SVR(支持向量机)用法介绍
一、SVR回归介绍
SVR(Support Vector Regression)是支持向量机(SVM)在回归问题中的应用。与SVM分类模型相似,SVR也是一种非概率性算法,通过使用核函数将数据映射到高维空间,并在该空间上寻找最优的超平面与训练数据之间的间隔最大化,得到了回归模型。
与传统回归模型不同,SVR将回归问题转化为寻找一个函数逼近真实函数的过程。在实际应用中,可以使用不同的核函数和超参数来调整模型,以得到更好的拟合效果。
二、SVR回归模型建立
建立SVR回归模型的基本步骤如下:
1.数据预处理
SVR回归模型对数据的要求比较高,需要对数据进行预处理。首先需要对数据进行标准化处理,使其均值为0,方差为1。其次需要将数据进行归一化处理,将数据缩放到[0,1]范围内,以免特征之间的数据差异影响模型训练效果。
X_train = StandardScaler().fit_transform(X_train)
y_train = np.log1p(y_train) # 取对数归一化,提高拟合效果
2.模型训练
可以使用sklearn库中的SVR类来训练模型,其中需要指定核函数和超参数,例如:
clf = SVR(kernel='rbf', C=1, gamma=0.1, epsilon=0.1)
clf.fit(X_train, y_train)
其中,kernel参数是核函数类型,C是正则化参数,gamma是rbf核函数的带宽参数,epsilon是误差容忍度参数。
3.模型评估
可以使用sklearn库中的mean_squared_error函数来计算模型的均方误差(MSE),评估模型的拟合效果,例如:
y_pred = clf.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
可以将mse与均值和标准差进行比较,以评估模型的拟合效果。
三、SVR回归模型调参
在SVR回归中,调参是一个非常重要的过程。常用的调参方法主要有网格搜索法和随机搜索法两种。
1.网格搜索法
网格搜索法通过遍历超参数的所有可能取值,从中选取最佳超参数的组合以获得最优的模型。可以使用sklearn库中的GridSearchCV类来进行网格搜索。
例如,可以定义参数网格,指定不同核函数、C和gamma值,以进行模型训练和评估:
param_grid = {'kernel': ['rbf'], 'C': [0.1, 1, 10], 'gamma': [0.1, 0.01, 0.001]}
grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='neg_mean_squared_error')
grid_search.fit(X_train, y_train)
2.随机搜索法
与网格搜索法不同,随机搜索法是按照概率分布从指定的超参数空间中采样,从而更快地找到最优的超参数组合。可以使用sklearn库中的RandomizedSearchCV类来进行随机搜索。
例如,可以定义超参数分布,指定不同核函数、C和gamma的取值分布,以进行模型训练和评估:
param_distribs = {'kernel': ['rbf'], 'C': reciprocal(20, 200000), 'gamma': expon(scale=1.0)}
rnd_search = RandomizedSearchCV(clf, param_distributions=param_distribs, n_iter=50, cv=5, scoring='neg_mean_squared_error')
rnd_search.fit(X_train, y_train)
四、SVR回归实战应用
SVR回归可以在多个领域中进行应用,例如股票预测、房价预测、人物关系预测等领域。下面以一个简单的房价预测为例,介绍SVR回归的实际应用。
1.数据收集和处理
首先需要收集房屋样本数据,包括房屋面积、房间数、卫生间数、厨房数、地理位置等。对数据进行预处理,包括特征缩放、标准化和分类编码等。
2.模型训练和调参
可以使用sklearn库中的SVR类来训练模型,并使用网格搜索法或随机搜索法调整超参数,以获得最佳的拟合效果。
param_grid = {'kernel': ['rbf'], 'C': [0.1, 1, 10], 'gamma': [0.1, 0.01, 0.001]}
grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='neg_mean_squared_error')
grid_search.fit(X_train, y_train)
3.模型测试和性能评估
使用测试数据对模型进行测试,并使用均方误差(MSE)、R方值等指标来评估模型的性能。可以使用sklearn库中的mean_squared_error和r2_score函数来进行评估:
y_pred = clf.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
五、SVR回归小结
本文从SVR回归的介绍、模型建立、调参和实战应用等方面进行了阐述。SVR回归是一种非常有用的回归模型,在多个领域中具有广泛的应用。
相关文章:
用法介绍)
SVR(支持向量机)用法介绍
一、SVR回归介绍 SVR(Support Vector Regression)是支持向量机(SVM)在回归问题中的应用。与SVM分类模型相似,SVR也是一种非概率性算法,通过使用核函数将数据映射到高维空间,并在该空间上寻找最优的超平面与训练数据之间的间隔最大化…...

是面试官放水,还是公司实在是太缺人?这都没挂,腾讯原来这么容易进···
本人211非科班,之前在字节和腾讯实习过,这次其实没抱着什么特别大的希望投递,没想到腾讯可以再给我一次机会,还是挺开心的。 本来以为有个机会就不错啦!没想到能成功上岸,在这里要特别感谢帮我内推的同学&…...
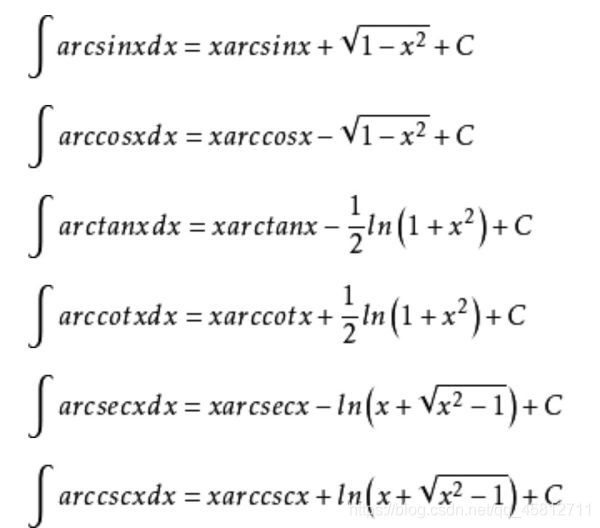
算法模板(5):数学(1):数学知识(1)
数论 整数的整除性 [x]表示不超过x的最大整数,叫做取整函数或高斯函数。设整数a,b不同时为零,则存在一对整数m,n,使得 ( a , b ) a m b n (a, b) am bn (a,b)ambn。注:a和b的最大公因数会写成 (a, b)…...
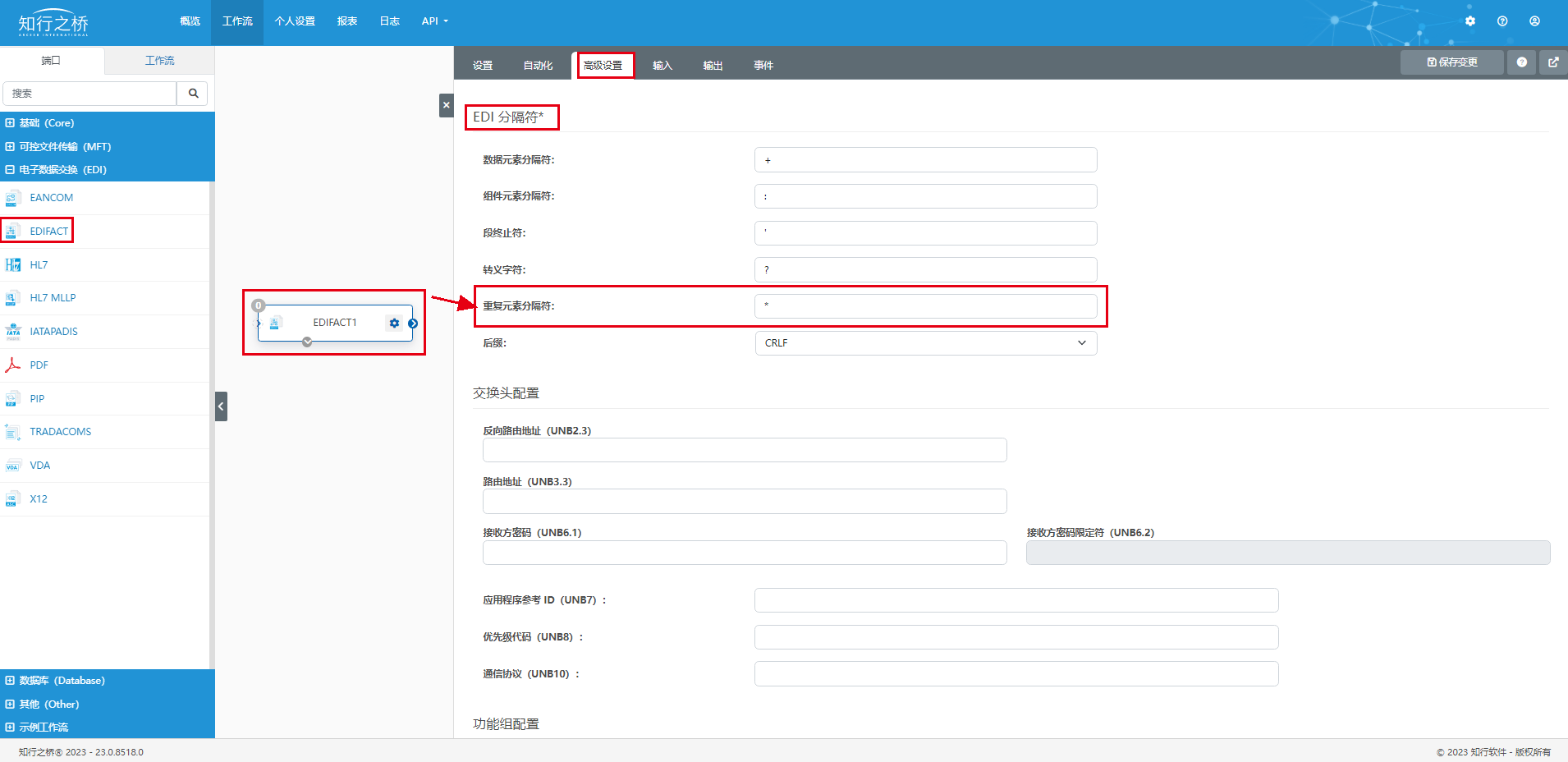
电子行业 K 公司对接 Nexperia EDI 项目案例
项目背景 Nexperia 是一家全球领先的半导体制造商,专注于提供高性能、高可靠性和创新性的半导体解决方案。公司成立于2017年,是前飞思卡尔半导体业务的一部分,并在全球范围内拥有多个设计、研发和生产基地。 Nexperia 使用 EDI(…...

chatgpt赋能python:Python如何将英文转化为中文的最佳方法
Python如何将英文转化为中文的最佳方法 介绍 在现代全球化社会中,国与国之间的交流越来越频繁,相应的语言翻译工具的需求也愈发迫切。Python是一种易于学习、快速上手的编程语言,适合初学者和经验丰富的程序员使用,在语言翻译方…...
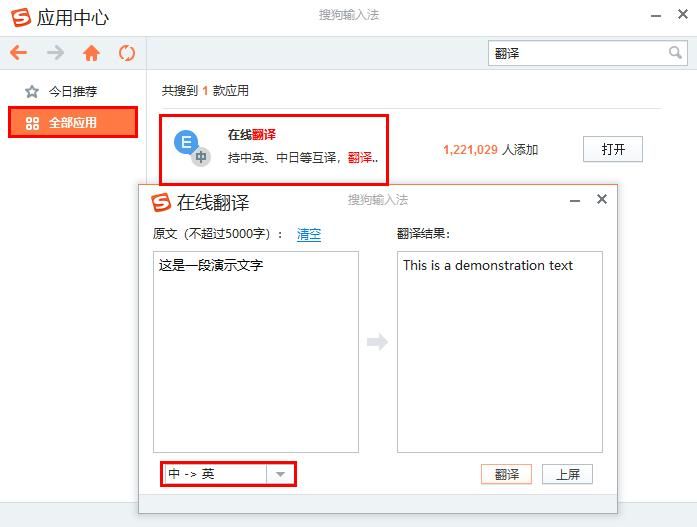
知道这些英文文档翻译的方式吗
在工作中,大家有没有遇到领导交给你一份外语的文档,要你去观看和理解,但是我们看不太懂或者没啥时间去一点点翻译怎么办呢?我们就需要有工具来将文档翻译,它是一项非常实用和便捷的功能,它可以将文档中的文…...
供应链安全
供应链安全 目录 文章目录 供应链安全目录本节实战可信任软件供应链概述构建镜像Dockerfile文件优化镜像漏洞扫描工具:Trivy检查YAML文件安全配置:kubesec准入控制器: Admission Webhook准入控制器: ImagePolicyWebhook关于我最后…...

华硕天选4原装Windows11系统带ASUSRECOVERY恢复工厂模式安装
华硕工厂恢复系统 ,安装结束后带隐藏分区以及机器所有驱动软件,奥创Myasus Recovery 文件地址https://pan.baidu.com/s/1Pq09oDzmFI6hXVdf8Vqjqw?pwd3fs8 提取码:3fs8 文件格式:5个底包(HDI KIT COM MCAFEE EDN) 1个引导工具TLK 支持ASUSRECOVERY型…...
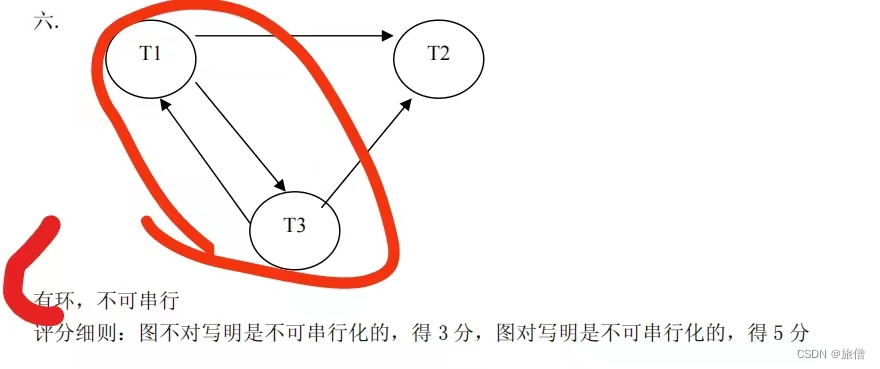
数据库期末复习(8)并发控制
笔记 数据库DBMS并发控制(1)_旅僧的博客-CSDN博客 数据库 并发控制(2)死锁和意向锁_旅僧的博客-CSDN博客 同一个对象不能既有slock又有xlock; 冲突可串行化和锁 怎么判断是否可以进行冲突可串行化:简便的方法是优先图 只有不同对象和同一对象都是读才不能发生非串行化调…...
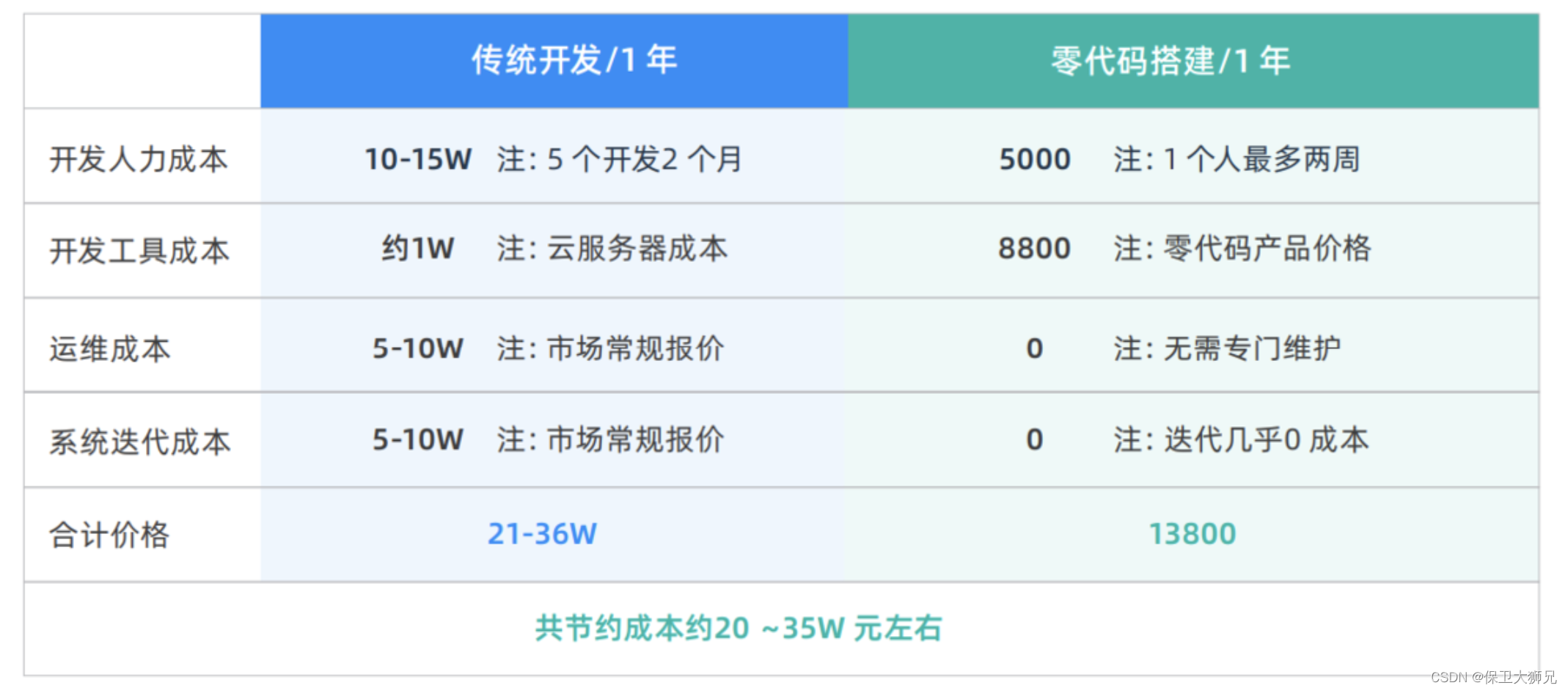
一文说透:低代码开发平台和零代码平台区别是什么?
低代码开发平台和零代码平台区别是什么? 一个简单的例子就可以解释清楚。 假设你想入住一套新房,回看住房变迁史: 最原始方式是:自己建造往后一点,交付“毛坯房”:开发商统一建小区,不需要自…...

4.将图神经网络应用于大规模图数据(Cluster-GCN)
到目前为止,我们已经为节点分类任务单独以全批方式训练了图神经网络。特别是,这意味着每个节点的隐藏表示都是并行计算的,并且可以在下一层中重复使用。 然而,一旦我们想在更大的图上操作,由于内存消耗爆炸,…...

pymongo更新数据
使用 PyMongo,可以通过以下步骤将查询到的记录进行更新: 下面是一个简单的示例代码片段,展示如何向名为users的集合中的所有文档添加一个新字段age。 import pymongo # 连接 MongoDB client pymongo.MongoClient("mongodb://localh…...
)
手机软件测试规范(含具体用例)
菜单基本功能测试规范一、短消息功能测试规范测试选项操作方法观察与判断结果创建、编辑短消息并发送书写短消息1、分别使用菜单或快捷方式进入书写短消息是否有异常; 2、输入0个字符,选择、输入号码发送,应成功; 3、输入1个中文…...

mysql having的用法
having的用法 having字句可以让我们筛选成组后的各种数据,where字句在聚合前先筛选记录,也就是说作用在group by和having字句前。而 having子句在聚合后对组记录进行筛选。我的理解就是真实表中没有此数据,这些数据是通过一些函数生存。 SQ…...
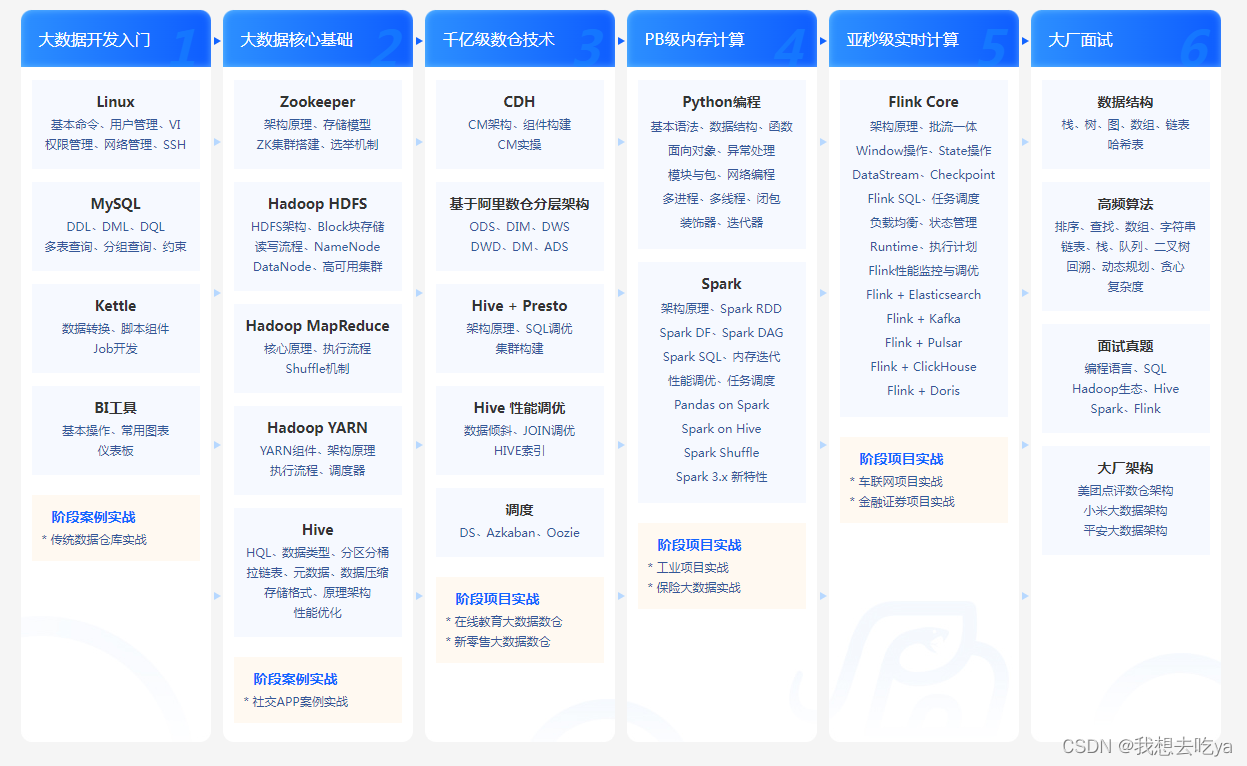
大数据需要学习哪些内容?
大数据技术的体系庞大且复杂,每年都会涌现出大量新的技术,目前大数据行业所涉及到的核心技术主要就是:数据采集、数据存储、数据清洗、数据查询分析和数据可视化。 Python 已成利器 在大数据领域中大放异彩 Python,成为职场人追求…...
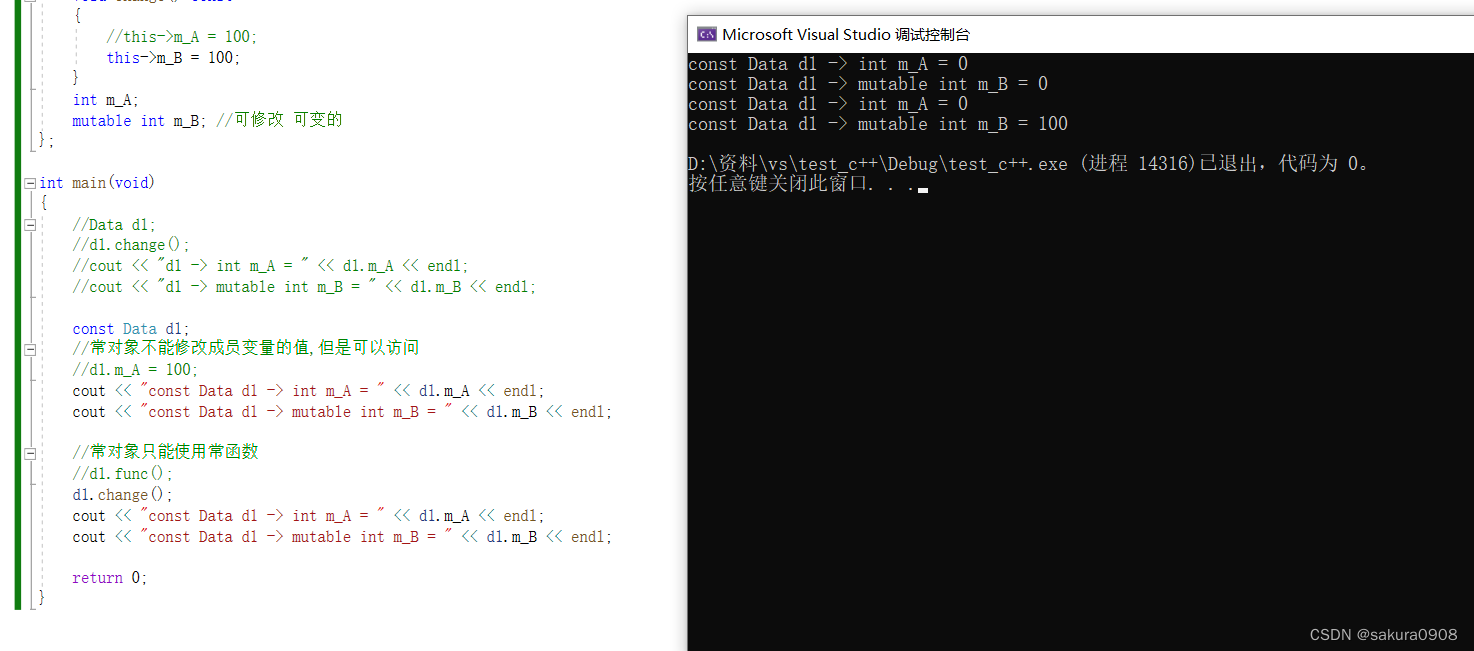
【c++】static和const修饰类的成员变量或成员函数
目录 1、静态成员变量 2、静态成员函数 3、常函数 4、常对象 当我们使用c的关键字static修饰类中的成员变量和成员函数的时候,此时的成员变量和成员函数被称为静态成员。 静态成员包含: 静态成员变量静态成员函数 1、静态成员变量 静态成员变量有…...
DVWA-9.Weak Session IDs
大约 了解会话 ID 通常是在登录后以特定用户身份访问站点所需的唯一内容,如果能够计算或轻松猜测该会话 ID,则攻击者将有一种简单的方法来访问用户帐户,而无需暴力破解密码或查找其他漏洞,例如跨站点脚本。 目的 该模块使用四种…...
Bug序列——容器内给/root目录777权限后无法使用ssh免密登录
Linux——创建容器并将本地调试完全的前后端分离项目打包上传docker运行_北岭山脚鼠鼠的博客-CSDN博客 接着上一篇文章结尾出现403错误时通过赋予/root目录以777权限解决403错误。 chmod 777 /root 现在又出现新的问题,远程ssh无法免密登录了,即使通过…...

华为OD机试真题 JavaScript 实现【服务中心选址】【2023Q1 100分 】
一、题目描述 一个快递公司希望在一条街道建立新的服务中心。公司统计了该街道中所有区域在地图上的位置,并希望能够以此为依据为新的服务中心选址,使服务中心到所有区域的距离的总和最小。 给你一个数组 positions,其中 positions[i] [le…...

<Linux>《OpenSSH 客户端配置文件ssh_config详解》
《OpenSSH 客户端配置文件ssh_config详解》 1、 ssh获取配置数据顺序2、关键字2.1 Host2.2 Match2.3 AddKeysToAgent2.4 AddressFamily2.5 BatchMode2.6 BindAddress2.7 BindInterface2.8 CanonicalDomains2.9 CanonicalizeFallbackLocal2.10 CanonicalizeHostname2.11 Canonic…...

别再死记硬背了!用这5个真实数据处理场景,彻底搞懂Python列表、字典和集合
别再死记硬背了!用这5个真实数据处理场景,彻底搞懂Python列表、字典和集合 当你第一次学习Python时,列表、字典和集合可能只是教科书上的几个定义。但真正掌握它们的关键,在于理解如何将这些数据结构转化为解决实际问题的工具。本…...

DreamBooth实战案例:从人物肖像到艺术风格的完整训练过程
DreamBooth实战案例:从人物肖像到艺术风格的完整训练过程 【免费下载链接】sd_dreambooth_extension 项目地址: https://gitcode.com/gh_mirrors/sd/sd_dreambooth_extension DreamBooth是一款强大的AI模型训练工具,能够让你通过少量图片快速定制…...

Azure OpenAI代理:无缝迁移OpenAI应用到Azure云服务
1. 项目概述如果你正在使用或开发基于OpenAI官方API的应用,比如各种ChatGPT Web UI、LangChain应用,但同时又想利用微软Azure OpenAI Service在合规性、稳定性、网络延迟或成本控制上的优势,那么你大概率会遇到一个头疼的问题:这两…...

高校vs中小学气象站:核心区别
绝大多数普通校园气象站仅适合中小学可视化科普展示,数据精度低、无原始数据导出、无开放接口、参数单一,完全无法满足高校教学科研需求。中小学设备:侧重外观展示、简单数据观看、趣味科普,精度普通、数据封闭、无科研溯源能力&a…...

NHSE:5分钟掌握动物森友会存档编辑,打造你的完美岛屿
NHSE:5分钟掌握动物森友会存档编辑,打造你的完美岛屿 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 你是否曾经为了收集某个稀有家具而花费数周时间?是否因为地…...

终极指南:在Windows上无需模拟器安装安卓应用的完整教程
终极指南:在Windows上无需模拟器安装安卓应用的完整教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为安卓模拟器的臃肿和卡顿烦恼吗?今…...

Keep架构深度解析:企业级AIOps告警管理平台的设计与实践
Keep架构深度解析:企业级AIOps告警管理平台的设计与实践 【免费下载链接】keep The open-source AIOps and alert management platform 项目地址: https://gitcode.com/GitHub_Trending/kee/keep Keep作为开源AIOps告警管理平台,采用现代化的微服…...

在Windows上直接安装Android应用:APK安装器的三大优势与完整使用指南
在Windows上直接安装Android应用:APK安装器的三大优势与完整使用指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经希望在Windows电脑上直接运…...

如何快速集成Prometheus和Jaeger:Echo框架第三方中间件终极指南
如何快速集成Prometheus和Jaeger:Echo框架第三方中间件终极指南 【免费下载链接】echo High performance, minimalist Go web framework 项目地址: https://gitcode.com/gh_mirrors/ec/echo Echo是一个高性能、极简的Go Web框架,为开发者提供了轻…...

Google Meet开启Gemini字幕后CPU飙升300%?资深SRE教你用Chrome Tracing+Gemini Profiling Dashboard精准定位瓶颈
更多请点击: https://intelliparadigm.com 第一章:Google Meet开启Gemini字幕后CPU飙升300%?资深SRE教你用Chrome TracingGemini Profiling Dashboard精准定位瓶颈 当团队在Google Meet中启用Gemini实时字幕功能后,参会终端Chrom…...