利用鸿鹄优化共享储能的SCADA 系统功能,赋能用户数据自助分析
摘要
本文主要介绍了共享储能的 SCADA 系统大数据架构,以及如何利用鸿鹄来更好的优化 SCADA 系统功能,如何为用户进行数据自助分析赋能。
1、共享储能介绍
说到共享储能,可能不少朋友比较陌生,下面我们简单介绍一下共享储能的价值及其未来的技术发展方向。
1.1 共享储能的价值
储能技术有着巨大的价值,储能的四个基本作用:一是削峰填谷,二是虚拟同步,三是准确控制性,四是响应电网的指令和控制负荷。储能的商业模式原来电源侧是自己用的,它是装在电源侧,但2019年6月份移到了电网侧由电网统一调度,叫共享储能,共享储能就由电网调度。
“共享储能”商业模式充分考虑到了各方需求。
从国际来看,2021年特斯拉部署的储能项目共4 GWh,2030年1500GWh 的目标,对比之下翻了375倍。由于市场需求仍持续高于产能,特斯拉储能业务增长依然受到供应链挑战的限制。
2020年,特斯拉美国官网正式上线Megapack 工业级电池储能系统,定价100万美元起,而且只面向企业销售,但依旧卖得火爆。在当年第二季度财报电话会议上,马斯克透露,Megapack 在2022年底的产能已全部售罄。
从国内来看,2021年4月21日,国家发展改革委、国家能源局发布《关于加快推动新型储能发展的指导意见(征求意见稿)》(以下简称《征求意见稿》)。《征求意见稿》提出,目标到2025年,实现新型储能从商业化初期向规模化发展转变,新型储能装机规模达3000万千瓦以上。
到2030年,实现新型储能全面市场化发展。
下图是彭博社关于未来共享储能市场各国装机容量的预测,我们可以看到,无论是中国还是美国,未来的储能市场都是一个至少万亿级的市场,天花板足够高。在这个新能源风起云涌的时代,共享储能已经跻身成为新型电力系统的基本要素。
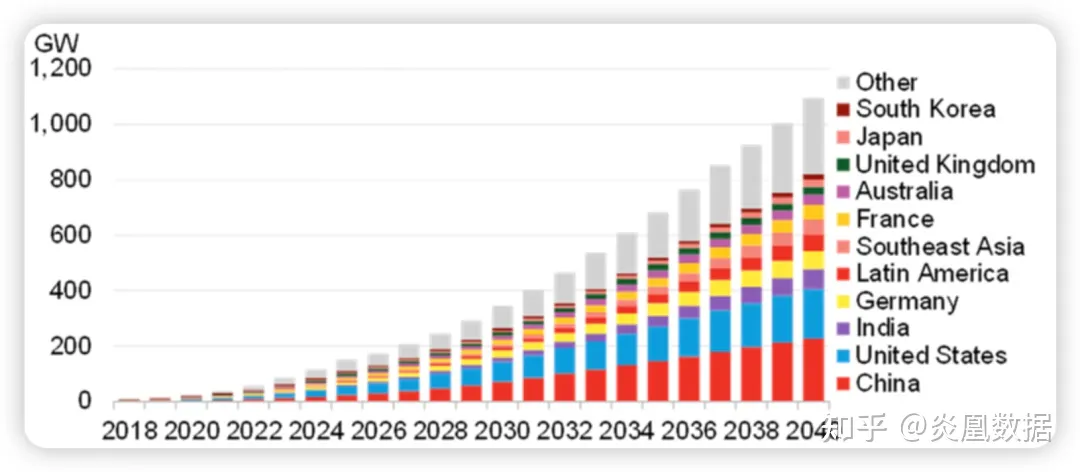
(来源:彭博社)
1.2 电池储能是技术发展的未来
一般来说,目前共享储能包括机械储能、电磁储能和电池(也叫电化学)储能。通过下表我们可以看出,基于锂电池的储能技术优点明显,也是目前和未来共享储能的主流。

其他还有压缩空气储能、高能电容储能、液流电池储能、钠硫电池储能、铅酸电池储能等,由于地理条件限制、比能量太低等各种不同原因,并不是业界的主流技术。我们的共享储能 SCADA 系统也主要基于锂电池共享储能进行建设。
2、传统SCADA系统
所谓 SCADA ( Supervisor Control And Data Acquisition ) 数据采集系统,是一种集测量技术、计算机技术、通讯技术于一体的综合性集成控制系统,可实现共享储能系统的实时中央监控和管理调度。
典型的 SCADA 如下图,分为场站端和管理端。场站端:主要是三部分:下位机、通信网络、上位机。管理端:一般包括前置采集、SCADA应用。

由于早期的 SCADA 系统面对的数据量相对较小,因此大部分采用单机或者 C/S 架构,一般采用关系型数据库,比如:MySQL、SQL Server 等进行存储。随着采集数据的增多,这样的系统不能保存过长时间的数据,都会设置几个月的定期数据清理策略,如果要进行长周期的数据对比分析,则很难满足需求。
以下是一个我们客户之前用的传统 SCADA 系统:

3、基于大数据平台的共享储能 SCADA 系统
随着各种新能源(风能、太阳能)电厂的建设,电厂的数据采集层具有数据采集量大、采集频率高的特点,历史库必将形成复杂、异构的储能大数据,传统的SCADA系统开始面临计算机 CPU 升级、内存不足、计算机硬件扩充、成本增加等一系列的问题。传统的数据处理方式,难以快速处理海量的共享储能大数据。

因此,我们的共享储能客户提出要基于大数据平台进行共享储能 SCADA 系统的建设。
3.1 总体架构
一般来说,共享储能电站主要由变配电设备、储能电池组、能源管理系统( EMS )、电池管理系统( BMS )、能量转换控制系统( PCS )及 SCADA 系统组成。

在建设中,我们考虑到现有共享储能系统复杂、采集点比较多的特点,采用了时序数据库进行主要数据存储。另外,共享储能系统一般要求是在一个封闭的环境下,无法连接互联网,因此我们会通过一台基于 GPS(北斗)的时间服务器进行时间同步。
下图是我们共享储能 SCADA 系统的示意图:

为了能更方便的集成一些第三方标准采集盒子,我们采用了 MQTT 协议作为数据传输的主要协议,这样对于第三方标准的采集盒子仅仅需要进行简单的配置,就能把数据采集上来。
为了更加灵活的进行采集程序编写,我们采用的是 Python 语言进行开发,对于数据展示、分析端,我们进行了前后端分离,后端使用主流的 Java 框架 Spring Boot 进行开发,前端采用 Vue 进行开发。
3.2 数据存储
采集的数据主要存储在 InfluxDB 中,对于一些特殊的报表需求,我们会定时ETL数据到 MySQL 关系型数据库中。
对于 InfluxDB 的存储结构,有一些查询的效率会比较低,因此,会提前进行预计算以满足快速的数据分析需求。当然对于大数据系统,这也是一个非常常用的要求,好在 InfluxDB 提供 Rollup 的功能,能很方便的通过编写 SQL 语句根据采样的精度和数据聚合方式进行预计算。
3.3 实景拍摄
这是第一个应用我们 SCADA 系统的共享储能电站实景拍摄图,该共享储能电站基本上具备了一般共享储能电站的主要功能:削峰填谷、响应电网的指令和控制负荷。

3.4 系统界面
下图是我们一个共享储能电站的主系统图,图中所有的数据都是实时进行采集显示。此外,根据客户的需求,也能直接在系统图上进行一些简单的系统交互控制。

一般在共享储能电站的 SCADA 系统首页,用户希望能看到储能系统响应电网计算机 AGC 指令的实时情况,从而快速分析出当前储能系统的工作功率。下图是我们建设的一个典型的 SCADA 系统首页:

4、利用鸿鹄优化共享储能 SCADA 系统
在了解到国内推出了一款新的大数据产品,我们就希望能尝鲜体验,当然之前我们也考虑过一些其他产品,但是从价格、易用性方面比我们现有架构并没有明显提升。
4.1 我们的痛点
虽然我们之前基于大数据平台建立的产品比原有传统的 SCADA 系统已经有了很大进步,但是仍然还是有一些不太令人满意的地方。
4.1.1 缺乏灵活性
对于共享储能SCADA系统来说,除了和一般SCADA系统一样具有监控的功能外,更重要的是共享储能SCADA系统必须响应电网的指令精准控制储能系统出力(也就是我们前面提到储能的四个基本作用的后面两个)提供数据分析服务和辅助决策。
共享储能系统建成后大约3-6个月的时间都处于电网指令响应算法的调试期,为了针对算法模型进行调参优化,电力工程师和算法工程师就会不断的有很多临时的想法,在看到算法调整后的数据变化,用户会进一步希望有一些新的指标或者统计图表呈现。
由于所有的统计分析功能都需要用Java代码进行实现,一旦用户提出更多的数据分析需求,就要重新对需求进行排期。如果能有一款所见即所得的辅助数据分析工具,显然能更好的满足一些临时性、探索性的分析需求。加快共享储能系统的算法模型调试进度。
4.1.2 ETL依赖
虽然我们核心的采集数据都保存到了 InfluxDB,目前一个储能电站的每日采集数据量大约是8-12GB,目前我们建设第一个共享储能电站SCADA系统运行一年后,大约有3TB的累计数据。有一些报表通过 SQL 直接查询 InfluxDB 效率就会比较低下,因此我们就会把一部分统计报表的数据从 InfluxDB 通过 ETL 脚本抽取到 MySQL 中,以应对相对复杂的分析报告需求。
4.1.3 扩展价格昂贵
随着数据量的增多,未来如果要采用 InfluxDB 集群,这个代价也是相当高的。由于社区版的 InfluxDB 不支持集群模式,所以,我们从相关渠道打听过支持集群模式的 InfluxDB 企业版,据说价格能达到百万,这显然对于一个SCADA 系统来说无法承受。
4.2 选型对比
基于提高灵活性、减少对 ETL 的依赖以及合理的成本等几项要素,我们更多的偏向于 ElasticSearch、Splunk 等能够省去 ETL 过程、建模更加灵活的产品,刚好最近从业界的朋友得知国内一个实力强劲的团队发布了一款比Splunk 更好的产品——鸿鹄社区版,就忍不住想上手试试。尤其是当我们看到鸿鹄的读时建模和向量加速的特性的时候,显然能解决我们之前的痛点。
4.2.1 读时建模
按照官方文档的解释,“读时模式”是一种在搜索数据的同时,从原始数据提取有用字段( field )的技术。由于可以省去ETL部分,该技术可以极大的减少数据导入时候的开销。这一点非常适合我们 SCADA 系统用户的一些临时性、探索性的需求。
尤其是当数据采集进入平台的时候,直接存储原始数据,通过定义一些列字段提取规则,在查询时,动态的根据引用到的规则,从原始数据中提取字段值。

(此图来源于鸿鹄官方文档)
4.2.2 向量加速
通过在使用中,我们还发现了鸿鹄系统的一个非常重要的特性,就是使用了向量加速计算,向量计算能充分利用CPU的SIMD(Single Instruction Multiple Data)指令,SIMD是一类特殊的CPU指令类型,这种指令可以在一条指令中同时操作多个数据,大大提升了数据处理的性能,这也是鸿鹄在安装的时候为什么要求CPU必须支持AVX2 指令集的原因。
4.3 新的架构
我们新的架构将鸿鹄替代关系型数据库,如果在装机容量不大的储能电站甚至可以做为主数据存储使用。
如下图所示,通过和鸿鹄的整合,提升了现有SCADA 系统的灵活性,相当于直接给原有的系统进行了自助分析赋能。

在新的架构中,我们会让鸿鹄和InfluxDB共同工作。使用鸿鹄,一方面替代了MySQL的作用以及一部分InfluxDB的预计算处理;另外一方面我们可以让用户直接登录鸿鹄的管理界面进行一些自助的数据分析,这也是之前用户一直期望的。
4.4 项目集成
说了这么多,已经迫不及待进行系统集成尝试了。
4.4.1 鸿鹄系统的安装
鸿鹄系统的安装非常简单,基本上按照官方文档一步步下来很快就能搞定,系统内存也只是需要 8G 的限制,在如今手机内存都超过 8G 的年代,还是非常良心的配置要求。
不过由于鸿鹄使用了矢量计算技术,官方文档提示:鸿鹄计算引擎使用了 AVX2 高级指令集做向量计算加速,因此,鸿鹄需要运行在支持 AVX2 指令集的 CPU 上。
当然,官方文档给出了测试方法,可以运行以下命令得知CPU是否支持AVX2 指令集:

刚好,我有一台现成的老服务器,赶紧进行测试。不幸的是,他……不支持。

很快,我找来一台云主机,完美解决。

安装需要安装docker以及其他一些相关组件,不过安装过程非常简单,完全按照官方安装文档(https://yanhuang.yuque.com/staff-sbytbc/rb5rur/auwfm3?)一步步进行即可。
这是安装完成后的界面,确实是“大数至简”。

4.4.2 接收MQTT数据
为了能赶紧试试鸿鹄的功能,我们需要先把数据灌进来,当然如果只是试用,你可以用 csv、json 等文件导入数据。
由于在之前的架构中,我们会采用 EMQX 来采集各种设备的数据,所以,在试用的过程中我简单的开发了一个从EMQX 接收 MQTT 数据并转发到鸿鹄的服务,并已发布到 Github 平台上。
开发过程就不细表,大家可以到如下地址看到并下载:
https://github.com/neulf/mqtt-honghu

4.4.3 数据预计算技术
由于数据量的增大,我们在 InfluxDB 上一般会采用 Rollup 进行预计算,以增强对大数据的处理能力,提高查询性能。因此,对于一款新的大数据产品,很自然地,我们对数据预计算方面也非常关切。
从官方文档上,我们发现鸿鹄提供了多种数据预计算技术,包括物化视图、预存查询、定时报表,你可以在官方文档中看到这几种技术的应用场景,我就不在这里一一赘述。
4.4.4 灵活的查询
鸿鹄提供简易查询和高阶查询的功能,支持业界通用的生产力工具——SQL 进行查询,这一点对于大部分工程师、数据分析人员甚至一部分资深的运营人员都是很方便的。
有关鸿鹄SQL的介绍,请参考这里
(https://yanhuang.yuque.com/staff-sbytbc/rb5rur/znakv0?)
4.4.5 丰富的开箱即用图表
鸿鹄提供了非常丰富的图表,对于一个使用过一些商业BI产品(比如:Tableau、PowerBI)的人来说,这款社区产品真的是非常给力,我们尝试把之前需要进行定制开发的功能,比如 AGC 指令、系统出力功率等指标的对比曲线用鸿鹄的高级查询功能实现,真的是非常简单。
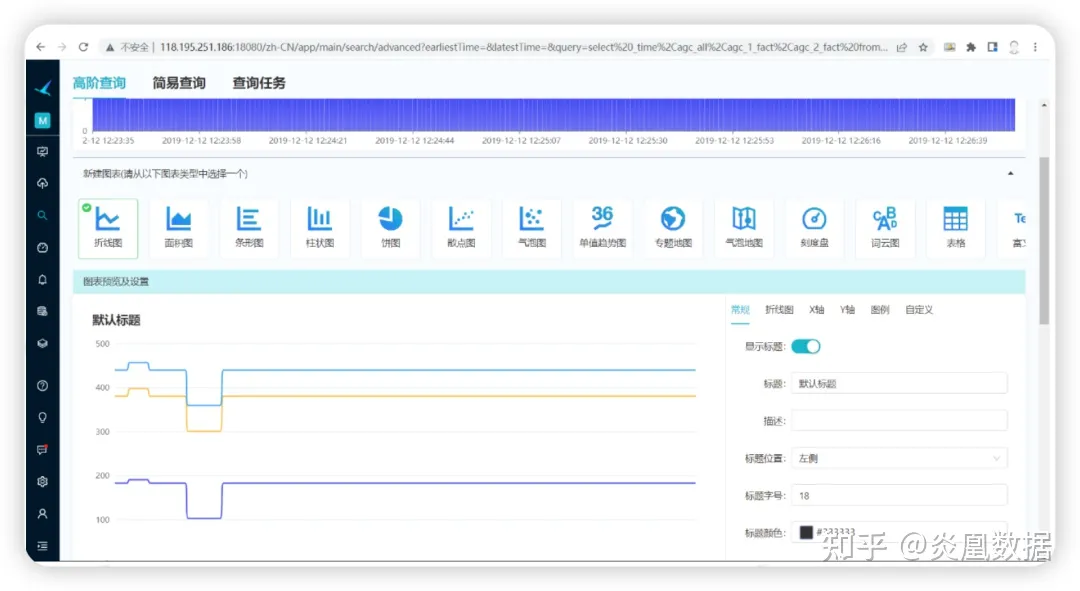
4.5 总结
从试用来看,鸿鹄是一款安装非常方便,具备丰富的图表分析功能的社区产品。由于我没有对鸿鹄和一些时序数据库进行插入性能方面的基准测试,但是从其他搜索引擎和时序数据库的对比以及个人经验来看,对于采集并发性能要求不是太严苛的新建共享储能 SCADA 系统,可以直接采用鸿鹄做为主存储进行使用;如果是已建项目的改造或者对性能要求非常高,可以考虑架构上采用时序性数据库配合鸿鹄的方式。
相关文章:
利用鸿鹄优化共享储能的SCADA 系统功能,赋能用户数据自助分析
摘要 本文主要介绍了共享储能的 SCADA 系统大数据架构,以及如何利用鸿鹄来更好的优化 SCADA 系统功能,如何为用户进行数据自助分析赋能。 1、共享储能介绍 说到共享储能,可能不少朋友比较陌生,下面我们简单介绍一下共享储能的价值…...

noSQL语句练习
Redis练习题 string list hash结构中,每个至少完成5个命令,包含插入 修改 删除 查询,list 和hash还需要增加遍历的操作命令 1、 string类型数据的命令操作: (1) 设置键值: 127.0.0.1:63…...

Spring:Bean生命周期
Bean 生命周期生命周期 Bean 生命周期是 bean 对象从创建到销毁的整个过程。 简单的 Bean 生命周期的过程: 1.实例化(调用构造方法对 bean 进行实例化) 2.依赖注入(调用 set 方法对 bean 进行赋值) 3.初始化(手动配置 xml 文件中 bean 标签的 init-method 属性值,来指…...
Vue自定义指令
需求1:定义一个v-big指令,和v-text功能类似,但会把绑定的数值放大10倍。 需求2:定义一个v-fbind指令,和v-bind功能类似,但可以让其所绑定的input元素默认获取焦点。 自定义指令函数式v-big: &l…...
SpringBoot+JWT实现单点登录解决方案
一、什么是单点登录? 单点登录是一种统一认证和授权机制,指在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的系统,不需要重新登录验证。 单点登录一般用于互相授信的系统,实现单一位置登录,其他信任的…...
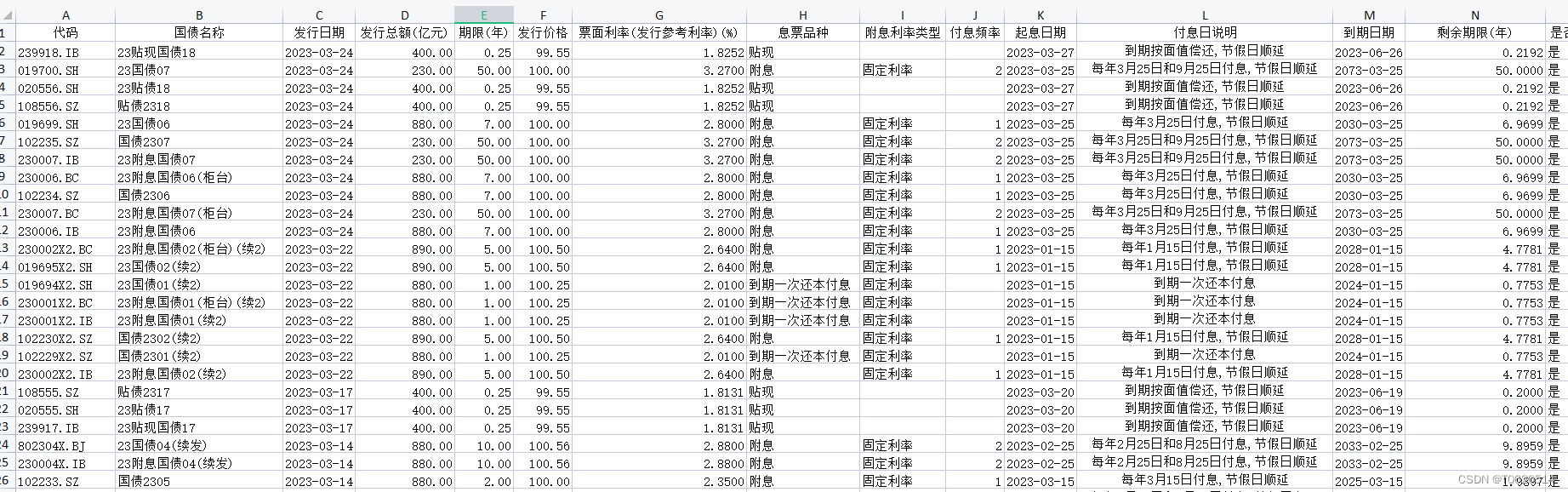
中国国债发行数据集(2002-2023)
国债是由国家发行的债券,由于国债的发行主体是国家,所以它具有最高的信用度,被公认为是最安全的投资工具。国债按照交易市场的不同分为三类,即银行间市场国债、交易所市场国债和柜台市场国债;按照交易方式的不同分为三…...
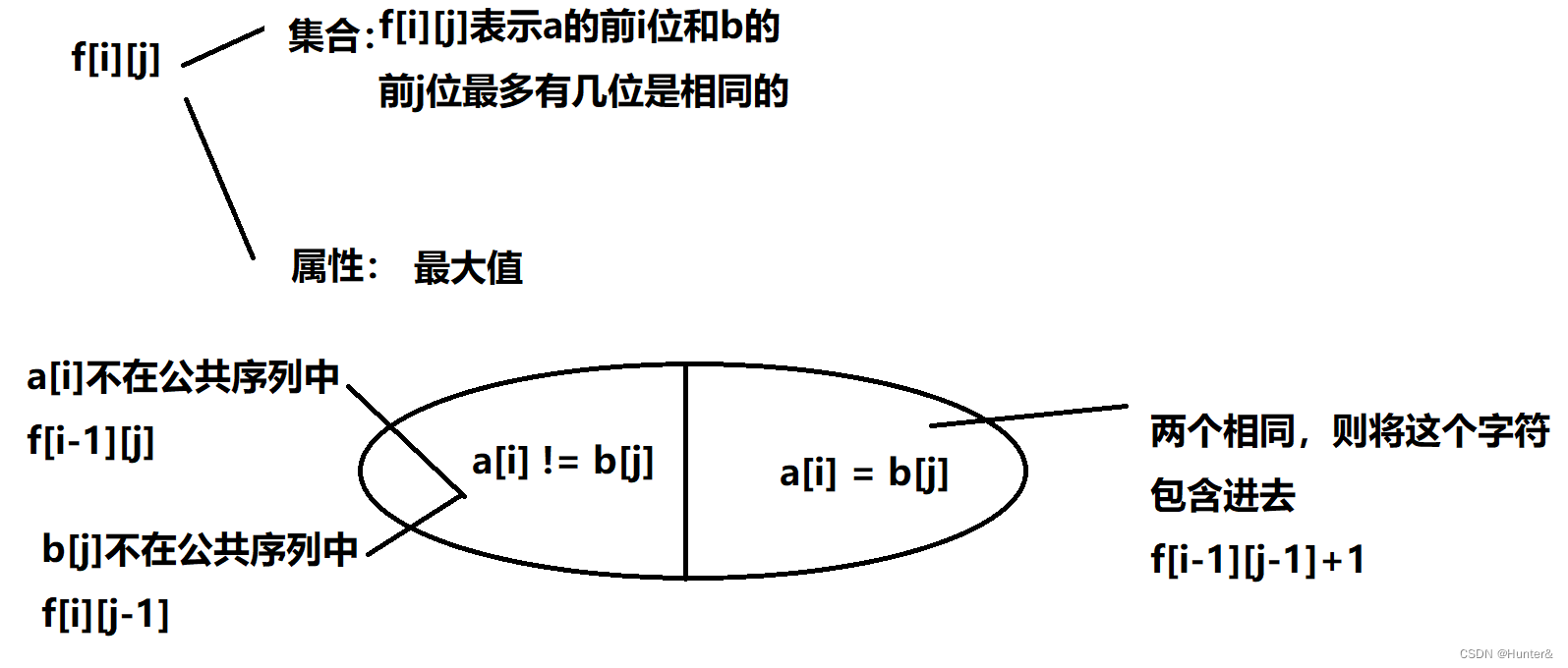
曲师大2023大一新生排位赛-C.String题解
C.String 题目描述 众所周知,许师哥精通字符串。 一天,许师哥意外的获得了一个字符串,但他发现这个字符串并不是一个回文串,因此他非常生气。于是他决定从这个字符串中删除若干个字符使得 剩余的字符串为一个回文串。 回想回文串…...

Linux Ubuntu安装RabbitMQ服务
文章目录 前言1.安装erlang 语言2.安装rabbitMQ3. 内网穿透3.1 安装cpolar内网穿透(支持一键自动安装脚本)3.2 创建HTTP隧道 4. 公网远程连接5.固定公网TCP地址5.1 保留一个固定的公网TCP端口地址5.2 配置固定公网TCP端口地址 前言 RabbitMQ是一个在 AMQP(高级消息队列协议)基…...

什么是测试用例?如何设计?
在学习或者实际的测试工作中经常都会提到“测试用例”这个词,没错,测试用例是测试工作的核心,不管要做的是什么样的测试,在真正动手执行测试之前,我们都需要先根据软件需求来设计测试用例,之后再依据设计好…...
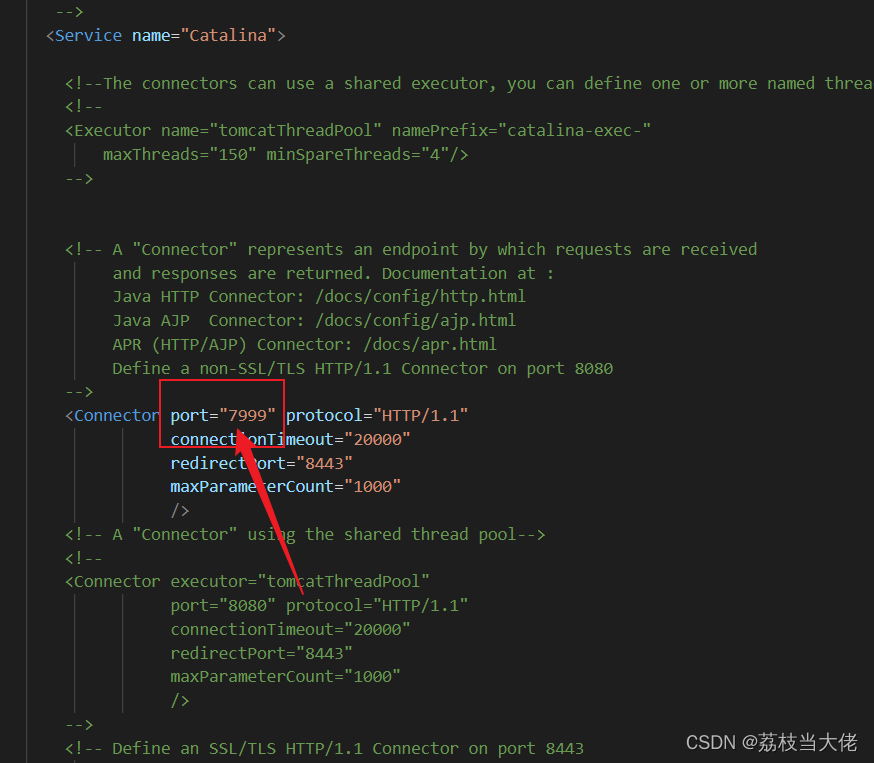
Maven —— 项目管理工具
前言 在这篇文章中,荔枝会介绍如何在项目工程中借助Maven的力量来开发,主要涉及Maven的下载安装、环境变量的配置、IDEA中的Maven的路径配置和信息修改以及通过Maven来快速构建项目。希望能对需要配置的小伙伴们有帮助哈哈哈哈~~~ 文章目录 前言 一、初…...

Ubuntu 命令行编辑文件后如何保存退出
在 Ubuntu 命令行中编辑文件后,可以使用以下步骤保存并退出: 按下键盘上的 Ctrl 键和 X 键组合,以退出编辑模式。如果文件已更改,你将看到提示,询问是否保存更改。按下 Y 键来确认保存更改,或按下 N 键取消…...
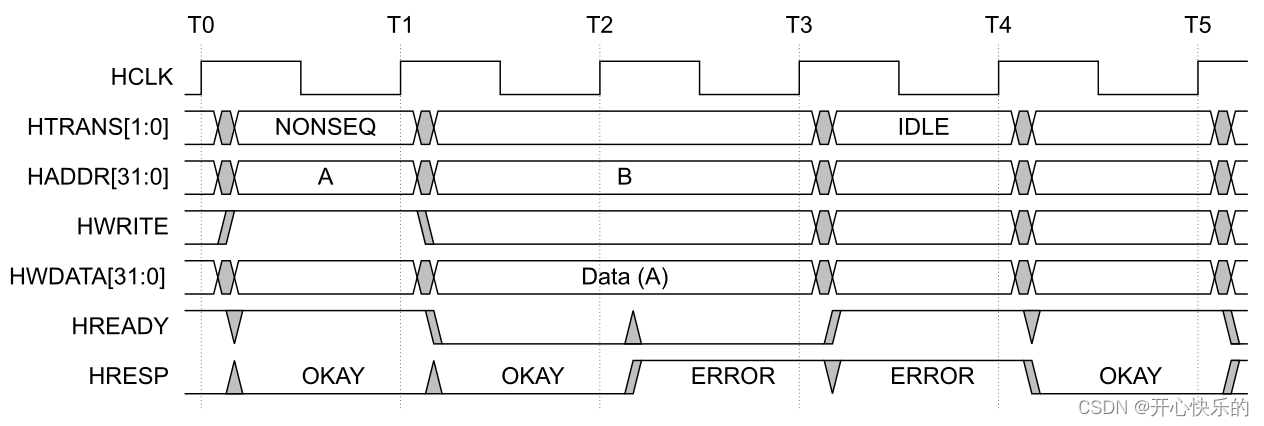
AHB协议理解
从小父亲就教育我,做一个对社会有用的人! 目录 Chapter1 AHB Block Diagram Ginput signal lnput signals Output Signal Chapter3 Transfers AHB接口Overview Chapter6 Data Buses HWDATA HRDATA Chapter1 Introduction AHB: Advanced High-performanc…...
【UE5 多人联机教程】01-创建主界面
目录 工程地址 步骤 参考链接 工程地址 GitHub - UE4-Maple/C_MP_Lobby: 多人大厅教程项目 步骤 1. 先新建一个工程 2. 将下载的工程中的Plugins目录拷贝到自己新建的工程下 3. 打开工程,新建一个游戏实例 这里命名为“GI_Main” 在项目设置中设置游戏实例类为…...

HarmonyOS学习路之方舟开发框架—学习ArkTS语言(基本语法 五)
Styles装饰器:定义组件重用样式 如果每个组件的样式都需要单独设置,在开发过程中会出现大量代码在进行重复样式设置,虽然可以复制粘贴,但为了代码简洁性和后续方便维护,我们推出了可以提炼公共样式进行复用的装饰器St…...

React(3)
1.案例选项卡 import React, { Component } from reactexport default class App extends Component {state{tabList:[{id:1,text:"电影"},{id:2,text:"影院"},{id:3,text:"我的"}]}render() {return (<div><ul>{this.state.tabList…...

LangChain大型语言模型(LLM)应用开发(三):Chains
LangChain是一个基于大语言模型(如ChatGPT)用于构建端到端语言模型应用的 Python 框架。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互&#x…...
FPGA——点亮led灯
文章目录 一、实验环境二、实验任务三、实验过程3.1 编写verliog程序3.2 引脚配置 四、仿真4.1 仿真代码4.2仿真结果 五、实验结果六、总结 一、实验环境 quartus18.1 vscode Cyclone IV开发板 二、实验任务 每间隔1S实现led灯的亮灭,实现流水灯的效果。 三、实…...

idea创建spark教程
1、环境准备 java -version scala -version mvn -version spark -version 2、创建spark项目 创建spark项目,有两种方式;一种是本地搭建hadoop和spark环境,另一种是下载maven依赖;最后在idea中进行配置,下面分别记录两…...

【JavaEE】DI与DL的介绍-Spring项目的创建-Bean对象的存储与获取
Spring的开发要点总结 文章目录 【JavaEE】Spring的开发要点总结(1)1. DI 和 DL1.1 DI 依赖注入1.2 DL 依赖查询1.3 DI 与 DL的区别1.4 IoC 与 DI/DL 的区别 2. Spring项目的创建2.1 创建Maven项目2.2 设置国内源2.2.1 勾选2.2.2 删除本地jar包2.2.3 re…...

C#图片处理
查找图片所在位置 原理:使用OpenCvSharp对比查找小图片在大图片上的位置 private static System.Drawing.Point Find(Mat BackGround, Mat Identify, double threshold 0.8) {using (Mat res new Mat(BackGround.Rows - Identify.Rows 1, BackGround.Cols - Iden…...

华为Matebook 13双系统实战:Win10与Ubuntu 16.04无缝共存指南
1. 为什么选择华为Matebook 13安装双系统 作为一名长期使用双系统开发的工程师,我最近在华为Matebook 13上成功部署了Win10Ubuntu 16.04双系统组合。这款13英寸的轻薄本确实给了我不少惊喜——2K全面屏、1.3kg超轻机身、第八代i5处理器,这些硬件配置对于…...

给嵌入式新手的保姆级指南:JTAG、SWD、J-Link、ST-Link到底怎么选?
嵌入式开发调试工具全指南:从JTAG到SWD的实战选择策略 第一次拿到STM32开发板时,看着板子上那排密密麻麻的调试接口针脚,我盯着J-Link和ST-Link这两个名词发了半小时呆——它们到底有什么区别?为什么有的教程用JTAG接线࿰…...

String、StringBuilder、StringBuffer 的本质区别
作为 Java 开发者,String、StringBuilder、StringBuffer 这三个类几乎每天都在用。但面试官总爱问这道题,因为它背后藏着 JVM 内存模型、线程安全、性能优化等核心知识点。今天我们从本质出发,彻底把这三个类讲透。一、String 为什么不可变&a…...

OpenClaw错误排查大全:百川2-13B接口调用常见问题与解决方案
OpenClaw错误排查大全:百川2-13B接口调用常见问题与解决方案 1. 为什么需要这份排查指南 上周我在本地部署百川2-13B模型对接OpenClaw时,连续遇到了三个晚上各种报错。从模型加载失败到Token耗尽,再到莫名其妙的响应超时,每次解…...

Android开发职位深度解析与面试指南
引言 Android开发作为移动应用开发的核心领域,近年来随着智能手机的普及和技术的迭代,已成为IT行业的热门职业方向。本文基于一份典型的Android开发职位描述展开,深入探讨其核心技能要求、经验门槛、工具使用等关键要素。职位描述强调了对Flutter、多线程、Framework、Andr…...

比迪丽AI绘画创意开发:使用Matlab进行生成效果分析
比迪丽AI绘画创意开发:使用Matlab进行生成效果分析 1. 引言 在AI绘画创作领域,比迪丽模型因其出色的角色生成能力而备受关注。但如何科学评估生成效果、量化分析风格特征,一直是创作者面临的挑战。传统的人工评估方式主观性强、效率低下&am…...

SDXL-Turbo快速上手:AutoDL开箱即用,零配置体验实时AI绘画
SDXL-Turbo快速上手:AutoDL开箱即用,零配置体验实时AI绘画 1. 什么是SDXL-Turbo SDXL-Turbo是StabilityAI推出的新一代实时AI绘画模型,它彻底改变了传统AI绘画需要等待数秒甚至数十秒才能看到结果的工作方式。基于创新的对抗扩散蒸馏技术(A…...

提升开发效率与视觉舒适度:LxgwWenKai字体全场景配置指南
提升开发效率与视觉舒适度:LxgwWenKai字体全场景配置指南 【免费下载链接】LxgwWenKai LxgwWenKai: 这是一个开源的中文字体项目,提供了多种版本的字体文件,适用于不同的使用场景,包括屏幕阅读、轻便版、GB规范字形和TC旧字形版。…...
)
从浮点到定点:手把手教你用MATLAB自定义函数实现加减乘除(避坑溢出与精度损失)
从浮点到定点:手把手教你用MATLAB自定义函数实现加减乘除(避坑溢出与精度损失) 当算法需要从实验室环境迁移到嵌入式设备时,浮点运算的硬件开销常常成为瓶颈。这时定点数运算就像一把手术刀——精准控制每个比特的用途,…...
)
保姆级教程:在Windows 11上用VSCode和Conda搞定Depth-Anything-3(含常见报错修复)
Windows 11深度估计实战:VSCodeConda环境下的Depth-Anything-3全流程指南 深度估计作为计算机视觉领域的重要技术,正在自动驾驶、增强现实等场景中发挥关键作用。本文将带你在Windows 11系统上,使用VSCode和Conda搭建Depth-Anything-3开发环境…...