梯度下降优化
二阶梯度优化
- 1.无约束优化算法
- 1.1最小二乘法
- 1.2梯度下降法
- 1.3牛顿法/拟牛顿法
- 2.一阶梯度优化
- 2.1梯度的数学原理
- 2.2梯度下降算法
- 3.二阶梯度优化梯度优化
- 3.1 牛顿法
- 3.2 拟牛顿法
1.无约束优化算法
在机器学习中的无约束优化算法中,除了梯度下降以外,还有最小二乘法,牛顿法和拟牛顿法。
1.1最小二乘法
最小二乘法是计算解析解,如果样本量不算很大,且存在解析解,最小二乘法比起梯度下降法要有优势,计算速度很快。
1.2梯度下降法
梯度下降法是迭代求解,是如果样本量很大,用最小二乘法由于需要求一个超级大的逆矩阵,这时就很难或者很慢才能求解解析解了,使用迭代的梯度下降法比较有优势。
1.3牛顿法/拟牛顿法
牛顿法/拟牛顿法也是迭代求解,不过梯度下降法是梯度求解,而牛顿法/拟牛顿法是用二阶的海森矩阵的逆矩阵或伪逆矩阵求解。相对而言,使用牛顿法/拟牛顿法收敛更快。但是每次迭代的时间比梯度下降法长。
2.一阶梯度优化
2.1梯度的数学原理
链接: 一文看懂常用的梯度下降算法
链接: 详解梯度下降法(干货篇)
链接: 梯度下降算法Gradient Descent的原理和实现步骤
2.2梯度下降算法
链接: 梯度下降算法(附代码实现)
#定义函数
def f(x):return 0.5 * (x - 0.25)**2
#f(x)的导数(现在只有一元所以是导数,如果是多元函数就是偏导数)
def df(x):return x - 0.25 #求导应该不用解释吧
alpha = 1.8 #你可以更改学习率试试其他值
GD_X = [] #每次x更新后把值存在这个列表里面
GD_Y = [] #每次更新x后目标函数的值存在这个列表里面
x = 4 #随机初始化的x,其他的值也可以
f_current = f_change = f(x)
iter_num = 0while iter_num <100 and f_change > 1e-10: #迭代次数小于100次或者函数变化小于1e-10次方时停止迭代iter_num += 1x = x - alpha * df(x)tmp = f(x)f_change = abs(f_current - tmp)f_current = tmpGD_X.append(x)GD_Y.append(f_current)import numpy as np
import matplotlib.pyplot as pltX = np.arange(-4,4,0.05)
Y = f(X)
Y = np.array(Y)plt.plot(X,Y)
plt.scatter(GD_X,GD_Y)
plt.title("$y = 0.5(x - 0.25)^2$")
plt.show()plt.plot(X,Y)
plt.plot(GD_X,GD_Y) #注意为了显示清楚每次变化这里我做了调整
plt.title("$y = 0.5(x - 0.25)^2$")
plt.show()
3.二阶梯度优化梯度优化
3.1 牛顿法
3.2 拟牛顿法
拟牛顿算法是二阶梯度下降吗?
是的,拟牛顿算法是一种二阶梯度下降算法。它通过估计目标函数的海森矩阵的逆矩阵来近似实际的牛顿方法,以加快收敛速度。与传统的一阶梯度下降算法相比,拟牛顿算法具有更快的收敛速度和更好的收敛性能。
LBFGS是拟牛顿算法吗
是的,LBFGS(Limited-memory Broyden-Fletcher-Goldfarb-Shanno)是一种拟牛顿算法。它是一种基于梯度的优化算法,通过逐步近似目标函数的海森矩阵的逆矩阵来更新参数。LBFGS算法主要的特点是利用有限的内存来存储历史信息,从而避免了海森矩阵的存储和计算,同时具有较好的收敛性能和计算效率。LBFGS算法在实际应用中广泛使用,特别是对于大规模优化问题的求解,是一种非常有效的算法。
链接: 二阶优化方法——牛顿法、拟牛顿法(BFGS、L-BFGS)
链接: L-BFGS算法
链接: 【技术分享】L-BFGS算法
链接: 机器学习基础·L-BFGS算法
链接: 一文读懂L-BFGS算法
链接: PyTorch 学习笔记(七):PyTorch的十个优化器
链接: 二阶梯度优化新崛起,超越 Adam,Transformer 只需一半迭代量
链接: 神经网络的训练可以采用二阶优化方法吗?
代码备份
#pytorch==1.8.1
#transformers==3.1.0
#tensorflow==2.4.1
#keras==2.4.3
import warnings
warnings.filterwarnings("ignore")
import time
import random
from sklearn.metrics import f1_score
import pandas as pd
import numpy as np
np.random.seed(2020)
from tqdm import tqdm,tqdm_notebookimport torch
from transformers import *
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(2020)
torch.cuda.manual_seed(2020)
torch.backends.cudnn.deterministic = Trueimport time
import warningsimport numpy as np
import pandas as pd
from mealpy.evolutionary_based.GA import BaseGA
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import statsmodels.api as sm
from scipy.stats import spearmanr
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from plotnine import *import torch
import torch.nn as nn
import torch.nn.functional as Ffrom numpy import abs as P
from numpy import square as squa
from numpy import sqrt as sqt#from __functions__ import check
#from utils import residualswarnings.filterwarnings('ignore')
def MAE(y_true, y_pred):return mean_absolute_error(y_true, y_pred)def RMSE(y_true, y_pred):return np.sqrt(mean_squared_error(y_true, y_pred))def MAPE(y_true, y_pred):return 1.0/len(y_true) * np.sum(np.abs((y_pred-y_true)/y_true)) * 100def SMAPE(y_true, y_pred):return 1.0/len(y_true) * np.sum(np.abs(y_pred-y_true) / (np.abs(y_pred)+np.abs(y_true))/2) * 100def CORR(y_true, y_pred):return np.corrcoef(y_true, y_pred)[0][1]def AIC(y_true, y_pred):X = sm.add_constant(y_pred)ols = sm.OLS(y_true, X)ols_res = ols.fit()return ols_res.aicdef BIC(y_true, y_pred):X = sm.add_constant(y_pred)ols = sm.OLS(y_true, X)ols_res = ols.fit()return ols_res.bicdef SpearmanR(y_true, y_pred):tmp = spearmanr(y_true, y_pred)return tmp.correlationclass CorrLoss(nn.Module):def __init__(self):super(CorrLoss,self).__init__()def forward(self, input1, input2):input1 = input1 - torch.mean(input1)input2 = input2 - torch.mean(input2)cos_sim = F.cosine_similarity(input1.view(1, -1), input2.view(1, -1))return 1 - cos_simclass AGBO(nn.Module):def __init__(self):super(AGBO, self).__init__()self.R_d = torch.tensor(0.5, dtype=torch.float, requires_grad=True)self.X_d = torch.tensor(0.5, dtype=torch.float, requires_grad=True)self.G_d = torch.tensor(0.5, dtype=torch.float, requires_grad=True)self.B_d = torch.tensor(0.5, dtype=torch.float, requires_grad=True)self.R_cd = torch.tensor(0.5, dtype=torch.float, requires_grad=True)self.X_cd = torch.tensor(0.5, dtype=torch.float, requires_grad=True)self.lr_weight = torch.tensor(0.5, dtype=torch.float, requires_grad=True)self.lr_bias = torch.tensor(0.5, dtype=torch.float, requires_grad=True)self.__init_params__()def forward(self, U_ld, P_ld, Q_ld):# Delta_U_d 节点d处变压器阻抗电压降落的纵分量Delta_U_d = (P_ld * torch.abs(self.R_d*9.2+0.8) + Q_ld * torch.abs(self.X_d*15+5)) / U_ld# delta_U_d 节点d处变压器阻抗电压降落的横分量delta_U_d = (P_ld * torch.abs(self.X_d*15+5) - Q_ld * torch.abs(self.R_d*9.2+0.8)) / U_ld# P_d 节点d高压侧的有功功率P_d = P_ld + (torch.pow(P_ld, 2) + torch.pow(Q_ld, 2)) / torch.pow(U_ld, 2) * torch.abs(self.R_d*9.2+0.8) + torch.pow(U_ld, 2) * torch.abs(self.G_d*4e-6+4e-6)# Q_d 节点d高压侧的无功功率Q_d = Q_ld + (torch.pow(P_ld, 2) + torch.pow(Q_ld, 2)) / torch.pow(U_ld, 2) * torch.abs(self.X_d*15+5) + torch.pow(U_ld, 2) * torch.abs(self.B_d*6e-5+2e-5)# U_d 节点d高压侧的电压U_d = torch.sqrt(torch.pow(U_ld+Delta_U_d, 2) + torch.pow(delta_U_d, 2))# Delta_U_cd 支路a上电压降落的纵分量Delta_U_cd = (P_d * torch.abs(self.R_cd*0.495+0.005) + Q_d * torch.abs(self.X_cd*0.495+0.005)) / U_d# delta_U_cd 支路a上电压降落的横分量delta_U_cd = (P_d * torch.abs(self.X_cd*0.495+0.005) - Q_d * torch.abs(self.R_cd*0.495+0.005)) / U_d# Uc 节点c的电压U_c_calc = torch.sqrt(torch.pow(U_d+Delta_U_cd, 2) + torch.pow(delta_U_cd, 2))# outputs = U_c_calc outputs = U_c_calc * (self.lr_weight*0.4+0.8) + (self.lr_bias*1000)return outputsdef __init_params__(self):nn.init.uniform_(self.R_d, 0, 1)nn.init.uniform_(self.X_d, 0, 1)nn.init.uniform_(self.G_d, 0, 1)nn.init.uniform_(self.B_d, 0, 1)nn.init.uniform_(self.R_cd, 0, 1)nn.init.uniform_(self.X_cd, 0, 1)nn.init.uniform_(self.lr_weight, 0, 1)nn.init.uniform_(self.lr_bias, 0, 1)rawdata = pd.read_csv('v20210306.csv')
DEVICE = 'cpu'train_data, test_data = train_test_split(rawdata, test_size=0.25, shuffle=True, random_state=2022)U_ld_train, U_ld_test = train_data['A相电压值L'].values, test_data['A相电压值L'].values
P_ld_train, P_ld_test = train_data['A相有功'].values, test_data['A相有功'].values
Q_ld_train, Q_ld_test = train_data['A相无功'].values, test_data['A相无功'].values
U_c_train, U_c_test = train_data['A相电压值H'].values, test_data['A相电压值H'].values
U_ld_train, U_ld_test = U_ld_train * 10 / 0.38, U_ld_test * 10 / 0.38U_ld_train_tensor, U_ld_test_tensor = torch.tensor(U_ld_train, dtype=torch.float), torch.tensor(U_ld_test, dtype=torch.float)
P_ld_train_tensor, P_ld_test_tensor = torch.tensor(P_ld_train, dtype=torch.float), torch.tensor(P_ld_test, dtype=torch.float)
Q_ld_train_tensor, Q_ld_test_tensor = torch.tensor(Q_ld_train, dtype=torch.float), torch.tensor(Q_ld_test, dtype=torch.float)
U_c_train_tensor, U_c_test_tensor = torch.tensor(U_c_train, dtype=torch.float), torch.tensor(U_c_test, dtype=torch.float)U_ld_train_tensor, U_ld_test_tensor = U_ld_train_tensor.to(DEVICE), U_ld_test_tensor.to(DEVICE)
P_ld_train_tensor, P_ld_test_tensor = P_ld_train_tensor.to(DEVICE), P_ld_test_tensor.to(DEVICE)
Q_ld_train_tensor, Q_ld_test_tensor = Q_ld_train_tensor.to(DEVICE), Q_ld_test_tensor.to(DEVICE)
U_c_train_tensor, U_c_test_tensor = U_c_train_tensor.to(DEVICE), U_c_test_tensor.to(DEVICE)model = AGBO()
model = model.to(DEVICE)epochs = 1000
lr = 5e-3
weight_decay = 1e-6
optimizer = torch.optim.LBFGS([model.R_d, model.X_d, model.G_d, model.B_d, model.R_cd, model.X_cd], lr=lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=2)
loss_fn = nn.MSELoss()def closure():optimizer.zero_grad()loss = loss_fn(model(U_ld_train_tensor,P_ld_train_tensor,Q_ld_train_tensor), U_c_train_tensor)loss.backward()return lossall_train_loss, all_test_loss = [], []
for epoch in range(epochs):model.train()optimizer.zero_grad()outputs = model(U_ld_train_tensor, P_ld_train_tensor, Q_ld_train_tensor)train_loss = loss_fn(outputs, U_c_train_tensor)train_loss.backward()optimizer.step(closure)scheduler.step(train_loss)# setting optimazing boundmodel.R_d.data = model.R_d.clamp(0, 1).datamodel.X_d.data = model.X_d.clamp(0, 1).datamodel.G_d.data = model.G_d.clamp(0, 1).datamodel.B_d.data = model.B_d.clamp(0, 1).datamodel.R_cd.data = model.R_cd.clamp(0, 1).datamodel.X_cd.data = model.X_cd.clamp(0, 1).datamodel.lr_weight.data = model.R_cd.clamp(0, 1).datamodel.lr_bias.data = model.R_cd.clamp(0, 1).datawith torch.no_grad():model.eval()outputs_test = model(U_ld_test_tensor, P_ld_test_tensor, Q_ld_test_tensor)test_loss = loss_fn(outputs_test, U_c_test_tensor)all_train_loss.append(float(train_loss.detach().cpu().numpy()))all_test_loss.append(float(test_loss.detach().cpu().numpy()))# verboseif epoch%50 == 0:#print('the epoch is %d with train loss of %f' %(epoch, train_loss.detach().cpu().numpy()))print('the epoch is %d with test loss of %f' %(epoch, test_loss.detach().cpu().numpy()))model.eval()
outputs_train = model(U_ld_train_tensor, P_ld_train_tensor, Q_ld_train_tensor)
outputs_test = model(U_ld_test_tensor, P_ld_test_tensor, Q_ld_test_tensor)lr = LinearRegression()
lr.fit(outputs_train.detach().cpu().numpy().reshape(-1, 1), train_data['A相电压值H'].values.reshape(-1, 1))
outputs_train = lr.predict(outputs_train.detach().cpu().numpy().reshape(-1, 1))
outputs_test = lr.predict(outputs_test.detach().cpu().numpy().reshape(-1, 1))plt.figure(figsize=(8, 6))
plt.plot(train_data['A相电压值H'], outputs_train, 'ok')
plt.plot(test_data['A相电压值H'], outputs_test, '^r')
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
plt.xlabel('Uc', fontdict={'family':'Times new Roman', 'size':24})
plt.ylabel('Ucal', fontdict={'family':'Times new Roman', 'size':24})
plt.legend(['train sample', 'test_sample'])
plt.savefig('agbo-nonlr-45.tiff', dpi=150)
print(np.corrcoef(test_data['A相电压值H'], outputs_test.ravel()))
print('+++ test results +++')
print(MAE(test_data['A相电压值H'], outputs_test))
print(RMSE(test_data['A相电压值H'], outputs_test))
print(MAPE(test_data['A相电压值H'], outputs_test.ravel()))
print(SMAPE(test_data['A相电压值H'], outputs_test.ravel()))相关文章:

梯度下降优化
二阶梯度优化 1.无约束优化算法1.1最小二乘法1.2梯度下降法1.3牛顿法/拟牛顿法 2.一阶梯度优化2.1梯度的数学原理2.2梯度下降算法 3.二阶梯度优化梯度优化3.1 牛顿法3.2 拟牛顿法 1.无约束优化算法 在机器学习中的无约束优化算法中,除了梯度下降以外,还…...

一起看 I/O | 将 Kotlin 引入 Web
作者 / 产品经理 Vivek Sekhar 我们将在本文为您介绍 JetBrains 和 Google 的早期实验性工作。您可以观看今年 Google I/O 大会中的 WebAssembly 相关演讲,了解更多详情: https://youtu.be/RcHER-3gFXI?t604 应用开发者想要尽可能地在更多平台上最大限度地吸引用户…...
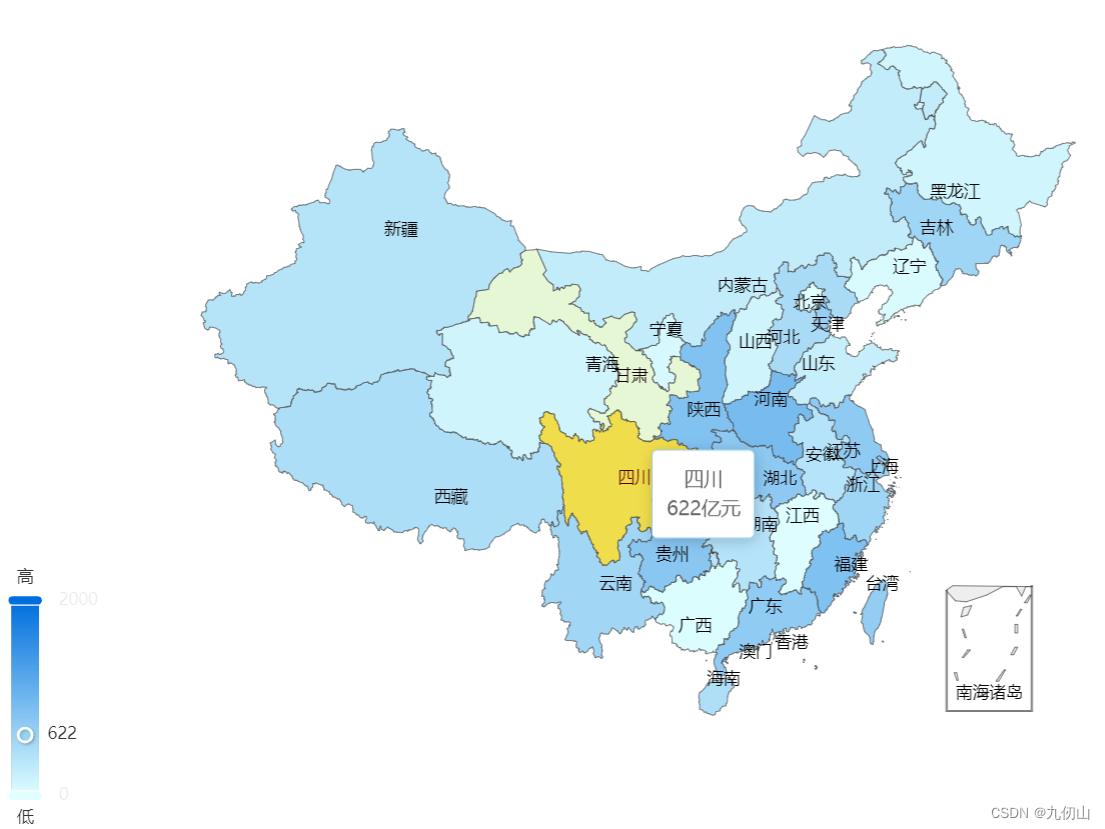
极致呈现系列之:Echarts地图的浩瀚视野(一)
目录 Echarts中的地图组件地图组件初体验下载地图数据准备Echarts的基本结构导入地图数据并注册展示地图数据结合visualMap展示地图数据 Echarts中的地图组件 Echarts中的地图组件是一种用于展示地理数据的可视化组件。它可以显示全国、各省市和各城市的地图,并支持…...
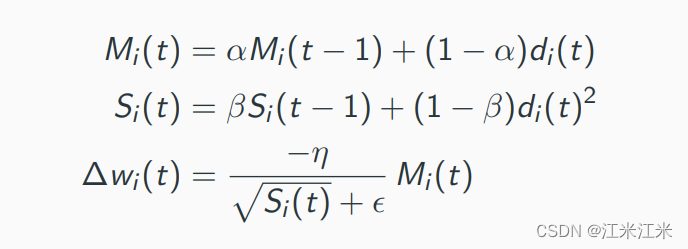
第四章 模型篇:模型训练与示例
文章目录 SummaryAutogradFunctions ()GradientBackward() OptimizationOptimization loopOptimizerLearning Rate SchedulesTime-dependent schedulesPerformance-dependent schedulesTraining with MomentumAdaptive learning rates optim.lr_scheluder Summary 在pytorch_t…...
利用人工智能模型学习Python爬虫
爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。 网络爬虫(又称为网页蜘蛛,网络机器人)是其中一种类型。 爬虫可以自动化浏览网络中的信息,当然浏览信息的时候需要按照我们制定的规则进行,这些规则我们称之为网络…...

.Net泛型详解
引言 在我们使用.Net进行编程的过程中经常遇到这样的场景:对于几乎相同的处理,由于入参的不同,我们需要写N多个重载,而执行过程几乎是相同的。更或者,对于几乎完成相同功能的类,由于其内部元素类型的不同&…...
——存储类)
C++ 教程(10)——存储类
存储类定义 C 程序中变量/函数的范围(可见性)和生命周期。这些说明符放置在它们所修饰的类型之前。下面列出 C 程序中可用的存储类: autoregisterstaticexternmutablethread_local (C11) 从 C 17 开始,auto 关键字不再是 C 存储…...

vue3+vite+element-plus创建项目,修改主题色
element-plus按需引入,修改项目的主题色 根据官方文档安装依赖 npm install -D unplugin-vue-components unplugin-auto-import vite.config.js配置 // vite.config.ts import { defineConfig } from vite import AutoImport from unplugin-auto-import/vite …...

mysql select是如何一步步执行的呢?
mysql select执行流程如图所示 server侧 在8.0之前server存在查询语句对应数据的缓存,不过在实际使用中比较鸡肋,对于更新比较频繁、稍微改点查询语句都会导致缓存无法用到 解析 解析sql语句为mysql能够直接执行的形式。通过词法分析识别表名、字段名等…...

找到距离最近的点,性能最好的方法
要找到距离最近的点并且性能最好,一种常用的方法是使用空间数据结构来加速搜索过程。以下是两个常见的数据结构和它们的应用: KD树(KD-Tree):KD树是一种二叉树数据结构,用于对k维空间中的点进行分割和组织…...

vue基础--重点
!1、vue的特性 !2、v-model 双向数据绑定指令 (data数据源变化,页面变化; 页面变化,data数据源也变化) 1、v-model 会感知到 框中数据变化 2、v-model 只有在表单元素中使用,才能…...

HarmonyOS元服务端云一体化开发快速入门(上)
一、前提条件 您已使用已实名认证的华为开发者帐号登录DevEco Studio。 请确保您的华为开发者帐号余额充足,账户欠费将导致云存储服务开通失败。 二、选择云开发模板 1.选择以下任一种方式,打开工程创建向导界面。 如果当前未打开任何工程,…...
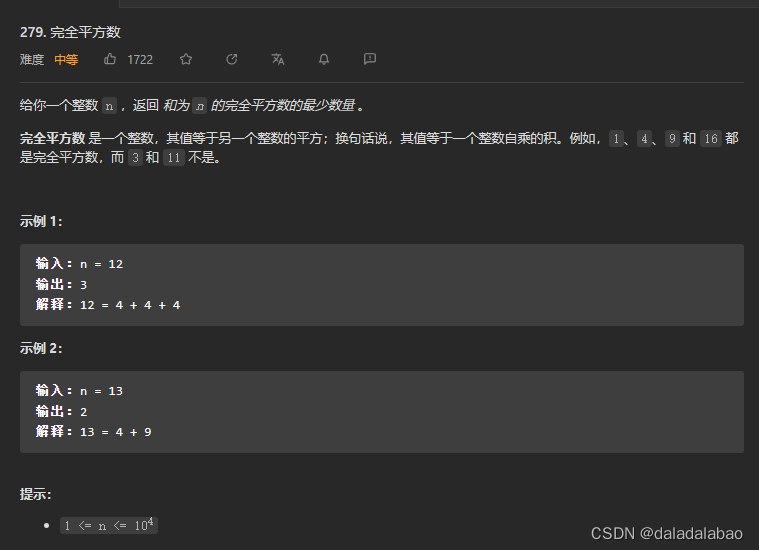
leetcode 279.完全平方数
题目描述 给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。 完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11 …...

Spring boot ApplicationContext
https://www.geeksforgeeks.org/spring-applicationcontext/ AnnotationConfigApplicationContext container 对象直接标注annotation: Configuration, Component ApplicationContext context new AnnotationConfigApplicationContext(AppConfig.class, AppConf…...

【Python实战】Python采集王者皮肤图片
前言 我们上一篇介绍了,如何采集王者最低战力,本文就来给大家介绍如何采集王者皮肤,买不起皮肤,当个桌面壁纸挺好的。下面,我和大家介绍如何获取数据。 环境使用 python 3.9pycharm 模块使用 requests 模块介绍 re…...

很详细的Django开发入门详解(图文并茂)
1.Django概述 Django是一个开放源代码的Web应用框架,由Python写成。采用了MTV的框架模式,即模型M,视图V和模版T。 Django 框架的核心组件有: 用于创建模型的对象关系映射;为最终用户设计较好的管理界面;…...

Ansible 部署
ansible 自动化运维工具,可以实现批量管理多台(成百上千)主机,应用级别的跨主机编排工具 特性: 无agent的存在,不要在被控制节点上安装客户端应用 通过ssh协议与被控制节点通信 基于模块工作的,…...
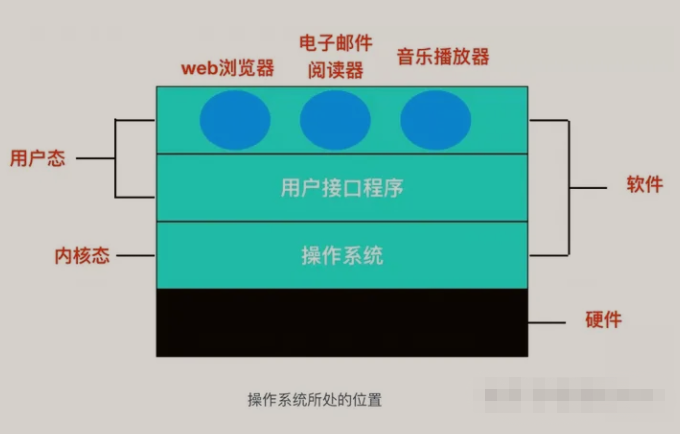
【操作系统】计算机操作系统知识点总结
文章目录 前言一、操作系统的概念与发展二、操作系统的结构与功能1、操作系统的结构2、操作系统的功能 三、进程管理1、进程2、进程的创建3、进程管理的实现4、进程控制块 四、内存管理1、内存2、内存管理3、内存管理的实现 五、文件系统1、文件系统2、文件系统的主要任务3、文…...

springmvc整合thymeleaf
概述 Thymeleaf提供了一组Spring集成,使您可以将其用作Spring MVC应用程序中JSP的全功能替代品。 这些集成将使您能够: Controller像使用JSP一样,将Spring MVC 对象中的映射方法转发到Thymeleaf管理的模板。在模板中使用Spring表达式语言&…...

Redis 内存管理机制
Redis作为一个内存数据库,内存资源非常珍贵。因此,Redis引入了3种内存管理机制来释放不必要的内存,包括定期删除、惰性删除和内存淘汰机制。 定期删除 定期删除是Redis内存管理机制的一种,它用于删除过期的键值对。Redis每隔 10…...

CodeGPT:基于AI的Git提交信息自动生成工具实战指南
1. 项目概述:CodeGPT,一个用Go写的AI驱动Git工具 如果你和我一样,每天都要在终端里敲无数次 git commit -m "..." ,并且为写一个清晰、规范的提交信息而绞尽脑汁,那今天分享的这个工具绝对能让你眼前一亮…...
)
手把手教你:在无外网环境下搞定VSCode插件离线安装(附下载地址拼接技巧)
企业内网开发环境高效配置指南:VSCode插件离线部署实战 在高度安全管控的企业研发环境中,外网隔离是常见的安全策略。当新入职的工程师第一次打开内网电脑上的VSCode时,面对空空如也的插件市场,那种无从下手的焦虑感我深有体会。三…...

HI3861实战指南:基于MQTT协议实现OneNET平台设备双向通信
1. HI3861与OneNET平台双向通信实战 第一次接触HI3861开发板时,我就被它轻量级的物联网开发能力吸引了。这块板子虽然体积小,但配合OneNET平台能实现完整的物联网数据交互。今天我就用最直白的语言,分享如何让HI3861通过MQTT协议与OneNET平台…...

终极歌词同步体验:揭秘LyricsX如何让macOS音乐播放变得更有趣
终极歌词同步体验:揭秘LyricsX如何让macOS音乐播放变得更有趣 【免费下载链接】LyricsX 🎶 Ultimate lyrics app for macOS. 项目地址: https://gitcode.com/gh_mirrors/ly/LyricsX 你是否曾经在听歌时想要跟着歌词一起唱,却发现找不到…...

别再死记硬背公式了!用“预测-更新”的贝叶斯视角,5分钟看懂卡尔曼滤波核心
卡尔曼滤波:用贝叶斯思维解决自动驾驶中的不确定性追踪问题 想象一下你正驾驶一辆特斯拉行驶在高速公路上,车载雷达显示前方100米处有一辆卡车。但下一秒雷达数据突然跳变到105米,而摄像头却显示距离是98米。作为人类司机,你会本能…...

观察Taotoken在多模型并发调用时的延迟表现与稳定性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型并发调用时的延迟表现与稳定性 在构建复杂的AI应用时,开发者常常需要同时或交替调用多个不同的大…...

如何零安装体验Windows 12:网页版模拟器完整指南
如何零安装体验Windows 12:网页版模拟器完整指南 【免费下载链接】win12 Windows 12 网页版,在线体验 点击下面的链接在线体验 项目地址: https://gitcode.com/gh_mirrors/wi/win12 你是否想在浏览器中直接运行Windows系统?无需下载任…...

软件工程自动化浪潮下,工程师如何从代码生产者转型为系统架构师?
1. 软件工程的自动化浪潮:从手工艺到基础设施的必然之路最近和几个在头部大厂干了十几年的老同事聊天,话题总绕不开一个词:焦虑。不是对业务增长的焦虑,而是对自身角色价值的焦虑。一个在阿里做P8的朋友说,他团队里新来…...

5分钟搞定B站视频数据分析:让数据采集变得像点外卖一样简单
5分钟搞定B站视频数据分析:让数据采集变得像点外卖一样简单 【免费下载链接】Bilivideoinfo Bilibili视频数据爬虫 精确爬取完整的b站视频数据,包括标题、up主、up主id、精确播放数、历史累计弹幕数、点赞数、投硬币枚数、收藏人数、转发人数、发布时间、…...

简化OpenAI API调用:轻量级封装库实践指南
1. 项目概述:一个极简的OpenAI API封装库 如果你正在开发一个需要集成AI能力的应用,比如一个聊天机器人、一个内容生成工具,或者一个代码助手,那么你大概率绕不开OpenAI的API。它的功能强大,文档也还算清晰࿰…...