49:字符串的新增方法
字符串的新增方法
- String.fromCodePoint()
- String.raw()
- 实例方法:codePointAt()
- 实例方法:normalize()
- [实例方法:includes(), startsWith(), endsWith()](https://es6.ruanyifeng.com/#docs/string-methods#实例方法:includes(), startsWith(), endsWith())
- 实例方法:repeat()
- 实例方法:padStart(),padEnd()
- 实例方法:trimStart(),trimEnd()
- 实例方法:matchAll()
- 实例方法:replaceAll()
- 实例方法:at()
本章介绍字符串对象的新增方法。
String.fromCodePoint()
ES5 提供String.fromCharCode()方法,用于从 Unicode 码点返回对应字符,但是这个方法不能识别码点大于0xFFFF的字符。
String.fromCharCode(0x20BB7)
// "ஷ"
上面代码中,String.fromCharCode()不能识别大于0xFFFF的码点,所以0x20BB7就发生了溢出,最高位2被舍弃了,最后返回码点U+0BB7对应的字符,而不是码点U+20BB7对应的字符。
ES6 提供了String.fromCodePoint()方法,可以识别大于0xFFFF的字符,弥补了String.fromCharCode()方法的不足。在作用上,正好与下面的codePointAt()方法相反。
String.fromCodePoint(0x20BB7)
// "𠮷"
String.fromCodePoint(0x78, 0x1f680, 0x79) === 'x\uD83D\uDE80y'
// true
上面代码中,如果String.fromCodePoint方法有多个参数,则它们会被合并成一个字符串返回。
注意,fromCodePoint方法定义在String对象上,而codePointAt方法定义在字符串的实例对象上。
String.raw()
ES6 还为原生的 String 对象,提供了一个raw()方法。该方法返回一个斜杠都被转义(即斜杠前面再加一个斜杠)的字符串,往往用于模板字符串的处理方法。
String.raw`Hi\n${2+3}!`
// 实际返回 "Hi\\n5!",显示的是转义后的结果 "Hi\n5!"String.raw`Hi\u000A!`;
// 实际返回 "Hi\\u000A!",显示的是转义后的结果 "Hi\u000A!"
如果原字符串的斜杠已经转义,那么String.raw()会进行再次转义。
String.raw`Hi\\n`
// 返回 "Hi\\\\n"String.raw`Hi\\n` === "Hi\\\\n" // true
String.raw()方法可以作为处理模板字符串的基本方法,它会将所有变量替换,而且对斜杠进行转义,方便下一步作为字符串来使用。
String.raw()本质上是一个正常的函数,只是专用于模板字符串的标签函数。如果写成正常函数的形式,它的第一个参数,应该是一个具有raw属性的对象,且raw属性的值应该是一个数组,对应模板字符串解析后的值。
// `foo${1 + 2}bar`
// 等同于
String.raw({ raw: ['foo', 'bar'] }, 1 + 2) // "foo3bar"
上面代码中,String.raw()方法的第一个参数是一个对象,它的raw属性等同于原始的模板字符串解析后得到的数组。
作为函数,String.raw()的代码实现基本如下。
String.raw = function (strings, ...values) {let output = '';let index;for (index = 0; index < values.length; index++) {output += strings.raw[index] + values[index];}output += strings.raw[index]return output;
}
实例方法:codePointAt()
JavaScript 内部,字符以 UTF-16 的格式储存,每个字符固定为2个字节。对于那些需要4个字节储存的字符(Unicode 码点大于0xFFFF的字符),JavaScript 会认为它们是两个字符。
var s = "𠮷";s.length // 2
s.charAt(0) // ''
s.charAt(1) // ''
s.charCodeAt(0) // 55362
s.charCodeAt(1) // 57271
上面代码中,汉字“𠮷”(注意,这个字不是“吉祥”的“吉”)的码点是0x20BB7,UTF-16 编码为0xD842 0xDFB7(十进制为55362 57271),需要4个字节储存。对于这种4个字节的字符,JavaScript 不能正确处理,字符串长度会误判为2,而且charAt()方法无法读取整个字符,charCodeAt()方法只能分别返回前两个字节和后两个字节的值。
ES6 提供了codePointAt()方法,能够正确处理 4 个字节储存的字符,返回一个字符的码点。
let s = '𠮷a';s.codePointAt(0) // 134071
s.codePointAt(1) // 57271s.codePointAt(2) // 97
codePointAt()方法的参数,是字符在字符串中的位置(从 0 开始)。上面代码中,JavaScript 将“𠮷a”视为三个字符,codePointAt 方法在第一个字符上,正确地识别了“𠮷”,返回了它的十进制码点 134071(即十六进制的20BB7)。在第二个字符(即“𠮷”的后两个字节)和第三个字符“a”上,codePointAt()方法的结果与charCodeAt()方法相同。
总之,codePointAt()方法会正确返回 32 位的 UTF-16 字符的码点。对于那些两个字节储存的常规字符,它的返回结果与charCodeAt()方法相同。
codePointAt()方法返回的是码点的十进制值,如果想要十六进制的值,可以使用toString()方法转换一下。
let s = '𠮷a';s.codePointAt(0).toString(16) // "20bb7"
s.codePointAt(2).toString(16) // "61"
你可能注意到了,codePointAt()方法的参数,仍然是不正确的。比如,上面代码中,字符a在字符串s的正确位置序号应该是 1,但是必须向codePointAt()方法传入 2。解决这个问题的一个办法是使用for...of循环,因为它会正确识别 32 位的 UTF-16 字符。
let s = '𠮷a';
for (let ch of s) {console.log(ch.codePointAt(0).toString(16));
}
// 20bb7
// 61
另一种方法也可以,使用扩展运算符(...)进行展开运算。
let arr = [...'𠮷a']; // arr.length === 2
arr.forEach(ch => console.log(ch.codePointAt(0).toString(16))
);
// 20bb7
// 61
codePointAt()方法是测试一个字符由两个字节还是由四个字节组成的最简单方法。
function is32Bit(c) {return c.codePointAt(0) > 0xFFFF;
}is32Bit("𠮷") // true
is32Bit("a") // false
实例方法:normalize()
许多欧洲语言有语调符号和重音符号。为了表示它们,Unicode 提供了两种方法。一种是直接提供带重音符号的字符,比如Ǒ(\u01D1)。另一种是提供合成符号(combining character),即原字符与重音符号的合成,两个字符合成一个字符,比如O(\u004F)和ˇ(\u030C)合成Ǒ(\u004F\u030C)。
这两种表示方法,在视觉和语义上都等价,但是 JavaScript 不能识别。
'\u01D1'==='\u004F\u030C' //false'\u01D1'.length // 1
'\u004F\u030C'.length // 2
上面代码表示,JavaScript 将合成字符视为两个字符,导致两种表示方法不相等。
ES6 提供字符串实例的normalize()方法,用来将字符的不同表示方法统一为同样的形式,这称为 Unicode 正规化。
'\u01D1'.normalize() === '\u004F\u030C'.normalize()
// true
normalize方法可以接受一个参数来指定normalize的方式,参数的四个可选值如下。
NFC,默认参数,表示“标准等价合成”(Normalization Form Canonical Composition),返回多个简单字符的合成字符。所谓“标准等价”指的是视觉和语义上的等价。NFD,表示“标准等价分解”(Normalization Form Canonical Decomposition),即在标准等价的前提下,返回合成字符分解的多个简单字符。NFKC,表示“兼容等价合成”(Normalization Form Compatibility Composition),返回合成字符。所谓“兼容等价”指的是语义上存在等价,但视觉上不等价,比如“囍”和“喜喜”。(这只是用来举例,normalize方法不能识别中文。)NFKD,表示“兼容等价分解”(Normalization Form Compatibility Decomposition),即在兼容等价的前提下,返回合成字符分解的多个简单字符。
'\u004F\u030C'.normalize('NFC').length // 1
'\u004F\u030C'.normalize('NFD').length // 2
上面代码表示,NFC参数返回字符的合成形式,NFD参数返回字符的分解形式。
不过,normalize方法目前不能识别三个或三个以上字符的合成。这种情况下,还是只能使用正则表达式,通过 Unicode 编号区间判断。
实例方法:includes(), startsWith(), endsWith()
传统上,JavaScript 只有indexOf方法,可以用来确定一个字符串是否包含在另一个字符串中。ES6 又提供了三种新方法。
- includes():返回布尔值,表示是否找到了参数字符串。
- startsWith():返回布尔值,表示参数字符串是否在原字符串的头部。
- endsWith():返回布尔值,表示参数字符串是否在原字符串的尾部。
let s = 'Hello world!';s.startsWith('Hello') // true
s.endsWith('!') // true
s.includes('o') // true
这三个方法都支持第二个参数,表示开始搜索的位置。
let s = 'Hello world!';s.startsWith('world', 6) // true
s.endsWith('Hello', 5) // true
s.includes('Hello', 6) // false
上面代码表示,使用第二个参数n时,endsWith的行为与其他两个方法有所不同。它针对前n个字符,而其他两个方法针对从第n个位置直到字符串结束。
实例方法:repeat()
repeat方法返回一个新字符串,表示将原字符串重复n次。
'x'.repeat(3) // "xxx"
'hello'.repeat(2) // "hellohello"
'na'.repeat(0) // ""
参数如果是小数,会被取整。
'na'.repeat(2.9) // "nana"
如果repeat的参数是负数或者Infinity,会报错。
'na'.repeat(Infinity)
// RangeError
'na'.repeat(-1)
// RangeError
但是,如果参数是 0 到-1 之间的小数,则等同于 0,这是因为会先进行取整运算。0 到-1 之间的小数,取整以后等于-0,repeat视同为 0。
'na'.repeat(-0.9) // ""
参数NaN等同于 0。
'na'.repeat(NaN) // ""
如果repeat的参数是字符串,则会先转换成数字。
'na'.repeat('na') // ""
'na'.repeat('3') // "nanana"
实例方法:padStart(),padEnd()
ES2017 引入了字符串补全长度的功能。如果某个字符串不够指定长度,会在头部或尾部补全。padStart()用于头部补全,padEnd()用于尾部补全。
'x'.padStart(5, 'ab') // 'ababx'
'x'.padStart(4, 'ab') // 'abax''x'.padEnd(5, 'ab') // 'xabab'
'x'.padEnd(4, 'ab') // 'xaba'
上面代码中,padStart()和padEnd()一共接受两个参数,第一个参数是字符串补全生效的最大长度,第二个参数是用来补全的字符串。
如果原字符串的长度,等于或大于最大长度,则字符串补全不生效,返回原字符串。
'xxx'.padStart(2, 'ab') // 'xxx'
'xxx'.padEnd(2, 'ab') // 'xxx'
如果用来补全的字符串与原字符串,两者的长度之和超过了最大长度,则会截去超出位数的补全字符串。
'abc'.padStart(10, '0123456789')
// '0123456abc'
如果省略第二个参数,默认使用空格补全长度。
'x'.padStart(4) // ' x'
'x'.padEnd(4) // 'x '
padStart()的常见用途是为数值补全指定位数。下面代码生成 10 位的数值字符串。
'1'.padStart(10, '0') // "0000000001"
'12'.padStart(10, '0') // "0000000012"
'123456'.padStart(10, '0') // "0000123456"
另一个用途是提示字符串格式。
'12'.padStart(10, 'YYYY-MM-DD') // "YYYY-MM-12"
'09-12'.padStart(10, 'YYYY-MM-DD') // "YYYY-09-12"
实例方法:trimStart(),trimEnd()
ES2019 对字符串实例新增了trimStart()和trimEnd()这两个方法。它们的行为与trim()一致,trimStart()消除字符串头部的空格,trimEnd()消除尾部的空格。它们返回的都是新字符串,不会修改原始字符串。
const s = ' abc ';s.trim() // "abc"
s.trimStart() // "abc "
s.trimEnd() // " abc"
上面代码中,trimStart()只消除头部的空格,保留尾部的空格。trimEnd()也是类似行为。
除了空格键,这两个方法对字符串头部(或尾部)的 tab 键、换行符等不可见的空白符号也有效。
浏览器还部署了额外的两个方法,trimLeft()是trimStart()的别名,trimRight()是trimEnd()的别名。
实例方法:matchAll()
matchAll()方法返回一个正则表达式在当前字符串的所有匹配,详见《正则的扩展》的一章。
实例方法:replaceAll()
历史上,字符串的实例方法replace()只能替换第一个匹配。
'aabbcc'.replace('b', '_')
// 'aa_bcc'
上面例子中,replace()只将第一个b替换成了下划线。
如果要替换所有的匹配,不得不使用正则表达式的g修饰符。
'aabbcc'.replace(/b/g, '_')
// 'aa__cc'
正则表达式毕竟不是那么方便和直观,ES2021 引入了replaceAll()方法,可以一次性替换所有匹配。
'aabbcc'.replaceAll('b', '_')
// 'aa__cc'
它的用法与replace()相同,返回一个新字符串,不会改变原字符串。
String.prototype.replaceAll(searchValue, replacement)
上面代码中,searchValue是搜索模式,可以是一个字符串,也可以是一个全局的正则表达式(带有g修饰符)。
如果searchValue是一个不带有g修饰符的正则表达式,replaceAll()会报错。这一点跟replace()不同。
// 不报错
'aabbcc'.replace(/b/, '_')// 报错
'aabbcc'.replaceAll(/b/, '_')
上面例子中,/b/不带有g修饰符,会导致replaceAll()报错。
replaceAll()的第二个参数replacement是一个字符串,表示替换的文本,其中可以使用一些特殊字符串。
$&:匹配的字符串。$`:匹配结果前面的文本。$':匹配结果后面的文本。$n:匹配成功的第n组内容,n是从1开始的自然数。这个参数生效的前提是,第一个参数必须是正则表达式。$$:指代美元符号$。
下面是一些例子。
// $& 表示匹配的字符串,即`b`本身
// 所以返回结果与原字符串一致
'abbc'.replaceAll('b', '$&')
// 'abbc'// $` 表示匹配结果之前的字符串
// 对于第一个`b`,$` 指代`a`
// 对于第二个`b`,$` 指代`ab`
'abbc'.replaceAll('b', '$`')
// 'aaabc'// $' 表示匹配结果之后的字符串
// 对于第一个`b`,$' 指代`bc`
// 对于第二个`b`,$' 指代`c`
'abbc'.replaceAll('b', `$'`)
// 'abccc'// $1 表示正则表达式的第一个组匹配,指代`ab`
// $2 表示正则表达式的第二个组匹配,指代`bc`
'abbc'.replaceAll(/(ab)(bc)/g, '$2$1')
// 'bcab'// $$ 指代 $
'abc'.replaceAll('b', '$$')
// 'a$c'
replaceAll()的第二个参数replacement除了为字符串,也可以是一个函数,该函数的返回值将替换掉第一个参数searchValue匹配的文本。
'aabbcc'.replaceAll('b', () => '_')
// 'aa__cc'
上面例子中,replaceAll()的第二个参数是一个函数,该函数的返回值会替换掉所有b的匹配。
这个替换函数可以接受多个参数。第一个参数是捕捉到的匹配内容,第二个参数捕捉到是组匹配(有多少个组匹配,就有多少个对应的参数)。此外,最后还可以添加两个参数,倒数第二个参数是捕捉到的内容在整个字符串中的位置,最后一个参数是原字符串。
const str = '123abc456';
const regex = /(\d+)([a-z]+)(\d+)/g;function replacer(match, p1, p2, p3, offset, string) {return [p1, p2, p3].join(' - ');
}str.replaceAll(regex, replacer)
// 123 - abc - 456
上面例子中,正则表达式有三个组匹配,所以replacer()函数的第一个参数match是捕捉到的匹配内容(即字符串123abc456),后面三个参数p1、p2、p3则依次为三个组匹配。
实例方法:at()
at()方法接受一个整数作为参数,返回参数指定位置的字符,支持负索引(即倒数的位置)。
const str = 'hello';
str.at(1) // "e"
str.at(-1) // "o"
如果参数位置超出了字符串范围,at()返回undefined。
该方法来自数组添加的at()方法,目前还是一个第三阶段的提案,可以参考《数组》一章的介绍。
相关文章:

49:字符串的新增方法
字符串的新增方法 String.fromCodePoint()String.raw()实例方法:codePointAt()实例方法:normalize()[实例方法:includes(), startsWith(), endsWith()](https://es6.ruanyifeng.com/#docs/string-methods#实例方法:includes(), s…...
Kaggle图表内容识别大赛TOP方案汇总
赛题名称:Benetech - Making Graphs Accessible 赛题链接:https://www.kaggle.com/competitions/benetech-making-graphs-accessible 赛题背景 数以百万计的学生有学习、身体或视力障碍,导致人们无法阅读传统印刷品。这些学生无法访问科学…...
DAY2,Qt(继续完善登录框,信号与槽的使用 )
1.继续完善登录框,当登录成功时,关闭登录界面,跳转到新的界面中,来回切换页面; ---mychat.h chatroom.h---两个页面头文件 #ifndef MYCHAT_H #define MYCHAT_H#include <QWidget> #include <QDebug> /…...

【设计模式】设计原则-开闭原则
单一职责原则 定义 当应用的需求改变时,在不修改软件实体的源代码或者二进制代码的前提下,可以扩展模块的功能,使其满足新的需求。作用 1、方便测试;测试时只需要对扩展的代码进行测试。 2、提高代码的可复用性;粒…...

【2500. 删除每行中的最大值】
来源:力扣(LeetCode) 描述: 给你一个 m x n 大小的矩阵 grid ,由若干正整数组成。 执行下述操作,直到 grid 变为空矩阵: 从每一行删除值最大的元素。如果存在多个这样的值,删除其…...

Superset部署
Superset部署 1、安装依赖 (superset) [hadoopnode1 ~]$ yum install -y python-setuptools (superset) [hadoopnode1 ~]$ yum install -y gcc gcc-c libffi-devel python-devel python-pip python-wheel openssl-devel2、安装Superset 2.1 安装(更新)…...

Python3 学习笔记 ~ 怎样打印字符串
Python中变量的打印方法_python打印变量_清欢依旧的博客-CSDN博客 a 9 b 2print(f"{a} / {b} {a/b}") print(a, "//", b, "", (a//b))a -9 print(f"{a} / {b} {a/b}") print(a, "//", b, "", (a//b))...

postgresql安装
安装postgresql Linux下载安装地址 https://www.postgresql.org/download/linux/redhat/ 指定对应版本,指定完成后会生成对应的安装语句 下载对应的包 yum –y install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-l…...

ElasticSearch之IK分词器安装以及使用介绍
文章目录 一、IK 分词器简介1. 支持细粒度分词:2. 支持多种分词模式:3. 支持自定义词典:4. 支持拼音分词:5. 易于集成和使用: 二、安装步骤1、下载 IK 分词器插件:2、安装 IK 分词器插件:3. 安装…...
Linux系统安装部署Jenkins详细教程(图文讲解)
前言:最近需要使用Jenkins部署项目,所以想出一篇关于如何使用Linux系统安装部署Jenkins的相关教程,整体部署过程还是挺顺利的,特此分享一下! 目录 一、安装JDK11和Tomcat11 二、准备Jenkins安装包 三、部署Jenkins…...
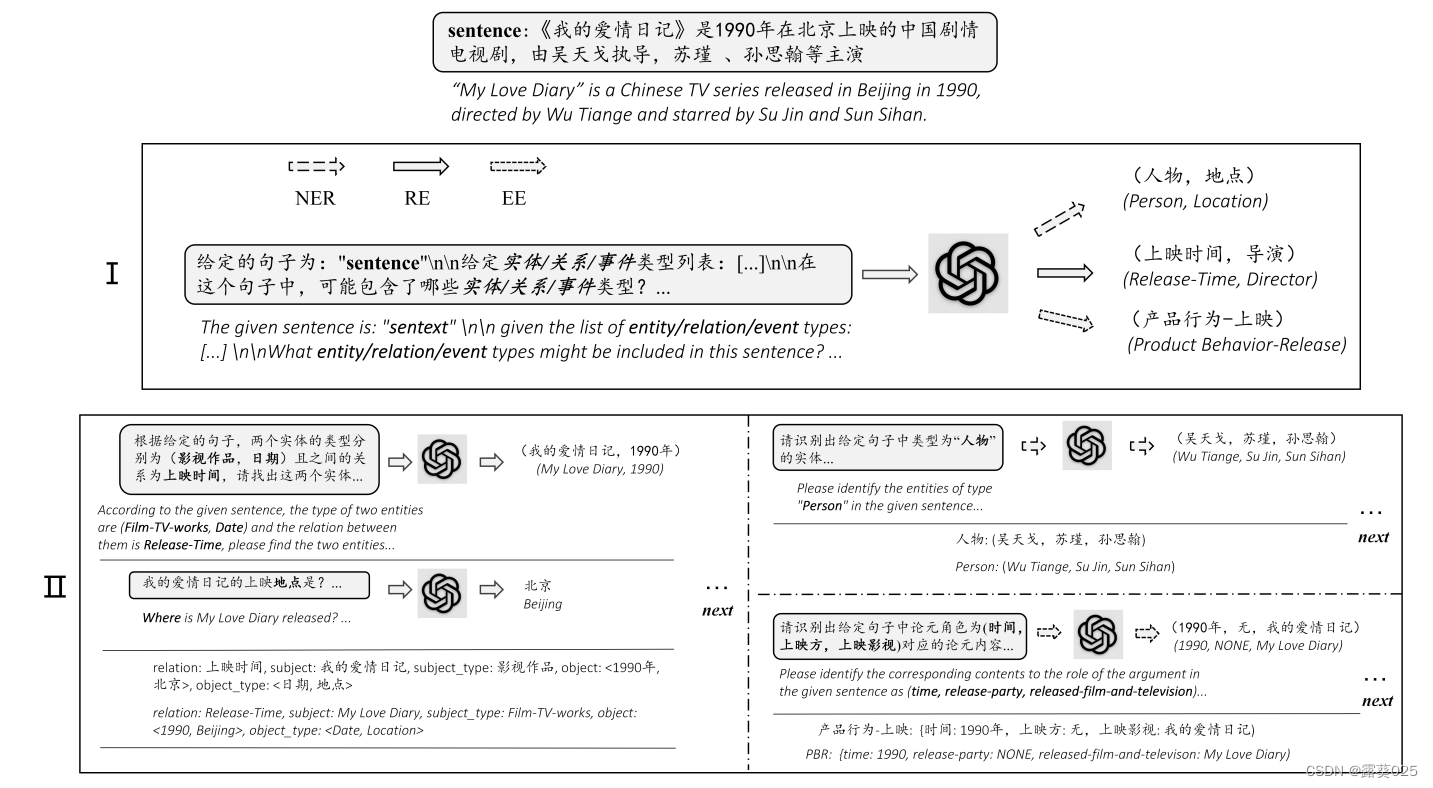
基于ChatGPT聊天的零样本信息提取7.25
基于ChatGPT聊天的零样本信息提取 摘要介绍ChatIE用于零样本IE的多轮 QA 实验总结 摘要 零样本信息提取(IE)旨在从未注释的文本中构建IE系统。由于很少涉及人类干预,因此具有挑战性。 零样本IE减少了数据标记所需的时间和工作量。最近对大型…...
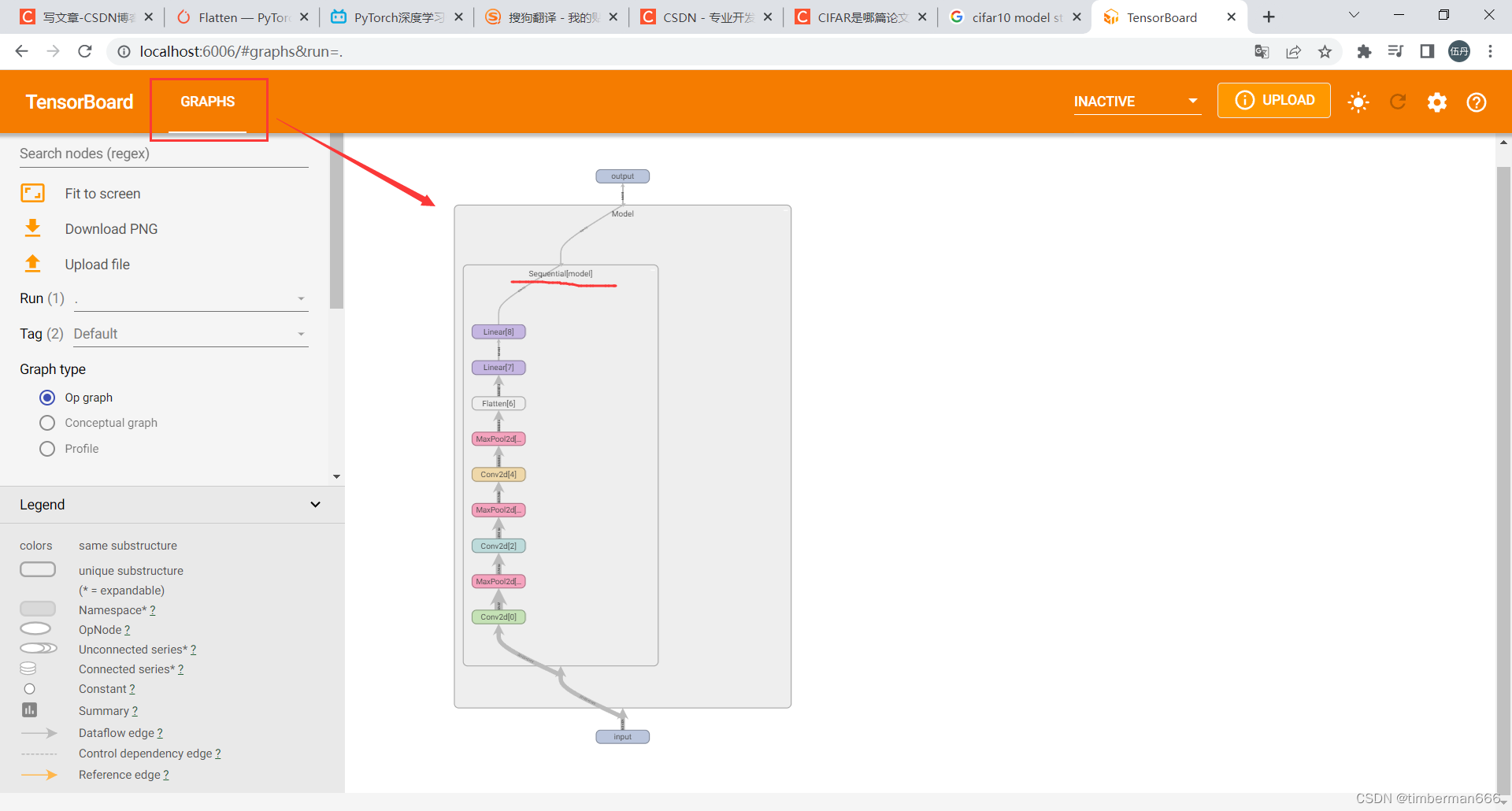
Pytorch个人学习记录总结 08
目录 神经网络-搭建小实战和Sequential的使用 版本1——未用Sequential 版本2——用Sequential 神经网络-搭建小实战和Sequential的使用 torch.nn.Sequential的官方文档地址,模块将按照它们在构造函数中传递的顺序添加。代码实现的是下图: 版本1—…...
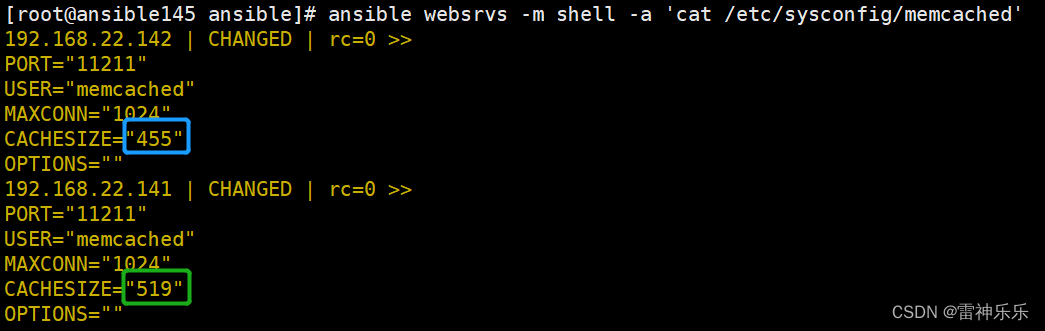
Ansible自动化运维学习——综合练习
目录 (一)练习一 1.新建一个role——app 2.创建文件 3.删除之前安装的httpd服务和apache用户 4.准备tasks任务 (1)创建组group.yml (2)创建用户user.yml (3)安装程序yum.yml (4)修改模板httpd.conf.j2 (5)编写templ.yml (6)编写start.yml (7)编写copyfile.yml (8…...

Java中正则表达式
一、概念 正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。在众多语言中…...
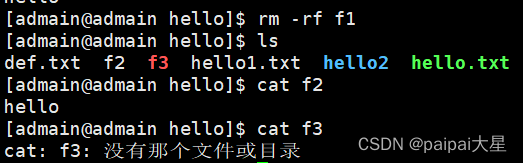
13 硬链接和软链接
13.1 硬链接和软链接的区别 硬链接:A---B,假设B是A的硬链接,那么只要存在一个,无论删除哪一个,文件都能访问得到。 软链接:类似于快捷方式,删除源文件,快捷方式就访问不了。 13.2 创…...

智能合约安全审计
智能合约安全审计的意义 智能合约审计用于整个 DeFi 生态系统,通过对协议代码的深入审查,可以帮助解决识别错误、低效代码以及这些问题。智能合约具有不可篡改的特点,这使得审计成为任何区块链项目安全流程的关键部分。 代码审计对任何应用…...

矩阵置零(力扣)思维 JAVA
给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。 输入:matrix [[1,1,1],[1,0,1],[1,1,1]] 输出:[[1,0,1],[0,0,0],[1,0,1]] 输入:matrix [[0,1,2,0],[3,4,5,2],[…...

centos制作openssh 9.3p2 rpm包
标题使用源码制作openssh 9.3p2 的rpm包 准备: 操作系统:CentOS Linux release 7.4.1708 (Core) #测试发现rpm包要在什么系统安装需要就需要在什么系统上制作 工具软件:rpm-build 源码文件:openssh-9.3p2.tar.gz x11-ssh-askpas…...
)
uni-app:切换页面刷新,返回上一页刷新(onShow钩子函数的使用)
切换页面刷新:通过onShow()便可实现 返回上一页通过uni.navigateBack({delta: 1});实现 以返回上一页刷新为例 从B页面返回上一页到A页面 在A页面写入方法refreshHandler() methods: { // 执行刷新逻辑refreshHandler() {uni.request({url: getApp().globalData.…...
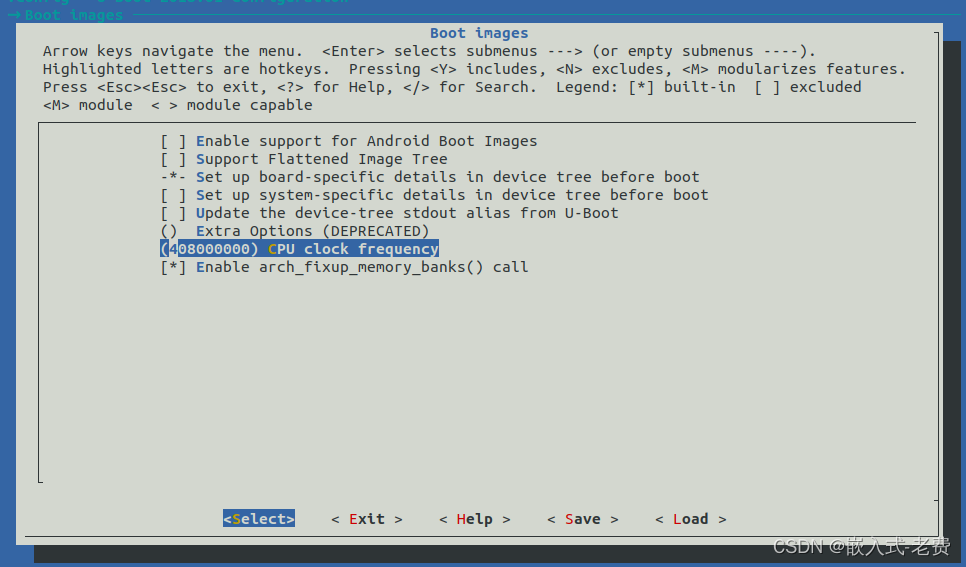
全志F1C200S嵌入式驱动开发(调整cpu频率和dram频率)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing @163.com】 f1c200s默认的cpu频率是408M,默认的dram频率是156M。这两个数值,坦白说,都算不上特别高的频率。因为我们的晶振是24M输入,所以408/24=17,相当于整个cpu的频率只是晶振倍频了17…...

Agent Skill 按需加载:架构设计与实现解析
❝当 AI Agent 需要的知识越来越多,把一切都塞进 System Prompt 显然不是个好主意。本文从架构设计的角度出发,深入探讨一种优雅的解法——「Skill 渐进式加载机制」。❞一、问题:当 Agent 需要"十八般武艺"构建一个功能丰富的 AI …...
)
QT无边框窗口圆角化实战:用paintEvent和样式表两种方法,打造你的专属UI(附完整代码)
QT无边框圆角窗口开发指南:从原理到实战的深度解析 在当今追求极致用户体验的桌面应用开发领域,无边框圆角窗口已经成为现代化UI设计的标配元素。从音乐播放器的沉浸式界面到社交软件的柔和视觉风格,圆角设计不仅能够降低用户的视觉疲劳&…...

**发散创新:基于Go语言实现的Raft共识算法实战解析**在分布式系统中,**一
发散创新:基于Go语言实现的Raft共识算法实战解析 在分布式系统中,一致性是核心挑战之一。而Raft共识算法因其简洁性和可理解性,已成为当前主流的分布式一致性协议(如etcd、Consul均采用Raft)。本文将带你深入用Go语言从…...

2025届学术党必备的六大降重复率神器横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当前,人工智能技术快速发展,这为毕业论文写作提供了新的辅助路径&…...

Cobalt Strike实战指南:从基础配置到高级渗透技巧
1. Cobalt Strike基础入门 第一次接触Cobalt Strike时,我被它强大的功能震撼到了。这款工具不仅能够模拟高级威胁攻击,还能进行红队协作操作,是渗透测试领域的瑞士军刀。记得刚开始搭建环境时,我在Kali和Windows双系统间反复切换&…...

从零开始:在Ubuntu 18.04上正确配置CUDA 11.7和bitsandbytes 0.38.0的完整指南
从零构建Ubuntu 18.04下的AI开发环境:CUDA 11.7与bitsandbytes 0.38.0深度配置手册 在深度学习领域,环境配置往往是项目推进的第一道门槛。特别是当我们需要使用bitsandbytes这样的高性能量化工具时,CUDA环境的纯净性与版本匹配度直接决定了后…...

AI赋能算法创新:让快马大模型为你的智能车竞赛方案提供灵感
AI赋能算法创新:让快马大模型为你的智能车竞赛方案提供灵感 智能车竞赛一直是技术爱好者展示创新能力的舞台,但面对复杂的赛道和实时控制需求,很多队伍在算法设计上容易陷入瓶颈。最近我在准备比赛时,发现InsCode(快马)平台的AI辅…...

3个技巧让你轻松掌控暗黑2角色命运:d2s-editor的存档修改艺术
3个技巧让你轻松掌控暗黑2角色命运:d2s-editor的存档修改艺术 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 在《暗黑破坏神2》的冒险旅程中,你是否曾因误加属性点而让精心培养的角色沦为废号࿱…...

MAA助手跨平台部署与自动化实践指南
MAA助手跨平台部署与自动化实践指南 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://gitcode.com/GitHub_Trending/ma/…...

利用快马AI快速生成Android Studio天气预报应用原型
最近在尝试开发一个简单的天气预报应用,发现用传统方式从零开始搭建Android项目框架特别耗时。特别是Gradle配置和各种依赖项的引入,经常要反复调试。后来尝试了InsCode(快马)平台,发现它的AI生成功能能极大提升原型开发效率,这里…...