分布式搜索--elasticsearch
一、初识 elasticsearch
1. 了解 ES
① elasticsearch 是一款非常强大的开源
搜索引擎,可以帮助我们从海量数据中
快速找到需要的内容
② elasticsearch 结合 kibana、Logstash、
Beats,也就是 elastic stack (ELK),被
广泛应用在日志数据分析、实时监控等
领域
③ elasticsearch 是elastic stack的核心,
负责存储、搜索、分析数据

(2) Lucene 与 elasticsearch 的区别
Lucene 是一个Java语言的搜索引擎类库
Lucene的优势:
① 易扩展
② 高性能 (基于倒排索引)
Lucene的缺点:
① 只限于 Java 语言开发
② 学习曲线陡峭
③ 不支持水平扩展
相比于 lucene,elasticsearch 具备下列
优势:
① 支持分布式,可水平扩展
② 提供 Restful 接口,可被任何语言
调用
2. 倒排索引
传统数据库 (如MySQL) 采用正向索引,
局部搜索会在表上逐条数据进行扫描,
非常的繁琐
elasticsearch 采用倒排索引:
会形成一个新的表,由两部分构成,进
行两次搜索,先搜词条再搜文档
文档 (document):每条数据就是一个文档
词条 (term):文档按照语义分成的词语
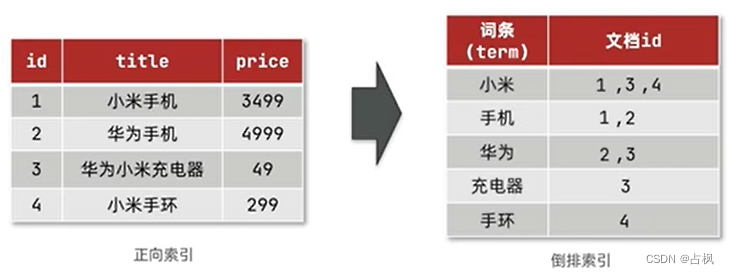

倒排索引中包含两部分内容:
词条词典 (Term Dictionary):记录所有词条,
以及词条与倒排列表 (Posting List) 之间的关
系,会给词条创建索引,提高查询和插入效
率
倒排列表 (Posting List):记录词条所在的文
档 id、词条出现频率 、词条在文档中的位置
等信息
文档 id:用于快速获取文档
词条频率 (TF):文档在词条出现的次数,
用于评分
3. es 的一些概念
(1) es 与 mysql 对比
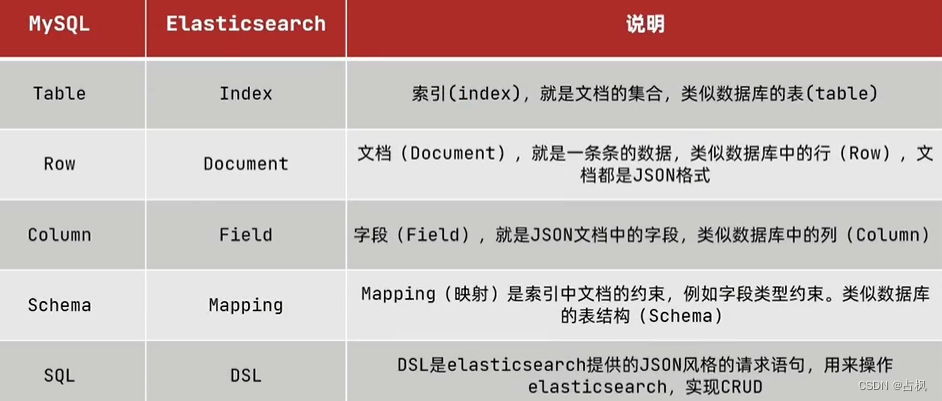
(2) 架构
Mysql:擅长事务类型操作,可以确保
数据的安全和一致性
Elasticsearch:擅长海量数据的搜索、
分析、计算
4. 安装 es、kibana
(1) 部署单点 es
(2) 部署 kibana
kibana 可以提供一个 elasticsearch 的可
视化界面
(3) 安装 IK 分词器
1) 分词器的作用
① 创建倒排索引时对文档分词
② 用户搜索时,对输入的内容分词
2) 默认的分词语法说明:
在 kibana 的 DevTools 中测试:
POST /_analyze
{"analyzer": "standard","text": "床前明月光,疑是地上霜!"
}
① POST:请求方式
② /_analyze:请求路径,这里省略了,
有 kibana 帮我们补充
③ 请求参数,json风格:
analyzer:分词器类型,这里是默
认的 standard 分词器
text:要分词的内容
默认将文字拆除一个字一个字的,对中
文分词很不友好,所以用 IK 分词器
3) ik 分词器包含两种模式:
ik_smart:最少切分,粗粒度
ik_max_word:最细切分,细粒度
一般情况下,为了提高搜索的效果,
需要这两种分词器配合使用,既建
索引时用 ik_max_word 尽可能多的
分词,而搜索时用 ik_smart 尽可能
提高匹配准度,让用户的搜索尽可
能的准确
4) ik 分词器扩展词条
要拓展ik分词器的词库,只需要修改一
个 ik 分词器目录中的 config 目录中的
IkAnalyzer.cfg.xml 文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典--><entry key="ext_dict">ext.dic</entry>
</properties>
然后在名为 ext.dic 的文件中,添加想要
拓展的词语即可
5) 停用词条
在 stopword.dic 文件中,添加想要拓展的
词语即可:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典--><entry key="ext_dict">ext.dic</entry><!--用户可以在这里配置自己的扩展停止词字典 *** 添加停用词词典--><entry key="ext_stopwords">stopword.dic</entry>
</properties>
(4) 部署 es 集群
直接使用 docker-compose 来完成
二、索引库操作
1. mapping 映射属性
(1) mapping 是对索引库中文档的约束,常
见的 mapping 属性包括:
① type:字段数据类型,常见的简单类型有:
字符串:text (可分词的文本)、keyword
(精确值,例如:品牌、国家、ip 地址)
数值:long、integer、short、byte、
double、float
布尔:boolean
日期:date
对象:object
② index:是否创建索引,默认为 true
③ analyzer:使用哪种分词器
④ properties:该字段的子字段
2. 索引库的 CRUD
(1) 创建索引库
ES 中通过 Restful 请求操作索引库、
文档,请求内容用 DSL 语句来表示
创建索引库和 mapping 的 DSL 语法如下:
PUT /索引库名称
PUT /索引库名称
{"mappings": {"properties": {"字段名":{"type": "text","analyzer": "ik_smart"},"字段名2":{"type": "keyword","index": "false"},"字段名3":{"properties": {"子字段": {"type": "keyword"}}},// ...略}}
}
(2) 查看索引库
GET /索引库名
(3) 修改索引库
索引库和 mapping 一旦创建无法修改,
但是可以添加新的字段,语法如下:
PUT /索引库名/_mapping
PUT /索引库名/_mapping
{"properties": {"新字段名":{"type": "integer"}}
}
(4) 删除索引库
DELETE /索引库名
三、文档操作
1. 新增文档
POST /索引库名/_doc/文档id
POST /索引库名/_doc/文档id
{"字段1": "值1","字段2": "值2","字段3": {"子属性1": "值3","子属性2": "值4"},// ...
}
2. 查询文档
GET /索引库名/_doc/文档id
3. 删除文档
DELETE /索引库名/_doc/文档id
4. 修改文档
(1) 全量修改
删除旧文档,添加新文档
本质是:根据指定的 id 删除文档,新增
一个相同 id 的文档
PUT /{索引库名}/_doc/文档id
{"字段1": "值1","字段2": "值2",// ... 略
}
(2) 增量修改
修改指定字段值
POST /{索引库名}/_update/文档id
{"doc": {"字段名": "新的值",}
}
5. Dynamic Mapping
我们向 ES 中插入文档时,如果文档中
字段没有对应的 mapping,ES 会帮助
我们字段设置 mapping
| JSON类型 | Elasticsearch类型 |
|---|---|
| 字符串 | ① 日期格式字符串:mapping 为 date 类型 ② 普通字符串:mapping 为 text 类型,并添加 keyword 类型子字段 |
| 布尔值 | boolean |
| 浮点数 | float |
| 整数 | long |
| 对象嵌套 | object,并添加 properties |
| 数组 | 由数组中的第一个非空类型决定 |
| 空值 | 忽略 |
四、RestClient 操作索引库
RESTClient 是一款用于测试各种 Web
服务的插件,它可以向服务器发送各种
HTTP请求(用户也可以自定义请求方式),
并显示服务器响应
本质就是组装 DSL 语句,通过 http请求
发送给 ES
1. 创建索引库
(1) 导入数据库
(2) 分析数据结构
mapping 要考虑的问题:
字段名、数据类型、是否参与搜索、是
否分词,如果分词,分词器是什么
(3) 初始化 JavaRestClient
① 引入依赖
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency><properties><java.version>1.8</java.version><elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
② 初始化
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.150.101:9200")
));
(4) 创建索引库代码
@Testvoid testCreateHotelIndex() throws IOException {// 1.创建Request对象CreateIndexRequest request = new CreateIndexRequest("hotel");// 2.请求参数,MAPPING_TEMPLATE是静态常量字符串,内容是创建索引库的DSL语句 request.source(MAPPING_TEMPLATE, XContentType.JSON);// 3.发起请求, indices 返回的对象中包含索引库操作的所有方法client.indices().create(request, RequestOptions.DEFAULT);
}

2. 删除索引库代码
@Test
void testDeleteHotelIndex() throws IOException {// 1.创建Request对象DeleteIndexRequest request = new DeleteIndexRequest("hotel");// 2.发起请求client.indices().delete(request, RequestOptions.DEFAULT);
}
3. 判断索引库是否存在
@Test
void testExistsHotelIndex() throws IOException {// 1.创建Request对象GetIndexRequest request = new GetIndexRequest("hotel");// 2.发起请求 boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);// 3.输出System.out.println(exists);
}
五、RestClient 操作文档
1. 初始化
public class ElasticsearchDocumentTest { // 客户端private RestHighLevelClient client;@BeforeEachvoid setUp() {client = new RestHighLevelClient(RestClient.builder( HttpHost.create("http://192.168.150.101:9200")));}@AfterEachvoid tearDown() throws IOException {client.close();}
}
2. 新增文档
@Test
void testIndexDocument() throws IOException {// 1.创建request对象IndexRequest request = new IndexRequest("indexName").id("1");// 2.准备JSON文档request.source("{\"name\": \"Jack\", \"age\": 21}", XContentType.JSON);// 3.发送请求client.index(request, RequestOptions.DEFAULT);
}
3. 查询文档
@Test
void testGetDocumentById() throws IOException {// 1.创建request对象GetRequest request = new GetRequest("indexName", "1");// 2.发送请求,得到结果GetResponse response = client.get(request, RequestOptions.DEFAULT);// 3.解析结果String json = response.getSourceAsString();System.out.println(json);
}
4. 修改文档
@Test
void testUpdateDocumentById() throws IOException {// 1.创建request对象UpdateRequest request = new UpdateRequest("indexName", "1");// 2.准备参数,每2个参数为一对 key valuerequest.doc("age", 18,"name", "Rose");// 3.更新文档client.update(request, RequestOptions.DEFAULT);
}
5. 删除文档
@Test
void testDeleteDocumentById() throws IOException {// 1.创建request对象DeleteRequest request = new DeleteRequest("indexName", "1");// 2.删除文档 client.delete(request, RequestOptions.DEFAULT);
}
6. 批量导入文档
@Test
void testBulk() throws IOException {// 1.创建Bulk请求BulkRequest request = new BulkRequest();// 2.添加要批量提交的请求:这里添加了两个新增文档的请求request.add(new IndexRequest("hotel").id("101").source("json source", XContentType.JSON));request.add(new IndexRequest("hotel").id("102").source("json source2", XContentType.JSON));// 3.发起bulk请求client.bulk(request, RequestOptions.DEFAULT);
}
相关文章:
分布式搜索--elasticsearch
一、初识 elasticsearch 1. 了解 ES ① elasticsearch 是一款非常强大的开源 搜索引擎,可以帮助我们从海量数据中 快速找到需要的内容 ② elasticsearch 结合 kibana、Logstash、 Beats,也就是 elastic stack (ELK),被 广泛应用在日志数据分…...

UE5《Electric Dreams》项目PCG技术解析 之 PCGCustomNodes详解(一)
《Electric Dreams》项目中提供了一些自定义节点和子图(文件位置:“/Content/PCG/Assets/PCGCustomNodes”),这些节点和子图在《Electric Dreams》被广泛使用,对于理解《Electric Dreams》非常重要,而且它们可以直接移…...

500万PV的网站需要多少台服务器?
1. 衡量业务量的指标 衡量业务量的指标项有很多,比如,常见Web类应用中的PV、UV、IP。而比较贴近业务的指标项就是大家通常所说的业务用户数。但这个用户数比较笼统,其实和真实访问量有比较大的差距,所以为了更贴近实际业务量及压力…...

拖动排序功能的实现 - 使用HTML、CSS和JavaScript
引言 在现代Web应用程序中,拖动排序是一种常见的用户界面交互方式,它允许用户通过拖动元素来重新排列列表或项目的顺序。本文将介绍如何使用HTML、CSS和JavaScript来实现手动拖动排序功能。 一、HTML结构 首先,我们需要定义一个列表&#…...

【STM32MP135 - ST官方源码移植】第三章:OPTEE源码移植教程
STM32MP135 OPTEE源码移植教程 一、解压optee的源码压缩包二、拷贝新的设备树文件三、修改Makefile.sdk文件(1)增加stm32mp135d-atk设备树编译(2)修改编译器为arm-none-linux-gnueabihf(3)使用buildroot工具…...
云主机安全-私有密钥安全认证
场景描述 云主机凭借其性价比高、生配扩容便利、运维便捷、稳定性高等优势深受用户青睐,越来越多的企业开始租用云主机,将自己的服务器、业务系统等搭建或存储到云主机上。 用户痛点 用户租用或托管的云主机,运维端口(远程桌面&…...

《Web安全基础》02. 信息收集
web 1:CDN 绕过1.1:判断是否有 CDN 服务1.2:常见绕过方法1.3:相关资源 2:网站架构3:WAF4:APP 及其他资产5:资产监控 本系列侧重方法论,各工具只是实现目标的载体。 命令与…...

ffmpeg根据原始视频的帧率进行提取视频帧
直接上代码,自己编写的。。。有问题可以提 安装教程看这个:https://blog.csdn.net/m0_61497715/article/details/129817641 去官网下个最新的ffmpeg,解压到随便的目录,上级目录最好不要用中文; 然后去设置环境变量&am…...
从零搭建秒杀服务
1. 前言 目的:该项目只用于技术交流,不用于过多商业用途。 适用:可用于简历亮点、毕业答辩等。 2. 项目成果 2.1 秒杀主页 包含5个功能点: ①、Product Name:秒杀商品名称 ②、Product Image:秒杀商…...

数据库应用:CentOS 7离线安装PostgreSQL
目录 一、理论 1.PostgreSQL 2.PostgreSQL离线安装 3.PostgreSQL初始化 4.PostgreSQL登录操作 二、实验 1.CentOS 7离线安装PostgreSQL 2.登录PostgreSQL 3.Navicat连接PostgreSQL 三、总结 一、理论 1.PostgreSQL (1)简介 PostgreSQL 是一个…...

【PHP面试题42】Laravel依赖注入实现的原理是怎么样的
文章目录 一、前言二、什么是依赖注入三、Laravel依赖注入的实现原理3.1 Laravel依赖注入的实现原理:3.2 Laravel依赖注入的代码示例 四、总结 一、前言 本文已收录于PHP全栈系列专栏:PHP面试专区。 计划将全覆盖PHP开发领域所有的面试题,对标…...
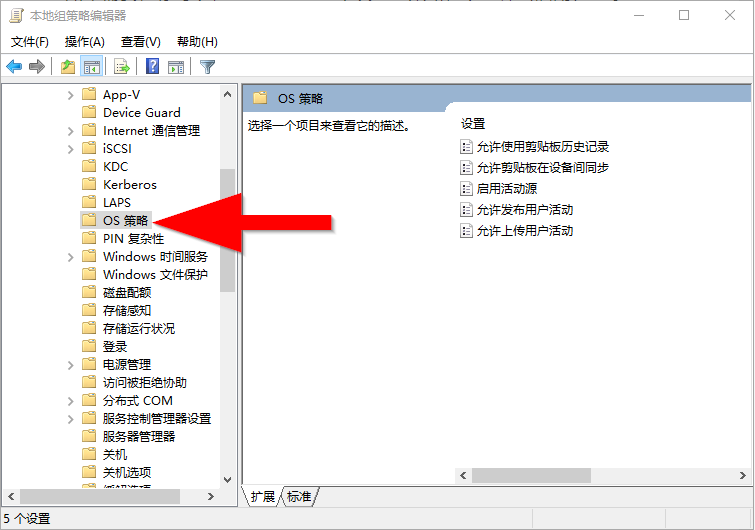
如何在本地组策略编辑器中启用或禁用剪贴板历史记录
复制粘贴是我们大家都会做的事情,可能一天要做多次。但是,如果你需要一次又一次地复制同样的几件事,你该怎么办?如何在设备上复制内容? 从Windows 10版本17666开始,微软正在解决这一问题,并将剪贴板提升到一个新的水平,只需按下Win+V,你将获得全新的剪贴板体验。 你…...

如何与ChatGPT愉快地聊天
原文链接:https://mp.weixin.qq.com/s/ui-O4CnT_W51_zqW4krtcQ 人工智能的发展已经走到了一个新的阶段,在这个阶段,人工智能可以像人一样与我们进行深度的文本交互。其中,OpenAI的ChatGPT是一个具有代表性的模型。然而࿰…...
使用Gradio库进行交互式数据可视化:Timeseries模块介绍
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️ 👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...

CONTAINER = ALL是ALTER USER语句的默认值
连接到root时查看有关root,CDB和PDB的数据 当公用用户执行查询时,可以限制X $表和V $,GV $和CDB_ *视图的视图信息。X$表和这些视图包含有关应用程序root及其关联应用程序PDB的信息,或者如果连接到CDB root,则是整个C…...

华为发布大模型时代AI存储新品
7月14日,华为发布大模型时代AI存储新品,为基础模型训练、行业模型训练,细分场景模型训练推理提供存储最优解,释放AI新动能。 企业在开发及实施大模型应用过程中,面临四大挑战: 首先,数据准备时…...

5G网络功能介绍
5G系统架构由以下网络功能(NF)组成 -身份验证服务器功能(AUSF)。 -接入和移动性管理功能(AMF)。 -数据网络(DN),例如运营商服务、互联网接入或第三方服务。 -非结构化数据存储功能(UDSF)。 -网络曝光功能(NEF)。 -网络存储库功能(NRF)。 -网络切片特定身…...
)
笙默考试管理系统-MyTestMean(13)
笙默考试管理系统-MyTestMean(13) 目录 一、 笙默考试管理系统-MyTestMean 二、 笙默考试管理系统-MyTestMean 三、 笙默考试管理系统-MyTestMean 四、 笙默考试管理系统-MyTestMean 五、 笙默考试管理系统-MyTestMean 笙默考试管理系统-MyTes…...

Tomcat之高可用配置
Nginx搭配Tomcat实现负载均衡 传统模型下,一个项目部署在一台tomcat上,这个时候,假如tomcat因为服务器资源不够,突然挂机了,那么整个项目就无法使用。 Nginx就可以避免单台服务如果挂机,依然能保证服务正…...
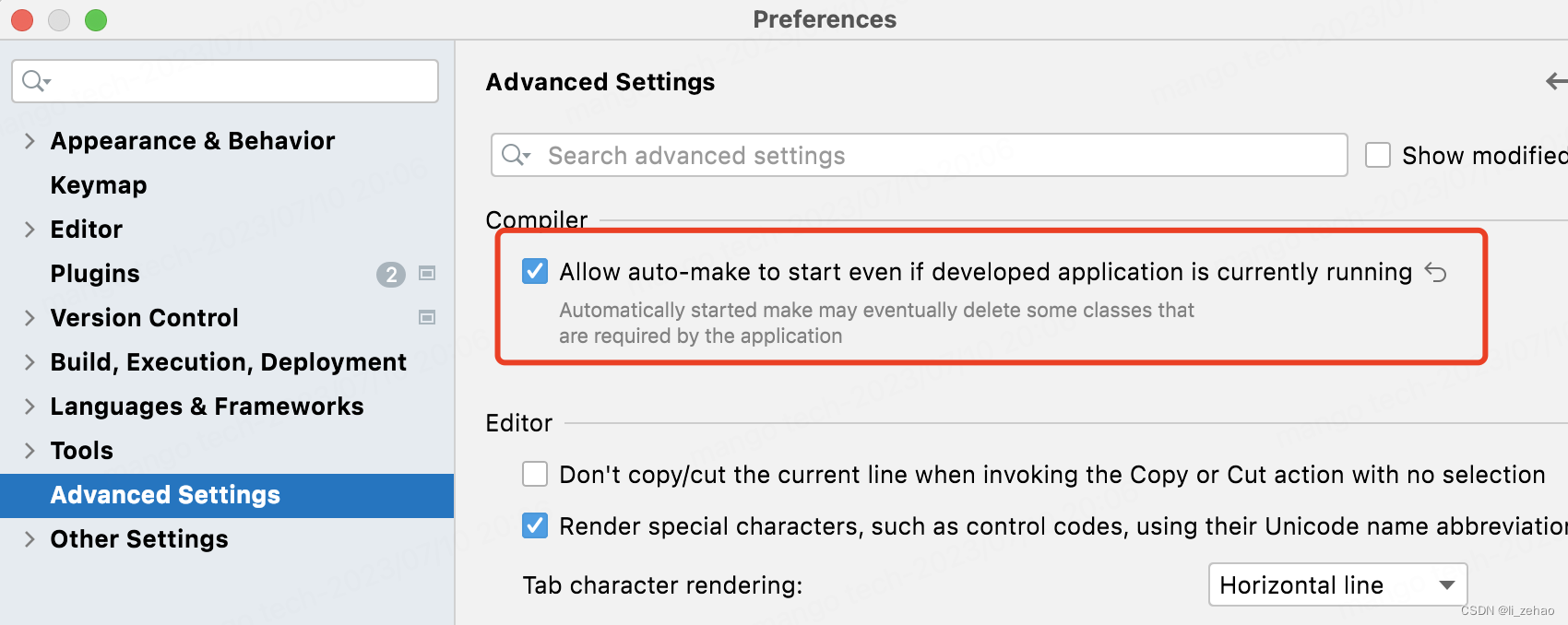
IDEA中springboot的热加载thymeleaf静态html页面
1.首先加入开发工具依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><optional>true</optional> </dependency> 2.其次在build maven插件中开启热部署 <bu…...

MCP服务器开发踩坑实录,深度解析asyncio+FastAPI+MCPv0.5兼容性难题及热修复方案
第一章:MCP服务器开发踩坑实录,深度解析asyncioFastAPIMCPv0.5兼容性难题及热修复方案在基于MCP(Model Context Protocol)v0.5规范构建异步AI服务代理时,我们发现FastAPI 0.115 与标准asyncio事件循环存在隐式冲突&…...

Polars 2.0大规模清洗性能翻倍的7个底层优化技巧:基于真实金融风控流水线压测数据
第一章:Polars 2.0大规模数据清洗性能跃迁的工程意义Polars 2.0 的发布标志着 Rust 原生 DataFrame 库在工程落地层面实现关键突破——其基于 Arrow 2.0 和全新查询优化器(QOv2)重构的执行引擎,将典型 ETL 清洗任务的吞吐量提升达…...

Kubernetes与Istio服务网格最佳实践
Kubernetes与Istio服务网格最佳实践 1. Istio服务网格核心概念 1.1 什么是服务网格 服务网格是一种专门用于处理服务间通信的基础设施层,它负责在现代云原生应用的复杂服务拓扑中可靠地传递请求。 1.2 Istio架构组件 控制平面:包含Pilot、Galley、Citade…...

Linux 内核中的内存管理:从物理内存到虚拟内存
Linux 内核中的内存管理:从物理内存到虚拟内存 引言 作为一名深耕操作系统和嵌入式开发的工程师,我深知资源管理的重要性。在系统开发中,合理的资源管理可以提高系统的性能和可靠性。在 Linux 内核中,内存管理是一个核心组件&…...

Realistic Vision V5.1镜像免配置部署教程:Docker+本地模型路径自动校验
Realistic Vision V5.1镜像免配置部署教程:Docker本地模型路径自动校验 1. 项目概述 Realistic Vision V5.1虚拟摄影棚是基于Stable Diffusion 1.5生态顶级写实模型开发的本地化工具,专为追求摄影级人像效果的用户设计。这个解决方案通过Docker容器化技…...

【DexGraspNet与多指手抓取算法详解】第三章 DexGraspNet数据集构建机理
目录 第三章 DexGraspNet数据集构建机理 第一部分 原理详解 3.1 数据生成流程总览 3.1.1 Asset准备与处理 3.1.1.1 ShapeNetSem物体库筛选 3.1.1.1.1 几何网格清理与流形检测 3.1.1.1.2 物理属性赋值(质量、质心) 3.1.1.2 视觉资产渲染管线 3.1.1.2.1 材质与纹理映射…...

Catia学习教程
写在前面 自学Catia的时候发现大部分教程在隔壁B站,CSDN上教程比较少,记录一下自己的学习过程,要有一定的AutoCAD和Solidworks基础,很多指令是相似的。 一、软件简介 CATIA(Computer Aided Three-dimensional Intera…...

AI开源项目贡献指南:测试工程师从PR提交到核心维护者的专业路径
测试工程师在AI开源生态中的独特价值在AI开源项目的演进中,软件测试从业者具备不可替代的专业优势:质量敏感度:精准识别模型漂移、接口兼容性、数据异常等AI特有风险系统化思维:构建覆盖数据流水线、模型服务、API交互的端到端验证…...

郭老师-帝王霸鬼四道:为何只能正学,不可反学
帝王霸鬼四道 ——为何只能正学,不可反学?“让三岁娃背《孙子兵法》? 不是启蒙, 而是—— 把刀交给婴儿。”🌿 真正的根基,不在谋略, 而在—— 《大学》《中庸》《系辞传》🧭 一、四…...

Legacy iOS Kit终极指南:旧款iOS设备降级、越狱与恢复完整教程
Legacy iOS Kit终极指南:旧款iOS设备降级、越狱与恢复完整教程 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to downgrade/restore, save SHSH blobs, and jailbreak legacy iOS devices 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit …...