MIT 6.830数据库系统 -- lab two
MIT 6.830数据库系统 -- lab two
- 项目拉取
- Lab Two
- 实现提示
- 练习一 -- Filter and Join
- 练习二 -- Aggregates
- 练习三 -- HeapFile Mutability
- 练习四 -- Insertion & deletion
- 练习五 -- Page eviction
- 练习六 -- Query walkthrough
- 练习七 - 查询解析
项目拉取
原项目使用ant进行项目构建,我已经更改为Maven构建,大家直接拉取我改好后的项目即可:
- https://gitee.com/DaHuYuXiXi/simple-db-hw-2021
然后就是正常的maven项目配置,启动即可。各个lab的实现,会放在lab/分支下。
Lab Two
lab2必须在lab1提交的代码基础上进行开发,否则无法完成相应的练习。此外,实验还提供了源码中不存在的额外测试文件。
实现提示
开始编写代码之前,强烈建议通读整篇文档,以对SimpleDB的设计有个整体的认识,对于我们编写代码非常有帮助
建议跟着文档的练习来实现对应的代码,每个练习都标明了要实现哪个类以及通过哪些单元测试,跟着练习走即可。
下面是本实验的大致流程:
- 实现Filter和Join操作并且通过相关的单元测试验证你的实现,阅读类的Javadoc将会帮助我们实现。项目中已经提供了Project和OrderBy操作的实现,阅读其代码能够帮助我们理解其他操作是如何实现的
- 实现IntegerAggregator和StringAggregator,你将会编写对元组的某一特定列分组进行聚合操作;其中integer支持求和、求最大最小值、求数量、求平均值,string只支持count聚合操作
- 实现Aggregate操作;同其他操作一样,聚合操作也实现类OpIterator接口。注意每次调用next()的Aggregate操作的输出是整个分组的聚合值,Aggregate构造函数将会设置聚合和分组操作对应的列
- 实现BufferPool类中的插入、删除和页面丢弃策略,暂时不需要关心事务
- 实现Insert和Delete操作;与所有的操作相似,Insert和Delete实现OpIterator接口,接收用于插入或者删除的元组并输出该操作影响的元组个数;这些操作将会调用BufferPool中合适的方法用于修改磁盘上的页
注意SimpleDB没有实现一致性和完整性检查,所以它可能会插入重复的记录,并且没有方法保证主键或外键的一致性。
在本节实现的基础上,我们需要使用项目提供的SQL解析器去运行SQL语句查询。
最后,你可能会发现本实验的操作扩展Operator类而不是实现OpIterator接口。因为next/hasNext的实现总是重复的、烦人的,Operator实现了通用的逻辑操作,并且仅需要实现readNext方法。可以随意使用这种风格,或者使用OpIterator。如果要实现OpIterator接口,请移除extends Operator,并替换为implements OpIterator。
练习一 – Filter and Join
Filter and Join:
本节将会实现比扫描整张表更有趣的操作:
- Filter:该操作仅返回满足(构造时指定的)Predicate操作的元组;因此,它会过滤那些不符合操作的元组
- Join:该操作将会通过(构造时指定的)JoinPredicate联合两个表的元组,Join操作仅需实现一个简单的嵌套循环连接
实现如下类中的方法:
- src/java/simpledb/execution/Predicate.java
- src/java/simpledb/execution/JoinPredicate.java
- src/java/simpledb/execution/Filter.java
- src/java/simpledb/execution/Join.java
Predict和JoinPredict分别负责普通的断言和Join断言的操作:
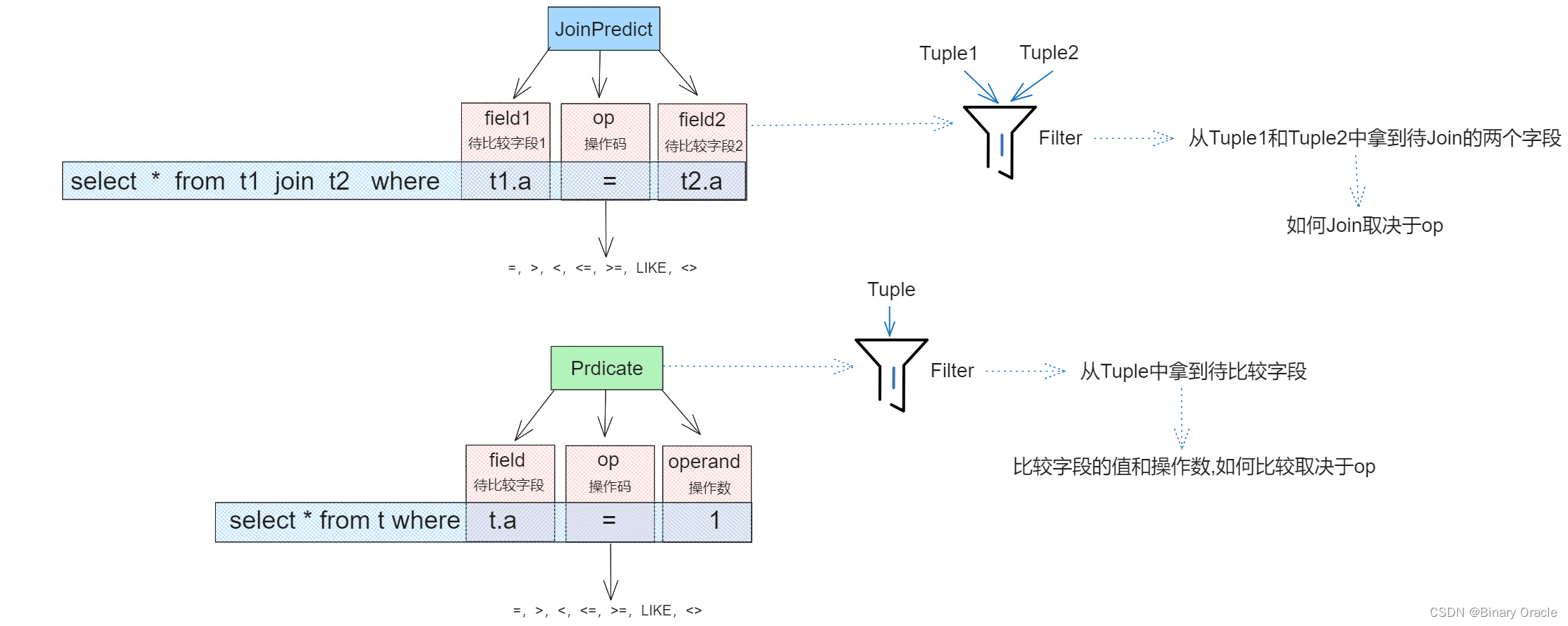
Predict类核心源码如下:
/*** Predicate compares tuples to a specified Field value.* 比较元组某个特定的字段--> select * from t where t.a=1;*/
public class Predicate implements Serializable {private static final long serialVersionUID = 1L;/*** 待比较字段*/private final int field;/*** 操作码*/private final Op op;/*** 操作数*/private final Field operand;/*** Constants used for return codes in Field.compare*/public enum Op implements Serializable {EQUALS, GREATER_THAN, LESS_THAN, LESS_THAN_OR_EQ, GREATER_THAN_OR_EQ, LIKE, NOT_EQUALS;/*** Interface to access operations by integer value for command-line* convenience.*/public static Op getOp(int i) {return values()[i];}public String toString() {if (this == EQUALS)return "=";if (this == GREATER_THAN)return ">";if (this == LESS_THAN)return "<";if (this == LESS_THAN_OR_EQ)return "<=";if (this == GREATER_THAN_OR_EQ)return ">=";if (this == LIKE)return "LIKE";if (this == NOT_EQUALS)return "<>";throw new IllegalStateException("impossible to reach here");}}public Predicate(int field, Op op, Field operand) {this.field = field;this.op = op;this.operand = operand;}/*** Compares the field number of t specified in the constructor to the* operand field specified in the constructor using the operator specific in* the constructor. The comparison can be made through Field's compare* method.*/public boolean filter(Tuple t) {if (t == null) {return false;}Field f = t.getField(this.field);return f.compare(this.op, this.operand);}. . .
}
JoinPredict类核心源码如下:
/*** JoinPredicate compares fields of two tuples using a predicate. JoinPredicate* is most likely used by the Join operator.* 用于JOIN连接断言的两个元组的某个字段 --> select * from t1 join t2 on t1.id=t2.id;*/
public class JoinPredicate implements Serializable {private static final long serialVersionUID = 1L;/*** 字段1*/private final int field1;/*** 操作码*/private final Predicate.Op op;/*** 字段2*/private final int field2;public JoinPredicate(int field1, Predicate.Op op, int field2) {this.field1 = field1;this.op = op;this.field2 = field2;}/*** Apply the predicate to the two specified tuples. The comparison can be* made through Field's compare method.*/public boolean filter(Tuple t1, Tuple t2) {if (t1 == null) {return false;}if (t2 == null) {return false;}Field first = t1.getField(field1);Field second = t2.getField(field2);return first.compare(this.op, second);}...
}
OpIterator意为可操作迭代器,在SimpleDB中的含义为: 迭代器遍历元素的时候可以同时进行一些操作,具体遍历时执行什么操作由子类决定。
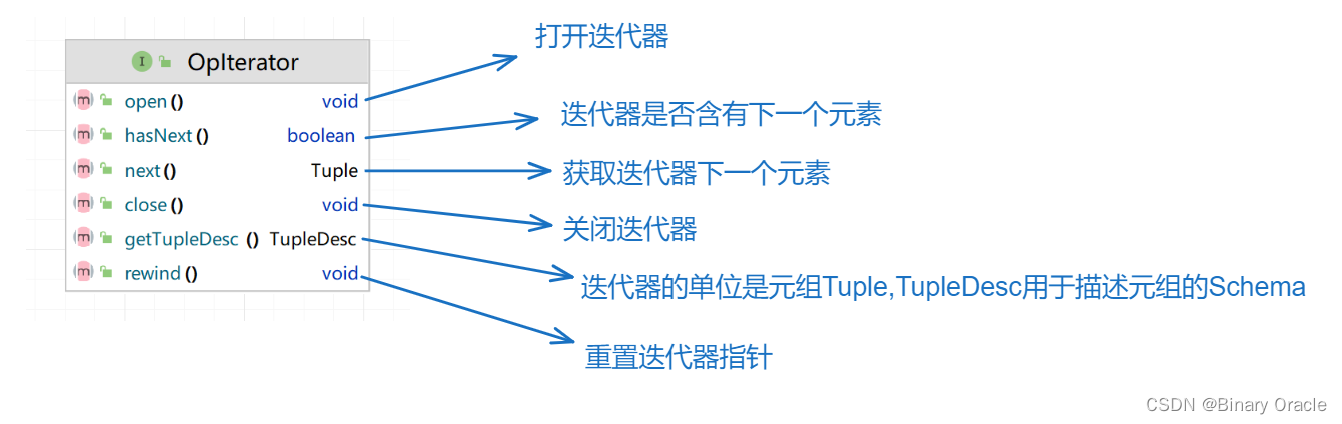
操作迭代器意味着迭代器自身在遍历数据时,会根据自身实现搞点事情,Operator接口模板化了部分流程,各个需要在迭代器遍历时进行操作的子类,只需要去实现readNext这个核心方法,并且每次获取下一个元组的时候,搞点事情即可。
这里不是说子类只需要去实现readNext方法,而是说readNext是子类需要实现的核心方法,其他均为辅助方法。
Operator类的核心源码如下:
/*** Abstract class for implementing operators. It handles close, next and hasNext. Subclasses only need to implement open and readNext.*/
public abstract class Operator implements OpIterator {public boolean hasNext() throws DbException, TransactionAbortedException {if (!this.open)throw new IllegalStateException("Operator not yet open");if (next == null)next = fetchNext();return next != null;}public Tuple next() throws DbException, TransactionAbortedException,NoSuchElementException {if (next == null) {next = fetchNext();if (next == null)throw new NoSuchElementException();}Tuple result = next;next = null;return result;}protected abstract Tuple fetchNext() throws DbException,TransactionAbortedException;/*** Closes this iterator. If overridden by a subclass, they should call* super.close() in order for Operator's internal state to be consistent.*/public void close() {// Ensures that a future call to next() will failnext = null;this.open = false;}private Tuple next = null;private boolean open = false;public void open() throws DbException, TransactionAbortedException {this.open = true;}/*** @return return the children DbIterators of this operator. If there is* only one child, return an array of only one element. For join* operators, the order of the children is not important. But they* should be consistent among multiple calls.* */public abstract OpIterator[] getChildren();/*** Set the children(child) of this operator. If the operator has only one* child, children[0] should be used. If the operator is a join, children[0]* and children[1] should be used.* */public abstract void setChildren(OpIterator[] children);/*** @return return the TupleDesc of the output tuples of this operator* */public abstract TupleDesc getTupleDesc();...
}
- 迭代器调用约定: 先调用hasNext判断是否还有下一个元素,如果有调用next获取下一个元素,并且调用hashNext前需要先调用Open。
- OpIterator操作迭代器分为两部分,一部分是原始职能: 提供数据进行迭代遍历; 另一部分是附加职能: 在原始迭代器遍历过程中进行操作。
- Operator采用装饰器模式封装原始迭代器遍历行为,并在其基础上增加了遍历时进行操作的行为。
- 装饰器模式需要有被装饰的对象,这里通过setChildren进行设置,但是这里与普通的装饰器模式不同,因为不同的操作会涉及到不同的个数的被装饰对象。
- select * from t where t.age=18 --> 此处实际使用了单值比较过滤操作,所以只涉及单表的迭代器
- select * from t1 join t2 on t1.age=t2.age --> 此时实际使用了两表JOIN操作,所以涉及两个表的迭代器
SimpleDB整个迭代器的设计思路采用了装饰器模式实现,具体如下图所示:
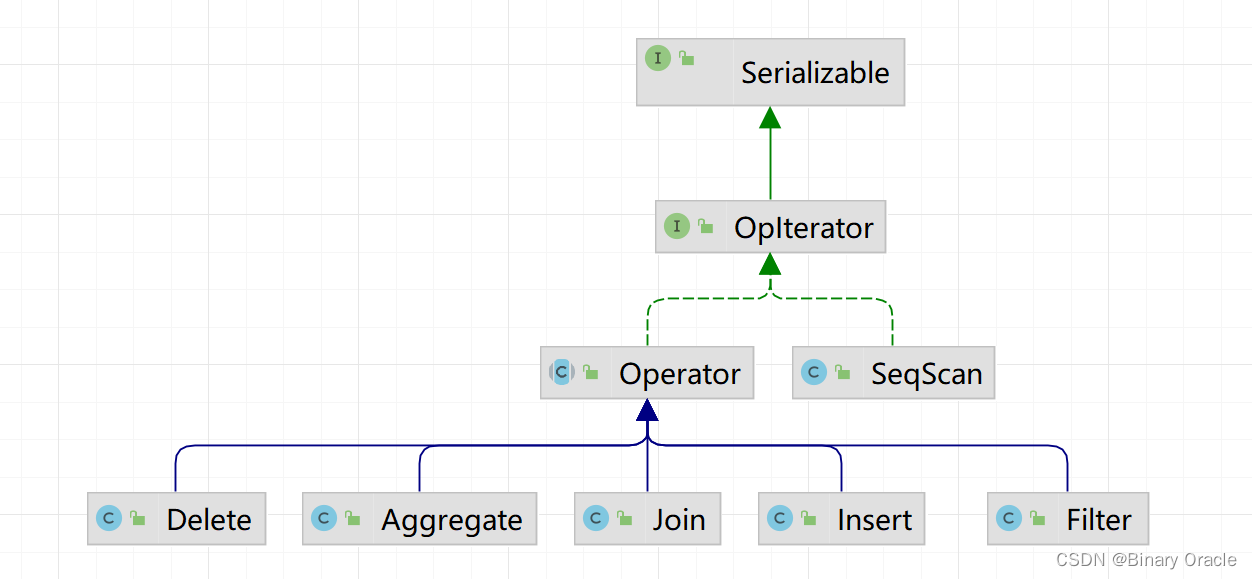
- Operator的实现类都是装饰器,而SeqScan是迭代器的实现,也就是被装饰的对象
迭代器模式的用法可以参考Java IO整体架构实现。
Filter用于单值比较操作,具体流程如下:
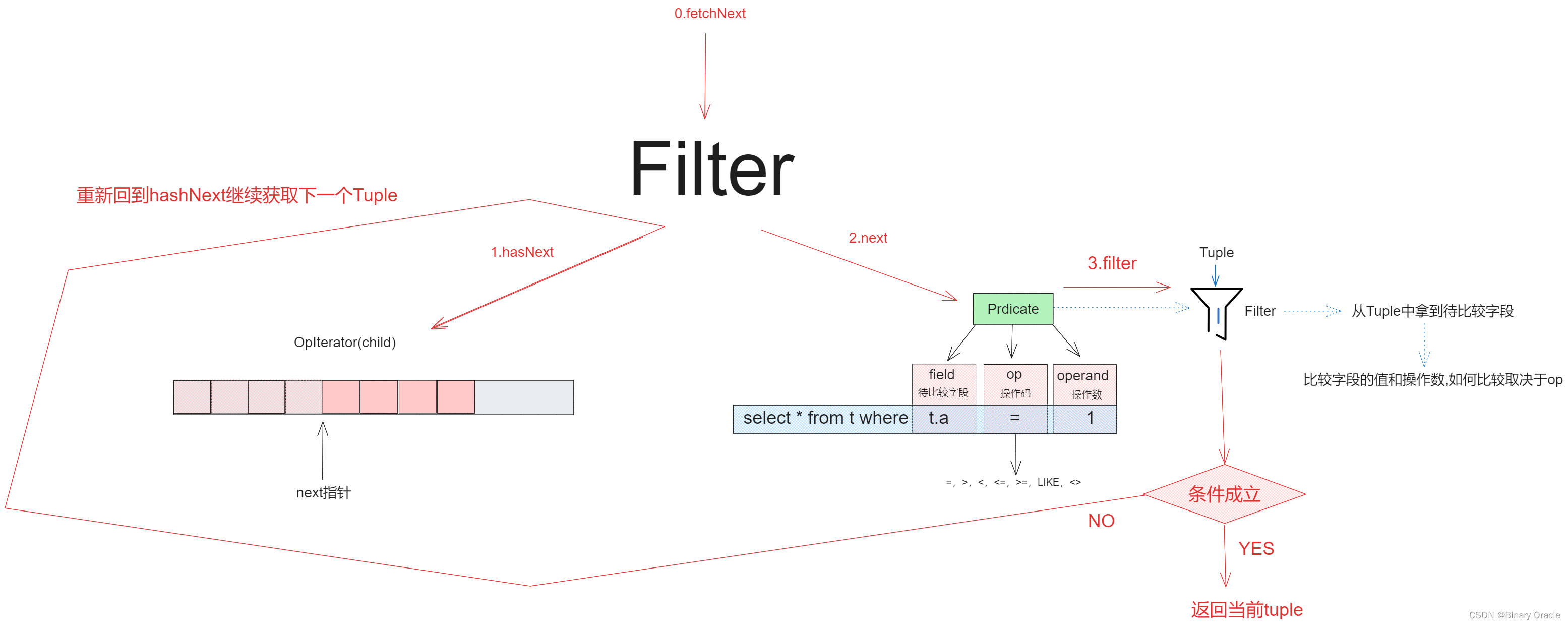
图中只展示的一层装饰,如果存在多层装饰,那么child仍然是个装饰器,可以利用多层装饰实现如: select * from t where t.age=18 and t.name="dhy"的匹配过滤。
Filter核心源码如下:
/*** Filter is an operator that implements a relational select.*/
public class Filter extends Operator {private final Predicate predicate;private OpIterator child;/*** Constructor accepts a predicate to apply and a child operator to read* tuples to filter from.*/public Filter(Predicate p, OpIterator child) {this.predicate = p;this.child = child;}public void open() throws DbException, NoSuchElementException,TransactionAbortedException {super.open();this.child.open();}public void close() {this.child.close();super.close();}public void rewind() throws DbException, TransactionAbortedException {this.child.rewind();}/*** AbstractDbIterator.readNext implementation. Iterates over tuples from the* child operator, applying the predicate to them and returning those that* pass the predicate (i.e. for which the Predicate.filter() returns true.)* */protected Tuple fetchNext() throws NoSuchElementException,TransactionAbortedException, DbException {while (this.child.hasNext()) {Tuple tuple = this.child.next();if (this.predicate.filter(tuple)) {return tuple;}}return null;}@Overridepublic OpIterator[] getChildren() {return new OpIterator[] {this.child};}@Overridepublic void setChildren(OpIterator[] children) {this.child = children[0];}...
}
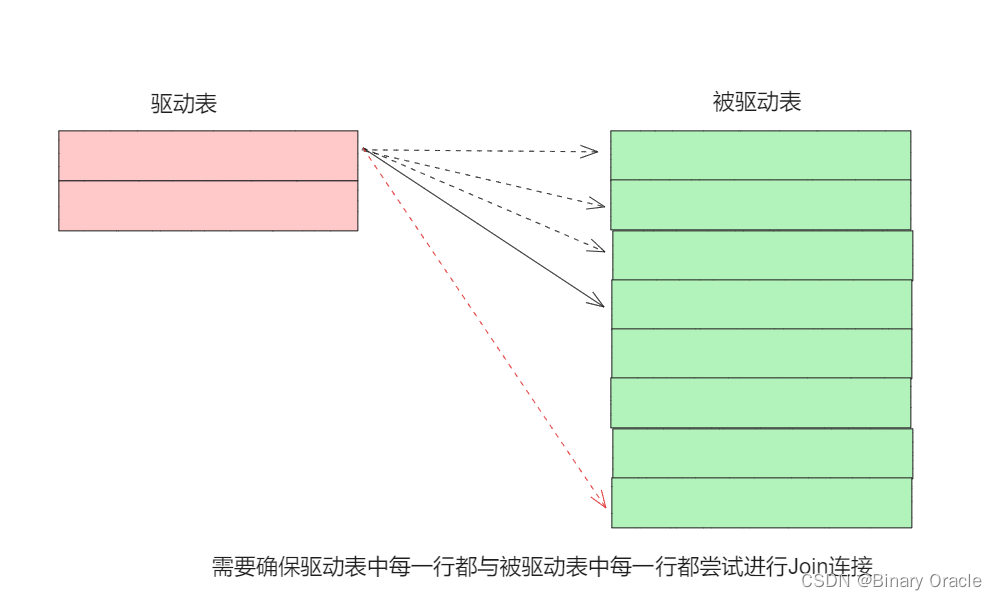
Join用于连接条件判断,流程如下:
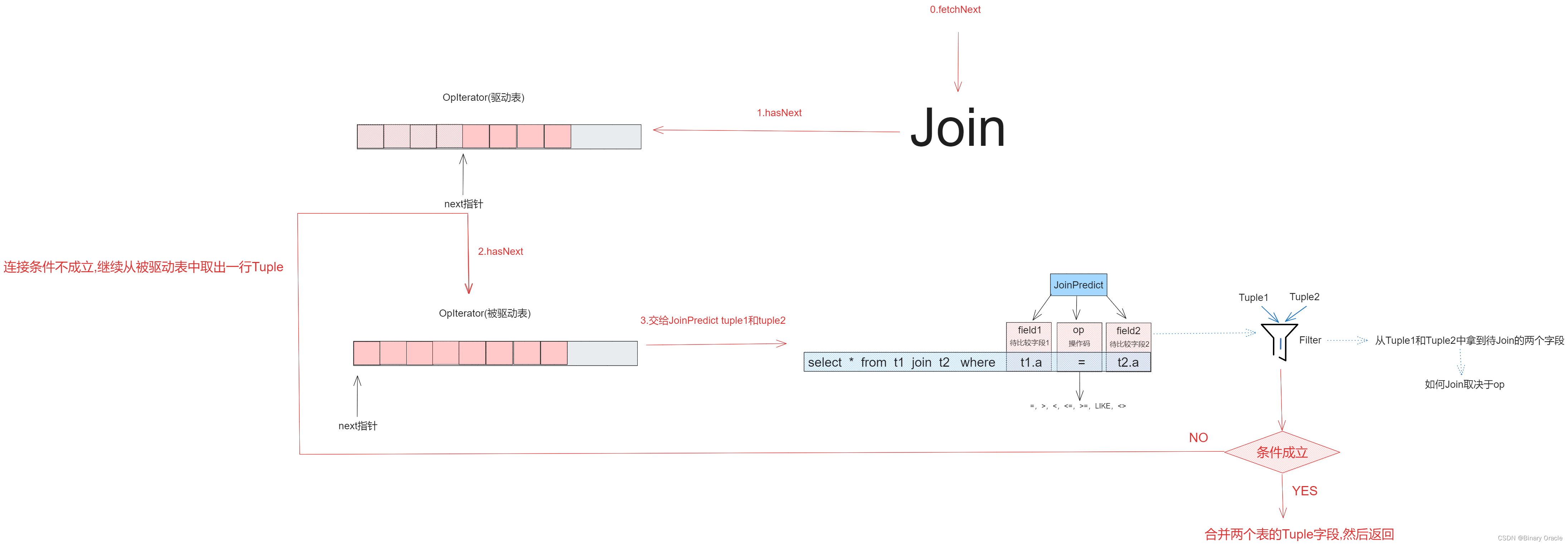
Join的核心源码如下:
/*** The Join operator implements the relational join operation.*/
public class Join extends Operator {private static final long serialVersionUID = 1L;/*** 连接条件*/private final JoinPredicate predicate;/*** 参与连接的表*/private OpIterator[] children;private Tuple tuple1;/*** Constructor. Accepts two children to join and the predicate to join them* on* @param p The predicate to use to join the children* @param child1 Iterator for the left(outer) relation to join* @param child2 Iterator for the right(inner) relation to join*/public Join(JoinPredicate p, OpIterator child1, OpIterator child2) {this.predicate = p;this.children = new OpIterator[]{child1, child2};this.tuple1 = null;}/*** 返回的是两表连接后得到结果的行schema*/public TupleDesc getTupleDesc() {return TupleDesc.merge(this.children[0].getTupleDesc(), this.children[1].getTupleDesc());}public void open() throws DbException, NoSuchElementException,TransactionAbortedException {for (OpIterator child : this.children) {child.open();}super.open();}public void close() {for (OpIterator child : this.children) {child.close();}super.close();}public void rewind() throws DbException, TransactionAbortedException {for (OpIterator child : this.children) {child.rewind();}}/*** Returns the next tuple generated by the join, or null if there are no* more tuples. Logically, this is the next tuple in r1 cross r2 that* satisfies the join predicate. There are many possible implementations;* the simplest is a nested loops join.* <p>* Note that the tuples returned from this particular implementation of Join* are simply the concatenation of joining tuples from the left and right* relation. Therefore, if an equality predicate is used there will be two* copies of the join attribute in the results. (Removing such duplicate* columns can be done with an additional projection operator if needed.)* <p>* For example, if one tuple is {1,2,3} and the other tuple is {1,5,6},* joined on equality of the first column, then this returns {1,2,3,1,5,6}.** @return The next matching tuple.* @see JoinPredicate#filter*/protected Tuple fetchNext() throws TransactionAbortedException, DbException {// 双重循环,将children[0]作为驱动表,children[1]作为被驱动表while (this.children[0].hasNext() || tuple1 != null) {// 获取驱动表的一行记录if (this.children[0].hasNext() && tuple1 == null) {tuple1 = this.children[0].next();}// 获取被驱动表的一行记录while (this.children[1].hasNext()) {Tuple tuple2 = this.children[1].next();// JoinPredicate判断join条件是否成立if (this.predicate.filter(tuple1, tuple2)) {// 获取驱动表schema和被驱动表schema合并后的schemaTupleDesc tupleDesc = getTupleDesc();// 用于承载合并后的行记录Tuple res = new Tuple(tupleDesc);int i = 0;// 拿到驱动表当前行的所有字段,然后设置到resIterator<Field> fields1 = tuple1.fields();while (fields1.hasNext() && i < tupleDesc.numFields()) {res.setField(i++, fields1.next());}// 拿到被驱动表当前行的所有字段,然后设置到resIterator<Field> fields2 = tuple2.fields();while (fields2.hasNext() && i < tupleDesc.numFields()) {res.setField(i++, fields2.next());}// 被驱动表遍历完了,重置指针,同时将tuple1也重置if (!this.children[1].hasNext()) {this.children[1].rewind();tuple1 = null;}// 返回捞到的记录return res;}}// 驱动表当前行在被驱动表中没有匹配行,那么将被驱动表迭代指针复原this.children[1].rewind();tuple1 = null;}// 没有匹配记录return null;}@Overridepublic OpIterator[] getChildren() {return this.children;}@Overridepublic void setChildren(OpIterator[] children) {this.children=children;}}
关于tuple1属性作用说明:
- 我们从驱动表中获取一条记录后,需要遍历被驱动表,在被驱动表中找出所有符合连接条件的行,然后拼接两表字段,然后返回结果
- fetchNext方法每调用一次,都会返回符合条件的一行记录,因此我们需要保留驱动表当前正在匹配的行,等到某一次fetchNext方法调用时,发现当前行与被驱动表每一行都进行了一次匹配后,才会从驱动表中取出下一行进行匹配。
练习二 – Aggregates
Aggregates:
本节我们应该实现如下五种聚合操作:count、sum、avg、min、max,并且支持分组聚合操作。仅支持对一个域进行聚合,对一个域进行分组即可。
为了实现聚合操作,我们使用Aggregator接口将新的元组合并到现有的聚合操作结果中。实际进行哪种聚合操作会在构造Aggregate时指明。所以,客户端代码需要为子操作的每个元组调用Aggregator.mergeTupleIntoGroup()方法,当所有的元组都被合并完成以后,客户端将会获得聚合操作的结果。
- 如果指定分组的话,那么返回结果格式为: (groupValue, aggregateValue);
- 没有指定分组的话,返回格式为:(aggregateValue)
本节实验中,我们不需要担心分组的数量超过可用内存的限制。
实现如下类中的方法:
- src/java/simpledb/execution/IntegerAggregator.java
- src/java/simpledb/execution/StringAggregator.java
- src/java/simpledb/execution/Aggregate.java
Aggregator聚合器干的事情就是接收传入的Tuple,然后内部进行计算,当我们传入n个tuple后,我们可以调用聚合器的迭代器,获取当前聚合的结果:
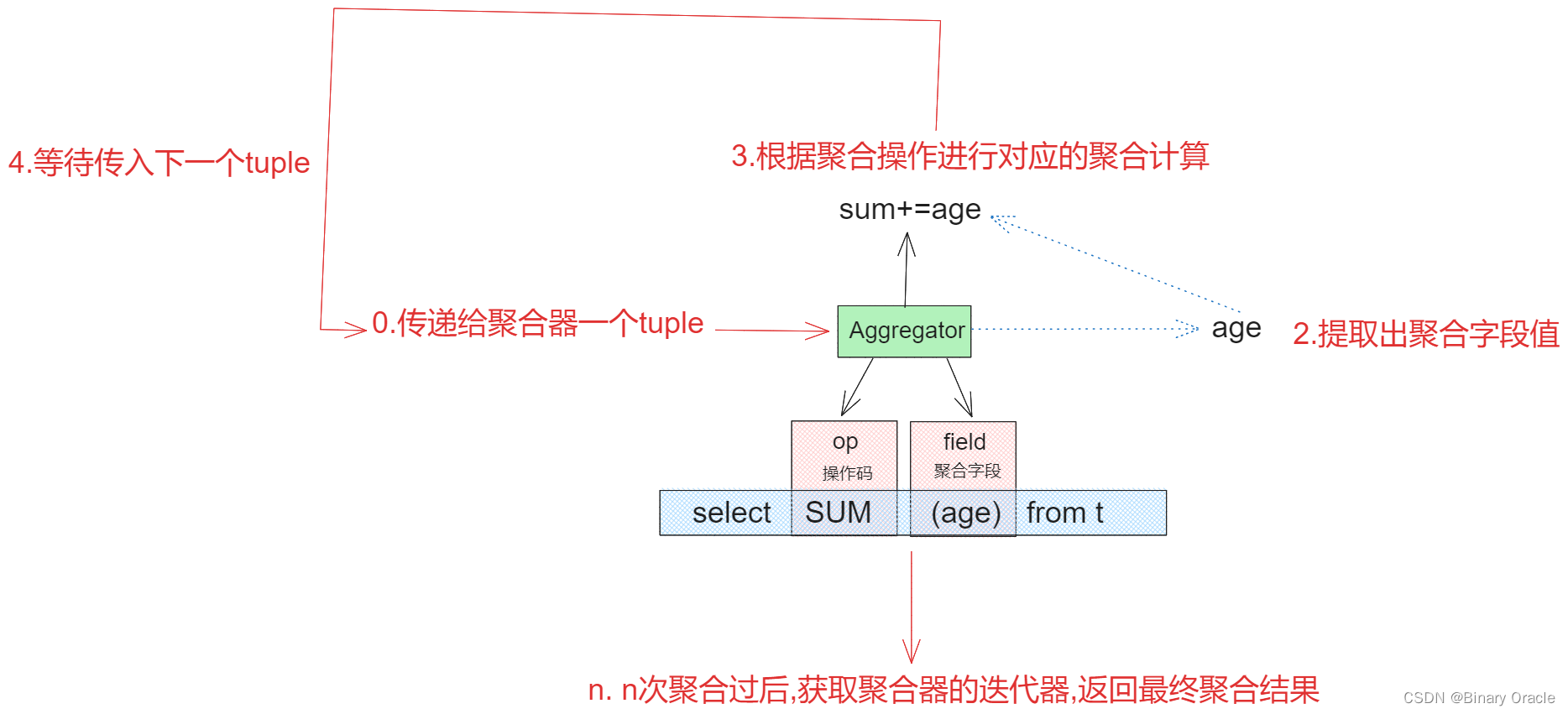
上面给出的是不涉及分组的聚合操作,如果涉及分组的话,聚合过程如下图所示:
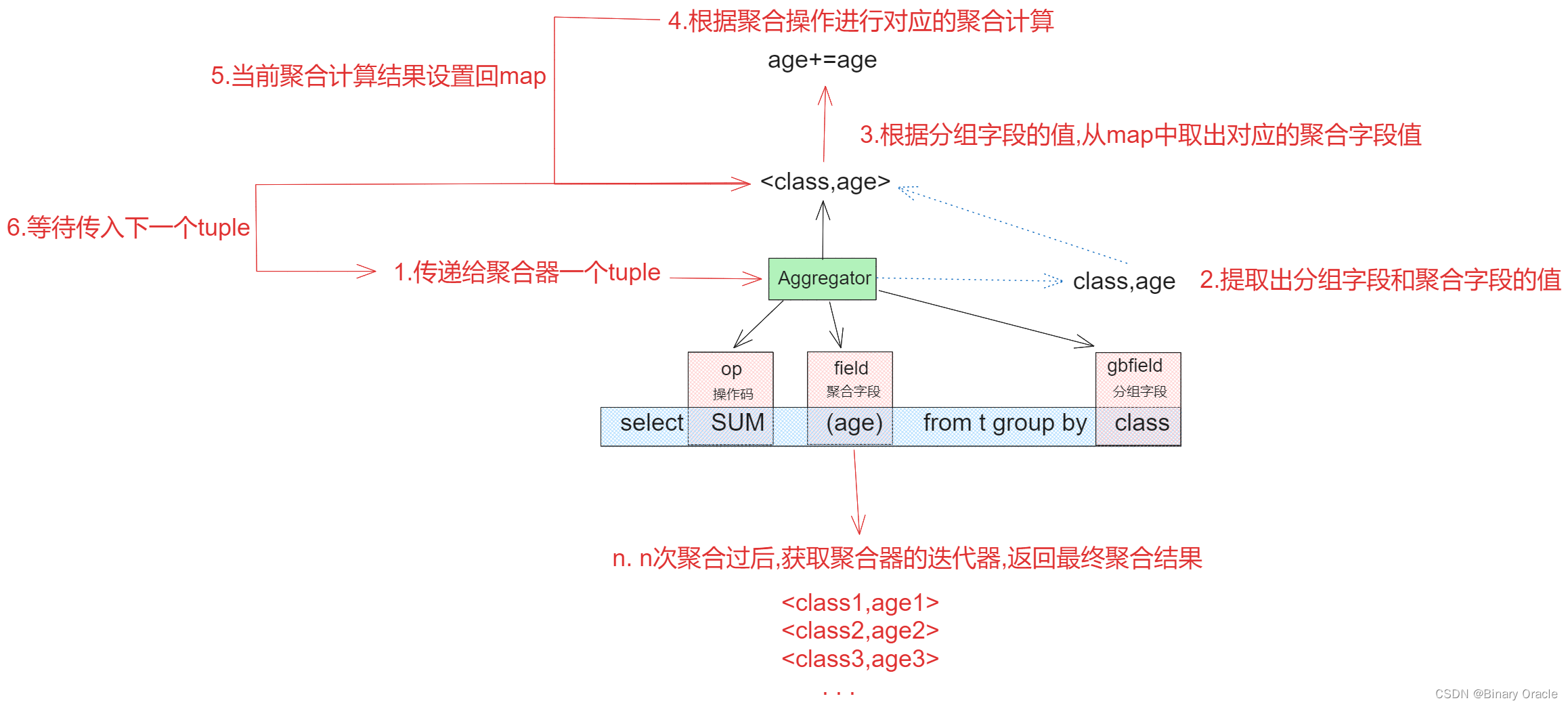
Aggregator聚合器接口定义如下:
/*** The common interface for any class that can compute an aggregate over a* list of Tuples.*/
public interface Aggregator extends Serializable {int NO_GROUPING = -1;/*** SUM_COUNT and SC_AVG will* only be used in lab7, you are not required* to implement them until then.* */enum Op implements Serializable {MIN, MAX, SUM, AVG, COUNT,/*** SUM_COUNT: compute sum and count simultaneously, will be* needed to compute distributed avg in lab7.* */SUM_COUNT,/*** SC_AVG: compute the avg of a set of SUM_COUNT tuples,* will be used to compute distributed avg in lab7.* */SC_AVG;...}/*** Merge a new tuple into the aggregate for a distinct group value;* creates a new group aggregate result if the group value has not yet* been encountered.** @param tup the Tuple containing an aggregate field and a group-by field*/void mergeTupleIntoGroup(Tuple tup);/*** Create a OpIterator over group aggregate results.* @see TupleIterator for a possible helper*/OpIterator iterator();}
对于不同类型字段的聚合有对应限制,比如: 字符串只支持COUNT统计个数聚合,不支持例如SUM,AVG等聚合操作。因此针对不兼容的类型,我们需要给出不同的聚合器实现:
- 首先来看比较简单的StringAggregator字符串聚合器,其只支持对COUNT聚合的操作
/*** Knows how to compute some aggregate over a set of StringFields.*/
public class StringAggregator implements Aggregator {private static final IntField NO_GROUP = new IntField(-1);/*** 用于分组*/private int gbfield;private Type gbfieldtype;/*** 用于聚合*/private int afield;private Op what;/*** 存放结果-- 分组聚合返回的是多组键值对,分别代表分组字段不同值对应的聚合结果* 非分组聚合只会返回一个聚合结果,这里为了统一化处理,采用NO_GROUP做标记,进行区分*/private Map<Field, Tuple> tupleMap;private TupleDesc desc;/*** Aggregate constructor** @param gbfield the 0-based index of the group-by field in the tuple, or NO_GROUPING if there is no grouping* @param gbfieldtype the type of the group by field (e.g., Type.INT_TYPE), or null if there is no grouping* @param afield the 0-based index of the aggregate field in the tuple* @param what aggregation operator to use -- only supports COUNT* @throws IllegalArgumentException if what != COUNT*/public StringAggregator(int gbfield, Type gbfieldtype, int afield, Op what) {//字符串只支持COUNT聚合操作if (!what.equals(Op.COUNT)) {throw new IllegalArgumentException();}this.gbfield = gbfield;this.gbfieldtype = gbfieldtype;this.afield = afield;this.what = what;this.tupleMap = new ConcurrentHashMap<>();//非分组聚合返回的结果采用占位符进行统一适配if (gbfield == NO_GROUPING) {this.desc = new TupleDesc(new Type[]{Type.INT_TYPE}, new String[]{"aggregateValue"});Tuple tuple = new Tuple(desc);tuple.setField(0, new IntField(0));this.tupleMap.put(NO_GROUP, tuple);} else {//分组聚合返回结果Schema由两个字段组成: 分组字段和聚合结果this.desc = new TupleDesc(new Type[]{gbfieldtype, Type.INT_TYPE}, new String[]{"groupValue", "aggregateValue"});}}/*** Merge a new tuple into the aggregate, grouping as indicated in the constructor** @param tup the Tuple containing an aggregate field and a group-by field*/public void mergeTupleIntoGroup(Tuple tup) {//只支持COUNT聚合if (this.gbfield == NO_GROUPING) {Tuple tuple = tupleMap.get(NO_GROUP);IntField field = (IntField) tuple.getField(0);tuple.setField(0, new IntField(field.getValue() + 1));tupleMap.put(NO_GROUP, tuple);} else {Field field = tup.getField(gbfield);if (!tupleMap.containsKey(field)) {Tuple tuple = new Tuple(this.desc);tuple.setField(0, field);tuple.setField(1, new IntField(1));tupleMap.put(field, tuple);} else {Tuple tuple = tupleMap.get(field);IntField intField = (IntField) tuple.getField(1);tuple.setField(1, new IntField(intField.getValue() + 1));tupleMap.put(field, tuple);}}}/*** Create a OpIterator over group aggregate results.*/public OpIterator iterator() {return new StringIterator(this);}public class StringIterator implements OpIterator {private StringAggregator aggregator;private Iterator<Tuple> iterator;public StringIterator(StringAggregator aggregator) {this.aggregator = aggregator;this.iterator = null;}@Overridepublic void open() throws DbException, TransactionAbortedException {this.iterator = aggregator.tupleMap.values().iterator();}@Overridepublic boolean hasNext() throws DbException, TransactionAbortedException {return iterator.hasNext();}@Overridepublic Tuple next() throws DbException, TransactionAbortedException, NoSuchElementException {return iterator.next();}@Overridepublic void rewind() throws DbException, TransactionAbortedException {iterator = aggregator.tupleMap.values().iterator();}@Overridepublic TupleDesc getTupleDesc() {return aggregator.desc;}@Overridepublic void close() {iterator = null;}}...
}
- 其次来看稍微比较复杂的IntegerAggregator整数聚合器,其支持Op枚举中所有聚合操作
/*** Knows how to compute some aggregate over a set of IntFields.* <p/>* 针对int字段进行聚合操作,聚合得到的结果需要是个整数*/
public class IntegerAggregator implements Aggregator {private static final long serialVersionUID = 1L;private static final Field NO_GROUP = new IntField(-1);/*** 用于分组*/private int gbfield;private Type gbfieldType;/*** 用于聚合*/private int afield;private Op what;/*** 存放结果*/private TupleDesc tupleDesc;private Map<Field, Tuple> aggregate;/*** 用于非分组情况下的聚合操作*/private int counts;private int summary;/*** 用于分组情况下的聚合操作*/private Map<Field, Integer> countsMap;private Map<Field, Integer> sumMap;/*** Aggregate constructor** @param gbfield the 0-based index of the group-by field in the tuple, or* NO_GROUPING if there is no grouping* @param gbfieldtype the type of the group by field (e.g., Type.INT_TYPE), or null* if there is no grouping* @param afield the 0-based index of the aggregate field in the tuple* @param what the aggregation operator*/public IntegerAggregator(int gbfield, Type gbfieldtype, int afield, Op what) {//分组字段this.gbfield = gbfield;//分组字段类型this.gbfieldType = gbfieldtype;//聚合得到的结果,在聚合返回结果行中的字段下标this.afield = afield;//进行什么样的聚合操作this.what = what;//存放聚合结果this.aggregate = new ConcurrentHashMap<>();// 非分组聚合if (gbfield == NO_GROUPING) {this.tupleDesc = new TupleDesc(new Type[]{Type.INT_TYPE}, new String[]{"aggregateValue"});Tuple tuple = new Tuple(tupleDesc);//占位符this.aggregate.put(NO_GROUP, tuple);} else {// 分组聚合,那么返回的聚合结果行由分组字段和该分组字段的聚合结果值组成this.tupleDesc = new TupleDesc(new Type[]{gbfieldtype, Type.INT_TYPE}, new String[]{"groupValue", "aggregateValue"});}// 如果聚合操作是AVG,那么需要初始化count和summary变量,用于存放AVG聚合中间计算状态if (gbfield == NO_GROUPING && what.equals(Op.AVG)) {this.counts = 0;this.summary = 0;} else if (gbfield != NO_GROUPING && what.equals(Op.AVG)) {this.countsMap = new ConcurrentHashMap<>();this.sumMap = new ConcurrentHashMap<>();}}/*** Merge a new tuple into the aggregate, grouping as indicated in the* constructor* <p>* 向整数聚合器中添加一行记录,进行分组计算* @param tup the Tuple containing an aggregate field and a group-by field*/public void mergeTupleIntoGroup(Tuple tup) {// 从传递给聚合器的行记录中取出聚合字段的值IntField operationField = (IntField) tup.getField(afield);if (operationField == null) {return;}// 非分组聚合:if (gbfield == NO_GROUPING) {// 拿到承载聚合结果的元组对象Tuple tuple = aggregate.get(NO_GROUP);IntField field = (IntField) tuple.getField(0);// 说明是进行聚合的第一行记录if (field == null) {// 如果聚合是统计个数操作if (what.equals(Op.COUNT)) {// 初值为1tuple.setField(0, new IntField(1));} else if (what.equals(Op.AVG)) {// 如果聚合是求平均值操作// 统计参与聚合的记录个数counts++;// 累加每个值summary = operationField.getValue();// 如果参与聚合的行只存在一个,那么平均值就是当前行的值tuple.setField(0, operationField);} else {// 其他的情况: MIN,MAX,SUM在参与聚合的行只存在一个时,聚合结果就是当前行的值// 所以这里可以统一处理tuple.setField(0, operationField);}return;}// 判断是哪种类型的聚合// 非第一行记录switch (what) {//select MIN(age) from t;case MIN:// 聚合字段的值和当前阶段已经保存的聚合结果进行比较,看谁更小if (operationField.compare(Predicate.Op.LESS_THAN, field)) {tuple.setField(0, operationField);aggregate.put(NO_GROUP, tuple);}return;//select MAX(age) from t;case MAX:// 聚合字段的值和当前阶段已经保存的聚合结果进行比较,看谁更大if (operationField.compare(Predicate.Op.GREATER_THAN, field)) {tuple.setField(0, operationField);aggregate.put(NO_GROUP, tuple);}return;//select COUNT(age) from t;case COUNT:// 计数+1IntField count = new IntField(field.getValue() + 1);tuple.setField(0, count);aggregate.put(NO_GROUP, tuple);return;//select SUM(age) from t;case SUM:// 求和IntField sum = new IntField(field.getValue() + operationField.getValue());tuple.setField(0, sum);aggregate.put(NO_GROUP, tuple);return;//select AVG(age) from t;case AVG:// 求平均值,每次往整数聚合器塞入一条记录时,都会将记录数和总和累加counts++;summary += operationField.getValue();IntField avg = new IntField(summary / counts);tuple.setField(0, avg);aggregate.put(NO_GROUP, tuple);return;default:return;}} else {// 分组聚合操作:// 获取分组字段 --> group by ageField groupField = tup.getField(gbfield);// 如果聚合结果中还不包括当前字段值,说明当前字段是第一次出现// 例如: group by age --> <age=18,count=20> ,如果此次获取的age=20,那么就是第一次出现的分组值if (!aggregate.containsKey(groupField)) {Tuple value = new Tuple(this.tupleDesc);value.setField(0, groupField);if (what.equals(Op.COUNT)) {value.setField(1, new IntField(1));} else if (what.equals(Op.AVG)) {countsMap.put(groupField, countsMap.getOrDefault(groupField, 0) + 1);sumMap.put(groupField, sumMap.getOrDefault(groupField, 0) + operationField.getValue());value.setField(1, operationField);} else {// 其他的情况: MIN,MAX,SUM在参与聚合的行只存在一个时,结果假设当前行的值// 所以这里可以统一处理value.setField(1, operationField);}aggregate.put(groupField, value);return;}// 当前字段不是第一次出现的分组值Tuple tuple = aggregate.get(groupField);// 获取本阶段的聚合结果IntField field = (IntField) tuple.getField(1);switch (what) {case MIN:if (operationField.compare(Predicate.Op.LESS_THAN, field)) {tuple.setField(1, operationField);aggregate.put(groupField, tuple);}return;case MAX:if (operationField.compare(Predicate.Op.GREATER_THAN, field)) {tuple.setField(1, operationField);aggregate.put(groupField, tuple);}return;case COUNT:IntField count = new IntField(field.getValue() + 1);tuple.setField(1, count);aggregate.put(groupField, tuple);return;case SUM:IntField sum = new IntField(field.getValue() + operationField.getValue());tuple.setField(1, sum);aggregate.put(groupField, tuple);return;case AVG:countsMap.put(groupField, countsMap.getOrDefault(groupField, 0) + 1);sumMap.put(groupField, sumMap.getOrDefault(groupField, 0) + operationField.getValue());IntField avg = new IntField(sumMap.get(groupField) / countsMap.get(groupField));tuple.setField(1, avg);aggregate.put(groupField, tuple);return;default:return;}}}public TupleDesc getTupleDesc() {return tupleDesc;}/*** Create a OpIterator over group aggregate results.** @return a OpIterator whose tuples are the pair (groupVal, aggregateVal)* if using group, or a single (aggregateVal) if no grouping. The* aggregateVal is determined by the type of aggregate specified in* the constructor.*/public OpIterator iterator() {return new IntOpIterator(this);}public class IntOpIterator implements OpIterator {private Iterator<Tuple> iterator;private IntegerAggregator aggregator;public IntOpIterator(IntegerAggregator aggregator) {this.aggregator = aggregator;this.iterator = null;}@Overridepublic void open() throws DbException, TransactionAbortedException {this.iterator = aggregator.aggregate.values().iterator();}@Overridepublic boolean hasNext() throws DbException, TransactionAbortedException {return iterator.hasNext();}@Overridepublic Tuple next() throws DbException, TransactionAbortedException, NoSuchElementException {return iterator.next();}@Overridepublic void rewind() throws DbException, TransactionAbortedException {iterator = aggregator.aggregate.values().iterator();}@Overridepublic TupleDesc getTupleDesc() {return aggregator.tupleDesc;}@Overridepublic void close() {iterator = null;}}
}
完成本节练习之后,需要通过PredicateTest, JoinPredicateTest, FilterTest, JoinTest单元测试;并通过FilterTest和JoinTest系统测试。
练习三 – HeapFile Mutability
本节我们将实现修改数据库表文件的方法,我们从单独的页面和文件开始,主要实现两种操作:增加元组和移除元组
- 移除元组:为了移除一个元组,我们需要实现
deleteTuple方法,元组包含RecordIDs可以帮助我们找到它们存储在哪一页,所以定位到元组对应的page并且正确修改page的headers信息就很简单了 - 增加元组:
HeapFile中的insertTuple方法主要用于向数据库文件添加一个元组。为了向HeapFile中添加一个新的元组,我们需要找到带有空槽的页,如果不存在这样的页,我们需要创造一个新页并且将其添加到磁盘的文件上。我们需要确保元组的RecordID被正确更新
实现如下类中的方法:
- src/java/simpledb/storage/HeapPage.java
- src/java/simpledb/storage/HeapFile.java (Note that you do not necessarily need to implement writePage at this point).
为了实现HeapPage,在insertTuple和deleteTuple方法中你需要修改表示header的bitmap;这里将会使用到我们在实验一中实现的getNumEmptySlots()和isSlotUsed方法,markSlotUsed方法是抽象方法,并且用于填充或者清除page header的的状态信息。
注意,insertTuple和deleteTuple方法需要通过BufferPool.getPage方法访问页,否则下一个实验中关于事务的实现将无法正常工作
HeapPage作为数据读写的最小单位,主要负责维护Page数据组织格式和数据读写操作,其内部属性如下所示:
public class HeapPage implements Page {final HeapPageId pid;final TupleDesc td;final byte[] header;final Tuple[] tuples;final int numSlots;byte[] oldData;private final Byte oldDataLock = (byte) 0;// 本lab新增的两个属性private boolean dirty;private TransactionId tid;...
本节我们需要在HeapPage中实现的方法主要包括元组的插入,删除以及脏页标记和判脏:
/*** Adds the specified tuple to the page; the tuple should be updated to reflect* that it is now stored on this page.** @param t The tuple to add.* @throws DbException if the page is full (no empty slots) or tupledesc* is mismatch.*/public void insertTuple(Tuple t) throws DbException {TupleDesc tupleDesc = t.getTupleDesc();if (getNumEmptySlots() == 0 || !tupleDesc.equals(this.td)) {throw new DbException("this page is full or tupledesc is mismatch");}for (int i = 0; i < numSlots; i++) {if (!isSlotUsed(i)) {markSlotUsed(i, true);t.setRecordId(new RecordId(this.pid, i));tuples[i] = t;break;}}}/*** Delete the specified tuple from the page; the corresponding header bit should be updated to reflect* that it is no longer stored on any page.** @param t The tuple to delete* @throws DbException if this tuple is not on this page, or tuple slot is* already empty.*/public void deleteTuple(Tuple t) throws DbException {RecordId recordId = t.getRecordId();int slotId = recordId.getTupleNumber();if (recordId.getPageId() != this.pid || !isSlotUsed(slotId)) {throw new DbException("tuple is not in this page");}// 将tuple对应的slot置为0markSlotUsed(slotId, false);// 将slot对应的tuple置为nulltuples[slotId] = null;}/*** Marks this page as dirty/not dirty and record that transaction* that did the dirtying*/public void markDirty(boolean dirty, TransactionId tid) {this.dirty = dirty;this.tid = tid;}/*** Returns the tid of the transaction that last dirtied this page, or null if the page is not dirty*/public TransactionId isDirty() {return dirty ? tid : null;}
其他辅助的工具方法大家自行查看源码
HeapFile可以看做是表的实体对象,表由一堆HeadPage组成,这一堆HeadPage存放于当前表的DBFile中,这里我们主要实现元组的插入和删除方法:
// see DbFile.java for javadocspublic List<Page> insertTuple(TransactionId tid, Tuple t)throws DbException, IOException, TransactionAbortedException {List<Page> modified = new ArrayList<>();for (int i = 0; i < numPages(); i++) {HeapPage page = (HeapPage) bufferPool.getPage(tid, new HeapPageId(this.getId(), i), Permissions.READ_WRITE);if (page.getNumEmptySlots() == 0) {continue;}page.insertTuple(t);modified.add(page);return modified;}// 当所有的页都满时,我们需要创建新的页并写入文件中BufferedOutputStream outputStream = new BufferedOutputStream(new FileOutputStream(file, true));byte[] emptyPageData = HeapPage.createEmptyPageData();// 向文件末尾添加数据outputStream.write(emptyPageData);outputStream.close();// 加载到缓存中,使用numPages() - 1是因为此时numPages()已经变为插入后的大小了HeapPage page = (HeapPage) bufferPool.getPage(tid, new HeapPageId(getId(), numPages() - 1), Permissions.READ_WRITE);page.insertTuple(t);modified.add(page);return modified;}// see DbFile.java for javadocspublic ArrayList<Page> deleteTuple(TransactionId tid, Tuple t) throws DbException,TransactionAbortedException {HeapPage page = (HeapPage) bufferPool.getPage(tid, t.getRecordId().getPageId(), Permissions.READ_WRITE);page.deleteTuple(t);ArrayList<Page> modified = new ArrayList<>();modified.add(page);return modified;}
实现BufferPool类中的如下方法:
- insertTuple()
- deleteTuple()
这些方法需要调用需要被修改的表的HeapFile中的合适的方法来实现
public void insertTuple(TransactionId tid, int tableId, Tuple t)throws DbException, IOException, TransactionAbortedException {DbFile dbFile = Database.getCatalog().getDatabaseFile(tableId);updateBufferPool(dbFile.insertTuple(tid, t), tid);}public void deleteTuple(TransactionId tid, Tuple t)throws DbException, IOException, TransactionAbortedException {DbFile dbFile = Database.getCatalog().getDatabaseFile(t.getRecordId().getPageId().getTableId());updateBufferPool(dbFile.deleteTuple(tid, t), tid);}private void updateBufferPool(List<Page> pages, TransactionId tid) throws DbException {for (Page page : pages) {page.markDirty(true, tid);}}
完成练习后,我们的代码需要通过HeapPageWriteTest、HeapFileWriteTest和BufferPoolWriteTest单元测试
练习四 – Insertion & deletion
现在我们已经实现了向HeapFile添加和删除元组的机制,接下来就需要实现Insert和Delete操作
为了实现insert和delete查询,我们需要使用Insert和Delete来修改磁盘上的页,这些操作会返回被影响的元组数量
- Insert:该操作从他的子操作中读取元组加入到构造函数指定的tableid对应的表中,需要调用BufferPool.insertTuple()方法实现
- Delete:该操作从构造函数的tableid找到对应的table,并删除子操作中的元组,需要调用BufferPool.deleteTuple方法实现
实现如下类中的方法:
- src/java/simpledb/execution/Insert.java
- src/java/simpledb/execution/Delete.java
Insert和Delete采用的也是装饰器模式,所以这里不再多讲:
- Insert操作
/*** Inserts tuples read from the child operator into the tableId specified in the* constructor*/
public class Insert extends Operator {private static final long serialVersionUID = 1L;private final TransactionId tid;private OpIterator child;private final int tableId;private final TupleDesc tupleDesc;private Tuple insertTuple;/*** Constructor.** @param t The transaction running the insert.* @param child The child operator from which to read tuples to be inserted.* @param tableId The table in which to insert tuples.* @throws DbException if TupleDesc of child differs from table into which we are to* insert.*/public Insert(TransactionId t, OpIterator child, int tableId)throws DbException {this.tid = t;this.child = child;this.tableId = tableId;this.tupleDesc = new TupleDesc(new Type[]{Type.INT_TYPE}, new String[]{"insertNums"});this.insertTuple = null;}public TupleDesc getTupleDesc() {return this.tupleDesc;}public void open() throws DbException, TransactionAbortedException {super.open();child.open();}public void close() {super.close();child.close();}public void rewind() throws DbException, TransactionAbortedException {child.rewind();}/*** Inserts tuples read from child into the tableId specified by the* constructor. It returns a one field tuple containing the number of* inserted records. Inserts should be passed through BufferPool. An* instances of BufferPool is available via Database.getBufferPool(). Note* that insert DOES NOT need check to see if a particular tuple is a* duplicate before inserting it.** @return A 1-field tuple containing the number of inserted records, or* null if called more than once.* @see Database#getBufferPool* @see BufferPool#insertTuple*/protected Tuple fetchNext() throws TransactionAbortedException, DbException {if (insertTuple != null) {return null;}BufferPool bufferPool = Database.getBufferPool();int insertTuples = 0;while (child.hasNext()) {try {bufferPool.insertTuple(tid, tableId, child.next());insertTuples++;} catch (IOException e) {e.printStackTrace();}}//返回的是插入的元组数量insertTuple = new Tuple(this.tupleDesc);insertTuple.setField(0, new IntField(insertTuples));return insertTuple;}@Overridepublic OpIterator[] getChildren() {return new OpIterator[]{child};}@Overridepublic void setChildren(OpIterator[] children) {this.child = children[0];}
}
装饰器模式要点有两个:
- 装饰器对象继承被装饰对象的抽象父类或者父类接口,这样我们才可以在使用时能够用基类指针接收被装饰后的对象实现
- 装饰器对象内部需要调用被装饰对象的方法获取原数据,然后再此基础上进行计算然后返回一个结果,或者在原有数据基础上增加附加信息,或者啥也不干,只进行相关信息记录。
- fetchNext方法这里就是Insert装饰器对象需要实现的方法,其内部调用被装饰器对象的next方法获取所有数据,然后执行insert操作,同时计算插入数据条数,最终返回的是插入的数据条数。
- delete操作
/*** The delete operator. Delete reads tuples from its child operator and removes* them from the table they belong to.*/
public class Delete extends Operator {private static final long serialVersionUID = 1L;private final TransactionId tid;private OpIterator child;private final TupleDesc tupleDesc;private Tuple deleteTuple;/*** Constructor specifying the transaction that this delete belongs to as* well as the child to read from.** @param t The transaction this delete runs in* @param child The child operator from which to read tuples for deletion*/public Delete(TransactionId t, OpIterator child) {this.tid = t;this.child = child;this.tupleDesc = new TupleDesc(new Type[]{Type.INT_TYPE}, new String[]{"deleteNums"});this.deleteTuple = null;}public TupleDesc getTupleDesc() {return this.tupleDesc;}public void open() throws DbException, TransactionAbortedException {super.open();child.open();}public void close() {super.close();child.close();}public void rewind() throws DbException, TransactionAbortedException {child.rewind();}/*** Deletes tuples as they are read from the child operator. Deletes are* processed via the buffer pool (which can be accessed via the* Database.getBufferPool() method.** @return A 1-field tuple containing the number of deleted records.* @see Database#getBufferPool* @see BufferPool#deleteTuple*/protected Tuple fetchNext() throws TransactionAbortedException, DbException {if (deleteTuple != null) {return null;}BufferPool bufferPool = Database.getBufferPool();int deleteNums = 0;while (child.hasNext()) {try {bufferPool.deleteTuple(tid, child.next());deleteNums++;} catch (IOException e) {e.printStackTrace();}}deleteTuple = new Tuple(tupleDesc);deleteTuple.setField(0, new IntField(deleteNums));return deleteTuple;}@Overridepublic OpIterator[] getChildren() {return new OpIterator[]{child};}@Overridepublic void setChildren(OpIterator[] children) {this.child = children[0];}}
完成实验后需要通过InsertTest单元测试,并且通过InsertTest和DeleteTest系统测试
练习五 – Page eviction
在实验一中,我们没有正确的根据BufferPool构造函数中定义的numPages对BufferPool中缓存的最大页面数量进行限制,本节我们将实现拒绝策略。
当缓冲池中存在超过numPages数量的页时,我们需要在加载下一个页时选择淘汰缓冲池中现存的一个页;具体的拒绝策略我们自己选择即可。
BufferPool中包含一个flushAllPages方法,该方法不会被实际用到,只是用来进行实际的测试,我们在实际代码中不会调用此方法。
flushAllPages方法需要调用flushPage方法,并且flushPage方法需要在page离开BufferPool时将脏页写入磁盘,并且将其置为非脏。
从缓冲池中移除页面的唯一方法是evictPage,当任何脏页被丢弃时,我们需要调用flushPage方法来将其刷新到磁盘。
如果学过操作系统,那么应该了解过缓存页面丢弃策略,主要有先进先出(FIFO)、最近最少使用(LRU)和最不常用(LFU)这几种方法,我们可以选择不同的策略实现。我这里给定了一个抽象的接口,定义好方法,最后实现了FIFO和LRU页面丢弃策略,详情请看代码。
实现BufferPool的页面丢弃策略:
- src/java/simpledb/storage/BufferPool.java
我们需要实现discardPage方法去移除缓冲池中没有被刷新到磁盘上的页,本次实验不会使用该方法,但是它是未来的实验所必须的。
页面淘汰采用策略模式进行实现,这里只展示FIFO策略的实现,LRU可以采用哈希链表实现,具体可以参考Lab2源代码中的LRUEvict类:
public interface EvictStrategy {/*** 修改对应的数据结构以满足丢弃策略* @param pageId*/void addPage(PageId pageId);/*** 获取要丢弃的Page的PageId信息,用于丢弃* @return PageId*/PageId getEvictPageId();}public class FIFOEvict implements EvictStrategy {/*** 存储数据的队列*/private final Queue<PageId> queue;public FIFOEvict(int numPages) {this.queue = new ArrayDeque<>(numPages);}@Overridepublic void addPage(PageId pageId) {// 向尾部插入元素boolean offer = queue.offer(pageId);if (offer) {System.out.println("PageId: " + pageId + " 插入队列成功");} else {System.out.println("PageId: " + pageId + " 插入队列失败");}}@Overridepublic PageId getEvictPageId() {// 从队列头部获取元素return queue.poll();}}
借助淘汰策略接口和实现类,完成BufferPool中关于flushPage和evitPage相关方法:
private final EvictStrategy evict;public BufferPool(int numPages) {this.numPages = numPages;this.pageCache = new ConcurrentHashMap<>();this.evict = new FIFOEvict(numPages);}/*** Flush all dirty pages to disk.* NB: Be careful using this routine -- it writes dirty data to disk so will* break simpledb if running in NO STEAL mode.*/public synchronized void flushAllPages() throws IOException {pageCache.forEach((pageId, page) -> {try {flushPage(pageId);} catch (IOException e) {e.printStackTrace();}});} /*** Remove the specific page id from the buffer pool.* Needed by the recovery manager to ensure that the* buffer pool doesn't keep a rolled back page in its* cache.* <p>* Also used by B+ tree files to ensure that deleted pages* are removed from the cache so they can be reused safely*/public synchronized void discardPage(PageId pid) {pageCache.remove(pid);}/*** Flushes a certain page to disk** @param pid an ID indicating the page to flush*/private synchronized void flushPage(PageId pid) throws IOException {Page flush = pageCache.get(pid);// 通过tableId找到对应的DbFile,并将page写入到对应的DbFile中int tableId = pid.getTableId();DbFile dbFile = Database.getCatalog().getDatabaseFile(tableId);// 将page刷新到磁盘dbFile.writePage(flush);}/*** Discards a page from the buffer pool.* Flushes the page to disk to ensure dirty pages are updated on disk.*/private synchronized void evictPage() throws DbException {PageId evictPageId = evict.getEvictPageId();try {flushPage(evictPageId);} catch (IOException e) {e.printStackTrace();}pageCache.remove(evictPageId);}public Page getPage(TransactionId tid, PageId pid, Permissions perm)throws TransactionAbortedException, DbException {if (!pageCache.containsKey(pid)) {if (pageCache.size() > numPages) {evictPage();}DbFile dbFile = Database.getCatalog().getDatabaseFile(pid.getTableId());Page page = dbFile.readPage(pid);pageCache.put(pid, page);evict.addPage(pid);}return pageCache.get(pid);}
完成练习之后,代码需要通过EvictionTest单元测试。
至此我们就完成本次实验了,接下来还有对实验内容的其他测试。
练习六 – Query walkthrough
通过我们实现的各种查询策略,来执行类似于下面SQL语句的联合查询:
SELECT *
FROM some_data_file1,some_data_file2
WHERE some_data_file1.field1 = some_data_file2.field1AND some_data_file1.id > 1
我们需要根据实验一中的方法创建两个数据库文件some_data_file1.dat和some_data_file2.dat,然后使用如下代码进行测试:
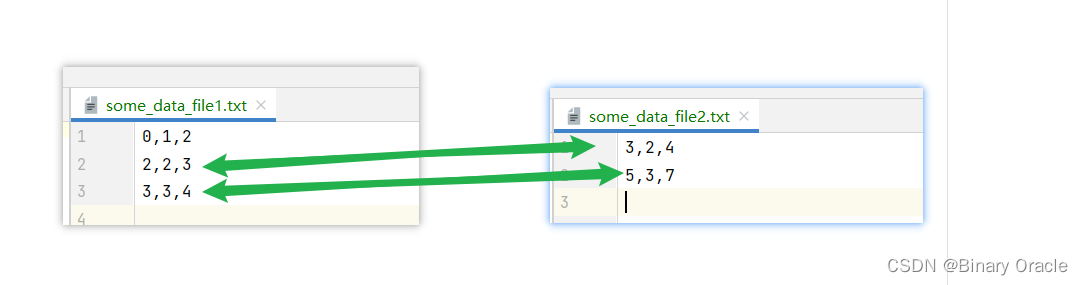
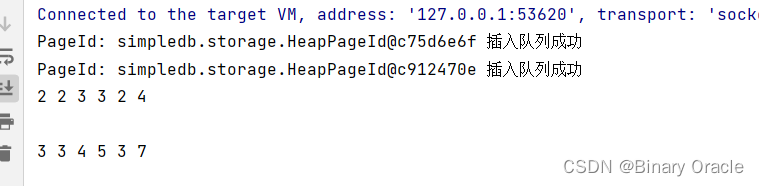
运行下面这个测试,可以得到2,2,3,3,2,4和3,3,4,5,3,7两条结果:
public class JoinTest {/*** select * from t1,t2 where t1.f0 > 1 and t1.f1 = t2.f1 ;*/public static void main (String[] args) {// construct a 3-column table schemaType[] types = new Type[]{Type.INT_TYPE, Type.INT_TYPE, Type.INT_TYPE};String[] names = new String[]{"f0", "f1", "f2"};TupleDesc td = new TupleDesc(types, names);// create the tables, associate them with the data files// and tell the catalog about the schema the tables.HeapFile table1 = new HeapFile(new File("some_data_file1.dat"), td);Database.getCatalog().addTable(table1, "t1");HeapFile table2 = new HeapFile(new File("some_data_file2.dat"), td);Database.getCatalog().addTable(table2, "t2");// construct the query: we use two SeqScans, which spoonfeed// tuples via iterators into joinTransactionId tid = new TransactionId();SeqScan ss1 = new SeqScan(tid, table1.getId(), "t1");SeqScan ss2 = new SeqScan(tid, table2.getId(), "t2");// create a filter for the where conditionFilter sf1 = new Filter(new Predicate(0,Predicate.Op.GREATER_THAN, new IntField(1)), ss1);JoinPredicate p = new JoinPredicate(1, Predicate.Op.EQUALS, 1);Join j = new Join(p, sf1, ss2);// and run ittry {j.open();while (j.hasNext()) {Tuple tup = j.next();System.out.println(tup);}j.close();Database.getBufferPool().transactionComplete(tid);} catch (Exception e) {e.printStackTrace();}}
}
练习七 - 查询解析
本节我们将会使用SimpleDB中已经编写好的SQL解析器来实现基于SQL语句的查询
首先我们需要创建数据库表和数据库目录,其中数据库表data.txt的内容如下:
1,10
2,20
3,30
4,40
5,50
5,50
通过如下命令将其转换为二进制文件:
java -jar dist/simpledb.jar convert data.txt 2 "int,int"
接下来创建数据库目录文件catalog.txt:
data (f1 int, f2 int)
该文件会告诉SimpleDB数据库中包含一个表:data,其结构为两个int类型的列
最后,我们运行如下命令:
java -jar dist/simpledb.jar parser catalog.txt
可以看到如下输出:
Added table : data with schema INT_TYPE(f1), INT_TYPE(f2)
Computing table stats.
Done.
SimpleDB>
接着输入SQL语句即可进行查询:
SimpleDB> select d.f1, d.f2 from data d;
Started a new transaction tid = 0
Added scan of table d
Added select list field d.f1
Added select list field d.f2
The query plan is:π(d.f1,d.f2),card:0|
scan(data d)d.f1 d.f2
------------------
1 102 203 304 405 505 506 rows.
Transaction 0 committed.
----------------
0.10 seconds
如果没有报错的话,证明你的相关实现都是正确的
相关文章:
MIT 6.830数据库系统 -- lab two
MIT 6.830数据库系统 -- lab two 项目拉取Lab Two实现提示练习一 -- Filter and Join练习二 -- Aggregates练习三 -- HeapFile Mutability练习四 -- Insertion & deletion练习五 -- Page eviction练习六 -- Query walkthrough练习七 - 查询解析 项目拉取 原项目使用ant进行…...
)
React基础知识点(一)
React基础知识点 目标 能够说出React是什么能够说出React的特点能够掌握React的基本使用能够使用React脚手架 什么是React (★★★) React是一个用于构建用户界面的javaScript库,起源于facebook的内部项目,后续在13年开源了出…...
机器学习-进化算法
进化算法 遗传算法(Genetic Algorithm,GA)crossovermutation 进化策略(Evolutionary Strategies,ES)基因编程(Genetic Programming)Multi-objective Evolutionary Algorithms 遗传算…...
leetcode 637. 二叉树的层平均值
2023.6.29 依旧是层序遍历的变体,在层序遍历的代码中的内层循环求个和,然后出循环之后取个平均值即可实现层平均值,下面上代码: class Solution { public:vector<double> averageOfLevels(TreeNode* root) {vector<doub…...

7-数组创建函数还有哪些?【视频版】
目录 问题视频解答 问题 视频解答 点击观看: 7-数组创建函数还有哪些?...

webrtc源码阅读之P2P流程分析
P2P从宏观原理上其实就是: 收集本地Candidates设置远程Candidates连通性测试及排序 本文我们从Offer端的角度进行源码分析,学习webrtc是如何进行P2P连接的。版本m98。 一、收集本地Candidates examples/peerconnection中,CreateOffer以后&…...
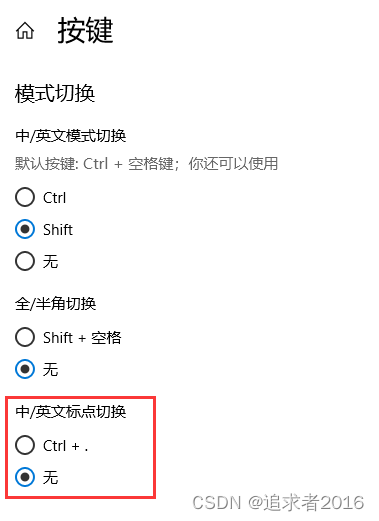
vscode 快速修复(quick fix) 快捷键(Ctrl + .)被占用问题解决方法
vscode 快速修复(quick fix) 快捷键(Ctrl .)被占用 微软拼音的中/英文标点切换的快捷键为Ctrl .,与 vscode 快速修复(quick fix)快捷键冲突。修复方法如下: 切换到微软拼音,在输入法中或英字上,点击右键。 再点设置 - 按键。 …...

阿里云——扩展Linux系统盘
扩展分区和文件系统_Linux系统盘 {#concept_ocb_htw_dhb .concept} 本文提供了如何使用growpart和resize2fs工具完成Linux系统盘分区扩容及文件系统扩展的操作指导。 适用范围 {#section_u9c_3g5_ljs .section} 本文的操作步骤适用于以下分区和文件系统格式的云盘࿱…...

TypeScript ~ 掌握基本类型 ②
作者 : SYFStrive 博客首页 : HomePage 📜: TypeScript ~ TS 📌:个人社区(欢迎大佬们加入) 👉:社区链接🔗 📌:觉得文章不错可以点点关注 &…...
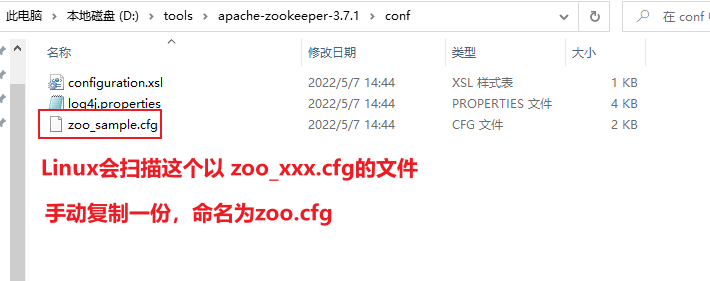
【Zookeeper】win安装随笔
目录 下载地址下载目标解压后目录结构配置文件配置文件详情伪分布式安装LinuxZooKeeper audit is disabled启动解决报错:SLF4J: Class path contains multiple SLF4J bindings. _ 下载地址 https://zookeeper.apache.org/releases.html 下载目标 记住选择带bin的…...
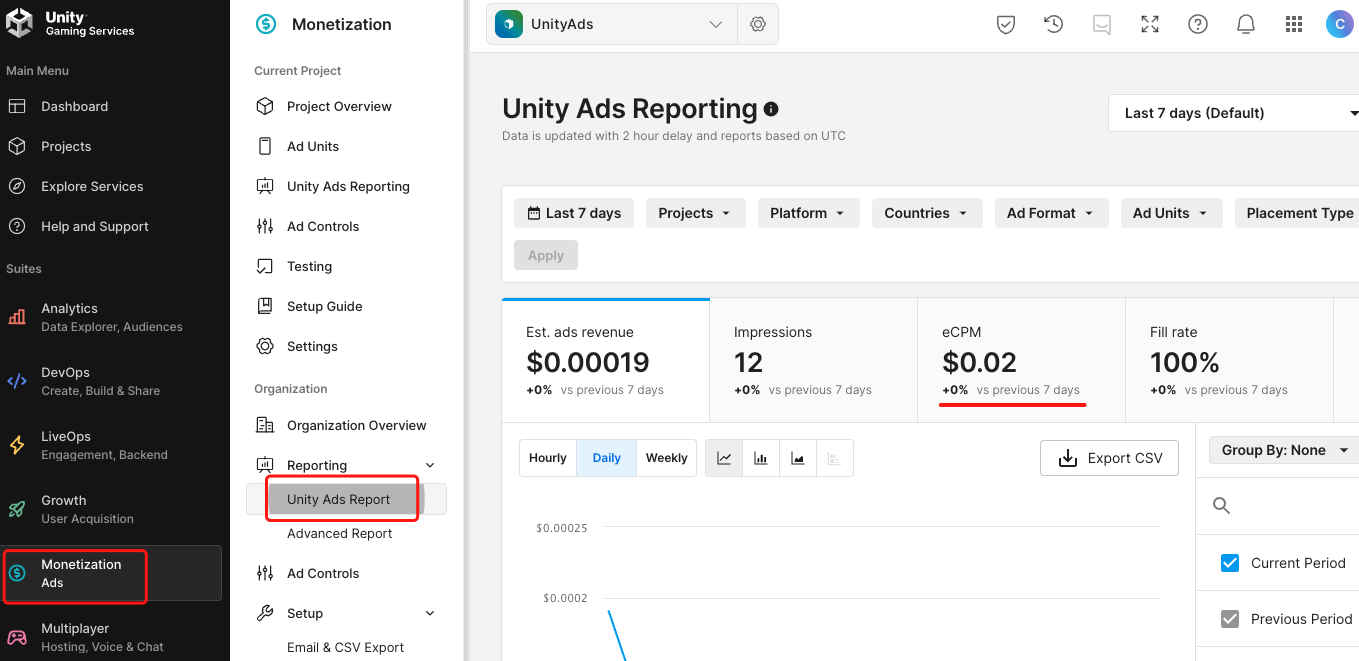
Unity 之 最新原生广告Ads接入 -- 助力增长游戏收益
Unity 之 最新Ads原生广告接入流程详解和工具类分享 一,注册 Unity Ads 广告 SDK二,下载 Unity Ads 广告 SDK三,配置 Unity Ads 广告 SDK3.1 广告位展示流程3.2 代码初始化 四,集成 Unity Ads 广告 SDK4.1 相关介绍4.2 代码分享 五…...

ChatGPT是否可以进行逻辑推理?
ChatGPT在逻辑推理方面的能力存在一定的限制。虽然它可以处理一些简单的逻辑问题,但由于其基于统计模型和语言模式的生成方式,它在复杂的逻辑推理和推断任务上可能会遇到挑战。以下是对ChatGPT在逻辑推理方面能力的详细分析: 1. 基于统计模型…...
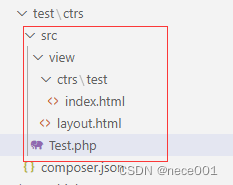
TP6在composer包里写控制器
前提:首先要了解下如何自建composer包。 1.先建一个空包,加一个文件:composer.json {"name": "test/ctrs","type": "library","license": "MIT","autoload": {&quo…...
Java面试Day11
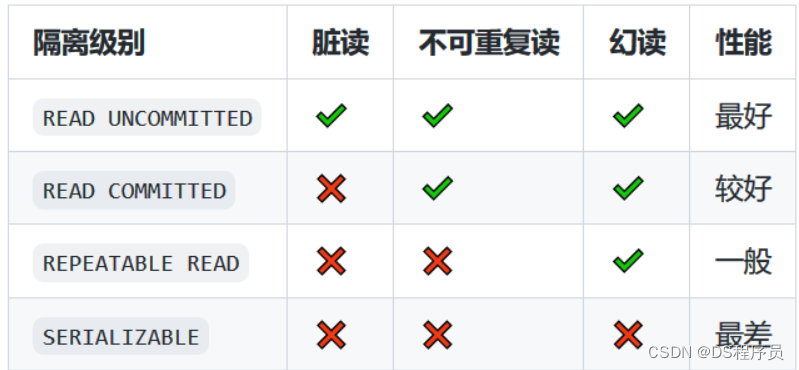
1. MySQL 事务有哪些隔离级别、分别有什么特点,以及 MySQL 的默认隔离级别是什么? 在MySQL中事务的隔离级别是为了解决常见的并发问题,在保证数据库性能的同时保持事务的隔离性,常见的并发问题有: 脏读:如果…...

python生成日报
目录 一:日报生成工具二:日报工具使用方式三:最终日报生成展示 一:日报生成工具 #!/usr/bin/python # coding:utf8class GetHtml(object):def __init__(self):self._html_head """<html><body style&qu…...
【机器学习】——续上:卷积神经网络(CNN)与参数训练
目录 引入 一、CNN基本结构 1、卷积层 2、下采样层 3、全连接层 二、CNN参数训练 总结 引入 卷积神经网络(CNN)是一种有监督深度模型框架,尤其适合处理二维数据问题,如行人检测、人脸识别、信号处理等领域,是带…...
鲸鱼算法WOA优化VMD参数,最小包络熵、样本熵、信息熵、排列熵(适应度函数可自行选择,一键修改)包含MATLAB源代码...
鲸鱼优化算法(Whale optimization algorithm, WOA)是Mirjalili根据座头鲸的捕食行为而提出来的,算法对座头鲸的狩猎行为进行模仿,通过对猎物的寻找,然后攻击进行觅食,以此来达到优化的目的,已有很多学者将算法用于实际…...
ELK日志收集系统集群实验
ELK日志收集系统集群实验 目录 一、实验拓扑 二、环境配置 三、 安装node1与node2节点的elasticsearch 1. 安装 2.配置 3.启动elasticsearch服务 4.查看节点信息 四、在node1安装elasticsearch-head插件 1.安装node 2.拷贝命令 3.安装elasticsearch-head 4.修改el…...

用Python写了一个下载网站所有内容的软件,可见即可下
目录标题 前言效果展示环境介绍:代码实战获取数据获取视频采集弹幕采集评论 GUI部分尾语 前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! 今天我们分享一个用Python写下载视频弹幕评论的代码。 顺便把这些写成GUI,把这些功能放到一起让朋友用起来更方便~ 效果…...

gin使用embed打包html
embed 使用类似的注释打包html文件 //go:embed pages/dist/* 打包的代码如下 package mainimport ("embed""io/fs""net/http""github.com/gin-gonic/gin" )//go:embed pages/dist/* var embedFs embed.FSfunc main() {e : gin.Defau…...

Fish-Speech-1.5应用案例:快速生成多语言语音的实际体验
Fish-Speech-1.5应用案例:快速生成多语言语音的实际体验 1. 引言:为什么选择Fish-Speech-1.5 想象一下,你需要为国际客户制作多语言产品演示视频,或者为在线课程添加不同语言的配音。传统方式需要雇佣多位母语配音员,…...

Three——优化glb模型加载性能的DRACOLoader实践
1. 为什么需要优化glb模型加载性能 在Vue3项目中使用three.js加载3D模型时,glb格式因其包含网格、材质、动画等完整场景数据而广受欢迎。但实际开发中,我们经常会遇到一个棘手问题:模型文件体积过大导致加载时间过长。想象一下,用…...

小白也能画火影:忍者绘卷Z-Image Turbo零基础入门到出图
小白也能画火影:忍者绘卷Z-Image Turbo零基础入门到出图 1. 为什么选择忍者绘卷Z-Image Turbo? 想画出专业级的火影忍者同人图却苦于不会画画?忍者绘卷Z-Image Turbo就是为你量身打造的AI绘画神器。这个基于Tongyi-MAI Z-Image底座的二次元…...

SecGPT-14B企业实操:将SecGPT-14B API集成至内部威胁情报平台
SecGPT-14B企业实操:将SecGPT-14B API集成至内部威胁情报平台 1. 为什么选择SecGPT-14B 在网络安全领域,快速准确地分析威胁情报是企业安全团队的核心需求。SecGPT-14B作为一款专注于网络安全问答与分析的14B参数大模型,能够理解复杂的安全…...

Ubuntu中英文切换全攻略:如何一键修改locale实现界面语言自由切换
Ubuntu系统语言环境自由切换实战指南 作为全球最流行的Linux发行版之一,Ubuntu系统支持多语言环境切换的特性常常被开发者忽视。很多用户在安装系统时随意选择语言,之后却发现需要频繁切换工作语言环境——比如开发时需要英文界面避免编码问题࿰…...

春联生成模型-中文-base入门实战:快速生成多副春联,挑选最满意作品
春联生成模型-中文-base入门实战:快速生成多副春联,挑选最满意作品 春节将至,家家户户都开始为贴春联做准备。传统的印刷春联虽然方便,但总感觉缺少个性;自己创作又担心文采不足。现在,借助"春联生成…...

时序RNN vs LSTM vs GRU:如何为你的时序数据选择最佳模型?
时序RNN vs LSTM vs GRU:如何为你的时序数据选择最佳模型? 在金融预测、工业设备监控或自然语言处理中,我们常面临一个关键抉择:面对不断涌入的时序数据流,究竟该选择哪种循环神经网络架构?传统时序RNN、LS…...
)
手机AI本地部署实战万字图文学习笔记(Termux+Python + 轻量文本生成模型Llama3-8b-Q4)
未来可以规划的方向 Ubuntu 桌面 AI 开发 VS Code 远程连接 Termux 电脑写代码 → 手机运行 做桌面端 Qt 软件 搭建独家的 CSV 私有记忆系统 命令行智能助手 语音助手,学习语音识别和语音合成 LLM大模型接入audio模型,LLM生成提示词导入diffusion图像模型 学习如何将大模型导…...

Autodesk Maya
链接:https://pan.quark.cn/s/36580a067803(玛雅)是一款全球著名的三维动画软件,建模软件,仿真和渲染软件.MAYA软件玛雅动画在广告传媒,影视行业,工业设计,建筑设计,三维动画,多媒体制作,游戏开发,辅助教学及工程可视化等领域广泛应用.更新日志help.autodesk.com/vi…...

答应我,不要再说自己不了解Spring源码的整体设计和实现细节了
Spring是我们Java程序员面试和工作都绕不开的重难点。很多粉丝就经常跟我反馈说由Spring衍生出来的一系列框架太多了,根本不知道从何下手;大家学习过程中大都不成体系,但面试的时候都上升到源码级别了,你不光要清楚了解Spring源码…...