极速查找(2)-算法分析
篇前小言
本篇文章是对查找(1)的续讲
线性索引查找
线性索引查找(Linear Index Search)是一种基于索引的查找算法。它在数据集合中创建一个索引
结构,然后使用该索引结构来加快对目标元素的查找。
线性索引是一种在数据集合中创建索引结构以加速查找的方法。它适用于较大的数据集合,可以在常数
时间内访问索引项并快速定位到目标元素所在的区域。
概念解读
线性索引的核心思想是将数据集合分割成多个块,并为每个块创建索引项。索引项通常包含块的起始位
置、结束位置以及块中的一些附加信息,比如最大值、最小值等。通过构建索引表,每个索引项记录了数据集合中一段连续块的信息。索引表的组织方式可以是一个数
组、链表或其他数据结构。当需要查找目标元素时,首先根据目标元素与索引项进行比较,确定目标元素可能出现在哪个块中。然
后,在对应的块范围内进行线性查找,直到找到目标元素或确认其不存在。使用线性索引可以节省查找时间,因为它将数据集合划分为块,首先在索引表中进行快速定位,然后在
目标块中进行查找。相比于遍历整个数据集合,线性索引可以大大减少查找的时间复杂度。然而,构建和维护索引需要额外的空间和时间成本。当数据集合发生变化时,如插入、删除等操作,索
引可能需要被更新,这可能导致索引失效或者增加更新的成本。线性索引是一种权衡索引结构,它在某些情况下可以提供较好的查询性能,但也需要考虑索引的开销和
维护的复杂性。在实际应用中,可以根据数据集合的大小、查询频率和更新频率等因素来选择适当的索
引策略。
稠密索引
概念
稠密索引(Dense Index)是线性索引的一种形式,它在索引表中为数据集合每个数据项创建一个索引
项,即每个数据项都有一个对应的索引项。稠密索引中的每个索引项通常包含以下信息:
键值(Key):对应数据项的键值。
指针(Pointer):指向数据项在物理存储中的位置,可以是数据的物理地址、页码或盘区号等。
特点
1、每个数据项都有一个对应的索引项,因此索引表的大小与数据集合的大小相同。
2、索引项按照键值进行排序,以支持快速的二分查找。
3、查询时,可以直接通过二分查找在索引表中定位到对应的索引项,然后使用索引项的指针找到相应的数据项。
优点
可以快速定位到指定键值的数据项,查找性能高。因为索引项与数据项是一一对应的,所以不需要进行
额外的查找或数据项的扫描。
缺点
1、索引表的大小与数据集合的大小相同,需要占用额外的存储空间。当数据集合较大时,索引表可能会占用大量的存储空间。
2、插入、删除数据项时,需要更新索引表。这可能导致频繁的索引维护操作,影响了性能。
3、索引项的排序需要一定的时间成本,尤其是在数据集合进行频繁的插入和删除操作时。
4、稠密索引适用于具有较小数据集合的情况,对于静态数据集合或者数据集合更新频率较低的情况,
稠密索引可以提供较好的查找性能。但在动态数据集合或频繁更新的情况下,稠密索引的更新成本可能
会变得很高。
实际应用
数据库管理系统:在数据库中,数据表中的主键通常会使用稠密索引进行管理。稠密索引可以快速定位
到具有特定主键值的数据记录,提高查询性能。数据库还可以使用稠密索引来优化其他常用的查询操作,
如范围查询、排序和连接操作等。文件系统:在文件系统中,可以使用稠密索引来管理文件的索引和位置信息。文件系统可以通过稠密索
引加快文件的定位和访问,提高文件系统的性能。图书索引:在图书馆或文档管理系统中,可以使用稠密索引来管理图书的关键词索引。稠密索引可以快
速定位到包含特定关键词的书籍,方便用户进行检索和访问。网络搜索引擎:搜索引擎可以使用稠密索引来管理互联网上的网页索引。稠密索引可以根据关键词快速
定位到具有相关内容的网页,提高搜索引擎的查询效率。文件或数据存储系统:在文件或数据存储系统中,可以使用稠密索引来加速数据的检索和访问。通过使
用稠密索引,可以快速定位和读取磁盘上的数据块或页面,提高读取和写入操作的性能。还可以应用于任何需要快速定位和检索数据的应用程序和系统。然而,需要注意的是,在使用稠密索引
时需要权衡存储空间的利用和维护索引的成本,以确保索引的性能和效益相匹配。
分块索引
概念
分块索引(Block Index)是线性索引的一种形式,它在数据集合中将数据分成多个块,并为每个块
创建一个索引项。与稠密索引不同,分块索引并不要求每个数据项都有对应的索引项,而是以块为单
位进行索引。
特点
减少索引表大小:相比于稠密索引,分块索引的索引表大小通常更小。因为不是每个数据项都有对应的
索引项,而是以块为单位进行索引。这减少了索引表的存储空间需求,并可以减少对额外存储空间的占
用。块级别的排序和查找:分块索引中的索引项按照块的顺序进行排序,而不是按照每个数据项的顺序。这
种排序方式使得可以在块级别上进行更快的查找,加速了查询操作。通过在确定的目标块中进行线性查
找,可以快速找到目标值,而不需要遍历整个数据集合。范围查询优化:分块索引对于范围查询具有优化的效果。由于索引项按照块的顺序排序,可以通过比较
目标范围的起始值和结束值与索引项的最大值和最小值来确定目标块的范围。然后,在确定的范围内进
行线性查找,降低了范围查询的时间复杂度。适应动态数据集合:当数据集合发生插入或删除操作时,分块索引相对于稠密索引具有更好的适应性。
只需要更新受影响的块和相关索引项,而不需要更新整个索引表。这降低了索引的维护成本,并提供了
更好的性能。可调节块大小:分块索引允许调整块的大小以适应不同的需求。较小的块大小可以提供更精细的索引,
更快的查询速度,但会增加索引表的大小。较大的块大小可以减少索引表的规模,但可能导致块内的
线性查找时间增加。根据具体应用的需求,可以根据数据集合的大小、查询模式和硬件资源等因素来
选择合适的块大小。
优点
减少索引表大小:相对于稠密索引,分块索引的索引表大小通常更小。由于只为每个块创建一个索引项,
而不是每个数据项,因此可以节省大量存储空间,尤其是当数据集合非常大时。提高查询性能:分块索引通过按照块的顺序对索引项进行排序,可以在块级别上进行更快的查找。在确
定目标块后,只需要在该块内进行线性查找即可找到目标值。这减少了查找过程中的比较次数和访问次
数,从而提高了查询性能。优化范围查询:由于索引项按照块的顺序排序,分块索引对范围查询有优化效果。通过比较目标范围的
起始值和结束值与索引项的最大值和最小值,可以确定目标块的范围。然后,只需在确定的块内进行线
性查找,避免了不必要的比较和访问。适应动态数据集合:分块索引对于动态数据集合更具适应性。当发生数据插入或删除操作时,只需更新
受影响的块和相关索引项,无需修改整个索引表。这样可以减少索引维护的开销,并提供更好的数据库
性能和响应时间。可调节块大小:分块索引允许调整块的大小以适应不同的需求。较小的块大小可以提供更精细的索引,
减少查找时间和空间占用。较大的块大小可以减少索引表的规模,适用于具有大块数据和较低查询频率
的场景。通过根据数据集合特征和查询模式选择合适的块大小,可以优化索引的性能和存储效率。
缺点
块内线性查找:在确定目标块后,需要在该块内进行线性查找。对于大块或者块内数据分布不均匀的情
况,线性查找时间可能较长,导致查询性能下降。相比于其他索引结构如B树或哈希索引,分块索引在
这方面的性能表现较差。块内数据的顺序性:分块索引要求将数据按块进行划分,并在块内保持一定的顺序性。如果数据分布不
均匀或者动态变化,块内数据的顺序性可能被打乱,导致查找性能下降。索引表的维护:当数据集合发生插入或删除操作时,需要更新索引表。尽管相比于其他索引结构,分块
索引的维护成本较低,但仍然存在一定的开销,特别是当数据插入或删除导致块的分割或合并时。对于点查询的效率:分块索引的主要优化点在于范围查询,对于点查询(即只查询一个特定值)的效率
可能不如其他索引结构高效。块大小的选择:分块索引中块的大小需要根据数据集合特征和查询模式来选择。选择过小的块大小可能
导致索引表过大,增加存储开销;选择过大的块大小可能增加了每个块内的线性查找成本。
实际应用
大规模数据集合:当处理大规模数据集合时,分块索引可以提供较好的存储效率和查询性能。通过将数
据划分为块,并为每个块创建索引项,可以减少索引表的大小并减少查找所需的时间。范围查询频繁的场景:如果应用需要频繁进行范围查询,例如根据时间范围或数值范围进行查询,分块
索引可以提供较好的查询性能。分块索引的块级别排序和范围查询优化可以加速范围查询操作。存储资源有限的环境:在存储资源有限的环境下,分块索引可以帮助降低索引表的大小,从而节省存储
空间。这对于存储密集型应用或者存储资源有限的嵌入式系统特别有价值。需要适应动态数据变化的应用:分块索引对动态数据集合的变化具有较好的适应性。由于只需要更新
受影响的块和相关索引项,而不需要修改整个索引表,分块索引可以提供更高的性能和更快的数据维
护。部分数据访问的场景:当应用仅需要访问数据集合的一部分数据时,分块索引可以提供较好的性能。
通过仅创建和维护需要访问的块的索引项,可以减少不必要的索引开销和占用的存储空间。
倒排索引
概念
倒排索引(Inverted Index)是一种常用的索引结构,用于支持文本搜索和信息检索。与传统索引结
构(如分块索引)不同,倒排索引是基于单词(词项)来建立索引。
特点
逆向索引策略:倒排索引以词项(单词)为索引项,将文档或文本片段与词项进行关联。相对于传统的
正向索引(以文档为索引项),倒排索引采用逆向的索引策略,以支持词项的搜索和访问。快速定位文档:倒排索引使用一个字典结构来存储词项和对应的倒排列表。在搜索过程中,可以快速定
位关键词项,并访问其倒排列表,获得包含该词项的文档或文本片段的信息。支持全文检索:倒排索引是全文检索的关键机制之一。通过查询词项在倒排索引中的倒排列表,可以找
到包含这些词项的文档或文本片段。这使得用户可以通过关键词来快速查找与搜索条件匹配的文本内容。高效的搜索性能:由于倒排索引的数据结构和查询算法的优化,它能够提供高效的搜索性能。通过跳跃
指针、字典压缩、倒排列表的压缩等技术,可以减少查询的时间和存储开销。支持复杂查询操作:倒排索引可以支持复杂的查询操作,如布尔逻辑运算、通配符查询、模糊查询等。
通过将多个词项的倒排列表进行逻辑组合,可以实现与、或、非等复杂查询需求。可扩展性和动态更新:倒排索引具有良好的可扩展性和动态更新性。当有新的文档加入或已有文档发生
变化时,只需更新相关的倒排列表,而无需修改整个索引结构。这使得倒排索引适用于处理大规模文本
集合和频繁变动的数据。
优点
字典结构:倒排索引以词项为索引项,使用一个字典结构来存储词项和对应的文档列表。这使得在文本搜索过程中可以快速定位和访问相关的文档。文本搜索和信息检索:倒排索引可以支持文本搜索和信息检索。通过查询词项对应的倒排列表,可以很快地获取包含该词项的文档或文本片段,从而实现全文检索。高效的搜索速度:倒排索引使用了逆向的索引策略,将词项与文档的关系进行关联,以支持高效的搜索和查询。通过索引结构和倒排列表,可以快速确定包含特定词项的文档。索引压缩和存储效率:倒排索引通常采用压缩技术,以减少索引的存储空间。倒排列表中的文档编号可以使用差分编码、变长编码等技术来降低存储空间。这使得倒排索引适用于处理大规模文本集合。支持复杂查询:倒排索引可以通过布尔逻辑运算和词项的组合,支持复杂的查询操作,如与、或、非等逻辑关系的组合查询。动态更新:倒排索引可以方便地支持文档的插入、删除和更新操作。当文档发生变化时,只需更新相关的倒排列表即可,而不需要修改整个索引结构。
缺点
空间消耗:倒排索引需要存储大量的索引数据结构,包括词项和倒排列表。对于大规模文本集合,倒排
索引需要占用相对较大的存储空间。构建和更新的开销:构建倒排索引需要遍历文本集合,对每个文档进行分词处理,并创建倒排列表。这
涉及到大量的计算和存储操作,因此构建和更新倒排索引需要一定的时间和计算资源。不支持多词项匹配:倒排索引是基于单词(词项)进行索引的,因此在进行搜索时不支持多词项的复杂
匹配。一些复杂的查询需求,如短语匹配或多词项关系匹配,可能需要额外的处理和算法。不支持部分匹配:倒排索引只记录包含词项的文档或文本片段的信息,而不记录词项在文档中的位置。
这使得倒排索引不适合支持部分匹配(如通配符查询)或基于位置的查询需求。不适用于结构化数据:倒排索引主要适用于处理文本数据,对于结构化数据(如数据库)的索引效果可
能不如其他索引结构(如B树索引)。查询性能受词项频率影响:对于频繁出现的词项,倒排索引的查询性能可能较低,因为倒排列表的大小
会增加,查询需要扫描更多的文档。
实际应用
搜索引擎:搜索引擎是倒排索引最为常见的应用场景之一。搜索引擎使用倒排索引构建搜索引擎的索引
库,以支持用户对网页、文档、图片等内容进行关键词搜索,并返回与搜索条件匹配的结果。文本搜索与信息检索:倒排索引被广泛应用于文本搜索和信息检索系统中。通过将词项与文档进行关
联,倒排索引可以实现关键词的全文搜索,并提供快速的检索性能,包括搜索引擎、文档管理系统、
电子图书馆等。大数据分析:倒排索引可以用于大数据分析和文本挖掘。通过建立词项到文档的映射关系,使得对大规
模文本数据进行统计分析、主题建模、词频分布等操作变得更加高效。媒体内容管理:倒排索引可以用于媒体内容管理系统,如音频、视频、图像等。通过分析和索引这些媒
体内容的关键词或描述信息,可以在媒体库中快速搜索和检索相关内容。社交媒体分析:对于社交媒体数据的分析和搜索,倒排索引可以快速定位包含特定关键词的帖子、评
论、用户等内容,实现社交媒体数据的搜索和检索功能。知识图谱和语义搜索:倒排索引可以用于构建知识图谱和语义搜索引擎。通过对知识图谱中的实体和
关系进行索引,可以支持语义相关性搜索和知识图谱推理。
下篇预告
二叉排序树、平衡二叉树
相关文章:
-算法分析)
极速查找(2)-算法分析
篇前小言 本篇文章是对查找(1)的续讲线性索引查找 线性索引查找(Linear Index Search)是一种基于索引的查找算法。它在数据集合中创建一个索引 结构,然后使用该索引结构来加快对目标元素的查找。 线性索引是一种在数…...

flask路由添加参数
flask路由添加参数 在 Flask 中,可以通过两种方式在路由中添加参数:在路由字符串中直接指定参数,或者通过 request 对象从请求中获取参数。 在路由字符串中指定参数:可以将参数直接包含在路由字符串中。参数可以是字符串、整数、…...

网络安全系统教程+学习路线(自学笔记)
一、什么是网络安全 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 无论网络、Web、移动、桌面、云等哪个领域,都有攻与防两面…...

23. 合并 K 个升序链表
题目描述 给你一个链表数组,每个链表都已经按升序排列。 请你将所有链表合并到一个升序链表中,返回合并后的链表。 示例 1: 输入:lists [[1,4,5],[1,3,4],[2,6]] 输出:[1,1,2,3,4,4,5,6] 解释:链表数组…...
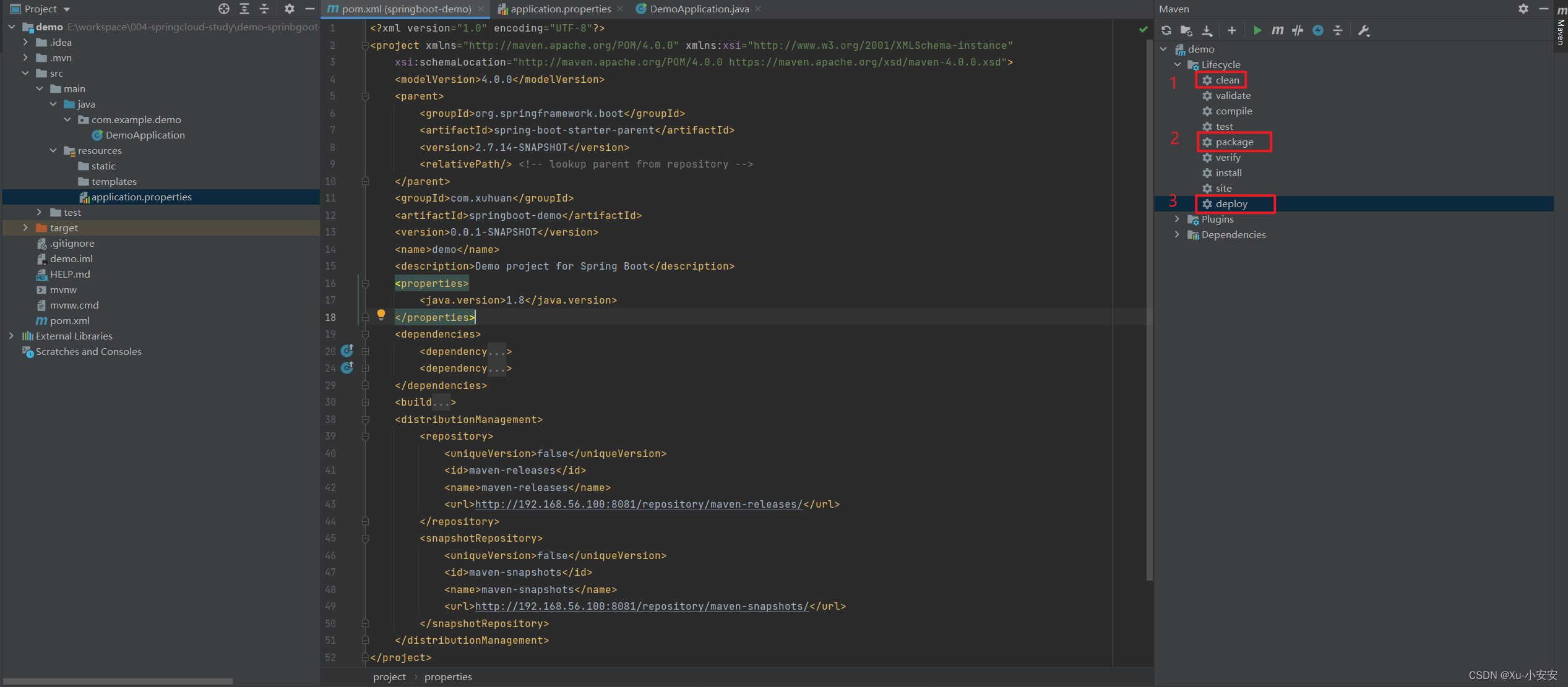
Nexus3部署、配置+SpringBoot项目Demo
Docker部署Nexus 搜索Nexus3镜像:[rootlocalhost ~]# docker search nexus 拉取Nexus3镜像:[rootlocalhost ~]# docker pull sonatype/nexus3 启动Nexus3前查看虚拟机端口是否被占用:[rootlocalhost ~]# netstat -nultp 通过Docker Hub查看安…...
linux下用docker安装mysql
1.mysql Docker镜像 docker pull mysql:[版本号 或 latest]例:docker pull mysql:5.7 2.查看拉取的docker镜像 docker images3.设置 Docker 卷 docker volume create mysql-data列出 Docker 已知的所有卷 docker volume ls4.运行一个 MySQL Docker 容器 docke…...
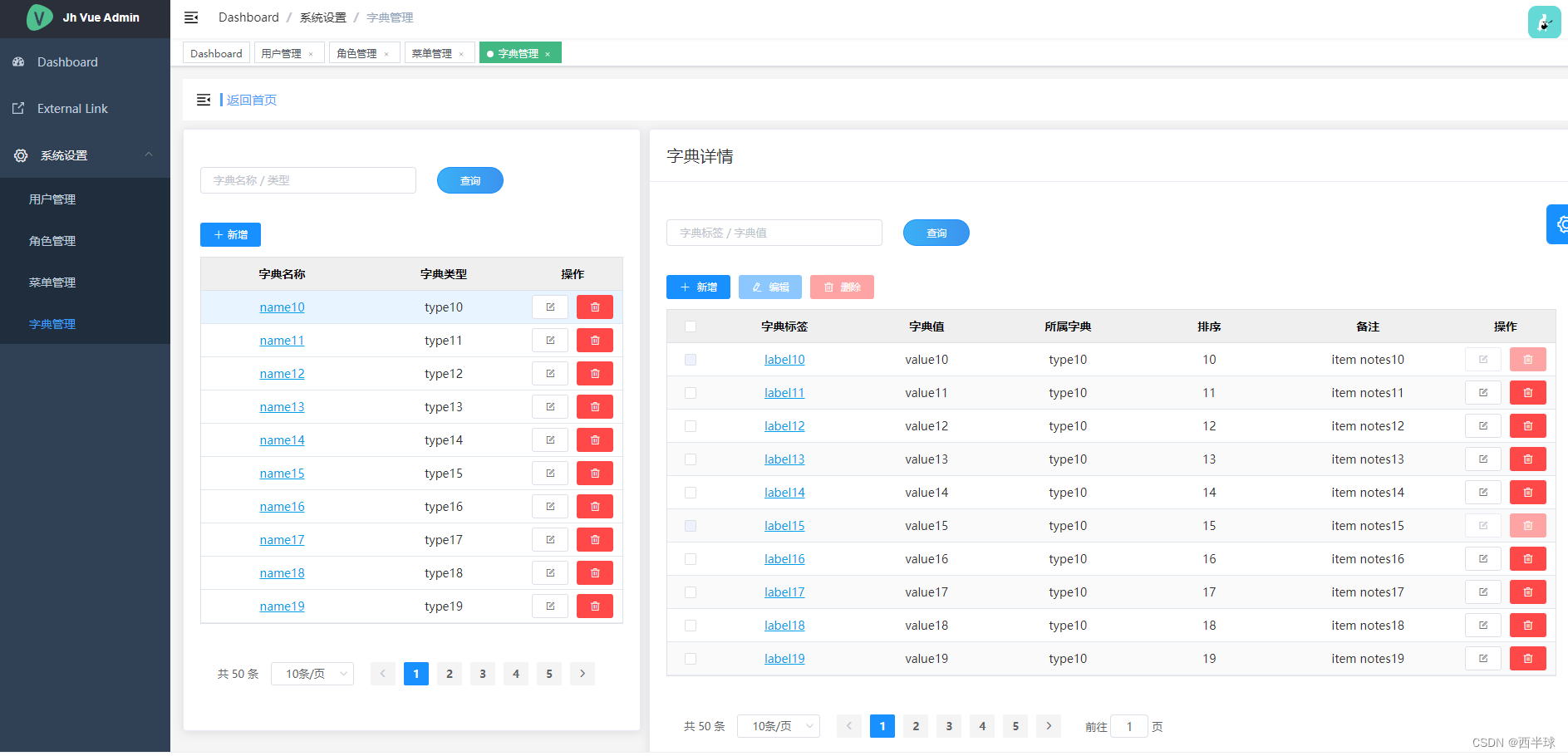
Vue - 可视化用户角色、菜单权限、按钮权限配置(动态获取菜单路由)
GitHub Demo 地址 在线预览 前言 关于动态获取路由已在这里给出方案 Vue - vue-admin-template模板项目改造:动态获取菜单路由 这里是在此基础上添加了系统管理模块,包含用户管理,角色管理,菜单管理,字典管理…...

hive库操作示例
hive库操作示例 1、常规表 创建数据库 CREATE DATABASE mydatabase;使用数据库 USE mydatabase;创建表 CREATE TABLE mytable (id INT,name STRING,age INT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY , STORED AS TEXTFILE;插入数据 INSERT INTO TABLE mytable VALUE…...
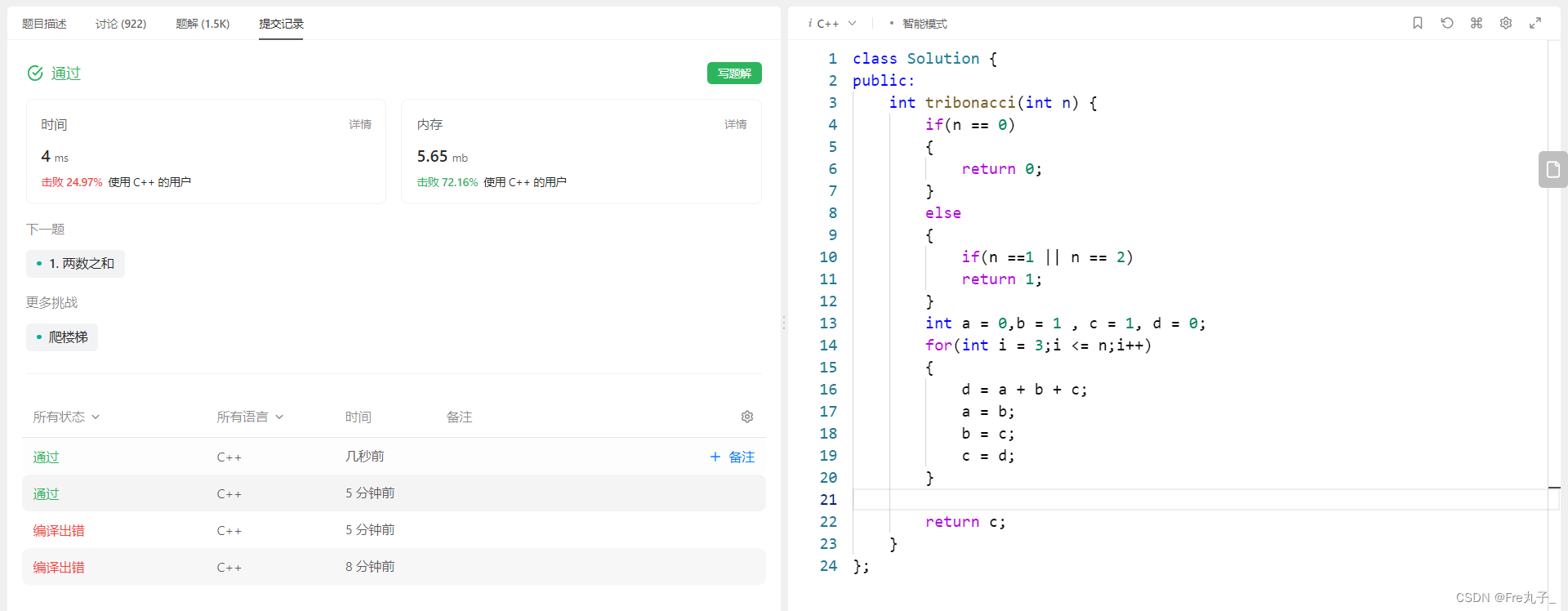
LeetCode第 N 个泰波那契数 (认识动态规划)
认识动态规划 编写代码代码空间优化 链接: 第 N 个泰波那契数 编写代码 class Solution { public:int tribonacci(int n) {if(n 0){return 0;}else{if(n 1 || n 2)return 1;}vector<int> dp(n 1);dp[0] 0;dp[1] 1;dp[2] 1;for(int i 3;i < n;i){dp[i] dp[i-3]…...
)
线程安全问题(内存可见性)
导致的原因 内存可见性问题的出现主要是因为编译器优化多线程导致的 示例代码 package 线程安全问题;import java.util.Scanner;/*** Created with IntelliJ IDEA.* Description:* User: wuyulin* Date: 2023-07-26* Time: 13:49*/ public class Demo2 {private volatile sta…...
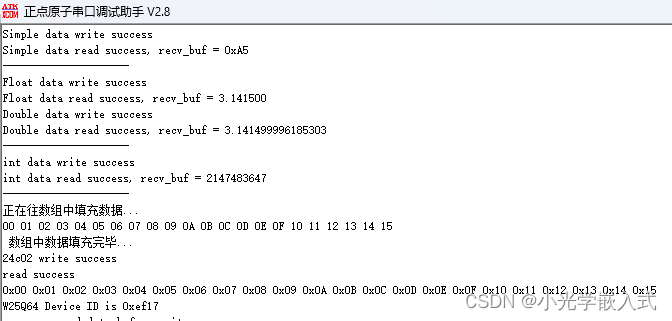
STM32MX配置EEPROM(AT24C02)------保姆级教程
———————————————————————————————————— ⏩ 大家好哇!我是小光,嵌入式爱好者,一个想要成为系统架构师的大三学生。 ⏩最近在开发一个STM32H723ZGT6的板子,使用STM32CUBEMX做了很多驱动&#x…...
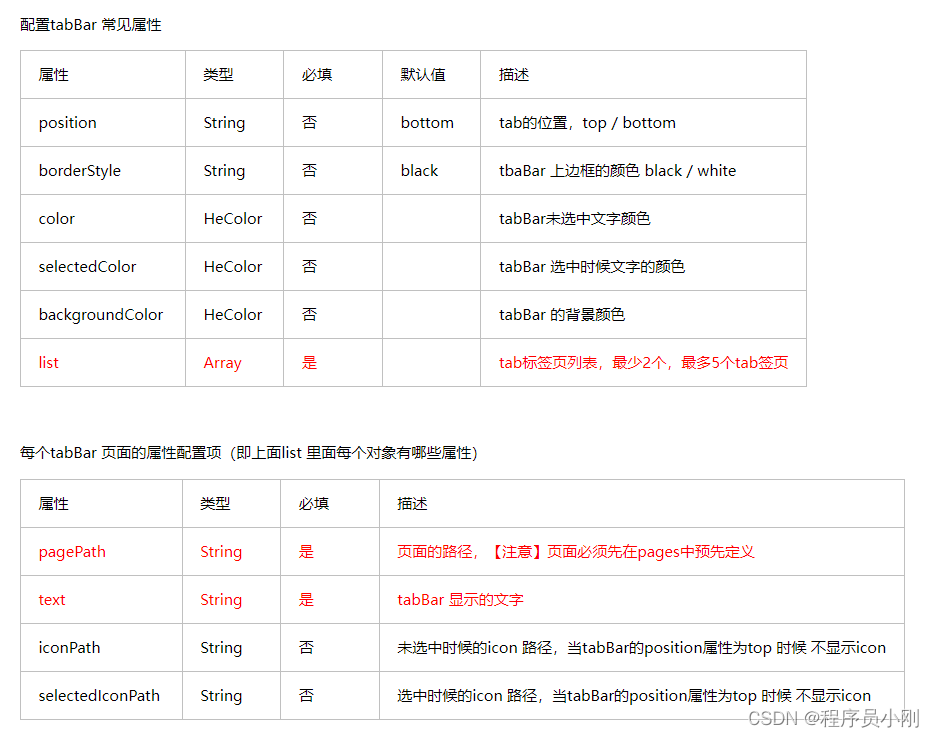
微信小程序 样式和全局配置
WXSS wxss 把屏幕分为750个物理像素,大屏大,小屏小,随着设备不一致自动适配 推荐使用iPhone6作为标准,1个rpx 0.5个px,把px乘以2就是rpx的参数 import 导入外部样式表 import /common/common.wxss 样式 权重一…...

一.初识C语言
一.初识C语言 C语言标准规定: sizeof(long)>sizeof(int)就可以了变量要定义在当前代码块的最前面 #defin _CRT_SECURE_NO_WARNINGS 1#include <stdio.h> //包含一个stdio.h的文件 std-标准standard input outputint main() //主函数-程序的入口-main函数…...

filebeat到kafka示例
docker run -d \ --namefilebeat_7.14_0 \ #filebeat名称 --userroot \ --volume"/data/filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml" \ #映射filebeat.yml配置 --volume"/data/filebeat/log:/usr/share/filebeat/log" \…...

AlmaLinux系统下的Zabbix汉化
我安装的是zabbix下的虚拟机,安装完成后,直接可以打开网站了,但是界面是英文,看了设置,没有中文选项,就需要在系统中安装中文字符集了。 # locale -a #查看里面没有zh_CN之类的项 # dnf install -…...
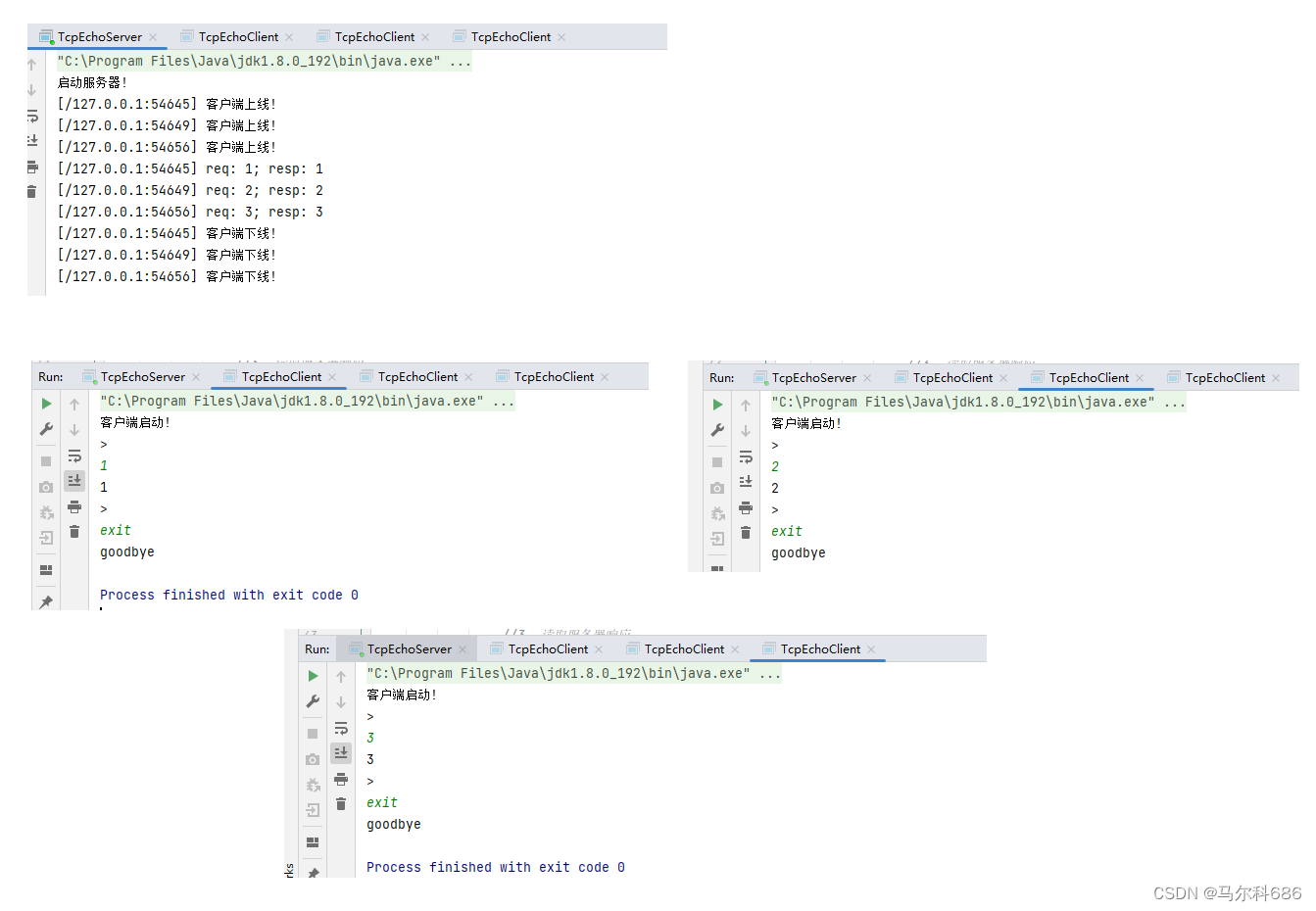
【网络编程】(TCP流套接字编程 ServerSocket API Socket API 手写TCP版本的回显服务器 TCP中的长短连接)
文章目录 网络编程TCP流套接字编程ServerSocket APISocket APITCP中的长短连接手写TCP版本的回显服务器 网络编程 TCP流套接字编程 TCP提供的API主要是两个类:ServerSocket 和 Socket . TCP不需要一个类来表示"TCP数据报"因为TCP不是以数据报为单位进行传输的.是以…...
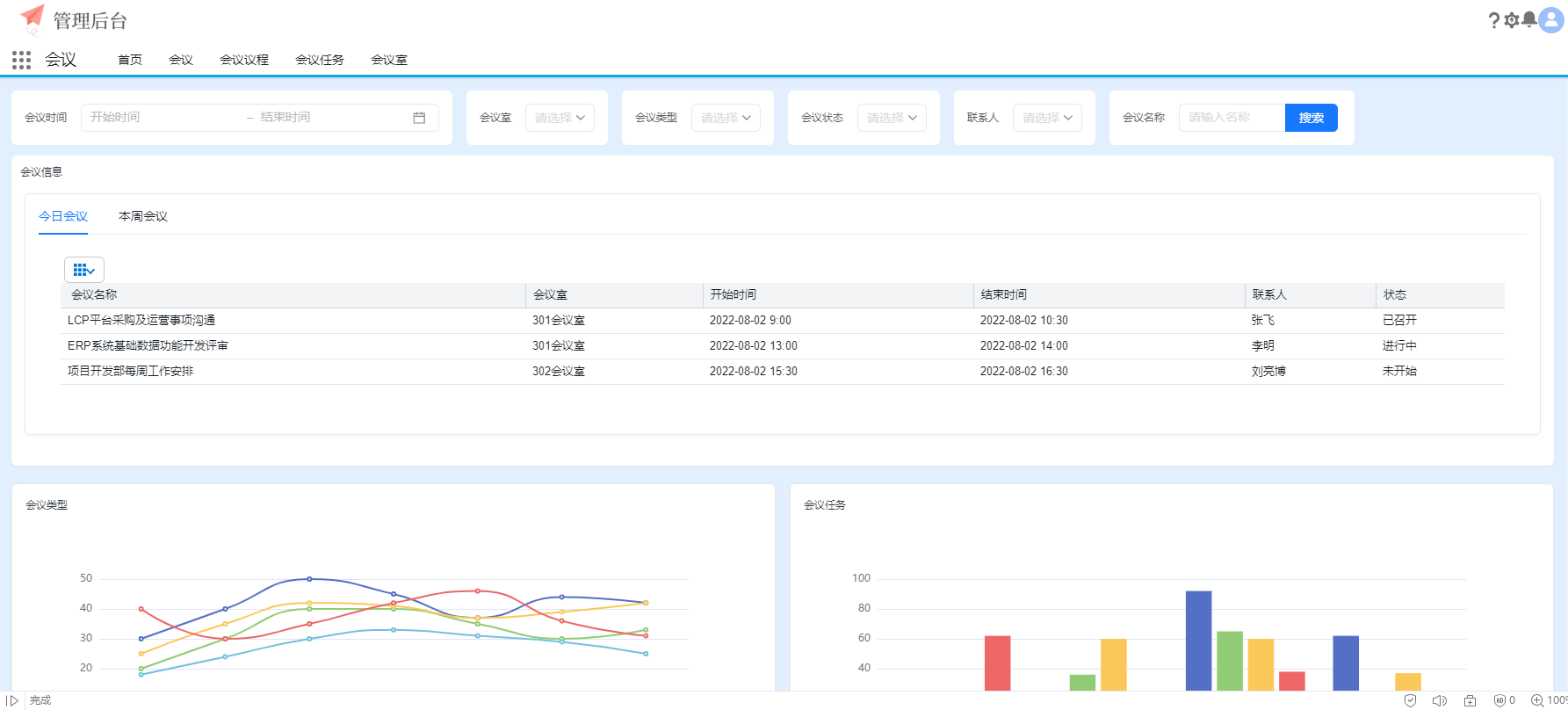
企业级PaaS低代码快开平台源码,基于 Salesforce Platform 的开源替代方案
PaaS低代码快开平台是一种快速开发应用系统的工具,用户通过少量代码甚至不写代码就可以快速构建出各种应用系统。 随着信息化技术的发展,企业对信息化开发的需求正在逐渐改变,传统的定制开发已经无法满足企业需求。低代码开发平台࿰…...

【LeetCode】72.编辑距离
题目 给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。 你可以对一个单词进行如下三种操作: 插入一个字符删除一个字符替换一个字符 示例 1: 输入:word1 "horse", word2 "…...
大模型,开源干不掉闭源
开源大模型对闭源大模型的冲击,变得非常猛烈。 今年3月,Meta发布了Llama(羊驼),很快成为AI社区内最强大的开源大模型,也是许多模型的基座模型。有人戏称,当前的大模型集群,就是一堆各…...

Redis 九种数据类型的基本操作
一、redis9种数据类型的基本操作 ①key操作 #查找所有的key 127.0.0.1:6379> keys * 1) "pop" 2) "mylist" 3) "lpl" 4) "myset" #设置key的过期时间 返回1表示执行成功,0表示失败,出现问题 127.0.0.1:6379…...

2025 ICPC武汉邀请赛 G [根号分治 容斥原理+DP]
Problem - G - Codeforces 观察题目,我们可以用贡献法, 计算每个格子的贡献,然后累加起来,对于重复的部分我们要减去 1.路径数量 首先,计算两个位置间有多少种路径互通,我们可以利用组合数进行计算&#x…...

Agent 的流程可以随时修改调整吗?深度解析 2026 年智能体动态编排与业务闭环
站在 2026 年的技术节点回望,AI Agent(智能体)早已脱离了最初“对话机器人”的稚嫩标签,演变为企业数字化转型的核心基础设施。针对“Agent 的流程可以随时修改调整吗?”这一核心疑问,答案不仅是肯定的&…...

AI安全高阶:生成式AI的安全风险与防御体系
AI安全高阶:生成式AI的安全风险与防御体系📝 本章学习目标:本章深入探讨高阶主题,适合有一定基础的读者深化理解。通过本章学习,你将全面掌握"AI安全高阶:生成式AI的安全风险与防御体系"这一核心…...

拓朋N86车载台:畜牧运输的隐形守护者
在广袤无垠的畜牧运输途中,牲畜的安全监控与车队间的协同调度是每位运输人员最为关心的两大要素。在这片充满不确定性的长途路线上,拓朋N86公网集群车载台以其出色的性能,悄然成为了畜牧运输的隐形守护者。 全国覆盖,沟通无阻 畜牧…...

零基础玩转DeepSeek-R1推理模型:Ollama一键部署Llama-8B教程
零基础玩转DeepSeek-R1推理模型:Ollama一键部署Llama-8B教程 1. 引言:为什么选择DeepSeek-R1-Distill-Llama-8B 你是否想体验强大的文本生成能力,却被复杂的模型部署流程劝退?DeepSeek-R1-Distill-Llama-8B是一个经过优化的8B参…...

Boost电路与SMC滑模控制策略:文章复现及性能优化探讨
boost电路,smc滑模控制,文章复现Boost电路在电力电子里算是老熟人了,但真要玩转它的闭环控制可不容易。最近在复现一篇用滑模控制(SMC)搞Boost电路的论文,实测发现这货对付负载突变确实有两把刷子。今天咱们…...

开源激活利器:KMS_VL_ALL_AIO全场景应用指南
开源激活利器:KMS_VL_ALL_AIO全场景应用指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 问题:激活困境与技术痛点 个人用户的激活难题 当Windows系统突然弹出激活提…...

Windows Defender Remover:系统优化工具与安全组件管理指南
Windows Defender Remover:系统优化工具与安全组件管理指南 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh_mirror…...

好写作AI“查重雷达”:用AI技术为论文“扫雷”,让学术诚信“稳如泰山”
写论文时,最让人心跳加速的瞬间是什么?不是选题时的纠结,也不是数据分析的崩溃,而是查重报告出来的那一刻——如果重复率超过30%,轻则被导师“请喝茶”要求修改,重则被扣上“学术不端”的帽子,影…...

威纶通MT8102iE触摸屏中文用户名显示不全?手把手教你用EasyBuilder Pro V6.09.01.357s搞定
威纶通MT8102iE触摸屏中文用户名显示异常的深度解决方案 在工业自动化控制系统中,人机界面(HMI)作为操作人员与设备交互的重要窗口,其用户体验直接影响着生产效率。威纶通(Weintek)MT8102iE作为一款广泛应用于工业场景的触摸屏,其用户管理功能…...