人工智能自然语言处理:N-gram和TF-IDF模型详解

人工智能自然语言处理:N-gram和TF-IDF模型详解
1.N-gram 模型
N-Gram 是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为 N 的滑动窗口操作,形成了长度是 N 的字节片段序列。
每一个字节片段称为 gram,对所有 gram 的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键 gram 列表,也就是这个文本的向量特征空间,列表中的每一种 gram 就是一个特征向量维度。
该模型基于这样一种假设,第 N 个词的出现只与前面 N-1 个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计 N 个词同时出现的次数得到。常用的是二元的 Bi-Gram 和三元的 Tri-Gram。
当 n=1 时,一个一元模型为:
P ( w 1 , w 2 , ⋯ , w m ) = ∏ i = 1 m P ( w i ) P(w1,w2,⋯,wm)=∏i=1mP(wi) P(w1,w2,⋯,wm)=∏i=1mP(wi)
当 n=2 时,一个二元模型为:
P ( w 1 , w 2 , ⋯ , w m ) = ∏ i = 1 m P ( w i ∣ w i − 1 ) P(w1,w2,⋯,wm)=∏i=1mP(wi∣wi−1) P(w1,w2,⋯,wm)=∏i=1mP(wi∣wi−1)
当 n=3 时,一个三元模型为:
P ( w 1 , w 2 , ⋯ , w m ) = ∏ i = 1 m P ( w i ∣ w i − 2 , w i − 1 ) P(w1,w2,⋯,wm)=∏i=1mP(wi∣wi−2,wi−1) P(w1,w2,⋯,wm)=∏i=1mP(wi∣wi−2,wi−1)
一个 n-gram 是 n 个词的序列:
一个 2-gram(bigram 或二元)是两个词的序列,例如 “I love”;
一个 3-gram(trigram 或三元)是三个词的序列,例如 “I love you”。
需要注意的是,通常 n-gram 即表示词序列,也表示预测这个词序列概率的模型。假设给定一个词序列(w1,w2,···,wm),根据概率的链式法则,可得公式 (1.1):
P ( w 1 , w 2 , ⋯ , w m ) = P ( w 1 ) ∗ P ( w 2 ∣ w 1 ) ⋯ P ( w m ∣ w 1 , ⋯ , w m − 1 ) = ∏ i = 1 m P ( w i ∣ w i − 2 , w i − 1 ) P(w1,w2,⋯,wm)=P(w1)∗P(w2∣w1)⋯P(wm∣w1,⋯,wm−1)=∏i=1mP(wi∣wi−2,wi−1) P(w1,w2,⋯,wm)=P(w1)∗P(w2∣w1)⋯P(wm∣w1,⋯,wm−1)=∏i=1mP(wi∣wi−2,wi−1)
公式(1.1)右边的 P(wi | w1,w2,···,wi-1)表示某个词 wi 在已知句子 w1,w2,···,wi-1 后面一个词出现的概率
1.1 马尔科夫假设
在实践中,如果文本的长度较长时,公式(1.1)右边的 P ( w i ∣ w 1 , w 2 , ⋅ ⋅ ⋅ , w i − 1 P(wi | w1,w2,···,wi-1 P(wi∣w1,w2,⋅⋅⋅,wi−1的估算会非常困难,因此需要引入马尔科夫假设。
马尔科夫假设是指,每个词出现的概率只跟它前面的少数几个词有关。比如,二阶马尔科夫假设只考虑前面两个词,相应的语言模型是三元(trigram)模型。应用了这个假设表明当前这个词仅仅跟前面几个有限的词有关,因此也就不必追溯到最开始的那个词,这样便可以大幅缩减上述算式的长度。
基于马尔科夫假设,可得公式 (1.2):
P ( w i ∣ w 1 , ⋯ , w i − 1 ) ≈ P ( w i ∣ w i − n + 1 , ⋯ , w i − 1 ) P(wi∣w1,⋯,wi−1)≈P(wi∣wi−n+1,⋯,wi−1) P(wi∣w1,⋯,wi−1)≈P(wi∣wi−n+1,⋯,wi−1)
当 n = 1 时称为一元模型(unigram model),公式(1.2)右边会演变成 P(wi),此时,整个句子的概率为:
P ( w 1 , w 2 , ⋯ , w m ) = P ( w 1 ) ∗ P ( w 2 ) ⋯ P ( w m ) = ∏ i = 1 m P ( w i ) P(w1,w2,⋯,wm)=P(w1)∗P(w2)⋯P(wm)=∏i=1mP(wi) P(w1,w2,⋯,wm)=P(w1)∗P(w2)⋯P(wm)=∏i=1mP(wi)
当 n = 2 时称为二元模型(bigram model),公式(1.2)右边会演变成 P(wi | wi-1),此时,整个句子的概率为:
P ( w 1 , w 2 , ⋯ , w m ) = P ( w 1 ) ∗ P ( w 2 ∣ w 1 ) ⋯ P ( w m ∣ w m − 1 ) = ∏ i = 1 m P ( w i ∣ w i − 1 ) P(w1,w2,⋯,wm)=P(w1)∗P(w2∣w1)⋯P(wm∣wm−1)=∏i=1mP(wi∣wi−1) P(w1,w2,⋯,wm)=P(w1)∗P(w2∣w1)⋯P(wm∣wm−1)=∏i=1mP(wi∣wi−1)
当 n = 3 时称为三元模型(trigram model),公式(1.2)右边会演变成 P(wi| wi-2,wi-1),此时,整个句子的概率为:
P ( w 1 , w 2 , ⋯ , w m ) = P ( w 1 ) ∗ P ( w 2 ∣ w 1 ) ⋯ P ( w m ∣ w m − 2 , ⋯ , w m − 1 ) = ∏ i = 1 m P ( w i ∣ w i − 2 , w i − 1 ) P(w1,w2,⋯,wm)=P(w1)∗P(w2∣w1)⋯P(wm∣wm−2,⋯,wm−1)=∏i=1mP(wi∣wi−2,wi−1) P(w1,w2,⋯,wm)=P(w1)∗P(w2∣w1)⋯P(wm∣wm−2,⋯,wm−1)=∏i=1mP(wi∣wi−2,wi−1)
估计 n-gram 模型概率采用极大似然估计(maximum likelihood estimation,MLE)。即通过从语料库中获取计数,并将计数归一化到(0,1),从而得到 n-gram 模型参数的极大似然估计。即:

其中 c o u n t ( W i − n + 1 , ⋅ ⋅ ⋅ , W i ) count(Wi-n+1,···,Wi) count(Wi−n+1,⋅⋅⋅,Wi)表示文本序列 ( W i − n + 1 , ⋅ ⋅ ⋅ , W i ) (Wi-n+1,···,Wi) (Wi−n+1,⋅⋅⋅,Wi),在语料库中出现的次数。
1.2 N-gram 模型优缺点
总结下基于统计的 n-gram 语言模型的优缺点:
-
优点:
- 采用极大似然估计,参数易训练;
- 完全包含了前 n-1 个词的全部信息;
- 可解释性强,直观易理解;
-
缺点:
- 缺乏长期依赖,只能建模到前 n-1 个词;
- 随着 n 的增大,参数空间呈指数增长;
- 数据稀疏,难免会出现 OOV 词(out of vocabulary)的问题;
- 单纯的基于统计频次,泛化能力差
2.TF-IDF
TF-IDF(term frequency-inverse document frequency,词频 - 逆向文件频率) 是一种用于信息检索 (information retrieval)) 与文本挖掘 (text mining) 的常用加权技术。它是一种统计方法,用以评估一个字或词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
在信息检索 (Information Retrieval)、文本挖掘(Text Mining) 以及自然语言处理 (Natural Language Processing) 领域,TF-IDF 算法都可以说是鼎鼎有名。虽然在这些领域中,目前也出现了不少以深度学习为基础的新的文本表达和算分 (Weighting) 方法,但是 TF-IDF 作为一个最基础的方法,依然在很多应用中发挥着不可替代的作用。
TF-IDF 的主要思想是:如果某个单词在一篇文章中出现的频率 TF 高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
-
TF(全称 TermFrequency),中文含义词频,即关键词出现在网页当中的频次。
-
IDF(全称 InverseDocumentFrequency),中文含义逆文档频率,即该关键词出现在所有文档里面的一种数据集合。
-
TF-IDF 的计算过程为:
-
第一步,计算词频。
词频(TF)= 文章的总词数某个词在文章中的出现次数
或者
词频(TF)= 该文出现次数最多的词出现的次数某个词在文章中的出现次数 -
第二步,计算逆文档频率。
逆文档频率(IDF)=log(包含该词的文档数 +1 语料库的文档总数)
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近 0。分母之所以要加 1,是为了避免分母为 0(即所有文档都不包含该词)。log 表示对得到的值取对数。 -
第三步,计算 TF-IDF。
TF−IDF= 词频(TF)× 逆文档频率(IDF)
-
可以看到,TF-IDF 与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就是计算出文档的每个词的 TF-IDF 值,然后按降序排列,取排在最前面的几个词。
2.1 TF-IDF 算法总结
TF-IDF 算法是一种常用的文本特征表示方法,用于评估一个词对于一个文档集或语料库中某个文档的重要程度,常用于以下领域:
(1)搜索引擎;
(2)关键词提取;
(3)文本相似性;
(4)文本摘要。
-
TF-IDF 算法优点:
-
简单有效:TF-IDF 算法简单易实现,计算速度快,并且在很多文本相关任务中表现良好。
-
考虑词频和文档频率:TF-IDF 综合考虑了词频和文档频率两个因素,可以准确表示词语在文档中的重要性。
-
强调关键词:TF-IDF 算法倾向于给予在文档中频繁出现但在整个语料库中较少见的词更高的权重,从而能够突出关键词。
-
适用性广泛:TF-IDF 算法可以应用于各种文本相关任务,如信息检索、文本分类、关键词提取等。
-
-
TF-IDF 算法缺点:
-
无法捕捉语义信息:TF-IDF 算法仅根据词频和文档频率进行计算,无法捕捉到词语之间的语义关系,因此在处理一些复杂的语义任务时可能效果有限。
-
忽略词序信息:TF-IDF 算法将文本表示为词语的集合,并忽略了词语之间的顺序信息,因此无法捕捉到词语顺序对于文本含义的影响。
-
对文档长度敏感:TF-IDF 算法受文档长度的影响较大,较长的文档可能会有较高的词频,从而影响到特征权重的计算结果。
-
词汇表限制:TF-IDF 算法需要构建词汇表来对文本进行表示,词汇表的大小会对算法的性能和计算开销产生影响,同时也可能存在未登录词的问题。
-
主题混杂问题:在包含多个主题的文档中,TF-IDF 算法可能会给予一些频繁出现的词较高的权重,导致提取的关键词并不完全与文档主题相关。
-
3.关键知识点总结:
-
在N-gram模型中,N表示表示每次取出的单词数量
-
在N-gram模型中,当N取值越大,模型的效果会不一定变得更好(要合适)
-
N-gram模型可以用于文本分类、语音识别和机器翻译等自然语言处理任务。
-
N-gram模型的主要优点是可以捕捉上下文信息,但缺点是无法处理未知的单词。
-
在TF-IDF模型中,IDF值越大代表该词对文本内容的区分度越高
-
在TF-IDF模型中,词频(TF)指的是某个词在一篇文档中出现的次数。
本分类、语音识别和机器翻译等自然语言处理任务。
-
N-gram模型的主要优点是可以捕捉上下文信息,但缺点是无法处理未知的单词。
-
在TF-IDF模型中,IDF值越大代表该词对文本内容的区分度越高
-
在TF-IDF模型中,词频(TF)指的是某个词在一篇文档中出现的次数。
相关文章:
人工智能自然语言处理:N-gram和TF-IDF模型详解
人工智能自然语言处理:N-gram和TF-IDF模型详解 1.N-gram 模型 N-Gram 是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为 N 的滑动窗口操作,形成了长度是 N 的字节片段序列。 每一个字节片段称为 gram,对所…...
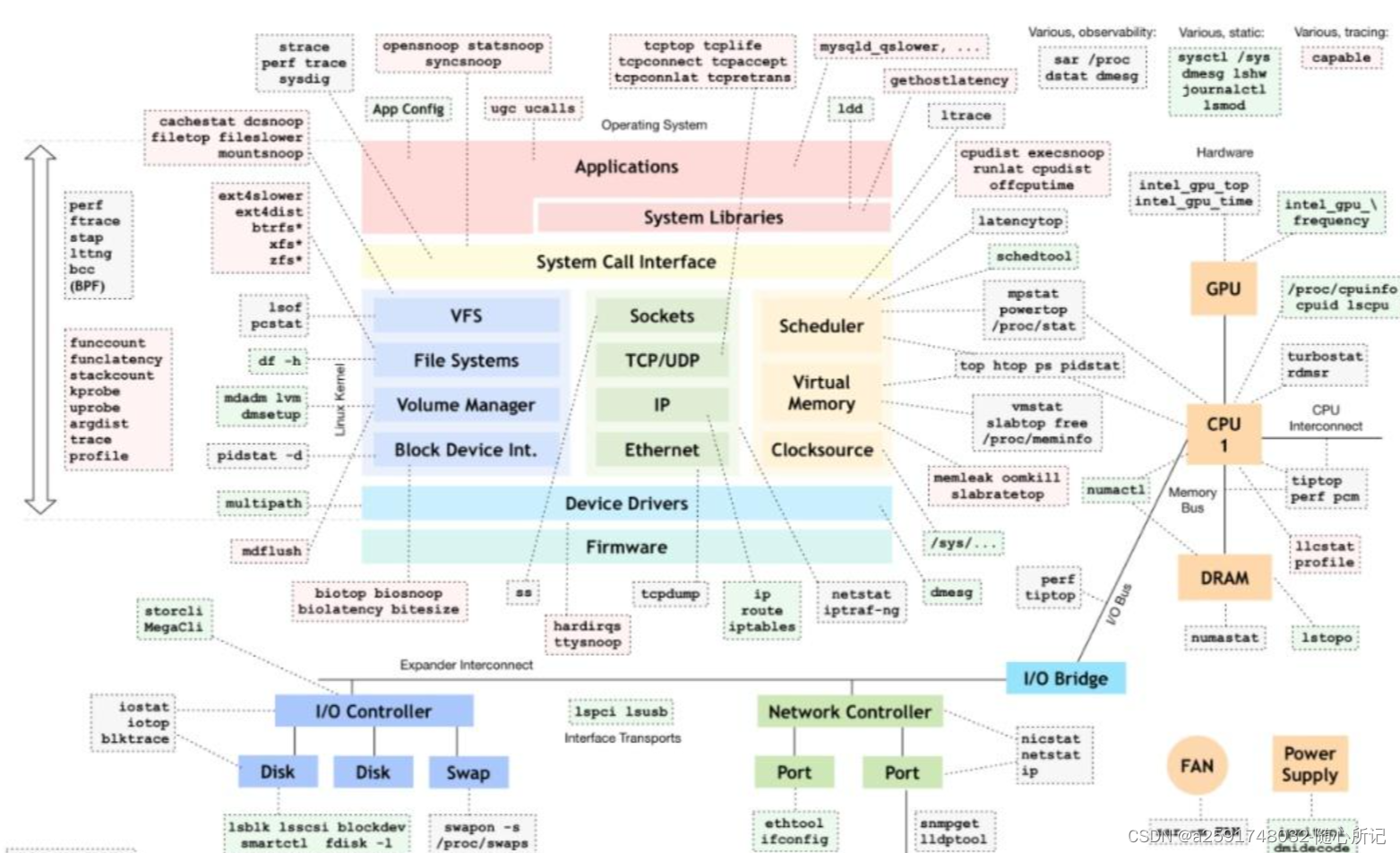
linux内核调试工具记录
Linux性能测试使用的工具在github网站可见,网址如下: slides: http://www.slideshare.net/brendangregg/linux-performance-analysis-new-tools-and-old-secrets video: https://www.usenix.org/conference/lisa14/conference-program/presentation/greg…...

XSS 攻击的检测和修复方法
XSS 攻击的检测和修复方法 XSS(Cross-Site Scripting)攻击是一种最为常见和危险的 Web 攻击,即攻击者通过在 Web 页面中注入恶意代码,使得用户在访问该页面时,恶意代码被执行,从而导致用户信息泄露、账户被…...

Spring后置处理器BeanFactoryPostProcessor与BeanPostProcessor源码解析
文章目录 一、简介1、BeanFactoryPostProcessor2、BeanPostProcessor 二、BeanFactoryPostProcessor 源码解析1、BeanDefinitionRegistryPostProcessor 接口实现类的处理流程2、BeanFactoryPostProcessor 接口实现类的处理流程3、总结 三、BeanPostProcessor 源码解析 一、简介…...
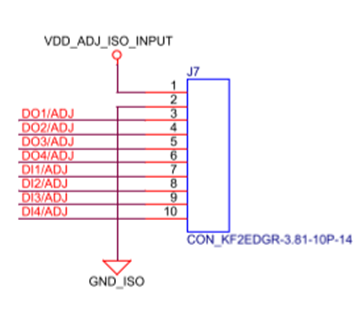
NXP i.MX 6ULL工业开发板硬件说明书( ARM Cortex-A7,主频792MHz)
前 言 本文档主要介绍TLIMX6U-EVM评估板硬件接口资源以及设计注意事项等内容。 创龙科技TLIMX6U-EVM是一款基于NXP i.MX 6ULL的ARM Cortex-A7高性能低功耗处理器设计的评估板,由核心板和评估底板组成。核心板经过专业的PCB Layout和高低温测试验证,稳…...
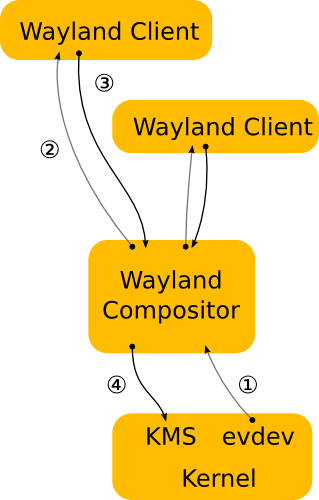
Ubuntu 放弃了战斗向微软投降
导读这几天看到 Ubuntu 放弃 Unity 和 Mir 开发,转向 Gnome 作为默认桌面环境的新闻,作为一个Linux十几年的老兵和Linux桌面的开发者,内心颇感良多。Ubuntu 做为全世界Linux界的桌面先驱者和创新者,突然宣布放弃自己多年开发的Uni…...
高并发的哲学原理(六)-- 拆分网络单点(下):SDN 如何替代百万人民币的负载均衡硬件
上一篇文章的末尾,我们利用负载均衡器打造了一个五万 QPS 的系统,本篇文章我们就来了解一下负载均衡技术的发展历程,并一起用 SDN(软件定义网络)技术打造出一个能够扛住 200Gbps 的负载均衡集群。 负载均衡发展史 F5 …...

用OpenCV进行图像分割--进阶篇
1. 引言 大家好,我的图像处理爱好者们! 在上一篇幅中,我们简单介绍了图像分割领域中的基础知识,包含基于固定阈值的分割和基于OSTU的分割算法。这一次,我们将通过介绍基于色度的分割来进一步巩固大家的基础知识。 闲…...
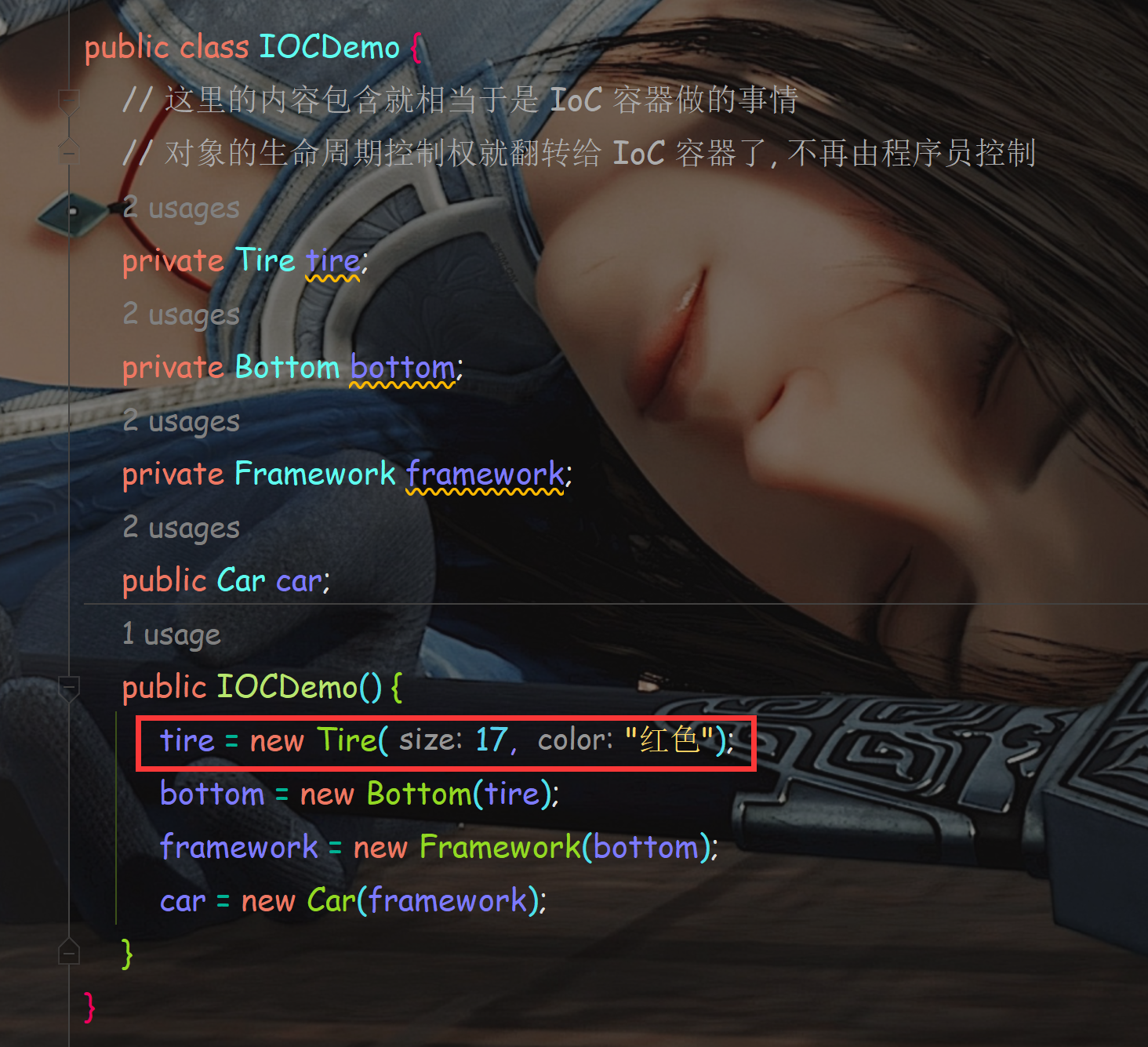
Spring框架概述及核心设计思想
文章目录 一. Spring框架概述1. 什么是Spring框架2. 为什么要学习框架?3. Spring框架学习的难点 二. Spring核心设计思想1. 容器是什么?2. IoC是什么?3. Spring是IoC容器4. DI(依赖注入)5. DL(依赖查找&…...

Unity自定义后处理——Vignette暗角
大家好,我是阿赵。 继续说一下屏幕后处理的做法,这一期讲的是Vignette暗角效果。 一、Vignette效果介绍 Vignette暗角的效果可以给画面提供一个氛围,或者模拟一些特殊的效果。 还是拿这个角色作为底图 添加了Vignette效果后࿰…...
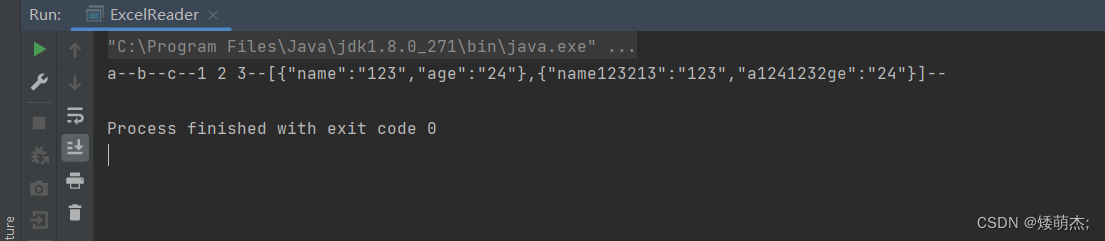
Java读取Excel 单元格包含换行问题
Java读取Excel 单元格包含换行问题 需求解决方案 需求 针对用户上传的Excel数据,或者本地读取的Excel数据。单元格中包含了换行,导致读取的数据被进行了切片。 正常读取如下图所示。 解决方案 目前是把数据读取出来的cell转成字符串后,…...

Django实现接口自动化平台(十)自定义action names【持续更新中】
相关文章: Django实现接口自动化平台(九)环境envs序列化器及视图【持续更新中】_做测试的喵酱的博客-CSDN博客 深入理解DRF中的Mixin类_做测试的喵酱的博客-CSDN博客 python中Mixin类的使用_做测试的喵酱的博客-CSDN博客 本章是项目的一…...
[爬虫]解决机票网站文本混淆问题-实战讲解
前言 最近有遇到很多小伙伴私信向我求助,遇到的问题基本上都是关于文本混淆或者是字体反爬的问题。今天给大家带来其中一个小伙伴的实际案例给大家讲讲解决方法 📝个人主页→数据挖掘博主ZTLJQ的主页 个人推荐python学习系列: ☄️爬虫J…...

【已解决】Flask项目报错AttributeError: ‘Request‘ object has no attribute ‘is_xhr‘
文章目录 报错及分析报错代码分析 解决方案必要的解决方法可能有用的解决方法 报错及分析 报错代码 File "/www/kuaidi/6f47274023d4ad9b608f078c76a900e5_venv/lib/python3.6/site-packages/flask/json.py", line 251, in jsonifyif current_app.config[JSONIFY_PR…...

【Java基础教程】Java学习路线攻略导图——史诗级别的细粒度归纳,持续更新中 ~
Java学习路线攻略导图 上篇 前言1、入门介绍篇2、程序基础概念篇3、包及访问权限篇4、异常处理篇5、特别篇6、面向对象篇7、新特性篇8、常用类库篇 前言 🍺🍺 各位读者朋友大家好!得益于各位朋友的支持和关注,我的专栏《Java基础…...

IntelliJ IDEA 2023.1 更新内容总结
IntelliJ IDEA 2023.1 更新内容总结 * 主要更新内容 * UI 大改版 * 性能改进项 * 其它更新内容IntelliJ IDEA 2023.1 更新内容总结 主要更新内容 IntelliJ IDEA 2023.1 针对新的用户界面进行了大量重构,这些改进都是基于收到的宝贵反馈而实现的。官方还实施了性能增强措施, …...

什么是计算机蠕虫?
计算机蠕虫诞生的背景 计算机蠕虫的诞生与计算机网络的发展密切相关。20世纪60年代末和70年代初,互联网还处于早期阶段,存在着相对较少的计算机和网络连接。然而,随着计算机技术的进步和互联网的普及,计算机网络得以迅速扩张&…...
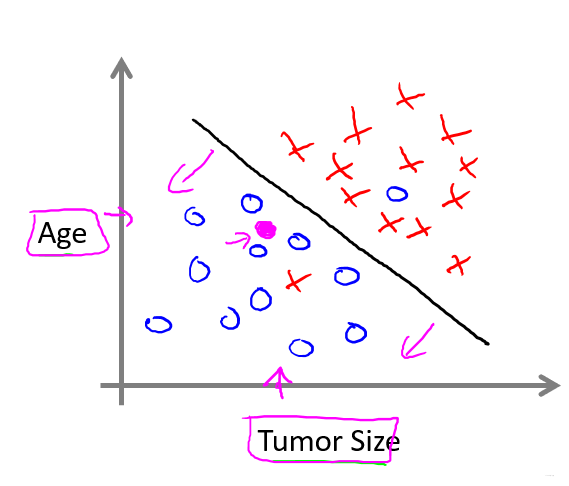
【机器学习】吴恩达课程1-Introduction
一、机器学习 1. 定义 计算机程序从经验E中学习,解决某一任务T,进行某一性能P,通过P测定在T上的表现因经验E而提高。 2. 例子 跳棋程序 E:程序自身下的上万盘棋局 T:下跳棋 P:与新对手下跳棋时赢的概…...
)
DBC转excel(python语言)
重复造轮子,只是为了熟悉一下DBC格式。 与同类工具的不同点: 能批量转换在同一文件夹下的所有DBC,省时省力。很多同类工具转换后的excel列宽较小,不能直接显示全部信息。本代码使用了自适应的列宽,看起来更方便。** …...
)
Java集合(List、Set、Map)
Java中的集合是用于存储和组织对象的数据结构。Java提供了许多不同的集合类,包括List、Set和Map等,以满足不同的需求。下面将介绍一些常见的Java集合类及其使用方法。 一、List List是一个有序的集合,它允许元素重复出现,并提供…...

HunyuanVideo-Foley镜像特性解析:低内存加载方案与显存碎片优化机制
HunyuanVideo-Foley镜像特性解析:低内存加载方案与显存碎片优化机制 1. 镜像概述与核心能力 HunyuanVideo-Foley是一款专为视频生成与音效合成任务优化的私有部署镜像,基于RTX 4090D 24GB显存环境深度调优。该镜像将视频生成与Foley音效生成能力整合在…...

OpenClaw技能开发:为Qwen3-32B定制PDF摘要插件
OpenClaw技能开发:为Qwen3-32B定制PDF摘要插件 1. 为什么需要PDF摘要技能 去年我接手了一个研究项目,需要快速消化上百份行业白皮书和学术论文。每天手动翻阅PDF的日子让我意识到:必须开发一个能自动提取核心观点的工具。这就是我决定为Ope…...

TTL串口设计及其注意事项
一、TTL串口设计概述我们常见的处理器(单片机)引出来的串口是UART、USART,其中有没有S取决于有没有时钟信号(SLK),出来的电平是TTL电平,常见的UART串口设计有3线串口设计,单线串口设计ÿ…...

macOS高效录屏工具实战指南:从入门到专业的QuickRecorder应用技巧
macOS高效录屏工具实战指南:从入门到专业的QuickRecorder应用技巧 【免费下载链接】QuickRecorder A lightweight screen recorder based on ScreenCapture Kit for macOS / 基于 ScreenCapture Kit 的轻量化多功能 macOS 录屏工具 项目地址: https://gitcode.com…...

160+实用功能:OneMore插件如何让OneNote笔记管理效率翻倍?[特殊字符]
160实用功能:OneMore插件如何让OneNote笔记管理效率翻倍?🚀 【免费下载链接】OneMore A OneNote add-in with simple, yet powerful and useful features 项目地址: https://gitcode.com/gh_mirrors/on/OneMore 还在为OneNote单调的功…...

OpenClaw安全防护指南:百川2-13B-4bits量化模型权限管控实践
OpenClaw安全防护指南:百川2-13B-4bits量化模型权限管控实践 1. 为什么需要安全防护? 当我第一次把OpenClaw接入百川2-13B-4bits量化模型时,那种兴奋感至今难忘——终于可以在本地运行一个强大的AI助手了。但很快,一个意外让我意…...

luci-app-unblockneteasemusic技术指南:解决网易云音乐播放限制问题
luci-app-unblockneteasemusic技术指南:解决网易云音乐播放限制问题 【免费下载链接】luci-app-unblockneteasemusic [OpenWrt] 解除网易云音乐播放限制 项目地址: https://gitcode.com/gh_mirrors/lu/luci-app-unblockneteasemusic 一、问题导向:…...

禅修运维法:服务器宕机时集体冥想
当技术危机遇上心灵平静在软件测试领域,服务器宕机是高频挑战,不仅中断测试流程,还引发团队压力。传统运维强调硬件修复和代码调试,但忽略了人的因素——压力下的决策失误往往加剧问题。禅修运维法创新性地将佛教禅修融入IT管理&a…...

精益生产方式的核心功能拆解:精益生产方式如何解决多品种小批量场景下的库存积压难题
在当前制造业从“少品种大批量”向“多品种小批量”急剧转型的背景下,精益生产方式已成为企业打破库存僵局的唯一出路,它通过准时化拉动和消除浪费的核心逻辑,精准解决了传统模式下因预测失效导致的严重库存积压问题;面对多变的订…...

Realistic Vision V5.1虚拟摄影棚效果验证:专业摄影师盲测准确率87.3%
Realistic Vision V5.1虚拟摄影棚效果验证:专业摄影师盲测准确率87.3% 1. 项目概述 Realistic Vision V5.1虚拟摄影棚是基于当前最先进的写实风格生成模型开发的本地化摄影工具。经过深度优化后,该工具能够生成与专业单反相机拍摄效果相媲美的人像作品…...