大模型,开源干不掉闭源
开源大模型对闭源大模型的冲击,变得非常猛烈。
今年3月,Meta发布了Llama(羊驼),很快成为AI社区内最强大的开源大模型,也是许多模型的基座模型。有人戏称,当前的大模型集群,就是一堆各种花色的“羊驼”。
而就在前些天,Meta又推出了免费可商用版本的“羊驼2号”——Llama2,据说性能比肩GPT-3.5。

这在整个大模型圈都是非常炸裂的。
我们知道,各个互联网、科技公司都在竞相训练、推出自己的大模型,投入了大量的计算资源和成本,如果不能有效的完成商业化,那么这些大模型就很难回收成本,后续的迭代、更新、升级都成问题,不仅研发企业会亏个底掉,更苦恼的大概就是“前功尽弃”的用户了。
而现在有了自由开放强大的开源大模型,谁还愿意给闭源大模型送钱呢?
还真的有。
开源是大势所趋,但闭源大模型依然有其存在意义和商业价值。按照目前的AI产业落地经验来看,用好大模型,还是得靠闭源。
今天我们就来聊聊这个问题,到底是谁,需要闭源大模型?
到产业去,到产业去
大模型的商业化终点是产业,想必已经是不用过多解释的共识了。
前不久,我参加某一个国产大模型的内部沟通会,对方高层就明确表示,自己全部用的是闭源代码,并且坚持走闭源路线,就是考虑到训练大模型与行业伙伴合作,其中很多隐私数据是不方便开源的。
见一斑可窥全豹,至少在短期内,大模型走向产业,落地还是要靠闭源。
模型方面,闭源大模型的质量更高。
就拿目前最能打的Llama 2为例,Meta 将 Llama 2 70B 的结果,与闭源模型进行了比较,结果在 MMLU 和 GSM8K 上接近 GPT-3.5,但在编码基准上,还存在显著差距,不少数据在多样性和质量方面有所欠缺。
当然,开源大模型的优化迭代速度很快。但开源的本质和“有性繁殖”很像,就是通过大量繁殖和变异,如同开篇那张“羊驼集群”一样,面对不确定的未来,借助进化的“优胜劣汰”,让最优质的后代持续涌现。所以,开源软件的分支多,对用户来说,这个选择的成本是很高的,加上开发人员众多,版本控制是一个问题。
安全性方面,闭源大模型的可靠性更高。
开源大模型要遵守开源协议,商业使用需要获得授权,海外开源大模型也要受到属地管辖,github就曾封禁俄罗斯开发者账号。使用海外开源大模型开发产品,供应链的风险,是客观存在的。
那么,使用国产开源大模型呢?安全性得到保障,但从商业角度看,很多客户,如大型政企,也非常看重大模型在业务上的可靠性,采购时往往需要大公司的品牌背书。一方面研发投入更大,口碑更高;另一方面,万一大模型生成不当,导致商业损失或商誉问题,使用闭源大模型可以问责服务商,使用开源大模型总不能找全球开发者算账吧?
比如大模型创业公司Huging Face,为客户提供AI咨询,是开源社区的台柱子,表示有大量客户希望把自己的私有数据/专业数据用来训模型,并不想把这些数据给到 OpenAl。

产业化方面,闭源大模型的长期服务能力更强、更可用。
大模型落地,并不是接入API、塞进数据、调参优化就结束了。作为一种新兴技术,大模型与业务场景的融合,还有非常多挑战。比如大模型需要通过蒸馏压缩,减小模型规模,才能在端侧部署,很多企业根本没有这类专业人才。
再比如,大模型与业务结合,需要产品、运营、测试工程师等多种角色共同参与,这些服务能力是以coder为主的开源团队,所很难提供的。此外,大模型的长期应用,算力、存储、网络等配套都要跟上,开源社区无法帮助用户“一站式”解决这些细节问题。
还有数据隐私顾虑,大模型是不能直接为产业所用的,还要通过专有场景数据进行优化,而这些数据训练完的模型会被开源开放出去,让企业顾虑重重。
我们曾采访过一个智慧医疗研发团队,对方表示,大量医疗数据分布在各大医院、研究机构,又涉及患者隐私,大家对于把数据拿出来共同训练一个行业模型,都存在顾虑。一方面是安全得不到保障,另一方面是自己的数据质量高,但从中得不到恰当的回报,和其他数据质量低的机构一样,很难协调。在开源大模型的共建中,如何得到数据、把握配方、确定各方贡献,还存在很多难题。
开源大模型需要平衡技术创新自由和版权收益之间的冲突,而使用闭源大模型就没有这方面的麻烦,数据和模型的所有权、使用权都很清晰,牢牢掌握在企业自己手里。
可以说,目前开源大模型还无法达到实际的业务需求。而开源大模型使用者和ISV集成商,是需要获得商业回报的,如果开源大模型不可商用、效果不好、很难赚钱,那么即使免费,企业也会慎重考虑要不要投入人来开发。
所以,未来一段时间,闭源依然是大模型落地产业的热门选择。
到群众去,到群众去
可能有人不理解了,开源免费商用,大家都能用上白菜价的大模型了,对开发者和企业用户多友好,你怎么还说闭源好?是不是为一门心思赚钱的大厂站台?
非也。
但凡了解开源,都会支持开源。但凡支持开源,都会关注开源的商业化。
中国科学院梅宏院士曾说过,开源以理想主义为源起,以商业化为蓬勃助力,是开放创新的典范。没有商业化,不可能有开源。
所以,开源也好,闭源也好,谁能更早“可商用”,谁就更有未来。这一点上,闭源大模型可能更占优势,毕竟有底气闭源的厂商,还是有两把刷子和研发家底儿的。
那么,开源大模型的优势在哪里呢?如果说闭源大模型要到产业去,那么开源大模型就要到群众中去,主打一个人多力量大。

(LeCun认为Llama-v2会改变LLM的市场格局)
开源大模型不同于传统开源软件,把源代码放上去,然后全球开发者来贡献代码就完了。大模型的协同共建,更多体现在社区繁荣,大家一起把模型做优化、数据做丰富、工具做完善、应用做全面……
这时候,开源模式能够带来几个好处:
1.技术创新。开源社区可以汇聚广大科技企业、研究机构和开发者,对模型进行优化、改进、加速迭代,让模型技术和配套数据集、应用工具等,变得丰富、高质,从而保持领先。
2.人才争夺。大模型作为新兴技术,人才紧缺,通过开源社区吸引全球优秀人才做贡献,加速大模型升级,能够拉开差距。有竞争才有压力,所以LLama 2发布之后,很快传出OpenAI也开始考虑半年内开源GPT-3.5的消息,开发者们有福了。
3.生态合拢。目前各行各业的IT解决方案和数字化转型,大量使用开源技术和应用,建设大模型开源生态,让IT人才和企业使用相关技术,对于后期的商业化非常有帮助。比如OpenAI 的合作伙伴/投资方微软,这次也选择成为Llama 2 的首要合作伙伴,支持个人开发者和中小公司以最低成本调用Llama 2,这对azure无疑是一大利好。
不是所有开源大模型都能成功,生态是关键的护城河。
夹心饼干,向何处去?
就像手机操作系统的 iOS 与 Andriod,开源与闭源的竞争,并不是某一个领域打的“你死我活”,而是各自走出一条差异化的道路,迎来自己的天地。大模型也是如此。
闭源大模型开门迎客,开源大模型红红火火,大家都有光明的未来。
既然如此,为什么还有专家认为,Llama 2开源对开源来说是一个巨大的飞跃,但对闭源的大模型公司是一个巨大打击?
究竟打击了谁?
答案应该是,既不甘心只做应用层、又没能力卷过大厂的基础大模型厂商。
谷歌研究人员曾发文说,因为有开源社区,我们(Google和OpenAI)没有护城河。但是,OpenAI还有GPT-4这样的闭源大模型作为杀手锏,只有被开源逼急了的情况下,才考虑把GPT-3.5开源,这里面是有技术代差的。而且GPT-3.5开源只透露了口风,具体进展还是未知数。
所以,这类头部科技厂商和云巨头,如海外的谷歌、OpenAI,国内的BATH,卡、钱、人才、数据、市场认知度、客户基础都有优势,走闭源路线来完成大模型商业化、产业化是有一定先发优势和壁垒的。
这就苦了那些一心想训基础通用大模型的二三线厂商了。
此前,全球大小科技公司和各类科研机构,一拥而上训基础大模型,比如某些机器视觉AI独角兽,不小心就成了基础层和应用层之间的“夹心饼干”。
实力上打不过GPT,成本上打不过Llama,训出来的基础通用大模型,还没等到正式开放商用,就已经过时了,注定是明日黄花。市场上拼不过巨头,开放度不如开源社区,几乎不可能收回高昂的开发成本。
趁早放弃死磕大模型,或许才是明智选择。
比如国内某AI公司的大模型,此前私有化报价是一年30万,随后就宣布对学术研究完全开放,获得授权可免费商用。做大模型开源社区,也有商业化的可能(如Linux/ Android/红帽),同时也能避免跟头部的通用大模型的“硬碰硬”。
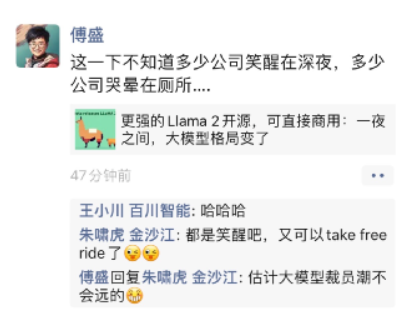
(知名投资人关于Llama2开源的讨论截图/来自网络)
对于应用层开发者和ISV集成商企业来说,用好产业接受度高的闭源大模型,可以更快让客户接受,更适合私有化定制部署的业务需求,更快完成商业落地和收入增长。
对于AI创业公司来说,开源直接就能用,避免重复造轮子,可能是更理想、低成本试错的商业化手段,“报团取暖”贡献大模型开源项目,推动大模型开源社区的发展,也会获得社区回馈和商业回馈。
中国大模型发展到高水平,既要有全球领先的闭源大模型打头阵,也要有具备世界影响力的大模型开源社区。
道阻且长,行则将至。不妨用建设性心态,来看待开源闭源之争,给国产闭源大模型一些信心,也给国內开源社区一些鼓励和支持。
相关文章:
大模型,开源干不掉闭源
开源大模型对闭源大模型的冲击,变得非常猛烈。 今年3月,Meta发布了Llama(羊驼),很快成为AI社区内最强大的开源大模型,也是许多模型的基座模型。有人戏称,当前的大模型集群,就是一堆各…...

Redis 九种数据类型的基本操作
一、redis9种数据类型的基本操作 ①key操作 #查找所有的key 127.0.0.1:6379> keys * 1) "pop" 2) "mylist" 3) "lpl" 4) "myset" #设置key的过期时间 返回1表示执行成功,0表示失败,出现问题 127.0.0.1:6379…...

爬取微博热搜榜并进行数据分析
设计方案 爬虫爬取的内容 :爬取微博热搜榜数据。 网络爬虫设计方案概述 用requests库访问页面用get方法获取页面资源,登录页面对页面HTML进行分析,用beautifulsoup库获取并提取自己所需要的信息。再讲数据保存到CSV文件中,进行…...
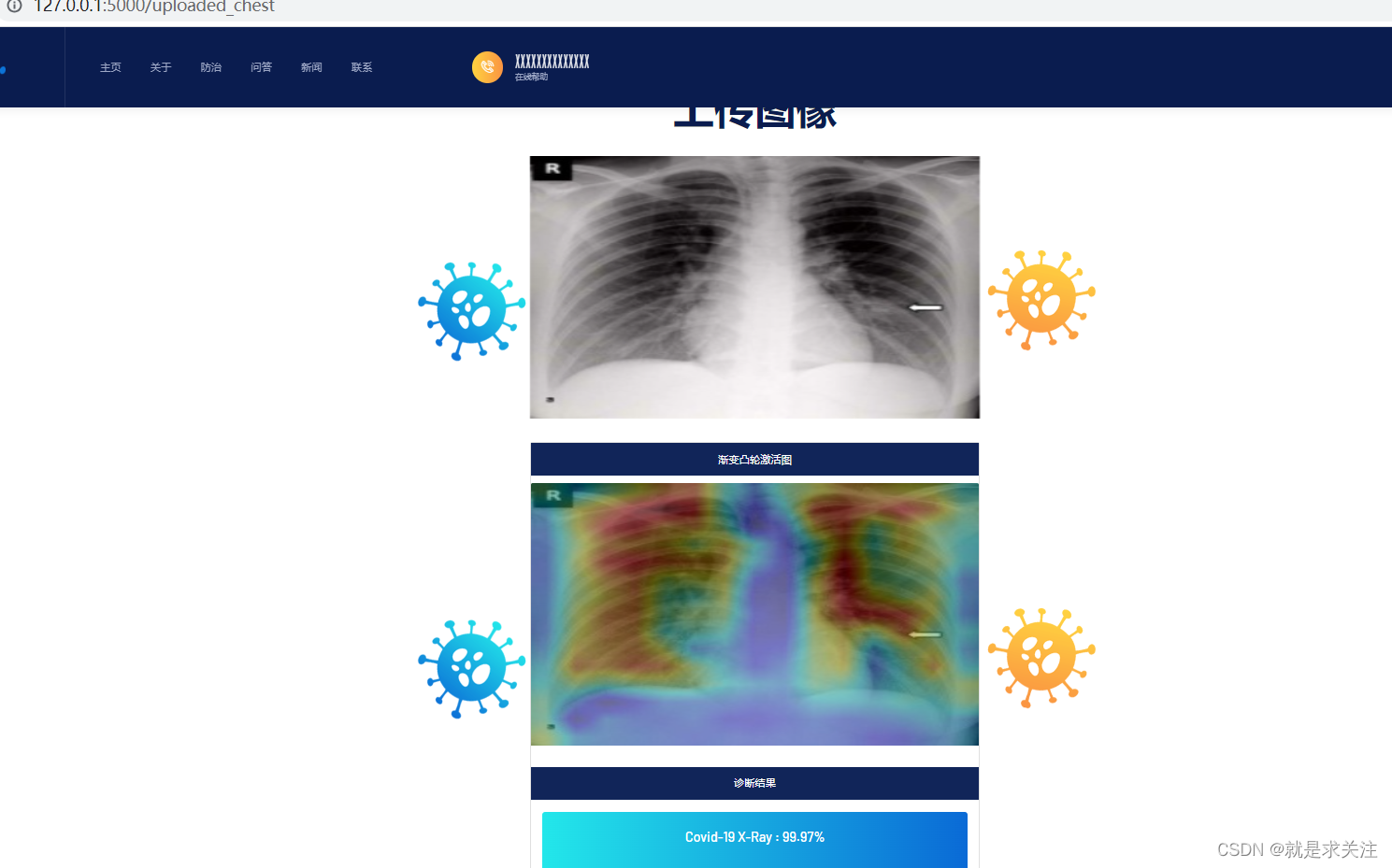
基于深度神经网络的肺炎检测系统实现
一、说在前面 使用AI进行新冠肺炎图像诊断可以加快病例的诊断速度,提高诊断的准确性,并在大规模筛查中发挥重要作用,从而更好地控制和管理这一流行病。然而,需要强调的是,AI技术仅作为辅助手段,最终的诊断决…...

C# LINQ和Lambda表达式对照
C# LINQ和Lambda表达式对照 1. 基本查询语句 Linq语法: var datafrom a in db.Areas select a ; Lamda语法: var datadb.Areas; sql语法: SELECT * FROM Areas2. 简单的WHERE语句 Linq语法: var datafrom a in db.orderI…...
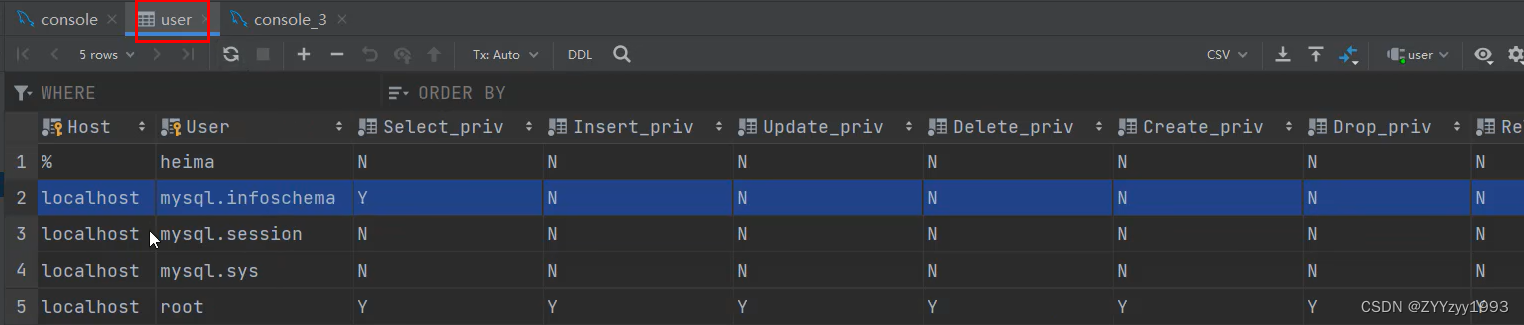
二、SQL-6.DCL-1).用户管理
一、DCL介绍 Data Control Language 数据控制语言 用来管理数据库 用户、控制数据库的 访问权限。 二、语法 1、管理用户 管理用户在系统数据库mysql中的user表中创建、删除一个用户,需要Host(主机名)和User(用户名࿰…...

ElasticSearch学习--数据聚合
介绍 数据聚合可以帮助我们对海量的数据进行统计分析,如果结合kibana,我们还能形成可视化的图形报表。自动补全可以根据用户输入的部分关键字去自动补全和提示。数据同步可以帮助我们解决es和mysql的数据一致性问题。集群可以帮助我们了解结构和不同节点…...
PostMan+Jmeter工具介绍及安装
目录 一、PostMan介绍编辑 二、下载安装 三、Postman与Jmeter的区别 一、开发语言区别: 二、使用范围区别: 三、使用区别: 四、Jmeter安装 附一个详细的Jmeter按照新手使用教程,感谢作者,亲测有效。 五、Jme…...
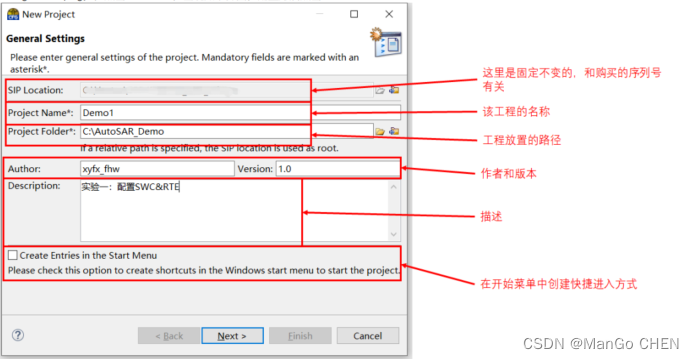
AutoSAR系列讲解(实践篇)7.4-实验:配置SWCRTE
注意: 实验篇是重点,有条件的同学最好跟着做一遍,然后回头对照着7.1-7.3理解其配置的目的和意义。实验下篇将在7.7节中继续做 一、实验概览 1、实验目的 通过本次实验,主要是让大家对Dev的配置有一个全流程的学习。这里会用到前两节的内容,将其串联起来,让大家能完整的…...

腾讯云内存型CVM服务器MA3、M6、M6ce和M5处理器CPU说明
腾讯云内存型CVM服务器CPU处理器大全,CVM内存型MA3、内存型M6、安全增强内存型M6ce、内存型M6p、内存型M5、MA2、M4、M3、M2、M1处理器主频、CPU性能性能大全说明,腾讯云内存型云服务器具有大内存的特点,适合高性能数据库、分布式内存缓存等需…...

集睿致远推出CS5466多功能拓展坞方案:支持DP1.4、HDMI2.1视频8K输出
ASL新推出的 CS5466是一款Type-C/DP1.4转HDMI2.1的显示协议转换芯片,,它通过类型C/显示端口链路接收视频和音 频流,并转换为支持TMDS或FRL输出信令。DP接收器支持81.Gbp s链路速率。HDMI输出端口可以作为TMDS或FRL发射机工作。FRL发射机符合HDMI 2.1规范…...
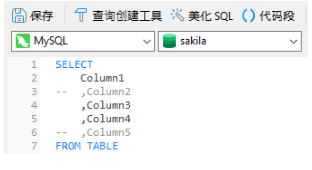
SQL中为何时常见到 where 1=1?
你是否曾在 SELECT 查询中看到过 WHERE 11 条件。我在许多不同的查询和许多 SQL 引擎中都有看过。这条件显然意味着 WHERE TRUE,所以它只是返回与没有 WHERE 子句时相同的查询结果。此外,由于查询优化器几乎肯定会删除它,因此对查询执行时间没…...

React AntDesign表批量操作时的selectedRowKeys回显选中
不知道大家是不是在AntDesign的某一个列表想要做一个批量导出或者操作的时候,发现只要选择下一页,即使选中的ids 都有记录下面,但是就是不回显 后来问了chatGPT,对方的回答是: 在Ant Design的DataTable组件中…...

anydesk远程控制,主动连接。
目标 远程控制目标电脑,且无需对方同意,并且可以控制目标电脑开关机。 实现 目标电脑和己方电脑均安装anydesk。目标电脑取消开机密码。打开目标电脑的anydesk在设置安全设置中打开为自主访问设置密码。 额外设置 为了让笔记本电脑合盖后仍能被控制…...
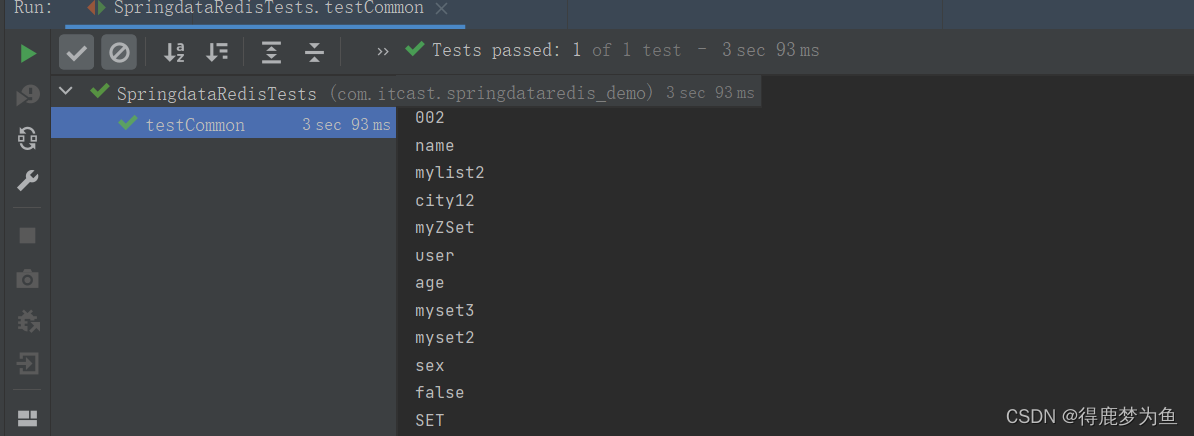
Spring Data Redis操作Redis
在Spring Boot项目中,可以使用Spring Data Redis来简化Redis操作,maven的依赖坐标: <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></…...
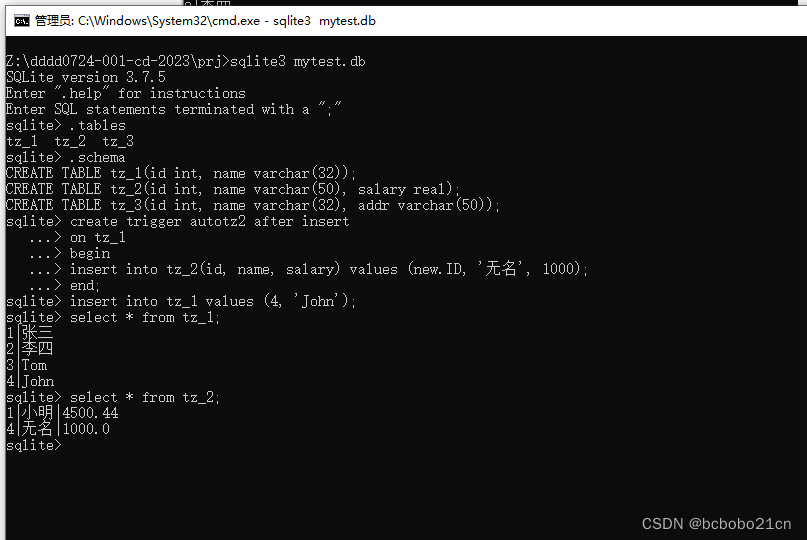
sqlite触发器1
SQLite 的触发器(Trigger)可以指定在特定的数据库表发生 DELETE、INSERT 或 UPDATE 时触发,或在一个或多个指定表的列发生更新时触发。 SQLite 只支持 FOR EACH ROW 触发器(Trigger),没有 FOR EACH STATEM…...

python中——requests爬虫【中文乱码】的3种解决方法
requests是一个较为简单易用的HTTP请求库,是python中编写爬虫程序最基础常用的一个库。 而【中文乱码】问题,是最常遇到的问题,对于初学者来说,是很困恼的。 本文将详细说明,python中使用requests库编写爬虫程序时&…...
)
E. Nastya and Potions(DFS+记忆化搜索)
炼金术士纳斯蒂亚喜欢混合药剂。一共有n种药剂,ci硬币可以买到一种 i 型药剂。 任何一种药剂都只能通过一种方式获得,即混合其他几种药剂。混合过程中使用的药剂将被消耗掉。此外,任何药剂都不能通过一个或多个混合过程从自身获得。 作为一名…...

什么是tcp rst以及什么时候产生?
rst包是仅在header control bits设置rst的空payload包,用于强制关闭tcp连接。常在以下场景发送 远程主机没有监听该端口 远程主机强迫关闭了一个现有连接。比如服务端进程崩溃后重启会向之前连接发送rst 相比于四次挥手的fin,rst是在异常情况下的无条…...
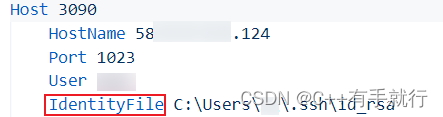
Visual Studio Code配置免密远程开发环境
VSCode安装插件 要是想连接远程服务器,先在本地安装下面的插件(红色圈起来的需要装) 连接远程服务器 配置服务器信息 保存然后再连接,输入密码,如果能连接上说明是没问题的,下面开始免密登录 免密配置 客…...

Binder Hook机制深度解析:understand-plugin-framework跨进程通信黑科技
Binder Hook机制深度解析:understand-plugin-framework跨进程通信黑科技 【免费下载链接】understand-plugin-framework demos to help understand plugin framwork 项目地址: https://gitcode.com/gh_mirrors/un/understand-plugin-framework 在Android开发…...
)
【PythonAI】2.1.2 数据处理的瑞士军刀:初识Pandas库(2. 快速入门示例)
#pandas_dataframe.py import pandas as pd# 创建DataFrame data {姓名: [张三, 李四, 王五, 赵六],年龄: [20, 21, 19, 22],专业: [计算机, 会计, 电商, 物流],成绩: [85.5, 92.0, 78.5, 88.0] }df pd.DataFrame(data)# 查看数据 print(df.head(2)) # 查看前2行 print(…...

将软件需求“翻译”成硬件语言:一份让设计团队无法拒绝的黄金文档
该文章同步至公众号OneChan ——如何用硬件工程师的思维,赢得他们的尊重与代码 你提交的不是一份“需求清单”,而是一份“缺陷预防方案”和“效率提升指南”。 引言:一次代价高昂的“翻译失败” 数年前,我参与一个关键IP的开发。…...

Python新年倒计时:用代码打造节日氛围的创意实践
1. 为什么用Python做新年倒计时? 每到年底,朋友圈就会被各种新年倒计时刷屏。你有没有想过用代码打造一个专属的倒计时工具?Python凭借其简洁的语法和丰富的库,特别适合这类创意编程项目。 我去年就用Python给团队做了个新年倒计时…...

从EDFA到SOA:Optisystem放大器库全解析,教你如何根据仿真场景选对光放类型
从EDFA到SOA:Optisystem放大器库全解析与选型实战指南 在光通信系统仿真中,放大器选型直接影响仿真结果的准确性和可信度。Optisystem作为行业标准工具,其Amplifiers Library提供了从传统EDFA到前沿SOA的完整器件模型,但如何根据具…...
实现 + 全排列(回溯经典)| 面试必刷模板题)
算法双杀:Trie(前缀树)实现 + 全排列(回溯经典)| 面试必刷模板题
目录 一、Trie(前缀树):字符串查询的效率神器 什么是前缀树? 核心设计 完整实现代码 关键解析 二、全排列:回溯算法入门经典 题目描述 核心思路(回溯法) 完整实现代码 关键解析 三、…...
)
2-4 避免踩坑:AI Agent架构的四大反模式(从百万美元事故看AI Agent设计的常见陷阱与规避策略)
过去两年,AI Agent项目从井喷式爆发到大量失败,暴露出许多共性问题。 通过分析这些失败案例,我总结了四类最常见的架构反模式(Anti-Patterns)。它们看似是捷径,实则是通往维护地狱的陷阱。 四大反模式架构对比 #mermaid-svg-OSytWDUbXJl85vKk{font-family:"trebuc…...

RAG系统提示词重构核心要点,深度拆解核心问题架构与应对方案,实战演练
将针对企业级应用优化的Prompt工程方法论迁移至RAG(检索增强生成)系统时,需要进行系统性的范式重构。这并非简单的指令复用,而是涉及从单体模型指令到“检索-生成”双阶段协同的体系升级。 问题解构与核心挑战 企业级RAG系统引入…...

OpenClaw+Phi-3-vision-128k-instruct低成本方案:自建多模态助手避坑指南
OpenClawPhi-3-vision-128k-instruct低成本方案:自建多模态助手避坑指南 1. 为什么选择本地部署多模态助手 去年我尝试用商业API搭建个人知识管理助手时,发现两个痛点:一是处理PDF和图片的token消耗像流水一样快,二是长文档分析…...

怎样高效激活Windows和Office:KMS_VL_ALL_AIO智能激活脚本完整指南
怎样高效激活Windows和Office:KMS_VL_ALL_AIO智能激活脚本完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO KMS_VL_ALL_AIO是一款强大的智能激活脚本,专门用于Win…...