医学图象分割常用损失函数(附Pytorch和Keras代码)
对损失函数没有太大的了解,就是知道它很重要,搜集了一些常用的医学图象分割损失函数,学习一下!
医学图象分割常见损失函数
- 前言
- 1 Dice Loss
- 2 BCE-Dice Loss
- 3 Jaccard/Intersection over Union (IoU) Loss
- 4 Focal Loss
- 5 Tvesky Loss
- 6 Focal Tvesky Loss
- 7 Lovasz Hinge Loss
- 8 Combo Loss
- 9 参考资料
前言
分割损失函数大致分为四类,分别是基于分布的损失函数,符合损失函数,基于区域的损失函数以及基于边界的损失函数!
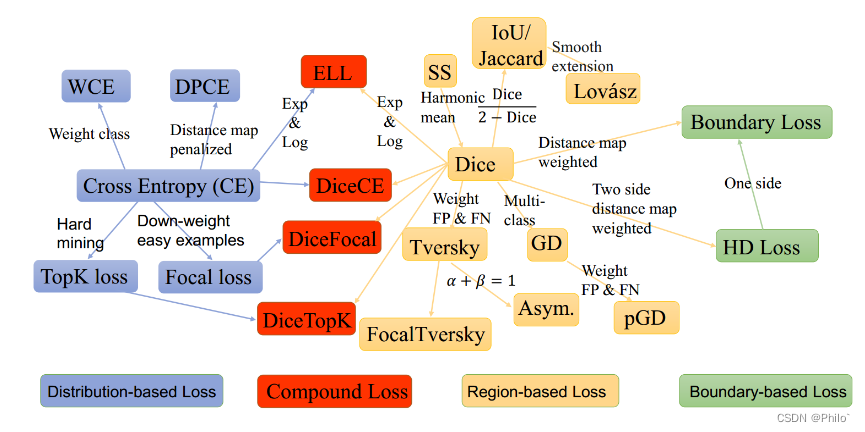
因为有些是评价指标作为损失函数的,因此在反向传播时候,为了使得损失函数趋向为0,需要对类似的损失函数进行1-loss操作!
1 Dice Loss
Dice 系数是像素分割的常用的评价指标,也可以修改为损失函数:
公式:
Dice=2∣X∩Y∣∣X∣+∣Y∣Dice=\frac{2|X \cap Y|}{|X|+|Y|} Dice=∣X∣+∣Y∣2∣X∩Y∣
其中X为实际区域,Y为预测区域
Pytorch代码:
import numpy
import torch
import torch.nn as nn
import torch.nn.functional as Fclass DiceLoss(nn.Module):def __init__(self, weight=None, size_average=True):super(DiceLoss, self).__init__()def forward(self, inputs, targets, smooth=1):#comment out if your model contains a sigmoid or equivalent activation layerinputs = F.sigmoid(inputs) #flatten label and prediction tensorsinputs = inputs.view(-1)targets = targets.view(-1)intersection = (inputs * targets).sum() dice = (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth) return 1 - dice
测试:
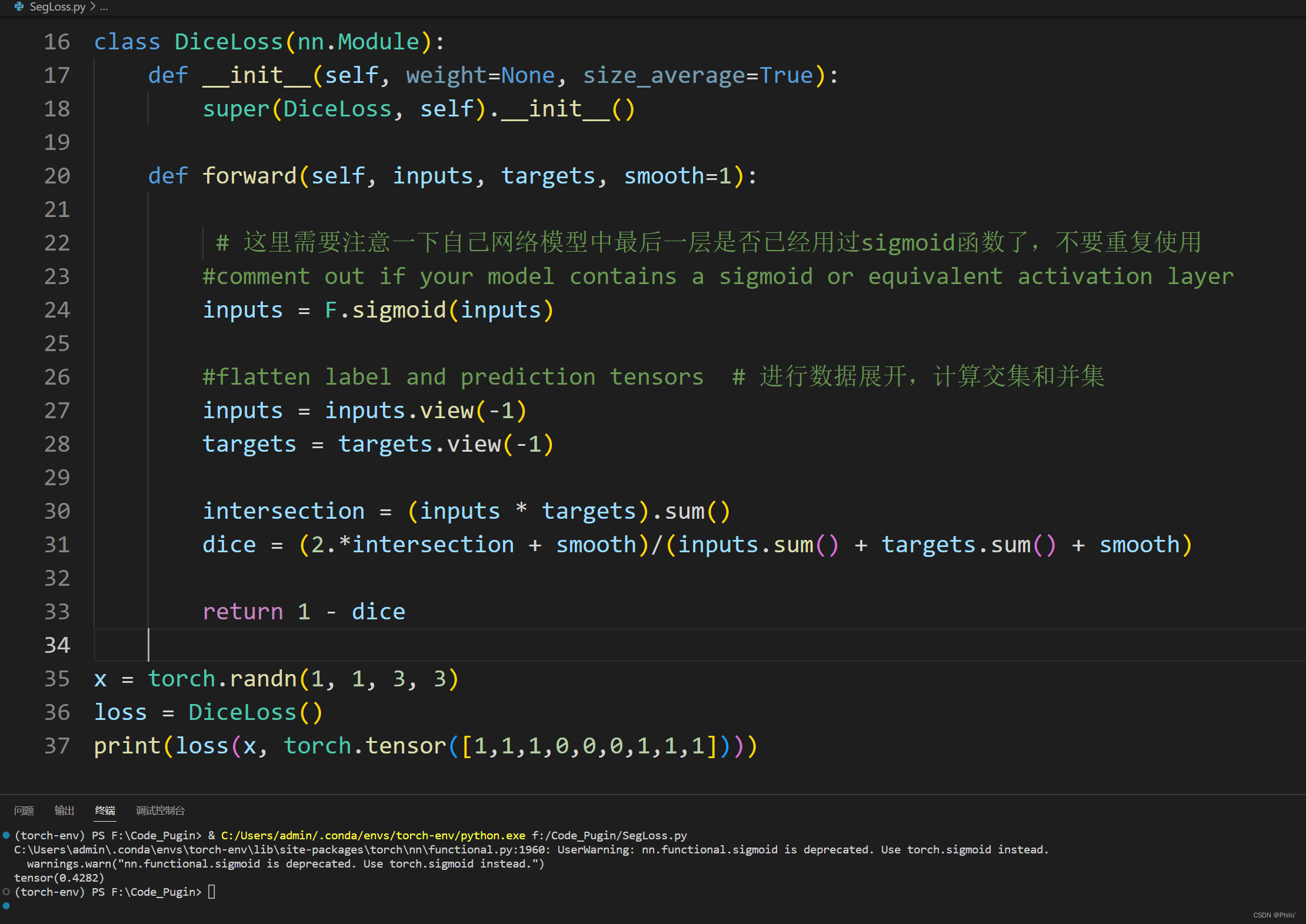
Keras代码:
import keras
import keras.backend as Kdef DiceLoss(targets, inputs, smooth=1e-6):#flatten label and prediction tensorsinputs = K.flatten(inputs)targets = K.flatten(targets)intersection = K.sum(K.dot(targets, inputs))dice = (2*intersection + smooth) / (K.sum(targets) + K.sum(inputs) + smooth)return 1 - dice
2 BCE-Dice Loss
这种损失结合了 Dice 损失和标准二元交叉熵 (BCE) 损失,后者通常是分割模型的默认值。将这两种方法结合起来可以使损失具有一定的多样性,同时受益于 BCE 的稳定性。
公式:
Dice+BCE=2∣X∩Y∣∣X∣+∣Y∣+1N∑n=1NH(pn,qn)Dice + BCE=\frac{2|X \cap Y|}{|X|+|Y|} + \frac{1}{N}\sum_{n=1}^{N}{H(p_n,q_n)} Dice+BCE=∣X∣+∣Y∣2∣X∩Y∣+N1n=1∑NH(pn,qn)
Pytorch代码:
class DiceBCELoss(nn.Module):def __init__(self, weight=None, size_average=True):super(DiceBCELoss, self).__init__()def forward(self, inputs, targets, smooth=1):#comment out if your model contains a sigmoid or equivalent activation layerinputs = F.sigmoid(inputs) #flatten label and prediction tensorsinputs = inputs.view(-1)targets = targets.view(-1)intersection = (inputs * targets).sum() dice_loss = 1 - (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth) # 注意这里已经使用1-dice BCE = F.binary_cross_entropy(inputs, targets, reduction='mean')Dice_BCE = BCE + dice_lossreturn Dice_BCE
Keras代码:
def DiceBCELoss(targets, inputs, smooth=1e-6): #flatten label and prediction tensorsinputs = K.flatten(inputs)targets = K.flatten(targets)BCE = binary_crossentropy(targets, inputs)intersection = K.sum(K.dot(targets, inputs)) dice_loss = 1 - (2*intersection + smooth) / (K.sum(targets) + K.sum(inputs) + smooth)Dice_BCE = BCE + dice_lossreturn Dice_BCE
3 Jaccard/Intersection over Union (IoU) Loss
IoU 指标,或 Jaccard 指数,类似于 Dice 指标,计算为两个集合之间正实例的重叠与其相互组合值之间的比率;与 Dice 指标一样,它是评估像素分割模型的性能。
公式:
J(A,B)=∣A∩B∣∣A∪B∣=∣A∩B∣∣A∣+∣B∣−∣A∩B∣J(A,B)=\frac{|A \cap B|}{|A \cup B|} = \frac{|A \cap B|}{|A| + |B|-|A\cap B|} J(A,B)=∣A∪B∣∣A∩B∣=∣A∣+∣B∣−∣A∩B∣∣A∩B∣
其中A为实际分割区域,B为预测的分割区域
Pytorch代码:
class IoULoss(nn.Module):def __init__(self, weight=None, size_average=True):super(IoULoss, self).__init__()def forward(self, inputs, targets, smooth=1):#comment out if your model contains a sigmoid or equivalent activation layerinputs = F.sigmoid(inputs) #flatten label and prediction tensorsinputs = inputs.view(-1)targets = targets.view(-1)#intersection is equivalent to True Positive count#union is the mutually inclusive area of all labels & predictions intersection = (inputs * targets).sum()total = (inputs + targets).sum()union = total - intersection IoU = (intersection + smooth)/(union + smooth)return 1 - IoU
Keras代码:
def IoULoss(targets, inputs, smooth=1e-6):#flatten label and prediction tensorsinputs = K.flatten(inputs)targets = K.flatten(targets)intersection = K.sum(K.dot(targets, inputs))total = K.sum(targets) + K.sum(inputs)union = total - intersectionIoU = (intersection + smooth) / (union + smooth)return 1 - IoU
4 Focal Loss
Focal损失函数是由Facebook AI Research的Lin等人在2017年提出的,作为一种对抗极端不平衡数据集的手段。
公式:
见文章:Focal Loss for Dense Object Detection
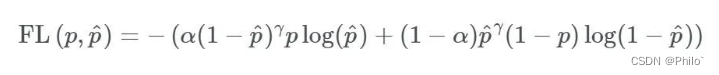
Pytorch代码:
class FocalLoss(nn.Module):def __init__(self, weight=None, size_average=True):super(FocalLoss, self).__init__()def forward(self, inputs, targets, alpha=0.8, gamma=2, smooth=1):#comment out if your model contains a sigmoid or equivalent activation layerinputs = F.sigmoid(inputs) #flatten label and prediction tensorsinputs = inputs.view(-1)targets = targets.view(-1)#first compute binary cross-entropy BCE = F.binary_cross_entropy(inputs, targets, reduction='mean')BCE_EXP = torch.exp(-BCE)focal_loss = alpha * (1-BCE_EXP)**gamma * BCEreturn focal_loss
Keras代码:
def FocalLoss(targets, inputs, alpha=0.8, gamma=2): inputs = K.flatten(inputs)targets = K.flatten(targets)BCE = K.binary_crossentropy(targets, inputs)BCE_EXP = K.exp(-BCE)focal_loss = K.mean(alpha * K.pow((1-BCE_EXP), gamma) * BCE)return focal_loss
5 Tvesky Loss
公式:
见文章:Tversky loss function for image segmentation using 3D fully convolutional deep networks
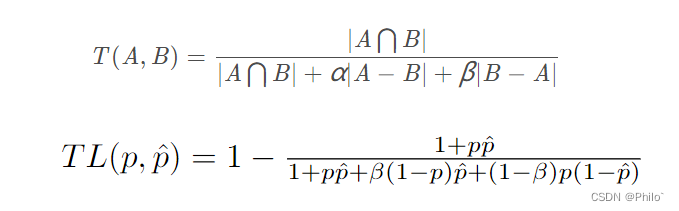
通过公式可以看出,其就是针对不同的指标进行加权,文章中指出,当a = b = 0.5, 就是Dice系数,当a = b = 1,就是Iou系数
Pytorch代码:
class TverskyLoss(nn.Module):def __init__(self, weight=None, size_average=True):super(TverskyLoss, self).__init__()def forward(self, inputs, targets, smooth=1, alpha=0.5, beta=0.5):#comment out if your model contains a sigmoid or equivalent activation layerinputs = F.sigmoid(inputs) #flatten label and prediction tensorsinputs = inputs.view(-1)targets = targets.view(-1)#True Positives, False Positives & False NegativesTP = (inputs * targets).sum() FP = ((1-targets) * inputs).sum()FN = (targets * (1-inputs)).sum()Tversky = (TP + smooth) / (TP + alpha*FP + beta*FN + smooth) return 1 - Tversky
Keras代码:
def TverskyLoss(targets, inputs, alpha=0.5, beta=0.5, smooth=1e-6):#flatten label and prediction tensorsinputs = K.flatten(inputs)targets = K.flatten(targets)#True Positives, False Positives & False NegativesTP = K.sum((inputs * targets))FP = K.sum(((1-targets) * inputs))FN = K.sum((targets * (1-inputs)))Tversky = (TP + smooth) / (TP + alpha*FP + beta*FN + smooth) return 1 - Tversky
6 Focal Tvesky Loss
就是将Focal Loss集成到Tvesky中
公式:
FocalTversky=(1−Tversky)αFocalTversky = (1-Tversky)^{\alpha } FocalTversky=(1−Tversky)α
Pytorch代码:
class FocalTverskyLoss(nn.Module):def __init__(self, weight=None, size_average=True):super(FocalTverskyLoss, self).__init__()def forward(self, inputs, targets, smooth=1, alpha=0.5, beta=0.5, gamma=2):#comment out if your model contains a sigmoid or equivalent activation layerinputs = F.sigmoid(inputs) #flatten label and prediction tensorsinputs = inputs.view(-1)targets = targets.view(-1)#True Positives, False Positives & False NegativesTP = (inputs * targets).sum() FP = ((1-targets) * inputs).sum()FN = (targets * (1-inputs)).sum()Tversky = (TP + smooth) / (TP + alpha*FP + beta*FN + smooth) FocalTversky = (1 - Tversky)**gammareturn FocalTversky
Keras代码:
def FocalTverskyLoss(targets, inputs, alpha=0.5, beta=0.5, gamma=2, smooth=1e-6):#flatten label and prediction tensorsinputs = K.flatten(inputs)targets = K.flatten(targets)#True Positives, False Positives & False NegativesTP = K.sum((inputs * targets))FP = K.sum(((1-targets) * inputs))FN = K.sum((targets * (1-inputs)))Tversky = (TP + smooth) / (TP + alpha*FP + beta*FN + smooth) FocalTversky = K.pow((1 - Tversky), gamma)return FocalTversky
7 Lovasz Hinge Loss
该损失函数是由Berman, Triki和Blaschko在他们的论文“The Lovasz-Softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks”中介绍的。
它被设计用于优化语义分割的交集优于联合分数,特别是对于多类实例。具体来说,它根据误差对预测进行排序,然后累积计算每个误差对IoU分数的影响。然后,这个梯度向量与初始误差向量相乘,以最强烈地惩罚降低IoU分数最多的预测。
代码连接::
Pytorch代码:https://github.com/bermanmaxim/LovaszSoftmax/blob/master/pytorch/lovasz_losses.py
"""
Lovasz-Softmax and Jaccard hinge loss in PyTorch
Maxim Berman 2018 ESAT-PSI KU Leuven (MIT License)
"""from __future__ import print_function, divisionimport torch
from torch.autograd import Variable
import torch.nn.functional as F
import numpy as np
try:from itertools import ifilterfalse
except ImportError: # py3kfrom itertools import filterfalse as ifilterfalsedef lovasz_grad(gt_sorted):"""Computes gradient of the Lovasz extension w.r.t sorted errorsSee Alg. 1 in paper"""p = len(gt_sorted)gts = gt_sorted.sum()intersection = gts - gt_sorted.float().cumsum(0)union = gts + (1 - gt_sorted).float().cumsum(0)jaccard = 1. - intersection / unionif p > 1: # cover 1-pixel casejaccard[1:p] = jaccard[1:p] - jaccard[0:-1]return jaccarddef iou_binary(preds, labels, EMPTY=1., ignore=None, per_image=True):"""IoU for foreground classbinary: 1 foreground, 0 background"""if not per_image:preds, labels = (preds,), (labels,)ious = []for pred, label in zip(preds, labels):intersection = ((label == 1) & (pred == 1)).sum()union = ((label == 1) | ((pred == 1) & (label != ignore))).sum()if not union:iou = EMPTYelse:iou = float(intersection) / float(union)ious.append(iou)iou = mean(ious) # mean accross images if per_imagereturn 100 * ioudef iou(preds, labels, C, EMPTY=1., ignore=None, per_image=False):"""Array of IoU for each (non ignored) class"""if not per_image:preds, labels = (preds,), (labels,)ious = []for pred, label in zip(preds, labels):iou = [] for i in range(C):if i != ignore: # The ignored label is sometimes among predicted classes (ENet - CityScapes)intersection = ((label == i) & (pred == i)).sum()union = ((label == i) | ((pred == i) & (label != ignore))).sum()if not union:iou.append(EMPTY)else:iou.append(float(intersection) / float(union))ious.append(iou)ious = [mean(iou) for iou in zip(*ious)] # mean accross images if per_imagereturn 100 * np.array(ious)# --------------------------- BINARY LOSSES ---------------------------def lovasz_hinge(logits, labels, per_image=True, ignore=None):"""Binary Lovasz hinge losslogits: [B, H, W] Variable, logits at each pixel (between -\infty and +\infty)labels: [B, H, W] Tensor, binary ground truth masks (0 or 1)per_image: compute the loss per image instead of per batchignore: void class id"""if per_image:loss = mean(lovasz_hinge_flat(*flatten_binary_scores(log.unsqueeze(0), lab.unsqueeze(0), ignore))for log, lab in zip(logits, labels))else:loss = lovasz_hinge_flat(*flatten_binary_scores(logits, labels, ignore))return lossdef lovasz_hinge_flat(logits, labels):"""Binary Lovasz hinge losslogits: [P] Variable, logits at each prediction (between -\infty and +\infty)labels: [P] Tensor, binary ground truth labels (0 or 1)ignore: label to ignore"""if len(labels) == 0:# only void pixels, the gradients should be 0return logits.sum() * 0.signs = 2. * labels.float() - 1.errors = (1. - logits * Variable(signs))errors_sorted, perm = torch.sort(errors, dim=0, descending=True)perm = perm.datagt_sorted = labels[perm]grad = lovasz_grad(gt_sorted)loss = torch.dot(F.relu(errors_sorted), Variable(grad))return lossdef flatten_binary_scores(scores, labels, ignore=None):"""Flattens predictions in the batch (binary case)Remove labels equal to 'ignore'"""scores = scores.view(-1)labels = labels.view(-1)if ignore is None:return scores, labelsvalid = (labels != ignore)vscores = scores[valid]vlabels = labels[valid]return vscores, vlabelsclass StableBCELoss(torch.nn.modules.Module):def __init__(self):super(StableBCELoss, self).__init__()def forward(self, input, target):neg_abs = - input.abs()loss = input.clamp(min=0) - input * target + (1 + neg_abs.exp()).log()return loss.mean()def binary_xloss(logits, labels, ignore=None):"""Binary Cross entropy losslogits: [B, H, W] Variable, logits at each pixel (between -\infty and +\infty)labels: [B, H, W] Tensor, binary ground truth masks (0 or 1)ignore: void class id"""logits, labels = flatten_binary_scores(logits, labels, ignore)loss = StableBCELoss()(logits, Variable(labels.float()))return loss# --------------------------- MULTICLASS LOSSES ---------------------------def lovasz_softmax(probas, labels, classes='present', per_image=False, ignore=None):"""Multi-class Lovasz-Softmax lossprobas: [B, C, H, W] Variable, class probabilities at each prediction (between 0 and 1).Interpreted as binary (sigmoid) output with outputs of size [B, H, W].labels: [B, H, W] Tensor, ground truth labels (between 0 and C - 1)classes: 'all' for all, 'present' for classes present in labels, or a list of classes to average.per_image: compute the loss per image instead of per batchignore: void class labels"""if per_image:loss = mean(lovasz_softmax_flat(*flatten_probas(prob.unsqueeze(0), lab.unsqueeze(0), ignore), classes=classes)for prob, lab in zip(probas, labels))else:loss = lovasz_softmax_flat(*flatten_probas(probas, labels, ignore), classes=classes)return lossdef lovasz_softmax_flat(probas, labels, classes='present'):"""Multi-class Lovasz-Softmax lossprobas: [P, C] Variable, class probabilities at each prediction (between 0 and 1)labels: [P] Tensor, ground truth labels (between 0 and C - 1)classes: 'all' for all, 'present' for classes present in labels, or a list of classes to average."""if probas.numel() == 0:# only void pixels, the gradients should be 0return probas * 0.C = probas.size(1)losses = []class_to_sum = list(range(C)) if classes in ['all', 'present'] else classesfor c in class_to_sum:fg = (labels == c).float() # foreground for class cif (classes is 'present' and fg.sum() == 0):continueif C == 1:if len(classes) > 1:raise ValueError('Sigmoid output possible only with 1 class')class_pred = probas[:, 0]else:class_pred = probas[:, c]errors = (Variable(fg) - class_pred).abs()errors_sorted, perm = torch.sort(errors, 0, descending=True)perm = perm.datafg_sorted = fg[perm]losses.append(torch.dot(errors_sorted, Variable(lovasz_grad(fg_sorted))))return mean(losses)def flatten_probas(probas, labels, ignore=None):"""Flattens predictions in the batch"""if probas.dim() == 3:# assumes output of a sigmoid layerB, H, W = probas.size()probas = probas.view(B, 1, H, W)B, C, H, W = probas.size()probas = probas.permute(0, 2, 3, 1).contiguous().view(-1, C) # B * H * W, C = P, Clabels = labels.view(-1)if ignore is None:return probas, labelsvalid = (labels != ignore)vprobas = probas[valid.nonzero().squeeze()]vlabels = labels[valid]return vprobas, vlabelsdef xloss(logits, labels, ignore=None):"""Cross entropy loss"""return F.cross_entropy(logits, Variable(labels), ignore_index=255)# --------------------------- HELPER FUNCTIONS ---------------------------
def isnan(x):return x != xdef mean(l, ignore_nan=False, empty=0):"""nanmean compatible with generators."""l = iter(l)if ignore_nan:l = ifilterfalse(isnan, l)try:n = 1acc = next(l)except StopIteration:if empty == 'raise':raise ValueError('Empty mean')return emptyfor n, v in enumerate(l, 2):acc += vif n == 1:return accreturn acc / n
8 Combo Loss
该损失函数是由Taghanaki等人在他们的论文"Combo loss: Handling input and output imbalance in multi-organ segmentation"中介绍的。组合损失是Dice损失和一个修正的BCE函数的组合,像Tversky损失一样,有额外的常数,分别惩罚假阳性或假阴性。
下面这个代码可能有些问题!!
Pytorch代码:
import torch.nn as nn
import torch
ALPHA = 0.5 # < 0.5 penalises FP more, > 0.5 penalises FN more
CE_RATIO = 0.5 #weighted contribution of modified CE loss compared to Dice loss
BETA = 0.5
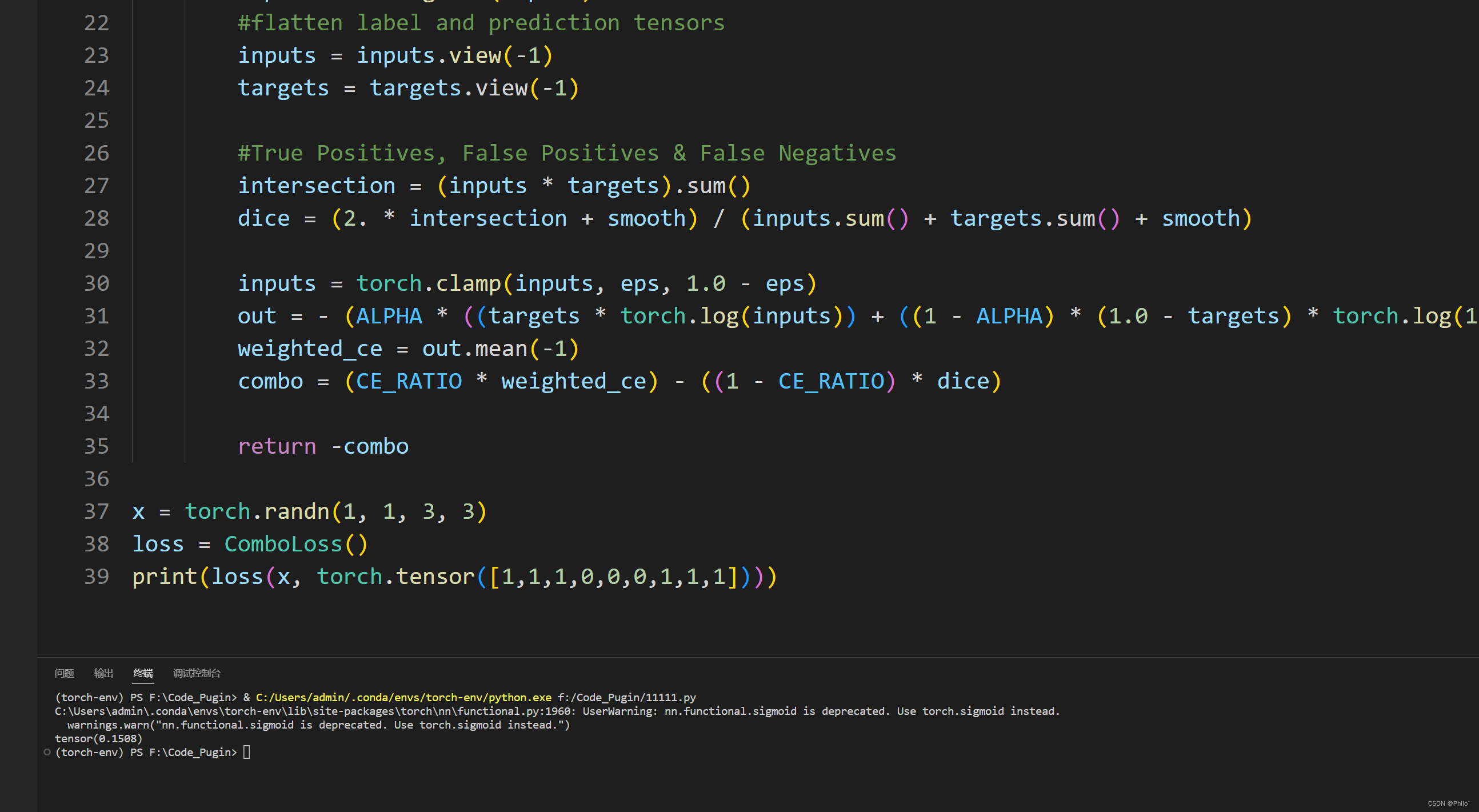
import torch.nn.functional as Fclass ComboLoss(nn.Module):def __init__(self, weight=None, size_average=True):super(ComboLoss, self).__init__()def forward(self, inputs, targets, smooth=1, alpha=ALPHA, beta=BETA, eps=1e-9):inputs = F.sigmoid(inputs)#flatten label and prediction tensorsinputs = inputs.view(-1)targets = targets.view(-1)#True Positives, False Positives & False Negativesintersection = (inputs * targets).sum() dice = (2. * intersection + smooth) / (inputs.sum() + targets.sum() + smooth)inputs = torch.clamp(inputs, eps, 1.0 - eps) out = - (ALPHA * ((targets * torch.log(inputs)) + ((1 - ALPHA) * (1.0 - targets) * torch.log(1.0 - inputs))))weighted_ce = out.mean(-1)combo = (CE_RATIO * weighted_ce) - ((1 - CE_RATIO) * dice)return -combo
结果:
9 参考资料
医学图象分割常见评价指标
SegLoss
Kaggle比较——SegLoss
相关文章:
医学图象分割常用损失函数(附Pytorch和Keras代码)
对损失函数没有太大的了解,就是知道它很重要,搜集了一些常用的医学图象分割损失函数,学习一下! 医学图象分割常见损失函数前言1 Dice Loss2 BCE-Dice Loss3 Jaccard/Intersection over Union (IoU) Loss4 Focal Loss5 Tvesky Loss…...
)
【新2023】华为OD机试 - 病菌感染(Python)
华为 OD 清单查看地址:blog.csdn.net/hihell/category_12199275.html 病菌感染 题目 在一个地图中(地图有N*N个区域组成) 有部分区域被感染病菌 感染区域每天都会把周围上下左右的四个区域感染 请根据给定的地图计算多少天以后全部区域都会被感染 如果初始地图上所有区域都…...
QGIS中进行批量坡向计算
QGIS中进行坡向计算1. 坡向计算中的Z因子(垂直单位与水平单位的比值)2. 坡向计算步骤坡度计算的姊妹篇–坡向计算来了 1. 坡向计算中的Z因子(垂直单位与水平单位的比值) z 因子是一个转换因子,当输入表面的垂直坐标&…...

Redis持久化机制
一、RDB RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。 RDB是Redis默认的持久化机制 - RDB持久化文件,速度比较快,而且存储的是一个二进制的文件,传输起来很方便。 - RD…...

2、VUE面试题
1, 如何让CSS只在当前组件中起作用?在组件中的style前面加上scoped2、<keep-alive></keep-alive>的作用是什么?keep-alive 是 Vue 内置的一个组件,可以使被包含的组件保留状态,或避免重新渲染。3, vue组件中如何获取dom元素?使…...

DeepSort:论文翻译
文章目录摘要1、简介2、利用深度关联度量进行排序2.1、轨迹处理和状态估计2.3、匹配的级联2.4、深度外观描述符3、实验4、结论论文链接:https://arxiv.org/pdf/1703.07402.pdf摘要 简单在线实时跟踪(SORT)是一种实用的多目标跟踪方法,专注于简单、有效的…...

Debezium系列之:重置Sqlserver数据库的LSN拉取历史数据
Debezium系列之:重置Sqlserver数据库的LSN拉取历史数据 一、需求背景二、理解LSN三、sqlserver offset数据样式四、写入历史LSN五、观察历史数据六、拉取最新数据一、需求背景 需要重新拉取sqlserver数据库采集表的历史数据或者connector故障,从指定LSN处拉取历史数据二、理解…...
)
一起Talk Android吧(第四百九十四回:在Android中使用MQTT通信四)
文章目录 问题概述解决办法经验总结各位看官们大家好,这一回中咱们说的例子是" 在Android中使用MQTT通信四",本章回内容与前后章节内容无关联。闲话休提,言归正转,让我们一起Talk Android吧! 问题概述 我们在很早之前介绍过MQTT的用法,本章回是在原来的基础上…...
【vcpkg】cpprestsdk之64位编译链接及踩坑
▒ 目录 ▒🛫 问题描述1️⃣ 多版本vs报错指定VS路径2️⃣ error LNK2001: 问题排查通过IDA打开lib文件,确认导出内容查看源码增加参数--editable,重新编译3️⃣ error LNK2001: 外部符号__imp_?close_...去除__imp_🛬 结论vcpkg…...
初始QML
Qt Quick的介绍 : Qt Quick是QML的标准类型和功能库。它包括视觉类型,交互类型,动画,模型和视图,粒子效果和着色器效果。QML 应用程序开发人员可以通过单个导入语句访问所有这些功能,简单来说Qt Quick是一…...

SpringAOP切面实例实现对数据过滤返回,SpringAOP切面实现对用户权限控制,通过@Around注解过滤修改方法返回值
文章目录需求内容:实现:步骤一:导入SpringAOP相关依赖pom.xml步骤二:自定义两个注解步骤三:需要用到的实体类**步骤四:切面具体实现**用法1.需要过滤返回值的方法添加注解FilterByUser2.数据Dto在需要过滤的字段添加Fi…...
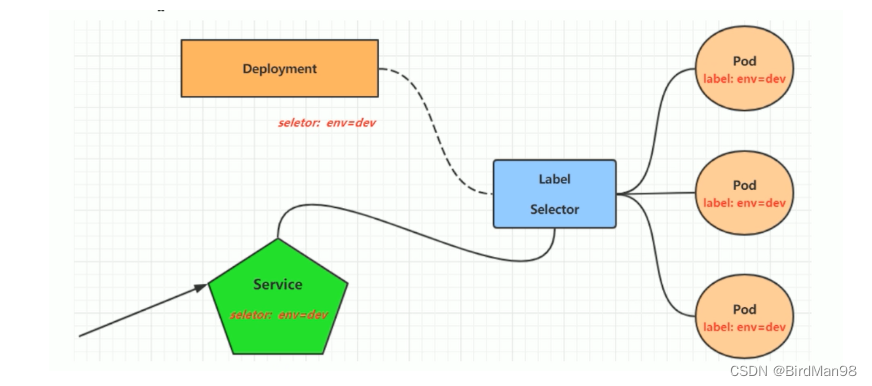
【Kubernetes】【九】Label,Deployment,Service
Label Label是kubernetes系统中的一个重要概念。它的作用就是在资源上添加标识,用来对它们进行区分和选择。 Label的特点: 一个Label会以key/value键值对的形式附加到各种对象上,如Node、Pod、Service等等一个资源对象可以定义任意数量的L…...
RuoYi-Vue部署(Nginx+Tomcat)
环境搭建RuoYi-Vue搭建、Linux安装Nginx、Linux安装JDK8、Linux安装MySql8、Linux安装Redis、Linux安装Tomcat9前端打包 1.ruoyi-ui鼠标右键-->打开于终端2.安装依赖:npm install --registryhttps://registry.npm.taobao.org-->node_modules3.编译打包&#x…...
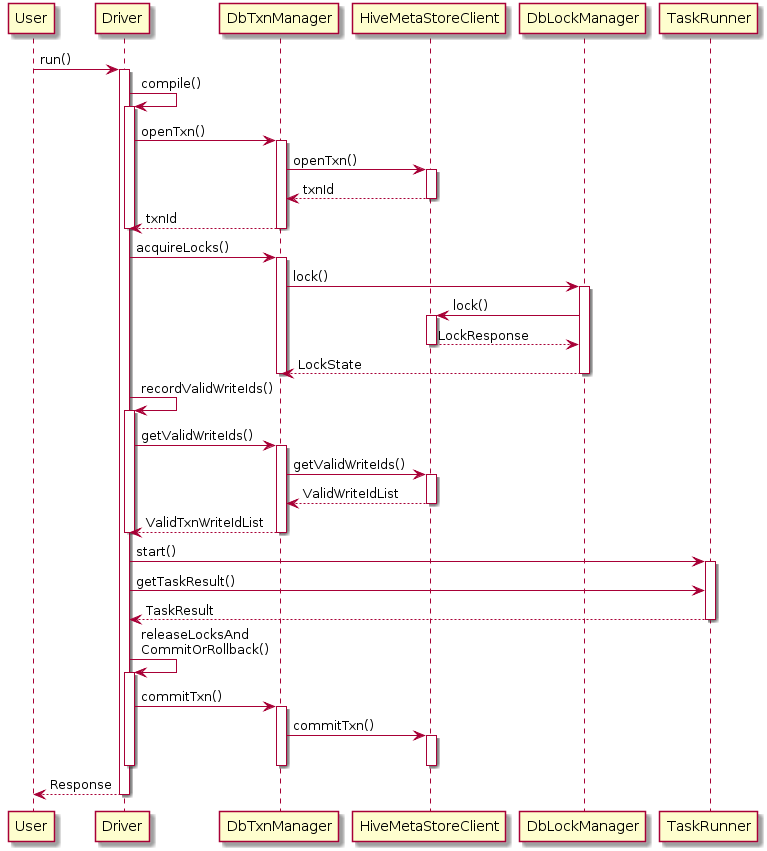
Hive提升篇-Hive修改事务
简介 Hive 默认是不允许数据更新操作的,毕竟它不擅长,即使在0.14版本后,做一些额外的配置便可开启Hive数据更新操作。而在海量数据场景下做update、delete之类的行级数据操作时,效率并不如意。 简单使用 修改HIVE_HOME/conf/hi…...

PMP项目管理未来的发展与趋势
什么是项目管理?关于项目管理的解释主要是基于国际项目管理三大体系不同的解释及本领域权威专家的解释。 项目管理就是以项目为对象的系统管理方法,通过一个临时性的、专门的柔性组织,对项目进行高效率的计划、组织、指导和控制,以…...

深度学习算法面试常问问题(三)
pooling层是如何进行反向传播的? average pooling: 在前向传播中,就是把一个patch的值取平均传递给下一层的一个像素。因此,在反向传播中,就是把某个像素的值平均分成n份 分配给上一层。 max pooling: 在前…...
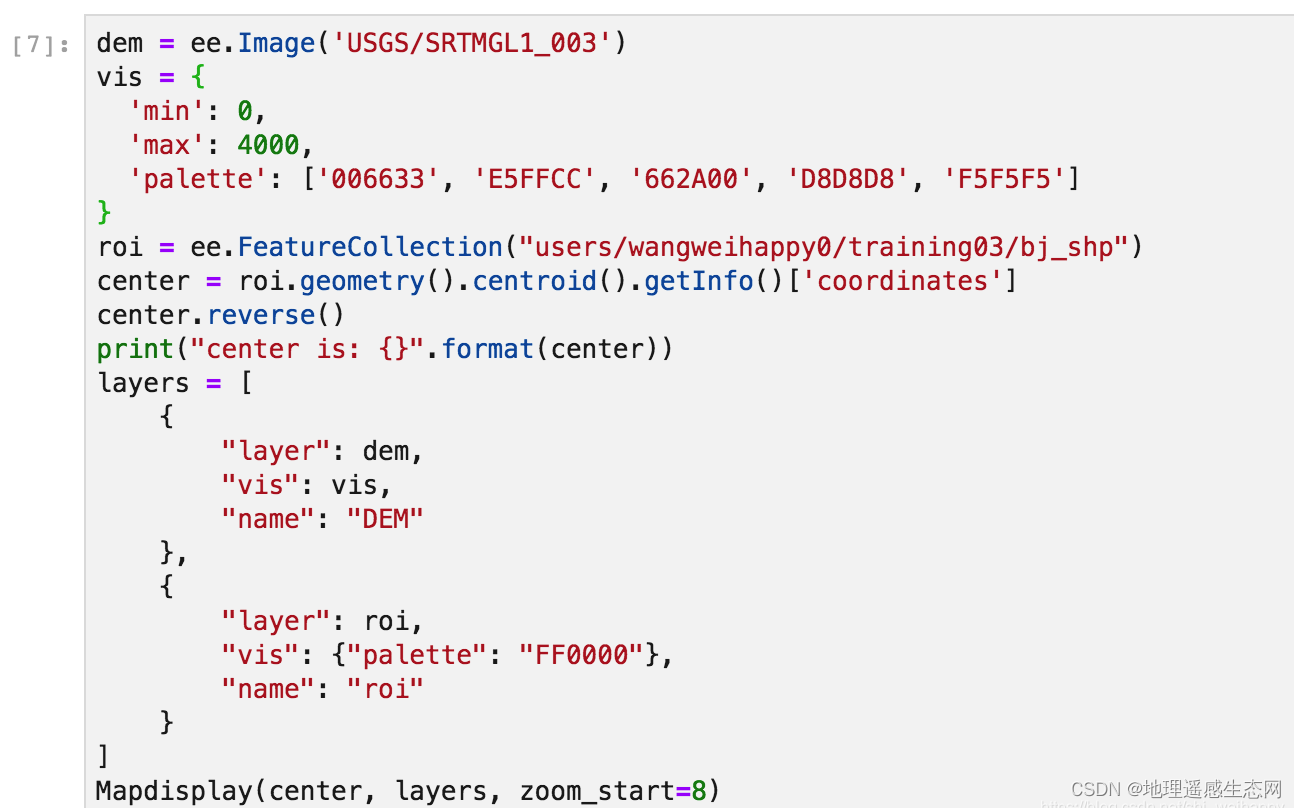
GEE学习笔记 八十七:python版GEE动态加载地图方法
在Google Earth Engine的python版API更新后,之前使用folium动态加载地图的代码就不能在正常运行,因为整个Google Earth Engine的地图加载服务的URL发生了更新,所以我们也需要更新相关绘制方法。下面我会讲解一种新的绘制方法,大家…...

第三章 SQL错误信息
文章目录第三章 SQL错误信息SQLCODE 0和100SQLCODE -400检索SQL消息文本第三章 SQL错误信息 下表列出了SQL数字错误代码及其错误消息。这些代码作为SQLCODE变量值返回。 注意:虽然本文档将错误代码列为负值,但JDBC和ODBC客户端始终收到正值。例如&…...

axios中的resolvePromise为什么影响promise状态
axios的取消请求意思很简单,就是在发送请求后不久停止发送请求 本文探讨的是v0.22.0之前的CancelToken API,因为在阅读源码交流的时候发现很多朋友不理解为什么CancelToken中的resolvePromise会影响到实例对象身上的promise状态 即下图所示代码…...

AWS攻略——创建VPC
文章目录创建一个可以外网访问的VPCCIDR主路由表DestinationTarget主网络ACL入站规则出站规则子网创建EC2测试连接创建互联网网关(IGW)编辑路由表知识点参考资料在 《AWS攻略——VPC初识》一文中,我们在AWS默认的VPC下部署了一台可以SSH访问的…...

2026届学术党必备的降重复率平台横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 1. 在学术写作这个特定领域里,合理运用AI工具能切实有效提升文献检索、大纲构建…...
)
flux_down 下载工具使用步骤详解(附FluxDown多线程下载与磁力解析教程)
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...

从ABL项目看激光武器发展:技术挑战、工程突破与未来转型
1. 项目背景与核心争议十几年前,当美国国防部(DoD)最终决定为YAL-1机载激光试验台(ABL)项目画上句号时,在军事与航空航天工程圈子里引发的讨论,远比一份简单的项目终止公告要复杂得多。这个项目…...

【AI搜索时代生存指南】:Perplexity vs Google搜索的5大核心差异,90%的开发者还不知道的关键决策点
更多请点击: https://intelliparadigm.com 第一章:AI搜索时代的技术范式迁移 传统关键词匹配式搜索正被语义理解、上下文感知与生成式推理深度重构。AI搜索不再仅返回文档链接,而是直接合成答案、推演逻辑链、调用工具并动态验证结果——这标…...

从 AI 电影到小说:《凰标》延续《第一大道》的东方梦@凤凰标志
科技为翼,文脉为魂; 大道开路,凰标定局。一、时代之问:当AI沦为流量收割机,谁来守护东方文脉? AI 正以惊人的速度渗透文娱产业,却多数被资本用作「快餐内容」的流水线。 海棠山铁哥反其道而行—…...
)
基于SSM框架的童装购买平台微信小程序(30286)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

为什么你的KFServing比别人慢3.8倍?:SITS 2026现场调试实录——AI原生编排中被忽略的4个cgroup v2陷阱
更多请点击: https://intelliparadigm.com 第一章:为什么你的KFServing比别人慢3.8倍?:SITS 2026现场调试实录——AI原生编排中被忽略的4个cgroup v2陷阱 在 SITS 2026 现场压测中,同一 KFServing v0.11.2 集群部署相…...
)
保姆级教程:用海思Hi3516EV200的himm命令手动切换IRCUT滤镜(附完整Shell脚本)
海思Hi3516EV200开发板实战:手把手教你用himm命令驱动IRCUT滤镜 在嵌入式视觉项目中,红外截止滤镜(IRCUT)的精准控制往往是决定夜间成像质量的关键。对于使用海思Hi3516EV200开发板的开发者来说,官方文档对GPIO底层操…...

Python爬虫实战:手把手教你如何采集开源许可证 FAQ 文章归档!
㊗️本期内容已收录至专栏《Python爬虫实战》,持续完善知识体系与项目实战,建议先订阅收藏,后续查阅更方便~ ㊙️本期爬虫难度指数:⭐⭐ (中级) 🉐福利: 一次订阅后,专栏内的所有文章…...

政府AI决策透明度如何影响公众信任?实证研究揭示关键机制
1. 项目概述:当算法成为“看不见的法官”在公共服务的数字化转型浪潮中,人工智能(AI)正从辅助工具演变为核心决策者。想象一下这样的场景:你提交了一份社会福利申请,原本需要数周的人工审核,现在…...