不允许你不知道的 MySQL 优化实战(二)
文章目录
- 11、使用联合索引时,注意索引列的顺序,一般遵循最左匹配原则。
- 12、对查询进行优化,应考虑在where及order by涉及的列上建立索引,尽量避免全表扫描。
- 13、如果插入数据过多,考虑批量插入。
- 14、在适当的时候,使用覆盖索引。
- 15、慎用distinct关键字
- 16、删除冗余和重复索引
- 17、如果数据量较大,优化你的修改/删除语句。
- 18、where子句中考虑使用默认值代替null。
- 19、不要有超过5个以上的表连接
- 20、exist&in的合理利用

多余的话就不说了,直接上菜!
11、使用联合索引时,注意索引列的顺序,一般遵循最左匹配原则。
表结构:(有一个联合索引idxuseridage,userId在前,age在后)
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userId` int(11) NOT NULL, `age` int(11) DEFAULT NULL, `name` varchar(255) NOT NULL, PRIMARY KEY (`id`), KEY `idx_userid_age` (`userId`,`age`) USING BTREE) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
反例:
select * from user where age = 10;
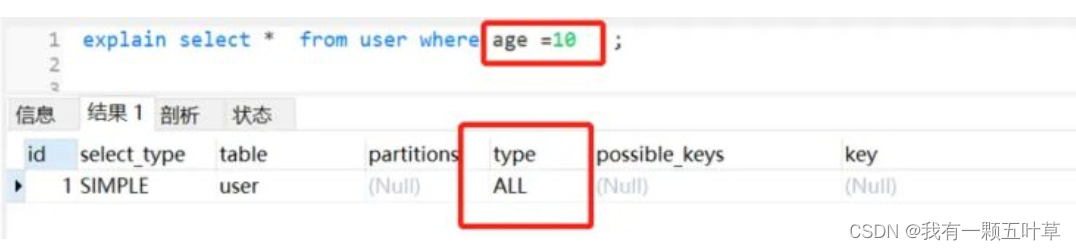
正例:
//符合最左匹配原则select * from user where userid=10 and age =10;//符合最左匹配原则select * from user where userid =10;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rIFQEWMQ-1689213442322)(img/image-20200416004457692.png)]
理由:
- 当我们创建一个联合索引的时候,如(k1,k2,k3),相当于创建了(k1)、(k1,k2)和(k1,k2,k3)三个索引,这就是最左匹配原则。
- 联合索引不满足最左原则,索引一般会失效,但是这个还跟Mysql优化器有关的。
12、对查询进行优化,应考虑在where及order by涉及的列上建立索引,尽量避免全表扫描。
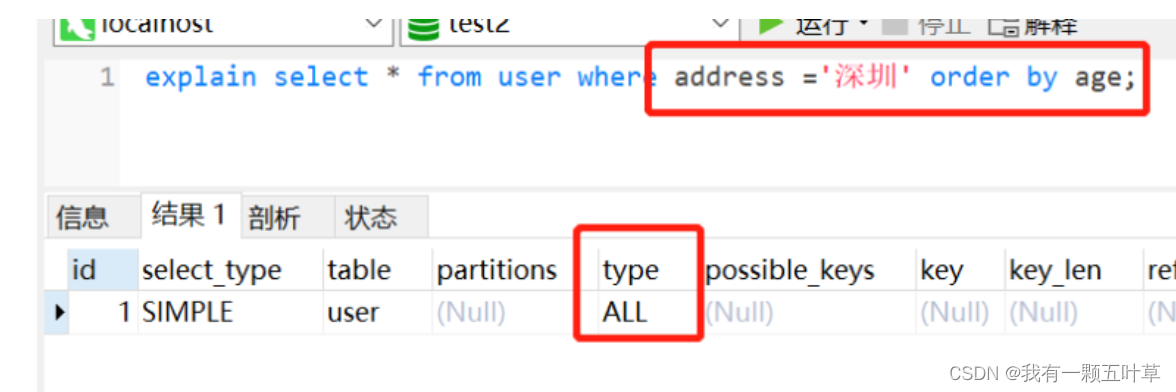
反例:
select * from user where address ='深圳' order by age ;
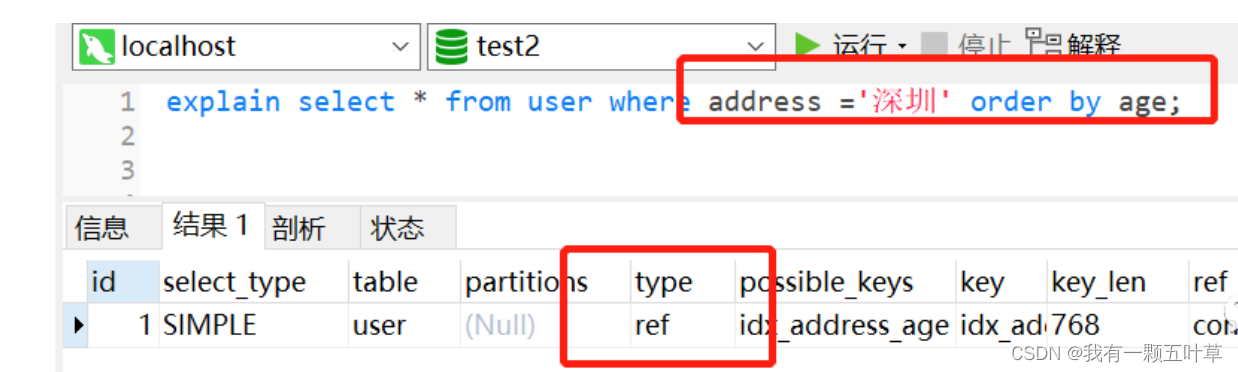
正例:
添加索引alter table user add index idx_address_age (address,age)
13、如果插入数据过多,考虑批量插入。
反例:
for(User u :list){ INSERT into user(name,age) values(#name#,#age#)}
正例:
//一次500批量插入,分批进行
insert into user(name,age) values
<foreach collection="list" item="user" index="index" separator=",">
(#{user.name},#{user.age})
</foreach>insert into user(name,age) values("zs",20),("ls",21)
理由:
- 批量插入性能好,更加省时间
打个比喻:假如你需要搬一万块砖到楼顶,你有一个电梯,电梯一次可以放适量的砖(最多放500),你可以选择一次运送一块砖,也可以一次运送500块砖,你觉得哪个时间消耗大?
14、在适当的时候,使用覆盖索引。
覆盖索引能够使得你的SQL语句不需要回表,仅仅访问索引就能够得到所有需要的数据,大大提高了查询效率。
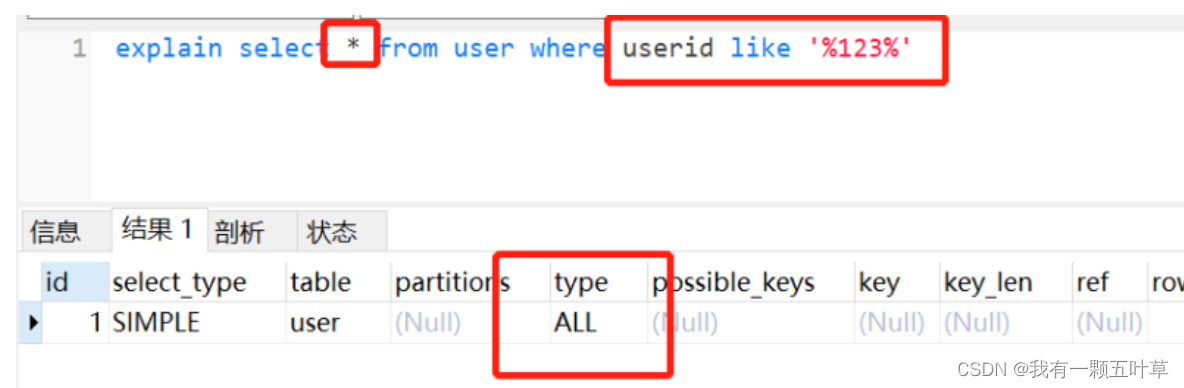
反例:
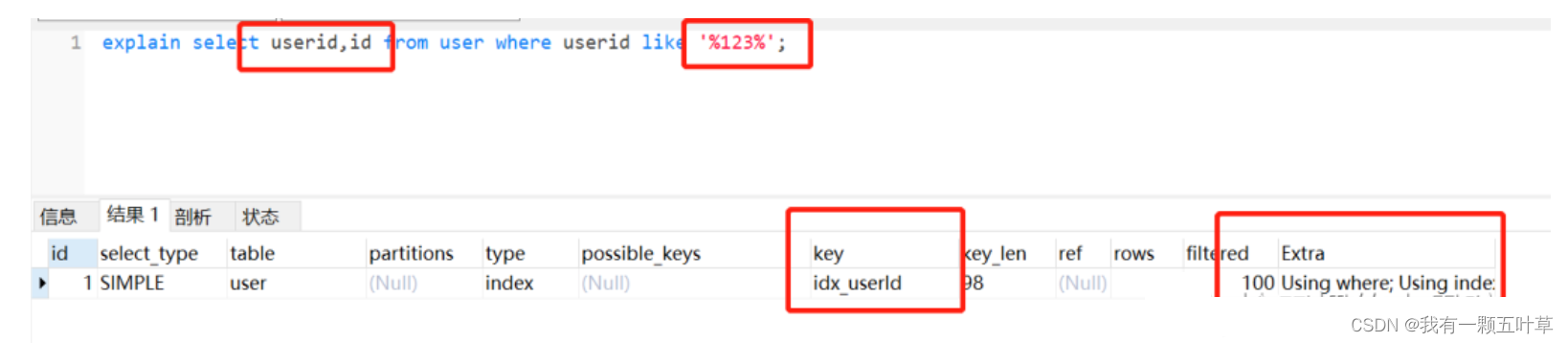
// like模糊查询,不走索引了select * from user where userid like '%123%'
正例:
//id为主键,那么为普通索引,即覆盖索引登场了。select id,name from user where userid like '%123%';
15、慎用distinct关键字
distinct 关键字一般用来过滤重复记录,以返回不重复的记录。在查询一个字段或者很少字段的情况下使用时,给查询带来优化效果。但是在字段很多的时候使用,却会大大降低查询效率。
反例:
SELECT DISTINCT * from user;
正例:
select DISTINCT name from user;
理由:
- 带distinct的语句cpu时间和占用时间都高于不带distinct的语句。因为当查询很多字段时,如果使用distinct,数据库引擎就会对数据进行比较,过滤掉重复数据,然而这个比较、过滤的过程会占用系统资源,cpu时间。
16、删除冗余和重复索引
反例:
KEY `idx_userId` (`userId`) KEY `idx_userId_age` (`userId`,`age`)
正例:
//删除userId索引,因为组合索引(A,B)相当于创建了(A)和(A,B)索引 KEY `idx_userId_age` (`userId`,`age`)
理由:
- 重复的索引需要维护,并且优化器在优化查询的时候也需要逐个地进行考虑,这会影响性能的。
17、如果数据量较大,优化你的修改/删除语句。
避免同时修改或删除过多数据,因为会造成cpu利用率过高,从而影响别人对数据库的访问。
反例:
//一次删除10万或者100万+?delete from user where id <100000;//或者采用单一循环操作,效率低,时间漫长for(User user:list){ delete from user; }
正例:
//分批进行删除,如每次500delete user where id<500delete product where id>=500 and id<1000;
理由:
- 一次性删除太多数据,可能会有lock wait timeout exceed的错误,所以建议分批操作。
18、where子句中考虑使用默认值代替null。
反例:
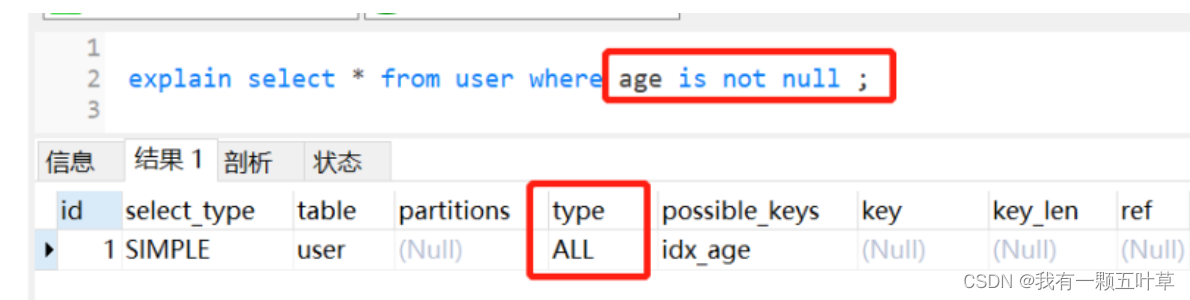
select * from user where age is not null;
正例:
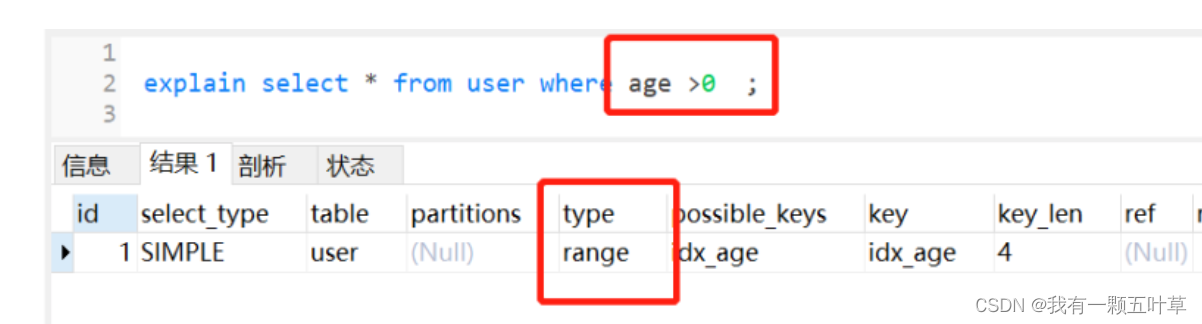
//设置0为默认值select * from user where age>0;
理由:
- 并不是说使用了is null 或者 is not null 就会不走索引了,这个跟mysql版本以及查询成本都有关。
如果mysql优化器发现,走索引比不走索引成本还要高,肯定会放弃索引,这些条件
!=,>isnull,isnotnull经常被认为让索引失效,其实是因为一般情况下,查询的成本高,优化器自动放弃索引的。
- 如果把null值,换成默认值,很多时候让走索引成为可能,同时,表达意思会相对清晰一点。
19、不要有超过5个以上的表连接
- 连表越多,编译的时间和开销也就越大。
- 把连接表拆开成较小的几个执行,可读性更高。
- 如果一定需要连接很多表才能得到数据,那么意味着糟糕的设计了。
20、exist&in的合理利用
假设表A表示某企业的员工表,表B表示部门表,查询所有部门的所有员工,很容易有以下SQL:
select * from A where deptId in (select deptId from B);
这样写等价于:
先查询部门表B
select deptId from B
再由部门deptId,查询A的员工
select * from A where A.deptId = B.deptId
可以抽象成这样的一个循环:
List<> resultSet ;
for(int i=0;i<B.length;i++) { for(int j=0;j<A.length;j++) { if(A[i].id==B[j].id) { resultSet.add(A[i]); break; } }
}
显然,除了使用in,我们也可以用exists实现一样的查询功能,如下:
select * from A where exists (select 1 from B where A.deptId = B.deptId);
因为exists查询的理解就是,先执行主查询,获得数据后,再放到子查询中做条件验证,根据验证结果(true或者false),来决定主查询的数据结果是否得意保留。
那么,这样写就等价于:
select * from A,先从A表做循环
select * from B where A.deptId = B.deptId,再从B表做循环.
同理,可以抽象成这样一个循环:
List<> resultSet ;
for(int i=0;i<A.length;i++) { for(int j=0;j<B.length;j++) { if(A[i].deptId==B[j].deptId) { resultSet.add(A[i]); break; } }
}
数据库最费劲的就是跟程序链接释放。假设链接了两次,每次做上百万次的数据集查询,查完就走,这样就只做了两次;相反建立了上百万次链接,申请链接释放反复重复,这样系统就受不了了。即mysql优化原则,就是小表驱动大表,小的数据集驱动大的数据集,从而让性能更优。
因此,我们要选择最外层循环小的,也就是,如果B的数据量小于A,适合使用in,如果B的数据量大于A,即适合选择exist。

相关文章:
不允许你不知道的 MySQL 优化实战(二)
文章目录 11、使用联合索引时,注意索引列的顺序,一般遵循最左匹配原则。12、对查询进行优化,应考虑在where及order by涉及的列上建立索引,尽量避免全表扫描。13、如果插入数据过多,考虑批量插入。14、在适当的时候&…...
JVM_00000
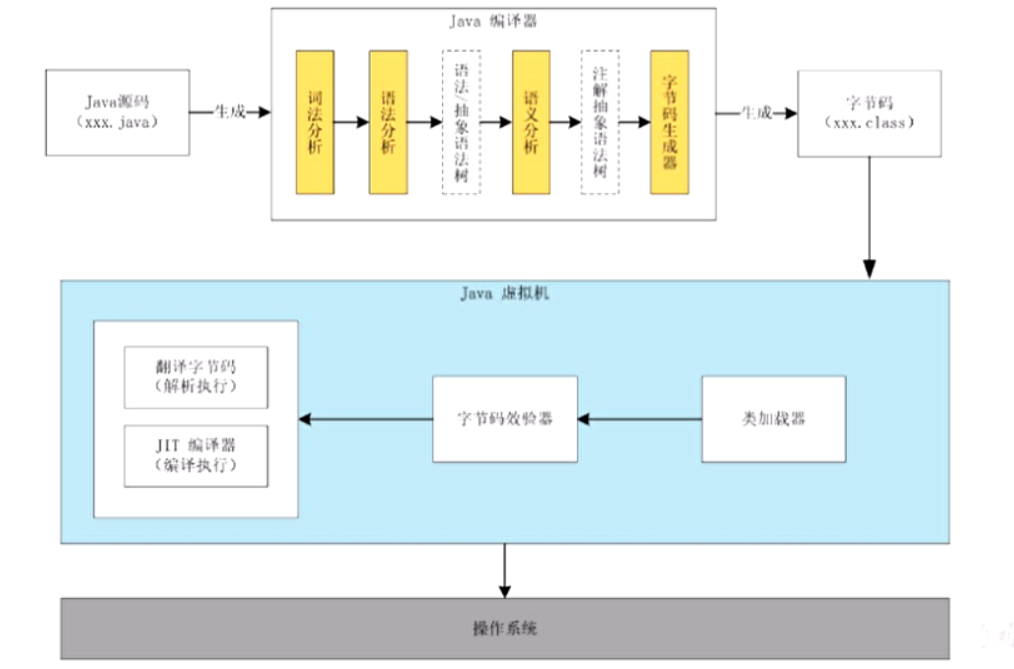
JVM 所谓虚拟机(Virtual Machine)就是一台虚拟的计算机。它是一款软件,用来执行一系列虚拟计算机指令。大体上,虚拟机可以分为系统虚拟机和程序虚拟机。 Visual Box,VMware就属于系统虚拟机,它们完全是对物…...

MCU嵌入式开发-硬件和开发语言选择
引入 RTOS的考虑因素 主要考虑以下方面来决定是否需要RTOS支持: 需要实现高响应时的多任务处理能力需要实现实时性能要求高的任务需要完成多个复杂的并发任务 NanoFramework 具备满足工控系统实时性要求的各项功能特性。通过它提供的硬件库、线程支持、中断支持等,可以完全控制…...

SVR算法简介及与其它回归算法的关系
目录 参考链接 有人可以帮助我理解支持向量回归技术和其他简单回归模型之间的主要区别是什么 支持向量回归找到一个线性函数,表示误差范围 (epsilon) 内的数据。也就是说,大多数点都可以在该边距内找到,如下图所示 这意味着 SVR 比大多数其…...
 内存管理)
Rust系列(二) 内存管理
上一篇:Rust系列(一) 所有权和生命周期 通过前面的文章,目前我已经了解到了单一所有权、Move语义、Copy语义、可变和不可变借用以及引用计数。突然回首可以发现,Move 语义和 Copy 语义保证了值的单一所有权;而可变和不可变借用又可…...

VYaml | 超快速低内存占用yaml库
一、介绍 官方github仓库 YAML:YAML Ain’t Markup Language(YAML 不是标记语言)。 使用Unity2021.3 or later。 通过Unity Package Manager安装: https://github.com/hadashiA/VYaml.git?pathVYaml.Unity/Assets/VYaml#0.13.1 …...

动态规划01背包之1049 最后一块石头的重量 II(第9道)
题目: 有一堆石头,用整数数组 stones 表示。其中 stones[i] 表示第 i 块石头的重量。 每一回合,从中选出任意两块石头,然后将它们一起粉碎。假设石头的重量分别为 x 和 y,且 。那么粉碎的可能结果如下: …...

运输层(TCP运输协议相关)
运输层 1. 运输层概述2. 端口号3. 运输层复用和分用4. 应用层常见协议使用的运输层熟知端口号5. TCP协议对比UDP协议6. TCP的流量控制7. TCP的拥塞控制7.1 慢开始算法、拥塞避免算法7.2 快重传算法7.3 快恢复算法 8. TCP超时重传时间的选择8.1 超时重传时间计算 9. TCP可靠传输…...

GDAL操作实践培训
1 主要安排 本帖子专门写给我侄儿,其他读者可以忽略。 步骤一: 跑程序 先下载GDAL,使用的版本号与项目组一致(当前使用的版本号为2.2.4,visual studio 2019);百度找到GDAL库的使用教程&#x…...

3.Redis主从复制、哨兵、集群
文章目录 Redis主从复制概念主从复制实验哨兵模式哨兵模式的作用故障转移机制:搭建Redis哨兵模式 Redis集群模式集群的作用搭建Redis集群扩容cluster集 Redis主从复制 概念 Redis主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务…...

Windows电源模式(命令行)
一、简介 windows使用powercfg.exe来控制电源方案,像cmd.exe一样,powercfg.exe也是windows自带的。 powercfg命令行选项 选项说明/?、-help显示有关命令行参数的信息。/list、/L列出所有电源方案。/query、/Q显示电源方案的内容。...

6月份读书学习好文记录
看看CHATGPT在最近几个月的发展趋势 https://blog.csdn.net/csdnnews/article/details/130878125?spm1000.2115.3001.5927 这是属于 AI 开发者的好时代,有什么理由不多去做一些尝试呢。 北大教授陈钟谈 AI 未来:逼近 AGI、融进元宇宙,开源…...

【C语言】字符串函数
文章目录 一、求字符串长度strlen例子模拟实现 二、长度不受限制的字符串函数strcpy例子模拟实现 strcat例子模拟实现 strcmp例子模拟实现 三、长度受限制的字符串函数strncpy例子 strncat例子 strncmp例子 四、字符串查找strstr例子模拟实现 strtok例子 五、错误信息报告strer…...
【数据挖掘】时间序列教程【九】
第5章 状态空间模型和卡尔曼滤波 状态空间模型通常试图描述具有两个特征的现象 有一个底层系统具有时变的动态关系,因此系统在时间上的“状态”t 与系统在时间的状态t−1有关 .如果我们知道系统在时间上的状态t−1 ,那么我们就有了我们需要知道的一切&am…...

数据结构---特殊矩阵和广义表
🌞欢迎来到机器学习的世界 🌈博客主页:卿云阁 💌欢迎关注🎉点赞👍收藏⭐️留言📝 🌟本文由卿云阁原创! 🙏作者水平很有限,如果发现错误ÿ…...

mysql数据库的定时备份脚本(docker环境和非docker环境)
一、非docker安装的MySQL MySQL作为一种常用的数据库管理系统,拥有着众多的优秀特性,如高性能、高可靠性、高可扩展性等。然而,在数据备份上,也需要我们进行一定的处理,这样才能保证数据的安全性。因此,在这里我们将介绍如何定时备份MySQL数据库。 我们可以通过MySQL自…...

【微信小程序】使用 wx.request 方法进行异步网络请求
在微信小程序中,你可以使用 wx.request 方法进行异步网络请求,并将获取到的列表数据渲染到 UI 上。 首先,在页面的 data 中定义一个数组变量,用于存储获取到的列表数据,例如: Page({data: {listData: [] …...
: You have an error in your SQL syntax;)
MySQL 8 修改root密码ERROR 1064 (42000): You have an error in your SQL syntax;
root先利用原密码登陆 mysql -u root -p Enter password: ******* Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 9 Server version: 8.0.26 MySQL Community Server - GPLCopyright (c) 2000, 2021, Oracle and/or its affiliate…...
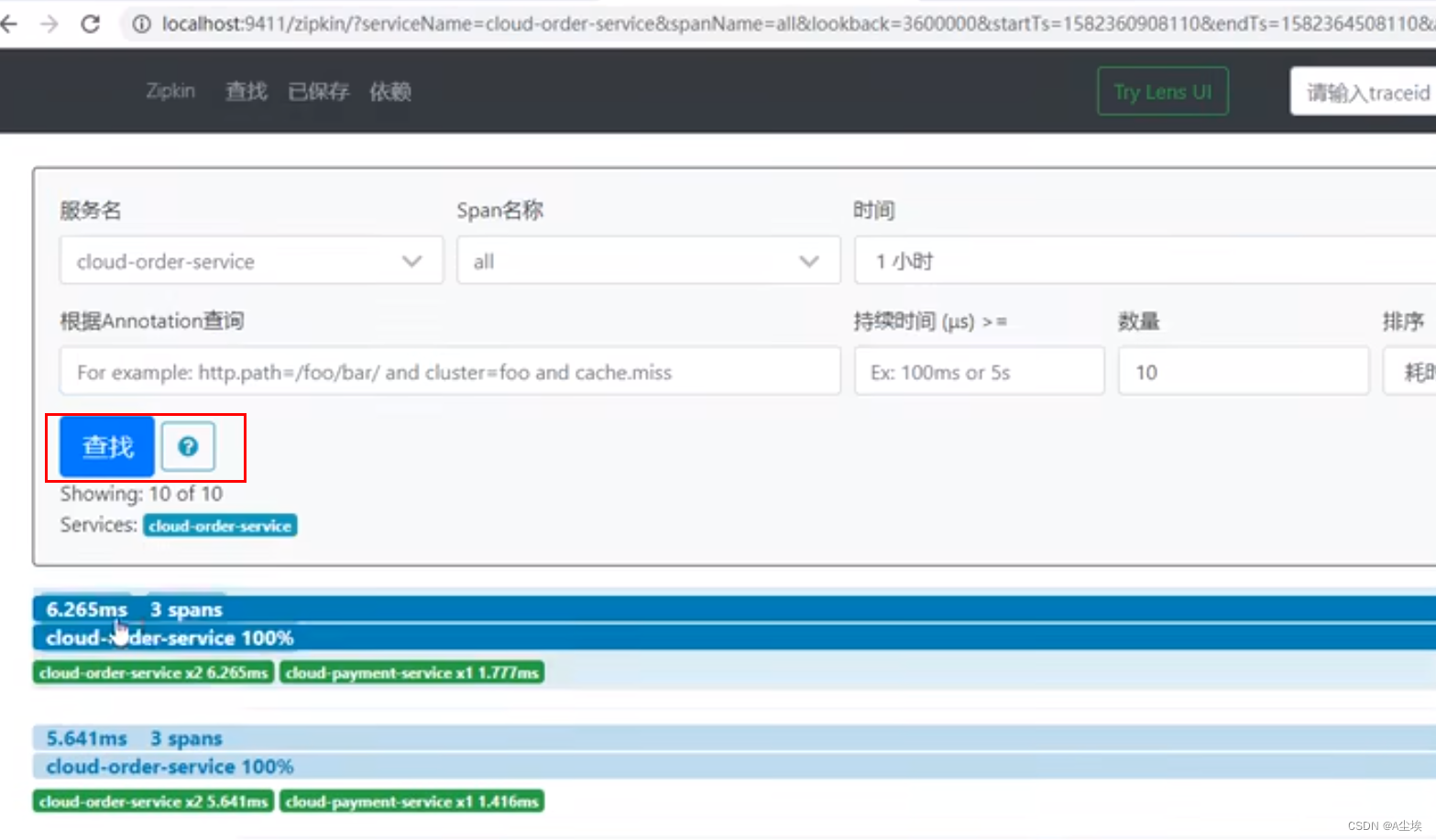
SpringCloud——分布式请求链路跟踪Sleuth
安装运行zipkin SpringCloud从F版已不需要自己构建Zipkin Server,只需要调用jar包即可 https://dl.bintray.com/oenzipkin/maven/io/zipkin/java/zipkin-server/ 下载:zipkin-server-2.12.9-exec.jar 运行:java -jar zipkin-server-2.12.9-e…...
【2 beego学习 - 项目导入与项目知识点】
0 项目导入 1 在英文路径下新建一个同名的项目,拷贝其他数据到这个文件 bee new 同名项目名 cd 同名项目名 go mod tidy go get -u -v github.com/astaxie/beego go get 同名项目名/models2 拷贝部分的项目文件到新目录 bee run 运行的其他错误,按照提示安装文件 1 后端获取…...

Fluent | 动网格技术解析与应用场景
1. 动网格技术到底是什么? 第一次接触动网格这个概念时,我也是一头雾水。简单来说,动网格就是让计算流体力学(CFD)模拟中的网格能够"动起来"的技术。想象一下你在用Fluent模拟一个活塞在气缸里的运动&#x…...

C++和C语言中填充字符、宽度的语法差异
本人因为昨天参加学校天梯赛,后惊讶发现天梯赛题目输出要求答案有格式需求,无奈落榜,仅以此文来告诫自身 (绷不住了)。C语言一、C 语言(printf)基本格式:%[flags][width][.precision…...

GLM-4v-9b开源镜像实操手册:transformers/vLLM/llama.cpp三端调用
GLM-4v-9b开源镜像实操手册:transformers/vLLM/llama.cpp三端调用 1. 开篇:认识这个强大的多模态模型 今天给大家介绍一个特别实用的AI模型——GLM-4v-9b,这是一个能同时看懂图片和文字的多模态模型。想象一下,你给它一张图片&a…...

VR视频转换:让3D内容在普通设备焕发新生的开源方案
VR视频转换:让3D内容在普通设备焕发新生的开源方案 【免费下载链接】VR-reversal VR-Reversal - Player for conversion of 3D video to 2D with optional saving of head tracking data and rendering out of 2D copies. 项目地址: https://gitcode.com/gh_mirro…...

Speech Seaco Paraformer问题解决:识别不准?试试热词功能提升准确率
Speech Seaco Paraformer问题解决:识别不准?试试热词功能提升准确率 1. 语音识别不准的常见困扰 语音识别技术在日常工作和生活中应用越来越广泛,但很多用户在使用过程中都会遇到一个共同问题:识别结果不准确。特别是当录音内容…...

如何在广告泛滥的时代找到纯粹的音乐净土?铜钟音乐的极简听歌方案
如何在广告泛滥的时代找到纯粹的音乐净土?铜钟音乐的极简听歌方案 【免费下载链接】tonzhon-music 铜钟 (Tonzhon.com): 免费听歌; 没有直播, 社交, 广告, 干扰; 简洁纯粹, 资源丰富, 体验独特!(密码重置功能已回归) 项目地址: https://gitcode.com/Gi…...

攻防世界 reverse题GFSJ0810-【crazy】
1.工具:exeinfope、IDA Pro (64-bit)、thonny2.解题:下载附件后,我们先在exeinfope里查壳,如下我们发现是64位无壳文件,然后我们把它放到IDA Pro (64-bit)里分析,我们点击F5先查看伪代码,如下代…...

MOOTDX实战指南:零门槛获取股票数据的Python解决方案
MOOTDX实战指南:零门槛获取股票数据的Python解决方案 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 副标题:量化投资 | 金融数据接口 | Python工具库 一、价值定位&#…...

AI驱动的像素级区域划分:Krita智能选区工具提升数字创作效率全指南
AI驱动的像素级区域划分:Krita智能选区工具提升数字创作效率全指南 【免费下载链接】krita-vision-tools Krita plugin which adds selection tools to mask objects with a single click, or by drawing a bounding box. 项目地址: https://gitcode.com/gh_mirro…...

GIS空间分析:从“裁剪”到“掩膜”,如何精准提取目标区域数据?
1. 为什么需要精准提取目标区域数据? 想象一下你手里有一张全国地图,但只需要研究某个城市的数据。这时候就需要像"剪刀"和"遮罩"这样的工具来帮我们精准提取目标区域。在GIS领域,这就是**裁剪(Clip)和掩膜(Mask)**两大核…...