hadoop之mapreduce详解
一、概述
优化前我们需要知道hadoop适合干什么活,适合什么场景,在工作中,我们要知道业务是怎样的,能才结合平台资源达到最有优化。除了这些我们当然还要知道mapreduce的执行过程,比如从文件的读取,map处理,shuffle过程,reduce处理,文件的输出或者存储。在工作中,往往平台的参数都是固定的,不可能为了某一个作业去修改整个平台的参数,所以在作业的执行过程中,需要对作业进行单独的设定,这样既不会对其他作业产生影响,也能很好的提高作业的性能,提高优化的灵活性。
现在回顾下hadoop的优势(适用场景):
1、可构建在廉价机器上,设备成本相对低
2、高容错性,HDFS将数据自动保存多个副本,副本丢失后,自动恢复,防止数据丢失或损坏
3、适合批处理,HDFS适合一次写入、多次查询(读取)的情况,适合在已有的数据进行多次分析,稳定性好
4、适合存储大文件,其中的大表示可以存储单个大文件,因为是分块存储,以及表示存储大量的数据
二、小文件优化
从概述中我们知道,很明显hadoop适合大文件的处理和存储,那为什么不适合小文件呢?
1、从存储方面来说:hadoop的存储每个文件都会在NameNode上记录元数据,如果同样大小的文件,文件很小的话,就会产生很多文件,造成NameNode的压力。
2、从读取方面来说:同样大小的文件分为很多小文件的话,会增加磁盘寻址次数,降低性能
3、从计算方面来说:我们知道一个map默认处理一个分片或者一个小文件,如果map的启动时间都比数据处理的时间还要长,那么就会造成性能低,而且在map端溢写磁盘的时候每一个map最终会产生reduce数量个数的中间结果,如果map数量特别多,就会造成临时文件很多,而且在reduce拉取数据的时候增加磁盘的IO。
好,我们明白小文件造成的弊端之后,那我们应该怎么处理这些小文件呢?
1、从源头干掉,也就是在hdfs上我们不存储小文件,也就是数据上传hdfs的时候我们就合并小文件
2、在FileInputFormat读取入数据的时候我们使用实现类CombineFileInputFormat读取数据,在读取数据的时候进行合并。
三、数据倾斜问题优化
我们都知道mapreduce是一个并行处理,那么处理的时间肯定是作业中所有任务最慢的那个了,可谓木桶效应?为什么会这样呢?
1、数据倾斜,每个reduce处理的数据量不是同一个级别的,所有导致有些已经跑完了,而有些跑的很慢。
2、还有可能就是某些作业所在的NodeManager有问题或者container有问题,导致作业执行缓慢。
那么为什么会产生数据倾斜呢?
数据本身就不平衡,所以在默认的hashpartition时造成分区数据不一致问题,还有就是代码设计不合理等。
那如何解决数据倾斜的问题呢?
1、既然默认的是hash算法进行分区,那我们自定义分区,修改分区实现逻辑,结合业务特点,使得每个分区数据基本平衡
2、既然有默认的分区算法,那么我们可以修改分区的键,让其符合hash分区,并且使得最后的分区平衡,比如在key前加随机数n-key。
3、既然reduce处理慢,我们可以增加reduce的内存和vcore呀,这样挺高性能就快了,虽然没从根本上解决问题,但是还有效果
4、既然一个reduce处理慢,那我们可以增加reduce的个数来分摊一些压力呀,也不能根本解决问题,还是有一定的效果。
那么如果不是数据倾斜带来的问题,而是节点服务有问题造成某些map和reduce执行缓慢呢?
那么我们可以使用推测执行呀,你跑的慢,我们可以找个其他的节点重启一样的任务竞争,谁快谁为准。推测执行时以空间换时间的优化。会带来集群资源的浪费,会给集群增加压力,所以我司集群的推测执行都是关闭的。其实在作业执行的时候可以偷偷开启的呀
推测执行参数控制:
mapreduce.map.speculative mapreduce.reduce.speculative
四、mapreduce过程优化
4.1、map端
上面我们从hadoop的特性场景等聊了下mapreduce的优化,接下来我们从mapreduce的执行过程进行优化。
好吧,我们就从源头开始说,从数据的读取以及map数的确定:
在前面我们聊过小文件的问题,所以在数据的读取这里也可以做优化,所以选择一个合适数据的文件的读取类(FIleInputFormat的实现类)也很重要我们在作业提交的过程中,会把jar,分片信息,资源信息提交到hdfs的临时目录,默认会有10个复本,通过参数mapreduce.client.submit.file.replication控制后期作业执行都会去下载这些东西到本地,中间会产生磁盘IO,所以如果集群很大的时候,可以增加该值,提高下载的效率。
分片的计算公式:
计算切片大小的逻辑:Math.max(minSize, Math.min(maxSize, blockSize))
minSize的默认值是1,而maxSize的默认值是long类型的最大值,即可得切片的默认大小是blockSize(128M)
maxSize参数如果调得比blocksize小,则会让切片变小,而且就等于配置的这个参数的值
minSize参数调的比blockSize大,则可以让切片变得比blocksize还大
因为map数没有具体的参数指定,所以我们可以通过如上的公式调整切片的大小,这样我们就可以设置map数了,那么问题来了,map数该如何设置呢?
这些东西一定要结合业务,map数太多,会产生很多中间结果,导致reduce拉取数据变慢,太少,每个map处理的时间又很长,结合数据的需求,可以把map的执行时间调至到一分钟左右比较合适,那如果数据量就是很大呢,我们有时候还是需要控制map的数量,这个时候每个map的执行时间就比较长了,那么我们可以调整每个map的资源来提升map的处理能力呀,我司就调整了mapreduce.map.memory.mb=3G(默认1G)mapreduce.map.cpu.vcores=1(默认也是1)
从源头上我们确定好map之后。那么接下来看map的具体执行过程咯。
首先写环形换冲区,那为啥要写环形换冲区呢,而不是直接写磁盘呢?这样的目的主要是为了减少磁盘i/o。
每个Map任务不断地将键值对输出到在内存中构造的一个环形数据结构中。使用环形数据结构是为了更有效地使用内存空间,在内存中放置尽可能多的数据。执行流程是,该缓冲默认100M(mapreduce.task.io.sort.mb参数控制),当到达80%(mapreduce.map.sort.spill.percent参数控制)时就会溢写磁盘。每达到80%都会重写溢写到一个新的文件。那么,我们完全可以根据机器的配置和数据来两种这两个参数,当内存足够,我们增大mapreduce.task.io.sort.mb完全会提高溢写的过程,而且会减少中间结果的文件数量。我司调整mapreduce.task.io.sort.mb=512。当文件溢写完后,会对这些文件进行合并,默认每次合并10(mapreduce.task.io.sort.factor参数控制)个溢写的文件,我司调整mapreduce.task.io.sort.factor=64。这样可以提高合并的并行度,减少合并的次数,降低对磁盘操作的次数。
mapreduce.shuffle.max.threads(默认为0,表示可用处理器的两倍),该参数表示每个节点管理器的工作线程,用于map输出到reduce。
那么map算是完整了,在reduce拉取数据之前,我们完全还可以combiner呀(不影响最终结果的情况下),此时会根据Combiner定义的函数对map的结果进行合并这样就可以减少数据的传输,降低磁盘io,提高性能了。
终于走到了map到reduce的数据传输过程了:
这中间主要的影响无非就是磁盘IO,网络IO,数据量的大小了(是否压缩),其实减少数据量的大小,就可以做到优化了,所以我们可以选择性压缩数据,这样在传输的过程中
就可以降低磁盘IO,网络IO等。可以通过mapreduce.map.output.compress(default:false)设置为true进行压缩,数据会被压缩写入磁盘,读数据读的是压缩数据需要解压,在实际经验中Hive在Hadoop的运行的瓶颈一般都是IO而不是CPU,压缩一般可以10倍的减少IO操作,压缩的方式Gzip,Lzo,BZip2,Lzma等,其中Lzo是一种比较平衡选择,mapreduce.map.output.compress.codec(default:org.apache.hadoop.io.compress.DefaultCodec)参数设置。我司使用org.apache.hadoop.io.compress.SnappyCodec算法,但这个过程会消耗CPU,适合IO瓶颈比较大。
mapreduce.task.io.sort.mb #排序map输出所需要使用内存缓冲的大小,以兆为单位, 默认为100 mapreduce.map.sort.spill.percent #map输出缓冲和用来磁盘溢写过程的记录边界索引,这两者使用的阈值,默认0.8 mapreduce.task.io.sort.factor #排序文件时,一次最多合并的文件数,默认10 mapreduce.map.output.compress #在map溢写磁盘的过程是否使用压缩,默认false org.apache.hadoop.io.compress.SnappyCodec #map溢写磁盘的压缩算法,默认org.apache.hadoop.io.compress.DefaultCodec mapreduce.shuffle.max.threads #该参数表示每个节点管理器的工作线程,用于map输出到reduce,默认为0,表示可用处理器的两倍
http://www.developcls.com/qa/8b6316e66b8740f9b9e10c6d22f65aba.html
4.1、reduce端
接下来就是reduce了,首先我们可以通过参数设置合理的reduce个数(mapreduce.job.reduces参数控制),以及通过参数设置每个reduce的资源,mapreduce.reduce.memory.mb=5G(默认1G)
mapreduce.reduce.cpu.vcores=1(默认为1)。
reduce在copy的过程中默认使用5(mapreduce.reduce.shuffle.parallelcopies参数控制)个并行度进行复制数据,我司调了mapreduce.reduce.shuffle.parallelcopies=100.reduce的每一个下载线程在下载某个map数据的时候,有可能因为那个map中间结果所在机器发生错误,或者中间结果的文件丢失,或者网络瞬断等等情况,这样reduce的下载就有可能失败,所以reduce的下载线程并不会无休止的等待下去,当一定时间后下载仍然失败,那么下载线程就会放弃这次下载,并在随后尝试从另外的地方下载(因为这段时间map可能重跑)。reduce下载线程的这个最大的下载时间段是可以通过mapreduce.reduce.shuffle.read.timeout(default180000秒)调整的。
Copy过来的数据会先放入内存缓冲区中,然后当使用内存达到一定量的时候才spill磁盘。这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置。这个内存大小的控制就不像map一样可以通过io.sort.mb来设定了,而是通过另外一个参数 mapreduce.reduce.shuffle.input.buffer.percent(default 0.7)控制的。意思是说,shuffile在reduce内存中的数据最多使用内存量为:0.7 × maxHeap of reduce task,内存到磁盘merge的启动门限可以通过mapreduce.reduce.shuffle.merge.percent(default0.66)配置。
copy完成后,reduce进入归并排序阶段,合并因子默认为10(mapreduce.task.io.sort.factor参数控制),如果map输出很多,则需要合并很多趟,所以可以提高此参数来减少合并次数。
mapreduce.reduce.shuffle.parallelcopies #把map输出复制到reduce的线程数,默认5 mapreduce.task.io.sort.factor #排序文件时一次最多合并文件的个数 mapreduce.reduce.shuffle.input.buffer.percent #在shuffle的复制阶段,分配给map输出缓冲区占堆内存的百分比,默认0.7 mapreduce.reduce.shuffle.merge.percent #map输出缓冲区的阈值,用于启动合并输出和磁盘溢写的过程
更多hadoop生态文章见: hadoop生态系列
相关文章:

hadoop之mapreduce详解
一、概述 优化前我们需要知道hadoop适合干什么活,适合什么场景,在工作中,我们要知道业务是怎样的,能才结合平台资源达到最有优化。除了这些我们当然还要知道mapreduce的执行过程,比如从文件的读取,map处理&…...

leetcode做题笔记44
给你一个输入字符串 (s) 和一个字符模式 (p) ,请你实现一个支持 ? 和 * 匹配规则的通配符匹配: ? 可以匹配任何单个字符。 * 可以匹配任意字符序列(包括空字符序列)。 判定匹配成功的充要条件是:字符模式必须能够 完…...

mac brew安装 node 踩坑日记- n切换node不生效
最近用了一个旧电脑开发,发现里面node管理混乱,有nvm、n和homebrew,导致切换node 切换不了,开发也有莫名其妙的错误。所以我打算重新装一下node,使用n做为管理工具。 1. 删除nvm cd ~ rm -rf .nvm2. 删除n sudo rm -…...
数据预处理matlab
matlab数据的获取、预处理、统计、可视化、降维 数据的预处理 - MATLAB & Simulink - MathWorks 中国https://ww2.mathworks.cn/help/matlab/preprocessing-data.html 一、数据的获取 1.1 从Excel中获取 使用readtable() 例1: 使用spreadsheetImportOption…...

ubuntu18.04安装autoware1.15
目录 前言一、准备工作1.安装autoware1.152.安装依赖3.把src/autoware/common/autoware_build_flags/cmake文件夹下的CUDA版本改为11.4(或者你电脑上的版本) 二、解决报错错误类型1错误类型2错误类型3错误类型4错误类型5错误类型6 前言 本文参考链接&am…...
)
在CSDN学Golang云原生(Docker基础)
一,docker安装配置 要在golang中使用Docker,需要先安装并配置好Docker。下面是基本的Docker安装和配置步骤: 下载并安装Docker 官方下载地址:https://docs.docker.com/get-docker/ 根据你的操作系统选择对应版本的Docker&…...
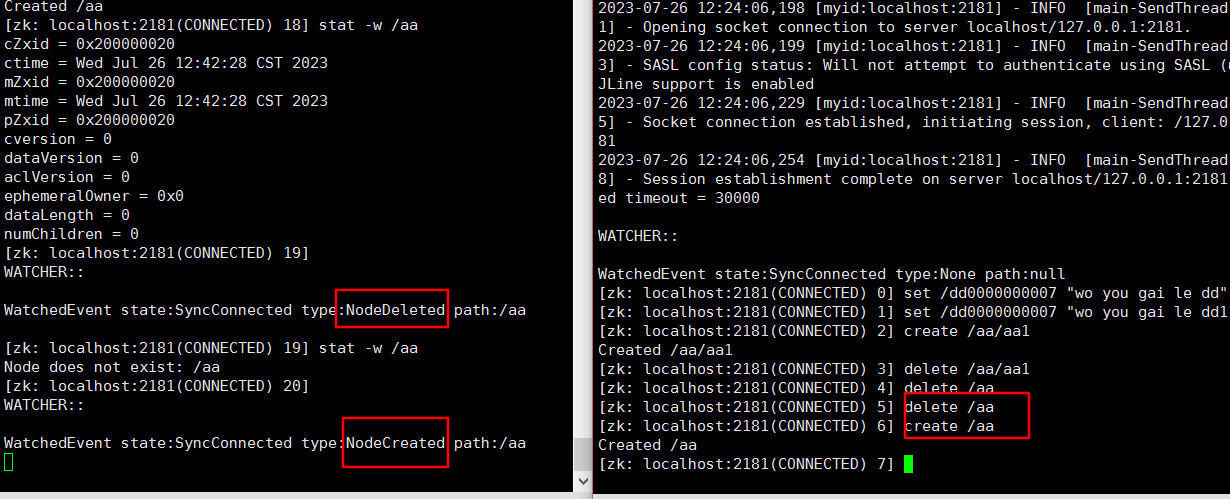
Zookeeper命令总结
目录 1、常用命令2、ls path3、create xxx创建持久化节点创建临时节点创建持久化序列节点 4、get path5、set path6、delete path7、监听器总结1)节点的值变化监听2)节点的子节点变化监听(路径变化)3)当某个节点创建或…...
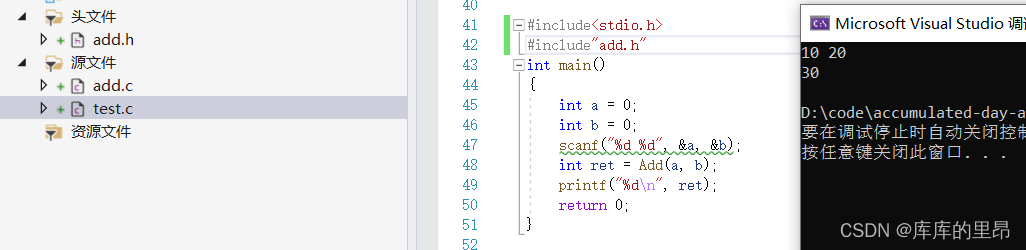
C语言中的函数(超详细)
C语言中的函数(超详细) 一、函数概述二、C语言中函数的分类1.库函数2.自定义函数三、函数的参数1.实际参数(实参)2.形式参数(形参)四、函数的调用1.传值调用2.传址调用五、函数的嵌套调用和链式访问1.嵌套调…...

华为H3C思科网络设备命令对照表
类别命令功能华为H3C思科通用取消关闭当前设置undoundono通用显示查看displaydisplayshow通用退回上级quitquitquit通用设置设备名称sysnamesysnamehostname通用到全局模式system-viewsystem-viewenable config terminal通用删除文件deletedeletedelete通用重启设备rebootreboo…...
产品需求、系统架构设计经验篇
需求设计思维导图UML 建模原型规范什么样的需求该忽略1.拍拍脑袋得来的想法,往往是没用的2.用户反馈的信息,不应该直接纳入需求3.扭改用户习惯的需求,一律不考虑 什么样的需求该重视1.从运维系统中根据数据结果分析得出的结论2.重视有洞见者的…...

关于websocket的几点注意事项
第一、普通websocket直接集成即可 <!-- Spring Websocket 相关依赖 --> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId> </dependency> 第二、web后端两点,创…...
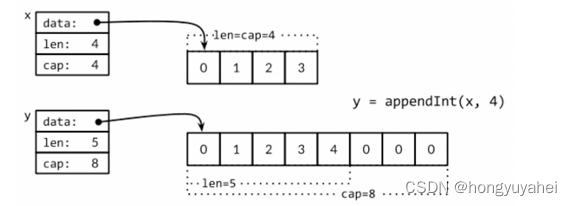
go学习 4、复合数据类型
4、复合数据类型 数组、slice、map和结构体 如何使用结构体来解码和编码到对应JSON格式的数据,并且通过结合使用模板来生成HTML页面 数组和结构体是聚合类型;它们的值由许多元素或成员字段的值组成。数组是由同构的元素组成(每个数组元素都是完全相同的…...
方法)
Rust: Vec类型的into_boxed_slice()方法
比如,我们经常看到Vec类型,但取转其裸指针,经常会看到into_boxed_slice()方法,这是为何? use std::{fmt, slice};#[derive(Clone, Copy)] struct RawBuffer {ptr: *mut u8,len: usize, }impl From<Vec<u8>&g…...
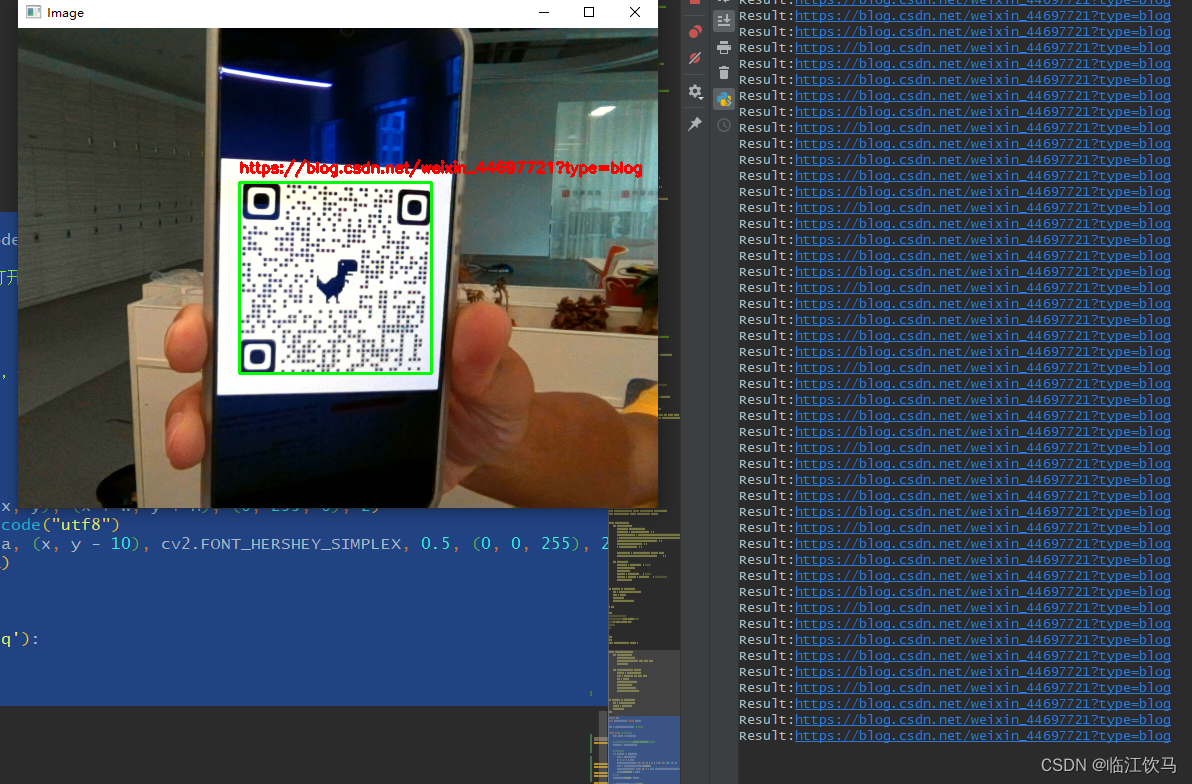
Python - Opencv + pyzbar实时摄像头识别二维码
直接上代码: import cv2 from pyzbar.pyzbar import decodecap cv2.VideoCapture(0) # 打开摄像头while True: # 循环读取摄像头帧ret, frame cap.read()# 在循环中,将每一帧作为图像输入,使用pyzbar的decode()函数识别二维码barcodes …...
网络安全(黑客)就业分析指导
一、针对网络安全市场分析 市场需求量高;则是发展相对成熟入门比较容易。所需要的技术水平国家政策环境 对于国家与企业的地位愈发重要,没有网络安全就没有国家安全 更有为国效力的正义黑客—红客联盟 可见其重视程度。 需要掌握的知识点偏多 外围打点…...

MySQL 主从复制的认识 2023.07.23
一、理解MySQL主从复制原理 1、概念:主从复制是用来建立一个和 主数据库完全一样的数据库环境称为从数据库;主数据库一般是准实时的业务数据库。 2、作用:灾备、数据分布、负载平衡、读写分离、提高并发能力 3、原理图 4、具体步骤 (1) M…...

elasticsearch查询操作(API方式)
说明:elasticsearch查询操作除了使用DSL语句的方式(参考:http://t.csdn.cn/k7IGL),也可以使用API的方式。 准备 使用前需先导入依赖 <!--RestHighLevelClient依赖--><dependency><groupId>org.ela…...
Java版企业工程项目管理系统源码+java版本+项目模块功能清单+spring cloud +spring boot
工程项目各模块及其功能点清单 一、系统管理 1、数据字典:实现对数据字典标签的增删改查操作 2、编码管理:实现对系统编码的增删改查操作 3、用户管理:管理和查看用户角色 4、菜单管理:实现对系统菜单的增删改查操…...

理解Android中不同的Context
作者:两日的blog Context是什么,有什么用 在Android开发中,Context是一个抽象类,它是Android应用程序环境的一部分。它提供了访问应用程序资源和执行各种操作的接口。可以说,Context是Android应用程序与系统环境进行交…...

linux判断端口是否占用(好用)
netstat 一般的话使用 netstat -tunlp | grep xxx参数作用-t指明显示TCP端口-u指明显示UDP端口-l仅显示监听套接字(所谓套接字就是使应用程序能够读写与收发通讯协议(protocol)与资料的程序)-p显示进程标识符和程序名称,每一个套接字/端口都属于一个程序。-n不进行…...

3步让老旧电脑重获新生:RyTuneX系统优化神器完全指南
3步让老旧电脑重获新生:RyTuneX系统优化神器完全指南 【免费下载链接】RyTuneX RyTuneX is a cutting-edge optimizer built with the WinUI 3 framework, designed to amplify the performance of Windows devices. Crafted for both Windows 10 and 11. 项目地址…...

Comfyui从入门到进阶教程分享
接触Comfyui的这段时间,从最开始的安装部署踩坑,到后来独立搭建自定义工作流,试过不少零散的教程,也整理了一套成体系的学习内容,覆盖了从基础操作到高阶玩法的各个环节,不管是刚入门的新手,还是…...

GraceTheme定义“优雅大气”的WordPress主题新标准
网站不仅是信息的载体,更是品牌气质的延伸。无论是企业官网、个人博客还是作品集展示,如何在茫茫网海中脱颖而出,给用户留下深刻的第一印象?答案往往就藏在网站的“气质”之中。如果你正在寻找一款能够完美平衡美学设计与功能实用性的WordPr…...
)
保姆级教程:用PyTorch从零搭建联邦学习MNIST实验环境(附完整代码)
联邦学习实战:PyTorch搭建MNIST实验环境全流程解析 1. 联邦学习与MNIST实验概述 联邦学习作为一种分布式机器学习范式,正在重塑传统模型训练的方式。不同于集中式训练,联邦学习允许多个客户端在保持数据本地化的前提下协作训练模型࿰…...

C 里面如何使用链表 list
1. 学生时代, 那会学习 C 数据结构, 比较简单 struct person {int id;char name[641];struct person * next; }; 类似上面这样, 需要什么依赖 next 指针来回调整, 然后手工 print F5 去 debug 熬. 2. 刚工作青年时代, 主要花活, 随大流类似 #pragma once#include "stru…...

直播推流技术:突破平台限制的开发者解决方案
直播推流技术:突破平台限制的开发者解决方案 【免费下载链接】bilibili_live_stream_code 用于在准备直播时获取第三方推流码,以便可以绕开哔哩哔哩直播姬,直接在如OBS等软件中进行直播,软件同时提供定义直播分区和标题功能 项目…...

DeepSeek kubernetes-1.35.3/api/api-rules/sample_apiserver_violation_exceptions.list 源码分析
我来分析 Kubernetes API 规则文件 sample_apiserver_violation_exceptions.list。这个文件是 Kubernetes API 合规性检查的一部分,用于管理 API 规则违规的例外情况。 文件概述 该文件位于 Kubernetes 源码的 api/api-rules/ 目录下,用于记录 API 规则检…...

PlayCover:跨生态运行iOS应用的性能优化与无缝体验指南
PlayCover:跨生态运行iOS应用的性能优化与无缝体验指南 【免费下载链接】PlayCover Community fork of PlayCover 项目地址: https://gitcode.com/gh_mirrors/pl/PlayCover 价值主张:重新定义Apple生态边界 PlayCover作为专为Apple Silicon Mac设…...

如何彻底解决Android Studio中文界面兼容性问题:专业级终极配置指南
如何彻底解决Android Studio中文界面兼容性问题:专业级终极配置指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还…...

一次 Spring 循环依赖源码走读:从三级缓存误用到 Bean 生命周期深度解析
在团队最近一次架构评审会上,关于 Spring 循环依赖的处理方式爆发了一场激烈争论。 “直接用 Lazy 不就行了?” 小李拍着桌子说,“我上个月在订单服务里就这么干的,上线一点问题没有。” “Lazy 只是绕开问题,不是解决…...