尚硅谷大数据Flink1.17实战教程-笔记02【Flink部署】
- 尚硅谷大数据技术-教程-学习路线-笔记汇总表【课程资料下载】
- 视频地址:尚硅谷大数据Flink1.17实战教程从入门到精通_哔哩哔哩_bilibili
- 尚硅谷大数据Flink1.17实战教程-笔记01【Flink概述、Flink快速上手】
- 尚硅谷大数据Flink1.17实战教程-笔记02【Flink部署】
- 尚硅谷大数据Flink1.17实战教程-笔记03【】
- 尚硅谷大数据Flink1.17实战教程-笔记04【】
- 尚硅谷大数据Flink1.17实战教程-笔记05【】
- 尚硅谷大数据Flink1.17实战教程-笔记06【】
- 尚硅谷大数据Flink1.17实战教程-笔记07【】
- 尚硅谷大数据Flink1.17实战教程-笔记08【】
目录
基础篇
第03章 Flink部署
P011【011_Flink部署_集群角色】03:07
P012【012_Flink部署_集群搭建_集群启动】14:22
P013【013_Flink部署_集群搭建_WebUI提交作业】13:58
P014【014_Flink部署_集群搭建_命令行提交作业】03:46
P015【015_Flink部署_部署模式介绍】10:17
P016【016_Flink部署_Standalone运行模式】08:16
P017【017_Flink部署_YARN运行模式_环境准备】07:41
P018【018_Flink部署_YARN运行模式_会话模式】18:11
P019【019_Flink部署_YARN运行模式_会话模式的停止】04:10
P020【020_Flink部署_YARN运行模式_单作业模式】09:49
P021【021_Flink部署_YARN运行模式_应用模式】12:51
P022【022_Flink部署_历史服务器】08:11
基础篇
第03章 Flink部署
P011【011_Flink部署_集群角色】03:07
第 3 章 Flink 部署
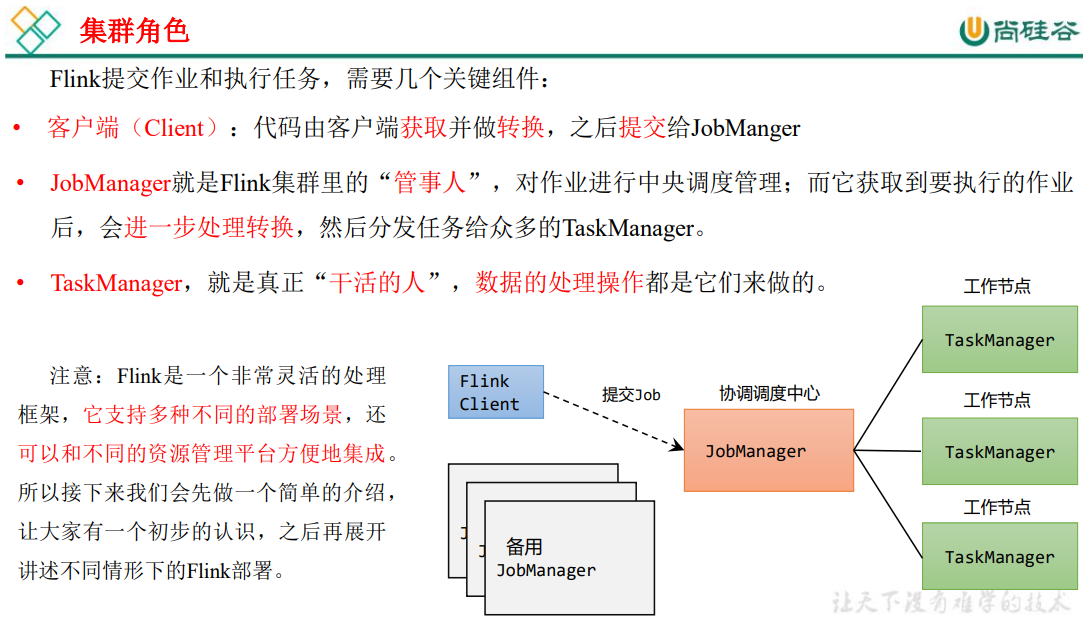
3.1 集群角色
P012【012_Flink部署_集群搭建_集群启动】14:22
表3-1 集群角色分配 节点服务器
hadoop102
hadoop103
hadoop104
角色
JobManager
TaskManager
TaskManager
TaskManager
[atguigu@node001 module]$ cd flink
[atguigu@node001 flink]$ cd flink-1.17.0/
[atguigu@node001 flink-1.17.0]$ bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host node001.
Starting taskexecutor daemon on host node001.
Starting taskexecutor daemon on host node002.
Starting taskexecutor daemon on host node003.
[atguigu@node001 flink-1.17.0]$ jpsall
================ node001 ================
3408 Jps
2938 StandaloneSessionClusterEntrypoint
3276 TaskManagerRunner
================ node002 ================
2852 TaskManagerRunner
2932 Jps
================ node003 ================
2864 TaskManagerRunner
2944 Jps
[atguigu@node001 flink-1.17.0]$ 
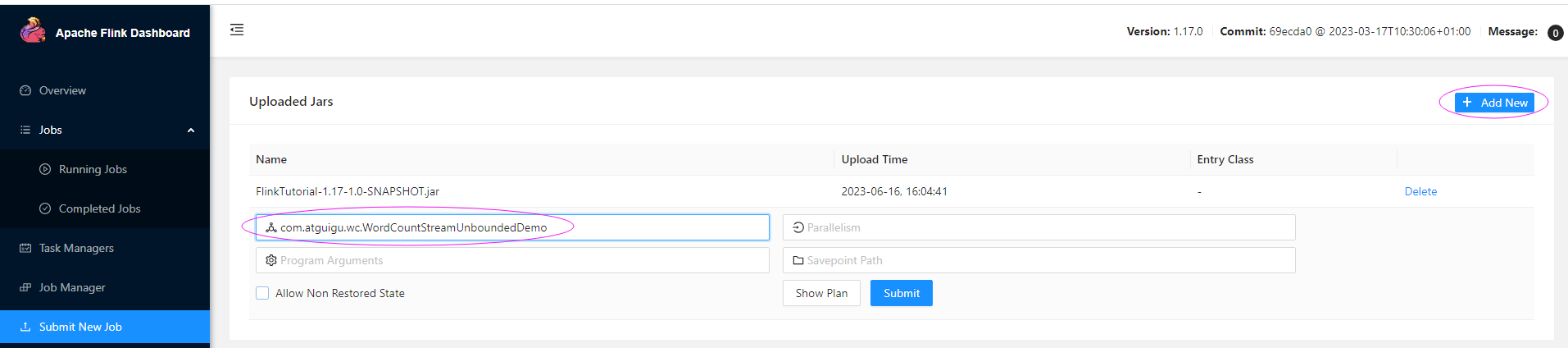
P013【013_Flink部署_集群搭建_WebUI提交作业】13:58
3.2.2 向集群提交作业
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.2.4</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><artifactSet><excludes><exclude>com.google.code.findbugs:jsr305</exclude><exclude>org.slf4j:*</exclude><exclude>log4j:*</exclude></excludes></artifactSet><filters><filter><!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. --><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers combine.children="append"><transformerimplementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"></transformer></transformers></configuration></execution></executions></plugin></plugins>
</build>
com.atguigu.wc.WordCountStreamUnboundedDemo

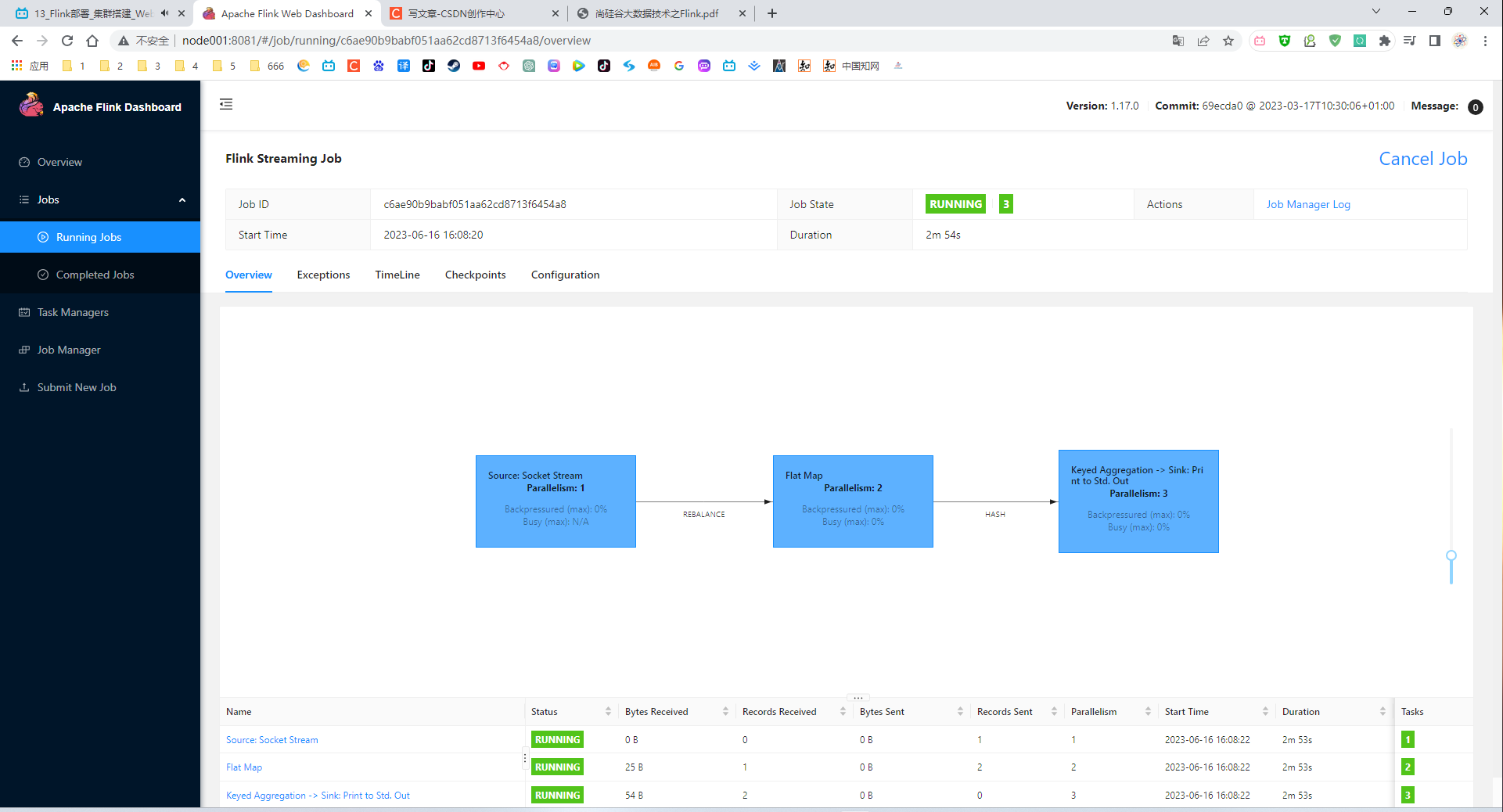

P014【014_Flink部署_集群搭建_命令行提交作业】03:46
3.2.2 向集群提交作业
4)命令行提交作业
连接成功
Last login: Fri Jun 16 14:44:01 2023 from 192.168.10.1
[atguigu@node001 ~]$ cd /opt/module/flink/flink-1.17.0/
[atguigu@node001 flink-1.17.0]$ cd bin
[atguigu@node001 bin]$ ./start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host node001.
Starting taskexecutor daemon on host node001.
Starting taskexecutor daemon on host node002.
Starting taskexecutor daemon on host node003.
[atguigu@node001 bin]$ jpsall
================ node001 ================
2723 TaskManagerRunner
2855 Jps
2380 StandaloneSessionClusterEntrypoint
================ node002 ================
2294 TaskManagerRunner
2367 Jps
================ node003 ================
2292 TaskManagerRunner
2330 Jps
[atguigu@node001 bin]$ cd ..
[atguigu@node001 flink-1.17.0]$ bin/flink run -m node001:8081 -c com.atguigu.wc.WordCountStreamUnboundedDemo ./
bin/ conf/ examples/ lib/ LICENSE licenses/ log/ NOTICE opt/ plugins/ README.txt
[atguigu@node001 flink-1.17.0]$ bin/flink run -m node001:8081 -c com.atguigu.wc.WordCountStreamUnboundedDemo ../
flink-1.17.0/ jar/
[atguigu@node001 flink-1.17.0]$ bin/flink run -m node001:8081 -c com.atguigu.wc.WordCountStreamUnboundedDemo ../jar/FlinkTutorial-1.17-1.0-SNAPSHOT.jar
Job has been submitted with JobID 59ae9d6532523b0c48cdb8b6c9105356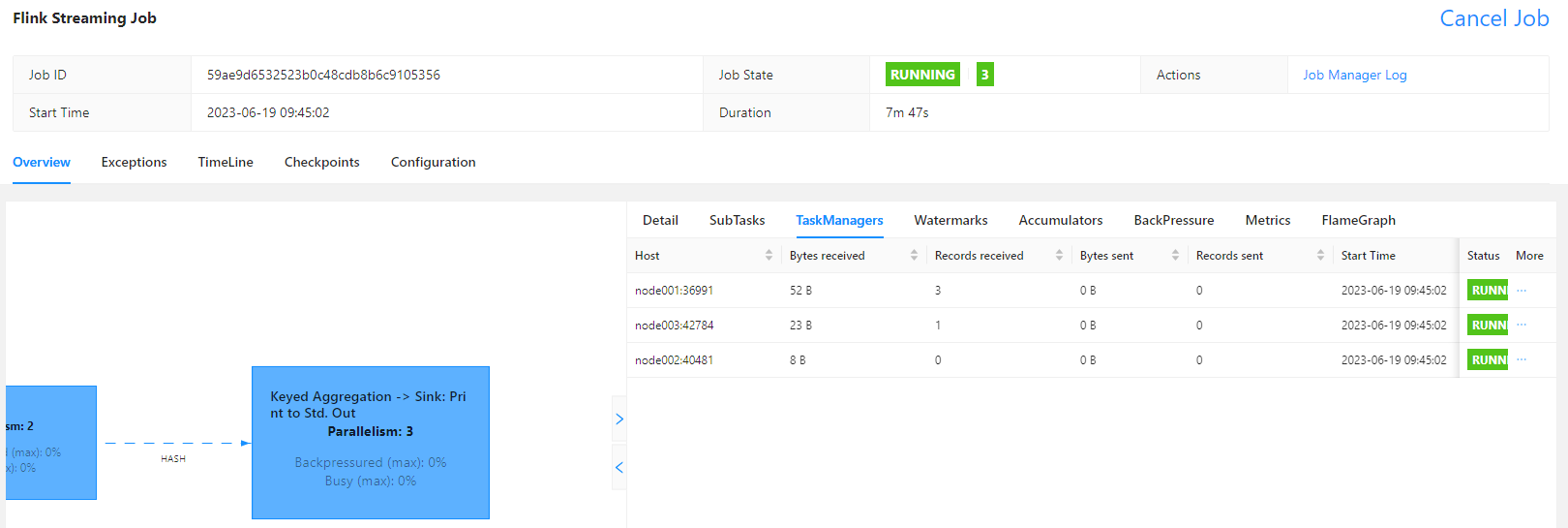


P015【015_Flink部署_部署模式介绍】10:17
3.3 部署模式
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。Flink为各种场景提供了不同的部署模式,主要有以下三种:会话模式(Session Mode)、单作业模式(Per-Job Mode)、应用模式(Application Mode)。
它们的区别主要在于:集群的生命周期以及资源的分配方式;以及应用的main方法到底在哪里执行——客户端(Client)还是JobManager。
P016【016_Flink部署_Standalone运行模式】08:16
3.4 Standalone运行模式(了解)
独立模式是独立运行的,不依赖任何外部的资源管理平台;当然独立也是有代价的:如果资源不足,或者出现故障,没有自动扩展或重分配资源的保证,必须手动处理。所以独立模式一般只用在开发测试或作业非常少的场景下。
[atguigu@node001 ~]$ cd /opt/module/flink/flink-1.17.0/bin
[atguigu@node001 bin]$ ./stop-cluster.sh
Stopping taskexecutor daemon (pid: 2723) on host node001.
Stopping taskexecutor daemon (pid: 2294) on host node002.
Stopping taskexecutor daemon (pid: 2292) on host node003.
Stopping standalonesession daemon (pid: 2380) on host node001.
[atguigu@node001 bin]$ jpsall
================ node001 ================
5120 Jps
================ node002 ================
3212 Jps
================ node003 ================
3159 Jps
[atguigu@node001 bin]$ ls
bash-java-utils.jar flink historyserver.sh kubernetes-session.sh sql-client.sh start-cluster.sh stop-zookeeper-quorum.sh zookeeper.sh
config.sh flink-console.sh jobmanager.sh kubernetes-taskmanager.sh sql-gateway.sh start-zookeeper-quorum.sh taskmanager.sh
find-flink-home.sh flink-daemon.sh kubernetes-jobmanager.sh pyflink-shell.sh standalone-job.sh stop-cluster.sh yarn-session.sh
[atguigu@node001 bin]$ cd ../lib/
[atguigu@node001 lib]$ ls
flink-cep-1.17.0.jar flink-dist-1.17.0.jar flink-table-api-java-uber-1.17.0.jar FlinkTutorial-1.17-1.0-SNAPSHOT.jar log4j-core-2.17.1.jar
flink-connector-files-1.17.0.jar flink-json-1.17.0.jar flink-table-planner-loader-1.17.0.jar log4j-1.2-api-2.17.1.jar log4j-slf4j-impl-2.17.1.jar
flink-csv-1.17.0.jar flink-scala_2.12-1.17.0.jar flink-table-runtime-1.17.0.jar log4j-api-2.17.1.jar
[atguigu@node001 lib]$ cd ../
[atguigu@node001 flink-1.17.0]$ bin/standalone-job.sh start --job-classname com.atguigu.wc.WordCountStreamUnboundedDemo
Starting standalonejob daemon on host node001.
[atguigu@node001 flink-1.17.0]$ jpsall
================ node001 ================
5491 StandaloneApplicationClusterEntryPoint
5583 Jps
================ node002 ================
3326 Jps
================ node003 ================
3307 Jps
[atguigu@node001 flink-1.17.0]$ bin/taskmanager.sh
Usage: taskmanager.sh (start|start-foreground|stop|stop-all)
[atguigu@node001 flink-1.17.0]$ bin/taskmanager.sh start
Starting taskexecutor daemon on host node001.
[atguigu@node001 flink-1.17.0]$ jpsall
================ node001 ================
5491 StandaloneApplicationClusterEntryPoint
5995 Jps
5903 TaskManagerRunner
================ node002 ================
3363 Jps
================ node003 ================
3350 Jps
[atguigu@node001 flink-1.17.0]$ bin/taskmanager.sh stop
Stopping taskexecutor daemon (pid: 5903) on host node001.
[atguigu@node001 flink-1.17.0]$ bin/standalone-job.sh stop
No standalonejob daemon (pid: 5491) is running anymore on node001.
[atguigu@node001 flink-1.17.0]$ xcall jps
=============== node001 ===============
6682 Jps
=============== node002 ===============
3429 Jps
=============== node003 ===============
3419 Jps
[atguigu@node001 flink-1.17.0]$ P017【017_Flink部署_YARN运行模式_环境准备】07:41
3.5 YARN运行模式(重点)
YARN上部署的过程是:客户端把Flink应用提交给Yarn的ResourceManager,Yarn的ResourceManager会向Yarn的NodeManager申请容器。在这些容器上,Flink会部署JobManager和TaskManager的实例,从而启动集群。Flink会根据运行在JobManger上的作业所需要的Slot数量动态分配TaskManager资源。
[atguigu@node001 flink-1.17.0]$ source /etc/profile.d/my_env.sh
[atguigu@node001 flink-1.17.0]$ myhadoop.sh s
Input Args Error...
[atguigu@node001 flink-1.17.0]$ myhadoop.sh start================ 启动 hadoop集群 ================---------------- 启动 hdfs ----------------
Starting namenodes on [node001]
Starting datanodes
Starting secondary namenodes [node003]--------------- 启动 yarn ---------------
Starting resourcemanager
Starting nodemanagers--------------- 启动 historyserver ---------------
[atguigu@node001 flink-1.17.0]$ jpsall
================ node001 ================
9200 JobHistoryServer
8416 NameNode
8580 DataNode
9284 Jps
8983 NodeManager
================ node002 ================
3892 ResourceManager
3690 DataNode
4365 Jps
4015 NodeManager
================ node003 ================
3680 DataNode
3778 SecondaryNameNode
3911 NodeManager
4044 Jps
[atguigu@node001 flink-1.17.0]$ P018【018_Flink部署_YARN运行模式_会话模式】18:11
[atguigu@node001 bin]$ ./yarn-session.sh --help
[atguigu@node001 bin]$ ./yarn-session.sh
[atguigu@node001 bin]$ ./yarn-session.sh -d -nm test
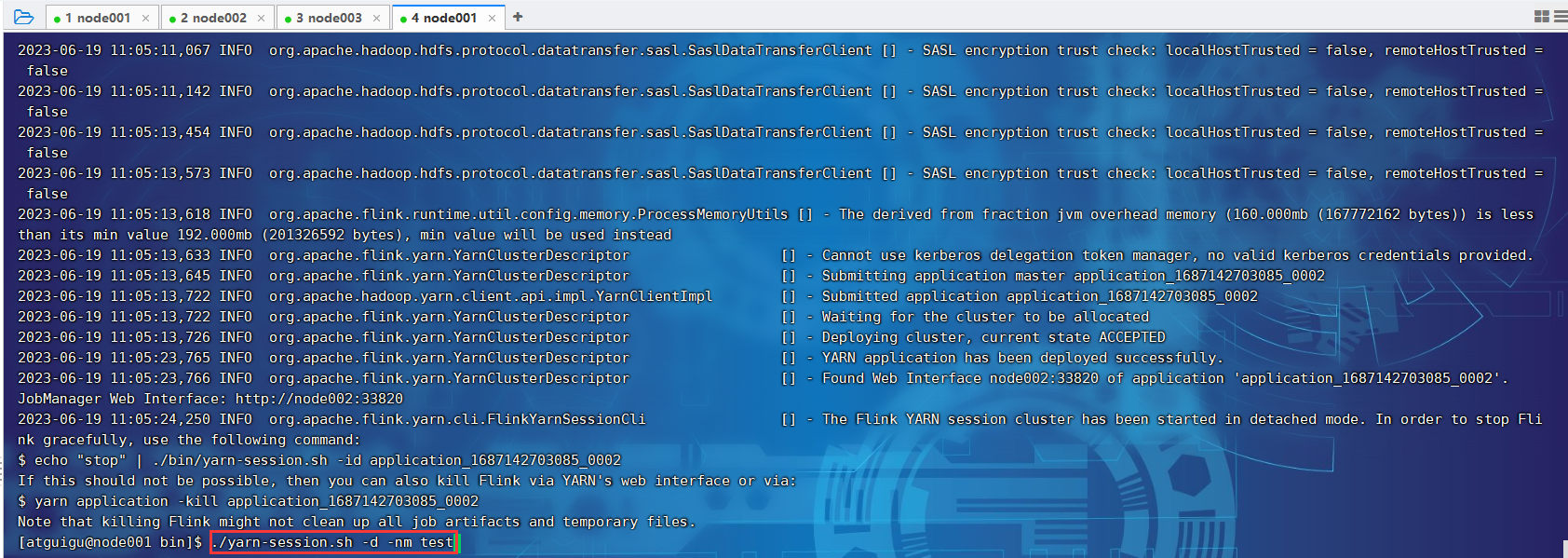
P019【019_Flink部署_YARN运行模式_会话模式的停止】04:10
3.5.3 单作业模式部署
在YARN环境中,由于有了外部平台做资源调度,所以我们也可以直接向YARN提交一个单独的作业,从而启动一个Flink集群。

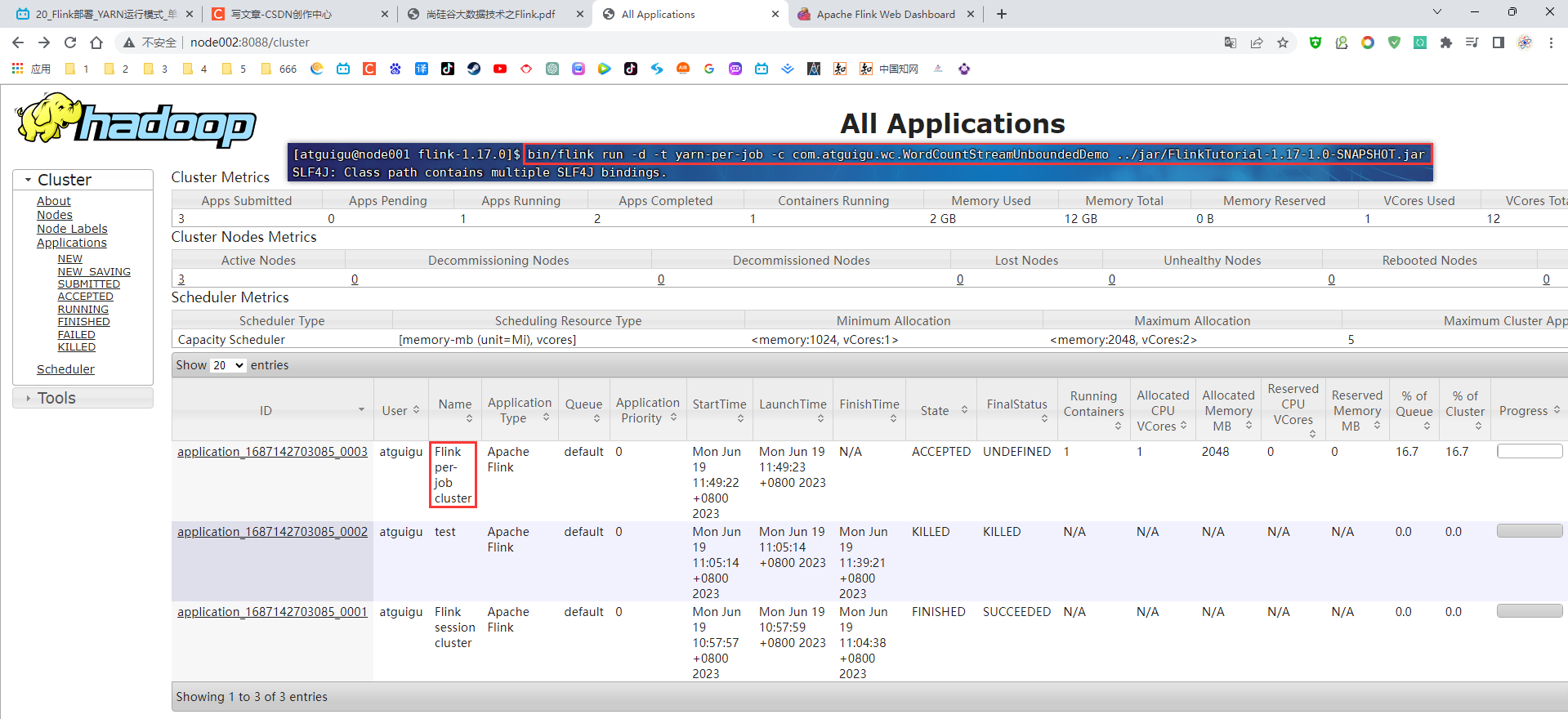
P020【020_Flink部署_YARN运行模式_单作业模式】09:49
3.5.3 单作业模式部署
(1)执行命令提交作业
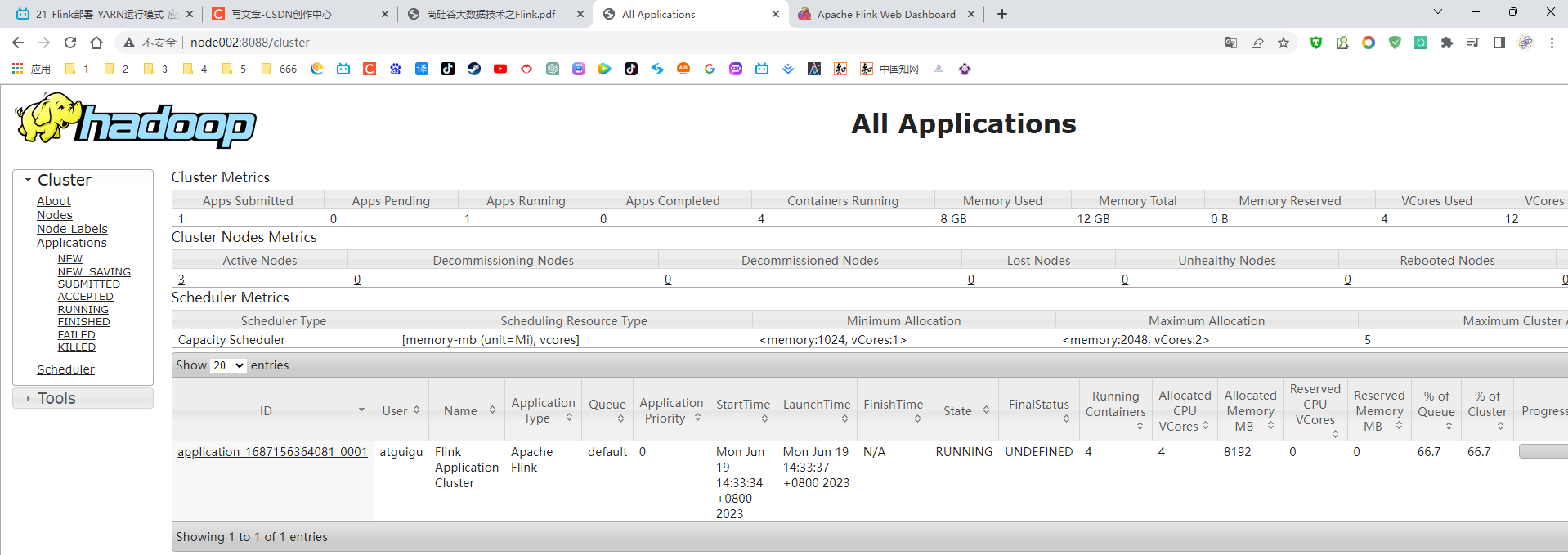
P021【021_Flink部署_YARN运行模式_应用模式】12:51
3.5.4 应用模式部署
应用模式同样非常简单,与单作业模式类似,直接执行flink run-application命令即可。
[atguigu@node001 flink-1.17.0]$ bin/flink run-application -t yarn-application -c com.atguigu.wc.WordCountStreamUnboundedDemo ./FlinkTutorial-1.17-1.0-SNAPSHOT.jar
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flink/flink-1.17.0/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2023-06-19 14:31:05,693 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-atguigu.
2023-06-19 14:31:05,693 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-atguigu.
2023-06-19 14:31:06,142 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/opt/module/flink/flink-1.17.0/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2023-06-19 14:31:06,632 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at node002/192.168.10.102:8032
2023-06-19 14:31:07,195 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar[atguigu@node001 flink-1.17.0]$ bin/flink run-application -t yarn-application -c com.atguigu.wc.WordCountStreamUnboundedDemo ./FlinkTutorial-1.17-1.0-SNAPSHOT.jar
SLF4J: Class path contains multiple SLF4J bindings.
[atguigu@node001 flink-1.17.0]$ bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://node001:8020/flink-dist" -c com.atguigu.wc.WordCountStreamUnboundedDemo hdfs://node001:8020/flink-jars/FlinkTutorial-1.17-1.0-SNAPSHOT.jar

P022【022_Flink部署_历史服务器】08:11
3.6 K8S 运行模式(了解)
容器化部署是如今业界流行的一项技术,基于Docker镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是Kubernetes(k8s),而Flink也在最近的版本中支持了k8s部署模式。基本原理与YARN是类似的,具体配置可以参见官网说明,这里我们就不做过多讲解了。
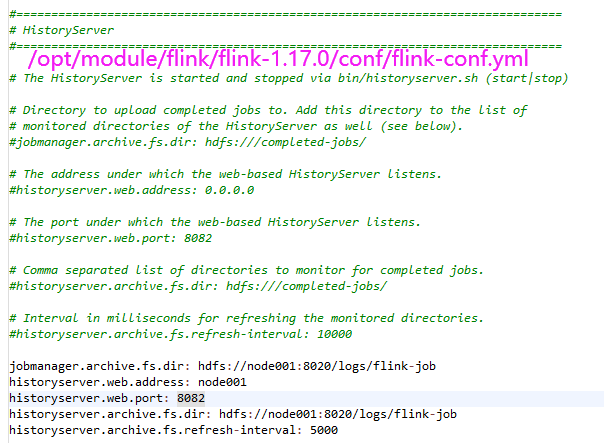
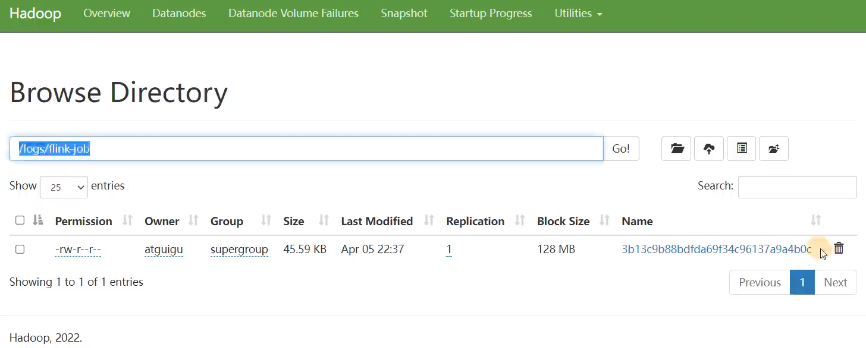
3.7 历史服务器
运行 Flink job 的集群一旦停止,只能去 yarn 或本地磁盘上查看日志,不再可以查看作业挂掉之前的运行的 Web UI,很难清楚知道作业在挂的那一刻到底发生了什么。如果我们还没有 Metrics 监控的话,那么完全就只能通过日志去分析和定位问题了,所以如果能还原之前的 Web UI,我们可以通过 UI 发现和定位一些问题。
Flink提供了历史服务器,用来在相应的 Flink 集群关闭后查询已完成作业的统计信息。我们都知道只有当作业处于运行中的状态,才能够查看到相关的WebUI统计信息。通过 History Server 我们才能查询这些已完成作业的统计信息,无论是正常退出还是异常退出。
此外,它对外提供了 REST API,它接受 HTTP 请求并使用 JSON 数据进行响应。Flink 任务停止后,JobManager 会将已经完成任务的统计信息进行存档,History Server 进程则在任务停止后可以对任务统计信息进行查询。比如:最后一次的 Checkpoint、任务运行时的相关配置。
[atguigu@node001 flink-1.17.0]$ bin/historyserver.sh start
Starting historyserver daemon on host node001.
[atguigu@node001 flink-1.17.0]$ bin/flink run -t yarn-per-job -d -c com.atguigu.wc.WordCountStreamUnboundedDemo ../jar/FlinkTutorial-1.17-1.0-SNAPSHOT.jar
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flink/flink-1.17.0/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
相关文章:
尚硅谷大数据Flink1.17实战教程-笔记02【Flink部署】
尚硅谷大数据技术-教程-学习路线-笔记汇总表【课程资料下载】视频地址:尚硅谷大数据Flink1.17实战教程从入门到精通_哔哩哔哩_bilibili 尚硅谷大数据Flink1.17实战教程-笔记01【Flink概述、Flink快速上手】尚硅谷大数据Flink1.17实战教程-笔记02【Flink部署】尚硅谷…...
【LeetCode每日一题合集】2023.7.3-2023.7.9
文章目录 2023.7.3——445. 两数相加 II(大数相加/高精度加法)2023.7.4——2679. 矩阵中的和2023.7.5——2600. K 件物品的最大和(贪心)代码1——贪心模拟代码2——Java一行 2023.7.6——2178. 拆分成最多数目的正偶数之和&#x…...
java企业工程项目管理系统平台源码
工程项目管理软件(工程项目管理系统)对建设工程项目管理组织建设、项目策划决策、规划设计、施工建设到竣工交付、总结评估、运维运营,全过程、全方位的对项目进行综合管理 工程项目各模块及其功能点清单 一、系统管理 1、数据字典&#…...
软件设计模式与体系结构-设计模式-行为型软件设计模式-访问者模式
目录 二、访问者模式概念代码类图实例一:名牌运动鞋专卖店销售软件实例二:计算机部件销售软优缺点适用场合课程作业 二、访问者模式 概念 对于系统中的某些对象,它们存储在同一个集合中,具有不同的类型对于该集合中的对象&#…...

【LeetCode】503. 下一个更大元素 II
503. 下一个更大元素 II(中等) 方法:单调栈 「 对于找最近一个比当前值大/小」的问题,都可以使用单调栈来解决。栈可以很好的保存原始位置,最近影射栈顶。题目要求更大,因此更大即解–出栈,更小…...
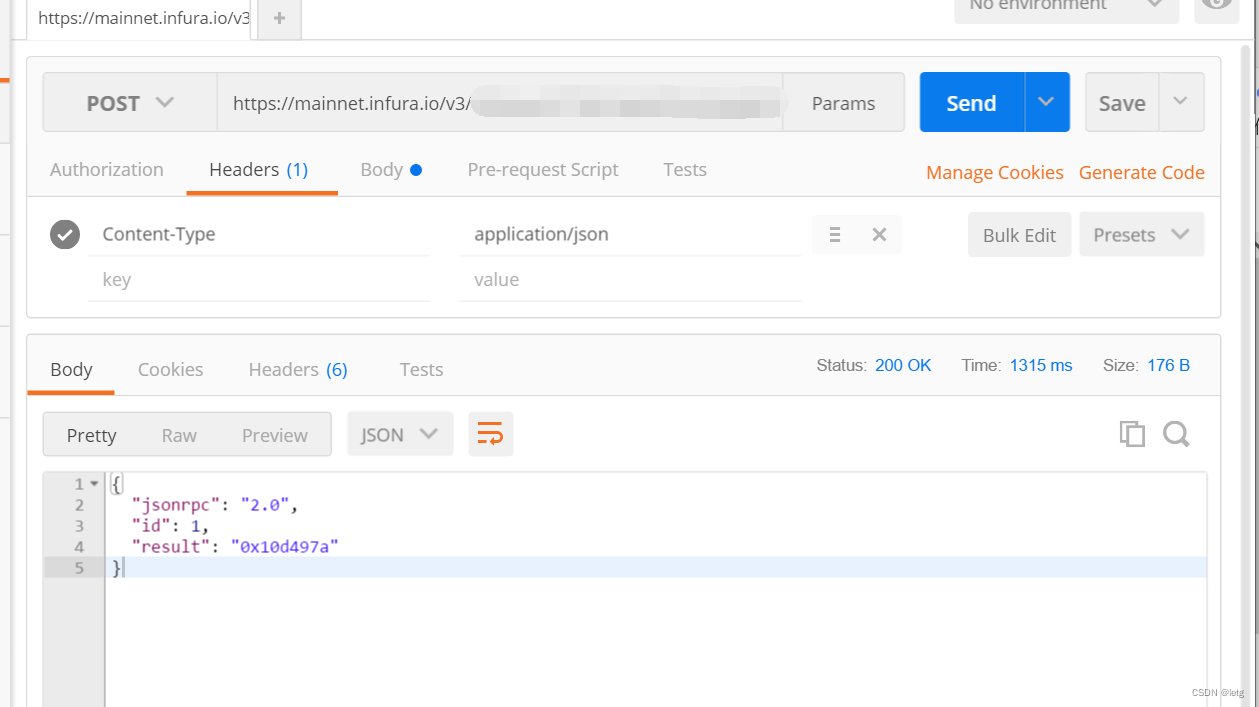
使用infura创建以太坊网络
创建账号 https://www.infura.io/zh 进入控制台Dashboard,选择CREATE API KEY 创建成功后,进入API KEY查看,使用PostMan测试 返回result即为当前区块。...
TCP/IP协议是什么?
78. TCP/IP协议是什么? TCP/IP协议是一组用于互联网通信的网络协议,它定义了数据在网络中的传输方式和规则。作为前端工程师,了解TCP/IP协议对于理解网络通信原理和调试网络问题非常重要。本篇文章将介绍TCP/IP协议的概念、主要组成部分和工…...

python图像处理实战(三)—图像几何变换
🚀写在前面🚀 🖊个人主页:https://blog.csdn.net/m0_52051577?typeblog 🎁欢迎各位大佬支持点赞收藏,三连必回!! 🔈本人新开系列专栏—python图像处理 ❀愿每一个骤雨初…...

学习vue2笔记
学习vue2笔记 文章目录 学习vue2笔记脚手架文件结构关于不同版本的Vuevue.config.js配置文件ref属性props配置项mixin(混入)插件scoped样式总结TodoList案例webStorage组件的自定义事件全局事件总线(GlobalEventBus)消息订阅与发布(pubsub&am…...
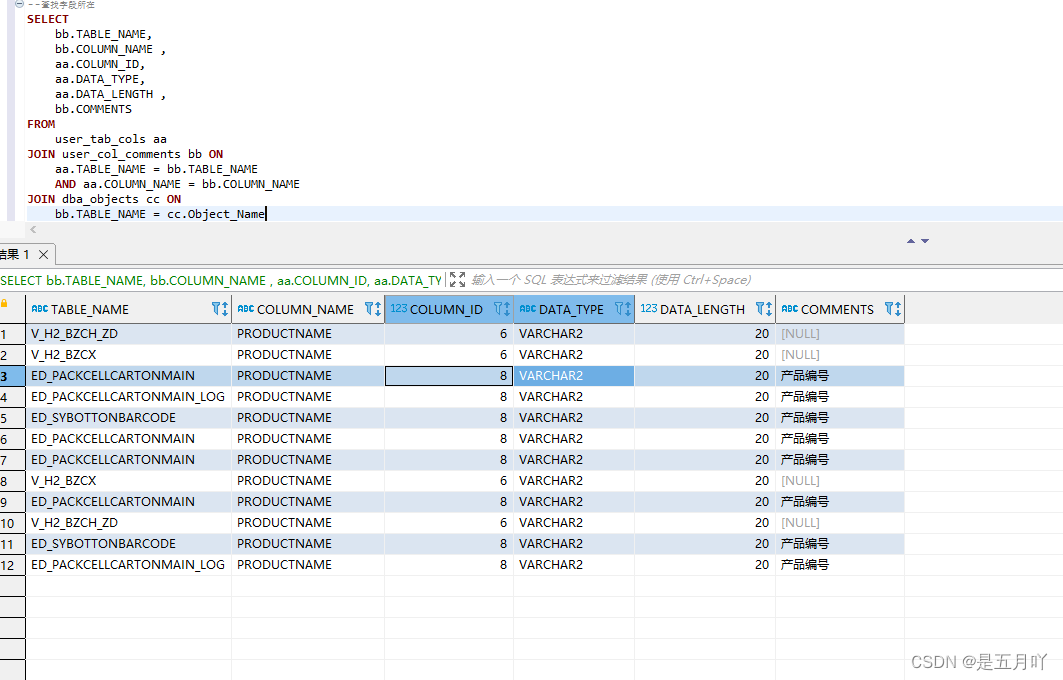
【SQL】查找多个表中相同的字段
--查找字段所在 SELECTbb.TABLE_NAME,bb.COLUMN_NAME ,aa.COLUMN_ID,aa.DATA_TYPE,aa.DATA_LENGTH ,bb.COMMENTS FROMuser_tab_cols aa JOIN user_col_comments bb ONaa.TABLE_NAME bb.TABLE_NAMEAND aa.COLUMN_NAME bb.COLUMN_NAME JOIN dba_objects cc ONbb.TABLE_NAME cc…...

“未来之光:揭秘创新科技下的挂灯魅力“
写在前面: 高度信息化当下时代,对电脑及数字设备的需求与日俱增无处不在,随之而来的视觉疲劳和眼睛问题也攀升到了前所未有的高度。传统台灯对于长时间使用电脑的人群来说是完全无法解决这些问题的。一款ScreenBar Halo 屏幕挂灯,…...

Spring boot MongoDB实现自增序列
在某些特定的业务场景下,会需要使用自增的序列来维护数据,目前项目中因为使用MongoDB,顾记录一下如何使用MongoDB实现自增序列。 MongoDB自增序列原理 MongoDB本身不具有自增序列的功能,但是MongoDB的$inc操作是具有原子性的&…...

MyBatis查询数据库【秘籍宝典】
0.MyBatis执行流程1.第一个MyBatis查询1.创建数据库和表1.2.添加MyBatis框架依赖【新项目】1.3.添加MyBatis框架依赖【旧项目】1.4.配置连接数据库1.5.配置MyBatis的XML路径2.MyBatis模式开发2.1 添加MyBatis的xml配置 3.增查改删(CRUD)5.1.增加操作5.2.…...

目标检测舰船数据集整合
PS:大家如果有想要的数据集可以私信我,如果我下载了的话,可以发给你们~ 一、光学数据集 1、 DIOR 数据集(已下载yolo版本)(论文中提到过) DIOR由23463张最优遥感图像和190288个目标实例组成,这些目标实例用…...

第一章 Android 基础--开发环境搭建
文章目录 1.Android 发展历程2.Android 开发机器配置要求3.Android Studio与SDK下载安装4.创建工程与创建模拟器5.观察App运行日志6.环境安装可能会遇到的问题7.练习题 本专栏主要在B站学习视频: B站Android视频链接 本视频范围:P1—P8 1.Android 发展历…...

【LeetCode周赛】2022上半年题目精选集——二分
文章目录 2141. 同时运行 N 台电脑的最长时间解法1——二分答案补充:求一个int数组的和,但数组和会超int 解法2——贪心解法 2251. 花期内花的数目解法1——二分答案代码1——朴素二分写法代码2——精简二分⭐ 解法2——差分⭐⭐⭐ 2258. 逃离火灾解法1—…...

vuejs如何将线上PDF转为base64编码
只需要两个方法-下载与转换: 下载方法: demoDownloadPDF(url) {// if (!(/^https?:/i.test(url))) return;if (window.XMLHttpRequest) var xhr new XMLHttpRequest(); else var xhr new ActiveXObject("MSXML2.XMLHTTP");xhr.open(GET, u…...

Repo工作原理及常用命令总结——2023.07
文章目录 1. 概要2. 工作原理2.1 项目清单库(.repo/manifests)2.2 repo脚本库(.repo/repo)2.3 仓库目录和工作目录2.4 repo 目录结构分析 3. 使用介绍3.1 init3.2 sync3.3 upload3.4 download3.5 forall3.6 prune3.7 start3.8 status 4. 使用实践4.1 对项目清单文件进行定制4.2…...

Python教程(2)——开发python常用的IDE
为什么需要IDE 在理解IDE之前,我们先做以下的实验,新建一个文件,输入以下代码 total_sum 0 for x in range(1,101):total_sum x print(total_sum)非常非常简单的一个程序,主要就是计算1加到100的值,我们将它重命名…...

【lambda函数】lambda()函数
lambda() lambda()语法捕捉列表mutable lambda 底层原理函数对象与lambda表达式 lambda()语法 lambda表达式书写格式: [capture-list] (parameters) mutable -> return-type{ statement }咱…...

AQM0802字符LCD轻量驱动库:裸机printf级显示方案
1. 项目概述AQM0802 是一款由旭化成(AKM)推出的超低功耗、单色字符型液晶显示模块,采用 COG(Chip-on-Glass)封装工艺,内置 KS0066 兼容控制器。其典型型号为 AQM0802A-YBW,具备 8 字符 2 行的显…...
)
P3916 图的遍历 题解(反向建图)
更好的阅读体验(博客园) 题面 P3916 图的遍历 题目描述 给出 NNN 个点,MMM 条边的有向图,对于每个点 vvv,令 A(v)A(v)A(v) 表示从点 vvv 出发,能到达的编号最大的点。现在请求出 A(1),A(2),…,A(N)A(1),…...

mbed OS双极性步进电机驱动库设计与应用
1. 项目概述BipoarStepperMotor 是一个面向 ARM Cortex-M 系统、专为 mbed OS 平台设计的双极性步进电机驱动库。该库不依赖特定硬件抽象层(HAL)变体,而是基于 mbed OS 提供的标准 DigitalOut 和 PwmOut 接口构建,具备良好的跨平台…...

从单工具到插件集:在Coze IDE里用Python/Node.js打造你的专属工具链
从单工具到插件集:在Coze IDE里用Python/Node.js打造你的专属工具链 在当今快速发展的AI应用开发领域,开发者们不再满足于简单的API调用和单一功能实现。随着业务逻辑的复杂化,如何高效地构建、管理和部署一系列相互关联的工具链,…...

Multisim仿真避坑指南:振幅调制器设计时,如何搞定静态工作点和输出幅度?
Multisim仿真实战:振幅调制器设计的5个关键调试技巧 在电子工程课程设计中,振幅调制器是一个经典但充满挑战的项目。许多学生在Multisim仿真阶段就会遇到各种问题——静态工作点不稳定、输出波形失真、峰峰值不达标...这些问题往往让初学者感到挫败。本文…...

Intent-MPC论文复现手记:我是如何用Docker搞定ROS多版本环境隔离的
Intent-MPC论文复现实战:基于Docker的ROS多版本环境隔离方案 当我在复现Intent-MPC这篇关于无人机动态环境轨迹预测的前沿论文时,最头疼的不是算法理解,而是环境配置——ROS Noetic的依赖冲突、系统库版本不匹配、图形界面无法显示等问题接踵…...

RTX5 | 消息队列实战 - 中断与线程间的数据桥梁
1. 消息队列在RTX5中的核心价值 第一次接触RTX5的消息队列功能时,我正被一个串口通信问题困扰:每次收到数据包都要在中断里完整解析,导致系统响应变慢。后来发现,消息队列就像快递柜——中断服务程序(ISR)是快递员,只需…...

C++程序发生崩溃闪退后为什么会自动重启?是因为程序中启用了重启管理器,系统感知到程序异常退出后自动重启程序
最近在使用sdkdemo程序测试我们的SDK功能时,发现当我们关闭程序后(程序确实关闭了),程序居然又自动启动起来了!后来运行Debug版本的sdkdemo,在关闭程序时会弹出报错提示框:估计是程序在退出时产…...

如何免费使用Pyfa:EVE Online舰船配置终极实用指南
如何免费使用Pyfa:EVE Online舰船配置终极实用指南 【免费下载链接】Pyfa Python fitting assistant, cross-platform fitting tool for EVE Online 项目地址: https://gitcode.com/gh_mirrors/py/Pyfa Pyfa(Python Fitting Assistant)…...

单片机入门指南:硬件工程师成长路径与实战技巧
1. 单片机入门:从零开始的硬件工程师成长之路作为一名在嵌入式领域摸爬滚打多年的工程师,我见过太多初学者在单片机学习路上走弯路。单片机确实是个神奇的东西——它体积小、价格低,却能控制各种电子设备,从智能家居到工业自动化无…...