Flink 读写Kafka总结
前言
总结Flink读写Kafka
Flink 版本
1.15.4
Table API
本文主要总结Table API的使用(SQL),官方文档:https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/connectors/table/kafka/
kerberos认证相关配置
官方文档:
- https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/connectors/datastream/kafka/#%E5%90%AF%E7%94%A8-kerberos-%E8%BA%AB%E4%BB%BD%E9%AA%8C%E8%AF%81
- https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/deployment/security/security-kerberos/
- https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/deployment/config/#auth-with-external-systems
修改conf/flink-conf.yaml
security.kerberos.login.keytab: /etc/security/keytabs/hive.service.keytab
security.kerberos.login.principal: hive/indata-192-168-44-128.indata.com@INDATA.COMjava.security.auth.login.config: /usr/hdp/3.1.0.0-78/kafka/conf/kafka_jaas.conf
security.kerberos.login.contexts: Client,KafkaClient
kafka_jaas.conf
KafkaClient {com.sun.security.auth.module.Krb5LoginModule requireduseTicketCache=truesecurity.protocol=SASL_PLAINTEXTrenewTicket=trueserviceName="kafka";};Client {com.sun.security.auth.module.Krb5LoginModule requireduseKeyTab=truesecurity.protocol=SASL_PLAINTEXTkeyTab="/etc/security/keytabs/kafka.service.keytab"storeKey=trueuseTicketCache=falseserviceName="zookeeper"principal="kafka/indata-192-168-44-128.indata.com@INDATA.COM";};
jar包
将flink-sql-connector-kafka-1.15.4.jar拷贝到lib路径下,下载地址:
https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-kafka/1.15.4/flink-sql-connector-kafka-1.15.4.jar
我最开始是将
flink-connector-kafka-1.15.4.jar和kafka-clients-2.8.1.jar拷贝到lib路径下,下载地址:
https://repo1.maven.org/maven2/org/apache/flink/flink-connector-kafka/1.15.4/flink-connector-kafka-1.15.4.jar
https://repo1.maven.org/maven2/org/apache/kafka/kafka-clients/2.8.1/kafka-clients-2.8.1.jar
原因是官方文档:https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/connectors/table/kafka/中提到的依赖就是flink-connector-kafka,而不是flink-sql-connector-kafka,至于为啥还需要kafka-clients,是因为如果不放kafka-clients包,会报异常:java.lang.ClassNotFoundException: org.apache.kafka.clients.consumer.OffsetResetStrategy
kafka-clients的版本可以在flink源码的pom中找到

其实flink-sql-connector-kafka就是将flink-connector-kafka和kafka相关的依赖一块打包的

对于其他类型的connector的jar包,都可以直接下载
flink-sql-connector-*.jar,名字带sql的jar包含了相关的依赖,不用单独配置其他依赖jar包,比较方便
sql-client
以sql-client提交SQL的方式进行测试验证。
读写Kafka
CREATE TABLE if not exists test_flink_kafka (id int,name string,price double,ts int,dt string
) WITH ('connector' = 'kafka','topic' = 'test_flink_kafka','properties.bootstrap.servers' = 'indata-192-168-44-128:6667','properties.security.protocol' = 'SASL_PLAINTEXT','properties.sasl.mechanism' = 'GSSAPI','properties.sasl.kerberos.service.name' = 'kafka','properties.group.id' = 'dkl','scan.startup.mode' = 'earliest-offset','value.format' = 'json'
);
写Kafka
insert into test_flink_kafka values (1,'hudi1',1.1,1000,'20230619'),(2,'hudi2',2.2,2000,'20230619');
读Kafka
select * from test_flink_kafka;
Kafka2Hudi
Hudi 0.13.0 需要将
calcite-core-1.10.0.jar放到Flink lib下,同步Hive时需要
set yarn.application.name=kafka2hudi;set parallelism.default=1;
set taskmanager.memory.process.size=3g;set execution.checkpointing.interval=10000;
set state.checkpoints.dir=hdfs:///flink/checkpoints/kafka2hudi;
set execution.checkpointing.externalized-checkpoint-retention= RETAIN_ON_CANCELLATION;CREATE TABLE if not exists kafka_source (id int,name string,price double,ts int,dt string
) WITH ('connector' = 'kafka','topic' = 'test_flink_kafka','properties.bootstrap.servers' = 'indata-192-168-44-128:6667','properties.security.protocol' = 'SASL_PLAINTEXT','properties.sasl.mechanism' = 'GSSAPI','properties.sasl.kerberos.service.name' = 'kafka','properties.group.id' = 'dkl','scan.startup.mode' = 'earliest-offset','value.format' = 'json'
);CREATE TABLE hudi_sink (id int PRIMARY KEY NOT ENFORCED,name string,price double,ts bigint,dt string
)
WITH ('connector' = 'hudi','path' = '/tmp/cdc/hudi_sink','write.operation'='insert', --写类型,可选'write.tasks'='1', --并行度,可选,需要传参'table.type'='COPY_ON_WRITE', --表类型,可选'precombine.field' = 'ts', --可选,预合并字段和历史比较字段,当新来的数据该字段大于历史值时才会更新,默认为ts(如果有这个ts字段的话),需要传参,没有可不填,建议将该值设置为update_time'hoodie.datasource.write.recordkey.field' = 'id', -- 可选,和primary key效果一样,二者至少选一个'hoodie.datasource.write.keygenerator.class' = 'org.apache.hudi.keygen.ComplexAvroKeyGenerator', --该参数目前版本有bug'index.type' = 'BUCKET', -- flink只支持两种index,默认FLINK_STATE;默认的state index对于数据量比较大的情况会因为tm内存不足导致GC OOM,并且如果不是用checkpoint恢复的话会导致数据重复'hoodie.bucket.index.num.buckets' = '16', -- 桶数'hive_sync.enable' = 'true','hive_sync.mode' = 'hms','hive_sync.conf.dir'='/usr/hdp/3.1.0.0-78/hive/conf','hive_sync.db' = 'cdc','hive_sync.table' = 'hudi_sink','hoodie.datasource.hive_sync.create_managed_table' = 'true' --是否为内部表,0.13.0版本开始支持
);insert into hudi_sink select * from kafka_source;cdc2Kafka
对于cdc数据写kafka,普通的formats是不支持的,需要使用cdc格式的formats,比如debezium-json,此外还有canal-json、maxwell-json和ogg-json,Flink有哪些formats以及支持的connectors可以参考官网:https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/connectors/table/formats/overview/。
除了使用cdc格式的formats,还可以将cdc数据写到upsert-kafka中(‘connector’ = ‘upsert-kafka’),upsert-kafka对应的文档地址:https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/connectors/table/upsert-kafka/
普通的formats会报如下异常:
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.TableException: Table sink 'default_catalog.default_database.kafka_sink' doesn't support consuming update and delete changes which is produced by node TableSourceScan(table=[[default_catalog, default_database, mysql_cdc_source]], fields=[id, name, price, ts, dt])
使用debezium-json,cdc_mysql2kafka示例SQL
set yarn.application.name=cdc_mysql2kafka;set execution.checkpointing.interval=1000;
set state.checkpoints.dir=hdfs:///flink/checkpoints/cdc_mysql2kafka;
set execution.checkpointing.externalized-checkpoint-retention= RETAIN_ON_CANCELLATION;set state.backend=rocksdb;CREATE TABLE mysql_cdc_source (id int PRIMARY KEY NOT ENFORCED, --主键必填,且要求源表必须有主键,flink主键可以和mysql主键不一致name string,price double,ts bigint,dt string
) WITH ('connector' = 'mysql-cdc','hostname' = '192.168.44.128','port' = '3306','username' = 'root','password' = 'password','database-name' = 'cdc','table-name' = 'mysql_cdc_source'
);CREATE TABLE if not exists kafka_sink (id int,name string,price double,ts bigint,dt string
) WITH ('connector' = 'kafka','topic' = 'kafka_sink','properties.bootstrap.servers' = 'indata-192-168-44-128:6667','properties.security.protocol' = 'SASL_PLAINTEXT','properties.sasl.mechanism' = 'GSSAPI','properties.sasl.kerberos.service.name' = 'kafka','properties.group.id' = 'dkl','scan.startup.mode' = 'earliest-offset','value.format' = 'debezium-json'
);insert into kafka_sink select * from mysql_cdc_source;使用kafka命令行查看一下topic里面的内容,看看debezium-json格式的数据长什么样
/usr/hdp/3.1.0.0-78/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.44.128:6667 --from-beginning --topic kafka_sink --group dkl --consumer-property security.protocol=SASL_PLAINTEXT{"before":null,"after":{"id":1,"name":"my_catalog","price":11.11,"ts":1000,"dt":"2023-04-12"},"op":"c"}
{"before":null,"after":{"id":2,"name":"my_catalog","price":11.11,"ts":1000,"dt":"2023-04-12"},"op":"c"}
{"before":null,"after":{"id":3,"name":"my_catalog","price":123.0,"ts":1000,"dt":"2023-04-12"},"op":"c"}
{"before":null,"after":{"id":4,"name":"my_catalog","price":123.0,"ts":1000,"dt":"2023-04-12"},"op":"c"}
upsert-kafka SQL示例
CREATE TABLE if not exists upsert_kafka_sink (id int,name string,price double,ts bigint,dt string,PRIMARY KEY (id) NOT ENFORCED
) WITH ('connector' = 'upsert-kafka','topic' = 'upsert_kafka_sink','properties.bootstrap.servers' = 'indata-192-168-44-128:6667','properties.security.protocol' = 'SASL_PLAINTEXT','properties.sasl.mechanism' = 'GSSAPI','properties.sasl.kerberos.service.name' = 'kafka','properties.group.id' = 'dkl','scan.startup.mode' = 'earliest-offset','key.format' = 'json','value.format' = 'json'
);
upsert-kafka参数和kafka参数有以下不同,多了两个必选:
- PRIMARY KEY
- key.format
不支持参数:
- scan.startup.mode
消费CDC格式的Kafka
Flink消费CDC格式的kafa数据时,有一个问题:checkpoint会随着消费数据量的增加越来越大,和sink端无关
比如sink端是print(‘connector’ = ‘print’)的截图

根据我个人理解,checkpoint一般只需要保存kafka offset信息就可以了,但是offset对应的文件不可能有那么大,将checkpoint文件查看一下里面的内容,发现保存的也不是kafka的数据。
可能和SourceSplit有关,这块我也不太懂,这个问题我还没有解决,下面是checkpoint文件内容截图:



Sink kafka exactly once
官方文档地址:https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/connectors/table/kafka/#%E4%B8%80%E8%87%B4%E6%80%A7%E4%BF%9D%E8%AF%81
https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/connectors/datastream/kafka/#%E5%AE%B9%E9%94%99
文档一:
默认情况下,如果查询在 启用 checkpoint 模式下执行时,Kafka sink 按照至少一次(at-lease-once)语义保证将数据写入到 Kafka topic 中。
当 Flink checkpoint 启用时,kafka 连接器可以提供精确一次(exactly-once)的语义保证。
除了启用 Flink checkpoint,还可以通过传入对应的 sink.semantic 选项来选择三种不同的运行模式:
none:Flink 不保证任何语义。已经写出的记录可能会丢失或重复。
at-least-once (默认设置):保证没有记录会丢失(但可能会重复)。
exactly-once:使用 Kafka 事务提供精确一次(exactly-once)语义。当使用事务向 Kafka 写入数据时,请将所有从 Kafka 中消费记录的应用中的 isolation.level 配置项设置成实际所需的值(read_committed 或 read_uncommitted,后者为默认值)。
文档二:
KafkaSink 总共支持三种不同的语义保证(DeliveryGuarantee)。对于 DeliveryGuarantee.AT_LEAST_ONCE 和 DeliveryGuarantee.EXACTLY_ONCE,Flink checkpoint 必须启用。默认情况下 KafkaSink 使用 DeliveryGuarantee.NONE。 以下是对不同语义保证的解释:
DeliveryGuarantee.NONE 不提供任何保证:消息有可能会因 Kafka broker 的原因发生丢失或因 Flink 的故障发生重复。
DeliveryGuarantee.AT_LEAST_ONCE: sink 在 checkpoint 时会等待 Kafka 缓冲区中的数据全部被 Kafka producer 确认。消息不会因 Kafka broker 端发生的事件而丢失,但可能会在Flink重启时重复,因为Flink会重新处理旧数据。
DeliveryGuarantee.EXACTLY_ONCE: 该模式下,Kafka sink 会将所有数据通过在 checkpoint 时提交的事务写入。因此,如果 consumer 只读取已提交的数据(参见 Kafka consumer 配置 isolation.level),在 Flink 发生重启时不会发生数据重复。然而这会使数据在checkpoint完成时才会可见,因此请按需调整 checkpoint 的间隔。请确认事务ID的前缀(transactionIdPrefix)对不同的应用是唯一的,以保证不同作业的事务不会互相影响!此外,强烈建议将Kafka的事务超时时间调整至远大于checkpoint最大间隔 + 最大重启时间,否则Kafka对未提交事务的过期处理会导致数据丢失。
前提:开启checkpoint;exactly-once其实是通过kafka事务实现的,kafka 0.11+开始支持事务,所以还需要kafka的版本大于0.11;将Kafka的事务超时时间(producer transaction.timeout.ms)调整至远大于checkpoint最大间隔 + 最大重启时间,否则Kafka对未提交事务的过期处理会导致数据丢失。
文档一为Table API的文档,文档二为DataStream的文档,两者看起来差不太多,但是参数又不太一样,这很令人费解,加上后面验证sink cdc格式exactly once正好碰到了问题,用文档二的参数才解决,所以我看了源码一探究竟,两者的区别如下:
sink.semantic为弃用参数,新的参数为sink.delivery-guarantee,另外可能还需要结合sink.transactional-id-prefix一起使用,下面是相关源码:
private static DeliveryGuarantee validateDeprecatedSemantic(ReadableConfig tableOptions) {// 如果配置了sink.semanticif (tableOptions.getOptional(SINK_SEMANTIC).isPresent()) {// 警告sink.semantic已经弃用,其使用新的参数sink.delivery-guaranteeLOG.warn("{} is deprecated and will be removed. Please use {} instead.",SINK_SEMANTIC.key(),DELIVERY_GUARANTEE.key());// 根据sink.semantic的值构建DeliveryGuarantee并返回 return DeliveryGuarantee.valueOf(tableOptions.get(SINK_SEMANTIC).toUpperCase().replace("-", "_"));}// 否则直接返回sink.delivery-guarantee对应的值return tableOptions.get(DELIVERY_GUARANTEE);}

官方文档不及时更新或者不一致也挺耽误事儿的,之前总结checkpoint时也发现了官方文档很多配置参数都是过时弃用的。。
配置参数:
'properties.transaction.timeout.ms'='900000', --可选,后面异常解决中有解释
'sink.delivery-guarantee'='exactly-once'
-- 'sink.semantic' = 'exactly-once' -- 已经弃用
-- 'sink.transactional-id-prefix'='dkl', --可选,默认值:kafka-sink;事务前缀,需要保证对不同的应用是唯一的,以保证不同作业的事务不会互相影响先说结论:sink.delivery-guarantee和sink.transactional-id-prefix最好一起使用,因为不设置sink.transactional-id-prefix也就是使用默认值的情况会出现问题(后面有解释)
一致性验证
首先启动sink kafka的任务,在生成了一个ckp之后(且还有数据没有写完),停止kafka服务,等一段时间后启动kafka服务,然后等待数据跑完,验证数据量。
假如source数据量有200万条数据,用Flink SQL count验证
默认参数:数据量大于200万
配置consumer读事务参数:‘properties.isolation.level’=‘read_committed’ (Flink SQL建表语句中添加),数据量正好等于200万
isolation.level默认值为read_uncommitted,默认读所有的消息,commit和没commit都会读出来,所以数据可能会重复。而read_committed只读commit的记录,数据没有重复,可以保证 exactly once。
事务和topic是否分区无关,也就是对于多个分区的topic也支持事务
CDC格式 exactly once
对于sink普通格式,我最开始通过参数’sink.semantic’ = 'exactly-once’就可以了(开始不知道有新的参数),但是对于sink cdc格式,只使用sink.semantic参数,会有问题,需要通过参数sink.transactional-id-prefix和sink.delivery-guarantee来解决。
'sink.transactional-id-prefix'='dkl', --事务前缀,需要保证对不同的应用是唯一的,以保证不同作业的事务不会互相影响
'sink.delivery-guarantee'='exactly-once'
仅使用sink.semantic参数时也就是不设置事务前缀(默认值kafka-sink)的问题:有一个任务一直处于INITIALIZING,很长时间(现在测试的是卡住8分钟左右,之前测试的是卡住一个半小时左右,不知道什么原因导致时间减少了)之后才会变为running,导致任务卡住很长时间。


小结
我最开始仅设置了sink.semantic参数来验证sink普通格式是没有问题的,后来同事提出问题说sink cdc格式时任务会卡住。最后用了新的参数:sink.delivery-guarantee和sink.transactional-id-prefix解决了这个问题,当时以为对于cdc格式的必须用新参数才行,当时就感觉这个结论不是很合理。
后面因为没有时间管这个问题就没有去深究,现在再进行总结,有了新的认知:
1、sink.semantic和sink.delivery-guarantee是一样的,只是一个是弃用的旧参数,一个新参数
2、仅设置sink.semantic时和同时设置sink.delivery-guarantee和sink.transactional-id-prefix参数的唯一区别是前缀不一样,一个是使用默认前缀kafka-sink(当时不知道有默认值),另一个是自己配置
那么问题来了,其实两种设置没有本质区别,都有前缀,那为啥表现不一样,后者会卡住呢?后来我再验证发现,对于普通格式,使用默认前缀也会卡住;对于所有的格式,我自己配置了一个前缀有的也会卡住,也就是问题和格式无关。
那原因是啥呢,我想的是卡住的原因是不同的任务前缀不能一样,如果一样了就会卡住。其实我停止了前面的所有任务,再使用相同的前缀起一个新的任务也有可能会卡住(有概率),我想这个可能是因为缓存的原因,也就是前面的任务虽然停了,但是不知道哪里还有缓存,导致新的任务认为有其他任务在使用这个相同的前缀,所以卡住了(结论不一定正确)。所以对于每一个任务我们都最好生成一个新的唯一的前缀。
默认前缀:

异常解决
异常一
org.apache.flink.kafka.shaded.org.apache.kafka.common.errors.TransactionalIdAuthorizationException: Transactional Id authorization failed.
这个异常,网上没有找到对应的资料,是我自己偶然发现的,解决方案:在ranger kafka策略里有一条策略单独控制Transactional Id,改一下这个策略加上对应的用户,比如我是用的hive用户

异常二
org.apache.flink.kafka.shaded.org.apache.kafka.common.KafkaException: Unexpected error in InitProducerIdResponse; The transaction timeout is larger than the maximum value allowed by the broker (as configured by transaction.max.timeout.ms).at org.apache.flink.kafka.shaded.org.apache.kafka.clients.producer.internals.TransactionManager$InitProducerIdHandler.handleResponse(TransactionManager.java:1386)at org.apache.flink.kafka.shaded.org.apache.kafka.clients.producer.internals.TransactionManager$TxnRequestHandler.onComplete(TransactionManager.java:1290)at org.apache.flink.kafka.shaded.org.apache.kafka.clients.ClientResponse.onComplete(ClientResponse.java:109)at org.apache.flink.kafka.shaded.org.apache.kafka.clients.NetworkClient.completeResponses(NetworkClient.java:584)at org.apache.flink.kafka.shaded.org.apache.kafka.clients.NetworkClient.poll(NetworkClient.java:576)at org.apache.flink.kafka.shaded.org.apache.kafka.clients.producer.internals.Sender.maybeSendAndPollTransactionalRequest(Sender.java:417)at org.apache.flink.kafka.shaded.org.apache.kafka.clients.producer.internals.Sender.runOnce(Sender.java:315)at org.apache.flink.kafka.shaded.org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:242)at java.lang.Thread.run(Thread.java:748)
原因是因为flink kafka connector sink kafka时将事务默认的超时时间(transaction.timeout.ms)设置为一小时,超过了kafka默认的最大超时时间(transaction.max.timeout.ms)15分钟,解决方法有两个,一个是在建表语句中将transaction.timeout.ms设置小一点,比如设置为15分钟
'properties.transaction.timeout.ms'='900000'
另一种方法是修改kafka服务端的配置,增加transaction.max.timeout.ms,比如设置为一小时,transaction.max.timeout.ms=‘3600000’,两种方法可以结合使用,个人建议最好将transaction.max.timeout.ms设置大一点。因为上面有提到:强烈建议将Kafka的事务超时时间(producer transaction.timeout.ms)调整至远大于checkpoint最大间隔 + 最大重启时间,否则Kafka对未提交事务的过期处理会导致数据丢失。如果checkpoint的时间间隔比,较大超过15分钟了,大于了事务时间,那么就可能会丢失数据,所以不如直接将transaction.max.timeout.ms设置为一小时,properties.transaction.timeout.ms不用设置,也就是按照默认的一小时。
ambari修改kafka broker的事务最大超时时间

flink sink kafka默认一小时(transaction.timeout.ms)

kafka默认15分钟(transaction.max.timeout.ms)
其他异常
有几个可以忽略的异常,具体表现为停止kafka一段时间,再重启动kafka时会抛出一个异常,只有一次,不会一直报,具体的异常信息就不贴了
默认配置
默认值是AT_LEAST_ONCE,也就是默认情况下数据可能会重复但不会少,但是我之前测试的是数据会少,不过没有研究原因,现在想要研究一下之前问题少的原因,结果又正常了,无法复现之前的问题了,不知道啥原因~
参考文章
https://www.cnblogs.com/xijiu/p/16917741.html
相关阅读
- Flink用户自定义连接器(Table API Connectors)学习总结
- Flink MySQL CDC 使用总结
- Flink SQL Checkpoint 学习总结
相关文章:
Flink 读写Kafka总结
前言 总结Flink读写Kafka Flink 版本 1.15.4 Table API 本文主要总结Table API的使用(SQL),官方文档:https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/connectors/table/kafka/ kerberos认证相关配置 …...
LiDAR SLAM 闭环——BoW3D论文详解
标题:BoW3D: Bag of Words for Real-Time Loop Closing in 3D LiDAR SLAM 作者:Yunge Cui,Xieyuanli Chen,Yinlong Zhang,Jiahua Dong,Qingxiao Wu,Feng Zhu 机构:中科院沈阳自动化研究所 来源:2022 RAL 现算法已经开源&#…...

Android NTP时间同步源码分析
Android NTP时间同步源码分析 Android系统设置自动时间后,如果连接了可用的网络。会同步网络时间。这个处理是 NetworkTimeUpdateService完成的。某些定制化的系统,需要禁止网络时间同步。比如仅仅使用GPS时间。基于Android9,分析一下 Andro…...

数据库之MySQL字符集与数据库操作
目录 字符集 CHRARCTER SET 与COLLATION的关联 CHRARCTER SET 定义 基础操作 查看当前MySQL Server支持的 CHARACTER SET 查看特定字符集信息(主要包含默认的COLLATION 与 MAXLEN) COLLATION 定义 COLLATION后缀 基础操作 查看MySQL Server支持的…...
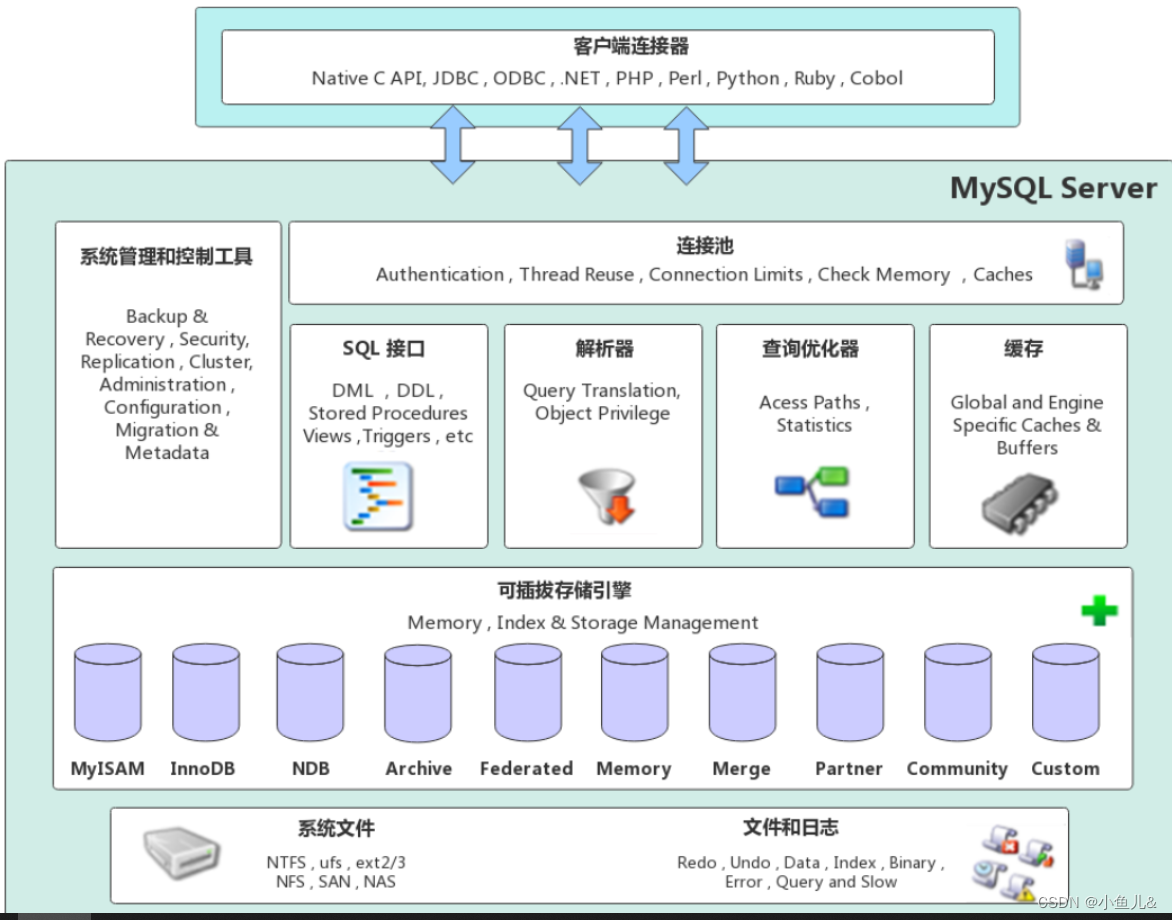
搜索引擎概念解析
搜索引擎概念解析 什么是搜索引擎 MySQL搜索引擎举例 搜索引擎是一种用于在互联网上搜索并呈现相关信息的工具。它通过自动扫描和索引大量网页内容,并根据用户提供的关键词或查询条件,返回与之相关的网页链接和摘要。 当用户在搜索引擎中输入关键词或…...
网页链接投票链接步骤公众号投票链接制作制作投票
大家在选择投票小程序之前,可以先梳理一下自己的投票评选活动是哪种类型,目前有匿名投票、图文投票、视频投票、赛事征集投票等。 我们现在要以“笛乐悠扬”为主题进行一次投票活动,我们可以在在微信小程序搜索,“活动星”投票小程…...

【通信安全CACE-管理类基础级】第7章 安全运维
资源 中国通信企业协会网络安全人员能力认证考试知识点大纲 中国通信企业协会网络安全人员能力认证管理类基础级考试课件 中国通信企业协会网络安全人员能力认证考试管理类基础级复习资料 中国通信企业协会网络安全人员能力认证考试管理类基础级模拟题 系列文章 【通信安全CAC…...
)
随手笔记——将ROS图像话题转为OpenCV图像格式处理后再转为ROS图像话题发布(Python版)
随手笔记——将ROS图像话题转为OpenCV图像格式处理后再转为ROS图像话题发布(Python版) 说明关键函数代码 说明 将ROS图像话题转为OpenCV图像格式处理后再转为ROS图像话题发布,主要通过CvBridge的cv2_to_imgmsg和imgmsg_to_cv2函数࿰…...
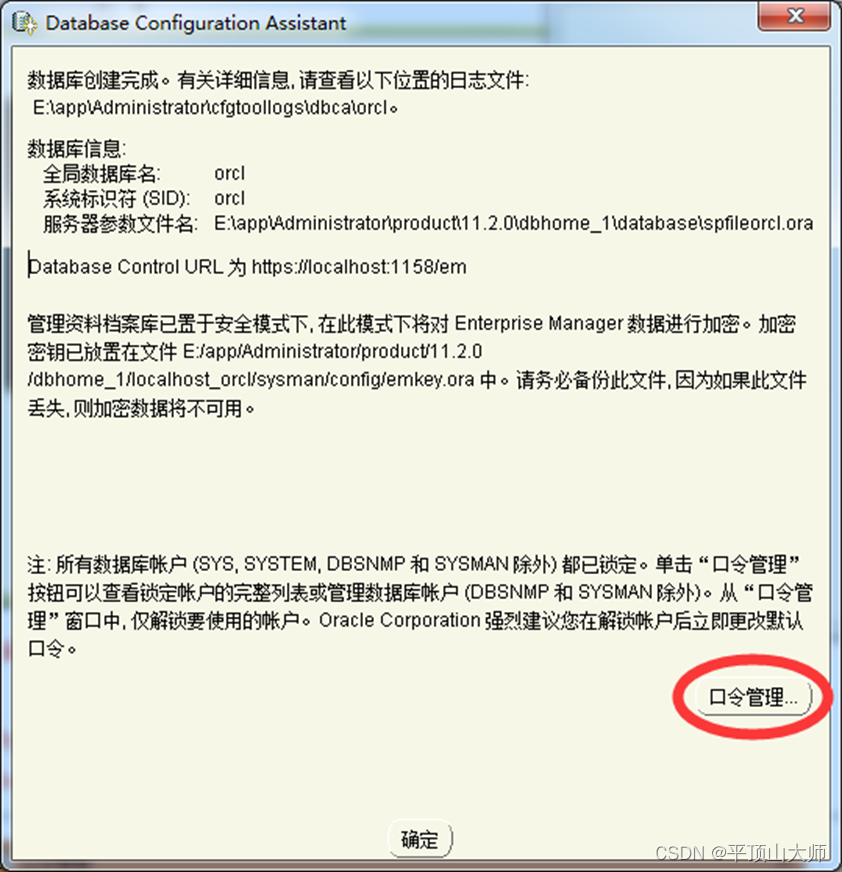
Win11系统如何安装Oracle数据库(超级详细)
前言:在我们安装Oracle之前我们得理解Oracle数据库的优点是什么: Oracle是一个功能强大、可扩展和全面的数据库平台,具有广泛的功能和企业级能力,适用于处理复杂的企业级应用和大型数据集。 目录 一.下载Oracle数据库软件&…...
【代理服务器】Squid 反向代理与Nginx缓存代理
目录 一、Squid 反向代理1.1工作机制1.2反向代理实验1.3清空iptables规则,关闭防火墙1.4验证 二、使用Nginx做反向代理缓存服务器三CDN简介3.1什么是CDN3.1CDN工作原理 一、Squid 反向代理 如果 Squid 反向代理服务器中缓存了该请求的资源,则将该请求的…...

目标检测之遮挡物体检测
一、遮挡的类别 类内遮挡,目标被同一类别的目标遮挡类间遮挡,目标被其它类别的目标遮挡 二、解决方法 数据标注 精调遮挡目标的GT边界框 数据增强 cutout:在训练时,随机mask目标,提升模型对遮挡的应对能力mosaic…...

Vim 命令大全
文章目录 Vim 命令大全移动光标编辑文本查找和替换保存和退出打开多个文件:在文件之间切换:打开新窗口切换窗口其他常用命令 Vim 命令大全 移动光标 h: 左移光标j: 下移光标k: 上移光标l: 右移光标0: 移动光标到行首$: 移动光标到行末G: 移动光标到文件…...

【Visual Studio】printf() 函数无输出显示问题。使用 C++ 语言,配合 Qt 开发串口通信界面
使用 C 语言,配合 Qt 开发串口通信界面时,遇到 printf() 函数无输出显示。 在工程属性的对应位置添加 editbin /SUBSYSTEM:CONSOLE $(OUTDIR)\$(ProjectName).exe 即可,如下图所示。 成功运行的截图如下: Ref. Visual Studio 20…...
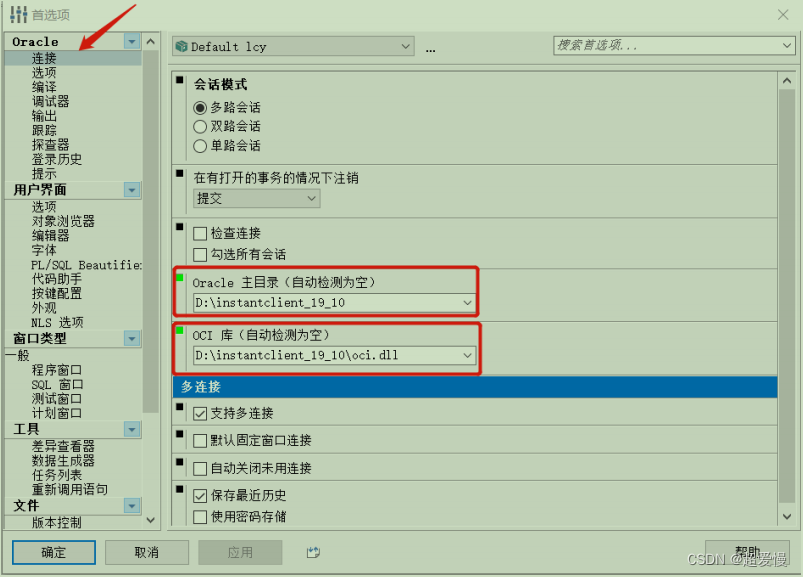
Linux安装配置Oracle+plsql安装配置(详细)
如果觉得本文不够详细,没有效果图,可移步详细版: Linux安装配置Oracleplsql安装配置(超详细)_超爱慢的博客-CSDN博客 目录 1.安装虚拟机系统 1.安装虚拟机 2.配置虚拟机 1.设置机器名 2.修改域名映射 3.固定IP…...

软件UI工程师的职责模板
软件UI工程师的职责模板1 职责: 1.负责产品的UI视觉设计(手机软件界面 网站界面 图标设计产品广告及 企业文化的创意设计等); 2.负责公司各种客户端软件客户端的UI界面及相关图标制作; 3.设定产品界面的整体视觉风格; 4.为开发工程师创建详细的界面说明文档&…...

【Python】Selenium操作cookie实现免登录
文章目录 一、查看浏览器cookie二、获取cookie基本操作三、获取cookie并实现免登录四、封装成函数 一、查看浏览器cookie cookie、session、token的区别: cookie存储在浏览器本地客户端,发送的请求携带cookie时可以实现登录操作。session存放在服务器。…...
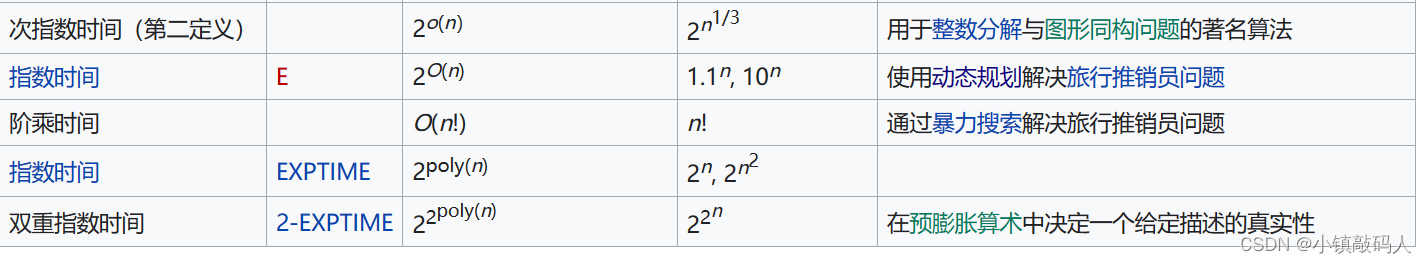
【数据结构与算法篇】之时间复杂度与空间复杂度
【数据结构与算法篇】之时间复杂度与空间复杂度 一、时间复杂度1.1时间复杂度的定义1.2 常见的时间复杂度的计算1.2.1 常数时间复杂度( O ( 1 ) ) O(1)) O(1))1.2.2 线性时间复杂度( O ( N ) O(N) O(N))1.2.3 对数时间复杂度( O (…...

硬件性能 - 网络瓶颈分析
简介 本文章主要通过Linux命令查看网络信息、判断是否出现网络瓶颈等简单分析方法。其他硬件性能分析如下: 1. 硬件性能 - CPU瓶颈分析 2. 硬件性能 - 掌握内存知识 3. 硬件性能 - 磁盘瓶颈分析 目录 1. 监控命令 sar 2. 带宽利用率 3. 网络延迟 4. 网络连接数 …...

stm32驱动MCP2515芯片,项目已通过测试
最近公司做一个项目,需要3路can通道,但是stm32看了很久,最多也就只有2个can,所以找到了一款MCP2515芯片,可以用spi驱动can。 已经实现了can的发送和接收,接收采用的是外部中断接收的方式。和单片机本身带的…...
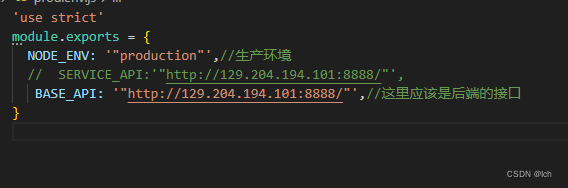
Nginx部署前后端分离项目
dev.env.js解释 //此文件时开发环境配置文件 use strice//使用严格模式 const merge require(webpacl-merge)//合并对象 const prodEnv require(./prod.env)//导出 module.exports merge(prodEnv,{//合并两个配置文件对象并生成一个新的配置文件,如果合并的过程…...

QWEN-AUDIO开箱即用指南:无需conda/pip,纯Docker镜像启动
QWEN-AUDIO开箱即用指南:无需conda/pip,纯Docker镜像启动 想体验一下“有温度”的AI语音合成吗?以前你可能需要折腾Python环境、安装各种依赖、处理版本冲突,光是配置环境就能劝退一大半人。今天,我要分享一个完全不同…...

【限时开源】FastAPI 2.0 AI流式SDK v1.0:内置token计数、流控限速、断点续传、前端SSE自动重连——仅开放首批200个GitHub Star领取资格
第一章:FastAPI 2.0 异步 AI 流式响应的核心演进与架构定位FastAPI 2.0 将原生异步流式响应能力从实验性支持升级为一级公民,彻底重构了 AI 应用服务端的实时交互范式。其核心演进体现在对 StreamingResponse 的深度重写、对 ASGI 3.0 协议的精准适配&am…...

JAVA中try catch无法捕获异常的原因是什么
Java 中的 try-catch 机制是处理异常的重要手段,但有时即使写了 try-catch 代码,异常仍会被抛出。这是因为 catch 块指定的异常类型可能无法与实际抛出的异常相匹配。让我们举一个代码意图捕获异常并打印特定信息的例子:public class Test {p…...

Venera开源漫画阅读工具:构建个性化漫画内容生态系统指南
Venera开源漫画阅读工具:构建个性化漫画内容生态系统指南 【免费下载链接】venera A comic app 项目地址: https://gitcode.com/gh_mirrors/ve/venera 副标题:如何通过模块化漫画源配置解决多平台阅读碎片化难题 价值定位:重新定义漫…...

5分钟搞懂MTMCT:多目标多摄像头跟踪的实战应用与避坑指南
5分钟搞懂MTMCT:多目标多摄像头跟踪的实战应用与避坑指南 想象一下这样的场景:当你走进一家大型超市,天花板上数十个摄像头正无声地记录着每个顾客的移动轨迹。如何确保系统能准确识别同一个人在不同摄像头间的切换?这就是多目标多…...
)
别再硬算螺栓预紧力了!用COMSOL 6.2快速搞定螺栓连接的有限元仿真(附模型文件)
COMSOL 6.2螺栓连接仿真实战:从理论陷阱到高效建模 螺栓连接在机械结构中无处不在,但传统的手动计算预紧力方法不仅耗时耗力,还容易忽略接触非线性、摩擦效应等关键因素。COMSOL Multiphysics 6.2版本针对这一工程痛点进行了专项优化…...

查询参数拼接
export function objectToQueryString(params) {return Object.entries(params).filter(([key, value]) > value ! undefined && value ! null) // 过滤掉 undefined 和 null.map(([key, value]) > ${encodeURIComponent(key)}${encodeURIComponent(value)}).joi…...

嵌入式开发中回调函数的解耦实践与高级应用
1. 回调函数在嵌入式开发中的解耦实践在嵌入式系统开发中,模块间的耦合度直接影响着代码的可维护性和可扩展性。最近我在重构一个智能家居项目时,就遇到了模块间强耦合导致修改困难的问题。通过引入回调函数机制,成功将原本紧密交织的代码逻辑…...

开源吐槽大会:技术人的快乐与烦恼
开源项目吐槽大会:技术文章大纲技术吐槽的核心议题开源项目的常见痛点:文档不全、代码混乱、维护停滞 社区互动的典型问题:响应慢、沟通低效、贡献者流失 技术债务与设计缺陷:历史包袱、架构不合理、兼容性差吐槽背后的技术分析代…...

猫抓插件:突破网页资源限制的媒体捕获解决方案
猫抓插件:突破网页资源限制的媒体捕获解决方案 【免费下载链接】cat-catch 猫抓 chrome资源嗅探扩展 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字内容爆炸的时代,我们每天浏览的网页中蕴含着丰富的视频、音频和图片资源。…...