Kafka高性能集群部署与优化
Kafka高性能集群部署与优化
- 一、简介
- 1. 基本概念
- 2. Kafka生态系统
- 二、Kafka集群部署
- 1. Kafka节点规划
- 2. 集群环境准备
- 3. 集群容错设计原则
- 三、Kafka高性能优化
- 1. 硬件优化
- CPU优化
- 内存优化
- 磁盘IO优化
- 2. Kafka参数配置优化
- Broker配置
- Producer配置
- Consumer配置
- 3. 数据压缩和批量发送
- 压缩选择
- 批处理方式
- 四、Kafka监控和运维
- 1. 监控指标和工具
- a. 消息队列监控
- b. 系统监控
- c. 服务监控
- 2. 告警机制设计
- a. 告警类型
- b. 告警门限和策略
- 五、Kafka容量评估与扩容
- 1. 容量预估方法
- 2. 扩容原则和方法
- 六、安全和权限设置
- 1. 安全风险分析和规避
- 2. 权限设计与管理
一、简介
1. 基本概念
Kafka是由Apache Software Foundation开发的一个分布式流处理平台,源代码以Scala编写。Kafka最初是由LinkedIn公司开发的,于2011年成为Apache的顶级项目之一。它是一种高吞吐量、可扩展的发布订阅消息系统,具有以下特点:
- 高吞吐量:Kafka每秒可以处理数百万条消息。
- 持久化:数据存储在硬盘上,支持数据可靠性和持久性。
- 分布式:Kafka集群可以在多台服务器上运行,提供高可用性和容错性。
- 多语言支持:Kafka提供多种编程语言的客户端API,包括Java、Python、Go等。
Kafka的架构包含以下几个主要组件:
- Producer(生产者):向Kafka服务器发送消息的客户端。
- Consumer(消费者):从Kafka服务器读取消息的客户端。
- Broker(代理):Kafka服务器节点,在集群中负责消息的存储和转发。
- Topic(主题):消息的类别,相当于一个消息队列。
- Partition(分区):每个topic可以分成多个分区,每个分区存储一部分消息。
- Offset(偏移量):每个分区中的消息都按照顺序有一个唯一的序号,称为offset。
2. Kafka生态系统
Kafka作为一个流处理平台与其他开源项目有着良好的整合。Kafka生态系统包含以下主要组件:
- ZooKeeper:是一个分布式协调服务,作为Kafka集群的元数据存储之用。
- Connect:是一个可扩展的框架,用于编写和运行Kafka Connectors,实现与其他系统的数据交换。
- Streams:是一个用于构建高吞吐量、低延迟的流处理应用程序的库。
- Schema Registry:是一个服务,用于存储和管理Kafka消息的Schema。
二、Kafka集群部署
1. Kafka节点规划
- 节点角色:
- Broker节点:Kafka集群中的消息代理节点,每个Broker节点负责存储一部分Topic的数据,并处理数据的读写请求。
- Zookeeper节点:Kafka集群中的协调节点,主要用于Broker节点的注册和发现、Topic配置的管理以及集群元数据的维护。
- 硬件配置:
- Broker节点:建议采用高效的磁盘存储,例如SSD硬盘,内存至少32GB以上,CPU建议4核以上。
- Zookeeper节点:建议使用高性能的服务器,内存建议8GB以上,CPU建议2核以上。
2. 集群环境准备
- a. Zookeeper集群安装和配置:
- 安装Java运行环境;
- 下载Zookeeper压缩包并解压;
- 根据需求修改Zookeeper的配置文件zoo.cfg;
- 启动Zookeeper集群。
- b. Kafka集群安装和配置:
- 安装Java运行环境;
- 下载Kafka压缩包并解压;
- 根据需求修改Kafka的配置文件server.properties;
- 启动Kafka集群。
3. 集群容错设计原则
- a. 副本分配策略
- Kafka采用分区机制对数据进行管理和存储,每个Topic可以有多个分区,每个分区可以有多个副本。
- 应根据业务需求合理配置副本,一般建议设置至少3个副本以保证高可用性。
- b. 故障转移方案
- 当Kafka集群中的某个Broker节点发生故障时,其负责的分区副本将会被重新分配到其他存活的Broker节点上,并且会自动选择一个备份分区作为新的主分区来处理消息的读写请求。
- c. 数据备份与恢复
- Kafka采用基于日志文件的存储方式,每个Broker节点上都有副本数据的本地备份。
- 在数据备份方面,可以通过配置Kafka的数据保留策略和数据分区调整策略来保证数据的持久性和安全性;在数据恢复方面,可以通过查找备份数据并进行相应的分区副本替换来恢复数据。
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;public class KafkaProducerDemo {public static void main(String[] args) {// 配置Kafka Producer相关属性Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("acks", "all");props.put("retries", 0);props.put("batch.size", 16384);props.put("linger.ms", 1);props.put("buffer.memory", 33554432);props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 创建KafkaProducer实例KafkaProducer<String, String> producer = new KafkaProducer<>(props);// 构造待发送的消息for (int i = 0; i < 100; i++) {String msg = "test" + i;ProducerRecord<String, String> record = new ProducerRecord<>("test-topic", msg);producer.send(record);}// 关闭KafkaProducer实例producer.close();}
}
注释说明:
- bootstrap.servers: Kafka集群中Broker节点的地址列表;
- acks: 指定消息的确认机制,“all”表示最多等待所有节点的确认,在可靠性方面要求最高;
- retries: Producer在消息发送失败时会自动尝试重新发送,此配置项为重试次数;
- batch.size: Producer将要发送的消息累计到一定大小后,才会批量发送;
- linger.ms: Producer在延迟一定时间后再批量发送已经缓存的消息,以减少网络消耗;
- buffer.memory: Producer用于缓存消息的内存大小;
- key.serializer和value.serializer: Kafka集群中消息的key和value所采用的序列化方式。
三、Kafka高性能优化
1. 硬件优化
在硬件方面可以针对CPU、内存和磁盘IO进行优化。
CPU优化
在CPU方面,可以考虑以下措施:
- 提高CPU时钟频率;
- 给Kafka分配独立的CPU资源或独占一定CPU核心。
内存优化
在内存方面可以采取如下策略:
- 增加物理内存,这可以显著提高Kafka的性能;
- 设置合理的JVM内存参数,如堆内存大小、直接内存大小等。
磁盘IO优化
在磁盘IO方面可以实施以下措施:
- 使用更快、更可靠的磁盘设备,如固态硬盘(SSD)。
- 提高磁盘读写性能,例如设置RAID扩展容量、使用更高级别的RAID控制器等。
2. Kafka参数配置优化
在参数配置方面需要分别对Broker、Producer和Consumer进行配置优化。
Broker配置
- 对于低延迟场景可以适当增加
num.network.threads和num.io.threads的值; - 对于高吞吐场景可以适当增大
socket.send.buffer.bytes和socket.receive.buffer.bytes的大小; - 单个分区中消息堆积较多时,可提高
queue.buffering.max.ms、降低batch.size。
Producer配置
- 如果需要强制要求消息有序,则需要设置
max.in.flight.requests.per.connection为1; - 对于高吞吐场景下的Producer,可以适当增大
buffer.memory值; - 设置合理的
batch.size、linger.ms参数,可以显著提高Producer性能。
Consumer配置
- 提高
fetch.min.bytes参数,可以减少网络交互次数,提高性能; - 如果需要批量处理消息,使用
max.poll.records和fetch.max.bytes控制批量获取消息数量和大小。
3. 数据压缩和批量发送
通过压缩和批量发送可以优化Kafka的性能表现
压缩选择
Kafka支持多种数据压缩算法,包括Gzip、Snappy和LZ4。在不同场景下,需要选择合适的压缩算法,以确保性能最优。
批处理方式
Kafka支持两种批处理方式:异步批处理和同步批处理。在不同场景下,需要选择合适的批处理方式,进行性能优化。同时需要合理设置批处理参数,如batch.size、linger.ms等。
以下是基于Java语言的Kafka生产者(Producer)配置示例
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");//设置Broker地址
props.put("acks", "all");// 设置消息确认机制"all"/"0"/"1/-1"
props.put("retries", 0);// 消息发送失败重试次数
props.put("batch.size", 16384);// 批处理消息大小
props.put("linger.ms", 1000);// 批处理等待时间
props.put("buffer.memory", 33554432);// Producer缓冲区大小
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");// key序列化方式
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// value序列化方式
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 向指定主题发送消息
for(int i = 0; i < 100; i++)producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
四、Kafka监控和运维
1. 监控指标和工具
a. 消息队列监控
Kafka的消息队列监控可以通过以下指标来实现:
- 生产者指标:发送的消息数量、失败数量、请求延迟等。
- 消费者指标:消费的消息数量、失败数量、消费延迟等。
- 集群指标:分区数量、broker数量、ISR大小等。
监控工具可选用Kafka自带的JMX监控和第三方监控工具,如Graphite、Prometheus等。
b. 系统监控
Kafka所在机器的系统监控可以通过以下指标来实现:
- CPU使用率
- 内存使用量和剩余量
- 磁盘读写速率和使用量
- 网络流量等
监控工具可以使用系统自带的监控工具,如top、iostat、iftop等,也可以使用第三方工具以及监控软件,如Zabbix、Prometheus等。
c. 服务监控
Kafka微服务的监控可以用以下指标来实现:
- 各个服务实例的状态
- 响应速度
- 错误数量
- 访问量等
监控工具可以采用类似于系统监控的方式来监控,其中可以集成Kafka自带的JMX监控以及第三方监控软件,如Zabbix、Prometheus等。
2. 告警机制设计
a. 告警类型
Kafka告警可以分为以下几种类型:
- 生产者告警:生产者发送消息失败、响应延迟过高、发送速率过慢等。
- 消费者告警:消费者无法消费消息、消费延迟过高、消费速率过慢等。
- 集群告警:新的broker无法加入集群、ISR缩小、分区数量不足等。
b. 告警门限和策略
门限和策略的设置应该基于特定的应用场景,以下是一些常见的设置:
-
生产者告警门限:
- 发送失败比例超过1%。
- 响应时间超过5秒。
- 发送速率低于100条/秒。
-
消费者告警门限:
- 消费失败比例超过1%。
- 消费延迟超过30秒。
- 消费速率低于10条/秒。
-
集群告警门限:
- 新的broker无法加入集群。
- ISR缩小到小于副本数的80%。
- 分区数量少于总broker数量的50%。
告警的策略可以通过邮件、短信等方式通知运维人员,同时应该在监控面板上展示告警信息。 告警信息应该包含告警类型、时间、告警等级等重要信息,以便运维人员快速响应和解决问题。
//设置生产者告警门限
if (sendFailRatio >= 0.01 || responseTime >= 5000 || sendRate <= 100) {String message = "生产者告警:" + "\n" +"发送失败比例:" + sendFailRatio + "\n" +"响应时间:" + responseTime + "ms" + "\n" +"发送速率:" + sendRate + "条/秒";sendAlertMessage(message);
}//设置消费者告警门限
if (consumeFailRatio >= 0.01 || consumeDelay >= 30000 || consumeRate <= 10) {String message = "消费者告警:" + "\n" +"消费失败比例:" + consumeFailRatio + "\n" +"消费延迟:" + consumeDelay + "ms" + "\n" +"消费速率:" + consumeRate + "条/秒";sendAlertMessage(message);
}//设置集群告警门限
if (!newBrokerJoined || isrSize < replicaNum * 0.8 || partitionNum < brokerNum * 0.5) {String message = "集群告警:" + "\n" +"新的broker无法加入集群:" + !newBrokerJoined + "\n" +"ISR缩小到小于副本数的80%:" + isrSize + "\n" +"分区数量少于总broker数量的50%:" + partitionNum;sendAlertMessage(message);
}//发送告警信息的方法
public void sendAlertMessage(String message) {//使用短信、邮件等方式发送告警信息给运维人员
}
五、Kafka容量评估与扩容
1. 容量预估方法
a. 负载分析法
使用负载分析方法可以大致预估Kafka集群需要的磁盘容量。首先,我们需要确定数据发送频率和数据大小,然后计算每秒钟消息的总大小。接下来通过估算存储保留期,得出需要的总存储空间。最后考虑备份和冗余需求,确定整个Kafka集群所需的存储容量。
b. 性能测试法
使用性能测试法可以确定Kafka集群的带宽容量和吞吐量。在进行性能测试时,应该模拟实际生产环境中的负载并记录各项指标,如写入速率、消费速率、延迟时间等,并根据这些数据优化Kafka集群的配置。
2. 扩容原则和方法
a.扩容类型分析(纵向,横向)
扩容有两种方式:纵向扩容和横向扩容。纵向扩容是在原有机器上增加更多的CPU及内存来提高Kafka集群的整体性能和吞吐量;横向扩容则是在已有的集群中增加更多的节点,以扩大Kafka集群规模;在进行扩容的时候应该根据当前的负载情况以及未来的发展需要,综合考虑选择何种方式来进行扩容。
b. 数据迁移方案
在进行扩容时,也需要考虑如何进行数据迁移。通常有两种方式:一种是在线数据迁移,即在新节点上开启Kafka服务,然后将数据从旧节点迁移到新节点,这种方式需要确保新老节点之间的版本兼容;另一种方式是离线复制,即在新节点上设置与旧节点相同的消息存储路径,再拷贝旧节点中的数据到新节点中。
六、安全和权限设置
1. 安全风险分析和规避
在使用Kafka集群时,需要注意安全风险。一些基本的措施包括限制网络访问、强化身份验证、加密数据传输等。同时应该定期升级软件版本,避免使用过时的软件存在漏洞。
2. 权限设计与管理
Kafka集群也需要权限管理机制,以确保数据和集群的安全。可以使用ACL(访问控制列表)来控制客户端对特定主题、分区或其他资源的访问权限,还可以实现基于角色的访问控制来简化权限配置。同时可以使用SSL证书等方式提高认证安全级别,以确保只有合法用户可以访问Kafka集群。在使用任何权限设置前都应该充分了解相关安全机制的特性和限制。
/**
* 扩容原则和方法
*/// 横向扩容示例代码
public class KafkaNodeAddition { public static void main(String[] args) { // 创建新的Kafka节点实例 Kafka newKafkaNode = new Kafka(NEW_NODE_ID); // 添加到当前Kafka集群KafkaCluster.addNode(newKafkaNode); // 开始数据迁移Migration migration = new Migration(); migration.migrateData(OLD_NODE, NEW_NODE); // 完成后从旧节点删除数据OLD_NODE.deleteData(); System.out.println("添加节点成功!"); }
}
相关文章:

Kafka高性能集群部署与优化
Kafka高性能集群部署与优化 一、简介1. 基本概念2. Kafka生态系统 二、Kafka集群部署1. Kafka节点规划2. 集群环境准备3. 集群容错设计原则 三、Kafka高性能优化1. 硬件优化CPU优化内存优化磁盘IO优化 2. Kafka参数配置优化Broker配置Producer配置Consumer配置 3. 数据压缩和批…...

Lucene介绍与入门使用
https://github.com/apache/lucene Lucene简介 Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎…...

【最短路+状压】CF1846 G
Problem - G - Codeforces 题意: 思路: Code: #include <bits/stdc.h>//#define int long longusing namespace std;const int mxn1e610; const int mxv1e610; const int mxe2e310; const int mod1e97; const int Inf0x3f3f3f3f;stru…...
vue+elementui实现英雄联盟道具城
目录 一、效果图 1.首页 2.商品列表、分类 二、实现重点讲解 1.首页轮播图 1.1技术实现: 1.2.鼠标聚焦切换图片事件 2.首页tab切换 3.商品列表实现 三、项目结构说明 四、总结 一、效果图 1.首页 项目与官方效果没有太大差异: 游戏导航࿱…...

ruby注释
在Ruby中,可以使用以下两种方式进行注释: 1. 单行注释:使用井号(#)在代码行的开头添加注释。例如: # 这是一个单行注释 puts "Hello, World!" 2. 多行注释:使用begin和end将多行注…...

2023(WAIC)智能驾驶科技峰会丨拓数派大模型下的数据计算系统,助力汽车智能化产业数据增值
2023 智能驾驶科技峰会在上海圆满落幕,本次大会由世界人工智能大会(WAIC)组委会办公室指导,浦东新区人民政府支持,浦东新区科技和经济委员会、中国 (上海)自由贸易试验区管理委员会金桥管理局主…...
牛客周赛 Round 2
小红的环形字符串小红的环形字符串 题目描述 小红拿到了一个环形字符串s。所谓环形字符串,指首尾相接的字符串。 小红想顺时针截取其中一段连续子串正好等于t,一共有多少种截法? 思路分析 环形问题。 将字符串 s 拼接自身,得到新…...
Git 命令提交和分支控制
强大的分支和合并:Git 提供了强大的分支功能,使得开发者可以轻松创建、合并和管理分支。这种灵活性使得团队可以同时进行多个任务和实验性开发,而不会相互干扰 Git 在处理大型代码仓库和版本历史时表现出色。它使用了一种称为“快照”的机制…...
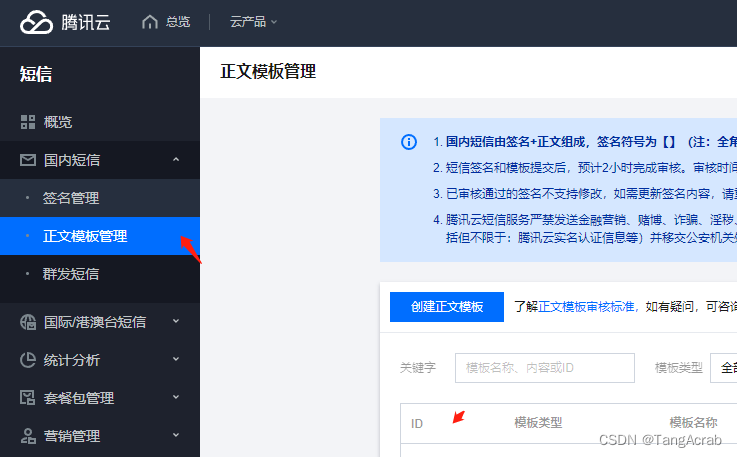
2023 node 接入腾讯云短信服务,实现发送短信功能
1、在 腾讯云开通短信服务,并申请签名和正文模板 腾讯云短信 https://console.cloud.tencent.com/smsv2 a、签名即是短信的开头。例如 【腾讯云短信】xxxxxxx; b、正文模板即短信内容, 变量部分使用{1}, 数字从1开始累推。例如&a…...
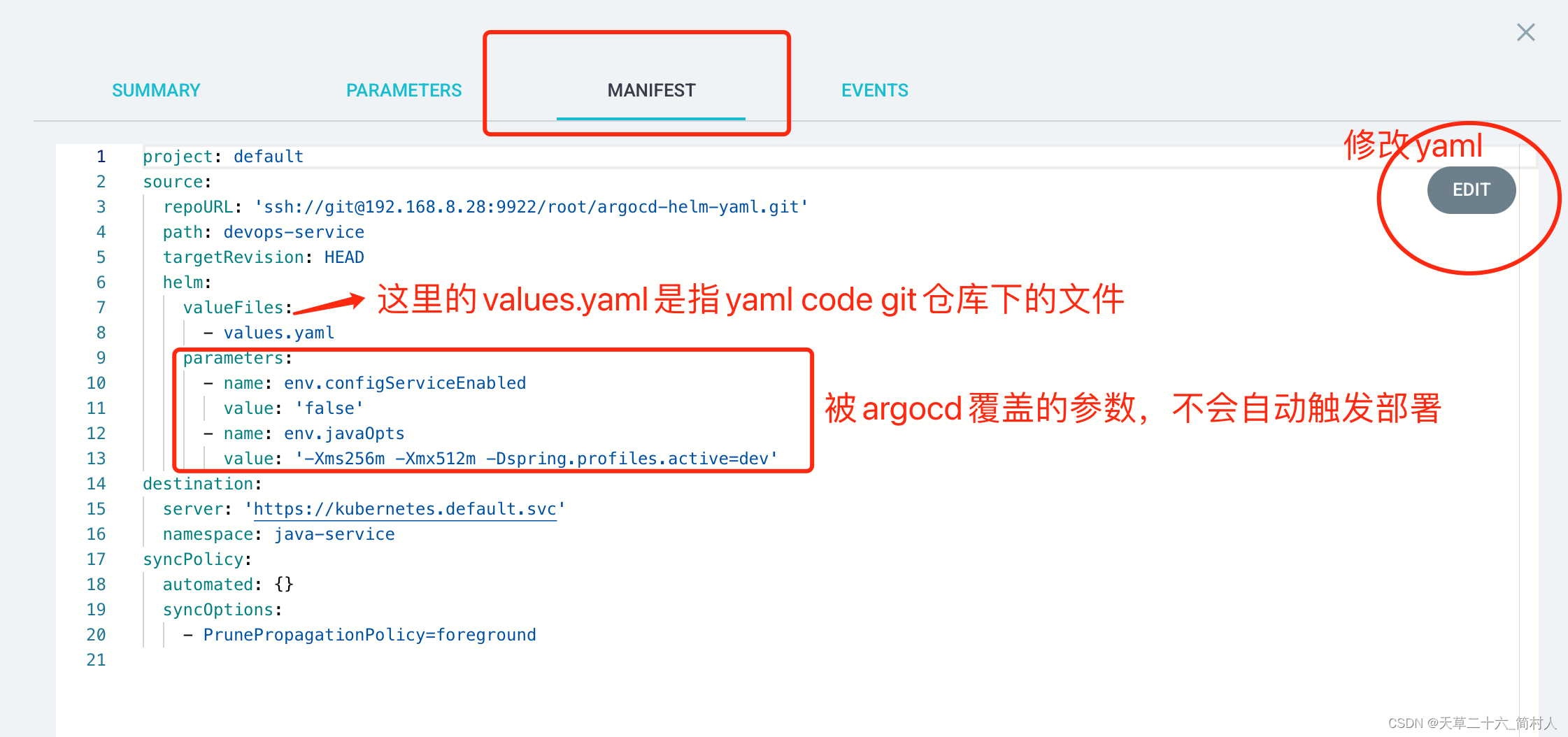
Devops系列四(使用argocd部署java应用到k8s容器)
一、说在前面的话 上文已为我们准备好了以下内容: 制作java应用的docker镜像,并推送至镜像仓库上传helm yaml代码至gitlab仓库(此gitlab和java应用所在的gitlab可以独立,也可以在一起,但是不宜在同一个工程ÿ…...
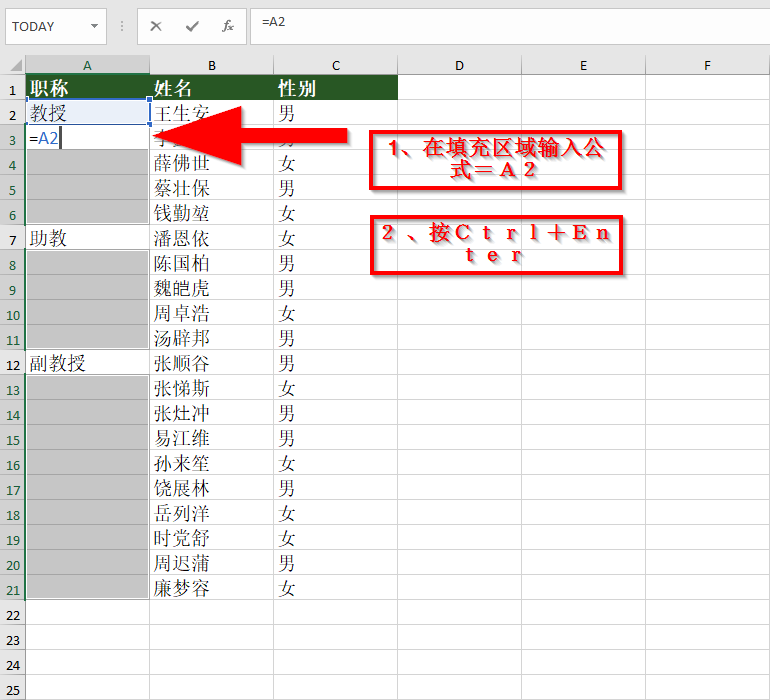
如何在Microsoft Excel中进行不连续区域批量填充
快速填充是 Excel 最令人惊叹的功能之一,它因让一个需要数小时手动执行的乏味任务瞬间自动执行而得名,然而它也有局限性: 结果不是动态的。当你更改其所基于的值时,快速填充值不会更新。你需要再次执行快速填充才能更新值。 快速填充可能并不总是返回结果。该模式对于 Exce…...

k8s+springboot+CronJob 定时任务部署
kubernetesspringbootCronJob 定时任务配置如下代码: cronjob.yaml k8s 文件 apiVersion: batch/v1 kind: CronJob metadata:name: k8s-springboot-demonamespace: rz-dt spec:failedJobsHistoryLimit: 3 #执行失败job任务保留数量successfulJobsHistoryLimit: 5 …...
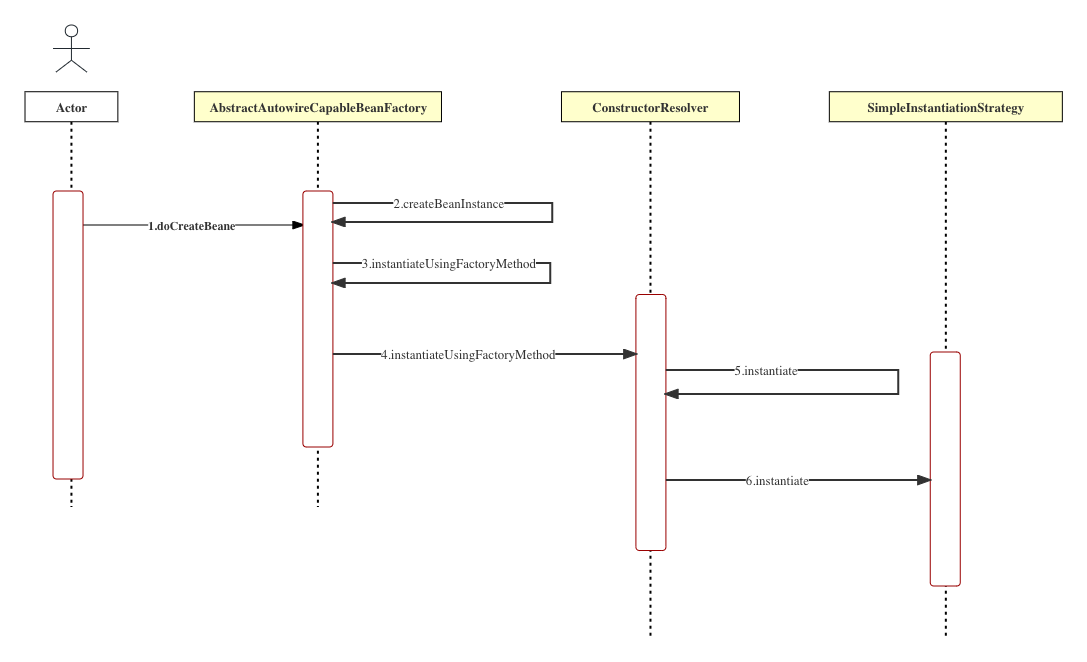
Spring5 中更优雅的第三方 Bean 注入
小伙伴们知道,当我们使用 Spring 容器的时候,如果遇到一些特殊的 Bean,一般来说可以通过如下三种方式进行配置: 静态工厂方法实例工厂方法FactoryBean 不过从 Spring5 开始,在 AbstractBeandefinition 类中多了一个属…...

Yolov5-Face 原理解析及算法解析
YOLOv5-Face 文章目录 YOLOv5-Face1. 为什么人脸检测 一般检测?1.1 YOLOv5Face人脸检测1.2 YOLOv5Face Landmark 2.YOLOv5Face的设计目标和主要贡献2.1 设计目标2.2 主要贡献 3. YOLOv5Face架构3.1 模型架构3.1.1 模型示意图3.1.2 CBS模块3.1.3 Head输出3.1.4 stem…...

通俗易懂讲解CPU、GPU、FPGA的特点
1. CPU vs GPU 大家可以简单的将CPU理解为学识渊博的教授,什么都精通;而GPU则是一堆小学生,只会简单的算数运算。可即使教授再神通广大,也不能一秒钟内计算出500次加减法。因此,对简单重复的计算来说,单单一…...

PIC18 DataRAM 笔记
1.疑似最糟糕的英文技术文档段落 Since up to 16 registers may share the same low-order address, the user must always be careful to ensure that the proper bank is selected before performing a data read or write. For example, writing what should be program dat…...
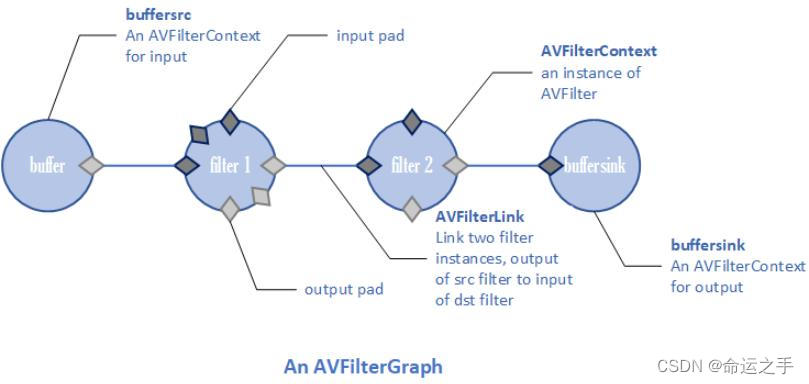
【FFMPEG】AVFilter使用流程
流程图 核心类 AVFilterGraph ⽤于统合这整个滤波过程的结构体 AVFilter 滤波器,滤波器的实现是通过AVFilter以及位于其下的结构体/函数来维护的 AVFilterContext ⼀个滤波器实例,即使是同⼀个滤波器,但是在进⾏实际的滤波时,也…...

爬虫入门06——了解cookie和session
爬虫入门06——了解cookie和session (1)什么是cookie,有什么作用 http请求是无状态的请求协议,不会记住用户的状态和信息,也不清楚你在这之前访问过什么而当网站需要记录用户是否登录时,就需要在用户登录…...

Ubuntu 的移动梦醒了
老实讲,移动版 Ubuntu 在手机、平板上的发展自始至终可能都没有达到过 Canonical 的期望,既然如此,不再勉为其难地坚持下去,或许才是更加明智的做法。 时至今日,官方显然也意识到了这一点,在早些时候发布的…...
RabbitMQ的集群
新建一个虚拟机,重新安装一个RabbitMQ,不会安装的可以看下面的连接: 在Linux中安装RabbitMQ_流殇꧂的博客-CSDN博客 1.修改/etc/hosts映射文件,两台虚拟机都需要修改 vim /etc/hosts 127.0.0.1 node1 localhost.localdomain localhost4 localhost4.localdomain4 ::1 node1 loca…...

如何生成USearch API文档的PDF手册:快速创建可打印版本指南
如何生成USearch API文档的PDF手册:快速创建可打印版本指南 【免费下载链接】usearch Fastest Open-Source Search & Clustering engine for Vectors & 🔜 Strings in C, C, Python, JavaScript, Rust, Java, Objective-C, Swift, C#, GoLang,…...

深入解析MMU:从虚拟地址到物理地址的转换机制
1. 为什么需要虚拟地址? 想象一下你正在玩一个大型多人在线游戏,游戏里每个玩家都有自己的房子、装备和任务进度。如果所有玩家的数据都混在一起存放,你的装备可能会被隔壁玩家不小心拿走,甚至整个游戏世界都会乱套。虚拟地址的出…...

PyCharm 2025.2 离线安装与配置全攻略:绕过登录,直接使用完整汉化版
PyCharm 2025.2 离线安装与配置全攻略:企业级免登录解决方案 在企业开发环境中,Python开发者常常面临网络限制、账号管理繁琐等问题。PyCharm作为最受欢迎的Python IDE之一,其官方版本需要联网激活和登录JetBrains账户,这对内网开…...

Vivo Xplay6专用降级刷机工具AFTool|支持1.15.1/1.16.6/1.16.14等多版本线刷|含教程+驱动+工具包
温馨提示:文末有联系方式【适用机型精准说明】 本工具包专为Vivo Xplay6(型号V317A/V317K)深度适配,非Xplay6机型(含其他Vivo手机)请勿购买——不同机型Bootloader锁机制与分区结构差异极大,强行…...

探索kedro:数据科学项目的高效管理框架
探索kedro:数据科学项目的高效管理框架 【免费下载链接】kedro Kedro is a toolbox for production-ready data science. It uses software engineering best practices to help you create data engineering and data science pipelines that are reproducible, ma…...

3步解放双手:崩坏星穹铁道自动化工具让资源收集效率提升200%
3步解放双手:崩坏星穹铁道自动化工具让资源收集效率提升200% 【免费下载链接】StarRailAssistant 崩坏:星穹铁道自动化 | 崩坏:星穹铁道自动锄大地 | 崩坏:星穹铁道锄大地 | 自动锄大地 | 基于模拟按键 项目地址: https://gitco…...

PCB板验证
铺铜完成是PCB设计中的一个重要里程碑,但还不是终点。在发送给板厂生产之前,还需要完成一系列关键的验证、优化和文件输出工作。简单来说,铺铜之后的标准流程是:设计验证(DRC/DFM) → 必要分析(…...

Python F1数据分析终极指南:5个高级技巧掌握赛车性能可视化
Python F1数据分析终极指南:5个高级技巧掌握赛车性能可视化 【免费下载链接】Fast-F1 FastF1 is a python package for accessing and analyzing Formula 1 results, schedules, timing data and telemetry 项目地址: https://gitcode.com/GitHub_Trending/fa/Fas…...

FFCreator 10个实用技巧:轻松掌握视频制作的核心功能
FFCreator 10个实用技巧:轻松掌握视频制作的核心功能 【免费下载链接】FFCreator 一个基于node.js的高速视频制作库 A fast video processing library based on node.js 项目地址: https://gitcode.com/gh_mirrors/ff/FFCreator FFCreator是一个基于Node.js的…...

VIBE革命性视频人体姿态估计:CVPR2020获奖论文完整实现解析
VIBE革命性视频人体姿态估计:CVPR2020获奖论文完整实现解析 【免费下载链接】VIBE Official implementation of CVPR2020 paper "VIBE: Video Inference for Human Body Pose and Shape Estimation" 项目地址: https://gitcode.com/gh_mirrors/vi/VIBE …...