ELK日志收集系统集群实验
ELK日志收集系统集群实验
目录
一、实验拓扑
二、环境配置
三、 安装node1与node2节点的elasticsearch
1. 安装
2.配置
3.启动elasticsearch服务
4.查看节点信息
四、在node1安装elasticsearch-head插件
1.安装node
2.拷贝命令
3.安装elasticsearch-head
4.修改elasticsearch配置文件
5.启动elasticsearch-head
6.访问:
7.测试
五、node1服务器安装logstash
六、logstash日志收集文件格式
七、node1节点安装kibana
八、企业案例:
一、实验拓扑

二、环境配置
设置各个主机的IP地址为拓扑中的静态IP,在两个节点中修改主机名为node1和node2并设置hosts文件
node1:
hostnamectl set-hostname node1
vim /etc/hosts
192.168.1.1 node1
192.168.1.2 node2
node2:
hostnamectl set-hostname node2
vim /etc/hosts
192.168.1.1 node1
192.168.1.2 node2
三、 安装node1与node2节点的elasticsearch
1. 安装
mv elk软件包 elk
cd elk
rpm -ivh elasticsearch-5.5.0.rpm
2.配置
node1:
vim /etc/elasticsearch/elasticsearch.yml
cluster.name:my-elk-cluster //集群名称
node.name:node1 //节点名字
path.data:/var/lib/elasticsearch //数据存放路径
path.logs: /var/log/elasticsearch/ //日志存放路径
bootstrap.memory_lock:false //在启动的时候不锁定内存
network.host:0.0.0.0 //提供服务绑定的IP地址,0.0.0.0代表所有地址
http.port:9200 //侦听端口为9200
discovery.zen.ping.unicast.hosts:【"node1","node2"】 //群集发现通过单播实现
node2:
vim /etc/elasticsearch/elasticsearch.yml
cluster.name:my-elk-cluster //集群名称
node.name:node2 //节点名字
path.data:/var/lib/elasticsearch //数据存放路径
path.logs: /var/log/elasticsearch/ //日志存放路径
bootstrap.memory_lock:false //在启动的时候不锁定内存
network.host:0.0.0.0 //提供服务绑定的IP地址,0.0.0.0代表所有地址
http.port:9200 //侦听端口为9200
discovery.zen.ping.unicast.hosts:【"node1","node2"】 //群集发现通过单播实现
3.启动elasticsearch服务
node1和node2
systemctl start elasticsearch
4.查看节点信息
http://192.168.1.1:9200
http://192.168.1.2:9200
四、在node1安装elasticsearch-head插件
1.安装node
cd elk
tar xf node-v8.2.1.tar.gz
cd node-v8.2.1
./configure && make && make install
等待安装完毕。
2.拷贝命令
cd elk
tar xf phantomjs-2.1.1-linux-x86_64.tar.bz2
cd phantomjs-2.1.1-linux-x86_64/bin
cp phantomjs /usr/local/bin
3.安装elasticsearch-head
cd elk
tar xf elasticsearch-head.tar.gz
cd elasticsearch-head
npm install
4.修改elasticsearch配置文件
vim /etc/elasticsearch/elasticsearch.yml
# Require explicit names when deleting indices:
#
#action.destructive_requires_name:true
http.cors.enabled: true //开启跨域访问支持,默认为false
http.cors.allow-origin:"*" //跨域访问允许的域名地址
重启服务: systemctl restart elasticsearch
5.启动elasticsearch-head
cd /root/elk/elasticsearch-head
npm run start &
查看监听: netstat -anput | grep :9100
6.访问:
http://192.168.1.1:9100
7.测试
在node1的终端中输入:
curl -XPUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'Content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
刷新浏览器可以看到对应信息即可
五、node1服务器安装logstash
cd elk
rpm -ivh logstash-5.5.1.rpm
systemctl start logstash.service
In -s /usr/share/logstash/bin/logstash /usr/local/bin/
测试1: 标准输入与输出
logstash -e 'input{ stdin{} }output { stdout{} }'
测试2: 使用rubydebug解码
logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug }}'
测试3:输出到elasticsearch
logstash -e 'input { stdin{} } output { elasticsearch{ hosts=>["192.168.1.1:9200"]} }'
查看结果:
http://192.168.1.1:9100
若看不到,请刷新!!!
六、logstash日志收集文件格式
(默认存储在/etc/logstash/conf.d)
Logstash配置文件基本由三部分组成:input、output以及 filter(根据需要)。标准的配置文件格式如下:
input (...) 输入
filter {...} 过滤
output {...} 输出
在每个部分中,也可以指定多个访问方式。例如,若要指定两个日志来源文件,则格式如下:
input {
file{path =>"/var/log/messages" type =>"syslog"}
file { path =>"/var/log/apache/access.log" type =>"apache"}
}
案例:通过logstash收集系统信息日志
chmod o+r /var/log/messages
vim /etc/logstash/conf.d/system.conf
input {
file{
path =>"/var/log/messages"
type => "system"
start_position => "beginning"
}
}
output {
elasticsearch{
hosts =>["192.168.1.1:9200"]
index => "system-%{+YYYY.MM.dd}"
}
}
重启日志服务: systemctl restart logstash
查看日志: http://192.168.1.1:9100
七、node1节点安装kibana
cd elk
rpm -ivh kibana-5.5.1-x86_64.rpm
配置kibana
vim /etc/kibana/kibana.yml
server.port:5601 //Kibana打开的端口
server.host:"0.0.0.0" //Kibana侦听的地址
elasticsearch.url: "http://192.168.8.134:9200"
//和Elasticsearch 建立连接
kibana.index:".kibana" //在Elasticsearch中添加.kibana索引
启动kibana
systemctl start kibana
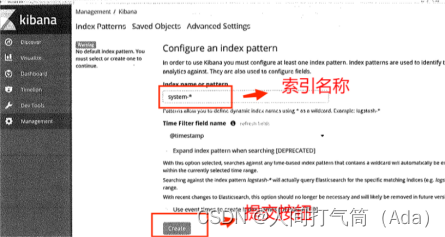
访问kibana :
http://192.168.1.1:5601
首次访问需要添加索引,我们添加前面已经添加过的索引:system-*
八、企业案例:
收集httpd访问日志信息
在httpd服务器上安装logstash,参数上述安装过程,可以不进行测试
logstash在httpd服务器上作为agent(代理),不需要启动
编写httpd日志收集配置文件
vim /etc/logstash/conf.d/httpd.conf
input {
file{
path=>"/var/log/httpd/access_log" //收集Apache访问日志
type => "access" //类型指定为 access
start_position => "beginning" //从开始处收集
}
output{
elasticsearch {
hosts =>["192.168.8.134:9200"] // elasticsearch 监听地址及端口
index =>"httpd_access-%{+YYYY.MM.dd}" //指定索引格式
}
}
使用logstash命令导入配置:
logstash -f /etc/logstash/conf.d/httpd.conf
使用kibana查看即可! http://192.168.1.1:5601 查看时在mangement选项卡创建索引httpd_access-* 即可!
相关文章:
ELK日志收集系统集群实验
ELK日志收集系统集群实验 目录 一、实验拓扑 二、环境配置 三、 安装node1与node2节点的elasticsearch 1. 安装 2.配置 3.启动elasticsearch服务 4.查看节点信息 四、在node1安装elasticsearch-head插件 1.安装node 2.拷贝命令 3.安装elasticsearch-head 4.修改el…...

用Python写了一个下载网站所有内容的软件,可见即可下
目录标题 前言效果展示环境介绍:代码实战获取数据获取视频采集弹幕采集评论 GUI部分尾语 前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! 今天我们分享一个用Python写下载视频弹幕评论的代码。 顺便把这些写成GUI,把这些功能放到一起让朋友用起来更方便~ 效果…...

gin使用embed打包html
embed 使用类似的注释打包html文件 //go:embed pages/dist/* 打包的代码如下 package mainimport ("embed""io/fs""net/http""github.com/gin-gonic/gin" )//go:embed pages/dist/* var embedFs embed.FSfunc main() {e : gin.Defau…...
Android启动优化实践
作者:95分技术 启动优化是Android优化老生常谈的问题了。众所周知,android的启动是指用户从点击 icon 到看到首帧可交互的流程。 而启动流程 粗略的可以分为以下几个阶段 fork创建出一个新的进程创建初始化Application类、创建四大组件等 走Applicatio…...

ROS:通信机制实操
目录 ROS:通信机制一、话题发布实操1.1需求1.2分析1.3实现流程1.4实现代码1.4.1C版1.4.2Python版 1.5执行 二、话题订阅实操2.1需求2.2分析2.3流程2.4实现代码2.4.1启动无辜GUI与键盘控制节点2.4.2C版 ROS:通信机制 一、话题发布实操 1.1需求 编码实现…...
C/C++内存管理(内存分布、动态内存分配、动态内存分配与释放、内存泄漏等)
喵~ 内存之5大区(栈区、堆区、静态区、常量区、代码区)C/C中各自的内存分配操作符内存泄露?内存泄漏检测方法 内存之5大区(栈区、堆区、静态区、常量区、代码区) 1、栈区(stack):由编译器自动分…...

【云原生】软件架构的演进以及各个架构的优缺点
文章目录 1. 什么是软件架构?2. 单机架构3. 应用数据分离架构4. 应用服务集群架构5. 读写分离架构6. 冷热分离架构7.垂直分库架构8. 微服务架构9. 容器编排架构10. 小结 1. 什么是软件架构? 软件架构是指在设计和构建软件系统时,对系统的组织结构、组件、模块、接…...

力扣刷题笔记——二叉树
首先定义二叉树节点的结构体 struct TreeNode{TreeNode* left;TreeNode* right;int val;TreeNode():val(0),left(nullptr),right(nullptr){}TreeNode(int val):val(val),left(nullptr),right(nullptr){}TreeNode(int val,TreeNode* l,TreeNode* R):val(val),left(l),right(R){…...
)
【华为OD机试】工号不够用了怎么办?(python, java, c++, js)
工号不够用了怎么办? 前言:本专栏将持续更新华为OD机试题目,并进行详细的分析与解答,包含完整的代码实现,希望可以帮助到正在努力的你。关于OD机试流程、面经、面试指导等,如有任何疑问,欢迎联系我,wechat:steven_moda;email:nansun0903@163.com;备注:CSDN。 题目…...

【leetcode】198. 打家劫舍
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。 给定一个代表每个房屋存放金额的非…...

【react全家桶学习】react的 (新/旧) 生命周期(重点)
目录 生命周期(旧) 挂载时的生命周期 constructor(props) componentWillMount()-------------新生命周期已替换 render() componentDidMount()--- 组件…...

Gradio私网和公网的使用
Gradio私网问题 如果部署的服务器只有私有地址,那么无法直接从外部网络中的其他计算机访问该服务器和其中运行的 Gradio 应用程序。在这种情况下,你可以考虑使用端口转发技术,将服务器的私有地址映射到一定的公开地址上,从而可以…...
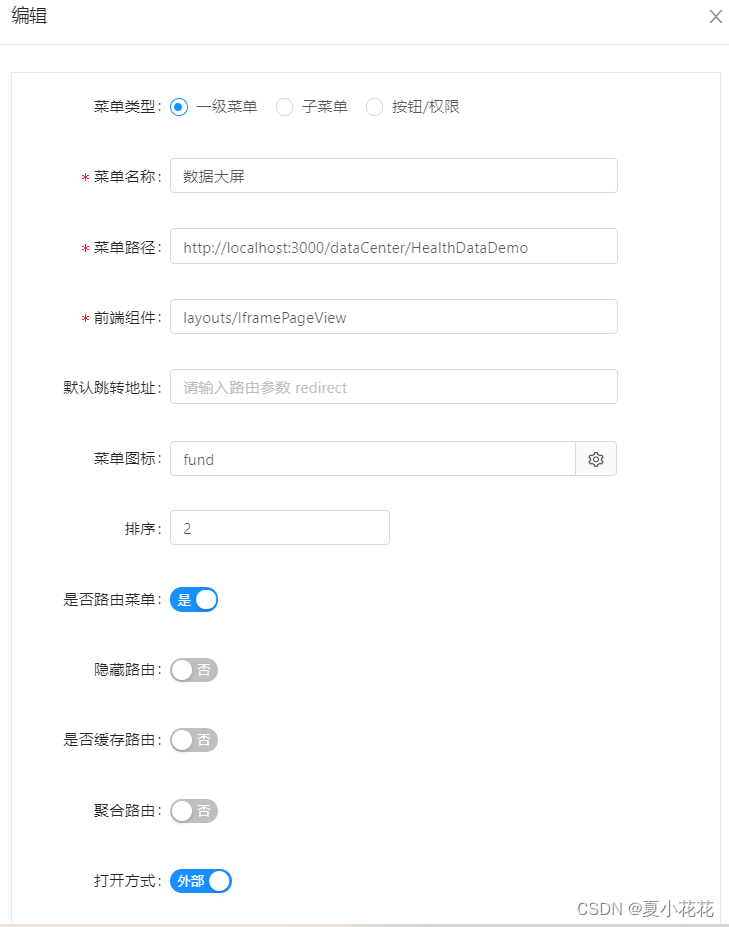
ant design vue 配置菜单外部打开
实现如下 菜单配置 前端项目地址:http://localhost:3000 菜单路径:dataCenter/HealthData 打开方式:外部 在项目中src-->config-->router.config.js文件 将需要再外部打开的菜单地址进行如下配置 菜单地址:/dataCenter/Hea…...

YOLOv5/v7 添加注意力机制,30多种模块分析⑦,CCN模块,GAMAttention模块
目录 一、注意力机制介绍1、什么是注意力机制?2、注意力机制的分类3、注意力机制的核心 二、CCN模块1、CCN模块的原理2、实验结果3、应用示例 三、GAMAttention模块1、GAMAttention模块的原理2、实验结果3、应用示例 大家好,我是哪吒。 🏆本…...
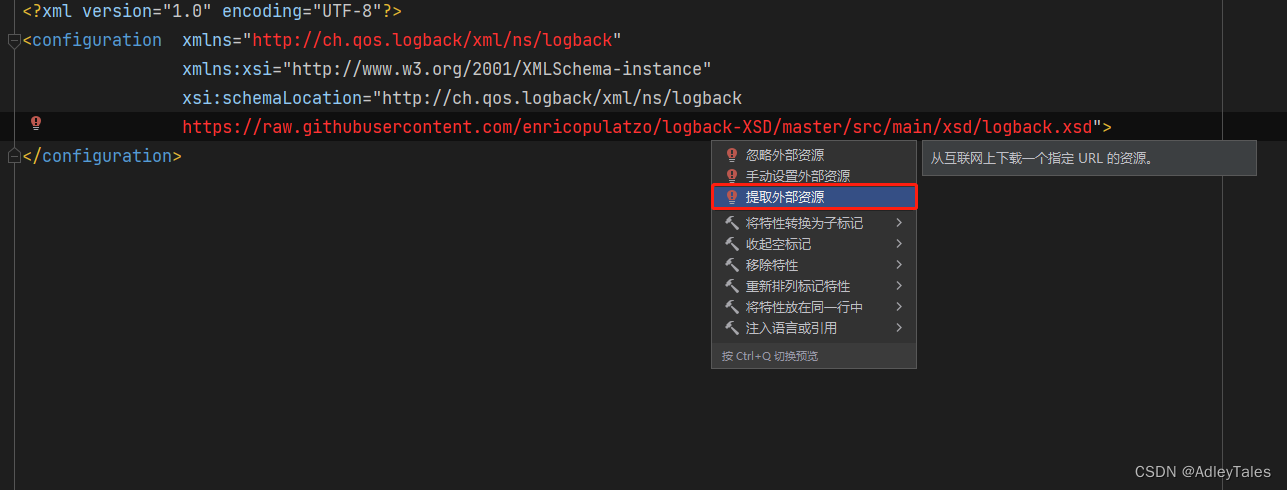
IDEA下Logback.xml自动提示功能配置
首先打开logback的配置文件,在configuration标签中加入xsd的配置 <configuration xmlns"http://ch.qos.logback/xml/ns/logback"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://ch.qos.logback/xml…...
)
CUDA编程模型系列八(原子操作 / 规约 / 向量元素求和)
本系列视频目的是帮助开发者们一步步地学会利用CUDA编程模型加速GPU应用, 我们的口号是: 让GPU飞起来 本期我介绍了cuda 当中规约算法的一种情况, 也是小何尚职业生涯中的第一道面试题, 计算数组中所有元素的和. CUDA编程模型系列八(原子操作 / 规约 / 向量元素求和) #include…...
)
go语言系列基础教程总结(4)
1、goroutine和channel 每执行一次go func()就创建一个 goroutine,包含要执行的函数和上下文信息。 goroutine 是Go程序并发的执行体,channel是它们之间的沟通连接通道。 var ch1 chan int. //声明一个整型的通道 2、channel 常用操作 //定义一个…...
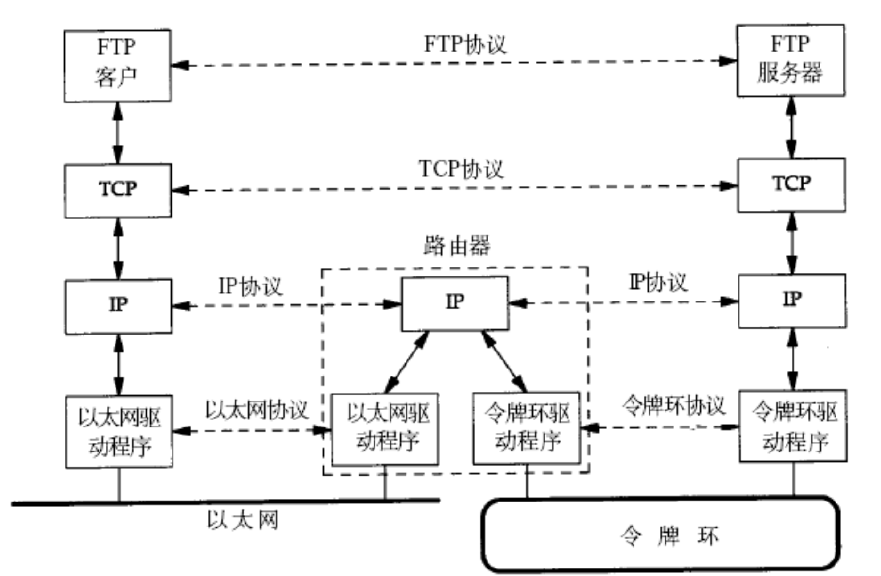
网络基础一:网络协议初识与网络传输基本流程
目录 网络协议认识“协议”网络协议初识协议分层OSI七层模型(理论模型)TCP/IP五层(或四层)模型(工程实现模型) 网络中的地址管理MAC地址IP地址 网络传输基本流程路由的本质 数据包封装和分用网络协议需要解决的问题 网络协议 计算…...

Mysql找出执行慢的SQL【慢查询日志使用与分析】
分析慢SQL的步骤 慢查询的开启并捕获:开启慢查询日志,设置阈值,比如超过5秒钟的就是慢SQL,至少跑1天,看看生产的慢SQL情况,并将它抓取出来explain 慢SQL分析show Profile。(比explain还要详细…...
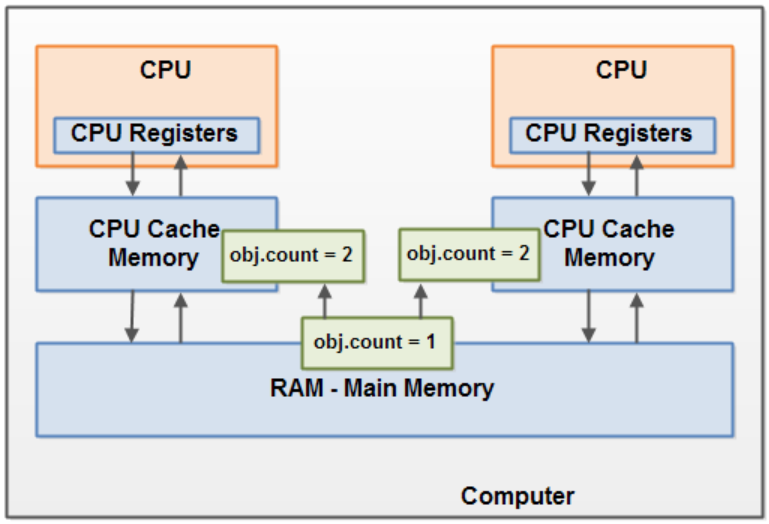
设计模式3:单例模式:JMM与volatile和synchronized的关系
本文目录 JMM简介Java 内部内存模型(The Internal Java Memory Model)硬件内存架构(Hardware Memory Architecture)弥合 Java 内存模型和硬件内存架构之间的差距(Bridging The Gap Between The Java Memory Model And The Hardware Memory Architecture)1.共享对象的可见性2.竞…...

避开这些坑!在PX4 1.14.0上添加自定义串口传感器的完整避坑指南
PX4 1.14.0自定义串口传感器开发实战:从设备注册到数据解析全链路避坑指南 当你在PX4飞控上尝试接入一款新型激光雷达时,是否遇到过这样的场景:按照官方文档一步步操作,编译通过后却发现传感器始终无法输出有效数据?本…...

车载Java OTA升级崩溃率从18.7%降至0.3%:基于Delta Patch + 类隔离热修复的4步标准化流程
第一章:车载Java OTA升级崩溃率从18.7%降至0.3%:基于Delta Patch 类隔离热修复的4步标准化流程在车载嵌入式Java环境(JVM 11,ART兼容层)中,OTA升级引发的ClassCastException与NoClassDefFoundError曾导致高…...
)
安规设计规范-3(如何计算电气间隙和爬电距离)
详尽的计算方式建议参考各个标准的要求,本文只指出常规的基础计算流程。以下示例严格遵循 GB/T 16935.1-2023/IEC 60664-1:2020《低压系统内设备的绝缘配合》,选用储能 PCS(储能变流器)最常见的230V AC 电网侧对低压控制侧场景&am…...

2026年高压电磁阀制造厂大比拼:哪家更值得信赖?
在工业领域,高压电磁阀是许多关键系统的核心部件,其性能和可靠性直接关系到整个系统的稳定性和安全性。随着技术的不断进步和市场需求的多样化,选择一家值得信赖的高压电磁阀制造厂变得尤为重要。本文将从多个维度对比分析几家主流高压电磁阀…...

从 DEFINE VIEW 走向 DEFINE VIEW ENTITY:把 CDS View 迁移到 CDS View Entity 的方法、边界与实战心法
围绕 CDS View Entity 迁移这条主线,下面把概念演进、工具链、风险识别、手工改造要点以及项目落地策略完整梳理一遍。文章既适合还在维护传统 CDS DDIC-based view 的团队,也适合正在推进 S/4HANA、ABAP Cloud、RAP、Clean Core 的开发团队参考。 CDS View Entity 在 ABAP …...

抖音下载器:从零开始,轻松获取无水印视频的完整指南
抖音下载器:从零开始,轻松获取无水印视频的完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallb…...

别死记硬背了!一张图带你理清编译原理‘语法制导翻译’到‘代码优化’的核心链路
编译原理核心链路解析:从语法制导翻译到代码优化的实战指南 编译原理作为计算机科学的重要基石,常常让学习者感到知识点零散、难以形成系统认知。本文将以赋值语句为例,通过清晰的逻辑链路,展示从源代码到优化代码的完整编译过程&…...

收藏!小白也能看懂的大模型推理能力训练与未来趋势深度解析
文章讨论了大模型的发展历程,从早期的“读很多书”模式到引入“思考”能力的转变。重点介绍了推理式思考与智能体式思考的区别,以及Qwen团队在模型训练中的经验与挑战。文章指出,未来的重心将从单纯训练模型“思考”转向训练智能体“边想边做…...

RT-Thread下STM32与BH1750光照传感器的快速驱动实现
1. RT-Thread与BH1750的完美组合 第一次接触BH1750光照传感器时,我还在用裸机开发。当时为了调试IIC通讯,整整花了两天时间排查时序问题。后来接触到RT-Thread,发现它的软件包生态简直是为传感器开发量身定制的。就拿BH1750来说,官…...

AI辅助开发新范式:让快马AI优化你的17.143.cv模型推理管线
AI辅助开发新范式:让快马AI优化你的17.143.cv模型推理管线 最近在做一个实时视频流人物动作识别的项目,用到了17.143.cv库中的姿态估计模型。开发过程中遇到了两个比较棘手的问题:一是模型在某些帧上的推理速度不够理想,影响了实…...