中文分词入门:使用IK分词器进行文本分词(附Java代码示例)
1. 介绍
中文分词是将连续的中文文本切分成一个个独立的词语的过程,是中文文本处理的基础。IK分词器是一个高效准确的中文分词工具,采用了"正向最大匹配"算法,并提供了丰富的功能和可定制选项。
2. IK分词器的特点
- 细粒度和颗粒度的分词模式选择。
- 可自定义词典,提高分词准确性。
- 支持中文人名、地名等专有名词的识别。
- 适用于中文搜索、信息检索、文本挖掘等应用领域。
3. 引入IK分词器的依赖
IK分词器的实现是基于Java语言的,所以你需要下载IK分词器的jar包,并将其添加到你的Java项目的构建路径中。你可以从IK分词器的官方网站或GitHub仓库上获取最新的jar包。
<dependency><groupId>org.wltea</groupId><artifactId>ik-analyzer</artifactId><version>6.6.6</version>
</dependency>
4. 示例代码
我们提供了一个简单的Java示例代码,展示了如何使用IK分词器进行中文文本分词。示例代码包括初始化分词器、输入待分词文本、获取分词结果等步骤。读者可以根据该示例快速上手使用IK分词器。
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;import java.io.IOException;
import java.io.StringReader;public class IKDemo {public static void main(String[] args) {String text = "我喜欢使用IK分词器进行中文分词。";try (StringReader reader = new StringReader(text)) {IKSegmenter segmenter = new IKSegmenter(reader, true);Lexeme lexeme;while ((lexeme = segmenter.next()) != null) {System.out.println(lexeme.getLexemeText());}} catch (IOException e) {e.printStackTrace();}}
}
在上述示例中,我们首先定义了一个待分词的文本字符串。然后,我们创建一个StringReader对象,将待分词的文本作为输入。接下来,我们创建一个IKSegmenter对象,并传入StringReader对象和true参数,表示启用智能分词模式。
在使用IKSegmenter对象进行分词时,我们使用next()方法获取下一个分词结果,返回一个Lexeme对象。我们通过调用getLexemeText()方法获取分词结果的文本内容,并将其打印输出
我
喜欢
使用
IK
分词器
进行
中文
分词
这个示例演示了如何使用IK分词器对中文文本进行基本的分词处理。你可以根据需要扩展和定制分词器的功能,例如添加自定义词典、设置分词模式等,以满足特定的分词需求。
5.扩展用法:自定义词片
IK分词器允许自定义词典,以便更好地适应特定的分词需求。通过添加自定义词典,你可以确保IK分词器能够识别和切分你所需的特定词汇。
IK分词器提供两种方式来添加自定义词典:
- 扩展词典:你可以创建一个文本文件,每行添加一个词汇,用于扩展分词器的默认词典。每个词汇可以包含一个或多个中文词语,并使用空格或其他分隔符进行分隔。然后,通过
Configuration类的setMainDictionary方法将自定义词典文件加载到IK分词器中。 - 补充词典:在某些情况下,你可能需要临时添加一些词汇,而不想修改默认的词典。在这种情况下,你可以使用
IKSegmenter的addSupplementDictionary方法,动态地添加补充词典。补充词典中的词汇将会在分词过程中生效,但并不会被永久保存。
通过自定义词典,你可以增加或修改IK分词器的词汇库,从而使其更准确地切分特定的词汇。这对于领域特定的文本处理任务尤为重要,例如特定行业的术语、品牌名称等。
示例代码:
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
import org.wltea.analyzer.core.Lexeme;import java.io.IOException;
import java.io.StringReader;public class IKDemo {public static void main(String[] args) {String text = "我喜欢使用IK分词器进行中文分词。";// 添加自定义词典String customDictionary = "自定义词\n喜欢使用\n中文分词";IKSegmenter segmenter = new IKSegmenter(new StringReader(text), true);segmenter.setMainDictionary(customDictionary);try {Lexeme lexeme;while ((lexeme = segmenter.next()) != null) {System.out.println(lexeme.getLexemeText());}} catch (IOException e) {e.printStackTrace();}}
}
在上述示例中,我们首先定义了一个待分词的文本字符串。然后,我们创建了一个自定义词典字符串,包含了我们希望添加到分词器中的自定义词汇。在这个例子中,我们添加了词汇"自定义词"、“喜欢使用"和"中文分词”。
接下来,我们创建了一个IKSegmenter对象,将待分词的文本和一个布尔值参数传递给构造函数。该布尔值参数表示是否使用智能分词模式。
然后,我们使用setMainDictionary方法将自定义词典字符串设置为主词典。这样,自定义词典中的词汇将会被加载到IK分词器中,并在分词过程中起作用。
最后,我们使用next方法获取下一个分词结果,并通过getLexemeText方法获取分词结果的文本内容,并将其打印输出。
运行以上代码,你将看到以下输出结果:
我
喜欢使用
IK
分词器
进行
中文分词
6. 结论
IK分词器是一个功能强大的中文分词工具,可广泛应用于各种中文文本处理任务。本文通过介绍IK分词器的特点和使用方法,帮助读者了解和掌握中文分词的基本概念和操作。读者可以根据自己的需求扩展和定制IK分词器,以实现更精确和高效的中文分词效果。
在实际应用中,中文分词对于提高文本处理和信息检索的准确性和效率至关重要。通过使用IK分词器,我们可以更好地处理中文文本,从而提供更好的用户体验和结果。希望本文能为读者提供有价值的指导和启示,促进中文分词技术的应用和发展。
相关文章:
)
中文分词入门:使用IK分词器进行文本分词(附Java代码示例)
1. 介绍 中文分词是将连续的中文文本切分成一个个独立的词语的过程,是中文文本处理的基础。IK分词器是一个高效准确的中文分词工具,采用了"正向最大匹配"算法,并提供了丰富的功能和可定制选项。 2. IK分词器的特点 细粒度和颗粒…...
CTFSHOW web 信息收集
web入门的刷题 web1 教我们多看看源代码 web2 抓包 web3 抓包 web4 robots.txt robots.txt web5 phps源代码泄露 phps 就是php的源代码 用户无法访问 php 只可以通过phps来访问 web6 源代码备份 web7 git web8 svn web9 swp /index.php.swp web10 cookie web11 查域名…...
速锐得开发社区-新一代汽车网络通信技术CAN FD的特点归纳
随着汽车工业的快速发展,汽车逐渐走向智能化,功能也越来越丰富,例如特斯拉、比亚迪、理想汽车为代表,在车载导航、驻车雷达、胎压监测、倒车影像、无钥匙启动、定速巡航、自动泊车、高级辅助驾驶系统、自动驾驶、域控制器、智能网…...
Android adb shell 查看App内存(java堆内存/vss虚拟内存/详细的内存状况/内存快照hprof)和系统可用内存
1.adb shell 获取app 进程的pid adb shell "ps|grep com.xxx包名"根据某个渠道包,去查询对应的pid,如下所示: 2.通过adb shell 查看设备的java dalvik 堆内存的最大值 执行命令行: adb shell getprop dalvik.vm.h…...

java篇 类的进阶0x0A:万类之祖:Object 类
文章目录 万类之祖:Object 类hashCode() 与 equals()hashCode() 方法equals() 方法 vs. equals()String 的 equals() 为什么要重写 hashCode 和 equals 方法重写(覆盖)前 hashCode() 和 equals() 的作用什么情况下需要重写(覆盖&a…...

AVFoundation - 音频录制
文章目录 需要调用到麦克风方法,别忘记添加 Privacy - Microphone Usage Description @interface AudioRecorder ()<AVAudioRecorderDelegate>@property (strong, nonatomic) AVAudioRecorder *recorder;@end@implementation AudioRecorder- (void...
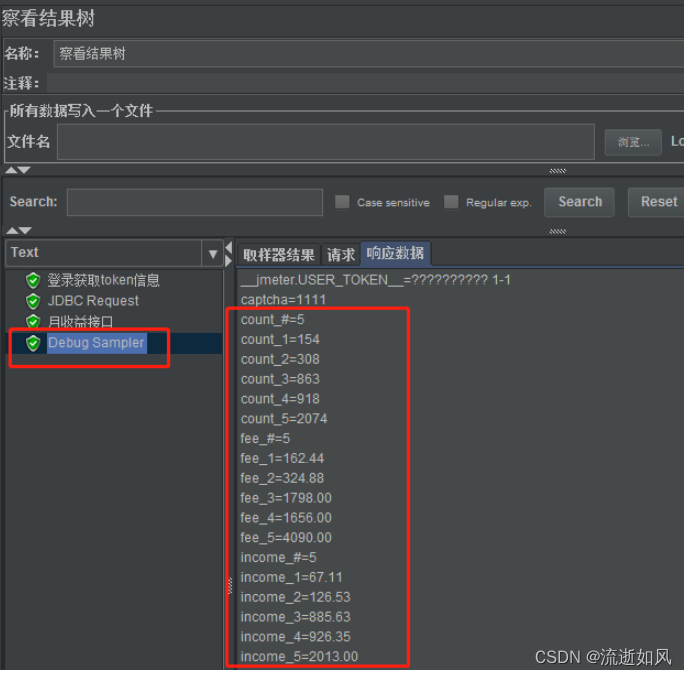
Jmeter+MySQL链接+JDBC Connection配置元件+使用
参考大大的博客学习:怎么用JMeter操作MySQL数据库?看完秒懂!_jmeter mysql_程序员馨馨的博客-CSDN博客 注:里面所有没打码的都是假数据,麻烦大家自行修改正确的信息。 一、背景 需要取数据库中的值,作为…...
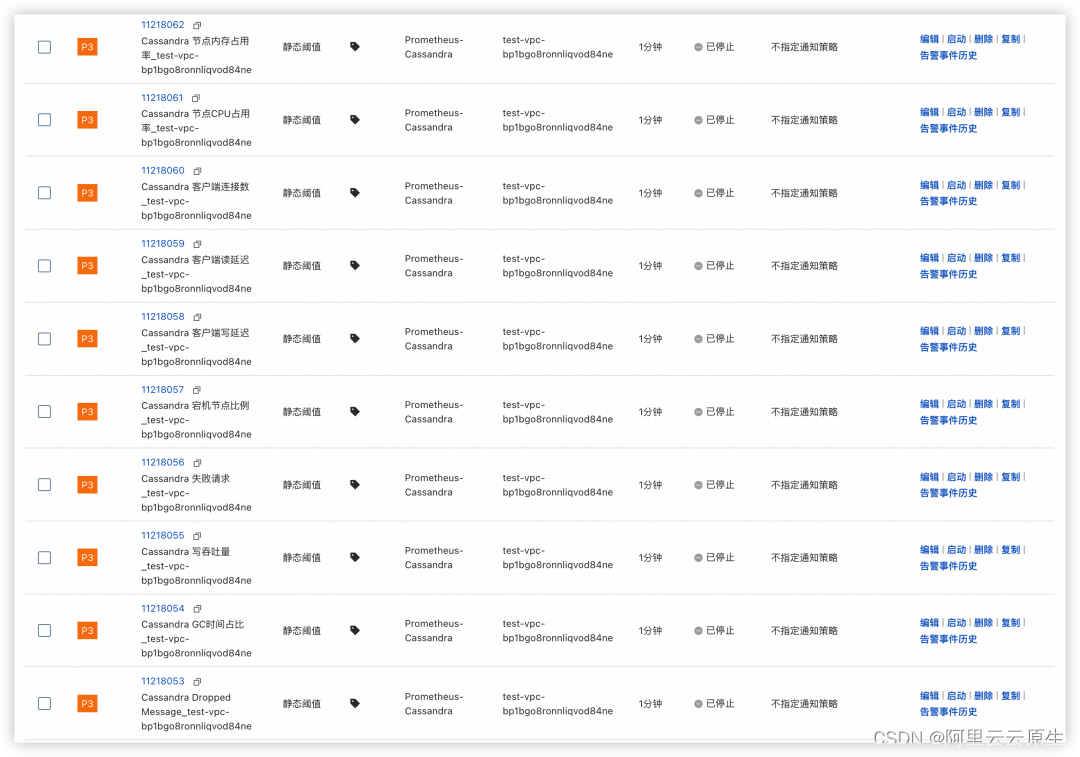
统一观测丨使用 Prometheus 监控 Cassandra 数据库最佳实践
作者:元格 本篇内容主要包括四部分:Cassandra 概览介绍、常见关键指标解读、常见告警规则解读、如何通过 Prometheus 建立相应监控体系。 Cassandra 简介 Cassandra 是什么? Apache Cassandra 是一个开源、分布式、去中心化、弹性可伸缩、…...

Hive视图
hive的视图 简介 hive的视图简单理解为逻辑上的表hive只支持逻辑视图,不支持物化视图视图存在的意义 对数据进行局部暴露(涉及隐私的数据不暴露)简化复杂查询 创建视图: create view if not exists v_1 as select uid,movie f…...

node中使用jsonwebtoken实现身份认证
在现代web应用中,用户身份认证是非常重要且必不可少的一环。而使用Node.js和Express框架,可以方便地实现用户身份认证。而在这个过程中,jsonwebtoken这个基于JWT协议的模块可以帮助我们实现安全且可靠的身份认证机制,可以让我们轻…...

pyspark笔记:读取 处理csv文件
pyspark cmd上的命令 1 读取文件 1.1 基本读取方式 注意读取出来的格式是Pyspark DataFrame,不是DataFrame,所以一些操作上是有区别的 1.1.1 format DataFrame spark.read.format("csv").option(name,value).load(path) format表示读取…...
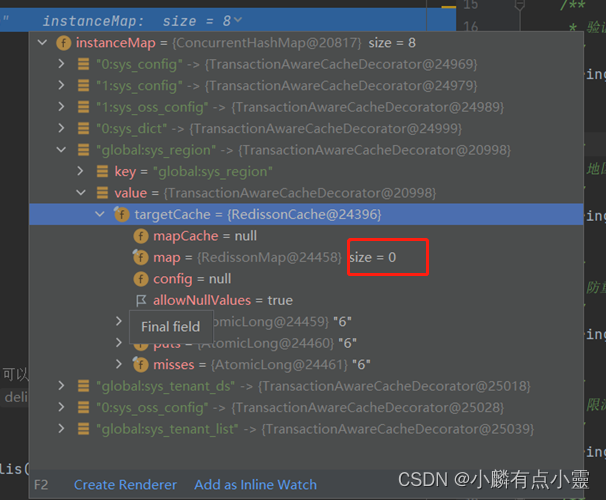
多租户分缓存处理
多租户redis缓存分租户处理 那么数据库方面已经做到了拦截,但是缓存还是没有分租户,还是通通一个文件夹里, 想实现上图效果,global文件夹里存的是公共缓存。 首先,那么就要规定一个俗称,缓存名字带有globa…...
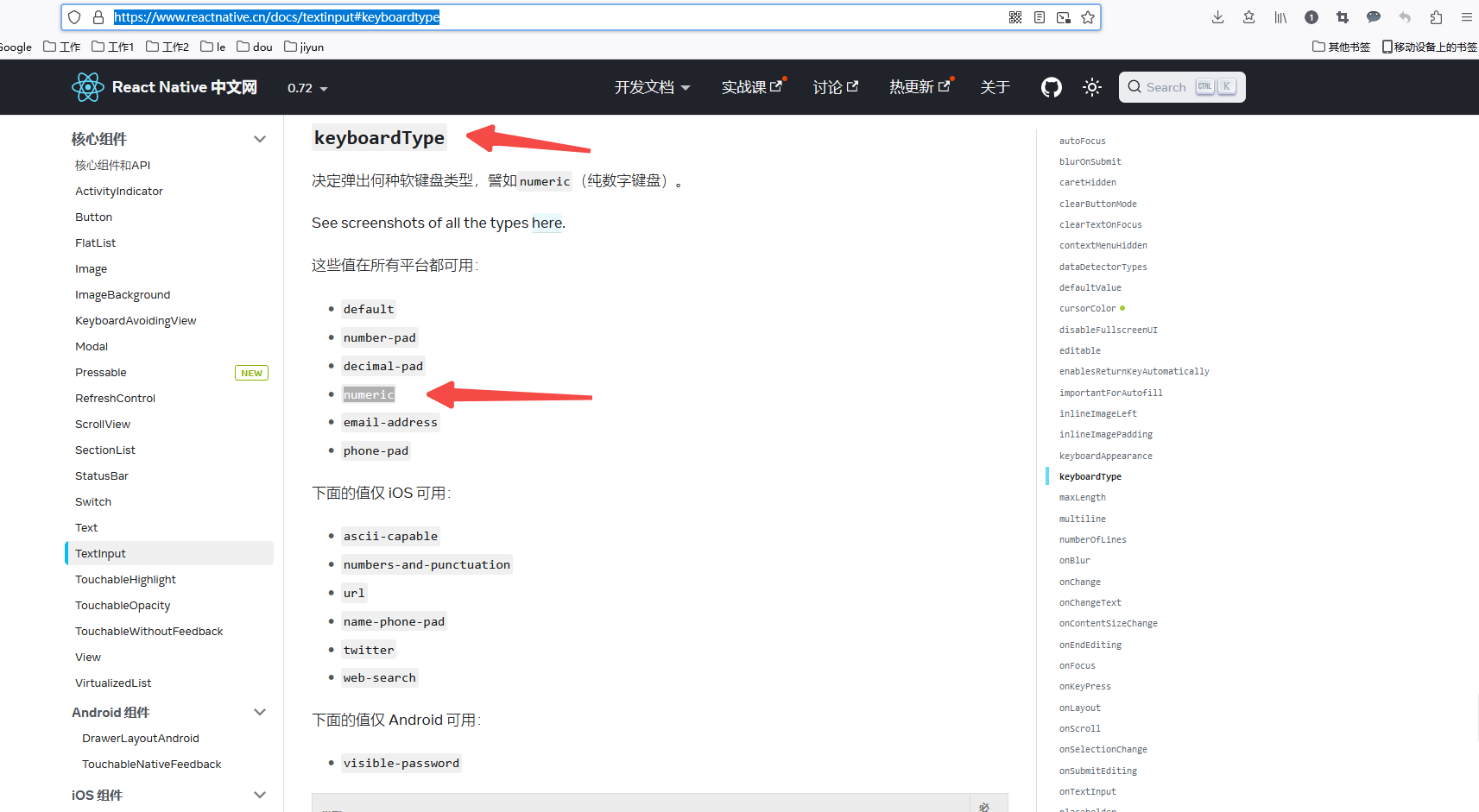
RN输入框默认设置数字键盘
<TextInput keyboardType"numeric"/> keyboardType 决定弹出何种软键盘类型,譬如numeric(纯数字键盘)。 See screenshots of all the types here. 这些值在所有平台都可用: defaultnumber-paddecimal-padnume…...

计算机网络——应用层
文章目录 **1 网络应用模型****2 域名系统DNS****3 文件传输协议FTP****4 电子邮件****4.1 电子邮件系统的组成结构****4.2 电子邮件格式与MIME****4.3 SMTP和POP3** **5 万维网WWW****5.1 HTTP** 1 网络应用模型 客户/服务器模型 C/S 服务器服务于许多来自其他称为客户机的主…...

【C++】写一个函数实现系统时间与输入时间进行比较
目录 1 代码 2 运行结果 时间比较函数: 输入为字符串2023-7-28,将字符串分解为年、月、日信息。 获取系统时间2023-7-24,然后将输入时间和系统时间进行比较,输出比较结果。 1 代码 #include <ctime> #include<iostream> #include<vector> using names…...
uniapp 微信小程序 navigationBarBackgroundColor 标题栏颜色渐变
大体思路: 第一步:“navigationStyle”:“custom” 第二步: template内 重点:给view添加ref“top” 第三步:添加渐变色样式 1、pages.json {"path" : "pages/user/user","style" : …...
----音视频暂停模块分析)
ffplay播放器剖析(7)----音视频暂停模块分析
文章目录 1. 暂停触发流程2. toggle_pause3. stream_toggle_pause 1. 暂停触发流程 1.通过SDL触发事件调用toggle_pause 2.toggle_pause调用stream_toggle_pause 3.stream_toggle_pause修改暂停变量 2. toggle_pause static void toggle_pause(VideoState *is) {stream_to…...
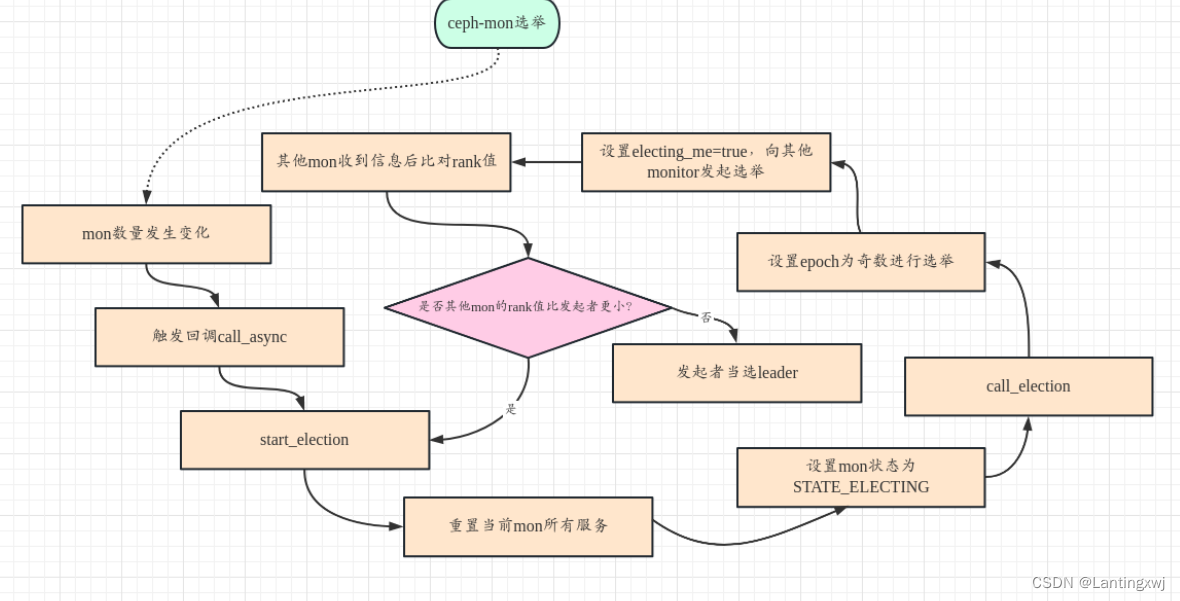
ceph-mon运行原理分析
一、流程:ceph-deploy部署ceph-mon组建集群 1.ceph-deploy部署ceph-mon的工作流程及首次启动 1)通过命令创建ceph-mon,命令为:ceph-deploy create mon keyring def mon(args):if args.subcommand create:mon_create(args)elif…...
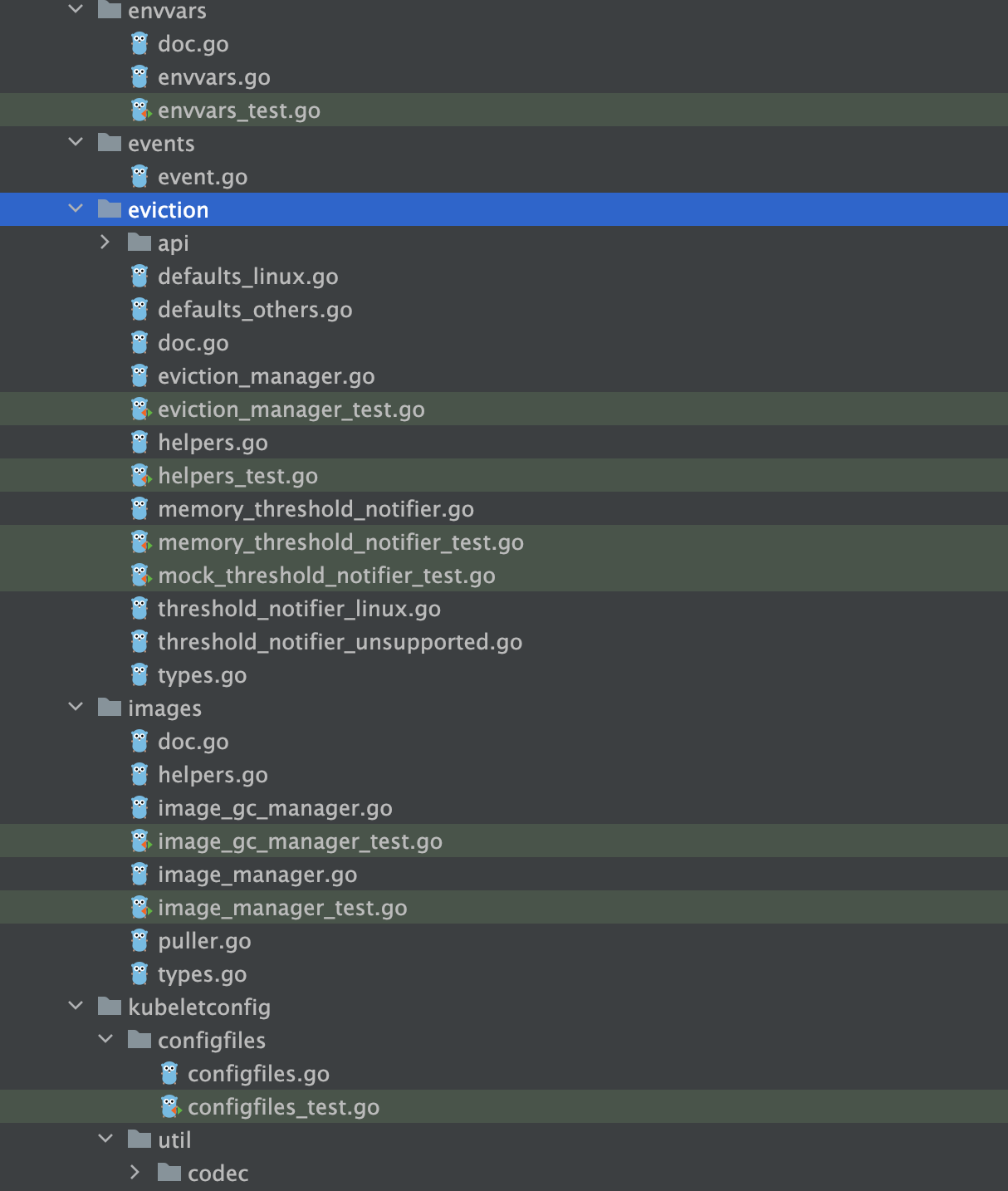
听GPT 讲K8s源代码--pkg(八)
k8s项目中 pkg/kubelet/envvars,pkg/kubelet/events,pkg/kubelet/eviction,pkg/kubelet/images,pkg/kubelet/kubeletconfig这些目录都是 kubelet 组件的不同功能模块所在的代码目录。 pkg/kubelet/envvars 目录中包含了与容器运行…...

差速驱动机器人的车轮里程计模型
一、说明 车轮测程法是指使用旋转编码器(即连接到车轮电机以测量旋转的传感器)的测程法(即估计运动和位置)。这是轮式机器人和自动驾驶汽车定位的有用技术。 在本文中,我们将通过探索差速驱动机器人的车轮里程计模型来深入研究车轮里...

如何5分钟为Unity游戏实现智能实时翻译:XUnity.AutoTranslator完整指南
如何5分钟为Unity游戏实现智能实时翻译:XUnity.AutoTranslator完整指南 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为外语游戏的语言障碍而烦恼吗?XUnity.AutoTranslator作…...

中文文献管理效率革命:Jasminum插件全方位应用指南
中文文献管理效率革命:Jasminum插件全方位应用指南 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 在学术研究的数字化…...

DeepSeek实战秘籍:从基础到高级的完整应用指南
写在前面 DeepSeek,这个由中国公司深度求索推出的大语言模型系列,自2025年初横空出世以来,以极低的训练成本达到媲美GPT-4级别的性能,震惊了全球AI业界。它不仅完全开源,还完全免费对公众开放使用,迅速成为…...

杰理之中控耳机支持通话中进行BLE广播的修改【篇】
修改ESCO和BLE广播的调度策略...

SDN南向接口协议深度解析:从OpenFlow到P4的演进与实战选型
1. SDN南向接口协议的技术演进之路 第一次接触SDN南向接口时,我被各种协议搞得晕头转向。直到在数据中心网络改造项目中踩过几次坑才明白,不同协议就像不同型号的螺丝刀——OpenFlow是精密钟表螺丝刀,OVSDB是家用多功能螺丝刀,NET…...

用WinDbg实战解析Windows内核:EPROCESS结构体里那些你意想不到的隐藏信息
用WinDbg实战解析Windows内核:EPROCESS结构体里那些你意想不到的隐藏信息 当你在分析一个可疑进程或进行漏洞挖掘时,Windows内核中的EPROCESS结构体就像一座金矿,蕴藏着大量关键信息。这个结构体远不止是进程的简单描述符,它包含了…...

PostgreSQL 安装指南:常见问题排查与实战解决方案
1. PostgreSQL安装前的准备工作 第一次接触PostgreSQL的朋友可能会觉得安装过程有点复杂,但其实只要做好准备工作,安装过程就会顺利很多。我在帮团队部署PostgreSQL环境时,发现90%的安装问题都源于前期准备不足。下面分享几个关键点ÿ…...

FPointer:嵌入式C语言轻量级带参回调机制
1. FPointer:面向嵌入式系统的轻量级泛型回调机制设计与实现1.1 设计动因与工程定位在裸机(Bare-Metal)或实时操作系统(如FreeRTOS、Zephyr)环境下,回调函数(Callback Function)是解…...

Windows下OpenClaw安装指南:一键对接Qwen3-4B-Thinking-2507-GPT-5-Codex-Distill-GGUF模型
Windows下OpenClaw安装指南:一键对接Qwen3-4B-Thinking-2507-GPT-5-Codex-Distill-GGUF模型 1. 为什么选择WindowsOpenClaw组合 去年我在帮一个创业团队搭建内部自动化工具时,第一次接触到OpenClaw。当时他们需要一套能自动处理客户反馈、生成日报的系…...

OpenClaw多任务调度:千问3.5-9B并行处理多个自动化流程
OpenClaw多任务调度:千问3.5-9B并行处理多个自动化流程 1. 为什么需要多任务调度? 去年夏天,我同时接手了三个技术项目:一个爬虫数据清洗任务、一个Markdown文档自动化整理工具,还有一个需要定期检查服务器日志的监控…...