MongoDB使用
文档连接: link
创建表
不需要创建表的语句,当插入表的第一条语句时,会隐式的创建表。
增
插入一条
db.people.insertOne({ user_id: "bcd001", age: 45, status: "A" }
)
插入多条
db.collection.insertMany([ <document 1> , <document 2>, ... ],{writeConcern: <document>,ordered: <boolean>}
)
writeConcern
如果mongodb有多个节点,这个writeConcern是说到底写几个节点再返回。写一个节点性能快,写多个节点性能慢。
test> db.people.insertOne(
... { user_id: "bcd001", age: 45, status: "A" },
... {
... "writeConcern":{w:"majority",j:true,wtimeout:5000}
... }
... )
{acknowledged: true,insertedId: ObjectId("649be01774d3e265a2c00f74")
}
| 参数 | 说明 |
|---|---|
| w:"majority” | 写的时候写大多数节点就返回 |
| j:true | 表示刷到磁盘之后在返回(日志为false,计算结果为true) |
| wtimeout:5000 | 快速失败(熔断) |
| ordered:true | 多条情况下是否按顺序插入 |
js脚本批量新增
客户端就是一个js的控制台。
# 通过使用客户端的load()命令批量新增
# /mongodb/js/books.js是下面脚本的路径
test> load("/mongodb/js/books.js");
true
test> db.books.countDocuments();
500000
var tags = ["nosql","mongodb","document","developer","popular"];
var types = ["technology","sociality","travel","novel","literature"];
var books=[];
for(var i=0;i<500000;i++){
var typeIdx = Math.floor(Math.random()*types.length);
var tagIdx = Math.floor(Math.random()*tags.length);
var favCount = Math.floor(Math.random()*100);
var book = {
title: "book-"+i,
type: types[typeIdx],
tag: tags[tagIdx],
favCount: favCount,
author: "xxx"+i
};
books.push(book)
}
db.books.insertMany(books);
help
db.help()
db.books.help()
查
db.books.find()
db.books.find({tag:"nosql"})
条件查询
| SQL | MQL |
|---|---|
| a = 1 | {a: 1} |
| a <> 1 | {a: {$ne: 1}} |
| a > 1 | {a: {$gt: 1}} |
| a >= 1 | {a: {$gte: 1}} |
| a < 1 | {a: {$lt: 1}} |
| a <= 1 | {a: {$lte: 1}} |
查询逻辑
| SQL | MQL |
|---|---|
| a = 1 AND b = 1 | {a: 1, b: 1}或{$and: [{a: 1}, {b: 1}]} |
| a = 1 OR b = 1 | {$or: [{a: 1}, {b: 1}]} |
| a IS NULL | {a: {$exists: false}} |
| a IN (1, 2, 3) | {a: {$in: [1, 2, 3]}} |
正则表达式
## 使用正则表达式查找type包含 so 字符串的book
db.books.find({type:{$regex:"so"}})
## 或者
db.books.find({type:/so/})
排序
# #指定按收藏数(favCount)降序返回
db.books.find({type:"travel"}).sort({favCount:-1})
分页
db.books.find().skip(16).limit(8)
数据量非常大的情况下,避免使用分页,因为还是会扫描前多少条。
test> db.books.find({_id:{$gt: ObjectId("649be1ac74d3e265a2c00ff8")}}).limit(1)
[{_id: ObjectId("649be1ac74d3e265a2c00ff9"),title: 'book-132',type: 'literature',tag: 'popular',favCount: 97,author: 'xxx132'}
]
聚合函数
count
避免这种查询,这种也会扫描全部
# 为了计算总页数而进行的 count() 往往是拖慢页面整体加载速度的原因
db.coll.count({x: 100});
改
db.collection.updateOne()
db.collection.updateMany()
db.collection.updateOne(
<filter>,
<update>,{upsert: <boolean>,writeConcern: <document>,collation: <document>,arrayFilters: [ <filterdocument1>, ... ],hint: <document|string> // Available starting in MongoDB 4.2.1}
)
参数说明
| 参数 | 值 |
|---|---|
| filter | 一个筛选器对象,用于指定要更新的文档。只有与筛选器对象匹配的第一个文档才会被更新。 |
| update | 一个更新操作对象,用于指定如何更新文档。可以使用一些操作符,例如 s e t 、 set、 set、inc、$unset等, |
| 以更新文档中的特定字段 | |
| upsert | 一个布尔值,用于指定如果找不到与筛选器匹配的文档时是否应插入一个新文档。如果upsert为true, |
| 则会插入一个新文档。默认值为false。 | |
| writeConcern | 一个文档,用于指定写入操作的安全级别。可以指定写入操作需要到达的节点数或等待写入操作的时间。 |
| collation | 一个文档,用于指定用于查询的排序规则。例如,可以通过指定locale属性来指定语言环境,从而实现基于区域设置的排序 |
| arrayFilters | 一个数组,用于指定要更新的数组元素。数组元素是通过使用更新操作符 [ ] 和 []和 []和来指定的。 |
| hint | 一个文档或字符串,用于指定查询使用的索引。该参数仅在MongoDB 4.2.1及以上版本中可用。 |
update的操作符
| 操作符 | 格式 | 描述 |
|---|---|---|
| $set | {$set:{field:value}} | 指定一个键并更新值,若键不存 |
| 在则创建 | ||
| $unset | {$unset : {field : 1 }} | 删除一个键 |
| $inc | {$inc : {field : value } } | 对数值类型进行增减 |
| $rename | {$rename : {old_field_name :new_field_name } } | 修改字段名称 |
| $push | { $push : {field : value } } | 将数值追加到数组中,若数组不存在则会进行初始化 |
| $pushAll | {$pushAll : {field : value_array}} | 追加多个值到一个数组字段内 |
| $pull | {$pull : {field : _value } } | 从数组中删除指定的元素 |
| $addToSet | {$addToSet : {field : value } } | 添加元素到数组中,具有排重功能 |
| $pop | {$pop : {field : 1 }} | 删除数组的第一个或最后一个元素 |
test> db.books.find({_id:{$gt: ObjectId("649be1ac74d3e265a2c00ff8")}}).limit(1)
[{_id: ObjectId("649be1ac74d3e265a2c00ff9"),title: 'book-132',type: 'literature',tag: 'popular',favCount: 98,author: 'xxx132'}
]
test> db.books.updateOne(
... {title:"my book"},
... {$set:{tags:["nosql","mongodb"],type:"none",author:"fox"}},
... {upsert:true}
... )
{acknowledged: true,insertedId: ObjectId("649bf00ce9b03ae08c3a971e"),matchedCount: 0,modifiedCount: 0,upsertedCount: 1
}更新多个
# 插入的时间统一以零时区为准,存在多个地区多个节点的情况下,如果以各自时区为准,会乱套。
db.books.updateMany({type:"novel"},{$set:{publishedDate:new Date()}})
findAndModify
先查,再返回。类似并发的getAndIncreament();返回旧值
# 将某个book文档的收藏数(favCount)加1
db.books.findAndModify({query:{_id:ObjectId("642ec31813bdda928a1ea2a8")},update:{$inc:{favCount:1}}
})
默认情况下,findAndModify会返回修改前的“旧”数据。如果希望返回修改后的数据,则可以指定
new选项
db.books.findAndModify({query:{_id:ObjectId("642ec31813bdda928a1ea2a8")},update:{$inc:{favCount:1}},new:true
})
删
# 删除一个
db.books.deleteOne ({ type:"novel" })
# 删除集合下全部文档 ,不如直接drop性能快
db.books.deleteMany ({})
# 删除 type等于 novel 的全部文档
db.books.deleteMany ({ type:"novel" })
findOneAndDelete
可以实现队列,某些场景下可以实现一个队列。
db.books.findOneAndDelete({type:"novel"})
批量操作
db.pizzas.insertMany( [
{ _id: 0, type: "pepperoni", size: "small", price: 4 },
{ _id: 1, type: "cheese", size: "medium", price: 7 },
{ _id: 2, type: "vegan", size: "large", price: 8 }
] )db.pizzas.bulkWrite( [
{ insertOne: { document: { _id: 3, type: "beef", size: "medium", price: 6 } } },
{ insertOne: { document: { _id: 4, type: "sausage", size: "large", price: 10 } }
},
{ updateOne: {
filter: { type: "cheese" },
update: { $set: { price: 8 } }
} },
{ deleteOne: { filter: { type: "pepperoni"} } },
{ replaceOne: {
filter: { type: "vegan" },
replacement: { type: "tofu", size: "small", price: 4 }
} }
] )
相关文章:

MongoDB使用
文档连接: link 创建表 不需要创建表的语句,当插入表的第一条语句时,会隐式的创建表。 增 插入一条 db.people.insertOne({ user_id: "bcd001", age: 45, status: "A" } )插入多条 db.collection.insertMany([ <document 1&g…...

C#文件安全管理解析
在实际的项目开发中,我们经常需要使用到文件的I/O操作,主要包含对文件的增改删查等操作,这些基本的操作我们都是很熟悉,但是较少的人去考虑文件的安全和操作的管理等方面,例如文件的访问权限管理,文件数据的…...
基于Dubbo分布式学校信息管理系统设计与实现
一、引言 1.1 课题背景 随着时代的发展与进步,计算机网络也随之日益完善,渐渐覆盖了我们生活的各个方面。在信息化和数字化的时代背景下,使用计算机管理学校信息来提升教育工作的质量和效率,是大势所趋,所以近年来,随着网络技术的不断发展,使用信息管理系统的学校越来…...

oracle面试问题和笔记整理
oracle面试笔记 ORACLE 面试问题-技术篇(2) 如何判断数据库的时区? 解答:SELECT DBTIMEZONE FROM DUAL; 解释GLOBAL_NAMES设为TRUE的用途 解答:GLOBAL_NAMES指明联接数据库的方式。如果这个参数设置为TRUE, 在建立数据库链接时就必须用相同的名字连结远程数据库 23。如何…...

Hadoop_Yarn实践 (三) => (Yarn的基础架构、原理、容量/公平调度器、Tool接口、Yarn常用命令、核心参数)
目录 Hadoop_HDFS、Hadoop_MapReduce、Hadoop_Yarn 实践 (三)一、Hadoop_HDFS二、Hadoop_MapReduce三、Hadoop_Yarn1、Yarn资源调度1.1、基础架构1.2、Yarn的工作调度机制(Job提交过程)1.3、Yarn 调度器和调度算法1.3.1、先进先出调度器(FIFO…...

postgresql 从应用角度看快照snapshot使用,事务隔离控制不再神密
专栏内容:postgresql内核源码分析 个人主页:我的主页 座右铭:天行健,君子以自强不息;地势坤,君子以厚德载物. 快照使用 快照是事务中使用,配合事务的隔离级别,体现出不同的可见性。…...
读写分离部署)
mysql(mariadb)读写分离部署
目录 一、原理 二、准备环境 三、部署mysql主从复制 1.五台服务器下载mariadb 2.修改master配置文件,重启数据库 3.登录mysql创建replication 4.从服务器登录验证 5.获得master服务器 DB的相关信息 6.备份master原有数据 7.修改slave1、slave2配置 8. 进入…...

ES-工作原理
前言 搜索引擎是对数据的检索,而数据总体分为两种:结构化数据和非结构化数据。而对于结构化数据,因为他们具有特定的结构,所以一般都是可以通过关系型数据库MySQL/oracle的二维表的方式存储和搜索,也可以建立索引。…...
)
C++小结(4)
C 字符串 C 提供了两种类型的字符串表示形式: C 风格字符串C 引入的 string 类类型 C 风格字符串 C 风格的字符串起源于 C 语言,并在 C 中继续得到支持。字符串实际上是使用 null 字符 \0 终止的一维字符数组。因此,一个以 null 结尾的字…...

Java框架之spring 的 messaging
写在前面 本文看下spring message相关的内容。 1:Message?Messaging? Message是消息的意思,是一个名词。而Messaging是一个动名词,是将消息发送出去的意思,因此,我们的消息系统是messaging s…...

linux使用grep命令查询nginx的进程情况时总是出现 grep --color=auto nginx
问题: 每次使用ps aux | grep 服务名 命令查询某个服务的进程时,总会出现一条grep --colorauto 服务名 例如: ps aux | grep nginx # 会出现图片中的情况解答: 这是因为grep 也是一条命令,它在输出时,会…...
)
FFmpeg音视频开发知识点(二)
系列文章目录 FFmpeg音视频开发知识点(一) 文章目录 系列文章目录前言一、AAC音频编码1. ffmpeg编译第三方的libfdk_aac2. S16重采样FLTP 二、AAC音频解码总结 前言 该篇讲解一下,音频编解码中的难点,以及开发过程中遇到问题&am…...

【Java可执行命令】(十)JAR文件签名工具 jarsigner:通过数字签名及验证保证代码信任与安全,深入解析 Java的 jarsigner命令~
Java可执行命令之jarsigner 1️⃣ 概念2️⃣ 优势和缺点3️⃣ 使用3.1 语法3.1.1 可选参数:jarsigner -keystore < url>3.1.2 可选参数:jarsigner -storepass <口令>3.1.3 可选参数:jarsigner -keypass <口令>3.1.4 可选参…...

c#调用c++ dll,Release版本内存访问错误
最近遇到个比较经典的案例,在c#中调用yara进行文件检测,yara是c编写的一个非常强大库,github有个大佬用c#对其进行了封装,使其能在跨平台下,只需编译yara的so或dll就能直接跑。但总是在Release版本下时不时就崩溃&…...
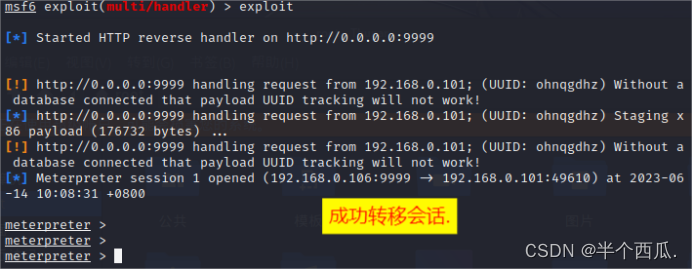
内网安全:Cobalt Strike 与 MSF 联动( 会话 相互转移 )
内网安全:Cobalt Strike 与 MSF 联动( 会话 相互转移 ) 在渗透中,有时候 Cobalt Strike 会话可能会受限制,所以我们需要把 Cobalt Strike 会话转移到 MSF 上进行后面的渗透。也有的时候会话在 MSF 上,但是…...

性能测试讲解超详细Jmeter
目录 什么是性能 性能测试的目的 功能测试和性能测试 基准测试 负载测试 稳定性测试 压力测试 并发测试 总结 性能测试指标 响应时间 并发数 吞吐量 点击数 错误率 资源使用率 总结 性能测试流程 性能测试需求分析 性能测试计划和方案 编辑性能测试用例编辑 性…...

微服务 – Spring Cloud – Nacos 配置中心
微服务 – Spring Cloud – Nacos 配置中心 文章目录 微服务 – Spring Cloud – Nacos 配置中心打开nacos面板新建配置引入依赖配置文件启动类业务类打开nacos面板新建配置 Data ID: nacos-config-client-dev.yaml Group: DEV-CLOUD2023 config:info: config info lalalal …...
超细,设计一个“完美“的测试用例,用户登录模块实例...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 好的测试用例一定…...
【C#】文件拖拽,获取文件路径
系列文章 【C#】编号生成器(定义单号规则、固定字符、流水号、业务单号) 本文链接:https://blog.csdn.net/youcheng_ge/article/details/129129787 【C#】日期范围生成器(开始日期、结束日期) 本文链接:h…...

SAP PI/PO初步了解 2023.07.03
SAP PI/PO 是SAP 提供的一种集成中间件解决方案,用于在组织内部或不同组织之间实现系统的无缝通信和数据交换。它使企业能够以统一高效的方式集成各种应用和系统,无论这些系统的技术平台或数据格式如何。 以下是关于SAP PI/PO的简要概述: 1…...

原神帧率解锁终极指南:3步轻松突破60FPS限制,享受极致流畅体验
原神帧率解锁终极指南:3步轻松突破60FPS限制,享受极致流畅体验 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 还在为原神60帧限制而苦恼吗?高端显卡却…...
)
别再问怎么给QQ机器人加功能了!手把手教你用Nonebot2写一个天气查询插件(附完整代码)
NoneBot2实战:从零构建智能QQ机器人天气查询插件 在当今即时通讯生态中,智能机器人已成为提升社群互动效率的利器。本文将深入探讨如何基于Python的NoneBot2框架,为QQ机器人开发一个功能完备的天气查询插件。不同于基础教程,我们聚…...
)
WebGL开发者必备:用RenderDoc旧版本抓帧调试的完整避坑指南(附DEBUG_CHROME.bat脚本)
WebGL开发者必备:用RenderDoc旧版本抓帧调试的完整避坑指南(附DEBUG_CHROME.bat脚本) 最近在WebGL开发中遇到一个棘手问题:最新版RenderDoc已经禁止了对Chrome等浏览器的抓帧功能。这对于正在学习图形学课程(比如GAMES…...

Qwen2.5-14B-Instruct+Pixel Script Temple:高校戏剧系AI辅助教学实战案例
Qwen2.5-14B-InstructPixel Script Temple:高校戏剧系AI辅助教学实战案例 1. 项目背景与价值 在高校戏剧教育领域,剧本创作一直是教学难点。传统教学模式下,学生需要花费大量时间在格式规范、基础场景构建等基础性工作上,而教师…...

从自动驾驶到AR眼镜:聊聊PSMNet这个双目立体匹配的‘老将’现在还能怎么用
PSMNet在2024年的技术重生:从经典立体匹配到轻量化落地的实战指南 六年前,当PSMNet在CVPR 2018上首次亮相时,其金字塔池化模块和堆叠沙漏3D CNN架构刷新了KITTI榜单的精度记录。如今,在Transformer大行其道的时代,这个…...

foobar2000界面美化终极指南:3步打造你的专属音乐播放器
foobar2000界面美化终极指南:3步打造你的专属音乐播放器 【免费下载链接】foobox-cn DUI 配置 for foobar2000 项目地址: https://gitcode.com/GitHub_Trending/fo/foobox-cn 还在为foobar2000那套单调乏味的默认界面感到困扰吗?今天我要为你介绍…...

VxLAN网络如何“破圈”?聊聊Type5路由在云网融合中的真实应用场景
VxLAN Type5路由:云网融合时代的智能连接引擎 在数字化转型浪潮中,企业网络架构正经历着从传统三层架构向云原生网络的跃迁。VxLAN作为新一代网络虚拟化技术的代表,其Type5路由功能正在成为打通云网边界的关键推手。想象一下这样的场景&#…...

OpenClaw 深度研究报告:从开源框架到企业级智能体平台的演进之路
一、核心定位:突破"对话天花板"的执行中枢 OpenClaw(外号"龙虾") 是由奥地利工程师 Peter Steinberger 于 2025 年底开发的本地优先、模型无关的 AI 智能体运行框架。其核心价值主张极为鲜明: “The AI that …...

Qwen3.5-2B部署实战:端侧轻量化多模态模型一键镜像教程
Qwen3.5-2B部署实战:端侧轻量化多模态模型一键镜像教程 1. 模型简介 Qwen3.5-2B是阿里云推出的轻量化多模态基础模型,属于Qwen3.5系列的小参数版本(20亿参数)。这个模型专为低功耗、低门槛部署场景设计,特别适合端侧…...

Kettle转换里‘阻塞数据’控件为啥不灵?我用这个真实ETL案例给你讲透
Kettle转换中‘阻塞数据’控件的实战解析:从失效到精准控制 在ETL工具Kettle的实际应用中,数据流的精确控制往往是决定任务成败的关键。许多中高级用户在使用"阻塞数据直到步骤都完成"控件时,都曾遇到过看似配置正确却无法生效的困…...