全国大学生数据统计与分析竞赛2021年【本科组】-B题:用户消费行为价值分析
目录
摘 要
1 任务背景与重述
1.1 任务背景
1.2 任务重述
2 任务分析
3 数据假设
4 任务求解
4.1 任务一:数据预处理
4.1.1 数据清洗
4.1.2 数据集成
4.1.3 数据变换
4.2 任务二:对用户城市分布情况与分布情况可视化分析
4.2.1 城市分布情况可视化分析
4.2.2 登录情况可视化分析
4.3 任务三:建立随机森林分类模型进行预测
4.3.1 符号说明
4.3.2 模型准备
4.3.3 预测模型的选择
4.3.4 随机森林分类模型
4.3.5 特征重要性分析
4.3.6 预测实验
4.3.7 模型评价
4.4 任务四:用户消费行为价值分析与建议
4.4.1 用户行为分析
4.4.2 用户行为转化分析
4.4.3 用户价值分析——RFM
4.4.4 给企业的建议
参考文献
代码实现
数据预处理部分代码展示
摘 要
1 任务背景与重述
1.1 任务背景
1.2 任务重述
2 任务分析
3 数据假设
4 任务求解
4.1 任务一:数据预处理
4.1.1 数据清洗
4.1.2 数据集成
4.1.3 数据变换

4.2 任务二:对用户城市分布情况与分布情况可视化分析
4.2.1 城市分布情况可视化分析

可以得出:
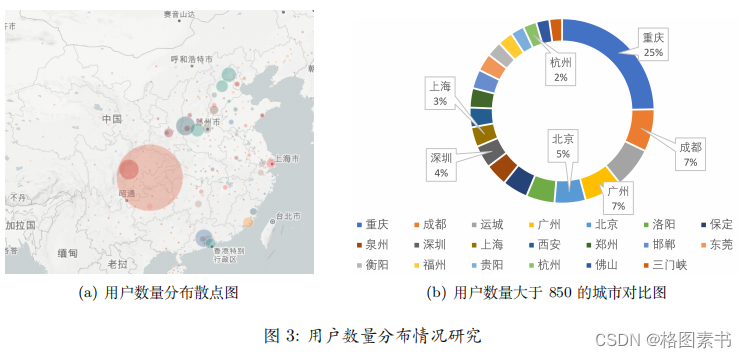
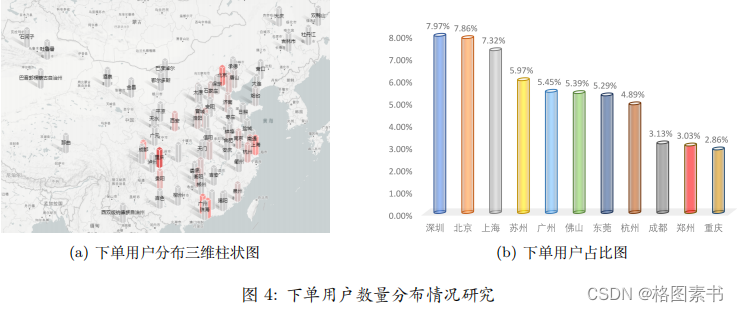
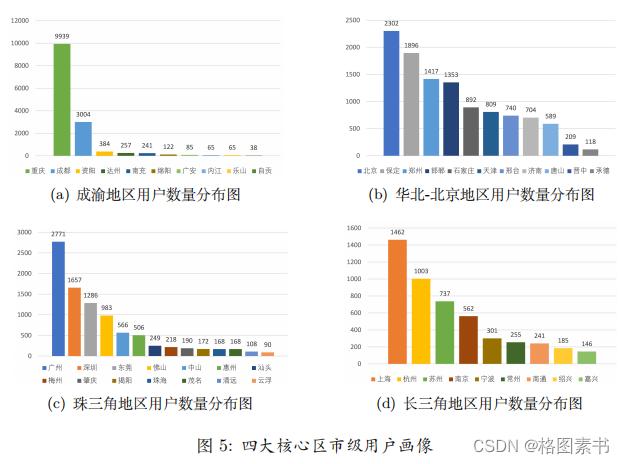
4.2.2 登录情况可视化分析
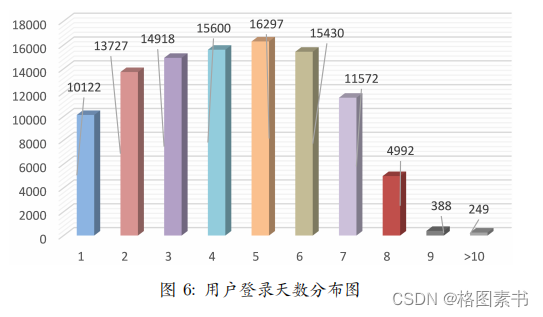
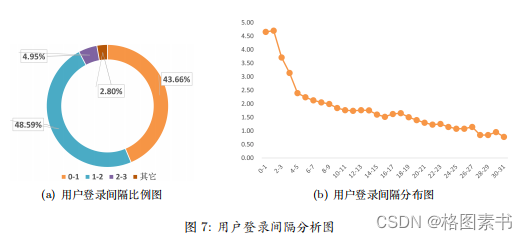
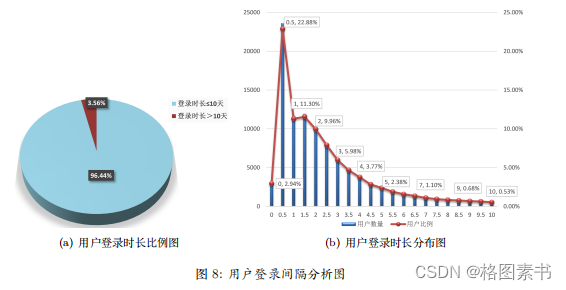 综上,针对用户活跃度,可以得到以下结论:
综上,针对用户活跃度,可以得到以下结论:  其中,针对异常值,推测该款软件于期末 46 周前进行过一次大批量的推广活动后,
其中,针对异常值,推测该款软件于期末 46 周前进行过一次大批量的推广活动后,  综上,针对用户活跃度,可以得到以下结论:
综上,针对用户活跃度,可以得到以下结论: 4.3 任务三:建立随机森林分类模型进行预测
4.3.1 符号说明

4.3.2 模型准备
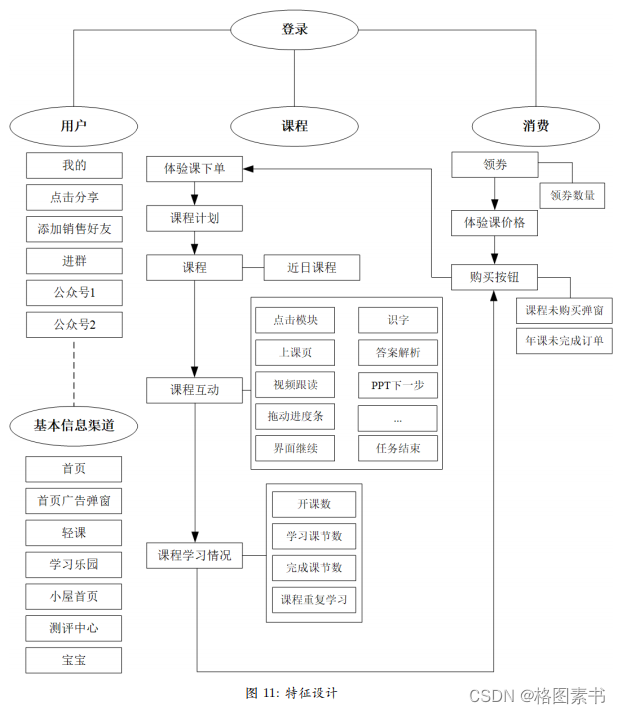 如体验课下单时间(first_order_time)、体验课价格( first_order_price )、购买
如体验课下单时间(first_order_time)、体验课价格( first_order_price )、购买 4.3.3 预测模型的选择
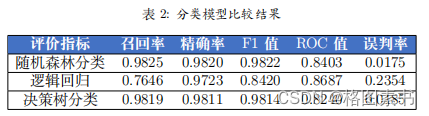 如表2所示,逻辑回归算法的表现最差,原因是逻辑回归这样的线性分类模型不适
如表2所示,逻辑回归算法的表现最差,原因是逻辑回归这样的线性分类模型不适 4.3.4 随机森林分类模型
 2. 边缘函数是正确分类结果大于最大错误分类结果的表征方式,即边缘函数越大,
2. 边缘函数是正确分类结果大于最大错误分类结果的表征方式,即边缘函数越大, 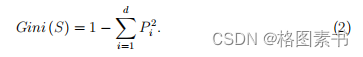
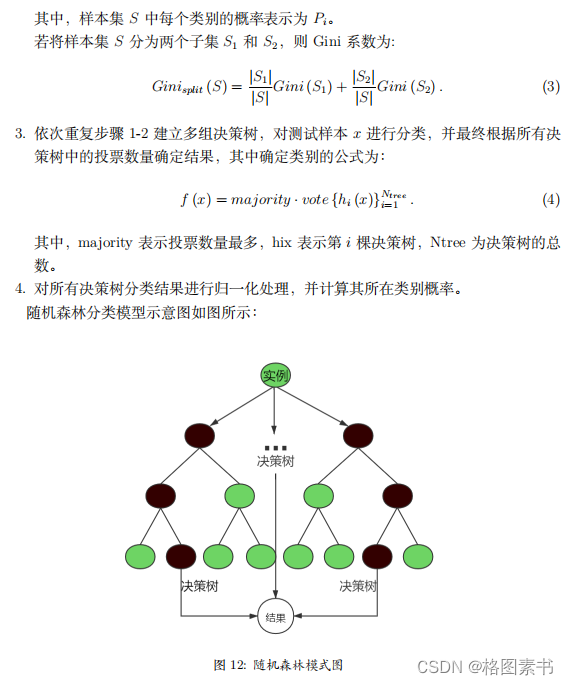
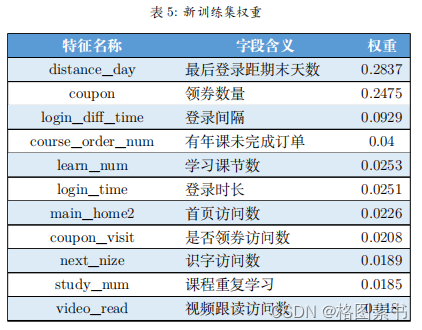
4.3.5 特征重要性分析
 解释模型或进一步调整模型结构。
解释模型或进一步调整模型结构。  从随机森林算法做出的特征重要性排序可以发现:
从随机森林算法做出的特征重要性排序可以发现:
4.3.6 预测实验

4.3.7 模型评价
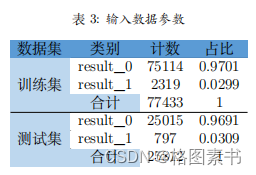
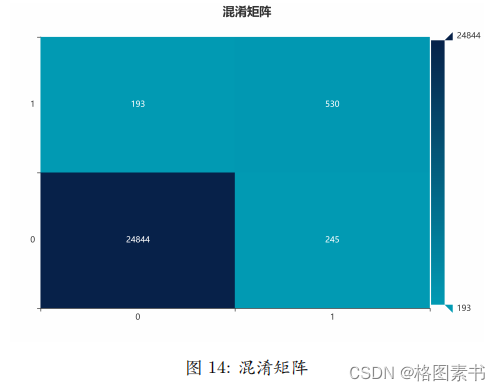 数据洗牌后,将 75% 的是否购买数据作为测试集,使用模型剩余 25% 的数据进行
数据洗牌后,将 75% 的是否购买数据作为测试集,使用模型剩余 25% 的数据进行
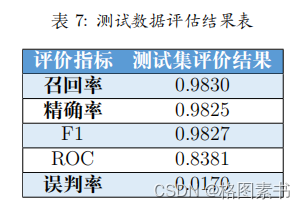 通过对比新测试集预测数据及原是否购买数据可以发现,该模型的精确率达到
通过对比新测试集预测数据及原是否购买数据可以发现,该模型的精确率达到 4.4 任务四:用户消费行为价值分析与建议
4.4.1 用户行为分析
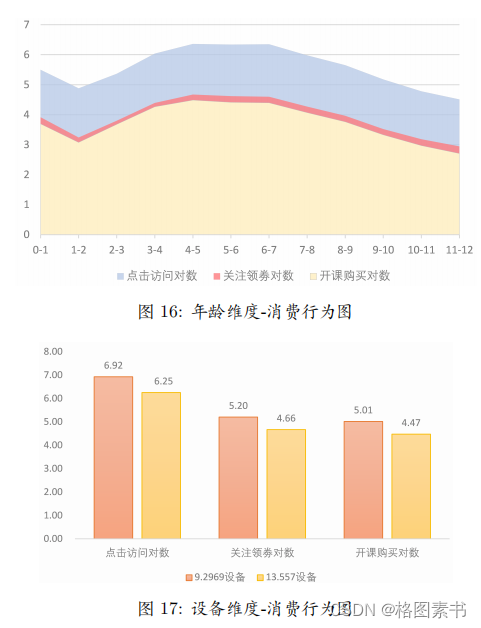
 明确用户消费行为后,需从不同维度对这些行为进行分析,通过观察数据,合理选
明确用户消费行为后,需从不同维度对这些行为进行分析,通过观察数据,合理选
 数处理,绘制出年龄维度-消费行为图,如图 16 所示:
数处理,绘制出年龄维度-消费行为图,如图 16 所示:
4.4.2 用户行为转化分析
4.4.3 用户价值分析——RFM
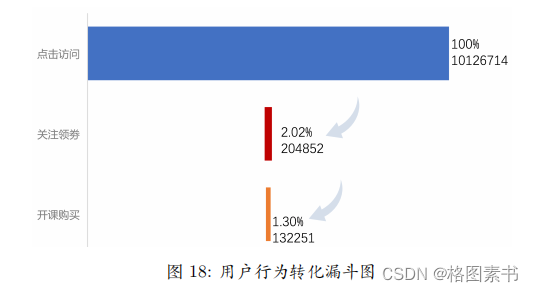 流失情况的衡量;将学习课节数作为 F 维度作为用户参与互动情况的衡量以及将体验
流失情况的衡量;将学习课节数作为 F 维度作为用户参与互动情况的衡量以及将体验

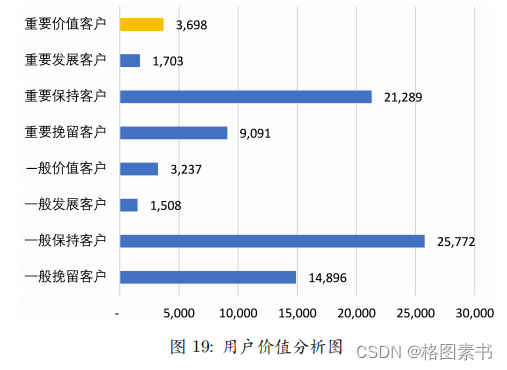 对于该平台大量的一般保持用户,推测为相关免费课程体验使用后就不再继续登
对于该平台大量的一般保持用户,推测为相关免费课程体验使用后就不再继续登 4.4.4 给企业的建议
参考文献

代码实现
数据预处理部分代码展示
import pandas as pd
data1 = pd.read_csv(’../../user_info.csv’)
data2 = pd.read_csv(’../../login_day.csv’)
data3 = pd.read_csv(’../../ visit_info .csv’)
data4 = pd.read_csv(’../../ result .csv’)
print(data1. isnull () .any())
print(data2. isnull () .any())
print(data3. isnull () .any())
print(data4. isnull () .any())
# display result
# user_id False
# first_order_time False
# first_order_price False
# age_month False
# city_num True
# platform_num False
# model_num False
# app_num False
# dtype: bool
# user_id False
# login_day False
# login_diff_time False
# distance_day False
# login_time False
# launch_time False
# chinese_subscribe_num False
# math_subscribe_num False
# add_friend False
# add_group False
# camp_num False
# learn_num False
# finish_num False
# study_num False
# coupon False# course_order_num False
# dtype: bool
# user_id False
# main_home False
# main_home2 False
# mainpage False
# schoolreportpage False
# main_mime False
# lightcoursetab False
# main_learnpark False
# partnergamebarrierspage False
# evaulationcenter False
# coupon_visit False
# click_buy False
# progress_bar False
# ppt False
# task False
# video_play False
# video_read False
# next_nize False
# answer_task False
# chapter_module False
# course_tab False
# slide_subscribe False
# baby_info False
# click_notunlocked False
# share False
# click_dialog False
# dtype: bool
# user_id False
# result False
# dtype: bool# -*-coding:utf-8-*-
import pandas as pd
data1 = pd.read_csv(’../user_info.csv’)
print(data1[’user_id’ ]. count())
wp1 = data1.drop_duplicates(subset=’user_id’,keep=False)print(wp1[’user_id’].count())
wp1.to_csv(’../user_infoPretreatment.csv’)
data2 = pd.read_csv(’../login_day.csv’)
print(data2[’user_id’ ]. count())
wp2 = data2.drop_duplicates(subset=’user_id’,keep=False)
print(wp2[’user_id’].count())
wp2.to_csv(’../login_dayPretreatment.csv’)
data3 = pd.read_csv(’../visit_info.csv’)
print(data3[’user_id’ ]. count())
wp3 = data3.drop_duplicates(subset=’user_id’,keep=False)
print(wp3[’user_id’].count())
wp3.to_csv(’../visit_infoPretreatment.csv’)
data4 = pd.read_csv(’../result.csv’)
print(data4[’user_id’ ]. count())
wp4 = data4.drop_duplicates(subset=[’user_id’],keep=False)
print(wp4[’user_id’].count())
wp4.to_csv(’../resultPretreatment.csv’)
# display result
# 135968
# 116703
# 135617
# 116416
# 135617
# 116416
# 4639
# 4613# -*-coding:utf-8-*-
import pandas as pd
data1 = pd.read_csv(’../user_info_tobemerged.csv’)
data2 = pd.read_csv(’../login_day_tobemerged.csv’)
data3 = pd.read_csv(’../visit_info_tobemerged.csv’)
data4 = pd.read_csv(’../result_tobemerged.csv’)result23 = pd.merge(data2, data3, on=[’user_id’])
result23 .to_csv(’../merge23.csv’, encoding=’gbk’)
result234 = pd.merge(result23, data4, on=[’user_id’], how=’left’)
result234 = result234. fillna (0)
result234.to_csv(’../merge234.csv’, encoding=’gbk’)
result1234 = pd.merge(data1, result234, on=[’user_id’], how=’right’)
result1234.to_csv(’../merge1234.csv’, encoding=’gbk’)import pandas as pd
import numpy as np
from sklearn. cluster import KMeans
import matplotlib.pyplot as plt
# ------ 1.导入数据 ------
df = pd.read_csv(’china.csv’) # 此处注意换成自己的数据集路径
#print(df.head()) # 展示前5行数据
# ------ 2.提取经纬度数据 ------
x = df
x_np = np.array(x) # 将x转化为numpy数组
# ------ 3.构造K-Means聚类器 ------
n_clusters = 5 # 类簇的数量
estimator = KMeans(n_clusters) # 构建聚类器
# ------ 4.训练K-Means聚类器 ------
estimator. fit (x)
# ------ 5.数据可视化 ------
markers = [’*’, ’v’, ’+’, ’^’, ’s’ , ’x’, ’o’ ] # 标记样式列表
colors = [’r’ , ’g’ , ’m’, ’c’ , ’y’, ’b’, ’orange’] # 标记颜色列表
labels = estimator.labels_ # 获取聚类标签
plt . figure ( figsize =(9, 6))
plt .xlabel(’East Longitude’, fontsize =18)
plt .ylabel(’North Latitude’, fontsize =18)for i in range(n_clusters): # 遍历所有城市,绘制散点图
members = labels == i # members是一个布尔型数组
plt . scatter(
x_np[members, 1], # 城市经度数组
x_np[members, 0], # 城市纬度数组
marker = markers[i], # 标记样式
c = colors[ i ] # 标记颜色
) # 绘制散点图
plt .grid()
plt .show()相关文章:
全国大学生数据统计与分析竞赛2021年【本科组】-B题:用户消费行为价值分析
目录 摘 要 1 任务背景与重述 1.1 任务背景 1.2 任务重述 2 任务分析 3 数据假设 4 任务求解 4.1 任务一:数据预处理 4.1.1 数据清洗 4.1.2 数据集成 4.1.3 数据变换 4.2 任务二:对用户城市分布情况与分布情况可视化分析 4.2.1 城市分布情况可视化分析 4…...

力扣1667. 修复表中的名字
表: Users ------------------------- | Column Name | Type | ------------------------- | user_id | int | | name | varchar | ------------------------- 在 SQL 中,user_id 是该表的主键。 该表包含用户的 ID 和名字。…...
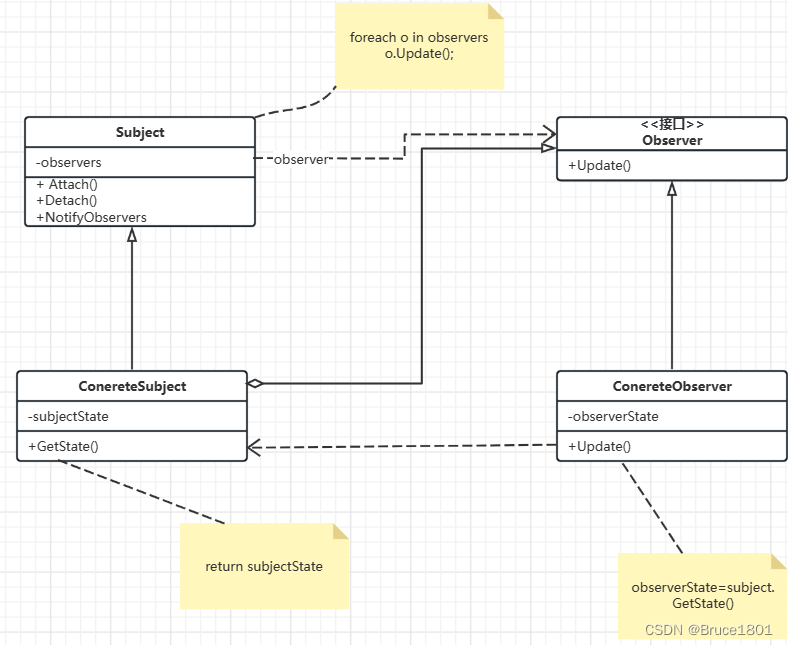
【设计模式】详解观察者模式
文章目录 1、简介2、观察者模式简单实现抽象主题(Subject)具体主题(ConcreteSubject)抽象观察者(Observer)具体观察者(ConcrereObserver)测试: 观察者设计模式优缺点观察…...

用html+javascript打造公文一键排版系统8:附件及标题排版
最近工作有点忙,所 以没能及时完善公文一键排版系统,现在只好熬夜更新一下。 有时公文有包括附件,招照公文排版规范: 附件应当另面编排,并在版记之前,与公文正文一起装订。“附件”二字及附件顺序号用3号黑…...
微服务体系<1>
我们的微服务架构 我们的微服务架构和单体架构的区别 什么是微服务架构 微服务就是吧我们传统的单体服务分成 订单模块 库存模块 账户模块单体模块 是本地调用 从订单模块 调用到库存模块 再到账户模块 这三个模块都是调用的同一个数据库 这就是我们的单体架构微服务 就是…...

M5ATOMS3基础02传感器MPU6886
M5ATOMS3基础01按键 简洁版本 MPU6886是一款6轴IMU单元,具有3轴重力加速度计和3轴陀螺仪。它采用16位ADC,内置可编程数字滤波器和片上温度传感器,并通过I2C接口(地址为0x68)与上位机通信。MPU6886支持低功耗模式&#…...

vue 快速自定义分页el-pagination
vue 快速自定义分页el-pagination template <div style"text-align: center"><el-paginationbackground:current-page"pageObj.currentPage":page-size"pageObj.page":page-sizes"pageObj.pageSize"layout"total,prev,…...
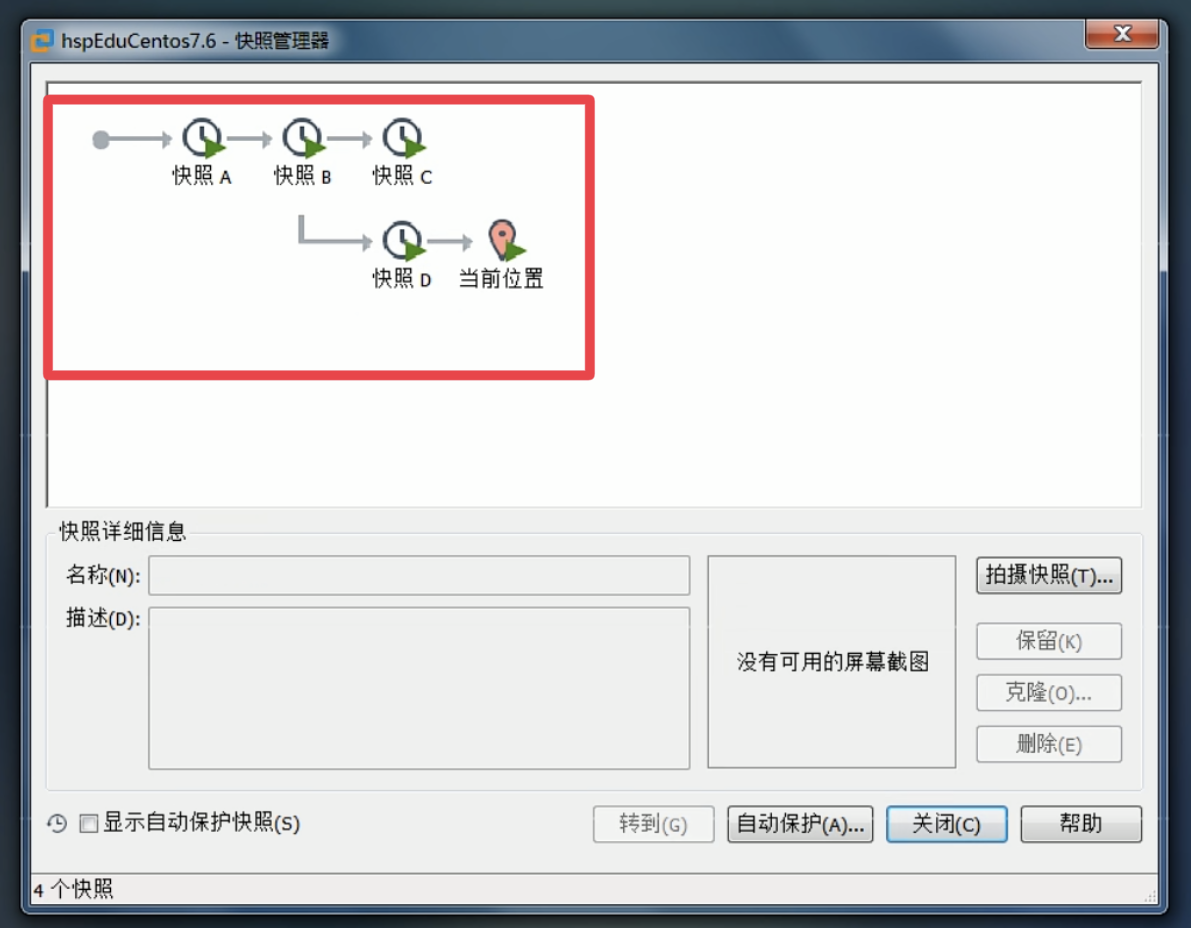
0-虚拟机补充知识
虚拟机克隆 如果想要构建服务器集群,没有必要一台一台的去进行安装,只要通过克隆就可以。 快速获得多台服务器主要有两种方式,分别为:直接拷贝操作和vmware的克隆操作 直接拷贝 将之前安装虚拟机的所有文件进行拷贝࿰…...

如何将电机控制器添加到您的 ROS 机器人
一、说明 如果您正在构建与 ROS/ROS2 一起使用的移动机器人,您需要做的第一件事就是集成电机控制器。电机控制器的目的是接受来自更高级别的软件(如导航堆栈)的消息,并将其转换为驱动电机的信号。它还将从电机的编码器接收信息,以计算机器人的速度和位置。 您可以…...

ChatGPT统计“一到点就下班”的人数
ChatGPT统计“一到点就下班”的人数 1、到点下班 Chatgpt统计各部门F-D级员工到点下班人数占比,是在批评公司内部存在到点下班现象。 根据图片,该占比的计算方法是:最后一次下班卡在17:30-17:40之间,且1-5月合计有40天以上的人…...

Games101学习笔记 - 变换矩阵基础
二维空间下的变换 缩放矩阵 缩放变换: 假如一个点(X,Y)。x经过n倍缩放,y经过m倍缩放,得到的新点(X1,Y1);那么新点和远点有如下关系,X1 n*X, Y1 m*Y写成矩阵就是如下…...

Ubuntu18.04未安装Qt报qt.qpa.plugin could not load the Qt platform plugin xcb问题的解决方法
在Ubuntu 18.04开发机上安装了Qt 5.14.2,当将其可执行程序拷贝到另一台未安装Qt的Ubuntu 18.04上报错:拷贝可执行程序前,使用ldd将此执行程序依赖的动态库也一起拷贝过去,包括Qt5.14.2/5.14.2/gcc_64/plugins目录系的platforms目录…...

GPT4ALL私有化部署 01 | Python环境
进入以下链接: https://www.python.org/downloads/release/python-3100/ 滑动到底部 选择你系统对应的版本,如果你是win,那么大概率是win-64bit 有可能你会因为网络的问题导致下载不了,我提供了 链接 接着只需要打开 等待…...
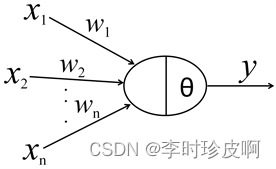
GPT-AI 使用的技术概览
ChatGPT 使用的技术概览 智心AI-3.5/4模型,联网对话,MJ快速绘画 从去年 OpenAI 发布 ChatGPT 以来,AI 的能力再次惊艳了世人。在这样的一个时间节点,重新去学习相关技术显得很有必要。 ChatGPT 的内容很多,我计划采用…...

NoSQL-Redis持久化
NoSQL-Redis持久化 一、Redis 高可用:1.概述: 二、Redis持久化:1.持久化的功能:2.Redis 提供两种方式进行持久化: 三、RDB 持久化:1.定义:2.触发条件:3.执行流程:4.启动时…...
关于uniapp中的日历组件uni-calendar中的小红点
关于uniapp中的日历组件uni-calendar中的小红点 如果你使用过uni-calendar组件,可能你觉得这个小红点有点碍眼,但是官方给定的日历组件uni-calendar中如果你想要在某一天上添加一些信息例如:价格,签到,打卡之类,只要标…...

【Nodejs】Node.js简介
1.前言 Node 的重要性已经不言而喻,很多互联网公司都已经有大量的高性能系统运行在 Node 之上。Node 凭借其单线程、异步等举措实现了极高的性能基准。此外,目前最为流行的 Web 开发模式是前后端分离的形式,即前端开发者与后端开发者在自己喜…...
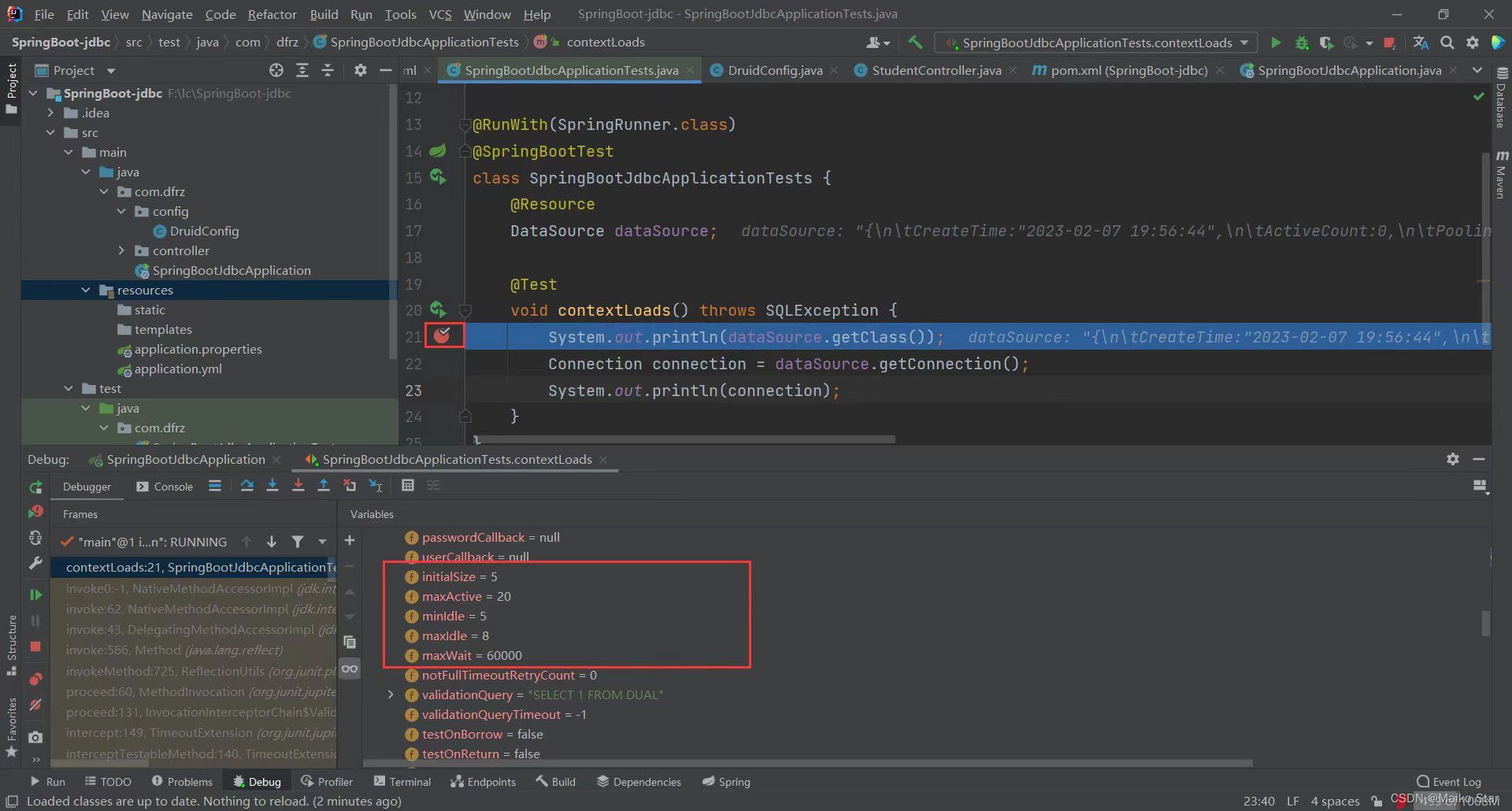
SpringBoot整合Druid
在Spring Boot中整合Druid时,需要导入Druid和JDBC的相关依赖,但不需要额外导入单独的JDBC包。 Druid是一个用于数据库连接池和监控的开源框架,它已经包含了对JDBC的实现。因此,当你导入Druid的依赖时,它已经包含了对J…...
mysql(二)SQL语句
目录 一、SQL语句类型 二、数据库操作 三、数据类型 四、创建 五、查看 六、更改 七、增、删、改、查 八、查询数据 一、SQL语句类型 SQL语句类型: DDL DDL(Data Definition Language,数据定义语言):用于…...

Unity自定义后处理——Tonemapping色调映射
大家好,我是阿赵。 继续介绍屏幕后处理,这一期介绍一下Tonemapping色调映射 一、Tone Mapping的介绍 Tone Mapping色调映射,是一种颜色的映射关系处理,简单一点说,一般是从原始色调(通常是高动态范围&…...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...

基于matlab策略迭代和值迭代法的动态规划
经典的基于策略迭代和值迭代法的动态规划matlab代码,实现机器人的最优运输 Dynamic-Programming-master/Environment.pdf , 104724 Dynamic-Programming-master/README.md , 506 Dynamic-Programming-master/generalizedPolicyIteration.m , 1970 Dynamic-Programm…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...