GIS大数据处理框架sedona(塞多纳)编程入门指导
GIS大数据处理框架sedona(塞多纳)编程入门指导
简介
Apache Sedona™是一个用于处理大规模空间数据的集群计算系统。Sedona扩展了现有的集群计算系统,如Apache Spark和Apache Flink,使用一组开箱即用的分布式空间数据集和空间SQL,可以有效地加载、处理和分析跨机器的大规模空间数据。码云镜像 码云sedona文档持续更新中
代码结构

- common java核心包,对底层JTS、geotools坐标系转换等操作方法的接口包装,并提供了circle(扩展JTS功能),距离计算方法:Haversine方式,Spheroid椭球;WKT,GeoJSON等格式转换;索引支持QUADTREE,RTREE;geohash计算;供spark、flink等上层应用调用使用
- core 与spark适配核心包,封装提供基础对象SpatialRDD,PointRDD,LineStingRDD,CircleRDD,PolygonRDD;几何链接操作joinJudgement(通过几何拓扑关系),knnJudgement(几何距离),rangeJudgement(treeIndex索引范围查询);数据读取转换formatMapper:cvs,wkt,geoJson,shapefile,netcdf;spatialPartitioning分区器:QuadtreePartitioning,KDBTreePartitioner等
- flink flink适配,调用common下的functions里面提供的函数方法
- python-adapter python适配,调用common下的functions里面提供的函数方法
- sql spark-sql适配,调用common下的functions里面提供的函数方法
使用说明
在spark下面的使用说明
1.安装
具体参看
<dependency><groupId>org.apache.sedona</groupId><artifactId>sedona-spark-shaded-3.0_2.12</artifactId><version>1.4.0</version>
</dependency>
<dependency><groupId>org.apache.sedona</groupId><artifactId>sedona-viz-3.0_2.12</artifactId><version>1.4.0</version>
</dependency>
<!-- Optional: https://mvnrepository.com/artifact/org.datasyslab/geotools-wrapper -->
<dependency><groupId>org.datasyslab</groupId><artifactId>geotools-wrapper</artifactId><version>1.4.0-28.2</version>
</dependency>2.初始化SparkSession
SparkSession sparkSession = SparkSession.builder()
.master("local[*]") // Delete this if run in cluster mode
.appName("readTestScala") // Change this to a proper name
// Enable Sedona custom Kryo serializer
.config("spark.serializer", KryoSerializer.class.getName) // org.apache.spark.serializer.KryoSerializer
.config("spark.kryo.registrator", SedonaKryoRegistrator.class.getName)
.getOrCreate() // org.apache.sedona.core.serde.SedonaKryoRegistrator
3.安装函数
SedonaSQLRegistrator.registerAll(sparkSession)
4.使用例子
4.1 dataFrame方式加载数据
4.1.1 从文件加载数据
假设有一个WKT数据格式的tsv文件,存储位置/Download/usa-county.tsv
POLYGON (..., ...) Cuming County
POLYGON (..., ...) Wahkiakum County
POLYGON (..., ...) De Baca County
POLYGON (..., ...) Lancaster County
加载
Dataset<Row> rawDf = sparkSession.read.format("csv").option("delimiter", "\t").option("header", "false").load("/Download/usa-county.tsv")
rawDf.createOrReplaceTempView("rawdf")
rawDf.show()
结果展示
| _c0|_c1|_c2| _c3| _c4| _c5| _c6|_c7|_c8| _c9|_c10| _c11|_c12|_c13| _c14| _c15| _c16| _c17|
+--------------------+---+---+--------+-----+-----------+--------------------+---+---+-----+----+-----+----+----+----------+--------+-----------+------------+
|POLYGON ((-97.019...| 31|039|00835841|31039| Cuming| Cuming County| 06| H1|G4020|null| null|null| A|1477895811|10447360|+41.9158651|-096.7885168|
|POLYGON ((-123.43...| 53|069|01513275|53069| Wahkiakum| Wahkiakum County| 06| H1|G4020|null| null|null| A| 682138871|61658258|+46.2946377|-123.4244583|
|POLYGON ((-104.56...| 35|011|00933054|35011| De Baca| De Baca County| 06| H1|G4020|null| null|null| A|6015539696|29159492|+34.3592729|-104.3686961|
|POLYGON ((-96.910...| 31|109|00835876|31109| Lancaster| Lancaster County| 06| H1|G4020| 339|30700|null| A|2169240202|22877180|+40.7835474|-096.6886584|
4.1.1 通过ST_函数
SELECT ST_GeomFromWKT(_c0) AS countyshape, _c1, _c2
4.1.3 从GeoJSON文件读取
String schema = "type string, crs string, totalFeatures long, features array<struct<type string, geometry string, properties map<string, string>>>";
sparkSession.read.schema(schema).json(geojson_path).selectExpr("explode(features) as features") // Explode the envelope to get one feature per row..select("features.*") // Unpack the features struct..withColumn("geometry", expr("ST_GeomFromGeoJSON(geometry)")) // Convert the geometry string..printSchema();
4.1.4 从数据库读取
// For any JDBC data source, inluding Postgis.
Dataset<Row> df = sparkSession.read().format("jdbc")// Other options..option("query", "SELECT id, ST_AsBinary(geom) as geom FROM my_table").load().withColumn("geom", expr("ST_GeomFromWKB(geom)"))// This is a simplified version that works for Postgis.
Dataset<Row> df = sparkSession.read().format("jdbc")// Other options..option("dbtable", "my_table").load().withColumn("geom", expr("ST_GeomFromWKB(geom)"))4.2 CRS(坐标系)转换
SELECT ST_Transform(countyshape, "epsg:4326", "epsg:3857") AS newcountyshape, _c1, _c2, _c3, _c4, _c5, _c6, _c7
FROM spatialdf
4.3 地理空间查询
4.3.1 范围查询
ST_Contains, ST_Intersects, ST_Within
SELECT *
FROM spatialdf
WHERE ST_Contains (ST_PolygonFromEnvelope(1.0,100.0,1000.0,1100.0), newcountyshape)
4.3.2 距离查询
ST_Distance
SELECT countyname, ST_Distance(ST_PolygonFromEnvelope(1.0,100.0,1000.0,1100.0), newcountyshape) AS distance
FROM spatialdf
ORDER BY distance DESC
LIMIT 5
4.3.3 关联查询
SELECT *
FROM polygondf, pointdf
WHERE ST_Contains(polygondf.polygonshape,pointdf.pointshape)SELECT *
FROM polygondf, pointdf
WHERE ST_Intersects(polygondf.polygonshape,pointdf.pointshape)SELECT *
FROM pointdf, polygondf
WHERE ST_Within(pointdf.pointshape, polygondf.polygonshape)SELECT *
FROM pointdf1, pointdf2
WHERE ST_Distance(pointdf1.pointshape1,pointdf2.pointshape2) < 25 存储
已入postgis为例
my_postgis_db# create table my_table (id int8, geom geometry);df.withColumn("geom", expr("ST_AsEWKB(geom)").write.format("jdbc").option("truncate","true") // Don't let Spark recreate the table.// Other options..save()// If you didn't create the table before writing you can change the type afterward.
my_postgis_db# alter table my_table alter column geom type geometry;6 SpatialRDD与DataFrame相好转换
6.1 SpatialRDD转DataFrame
Dataset<Row> spatialDf = Adapter.toDf(spatialRDD, sparkSession)
6.2 DataFrame转SpatialRDD
val schema = StructType(Array(StructField("county", GeometryUDT, nullable = true),StructField("name", StringType, nullable = true),StructField("price", DoubleType, nullable = true),StructField("age", IntegerType, nullable = true)
))
val spatialDf = Adapter.toDf(spatialRDD, schema, sparkSession)
相关文章:
GIS大数据处理框架sedona(塞多纳)编程入门指导
GIS大数据处理框架sedona(塞多纳)编程入门指导 简介 Apache Sedona™是一个用于处理大规模空间数据的集群计算系统。Sedona扩展了现有的集群计算系统,如Apache Spark和Apache Flink,使用一组开箱即用的分布式空间数据集和空间SQL,可以有效地…...

C++基础(7)——类和对象(5)
前言 本文主要介绍C中的继承 4.6.1:继承和继承方式(公有、保护、私有) 4.6.2:继承中的对象模型,sizeof()求子类对象大小 4.6.3:子类继承父类后,两者构造和析构顺序 父类先构造、子类先析构 如…...

【Express.js】sql-knex 增删改查
Sql增删改查 本节使用knex作为sql框架,以sqlite数据库为例 准备工作 knex是一个运行在各自数据库Driver上的框架,因此需要安装相应的js版数据库Driver,如: PostgreSQL -> pg, mysql/mariadb -> mysql, sqlite -> sqlite3… 安装…...
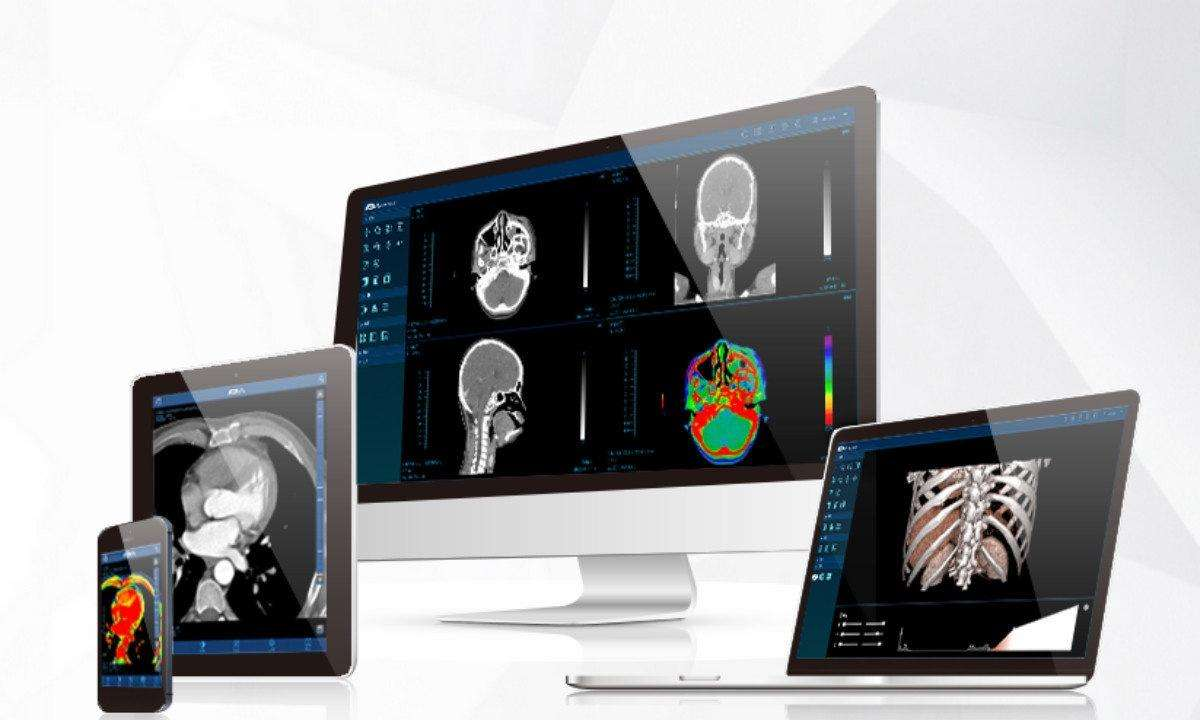
构建基于前后端分离的医学影像学学习平台:Java技术实现与深度解析
在医学领域,影像学学习平台是一种重要的工具,用于帮助医学学生和专业人士学习和研究医学影像。本文将介绍如何使用Java构建一个基于前后端分离的医学影像学学习平台,通过结合前沿的Web开发技术和医学影像处理算法,为用户提供强大且高效的学习工具。 技术架构设计: 在构…...

从零开始学习R语言编程:完全指南
一、引言 R语言是一种流行的数据分析语言,广泛应用于学术界、商业界和社会科学研究等领域。与其它数据分析软件相比,R语言的优点包括免费开源、高效可靠、具有强大的数据分析和可视化能力等。R语言的编程基础包括了各种控制结构和函数,可以方…...
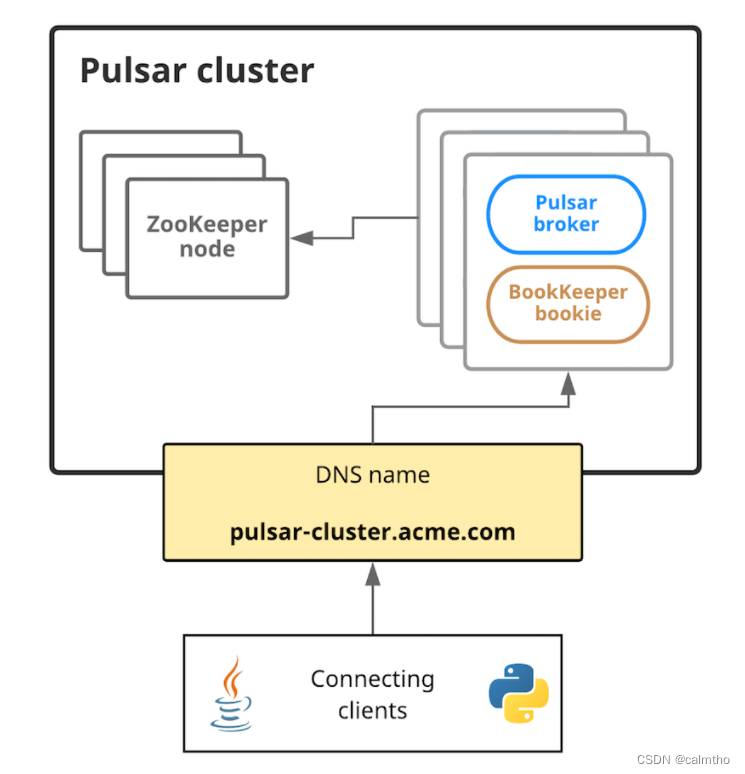
PulsarMQ系列入门篇
文章目录 介绍:部署安装讲解:安装单机版本测试(Linux下): 介绍: PulsarMQ 现托管于apache Apache 软件基金会顶级项目,2016年由雅虎公司开源的分布式多租户消息中间件 ,是下一代云原生分布式消息…...

编程的实践理论 第九章 交互
第九章 交互 根据状态的初始值和终止值,我们已经描述了计算。一个状态变量的声明如下: var x: T S ∃x, x′: T S 它说的是一个状态变量有两个数学变量,一个是初始值,一个是终止值。在这个 声明的作用域内,x和x…...

BSN全球技术创新发展峰会在武汉举办,“延安链”正式发布
原标题:《第二届BSN全球技术创新发展峰会在武汉成功举行》 6月9日,由湖北省人民政府指导,湖北省发展改革委、国家信息中心联合主办,中国移动、中国电信、中国联通、武汉市江汉区人民政府、区块链服务网络(BSN…...
8.4 IP地址与端口号
目录 IP地址 IP地址及编址方式 IP 地址及其表示方法 点分十进制记法举例 IP 地址采用 2 级结构 分类的 IP 地址 分类的 IP 地址 多归属主机 各类 IP 地址的指派范围 编辑 一般不使用的特殊的 IP 地址 编辑 分类的 IP 地址的优点和缺点 划分子网 无分类编址 CIDR 无…...

day56_springmvc
今日内容 零、 复习昨日 零、 复习昨日 一、JSON处理【重点】 springmvc支持json数据交互,但是自己本身没有对应jar,使用的是第三方Jackson,只需要导入对应依赖,springmvc即可使用 如果需要换用到FastJson 导入依赖配置文件中指定json转换的类型为FastJson本次课程没有替换,用的…...

SQL Server Management Studio (SSMS)下载,安装以及连接数据库配置
目录 (一)前言 (二)下载与安装 1. 下载 (1)下载地址 (2)SSMS对操作系统的要求 2. 安装 (1)存放下载好的安装包 (2) 双击进入安…...

go 错误 异常
自定义错误 Go语言中 错误使用内建的 error 类型表示, error类型是一个接口类型:定义如下: error 有一个 Error() 的方法‘所有实现该接口的类型 都可以当做一个错误的类型;Error()方法输入具体错误描述,在打印错误时…...

智慧加油站卸油作业行为分析算法 opencv
智慧加油站卸油作业行为分析系统通过opencvpython网络模型技术,智慧加油站卸油作业行为分析算法实现对卸油作业过程的实时监测。当现场出现卸油作业时人员离岗,打电话人员抽烟等违规行为,灭火器未正确摆放,明火和烟雾等异常状态&a…...
LiangGaRy-学习笔记-Day22
1、shell工具-tput 这个是tput bash工具 具体的操作如下: tput clear:清屏tput cup Y X 第Y行,第X列的位置 tput bold:字体加粗tput sgr0 : 重置命令tput setaf n n:代表数字0-7 0黑色1红色2绿色3黄色4蓝…...

数据库横表和竖表有什么区别
横表和竖表是描述数据库表结构的两种形式,它们之间的主要区别在于数据的组织方式和用途。 横表(宽表): 横表是一种常见的表结构,其特点是每一行数据包含所有相关属性,字段通常作为列出现。横表中的每行代表…...

哈希表--day1--基本理论介绍
文章目录 哈希表哈希函数哈希碰撞拉链法线性探测法 常见的三种哈希函数数组setmap 总结 哈希表 Hash table是根据关键码的值来直接进行访问的数据结构。 其实直白来讲其实数组就是一张哈希表,不过其索引是十分简单的,我们通过0来访问num[0],…...
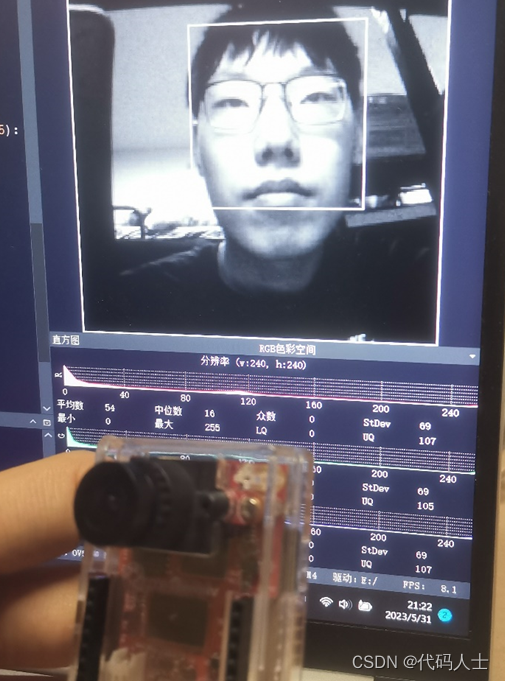
基于OpenMV的疲劳驾驶检测系统的设计
一、前言 借助平台将毕业设计记录下来,方便以后查看以及与各位大佬朋友们交流学习。如有问题可以私信哦。 本文主要从两个方面介绍毕业设计:硬件,软件(算法)。以及对最后的实验结果进行分析。感兴趣的朋友们可以评论区…...

chatgpt赋能python:使用Python来寻找两个列表不同元素的方法
使用Python来寻找两个列表不同元素的方法 在编写Python程序时,我们经常需要比较两个列表的元素,找出它们之间的不同之处。在搜索引擎优化(SEO)方面,这种比较对于找出两个网站内容的差异也非常有用。在这篇文章中&…...
简单学生管理系统
简单学生管理系统(Java)_封奚泽优的博客-CSDN博客https://blog.csdn.net/weixin_64066303/article/details/130667107?spm1001.2014.3001.5501 转载请注明出处,尊重作者劳动成果。 目录 前期准备: 数据库的连接: 用户账号类:…...
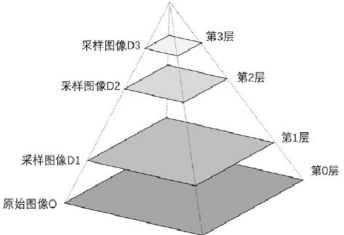
图像金字塔
图像金字塔是由一幅图像的多个不同分辨率的子图构成的图像集合。是通过一个图像不断的降低采样率产生的,最小的图像可能仅仅有一个像素点。下图是一个图像金子塔的示例。从图中可以看到,图像金字塔是一系列以金字塔形状排列的、自底向上分辨率逐渐降低…...

开源技术如何驱动物联网创新:从硬件到软件的平民化革命
1. 物联网与开源:一场全民工程的序章十年前,如果有人告诉我,一个没有任何电子工程背景的艺术家,能自己动手做一个能联网、能自动浇花、还能在社交媒体上发照片的智能花盆,我大概会觉得他在讲科幻故事。但今天ÿ…...

企业微信代开发应用:CallBackUrl验证失败排查与CorpID加密升级实战
1. 企业微信代开发应用验证失败的典型场景 最近不少服务商朋友反馈,代开发应用在验证CallBackUrl时频繁失败。这个问题其实源于企业微信在2022年6月底进行的一次安全升级。当时官方发布公告称,为了提升账户安全性,所有新建的代开发应用都需要…...

3分钟上手OmenSuperHub:解锁暗影精灵笔记本的真正性能潜力
3分钟上手OmenSuperHub:解锁暗影精灵笔记本的真正性能潜力 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 你是否厌倦了官方OMEN Gaming Hub的…...

基于Arduino Pro Micro的薄膜键盘矩阵改造:DIY低成本模拟飞行外设
1. 项目概述:为Falcon BMS打造一款经济型多功能按键面板如果你是一名《Falcon BMS》的飞行模拟爱好者,同时又对硬件DIY抱有热情,那么你很可能和我一样,对市面上那些动辄数百甚至上千元的专业模拟飞行外设感到望而却步。尤其是像F-…...

Windows本地AI开发环境搭建:OpenClaw与Ollama集成指南
1. 项目概述:一个为Windows开发者量身打造的本地AI开发环境如果你是一名在Windows 11上工作,同时又对本地运行大语言模型(LLM)和AI助手感兴趣的开发者,那么你很可能已经体验过那种“配置地狱”:WSL2、Docke…...

从零构建开发者效率工具:CLI脚手架与自动化工作流实践
1. 项目概述与核心价值最近在开源社区里,一个名为smouj/smouj的项目引起了我的注意。乍一看这个标题,可能会让人有些摸不着头脑,它不像常见的vue/vue或tensorflow/tensorflow那样直白地揭示了其技术栈。但恰恰是这种看似“神秘”的命名&#…...

Smart-SSO分布式部署踩坑实录:从POM依赖改写到Nginx配置的那些‘坑’
Smart-SSO分布式部署实战:从POM依赖到Nginx配置的深度避坑指南 去年我们团队在推进Smart-SSO分布式改造时,原以为按照官方文档两小时就能搞定,结果整整折腾了三天。这篇文章不是标准教程,而是我们踩过的坑和填坑经验。如果你正在…...

蓝桥杯EDA国赛备赛
一.电路设计部分(1)13届国赛要求:数码管驱动电路设计区域内,使用给定的元器件(锁存器-U6、电容等)和网络标识补充完成数码管驱动电路,实现单片机对数码管的显示控制。参考答案:1. 10…...

如何构建高效的个人游戏串流服务器:Sunshine完整部署指南
如何构建高效的个人游戏串流服务器:Sunshine完整部署指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 在当今数字娱乐时代,游戏玩家面临着设备限制与体验…...

北京数据恢复公司哪个公司好
在当今数字化时代,数据的重要性不言而喻。无论是个人用户的珍贵照片、文档,还是企业的重要商业数据,一旦丢失,都可能造成巨大的损失。在北京,有众多的数据恢复公司,那么哪家公司才是最好的选择呢࿱…...