基于Linux操作系统中的MySQL数据库SQL语句(三十一)
MySQL数据库SQL语句
目录
一、SQL语句类型
1、DDL
2、DML
3、DCL
4、DQL
二、数据库操作
1、查看
2、创建
2.1、默认字符集
2.2、指定字符集
3、进入
4、删除
5、更改
6、练习
三、数据表操作
(一)数据类型
1、数值类型
1.1、TINYINT
1.2、SMALLINT
1.3、INT
1.4、BIGINT
1.5、FLOAT(M,D)
2、时间\日期类型
2.1、DATE
2.2、TIME
2.3、DATETIME
2.4、TIMESTAMP
3、字符串类型
3.1、CHAR
3.2、VARCHAR
3.3、TEXT
4、二进制类型
4.1、BINARY
4.2、VARBINARY
4.3、BLOB
(二)创建
(三)查看
1、添加表内的数据
2、查看表内的数据
3、查看表格的属性
(四)删除
1、删除数据表
2、删除数据表数据,但是保留表结构
(五)更改
1、数据表
1.1、名称
1.2、字符集
2、数据表--列
1.1、名称
1.2、属性
1.3、字符集
(六)练习
四、数据操作
(一)增加数据
(二)删除数据
(三)更改数据
(四)查看数据
1、单表查询
1.1、全表查询
1.2、条件查询
1.2.1、条件表达式
1.2.1.1、运算符
1.2.1.2、通配符 ( %和_ )
1.2.2、查询类型
1)where子句
2)排序查询
3)分组查询
4)去重查询
5)分页查询
6)子查询
7)函数查询
7.1)聚合函数
7.1.1)SUM
7.1.2)AVG
7.1.3)COUNT
7.1.4)MAX
7.1.5)MIN
7.2)字符串函数
7.2.1)CONCAT
7.2.2)LENGTH
7.2.3)UPPER
7.2.4)LOWER
7.2.5)SUBSTR
7.2.6)REPLACE
7.3)日期时间函数
7.4)数学函数
7.5)拓展内容
2、多表查询
2.1.内连接查询
2.2、外连接查询
2.2.1、左外连接查询
2.2.2、右外连接查询
一、SQL语句类型
1、DDL
DDL(Data Definition Language,数据定义语言):用于定义数据库中的各种对象,包括数据库、表、视图、触发器等,常见的 DDL 命令有 CREATE、ALTER、DROP
2、DML
DML(Data Manipulation Language,数据操作语言):用于操作表格中的数据,进行新增、查询、更新、删除等操作,常见的 DML 命令有 SELECT、INSERT、UPDATE、DELETE
3、DCL
DCL(Data Control Language,数据控制语言):用于管理数据库的权限和安全性,包括授权、回收权限等操作,常见的 DCL 命令有 GRANT、REVOKE
4、DQL
DQL(Data Query Language,数据查询语言)是 SQL 的一个子集,主要用于查询数据库中的数据,常见的 DQL 命令包括 SELECT
二、数据库操作
1、查看
show databases; 
2、创建
2.1、默认字符集
create database 数据库名称;
默认不进行改动是latin1
create database back; 
2.2、指定字符集
create database 数据库名称 character set utf8;
使用uft8格式的字符集
create database bak character set utf8;
3、进入
use 数据库名称;
use bak; 
4、删除
drop database 数据库名称;
drop database bak; 
5、更改
库名称
进入到数据库的目录中修改数据库的名称
cd /var/lib/mysql
更改数据库名称
mv back bak回到数据库进行查看
show databases;
字符集
ALTER DATABASE <database_name> CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
6、练习
创建2个数据库,一个全写,一个缩写(指定字符集)
删除缩写的,将全写的名称改为缩写的
三、数据表操作
(一)数据类型
1、数值类型
1.1、TINYINT
1个字节,范围为 -128 到 127(有符号)或 0 到 255(无符号)
可以使用 TINYINT UNSIGNED 来存储年龄(无符号)或温度(有符号)等小数值
1.2、SMALLINT
2个字节,范围为 -32,768 到 32,767(有符号)或 0 到 65,535(无符号)
可以使用 SMALLINT 存储商品数量, 或者使用 SMALLINT UNSIGNED 存储区域编号(无符号)
1.3、INT
4个字节,范围为 -2,147,483,648 到 2,147,483,647(有符号)或 0 到 4,294,967,295(无符号)
这是最常用的整数类型,它可以被用于许多方面,例如存储订单号或者用户的数量
1.4、BIGINT
8个字节
存储很大的数值,例如资金、人口等
1.5、FLOAT(M,D)
单精度浮点数,M是总位数,D是小数位数
可以使用 FLOAT(8,2) 来存储商品的价格
2、时间\日期类型
2.1、DATE
用来存储日期,格式为’YYYY-MM-DD’
可以使用 DATE 存储出生日期或者过期日期等
2.2、TIME
用来存储时间,格式为’HH:MM:SS’
可以使用 TIME 存储过去一段时间内花费的小时数,分钟数或秒数等
2.3、DATETIME
用来存储日期和时间,格式为’YYYY-MM-DD HH:MM:SS’
可以使用 DATETIME 存储订单时间或者统计报告生成时间等
2.4、TIMESTAMP
用来存储日期和时间,通常被用于记录特定事件的时间戳。使用UNIX的日期和时间格式,从1970年1月1日午夜开始计算
可以使用 TIMESTAMP 存储用户上次登录的时间戳
3、字符串类型
3.1、CHAR
用来存储定长字符串,最大长度为255个字符
可以使用 CHAR(10) 存储用户的性别、婚姻状况等数据
3.2、VARCHAR
用来存储可变长度字符串,最大长度为65535个字符
可以使用 VARCHAR(255) 存储用户输入的文本内容、地址等数据
3.3、TEXT
用来存储大型字符数据,最大长度为2^16-1个字符
可以使用 TEXT 存储文章、评论等大型文本数据
4、二进制类型
4.1、BINARY
用来存储固定长度二进制数据,最大长度为255个字节
可以使用 BINARY(16) 存储UUID
4.2、VARBINARY
用来存储可变长度二进制数据,最大长度为65535个字节
可以使用 VARBINARY(256) 存储不定长度的二进制数据,例如图片和音频等文件
4.3、BLOB
用来存储大型二进制对象数据,最大长度为2^16-1个字节
可以使用 BLOB 存储音视频等媒体文件
(二)创建
create table tables_name(
第一列 类型属性,
第二列 类型属性,
) character set utf8mb4 collate utf8mb4_unicode_ci;
character set utf8mb4 collate utf8mb4_unicode_ci 写在表之后,声明表的字符集
create table a1(
编号 int not null,
姓名 varchar(20) not null,
性别 varchar(10) not null,
出生年月 date not null
)character set utf8mb4 collate utf8mb4_unicode_ci;
create table tables_name(
第一列 类型属性,
第二列 类型属性 character set utf8mb4 collate utf8mb4_unicode_ci,
);
character set utf8mb4 collate utf8mb4_unicode_ci, 写在列之后,声明列的字符集
create table a2(
编号 int not null,
姓名 varchar(20) character set utf8mb4 collate utf8mb4_unicode_ci,
性别 varchar(10) not null);
创建数据表时,添加约束条件
创建数据表时添加
CREATE TABLE 数据表名 (
id INT PRIMARY KEY, -- 定义 id 列为主键
name VARCHAR(20) NOT NULL,
age INT
);
create table a3(
编号 int not null primary key,
姓名 varchar(20) not null,
性别 varchar(10) not null
);


修改现有的数据表
(三)查看
1、添加表内的数据
INSERT INTO a4 (编号,姓名,性别) VALUES (1,'张三', '男'),
(2,'李四', '女'),
(3,'王五', '男'),
(4,'赵六', '男'),
(5,'小明', '男'),
(6,'小帅', '男'),
(7,'小美', '女'),
(8,'小红', '女'),
(9,'大明', '男'),
(10,'大帅', '男');
2、查看表内的数据
select * from tables_name;
select column1,column2 from tables_name where 条件;
select * from a4; 
select 编号,姓名,性别 from a4 where 性别='男';
select 编号,姓名,性别 from a4 where 性别='女';
3、查看表格的属性
describe tables_name;
desc tables_name; 此为缩写命令
describe a4;
desc a4;
(四)删除
1、删除数据表
drop table tables_name;
drop table a3;
2、删除数据表数据,但是保留表结构
delete from tables_name;

(五)更改
1、数据表
1.1、名称
查看数据表目录
show tables; 
更改数据表名称
alter table old_table_name rename to new_table_name;
注意事项:如果现在的表正在被其他表或程序应用,那么可能会导致无法正常引用。

检查验证
show tables; 
1.2、字符集
alter table my_table convert to character set utf8mb4 collate utf8mb4_unicode_ci;
alter table a6 convert to character set utf8mb4 collate utf8mb4_unicode_ci;
2、数据表--列
1.1、名称
alter table table_name change old_name new_name 属性;
alter table a6 change age number int; 
select * from a6; 

1.2、属性
alter table my_table modify 修改的列 修改的属性;
alter table a6 modify name char(10); 
检验数据表格属性
desc a6;原有的表格属性

现在的表格属性
1.3、字符集
alter table users modify name varchar(50) character set utf8mb4;
这是一个SQL语句,用于修改表格"users"中的"name"字段的数据类型。它将"name"字段的数据类型从原来的varchar(50)修改为varchar(50) character set utf8mb4,其中utf8mb4是一种支持更广范围字符集的编码方式。修改字符集可以确保该字段能够存储包含特殊字符(如表情符号、不同语言的字符等)的数据。
alter table a6 modify name char(50) character set utf8mb4 not null;这是一个SQL语句,用于修改表格"a6"中的"name"字段的数据类型和约束。它将"name"字段的数据类型从原来的char(50)修改为char(50) character set utf8mb4,其中utf8mb4是一种支持更广范围字符集的编码方式。同时,添加了"not null"约束,表示该字段不允许为空值。修改字符集可以确保该字段能够存储包含特殊字符(如表情符号、不同语言的字符等)的数据,而"not null"约束则要求该字段的值在插入或更新时不能为NULL。

(六)练习
创建两个表:
1、包含编号、姓名、性别
2、包含姓名、年龄、出生年月
四、数据操作
(一)增加数据
insert into table_name (column1, column2, ...) values (value1, value2, ...);
create table a6(
id int not null,
name varchar(20) not null,
age int not null
)character set utf8mb4 collate utf8mb4_unicode_ci;INSERT INTO a6 (id,name,age) VALUES (1,'zhangsan', 15),
(2,'lisi', 18),
(3,'wangwu', 22),
(4,'xiaoming', 25),
(5,'xiaomei', 28);
(二)删除数据
delete from table_name where 条件;
select * from a6; 
delete from a6 where id=5; 
select * from a6; 
(三)更改数据
update table_name set column1 = value1, column2 = value2, ... where 条件;
update a6 set id=5 where name='xiaoming'; 
select * from a6; 
(四)查看数据
select * from tables_name;
select column1,column2 from tables_name where 条件;
select * from a6; 
select id,name,age from a6 where age=18; 
查询数据(查)
1、单表查询
1.1、全表查询
在查询中没有指定任何的限制条件,会返回整张表的所有行
1.2、条件查询
1.2.1、条件表达式
1.2.1.1、运算符
等于=
select id,name,age from a6 where age=18; 
不等于!=或<>
select id,name,age from a6 where age!=18;
select id,name,age from a6 where age<>18;
大于>
select id,name,age from a6 where age>18;
大于等于>=
select id,name,age from a6 where age>=18;
小于<
select id,name,age from a6 where age<18; 
小于等于<=
select id,name,age from a6 where age<=18;
between
BETWEEN运算符用于表示在一个范围内的值,AND
select * from a6 where age between 18 and 25;select * from a6
where age between 18 and 25 (筛选年龄范围)
and score between 80 and 100;(筛选成绩范围)
多行内容写入以这种写法条理较为清晰

in
IN运算符用于比较一个表达式是否与一组表达式中的任意一个相匹配
select * from a6 where name in('li');
1.2.1.2、通配符 ( %和_ )
%通配符匹配任意数量(包括0个)的字符
select * from a6 where name like '%xi%';
通配符 _
_通配符匹配一个任意字符
通常会和like一起使用
select * from a6 where name like 'l_'; 
1.2.2、查询类型
1)where子句
查询时,指定要返回符合条件的行,后面跟条件
2)排序查询
排序查询是通过SQL查询语句将所查询的结果按照指定的排序方式排列
升序(默认) ASC
降序 DESC
select * from test order by colume1;
select * from test order by colume1 DESC, colume2 ASC;
select * from a6 order by age;
select * from a6 order by age asc; 

注:升序排列为系统默认,所以加不加asc都可以
年龄降序

多条件查询排序
select * from a6 order by age asc,name desc;
3)分组查询
主要用于统计分析,生成对应报表
count(*)函数用于统计出现过的记录总和
group by用于按照特定字段进行分组
select class, count(*) from test group by class;
select age,count(*) from a6 group by age;
经过筛选查询:
年龄为14的记录有1个
年龄为15的记录有1个
年龄为18的记录有2个
年龄为22的记录有1个
年龄为25的记录有2个
年龄为26的记录有1个
年龄为35的记录有1个

4)去重查询
用于从结果集中删除重复的行,只返回不同的值
select distinct colume1 from test;
select distinct age from a6; 
如果查询多个列,则会显示两列的组合,每个组合只会出现一次
select distinct colume1,colume2......... from test;
select distinct name,age from a6; 
5)分页查询
用于在SQL语句中限制返回数据的条数该技术可用于显示诸如Web页面之类的大量数据
limit 表示要返回的记录数
offset 表示查询结果的起始位置或查询结果的偏移量
select * from test limit 10 offset 10;
查询5行数据,从初始行偏移一行显示
select * from a6 limit 5 offset 1;
6)子查询
在一个SQL语句中嵌套使用另一个完整的SQL查询语句。子查询通常用作主查询的查询条件或结果过滤条件,以及用于提供主查询需要的一些数据
select * from test where age > (select avg(age) from test);
select * from a6 where age > (select avg(age)from a6);
7)函数查询
7.1)聚合函数
7.1.1)SUM
求某一列的值的总和
select sum(colume1) from test;
select sum(age) from a6; 
7.1.2)AVG
求某一列值的平均值
select avg(colume1) from test;
select avg(age) from a6; 
如果某一列中的值包含数值0,该如何计算?
7.1.3)COUNT
用于计算指定列中的行数,不包含非空行
select count(id) from test;
select count(age) from a6; 
7.1.4)MAX
用于计算指定列中的最大值
MAX函数适用于任何数据类型,无论列中包含的是数字、文本还是其他类型的数据
如果是文本字符串类型,则按照字符串的字典序进行排序
select max(id) from test;
select max(age) from a6; 
7.1.5)MIN
用于计算指定列中的最小值
MIN函数适用于任何数据类型,无论列中包含的是数字、文本还是其他类型的数据
如果是文本字符串类型,则按照字符串的字典序进行排序
select min(id) from test;
select min(age) from a6; 
7.2)字符串函数
7.2.1)CONCAT
连接两个或多个字符串,并返回合成后的新字符串
select concat('hello',' ','World');
select concat(name,' ',age) from a6; 
7.2.2)LENGTH
返回字符串的长度(字符数)
select length('Hello World');
select length(name) from a6; 
7.2.3)UPPER
将字符串转换为大写字母
select upper(Hello World);
select upper(name) from a6;
7.2.4)LOWER
将字符串转换为小写字母
select lower(Hello World);
select lower(name) from a6; 
7.2.5)SUBSTR
返回指定字符串中的一部分,可以使用起始位置和长度指定要返回的子字符串
select substr('Hello World',7,5);
select substr(name,1,4) from a6; 
7.2.6)REPLACE
将指定字符串中的一部分替换为新字符串,并返回新的字符串
select replace('Hello World','Hello','Hi');
select replace(name,'ln','zn') from a6;

7.3)日期时间函数
7.4)数学函数
7.5)拓展内容
2、多表查询
多表查询是指在关系型数据库中,查询多个表的信息并进行关联、筛选和排序等操作的过程或语句。在一个查询语句中同时查询多个表,并根据表之间的关联关系进行关联查询。通过多表查询,可以将多个表的数据进行联合,获取到需要的结果集,多表查询可以用来解决某些查询需求。
多表查询常用的关联方式包括:
内连接(INNER JOIN):根据两个表之间的关联字段进行查询,返回符合条件的数据。
左连接(LEFT JOIN):以左表为基准,将左表中的所有数据与右表中符合条件的数据进行关联查询,如果右表中没有符合条件的数据,则用NULL填充。
右连接(RIGHT JOIN):以右表为基准,将右表中的所有数据与左表中符合条件的数据进行关联查询,如果左表中没有符合条件的数据,则用NULL填充。
全连接(FULL JOIN):将左表和右表中的所有数据进行关联查询,如果左表和右表中没有符合条件的数据,则用NULL填充。
多表查询可以通过使用JOIN关键字来实现,其中可以通过ON关键字指定关联条件。
2.1.内连接查询
创建两个数据表写有数据
CREATE TABLE z1 (
id INT NOT NULL PRIMARY KEY,
name VARCHAR(50) NOT NULL,
age VARCHAR(50) NOT NULL
);CREATE TABLE n2 (
id INT NOT NULL PRIMARY KEY,
name VARCHAR(50) NOT NULL,
gender CHAR(10) NOT NULL,
date DATE NOT NULL
);INSERT INTO z1 (id, name, age) VALUES
(1,'zhangsan',18),
(2,'lisi',25),
(3,'wangwu',30);INSERT INTO n2 (id,name, gender,date) VALUES
(1,'xiaoming','man','2000-05-17'),
(2,'xiaomei','woman','2013-06-30'),
(3,'xiaoshuai','man','2020-05-16'),
(4,'xiaonan','woman','1997-10-07');

SELECT *
FROM table1
INNER JOIN table2
ON table1.column1 = table2.column2;
内连接是一种联结操作,它根据两个表之间的关联关系将它们的记录进行匹配。在这个例子中,通过指定 ON 子句来定义连接条件,即 table1.column1 = table2.column2。这表示将会以 column1 和 column2 的值相等作为连接条件,将两个表中匹配的记录合并在一起。
这个查询可以用于在两个表之间建立关联关系,并获取相关联的记录,以便进行进一步的分析或操作。
select *
from z1
inner join n2
on z1.id = n2.id;

2.2、外连接查询
2.2.1、左外连接查询
SELECT *
FROM table1
LEFT JOIN table2
ON table1.column1 = table2.column2;
这个查询语句表示在两个表(table1和table2)之间进行左连接(left join)操作。LEFT JOIN是一种关联操作,它会返回左表(table1)中的所有记录,以及右表(table2)中与左表关联列(column1)匹配的记录。通过指定"ON"关键词和关联条件(table1.column1 = table2.column2),可以确定两个表之间的关联关系。查询结果将包含所有匹配的记录,并且对于没有匹配记录的左表记录,右表会返回NULL值。
select *
from z1
left join n2
on z1.id = n2.id;

2.2.2、右外连接查询
SELECT *
FROM table1
RIGHT JOIN table2
ON table1.column1 = table2.column2;
这个查询语句表示在两个表(table1和table2)之间进行右连接(right join)操作。RIGHT JOIN是一种关联操作,它会返回右表(table2)中的所有记录,以及左表(table1)中与右表关联列(column1)匹配的记录。通过指定"ON"关键词和关联条件(table1.column1 = table2.column2),可以确定两个表之间的关联关系。查询结果将包含所有匹配的记录,并且对于没有匹配记录的右表记录,左表会返回NULL值。
select *
from z1
right join n2
on z1.id = n2.id;

相关文章:
基于Linux操作系统中的MySQL数据库SQL语句(三十一)
MySQL数据库SQL语句 目录 一、SQL语句类型 1、DDL 2、DML 3、DCL 4、DQL 二、数据库操作 1、查看 2、创建 2.1、默认字符集 2.2、指定字符集 3、进入 4、删除 5、更改 6、练习 三、数据表操作 (一)数据类型 1、数值类型 1.1、TINYINT …...
)
【Matlab】基于BP神经网络的数据回归预测新数据(Excel可直接替换数据)
【Matlab】基于BP神经网络的数据回归预测新数据(Excel可直接替换数据) 1.模型原理2.数学公式3.文件结构4.Excel数据5.分块代码5.1 main.m5.2 NewData.m6.完整代码6.1 main.m6.2 NewData.m7.运行结果1.模型原理 基于BP神经网络的数据回归预测是一种常见的机器学习方法,用于处…...
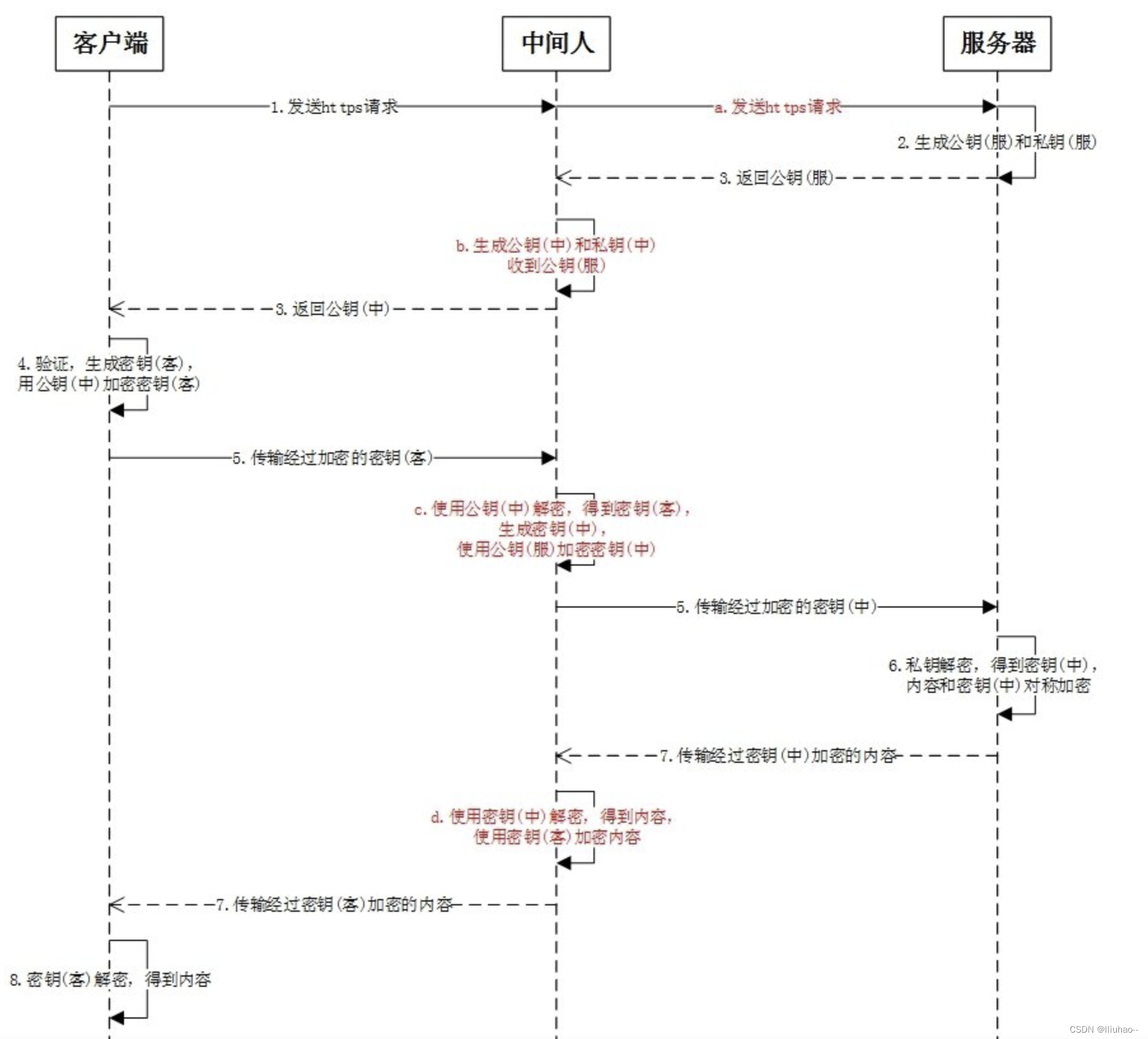
HTTPS连接过程中的中间人攻击
HTTPS连接过程中的中间人攻击 HTTPS连接过程中间人劫持攻击 HTTPS连接过程 https协议就是httpssl/tls协议,如下图所示为其连接过程: HTTPS连接的整个工程如下: https请求:客户端向服务端发送https请求;生成公钥和私…...
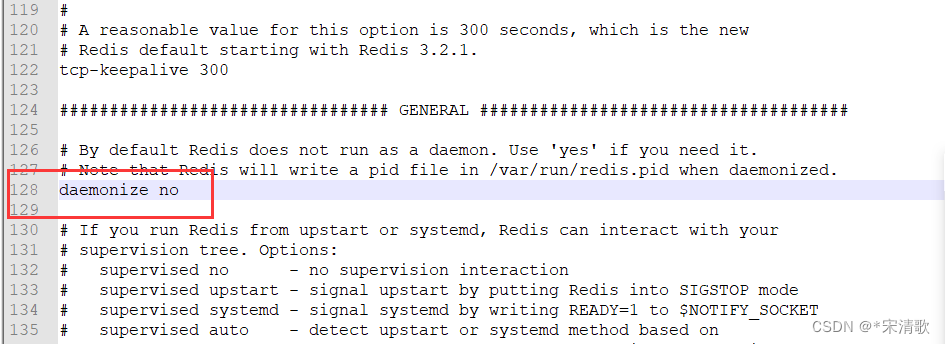
redis启动失败,oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
在redis文件夹下,启动redis正常。 但是加入到system后启动redis失败。 一直处于starting状态。 对比正常redis服务的配置之后,把redis.conf里的守护进程关掉就可以了(但是没用system管理之前,直接./redis.server启动是可以的&…...
milvus: 专为向量查询与检索设计的向量数据库
1. 什么是milvus? milvus docs milvus release Milvus的目标是:store, index, and manage massive embedding vectors generated by deep neural networks and other machine learning (ML) models. Milvus 向量数据库专为向量查询与检索设计…...
【C# 数据结构】Heap 堆
【C# 数据结构】Heap 堆 先看看C#中有那些常用的结构堆的介绍完全二叉树最大堆 Heap对类进行排序实现 IComparable<T> 接口 对CompareTo的一点解释 参考资料 先看看C#中有那些常用的结构 作为 数据结构系类文章 的开篇文章,我们先了解一下C# 有哪些常用的数据…...

智慧园区楼宇合集:数字孪生管控系统
智慧园区是指将物联网、大数据、人工智能等技术应用于传统建筑和基础设施,以实现对园区的全面监控、管理和服务的一种建筑形态。通过将园区内设备、设施和系统联网,实现数据的传输、共享和响应,提高园区的管理效率和运营效益,为居…...

Ajax 黑马学习
Ajax 资源 数据是服务器对外提供的资源,通过 请求 - 处理 - 响应方式获取 请求服务器数据, 用到 XMLHttpRequest 对象 XMLHttpRequest 是浏览器提供的js成员, 通过它可以请求服务器上的数据资源 let xmlHttpRequest new XMLHttpRequest(); 请求方式 : get向服务器获取数据…...

软件应用开发的常见环境
一般来说,在小型项目中可能只有开发环境和生产环境;在中型项目中会有开发环境、staging environment、生产环境;在大型项目中会有开发环境、测试环境、staging environment、生产环境。 一、Dev Env / Development Environment 开发环境 开…...
, into_iter(), iter_mut())
Rust中的iter(), into_iter(), iter_mut()
在Rust中,iter(), into_iter(), iter_mut()都是用于在集合类型上创建迭代器的方法。这三个方法各有不同,下面一一进行介绍。 iter(): iter() 方法创建一个不可变的引用迭代器。当你只想读取集合中的元素,而不想改变它们或消耗集合时ÿ…...

[SQL挖掘机] - 日期函数 - current_date
current_date函数时,它通常被用来获取当前的日期。它返回一个表示当前日期的日期值。 current_date函数没有任何参数,因此只需简单地调用它即可获得系统当前日期。 以下是一个示例: select current_date;这将返回当前日期,例如…...

JAVA面试总结-Redis篇章(三)——缓存雪崩
JAVA面试总结-Redis篇章(三)——缓存雪崩...
maven编译报错
参考链接:mvn打包No compiler is provided in this environment. Perhaps you are running on a JRE rather than a JDK_51CTO博客_mvn打包命令 在执行 yum install -y java-1.8.0-opensdk命令后,使用maven去编译打包,结果报错, …...

HPC集群调度系统和计算系统
什么是计算云? 所谓的计算云指的是为计算业务优化的类云基础架构,它强调用云的方式解决计算问题,而不是将“计算”搬到现有的公有云或者容器云上。 目前公有云或者容器云(例如k8s)上的HPC解决方案本质上都是将现有的H…...

pg_archivecleanup清理wal日志
一、 注意事项 pg_archivecleanup代码中仅进行了wal日志文件名的对比,没有实现对WAL日志名及对应生成时间的判断。在WAL日志未被重命名时,时间与日志名顺序名一致,没有问题。一旦WAL日志被重命名,pg_archivecleanup清理就可能清理…...
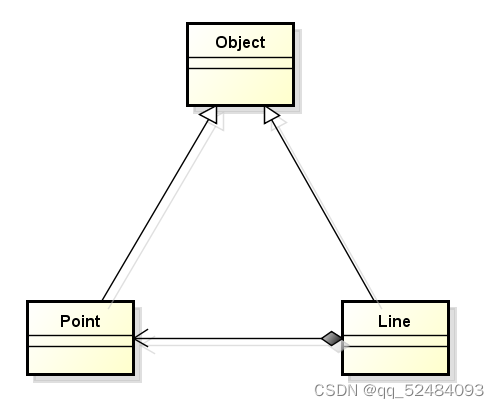
继承中的访问级别
值得思考的问题 子类是否可以直接访问父类的私有成员? 思考过程 继承中的访问级别 面向对象中的访问级别不止是 public 和 private 可以定义 protected 访问级别 关键字 protected 的意义 修饰的成员不能被外界直接访问修饰的成员可以被子类直接访问 思考 为什…...
(学习日记)2023.06.09
写在前面: 由于时间的不足与学习的碎片化,写博客变得有些奢侈。 但是对于记录学习(忘了以后能快速复习)的渴望一天天变得强烈。 既然如此 不如以天为单位,以时间为顺序,仅仅将博客当做一个知识学习的目录&a…...

激光雷达-相机联合标定
https://f.daixianiu.cn/csdn/9499401684344864.html ros usb相机内参标定 ROS系统-摄像头标定camera calibration_berry丶的博客-CSDN博客...
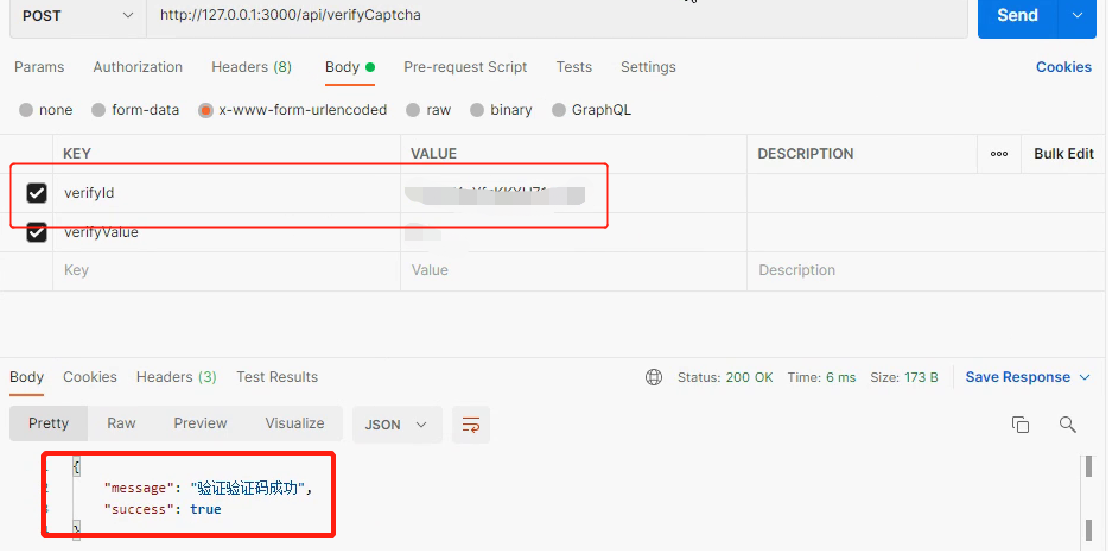
[golang gin框架] 40.Gin商城项目-微服务实战之Captcha验证码微服务
本次内容需要 gin框架基础知识, golang微服务基础知识才能更好理解 一.Captcha验证码功能引入 在前面,讲解了微服务的架构等,这里,来讲解前面商城项目的 Captcha验证码 微服务 ,captcha验证码功能在前台,后端 都要用到 ,可以把它 抽离出来 ,做成微服务功能 编辑 这个验证码功能…...
【LeetCode热题100】打卡第44天:倒数第30~25题
文章目录 【LeetCode热题100】打卡第44天:倒数第30~25题⛅前言 移动零🔒题目🔑题解 寻找重复数🔒题目🔑题解 二叉树的序列化与反序列化🔒题目🔑题解 最长递增子序列🔒题目ǵ…...

SEO_从零开始构建可持续流量的SEO体系
SEO:从零开始构建可持续流量的SEO体系 在互联网时代,拥有一个高流量的网站已经不再是小事。对于初学者来说,从零开始构建一个可持续的SEO体系,听起来可能有些令人望而生畏。通过一些基本策略和长期的努力,任何人都可以实现这一目…...

番茄小说下载器:全能解析引擎驱动的一站式数字阅读解决方案
番茄小说下载器:全能解析引擎驱动的一站式数字阅读解决方案 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 在数字阅读日益普及的今天,读者们常面临三大…...
)
告别激光雷达?手把手复现ST-P3:一个纯视觉的端到端自动驾驶模型(附避坑指南)
纯视觉自动驾驶实战:从零复现ST-P3模型的完整指南 当特斯拉在2021年宣布取消所有车型的雷达传感器时,整个行业都在质疑纯视觉方案的可靠性。然而ST-P3论文的发表,为这一技术路线提供了新的理论支撑。本文将带你深入这个前沿模型的实现细节&am…...

小说下载与数字图书馆构建:开源工具novel-downloader完全指南
小说下载与数字图书馆构建:开源工具novel-downloader完全指南 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,读者常面临三大困境:…...
,OpenClaw Auto-Dream 实战从入门到精通,收藏这一篇就够了!)
让 AI Agent “睡觉”整理记忆(非常详细),OpenClaw Auto-Dream 实战从入门到精通,收藏这一篇就够了!
你有没有遇到过这样的情况:辛辛苦苦教会了 AI Agent 你的工作习惯和项目背景,关掉窗口、重启会话后,它又变回了一张白纸?这是当前所有基于 LLM(大语言模型)的 Agent 面临的核心痛点——“聊完就忘”。2026 …...

谷歌:子目标驱动提升长程智能体
📖标题:A Subgoal-driven Framework for Improving Long-Horizon LLM Agents 🌐来源:arXiv, 2603.19685v1 🌟摘要 基于大语言模型(LLM)的代理已经成为数字环境的强大自主控制器,跨越…...

OpenXR Toolkit完全指南:3步让你的VR游戏性能提升50%
OpenXR Toolkit完全指南:3步让你的VR游戏性能提升50% 【免费下载链接】OpenXR-Toolkit A collection of useful features to customize and improve existing OpenXR applications. 项目地址: https://gitcode.com/gh_mirrors/op/OpenXR-Toolkit 想要在不升级…...

“你用AI,那我也会用AI,我还要你干什么?”
这个代码的核心功能是:基于输入词的长度动态选择反义词示例,并调用大模型生成反义词,体现了 “动态少样本提示(Dynamic Few-Shot Prompting)” 与 “上下文长度感知的示例选择” 的能力。 from langchain.prompts impo…...

SecGPT-14B多场景:安全设备日志归一化、威胁情报摘要生成、钓鱼邮件识别
SecGPT-14B多场景实战:安全设备日志归一化、威胁情报摘要生成、钓鱼邮件识别 在网络安全领域,每天面对海量的安全日志、繁杂的威胁情报和层出不穷的钓鱼邮件,安全分析师常常感到力不从心。手动处理这些信息不仅耗时耗力,还容易遗…...

如何高效加速GitHub下载:Fast-GitHub插件的完整指南
如何高效加速GitHub下载:Fast-GitHub插件的完整指南 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 你是否经常因为Git…...