【ChatGPT】数据科学 ChatGPT Cheat Sheet 书籍分享(阿里云盘下载)

封皮
以下为书中部分内容的机器翻译
我们的重要提示指南
1. 以 AI 角色的描述开始提示。 例如,“你是{x}”或“我希望你扮演{x}”。如果您不确定,请尝试“你是一个有帮助的助手”。
例如,您是 OpenAI 的数据科学家,您正在研究大型语言模型。向我解释 GPT-3 的工作原理
2. 将其用于常见任务。 任务越常见,使用 ChatGPT 成功的机会就越大
3. 提供上下文。 在向 ChatGPT 提出问题时提供上下文使其能够提供具体的答案。提供上下文允许模型理解问题的细微差别并生成更明智的响应。
例如,您是 OpenAI 的数据科学家,您正在研究大型语言模型。向没有技术背景的业务主管解释 GPT-3 如何工作。
4. 要精确。 精确是另一个最佳实践,可以最大限度地减少调整输出的需要。 提出问题时,请清楚输入(如果有)和期望的结果
5. 继续尝试。 不要害怕尝试多个提示。 使用不同的提示可以提供对问题的不同观点,并使模型能够生成各种响应
ChatGPT 的局限性
然而,ChatGPT 并不完美——它可能会生成错误的信息,或产生“幻觉”。 ChatGPT 可以以权威的语气提供错误的答案。因此,对所有答案进行事实核查非常重要
1. 一般编码工作流程的提示
调试 Python 代码
我希望你成为一名 Python 程序员,这是一段包含{问题}的 Python 代码 — {插入代码片段} — 我收到以下错误 {插入错误}。错误的原因是什么?
我希望你成为一名 R 程序员,这是一段包含{问题}的 R 代码——{插入代码片段}——我收到以下错误{插入错误}。错误的原因是什么?
我希望你成为一名 SQL 程序员,这是一段包含{问题}的 SQL 代码 — {插入代码片段} — 我收到以下错误 {插入错误}。错误的原因是什么?Python代码解释
我希望你充当 Python 中的代码解释器。我不明白这个功能。你能解释一下它的作用,并提供一个例子吗?{插入函数}
我想让你在R中充当代码解释器。我不明白这个功能。你能解释一下它的作用,并提供一个例子吗?{插入函数}
我希望你充当 SQL 中的代码解释器。我不明白这个片段。你能解释一下它的作用,并提供一个例子吗?{插入 SQL 查询}Python代码优化
我希望你充当 Python 中的代码优化器。{如果可能,请描述当前代码的问题}。你能让代码{更Pythonic/更干净/更高效/运行更快/更具可读性}吗?{插入代码}
我希望你充当 R 中的代码优化器。{如果可能,请描述当前代码的问题}。你能让代码{更干净/更高效/运行更快/更具可读性}吗?{插入代码}
我希望你充当 SQL 中的查询优化器。{如果可能,请描述当前代码的问题}。您能否建议使查询{运行得更快/更具可读性/更简单}的方法?{插入代码}Python代码简化
我想让你扮演 Python 的程序员。请简化此代码,同时确保它{高效/易于阅读/Pythonic}?
{插入代码}
我想让你充当 R 中的程序员。请简化此代码,同时确保它{高效/易于阅读}?{插入代码}
我想让你扮演一个 SQL 程序员。我正在运行 {PostgreSQL 14/MySQL 8/SQLite 3.4/其他版本。}。您能否简化此查询{同时确保它高效/易于阅读/插入任何其他要求}?从 R 到 Python 代码翻译
我想让你充当 R 中的程序员。请将此代码转换为 Python。{插入代码}
我想让你扮演 Python 的程序员。请将此代码翻译成 R。{插入代码}比较python中的函数速度
我想让你扮演一个 Python 程序员。你能编写代码来比较两个函数 {functionname} 和 {functionname} 的速度吗?{插入函数}在 R 中编写单元测试 、用 Python 编写单元测试
我想让你充当 R 程序员。你能为函数 {functionname} 编写单元测试吗?{插入单元测试的要求,如果有的话} {插入代码}
我想让你充当 Python 程序员。你能为函数 {functionname} 编写单元测试吗?{插入单元测试的要求,如果有的话} {插入代码}2. 数据分析工作流程提示
数据生成和创建表
I want you to act as a data generator. Can you write SQL queries in {database version} that create a table {table name} with the columns {column name}. Include relevant constraints and index
我希望你充当数据生成器。 您能否在 {database version} 中编写 SQL 查询,创建一个包含列 {column name} 的表 {table name}。 包括相关约束和索引常用表表达式
I want you to act as a SQL code programmer. I am running {database version}. Can you rewrite this query using CTE? {Insert query}
我想让你充当 SQL 代码程序员。 我正在运行{数据库版本}。 你能用 CTE 重写这个查询吗? {插入查询}从自然语言编写 SQL 查询
I want you to act as a data scientist. {Insert description of tables}. Can you {count/sum/take average} of {value} which are {insert filters}
我想让你扮演一名数据科学家。{插入表格说明}。你可以{count/sum/average} {value} 这是 {insert filters}
我想让你扮演一名数据科学家。我有一家电子商务公司的三个 PostgreSQL 14 表“客户”。客户表由列“customer_id”、“customer_name”、“customer_email”、“customer_phone”和“customer_address”组成。使用“customer_email”,你能计算出使用 gmail、outlook、yahoo 或其他提供商的客户数量吗?I want you to act as a data scientist. {Insert description of tables}. Can you {count/sum/take average} of {value} which are {insert filters}
我想让你扮演一名数据科学家。{插入表格说明}。你可以{count/sum/average} {value} 这是 {insert filters}
我想让你扮演一名数据科学家。我有一家电子商务公司的三个 PostgreSQL 14 表“客户”。客户表由列“customer_id”、“customer_name”、“customer_email”、“customer_phone”和“customer_address”组成。使用“customer_email”,你能计算出使用 gmail、outlook、yahoo 或其他提供商的客户数量吗?I want you to act as a data scientist. I am running {PostgreSQL 14/MySQL 8/SQLite 3.4/other versions.}. I have the tables {table_name} which are {table description}. The sales table consists of the columns {column names}. Can you please write a query that finds the 7-day running average of {quantity}?
我想让你扮演一名数据科学家。我正在运行 {PostgreSQL 14/MySQL 8/SQLite 3.4/其他版本。}。我有 {table_name} 表,它们是 {table description}。销售表由列 {column names} 组成。您能否编写一个查询来查找 {quantity} 的 7 天运行平均值?
我想让你扮演一名数据科学家。我有一家电子商务公司的 PostgreSQL 14 表“销售”。销售表由列“customer_id”、“product_id”、“sale_date”、“sale_quantity”组成。您能否编写一个查询来查找 sale_quantity 的 7 天运行平均值?I want you to act as a data scientist. I am running {PostgreSQL 14/MySQL 8/SQLite 3.4/other versions.}. I have the tables {table_name} which are {table description}. The sales table consists of the columns {column names}. Can you please write a query that finds {required window function}?
我想让你扮演一名数据科学家。我正在运行 {PostgreSQL 14/MySQL 8/SQLite 3.4/其他版本。}。我有 {table_name} 表,它们是 {table description}。销售表由列 {column names} 组成。你能写一个查询来找到{required window function}吗?
我想让你扮演一名数据科学家。我有一家电子商务公司的三个 PostgreSQL 14 表“销售”。销售表由列“customer_id”、“product_id”、“sale_date”、“sale_quantity”组成。你能写一个查询来找出当天的 sale_quantity 和平均 sale_quantity 之间的差异吗?数据生成工作流程
I want you to act as a data generator in Python. Can you generate a Markdown file that contains {data requirement}. Save the file to {filename}
我想让你充当 Python 中的数据生成器。你能生成一个包含{data requirement}的Markdown文件吗?将文件保存到 {filename}
我想让你充当 python 中的数据生成器。您能否生成一个包含模拟员工数据的 Markdown 文件,其中包含列 employee_id、name、department_id、email、join_date、current_salary。将文件保存到“employee.md”I want you to act as a data generator in Python. Can you generate a CSV file that contains {data requirement}. Save the file to {filename}
我想让你充当 Python 中的数据生成器。你能生成一个包含{data requirement}的CSV文件吗?将文件保存到 {filename}
我想让你充当 python 中的数据生成器。 您能否生成一个包含模拟员工数据的 CSV 文件,其中包含列 employee_id、name、department_id、email、join_date、current_salary。 将文件保存到 ' employee.csv'I want you to act as a data generator in Python. Can you generate a JSON file that contains {data requirement}. Save the file to {filename}
我想让你充当 Python 中的数据生成器。你能生成一个包含{data requirement}的JSON文件吗?将文件保存到 {filename}I want you to act as a data scientist programming in Python Pandas. Given a CSV file that contains data of {dataframe name} with the columns {colum names}for {dataset context}, write code to clean the data? {Insert requirements for data}
我希望你扮演一名使用 Python Pandas 编程的数据科学家。给定一个 CSV 文件,其中包含 {dataframe name} 的数据以及 {dataset context} 的列 {colum names},编写代码来清理数据?{插入数据要求}
我希望你扮演一名使用 Python Pandas 编程的数据科学家。 给定一个 CSV 文件,其中包含电子商务公司的“customers”信息数据,列为“customer_id”、“customer_name”、“customer_email”、“customer_phone”、“customer_address”,编写代码来清理数据? 请删除带有 customer_id 的行,并将空的 customer_name 替换为“UNKNOWN”。pandas 中的数据分析工作流程
I want you to act as a data scientist programming in Python Pandas. Given a table {table name} that consists of the columns {column names} can you please write a query that finds {requirement}?
我希望你扮演一名使用 Python Pandas 编程的数据科学家。给定一个由列 {column names} 组成的表 {table name},你能写一个查询来找到 {requirement} 吗?
我希望你扮演一名使用 Python Pandas 编程的数据科学家。给定一个电子商务公司的表“sales”,其中包含列“customer_id”、“product_id”、“sale_date”、“sale_quantity”,你能写一个查询来找到一月份最受欢迎的 product_id 吗I want you to act as a data scientist programming in Python Pandas. Given a table {table 1 name} that consists of the columns {column names} and another table {table 2 name} with the columns {column names} , please merge the two tables. {Insert additional requirement, if any}
我希望你扮演一名使用 Python Pandas 编程的数据科学家。给定一个由列 {column names} 组成的表 {table 1 name} 和另一个包含列 {column names} 的表 {table 2 name} ,请合并这两个表。{插入附加要求,如果有的话}
我希望你扮演一名使用 Python Pandas 编程的数据科学家。给定一个由列 {column names} 组成的表 {table name},您可以按 {column} 聚合 {value} 并将其从长格式转换为宽格式吗?I want you to act as a data generator in R. Can you generate a Markdown file that contains {data requirement}.
Save the file to {filename}
我想让你在 R 中充当数据生成器。你能生成一个包含 {data requirement} 的 Markdown 文件吗?
将文件保存到 {filename}数据生成工作流程
I want you to act as a data generator in R. Can you generate a CSV file that contains {data requirement}. Save the file to {filename}
我想让你在 R 中充当数据生成器。你能生成一个包含 {data requirement} 的 CSV 文件吗?将文件保存到 {filename}
我想让你在 R 中充当数据生成器。你能生成一个 CSV 文件,其中包含模拟员工数据,其中包含列 employee_id、name、department_id、email、join_date、current_salary。将文件保存到 ' employee.csv'我想让你在 R 中充当数据生成器。你能生成一个包含 {data requirement} 的 JSON 文件吗?将文件保存到 {filename}
我想让你在 R 中充当数据生成器。你能生成一个 JSON 文件,其中包含模拟员工数据,其中包含列 employee_id、name、department_id、email、join_date、current_salary。将文件保存到 ' employee. JSON'数据清洗工作流程
我希望你在 R tidyr 中担任数据科学家编程。您将获得包含列 {column name} 的 {dataframe name} 数据框。{插入要求}
我希望你在 R tidyr 中担任数据科学家编程。您将获得包含列 employee_id、name、department_id、email、join_date、current_salary 的“employee”数据框。编写代码以删除具有任何空值的行并执行其他数据清理步骤。tidyr 中的数据分析工作流程
我希望你在 R tidyr 中担任数据科学家编程。您将获得包含列 {column name} 的 {dataframe name} 数据框。{插入要求}
我希望你在 R tidyr 中担任数据科学家编程。您将获得包含列 employee_id、name、department_id、email、join_date、current_salary 的“employee”数据框。找出新加入人数最多的年份。我希望你在 R tidyr 中担任数据科学家编程。您将获得包含列 {column name} 的 {dataframe 1 name} 数据框。您还有一个包含列 {column name} 的 {dataframe 2 name} 数据框。找到{需要的输出}
我希望你在 R tidyr 中担任数据科学家编程。您将获得包含列 employee_id、name、department_id、email、join_date、current_salary 的“employee”数据框。您还有一个包含 department_id 和 department_name 列的“department”数据框。找到工资中位数最高的 department_name。我希望你在 R tidyr 中担任数据科学家编程。您将获得包含列 {column name} 的 {dataframe name} 数据框。请将数据转换为宽格式。
我希望你在 R tidyr 中担任数据科学家编程。您将获得包含列 {column name} 的 {dataframe name} 数据框。请将数据转换为长格式3. 数据可视化工作流程提示
在 ggplot2 中创建绘图
我希望你扮演一名使用 R 编写代码的数据科学家。给定一个包含列 {column names} 的数据框 {dataframe name} 使用 ggplot2 绘制 {chart type and requirement}。
我希望你扮演使用 R 编写代码的数据科学家。给定一个数据框“gapminder”,其中包含“国家”、“gdp”、“年”列。使用 ggplot2 绘制每个国家/地区 GDP 与年份的折线图。我希望你扮演使用 R 编写代码的数据科学家。给定一个包含列 {column names} 的数据框 {dataframe name}。使用 ggplot2 绘制一对图,显示一个变量与另一个变量的关系
我想让你扮演一名用 R 编写代码的数据科学家。给定一个包含列“sepal_length”、“sepal_width”、“petal_width”、“petal_length”的数据框“iris”使用 ggplot2 绘制一对图来显示一个变量的关系 针对另一个。注释和格式化图
我想让你扮演一个用 R 编写代码的数据科学家。给定一个包含列 {column names} 的数据框 {dataframe name},使用 ggplot2 绘制一个{chart type} {variables} 之间的关系。{插入注释和格式要求}
我希望你扮演一名使用 R 编写代码的数据科学家。给定一个包含列“sepal_length”、“sepal_width”、“flower_type”的数据框“iris”,使用 ggplot2 绘制 sepal_length 和 sepal_width 之间关系的散点图。使用颜色来表示不同的 flower_types。将图表命名为“长度与宽度”在 ggplot2 中更改绘图主题
我想让你扮演一名使用 R 编写代码的数据科学家。给定一个包含列 {column names} 的数据框 {dataframe name},使用 ggplot2 绘制一个{chart type} {variables} 之间的关系。更改颜色主题以匹配 {theme}
我希望你扮演一名使用 R 编写代码的数据科学家。给定一个包含列“sepal_length”、“sepal_width”、“flower_type”的数据框“iris”,使用 ggplot2 绘制 sepal_length 和 sepal_width 之间关系的散点图。更改颜色主题以匹配 fivethirtyeight 的颜色主题。使用 matplotlib 创建绘图
我希望你扮演一名使用 Python 编码的数据科学家。给定包含列 {column names} 的数据框 {dataframe name} 使用 matplotlib 绘制 {chart type and requirement}
我希望你扮演一名使用 Python 编码的数据科学家。给定一个数据框“gapminder”,其中包含列“country”、“gdp”、“year”。使用 matplotlib 绘制每个国家/地区 GDP 与年份的折线图。使用 matplotlib 创建箱线图
我希望你扮演一名使用 Python 编码的数据科学家。给定包含列 {column names} 的数据框 {dataframe name}。使用 matplotlib 绘制一对图,显示一个变量与另一个变量之间的关系。
我希望你扮演一名使用 Python 编码的数据科学家。给定包含列“sepal_length”、“sepal_width”、“petal_width”、“petal_length”的数据框“iris”使用 matplotlib 绘制一对图,显示一个变量与另一个变量的关系。在 matplotlib 中注释和格式化绘图
我希望你扮演一名使用 Python 编码的数据科学家。给定包含列 {column names} 的数据框 {dataframe name},使用 matplotlib 绘制{chart type} {variables} 之间的关系。{插入注释和格式要求}
我希望你扮演一名使用 Python 编码的数据科学家。给定包含列“sepal_length”、“sepal_width”、“flower_type”的数据框“iris”,使用 matplotlib 绘制 sepal_length 和 sepal_width 之间关系的散点图。使用颜色来表示不同的 flower_types。将图表命名为“长度与宽度”在 matplotlib 中更改绘图主题
我希望你扮演一名使用 Python 编码的数据科学家。给定包含列 {column names} 的数据框 {dataframe name},使用 matplotlib 绘制{chart type} {variables} 之间的关系。
更改颜色主题以匹配 {theme}
我希望你扮演一名使用 Python 编写代码的数据科学家。给定包含“sepal_length”、“sepal_width”、“flower_type”列的数据框“iris”,使用 matplotlib 绘制 sepal_length 和 sepal_width 之间关系的散点图。更改颜色主题以匹配 fivethirtyeight 的颜色主题。4. 机器学习工作流程提示
特征工程构思
我想让你扮演一名数据科学家。
给定包含 {columns} 的 {dataset name} 数据集,您要预测 {predicted variable}。建议对这个问题有帮助的数据,并针对这个问题进行特征工程
我想让你扮演一名数据科学家。给定一个包含演员表、发行年份、预算和其他电影数据的电影数据集,你要预测这部电影的全球票房是多少。建议对这个问题有帮助的数据,并针对这个问题进行特征工程。模型训练工作流程
我希望你扮演一名使用 Python 编程的数据科学家。给定包含 {column name} 的 {dataframe name} 数据集,编写代码来预测 {output variable}
我希望你扮演一名使用 Python 编程的数据科学家。给定包含演员表、发行年份、预算和其他电影数据的电影数据集,编写代码来预测电影的全球票房是多少。超参数调整工作流程
我希望你扮演一名使用 Python 编程的数据科学家。给定一个 {type of model} 模型,编写代码来调整超参数
我希望你扮演一名使用 Python 编程的数据科学家。给定一个决策树分类模型,编写代码来调整超参数。模型可解释性工作流
我希望你扮演一名使用 Python 编程的数据科学家。给定一个预测{预测变量}的{模型类型},编写代码使用 Shap 值解释输出
我希望你扮演一名使用 Python 编程的数据科学家。给定一个 sklearn 决策树模型,该模型根据演员表、发行年份、预算和其他电影数据预测模型的票房,编写代码使用 Shap 值解释输出。模型训练工作流程
我想让你扮演一名使用 R 编程的数据科学家。给定一个包含 {column names} 的 {dataframe name} 数据框,编写代码来预测 {output}。
我想让你扮演使用 R 编程的数据科学家。给定一个包含产品名称、价格和产品类别的产品数据框,编写代码来预测新产品的产品类别。超参数调整工作流程
我希望你扮演一名使用 R 编程的数据科学家。给定一个 {type of model} 模型,编写代码来调整超参数
我希望你扮演一名使用 R 编程的数据科学家。给定一个决策树分类模型,编写代码来调整超参数。模型可解释性工作流
我希望你担任 R 中的数据科学家编程。给定一个预测{预测变量}的{模型类型},编写代码使用 Shap 值解释输出
我希望你扮演使用 R 编程的数据科学家。给定一个决策树模型,该模型根据产品名称和价格预测产品的产品类别,编写代码来使用 Shap 值解释输出。5. 时间序列分析工作流程提示
使用pandas改变时间范围
我希望你扮演一名使用 Python 编码的数据科学家。给定 Pandas 数据帧 {dataframe name} 中的时间序列数据,时间戳索引为 {original frequency} 频率,一列 {column name},将时间戳频率转换为 {desired frequency}
我希望你扮演一名使用 Python 编码的数据科学家。给定 Pandas 数据帧“ts”中的时间序列数据,时间戳索引以每日频率和一列“值”,将时间戳频率转换为每周和每月。构建测试系列模型
我希望你扮演一名使用 Python 编码的数据科学家。给定数据帧 {dataframe name} 中的时间序列数据,时间戳索引为 {original frequency} 频率,一列 {column name},建立一个预测模型,假设数据是固定的
我希望你扮演一名使用 Python 编码的数据科学家。给定 Pandas 数据帧“ts”中的时间序列数据,其中时间戳索引以每日频率显示,其中有一列“value”,假设时间序列是平稳的,构建一个预测模型。执行平稳性测试
我希望你扮演一名使用 Python 编码的数据科学家。给定数据帧 {dataframe name} 中的时间序列数据,时间戳索引以 {original frequency} 频率和一列 {column name},执行 Dicky Fuller 测试
我希望你扮演一名使用 Python 编码的数据科学家。给定 Pandas 数据帧“ts”中的时间序列数据,时间戳索引以每日频率和一列“value”进行,执行 Dicky Fuller 测试。改变时间范围
我想让你充当用 R 编码的数据科学家。给定数据帧 {dataframe name} 中的时间序列数据,时间戳索引为 {original frequency} frequency with one column {column name},将时间戳频率转换为 {desired frequency }
我想让你扮演一名使用 R 编写代码的数据科学家。给定数据帧 ts 中的时间序列数据,时间戳索引以每日频率和一列值',将时间戳频率转换为每周和每月。构建测试系列模型
我想让你扮演一名用 R 编写代码的数据科学家。给定数据帧 {dataframe name} 中的时间序列数据,时间戳索引为 {original frequency} frequency with one column {column name},建立一个预测模型,假设数据是 静止的
我想让你扮演一名使用 R 编写代码的数据科学家。给定数据帧“ts”中的时间序列数据,其中时间戳索引以每日频率和一列“值”为基础,构建一个预测模型,假设数据是固定的。执行平稳性测试
我想让你扮演一名用 R 编写代码的数据科学家。给定数据帧 {dataframe name} 中的时间序列数据,时间戳索引以 {original frequency} 频率和一列 {column name} 执行 Dicky Fuller 测试。
我想让你扮演一名使用 R 编写代码的数据科学家。给定数据帧“ts”中的时间序列数据,时间戳索引以每日频率和一列“值”为单位,执行平稳性测试。6. 提示自然语言处理工作流程
分类文本情感
我想让你充当情绪分类器。将来自 {describe text origin} 的以下文本分类为“正面”、“负面”、“中性”或“不确定”:{Insert text to be classifier}
我想让你充当情绪分类器。将自助书籍上的以下评论分类为“正面”、“负面”、“中立”或“不确定”:读起来很棒 我打瞌睡了。厨师之吻。创建正则表达式
我想让你扮演一个用 Python 编写代码的程序员,使用正则表达式来测试一个字符串是否有 finsert 要求)
我想让你扮演一个用 Python 编写代码的程序员,使用正则表达式来测试一个字符串是否以数字开头,以“!”结尾。文本数据集生成
我希望你充当数据集生成器。请在{required text and the context} 上生成{number of text} 文本。{插入附加要求}
我希望你充当数据集生成器。请为二手车经销商的汽车评论生成 5 个文本。请包括正面、中性和负面情绪的数据。机器翻译
我要你当翻译。请将{phrase}从{origin language}翻译成{translated language}
我要你当翻译。你能用法语解释一下机器学习是什么吗?7. 概念和职业导向的提示
为业务主管解释数据概念
我想让你担任一家公司的数据科学家。{Describe content detailed, if required} 请向业务主管解释{concept}的含义。
我希望你在一家研究初创公司担任数据科学家。请将论文 {paper} 解释为 {level of difficulty,例如 软件开发人员,五岁,企业主管,教授}
我希望你在一家研究初创公司担任数据科学家。请向软件开发人员解释论文“Attention is all you need”。建议投资组合项目和想法
我想让你担任数据科学职业教练。我是{describe your background},我想{describe career objective}。建议投资组合项目和想法{描述投资组合的目标}
我想让你担任数据科学职业教练。我是化学工程专业的最后一年学生,我想转向数据科学。建议投资组合项目和想法,以显示我在化学工程领域的时间序列预测能力。写教程
我想让你扮演一名数据科学家作家。请写 {number-of-words} 字的介绍来介绍关于 {title} 的教程。{插入相关要点}
我想让你扮演一名数据科学家作家。请写一篇关于“学习分析 Pandas 中的脏数据”的教程的 100 字介绍本书阿里云盘下载地址:
https://www.aliyundrive.com/s/GTFSWmZN9eo
数据科学提示Github网址:
travistangvh/ChatGPT-Data-Science-Prompts: A repository of 60 useful data science prompts for ChatGPT (github.com)
Table of Contents:
Write python
Explain code
Optimize code
Format code
Translate code from one language to another
Explain concepts
Suggest ideas
Troubleshoot problem
Write SQL
Write other Code
Misc
The End
相关文章:
【ChatGPT】数据科学 ChatGPT Cheat Sheet 书籍分享(阿里云盘下载)
封皮 以下为书中部分内容的机器翻译 我们的重要提示指南 1. 以 AI 角色的描述开始提示。 例如,“你是{x}”或“我希望你扮演{x}”。如果您不确定,请尝试“你是一个有帮助的助手”。 例如,您是 OpenAI 的数据科学家,您正在研究大型…...

使用 Docker-compose 搭建lnmp
服务编排: 应用编排: 单机环境下:shell/python脚本多机/集群环境下:ansible、saltstack、pubbet docker容器编排: 单机:docker-compose多机/集群:docker swarm,mesos marathon&a…...

chatgpt赋能python:Python中的矩阵合并方法:介绍和使用方法
Python中的矩阵合并方法: 介绍和使用方法 矩阵合并是Python编程中常用的操作之一,特别是针对数据分析、机器学习和深度学习等领域。Python提供了多种方法来合并矩阵,本文将介绍这些方法并分享如何在实际应用中使用它们。 普通矩阵合并 最基础的矩阵合…...
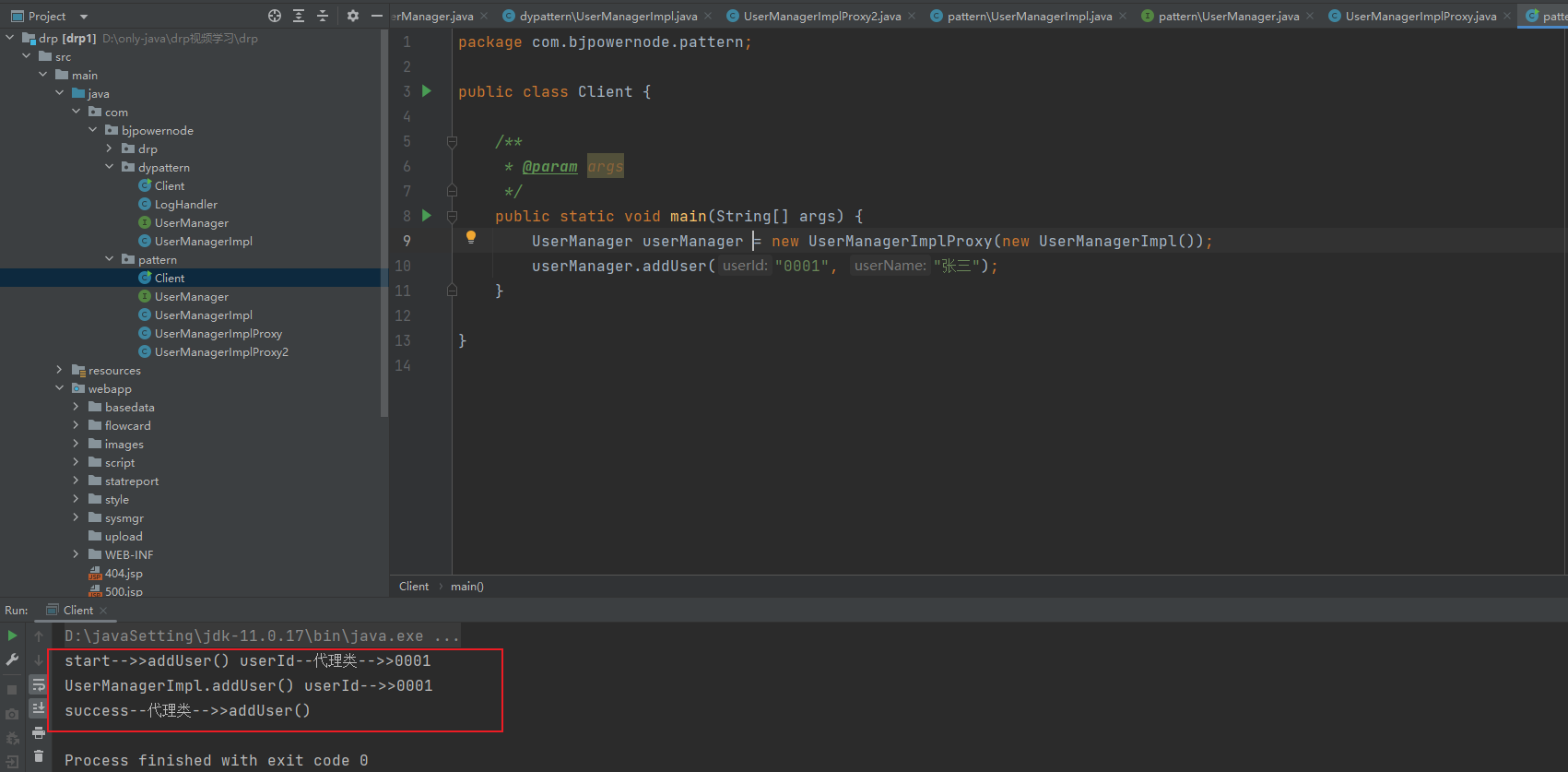
Java动态代理:优化静态代理模式的灵活解决方案
文章目录 代理模式定义具体实现分析优缺点 优化使用动态代理解决优化相关知识动态代理种类场景应用 代理模式 定义 代理模式,为其他对象提供一种代理以控制对这个对象的访问 具体实现 代理模式的具体实现描述可以分为以下几个步骤: 创建抽象对象接…...

四种Bootloader程序安全机制设计
正文 大家周末好,我是bug菌~ 不管是玩单片机还是嵌入式linux,基本上都会接触到bootloader,所以bootloader程序也是一个关键的组件,进行硬件初始化,应用程序的合法性、完成性检测、升级功能等等都与其息息相关。 像一些…...
【DBA 警世录之习惯性命令---读书笔记】
👈【上一篇】 💖The Begin💖点点关注,收藏不迷路💖 【下一篇】👉 🔻【💣 话题引入:既然 DBA 这个职业如此危险,那么哪些习惯是 DBA 必须养成的呢&#x…...

Vue中如何进行状态持久化(LocalStorage、SessionStorage)
Vue中如何进行状态持久化(LocalStorage、SessionStorage)? 在Vue应用中,通常需要将一些状态进行持久化,以便在用户关闭浏览器或刷新页面后,仍能保留之前的状态。常见的持久化方式包括LocalStorage和Sessio…...

【30天熟悉Go语言】6 Go 复杂数据类型之指针
文章目录 一、前言二、数据类型总览三、指针1、特殊运算符& *2、内存角度来看指针3、使用指针修改数据4、指针使用的注意事项5、对比着看Java的引用类型 三、总结 一、前言 Go系列文章: GO开篇:手握Java走进Golang的世界2 Go开发环境搭建、Hello Wor…...

Linux内核使用红黑树的场景
进程调度队列 (Process Scheduling):内核需要对进程按照一定的调度策略进行排队,以便更好地利用 CPU 的时间片。因此,内核使用红黑树作为查找和管理进程调度队列的数据结构,以支持快速的查找、插入和删除操作。 文件系统 (File S…...

遗留的 AppSec 工具迷失在云端
随着应用程序开发步伐的加快,IT 和安全团队正在对旧的应用程序安全(AppSec) 工具失去信心。 根据 Backslash 对 300 名 CISO、AppSec 经理和工程师的调查,遗留工具无法跟上并陷入永远的追赶游戏。 影响是深远的,大多数组织都看到云原生 App…...
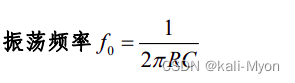
直流稳压电源与信号产生电路(模电速成)
目录 一、直流稳压电源 1、直流稳压电路 2、串联型稳压电路 3、集成稳压电路 二、信号产生电路 1、振荡电路 2、波形发生器 一、直流稳压电源 1、直流稳压电路 直流电源由 变压器、整流、滤波、稳压 四部分组成 整流:将交流变为直流 滤波:减小…...

0202性能分析-索引-MySQL
1 索引语法 创建索引 CREATE [UNIQUE|FULLTEXT] INDEX index_name ON table_name(index_column_name,...);Index_name:规范为idx_表名_字段名... 查看索引 SHOW INDEX FROM table_name;删除索引 DROP INDEX index_name ON table_name;按照下列要求,创建…...
Play wright自动化测试工具该如何更加完美地使用
目录 1.1 拦截网络请求 1.2 pytest 管理用例 1.3 PO模型 1.4 API 和 UI 自动化测试融合 1.5 数据驱动 1.6 动态挑选用例执行 1.6 Allure测试报告 1.7 持续集成 1.1 拦截网络请求 网络拦截: 无响应 pass 中止 route.abort("aborted") 放行 route…...

数据可视化学习笔记:Python实现汽车品牌销售量矩形树图
引言 本文将介绍如何使用 Python 和 Pyecharts 库创建一个汽车品牌销售量的矩形树图。我们将使用 Pandas 读取 CSV 文件数据,然后对数据进行处理、封装,最后将数据可视化为矩形树图。 准备工作 首先,我们需要先安装好相关库: PandasPyecharts可以使用 pip 命令进行安装:…...
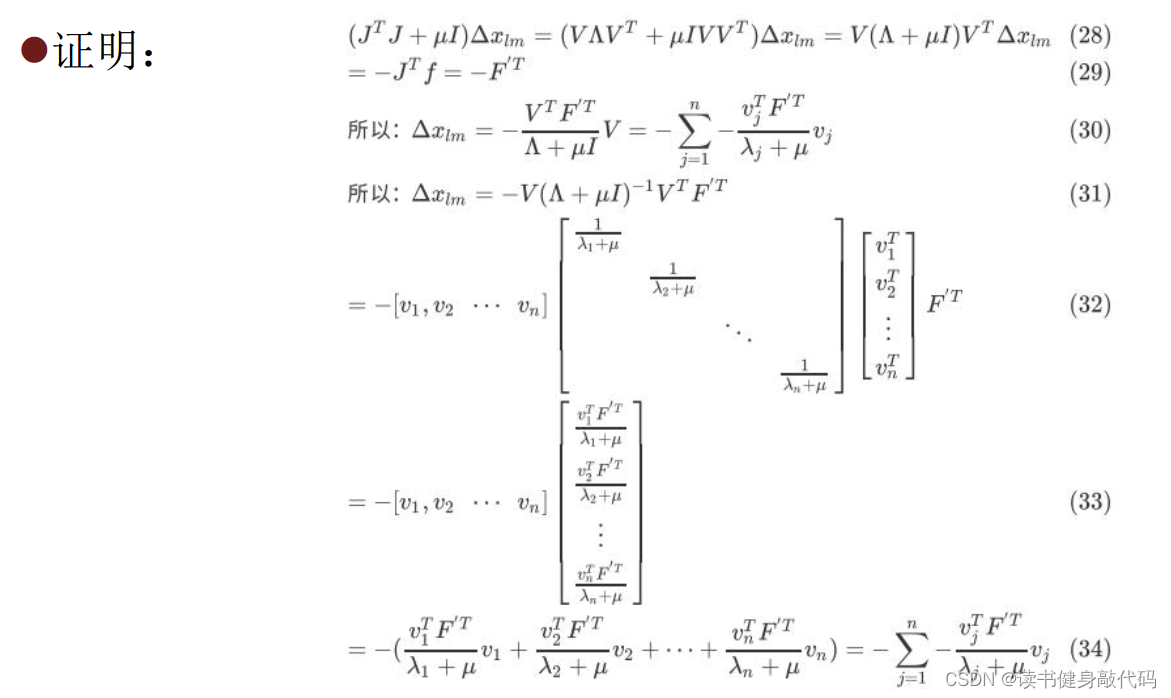
【深蓝学院】手写VIO第3章--基于优化的 IMU 与视觉信息融合--作业
0. 题目 1. T1 T1.1 绘制阻尼因子曲线 将尝试次数和lambda保存为csv,绘制成曲线如下图 iter, lambda 1, 0.002000 2, 0.008000 3, 0.064000 4, 1.024000 5, 32.768000 6, 2097.152000 7, 699.050667 8, 1398.101333 9, 5592.405333 10, 1864.135111 11, 1242.7567…...

企业级信息系统开发讲课笔记4.11 Spring Boot中Spring MVC的整合支持
文章目录 零、学习目标一、Spring MVC 自动配置(一)自动配置概述(二)Spring Boot整合Spring MVC 的自动化配置功能特性 二、Spring MVC 功能拓展实现(一)创建Spring Boot项目 - SpringMvcDemo2021ÿ…...
chatgpt赋能python:Python安装EGG——一个简单的指南
Python安装EGG——一个简单的指南 如果你使用Python有一段时间了,你可能会遇到需要安装扩展包(Package)的情况。在Python中,这些扩展包的文件格式通常是.egg(Easy Installable GZip)。在本文中,…...

Web前端-React学习
React基础 React 概述 React 是一个用于构建用户界面的JavaScript库。 用户界面: HTML页面(前端) React主要用来写HTML页面, 或构建Web应用 如果从MVC的角度来看,React仅仅是视图层(V),也就…...

【Rust项目实战】sensleak,扫描 Git 仓库中的敏感信息
github仓库:https://github.com/open-rust-initiative/sensleak-rs Rust是一门神奇的编程语言,它提供了内存安全、零成本抽象、并发安全等特性,使开发人员能够编写高性能、高抽象和安全的代码。 这是我用rust开发的第一个工作,希望…...

搭建一个定制版New Bing吧
项目介绍 项目地址:https://github.com/adams549659584/go-proxy-bingai 引用项目简介:用 Vue3 和 Go 搭建的微软 New Bing 演示站点,拥有一致的 UI 体验,支持 ChatGPT 提示词,国内可用,国内可用ÿ…...

联邦学习与RAG融合:构建隐私保护的分布式智能问答系统
1. 项目概述:当联邦学习遇上检索增强生成最近在折腾一个挺有意思的开源项目,叫fed-rag,来自 Vector Institute。光看名字,老司机们大概就能猜出个七七八八了:这玩意儿是把联邦学习和检索增强生成给揉到一块儿去了。我花…...

终极指南:如何一键下载网易云音乐无损FLAC格式歌曲
终极指南:如何一键下载网易云音乐无损FLAC格式歌曲 【免费下载链接】NeteaseCloudMusicFlac 根据网易云音乐的歌单, 下载flac无损音乐到本地.。 项目地址: https://gitcode.com/gh_mirrors/nete/NeteaseCloudMusicFlac 你是否曾为无法下载网易云音乐的无损音…...

中文知识管理利器:本地化部署与向量检索实践指南
1. 项目概述:一个面向中文用户的知识管理利器 最近在折腾个人知识库,发现了一个挺有意思的开源项目,叫 RomeoSY/zh-knowledge-manager 。乍一看名字,你可能觉得这又是一个“知识管理”工具,市面上不是有 Notion、Ob…...

Python调用Claude API实战:非官方库集成与自动化应用指南
1. 项目概述与核心价值 最近在尝试构建一些智能化的个人工作流时,我遇到了一个痛点:如何将 Anthropic 公司强大的 Claude 模型,像使用 OpenAI 的 GPT 模型那样,方便地集成到自己的脚本、应用或者自动化工具里。OpenAI 的 API 封装…...

多层板钻靶精度为什么越来越难控制?一套X-RAY预对位+六轴机械手的自动化方案解析
背景在高多层板和HDI板生产中,钻靶精度是影响良率的核心环节之一。压合后内层靶点被外层铜箔覆盖,传统视觉系统只能识别表面标记,无法获取真实的内层位置数据。同时,上料对位若依赖人工操作,放板角度和位置存在批次差异…...
)
Python爬虫实战:用urllib和正则搞定E-Hentai图片批量下载(附完整代码与避坑指南)
Python高效爬虫实战:多线程下载与智能错误处理 引言 在当今数据驱动的时代,网络爬虫已成为获取互联网信息的重要工具。对于开发者而言,掌握高效的爬虫技术不仅能提升工作效率,还能解决许多实际业务场景中的数据采集需求。本文将深…...

语言启蒙到底要不要背单词
语言启蒙阶段到底要不要背单词?我更愿意把这个问题换一种问法:这些词是不是能和声音、图像、语境连起来,并且隔几天还能回来一次。 如果只是拿一张词表硬记,入门用户很容易觉得枯燥。可如果完全不接触词汇,后面的听读…...

【收藏】2026测试人必看!再不学大模型AI,真的要被行业淘汰了
最近和身边做测试的朋友闲聊,发现大家的焦虑感比往年更重了——有人做了3年功能测试,跳槽面试连初筛都过不了;有人深耕性能测试5年,薪资原地踏步,反而被刚入行、懂AI测试的新人弯道超车。 从ChatGPT横空出世引爆AI行业…...

AI技能统一管理:用Obsidian插件Agentfiles构建你的智能编码中枢
1. 项目概述:一个为AI编码时代打造的技能中枢 如果你和我一样,日常开发工作流里已经塞满了各种AI编码助手——Claude Code、Cursor、Codex、Windsurf……那么你一定也面临过同样的困境:每个工具都有自己的一套“技能”或“记忆”系统…...

AI赋能二进制安全:BinAIVulHunter项目实战与逆向工程集成
1. 项目概述与核心价值最近在安全圈里,一个名为BinAIVulHunter的开源项目引起了我的注意。这个项目名直译过来就是“二进制AI漏洞猎人”,光看名字就能猜到它的核心玩法:利用人工智能技术,来自动化分析二进制文件,挖掘其…...