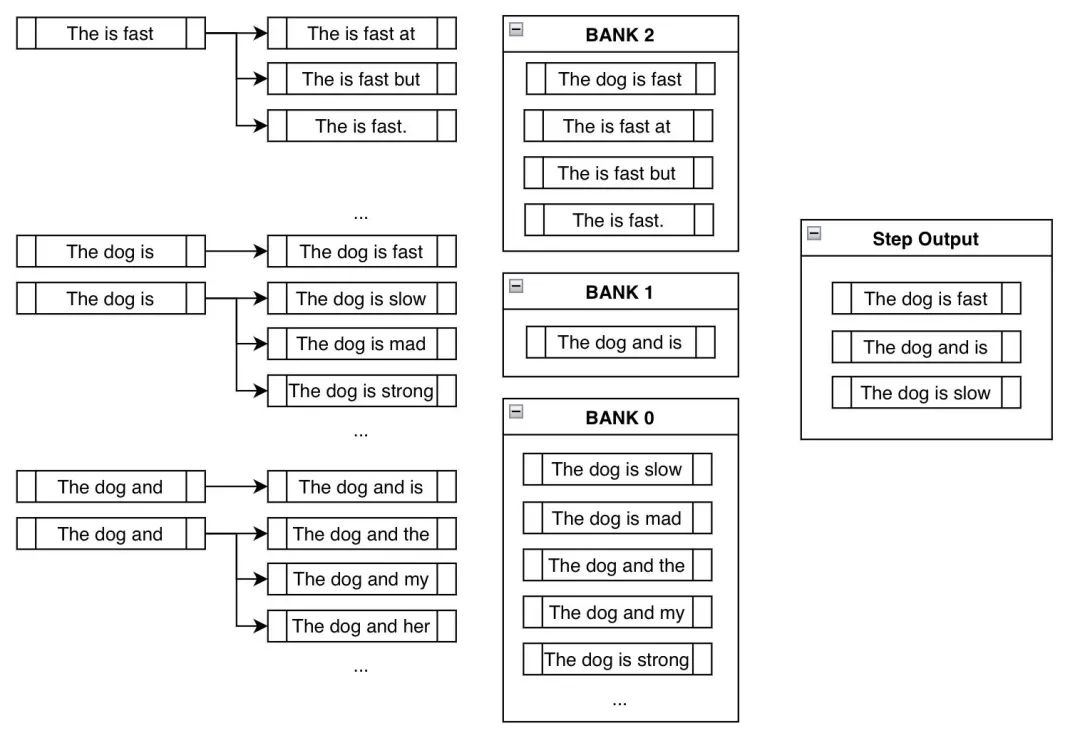
请注意,上图中不需要强制添加 "The is fast",因为它已经被包含在概率排序中了。另外,请注意像 "The dog is slow" 或 "The dog is mad" 这样的波束实际上是属于组 0 (Bank 0) 的,为什么呢?因为尽管它包含词 "is" ,但它不可用于生成 "is fast" ,因为 fast 的位子已经被 slow 或 mad 占掉了,也就杜绝了后续能生成 "is fast" 的可能性。从另一个角度讲,因为 slow 这样的词的加入,该分支 满足约束的进度 被重置成了 0。
最后请注意,我们最终生成了包含约束短语的合理输出: "The dog is fast" !
起初我们很担心,因为盲目地添加约束词会导致出现诸如 "The is fast" 之类的无意义短语。然而,使用基于组的轮流选择方法,我们最终隐式地摆脱了无意义的输出,优先选择了更合理的输出。
关于 Constraint 类的更多信息及自定义约束
我们总结下要点。每一步,我们都不断地纠缠模型,强制添加约束词,同时也跟踪不满足约束的分支,直到最终生成包含所需短语的合理的高概率序列。
在实现时,我们的主要方法是将每个约束表示为一个 Constraint 对象,其目的是跟踪满足约束的进度并告诉波束搜索接下来要生成哪些词。尽管我们可以使用 model.generate() 的关键字参数 force_words_ids ,但使用该参数时后端实际发生的情况如下:
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, PhrasalConstrainttokenizer = AutoTokenizer.from_pretrained("t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")encoder_input_str = "translate English to German: How old are you?"constraints = [PhrasalConstraint(tokenizer("Sie", add_special_tokens=False).input_ids)
]input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_idsoutputs = model.generate(input_ids,constraints=constraints,num_beams=10,num_return_sequences=1,no_repeat_ngram_size=1,remove_invalid_values=True,
)print("Output:\n" + 100 *'-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
Wie alt sind Sie?你甚至可以定义一个自己的约束并将其通过 constraints 参数输入给 model.generate() 。此时,你只需要创建 Constraint 抽象接口类的子类并遵循其要求即可。你可以在 此处 的 Constraint 定义中找到更多信息。
我们还可以尝试其他一些有意思的约束 (尚未实现,也许你可以试一试!) 如 OrderedConstraints 、 TemplateConstraints 等。目前,在最终输出中约束短语间是无序的。例如,前面的例子一个输出中的约束短语顺序为 scared -> screaming ,而另一个输出中的约束短语顺序为 screamed -> scared 。如果有了 OrderedConstraints, 我们就可以允许用户指定约束短语的顺序。TemplateConstraints 的功能更小众,其约束可以像这样:
starting_text = "The woman"
template = ["the", "", "School of", "", "in"]possible_outputs == ["The woman attended the Ross School of Business in Michigan.","The woman was the administrator for the Harvard School of Business in MA."
]或是这样:
starting_text = "The woman"
template = ["the", "", "", "University", "", "in"]possible_outputs == ["The woman attended the Carnegie Mellon University in Pittsburgh.",
]
impossible_outputs == ["The woman attended the Harvard University in MA."
]或者,如果用户不关心两个词之间应该隔多少个词,那仅用 OrderedConstraint 就可以了。
总结
约束波束搜索为我们提供了一种将外部知识和需求注入文本生成过程的灵活方法。以前,没有一个简单的方法可用于告诉模型 1. 输出中需要包含某列表中的词或短语,其中 2. 其中有一些是可选的,有些必须包含的,这样 3. 它们可以最终生成至在合理的位置。现在,我们可以通过综合使用 Constraint 的不同子类来完全控制我们的生成!
该新特性主要基于以下论文:
Guided Open Vocabulary Image Captioning with Constrained Beam Search
Fast Lexically Constrained Decoding with Dynamic Beam Allocation for Neural Machine Translation
Improved Lexically Constrained Decoding for Translation and Monolingual Rewriting
Guided Generation of Cause and Effect
与上述这些工作一样,还有许多新的研究正在探索如何使用外部知识 (例如 KG (Knowledge Graph) 、KB (Knowledge Base) ) 来指导大型深度学习模型输出。我们希望约束波束搜索功能成为实现此目的的有效方法之一。
感谢所有为此功能提供指导的人: Patrick von Platen 参与了从 初始问题 讨论到 最终 PR 的全过程,还有 Narsil Patry,他们二位对代码进行了详细的反馈。
本文使用的图标来自于 Freepik - Flaticon。
英文原文: https://hf.co/blog/constrained-beam-search
原文作者: Chan Woo Kim
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
审校/排版: zhongdongy (阿东)
相关文章:
在 Transformers 中使用约束波束搜索引导文本生成
引言 本文假设读者已经熟悉文本生成领域波束搜索相关的背景知识,具体可参见博文 如何生成文本: 通过 Transformers 用不同的解码方法生成文本。 与普通的波束搜索不同,约束 波束搜索允许我们控制所生成的文本。这很有用,因为有时我们确切地知…...

Centos7更换OpenSSL版本
OpenSSL 1.1.0 用户应升级至 1.1.0aOpenSSL 1.0.2 用户应升级至 1.0.2iOpenSSL 1.0.1 用户应升级至 1.0.1u 查看openssl版本 openssl version -v选择升级版本 我的版本是OpenSSL 1.0.2系列,所以要升级1.0.2i https://www.openssl.org/source/old/1.0.2/openssl-…...
基于摄影测量的三维重建【终极指南】
我们生活的时代非常令人兴奋,如果你对 3D 东西感兴趣,更是如此。 我们有能力使用任何相机,从感兴趣的物体中捕捉一些图像数据,并在眨眼间将它们变成 3D 资产! 这种通过简单的数据采集阶段进行的 3D 重建过程是许多行业…...

配置ThreadPoolExecutor
ThreadPoolExecutor为一些Executor 提供了基本的实现,这些Executor 是由Executors中的newCachedThreadPool、newFixedThreadPool和newScheduledThreadExecutor 等工厂方法返回的。ThreadPoolExecutor是一个灵活的、稳定的线程池,允许进行各种定制。 如果默认的执行策略不能满足…...
Yolov5s算法从训练到部署
文章目录 PyTorch GPU环境搭建查看显卡CUDA版本Anaconda安装PyTorch环境安装PyCharm中验证 训练算法模型克隆Yolov5代码工程制作数据集划分训练集、验证集修改工程相关文件配置预训练权重文件配置数据文件配置模型文件配置 超参数配置 测试训练出来的算法模型 量化转换算法模型…...
分布式补充技术 01.AOP技术
01.AOP技术是对于面向对象编程(OOP)的补充。是按照OCP原则进行的编写,(ocp是修改模块权限不行,扩充可以) 02.写一个例子: 创建一个新的java项目,在main主启动类中,写如下代码。 package com.co…...
)
QT 多对一服务插件 CTK开发(五)
CTK在软件的开发过程中可以很好的降低复杂性、使用 CTK Plugin Framework 提供统一的框架来进行开发增加了复用性 将同一功能打包可以提供多个应用程序使用避免重复性工作、可以进行版本控制提供了良好的版本更新迭代需求、并且支持动态热拔插 动态更新、开发更加简单快捷 方便…...

[Windows]_[初级]_[创建目录和文件的名字注意事项]
场景 在开发Windows程序时,会出现目录生成了,但是函数无法在目录里创建文件,怎么回事?说明 在之前说过Windows上有些字符是不能作为文件名的[1],但是检查了下出问题的目录名没有非法字符,所以不是这个原因。 把文件的绝对路径打印出来就发现了问题,目录名后边带了空格,…...

「QT」QT5程序设计目录
✨博客主页:何曾参静谧的博客 📌文章专栏:「QT」QT5程序设计 目录 📑【QT的基础知识篇】📑【QT的GUI编程篇】📑【QT的项目示例篇】📑【QT的网络编程篇】📑【QT的数据库编程篇】📑【QT的跨平台编程篇】📑【QT的高级编程篇】📑【QT的开发工具篇】📑【QT的调…...

ConcurrentHashMap核心源码(JDK1.8)
一、ConcurrentHashMap的前置知识扫盲 ConcurrentHashMap的存储结构? 数组 链表 红黑树 二、ConcurrentHashMap的DCL操作 HashMap线程不安全,在并发情况下,或者多个线程同时操作时,肯定要使用ConcurrentHashMap 无论是HashM…...

【Python】文件 读取 写 os模块 shutil模块 pickle模块
目录 1.文件 1.1 读取操作 1.2 写操作 1.3 os:文件管理 1.4 os.path:获取文件属性 1.5 shutil:文件的拷贝删除移动解压缩 1.6 pickle:数据永久存储 1.文件 文件编码 编码是一种规则集合,记录内容和二进制间相互…...

PAT A1087 All Roads Lead to Rome
1087 All Roads Lead to Rome 分数 30 作者 CHEN, Yue 单位 浙江大学 Indeed there are many different tourist routes from our city to Rome. You are supposed to find your clients the route with the least cost while gaining the most happiness. Input Specific…...

浅谈HttpURLConnection所有方法详解
HttpURLConnection 类是 Java 中用于实现 HTTP 协议的基础类,它提供了一系列方法来建立与 HTTP 服务器的连接、发送请求并读取响应信息。下面是 HttpURLConnection 类中常用的方法以及其详细解释: ---------------------------------------------------…...

前端快速创建web3应用模版分享
一、起因 一直以来都有一个创建前端Dapp模版的愿望,一来是工作中也有这样的需要,避免每次都要抽离重复的代码。二来是这样的模版也能帮助其他前端快速了解到web3应用的脚手架以及框架结构。于是决定整理一个模版并开源,希望我的代码能帮助到大…...

越权漏洞讲解
越权漏洞是指系统或应用程序中存在的安全漏洞,允许攻击者以超越其授权范围的方式访问系统资源或执行特权操作。这种漏洞可能会导致严重的安全风险,因为攻击者可以利用它来获取敏感信息、修改系统设置或执行恶意操作。 下面是一些常见的越权漏洞类型和它…...
短视频矩阵源码系统打包.源码
Masayl是一款基于区块链技术的去中心化应用程序开发平台,可帮助开发者快速、便捷地创建去中心化应用程序。Masayl拥有丰富的API和SDK,为开发者们提供了支持。此外,Masayl还采用了高效的智能合约技术,确保应用程序的稳定、安全和高…...

云南LED、LCD显示屏系统建设,户外、室内广告大屏建设方案
LED大屏幕显示系统是LED高清晰数字显示技术、显示单元无缝拼接技术、多屏图像处理技术、信号切换技术、网络技术等科技手段的应用综合为一体,形成一个拥有高亮度、高清晰度、技术先进、功能强大、使用方便的大屏幕投影显示系统。通过大屏幕显示系统,可以…...

Shell脚本:expect脚本免交互
Shell脚本:expect脚本免交互 expect脚本免交互 一、免交互基本概述:1.交互与免交互的区别:2.格式:3.通过read实现免交互:4.通过cat实现查看和重定向:5.变量替换: 二、expect安装:1.…...

王道考研计算机网络第二章知识点汇总
2.1.1物理层基本概念 电气特性和功能特性易混淆,注意区分。电气特性一般指的是某个范围,功能特性一般指的是电平所代表的含义。 2.1.2数据通信基础知识 同步传输是指发送方和接收方节奏是统一的,数据之间是没有间隔的是一个一个的区块。在键…...
06.05
1.二进制求和 给你两个二进制字符串 a 和 b ,以二进制字符串的形式返回它们的和。 考虑一个最朴素的方法:先将 aaa 和 bbb 转化成十进制数,求和后再转化为二进制数。利用 Python 和 Java 自带的高精度运算,我们可以很简单地写出这…...

APP加固后审核被拒怎么办?iOS上架失败紧急解决流程与性能排查
花了大量心血开发的应用,提交到App Store后,等来的不是上架成功的邮件,而是一封来自苹果的审核拒绝信,理由还是“元数据被拒”或“二进制文件被拒”。更让人崩溃的是,排查下来,问题很可能指向刚做的iOS应用…...

加法器优化:从并行前缀到AXON框架的技术演进
1. 加法器优化:从经典架构到AXON框架的演进在数字电路设计中,加法器作为最基础的算术运算单元,其性能直接影响整个系统的时钟频率和能效表现。传统加法器设计面临一个核心矛盾:如何在延迟(Delay)、功耗&…...

VINS-Mono跑EUROC数据集实战:如何解读Rviz可视化结果与评估轨迹精度?
VINS-Mono EUROC数据集实战:Rviz可视化与轨迹精度评估全解析 当你第一次在Rviz中看到VINS-Mono处理EUROC数据集生成的复杂点云和轨迹时,那种既兴奋又困惑的感觉我完全理解。作为一款开源的视觉惯性里程计(VIO)系统,VINS-Mono在无人机、移动机…...

为什么92%参会者在P3东区绕行超4分钟?2026大会停车动线算法白皮书首度披露
更多请点击: https://intelliparadigm.com 第一章:2026年AI技术大会停车指引概览 2026年AI技术大会主会场设于上海张江科学城国际会展中心,周边共开放3个智能停车场(P1–P3),全部支持车牌自动识别、无感支…...

全面掌握抖音下载工具:高效保存无水印视频的终极方案
全面掌握抖音下载工具:高效保存无水印视频的终极方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...

ComfyUI MixLab节点库:提升AI图像工作流控制与自动化能力
1. 项目概述:一个为ComfyUI注入新活力的节点库如果你和我一样,是个深度依赖ComfyUI进行AI图像工作流搭建的创作者,那你一定经历过这样的时刻:面对一个复杂的创意想法,却发现官方节点或者现有社区节点库的功能组合起来总…...

代码审查进入“零延迟”时代:如何在CI/CD流水线毫秒级触发语义级风险推演?——2026奇点大会核心议题深度拆解
更多请点击: https://intelliparadigm.com 第一章:AI原生代码审查:2026奇点智能技术大会Code Review新范式 在2026奇点智能技术大会上,AI原生代码审查(AI-Native Code Review)正式取代传统人工规则引擎混合…...
)
奇点不是预言,是进度条:SITS 2026公布的87项技术里程碑中,已有23项进入工信部信创适配目录(附完整清单速查表)
更多请点击: https://intelliparadigm.com 第一章:CSDN主办SITS 2026:2026奇点智能技术大会亮点全解析 SITS 2026(Singularity Intelligence Technology Summit)由CSDN联合中国人工智能学会、中科院自动化所共同主办&…...

终极兼容方案:让老旧游戏手柄在现代游戏中重获新生
终极兼容方案:让老旧游戏手柄在现代游戏中重获新生 【免费下载链接】XOutput DirectInput to XInput wrapper 项目地址: https://gitcode.com/gh_mirrors/xo/XOutput 还在为那些功能完好却被现代游戏抛弃的经典游戏手柄感到惋惜吗?我们深知那种无…...

海思Hi3516 GPIO复用避坑指南:从Excel引脚复用表到实际配置的完整解析
海思Hi3516 GPIO复用配置实战:从寄存器解析到避坑全攻略 当你在调试Hi3516开发板时,是否遇到过这样的场景:明明按照手册配置了GPIO,硬件却毫无反应?或者发现某个复用引脚无法正常工作?这些问题往往源于对海…...