字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
深度学习的模型规模越来越庞大,其训练数据量级也成倍增长,这对海量训练数据的存储方案也提出了更高的要求:怎样更高性能地读取训练样本、不使数据读取成为模型训练的瓶颈,怎样更高效地支持特征工程、更便捷地增删和回填特征。本文将介绍字节跳动如何通过 Iceberg 数据湖支持 EB 级机器学习样本存储,实现高性能特征读取和高效特征调研、特征工程加速模型迭代。
机器学习样本存储:背景与趋势
在字节跳动,机器学习模型的应用范围非常广泛。为了支持模型的训练,我们建立了两大训练平台:推荐广告训练平台和通用的 CV/NLP 训练平台。推荐广告平台每周训练规模达到上万个模型,而 CV/NLP 平台的训练规模更是每周高达 20 万个模型。如此庞大的模型训练规模背后离不开海量的训练样本支持。目前,在字节跳动的离线训练样本存储中,数据总量已经达到了 EB 级,每日还在以 PB 级的速度增长。这些数据被用于支持广告、搜索、推荐等模型的训练,覆盖了多个业务领域;这些数据还支持算法团队的特征调研、特征工程,并为模型的迭代和优化提供基础。目前字节跳动以及整个业界在机器学习和训练样本领域的一些趋势如下:
首先,模型/样本越来越大。随着模型参数的增多,为了训练这些庞大的模型需要更多、更丰富的训练数据来确保模型的准确性和泛化能力。
其次,训练算力越来越强。在过去,训练一个机器学习模型可能需要数周甚至数月的时间。然而,如今基于更好的模型架构和高速显卡,我们可以在相对较短的时间内完成训练过程并进行 A/B 测试验证。
另外,特征工程越来越自动化、端到端化。在传统的机器学习中,特征工程是非常重要的一环,通常需要大量的人工、时间和精力来处理数据和特征。而随着深度学习的发展,我们可以利用深度学习的特征提取能力,通过简单的数据处理步骤自动学习特征,甚至可以将过程简化为在待调研的原始特征中往一张样本表格里加列的操作后利用深度学习框架自动学习和提取信息。
总体来说字节跳动的机器学习和训练样本在其业务中发挥着重要作用。通过建立强大的训练平台、积累海量的训练样本,字节跳动能够支持大规模的模型训练和优化。此外,当前业界的趋势表明模型和样本规模的增长,以及训练算力的提升正推动着机器学习的发展,同时特征工程的自动化和端到端化也为模型训练带来了便利和效率。
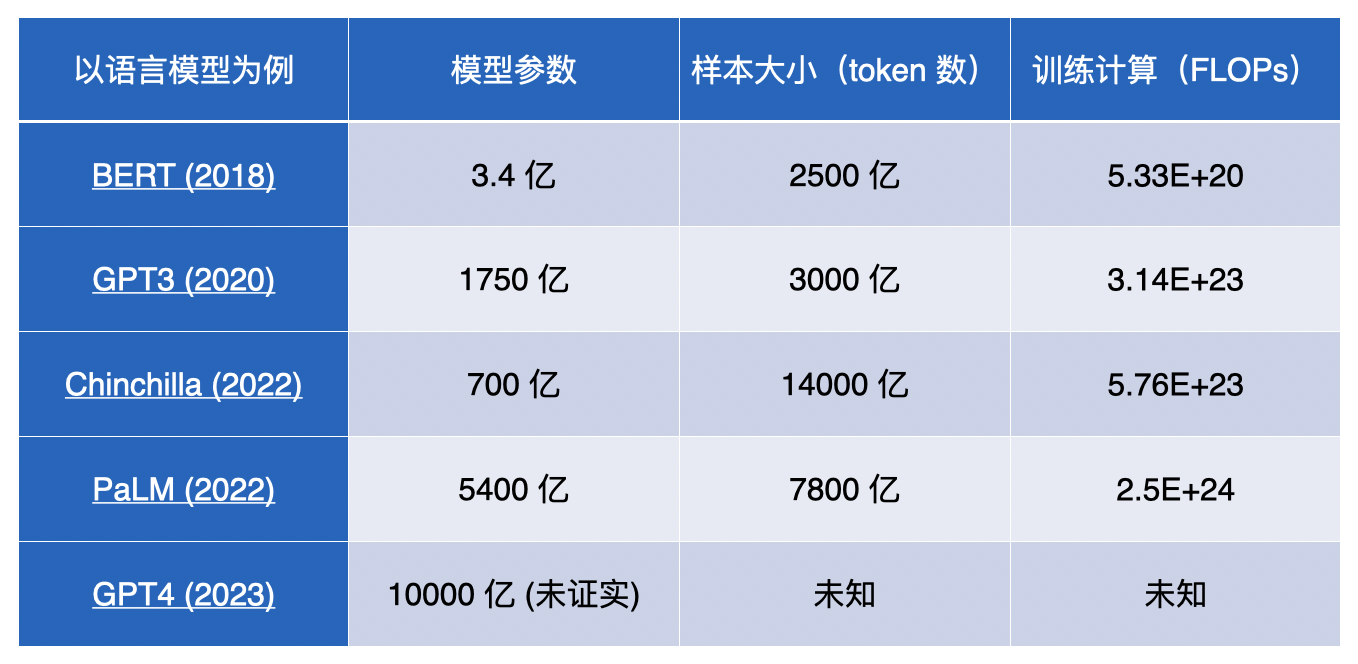
机器学习与训练样本-语言模型趋势
以语言模型为例看一下参数和样本量的趋势。首先是 BERT,这是一种在 2018 年首次亮相的语言模型。BERT 基于 Transformer 架构,仅有 3.4 亿个模型参数。当时,这已经被认为是一项重大突破。然而随着时间的推移,语言模型的规模和能力不断增长。引人注目的是 GPT-3,这是一种由 OpenAI 开发的强大语言模型。相比于 BERT 的 3.4 亿个参数,GPT-3 的模型参数数量飙升至 1750 亿个。这一巨大的增长引发了广泛的关注,并且使得 GPT-3 在自然语言处理任务中取得了令人瞩目的成就。
然而随着模型参数的增长,模型的大小也成为一个问题。为了解决这个问题,人们开始尝试模型小型化的方法。Chinchilla 就是一种模型小型化的尝试,相较于其前代模型,将模型参数缩小了 4 倍,但样本量却增大了 4 倍,这种方法试图在保持相对较小的模型规模的同时利用更多的数据提升模型的性能。最近最新推出的 GPT-4 模型以及 Google 最近发布的第二代 PaLM 没有公布具体的模型细节。但可以猜测的是,这些模型的规模可能已经达到了万亿级的参数,这些进展为自然语言处理和其他相关领域的研究者们带来了新的机遇和挑战。
通过前面提到的这些趋势,我们也可以看出当前需要解决的一些问题及为实现降本增效目标需要调整的地方。
首先,需要优化训练样本的存储大小,减少存储成本。随着数据集的规模增长,存储需求、成本也会相应增加,这对于大规模的训练模型来说是一个挑战。
其次,还需要优化训练样本的读取速度。随着芯片技术的迭代和算力的增长,训练模型所需的计算资源也在不断提升。然而如果样本的读取速度无法跟上算力的增长就会成为训练过程中的瓶颈,限制算力资源的有效利用率。所以我们需要寻找方法来提高样本的读取吞吐量,确保可以充分利用现有的算力资源。
最后,在深度学习的加持下特征工程已经变得更加自动化和简化,我们可以顺应趋势进一步提高特征调研和工程的效率。通过加速特征工程和调研过程缩短模型迭代周期、提高算法的开发效率。
存储样本方案演进
传统存储样本方案

首先,传统样本存储是将样本直接存放在 HDFS、对象存储或者 Hive 上的方案。这种方案在处理海量样本时会遇到性能瓶颈。由于采用了单点 List 操作,扫描海量样本时会变得非常缓慢。另外,当需要添加列或加特征时使用写时复制(Copy-On-Write)的方式会导致存储量翻倍,大幅增加成本负担的同时也会因为读写放大的本质导致不必要的计算资源开销。
其次是通过传统数据库方案存放样本,这种方案更多适用于处理少量样本的场景,当海量数据达到 PB、EB 级时会遇到困难。此外由于训练代码无法直接读取数据库底层文件,读取吞吐量可能受限制,即使在实时拼接特征、标签的应用场景也会导致训练吞吐速度的下降。
数据湖存储样本方案

基于数据湖的新兴样本存储方案中,两个备受关注的方案是 Apache Hudi 和 Apache Iceberg。
-
Apache Hudi 提供了 MOR(Merge-On-Read)的方式更新、加列,相比于传统的 COW 方式大大降低了特征调研导入的开销。然而 Hudi 在读取时的合并性能不太理想,涉及多种格式的转换、溢出磁盘引起额外 IO 等。此外 Hudi 不支持原生 Python API,只能通过 PySpark 的方式对于算法工程师来说不太友好。
-
Apache Iceberg 是一种开放的表格式,记录了一张表的元数据:包括表的 Schema、文件、分区、统计信息等。这种元数据计算具备高拓展性,为数据湖管理提供了更好的支持、更快的文件扫描。然而 Iceberg 的 MOR 方式也存在一些问题,比如社区版不支持只更新部分列(Partial Update)等。值得一提的是,Iceberg 提供了对 Python API 的支持,这对于算法工程师来说是一个很重要的优势。
综上,Apache Hudi 和 Apache Iceberg 都是基于数据湖的新兴样本存储方案,各自有着不同的特点和优势。虽然 Hudi 在某些方面存在一些性能上的问题并且不支持 Python,但它的 MOR 方式在加调研特征方面表现出色。而 Iceberg 则提供了开放的表格式和高度可扩展的元数据计算,同时还支持 Python API,为算法工程师提供了更友好的环境,但其 MOR 能力还有待加强。到这我们可以了解到,常见一些方案都存在些许不足之处,不够理想。最终我们经过多维度的考察,决定基于 Iceberg 数据湖来自研、强化,填补不足、满足业务的样本存储和特征工程等需求。
字节强化版 Iceberg 数据湖:Magnus 猛犸
整体架构
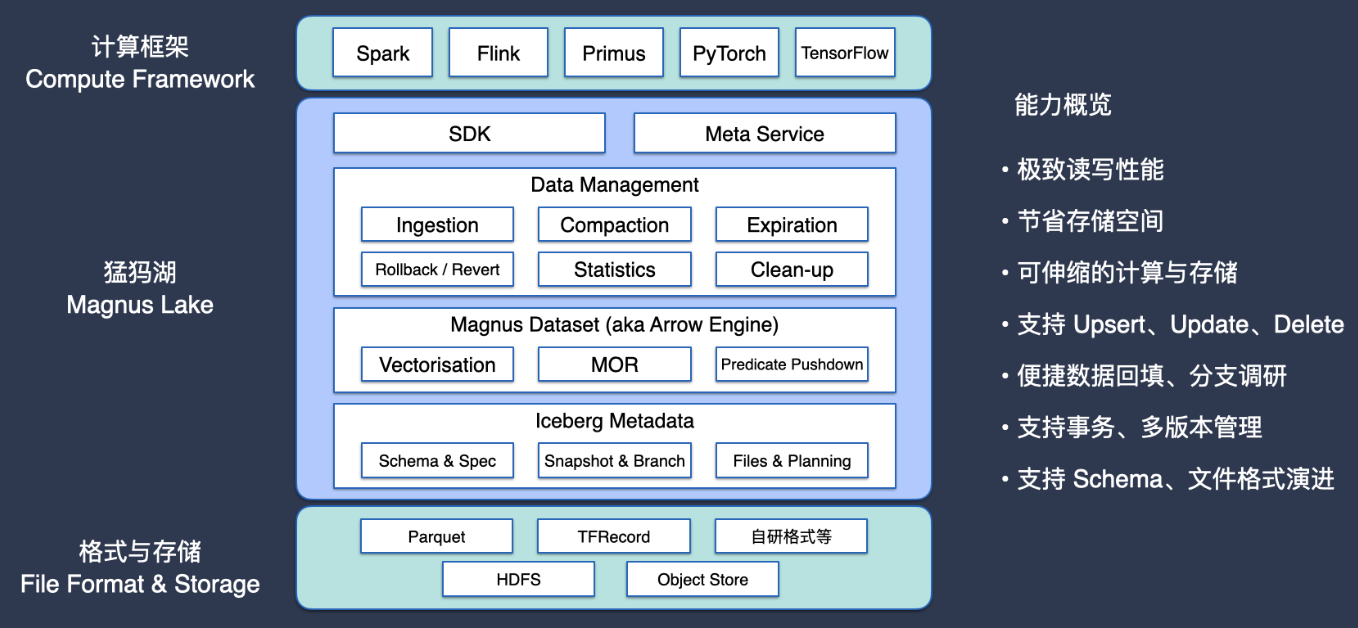
猛犸湖(Magnus)基于 Apache Iceberg 自研、强化的整体架构如下:
最上层的是计算层,延续了计算存储分离的设计理念。天然支持 Flink 和 Spark 引擎进行数据分析和 ETL 数据处理,同时还支持多种训练框架,包括我们团队近期开源的分布式训练调度框架 Primus,以及传统的 PyTorch 和 TensorFlow 等,用户可以根据需求选择适合的计算、训练框架。
第二层即猛犸湖的核心层。对外为用户提供了 SDK 自助和元数据服务,平台能力上支持多种运维作业,如数据导入、维护等任务。值得一提的是,该层引入了基于 Arrow 的高速向量化读时合并引擎,能够高效合并数据、提高读取性能。猛犸湖的底座是基于强化版的 Iceberg 元数据,元数据支持版本管理、文件扫描等功能,为用户提供更加全面的数据管理能力。
底下的存储层是整个架构的基础,负责实际的数据存储,支持多种文件格式,包括开源的列式存储格式 Parquet、行存格式 TFRecord 及其他自研格式。平台鼓励业务迁移到列存格式,可以平均节省存储成本约 30%~50%,并提升读取性能。最终这些文件会被存储在 HDFS 或对象存储中,以确保数据的安全可靠。
核心特性优化与实践
核心特性一:支持数据更新和写入分支

经过前文了解到基于 MOR 读时合并的轻量级更新操作是加速特征调研和工程迭代周期的关键。所以我们首先开发、引入了第一个核心特性:Iceberg 上的轻量级数据更新和分支管理。
Iceberg 数据湖管理了以下文件类型:Data File 数据文件—表达新增的行记录、Delete File 删除文件—表达行删除信息,在此基础上增加 Update File 更新文件—表达列更新信息。在写入数据、更新或者加列时,用户只需要提供行号、主键和回填列数据信息即可,极大避免了读写放大问题,实现轻量级更新。读的时候数据文件和更新文件可以一并读出,并进行读时合并、共同应用到更新和加列中。
Iceberg 的树状元数据表达力强,能够很好的支持数据分支表达。通过利用这一点在特征调研\写更新文件时写入到分支上进行调研,就可以直接引用主干上的数据文件,使各分支之间能够保持隔离,不影响主干上的基线模型训练,同时还避免了不必要的数据复制。也开发了对应的分支操作,可以像 Git 一样便捷的操作数据:合并、删除、Rebase(将分支重新以主干为根基),这些分支操作都是基于 Iceberg 元数据的,相比操作数据更加的轻量级。
该特性在缩短特征调研迭代周期和多个训练目标共享特征方向均有广泛应用。
-
应用一:大规模特征调研与工程

基于更新和分支的核心能力,为了提速特征调研迭代周期我们已经广泛将其应用于特征工程的流程中。在一些业务中含有多个高潜力的特征集,算法同学可以在各自的分支上进行并行回填、调研、训练。当调研模型指标满足预期后,用户可以提交工单进行分支合并审核及追新写入特征,分支合并与追新之间如果有缺失可以从离线回填到主干上。
对于成熟度高的模型大部分调研特征可能效果不明显,这时删除分支后数据维护任务会把这个分支的文件删除节省空间。当然算法工程师也可以继续对分支进行 Rebase 操作进行验证、调研。该应用也存在一些难点比如大量更新合并后带来的小文件问题,所以在分支上部署文件数量监控,只有在必要时才进行 Compact 合并小文件操作。
-
应用二:多个训练目标,共享特征

另一个应用场景是通过数据分支支持多个训练目标复用同一份特征。在推进新的推荐项目时,如果有一个新的推荐目标,算法工程师只需要回填该推荐目标的标签 Label 就可以直接复用主干已有的特征,训练几个小时后就可以开始 AB 实验、检验模型效果,在主干上调研成功的新特征也可以尽快在所有推荐目标上复用、零数据复制,最终我们通过分支、复用特征数据的能力在一些推荐项目上节省约 90% 的样本存储空间,极大的提速了推荐目标的调研周期。
核心特性二:高速读时合并引擎
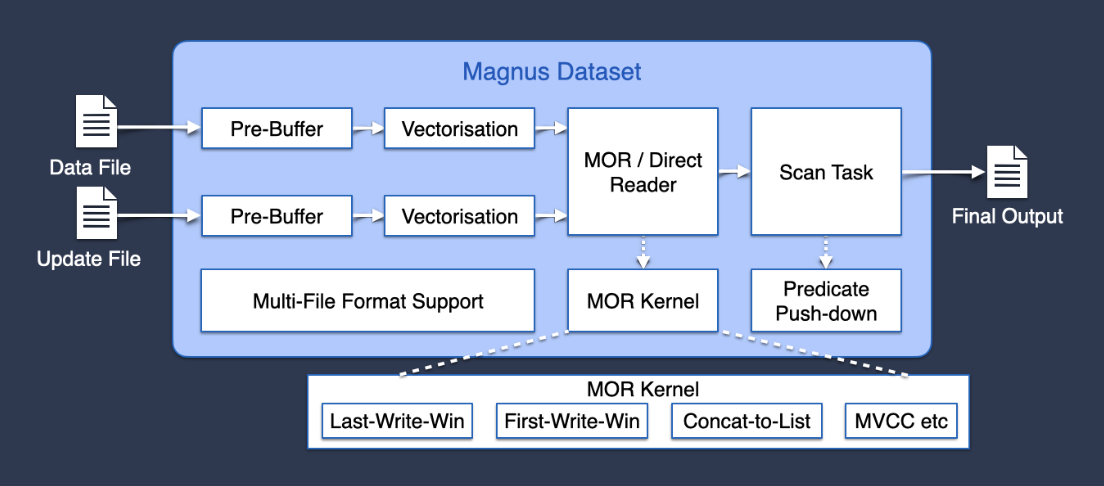
猛犸数据集(Magnus Dataset)是一个基于 Apache Arrow 开发的读时合并引擎。Apache Arrow 是一个开源的列式内存结构,支持多种语言、同进程零复制、极低序列化开销、向量化计算等能力。Iceberg 社区也拥有对 Arrow 向量化读取的支持,但是不支持复杂嵌套类型,这对包含嵌套类型数据的训练样本极不友好,而猛犸数据集则能够很好的支持。
在字节开源的训练调度框架 Primus 上,相比一般的向量化读能够实现约 2 倍的读吞吐提升。所以我们不依赖 Compaction 合并文件也能支持高性能样本读时合并、读取,在 GPU 训练中让数据读取不再是瓶颈。输出的结果是 Arrow 格式,能够很方便的以零复制的方式对接 Spark Dataset、Pandas 等接口。

其中读时合并和下推过滤在一些训练模型/数据处理中有很多样本是可以跳过和采样的,我们也通过下推过滤减少训练的样本计算量来提速。在支持高速读时合并中支持了内存统一化和海量样本 Shuffle 的优化,具体可见下两部分详细介绍。
-
应用一:内存统一化 Arrow

这个特性在业务的落地上我们和内部其他团队将离线训练端到端的内存格式在头部模型中全部切换成了 Arrow 格式,极大减少了内存、计算资源的使用,避免了很多不必要的内存格式转换和序列化开销,取得了很大的收益。在数据分析、处理常用的 Spark 引擎中也做了部分 Arrow 化改造。需要注意的是,我们也在在线流式训练中尝试切换 Arrow,但开销还是很大,可能的原因是流式的样本是每条通过的,不适合 Arrow 这种批式的形式从而导致额外的开销。
-
应用二:海量样本 Shuffle 优化

在海量样本的处理上,算法工程师为使模型表现更好会花费大量时间在数据的清洗上。而清洗数据往往需要使用 Shuffle 操作,常碰到的问题是 Shuffle 失败、慢。我们在这个部分基于更新和下推过滤做了 Shuffle 优化的响应工作。
比如用户需要将 PB 级样本表和某中型表拼接,他们的分桶方式不同-用不了常见的 Bucket Join,内存不足-也用不了常用的 Broadcast Join,这时我们可以通过 Update 更新操作,将小的表更新到大表的临时分支中、将其变成和大表一样的布局,再通过下推过滤将拼接上的样本高吞吐读出。
如果用户需要通过将 PB 级样本打散、去重来优化模型的性能效果,那么也可以按照类似的思路通过 Update Shuffle 小的数据将其更新到大表上再下推过滤、捞出即可。
核心特性三:Upsert 与全局索引

拥有更新、高速读时合并并不够,我们还需要有一些业务场景使多条样本的数据流能够直接并发入湖、拼接和回填,这就依赖于接下来介绍的第三个核心特性-全局索引。通过全局索引可以知道一条写进记录是否已经写入,没写入的可以 Insert 插入;写入的可以采用 Update 更新操作。这部分我们参考了 Apache Hudi 的设计,除了支持 HBase 全局索引,还支持 HFile 文件索引、即直接使用 HBase 底层的数据格式作为索引并托管在 Iceberg 元数据中,优化了性能和并发性等。
相比其他索引,使用 HFile 文件索引能够减少运维组件、复用存储资源,并且能够避免脉冲流量读写问题。整个写入流程上看,在写入数据的时候框架会查写全局索引定位一条记录应该写到哪个分区、桶,读取的时候会根据桶进行读时合并,最终还原出结果样本。具体应用上主要在大开窗特征、标签拼接等场景使用。
-
应用:大开窗特征与标签湖上拼接

风控等业务场景更适用大开窗(大于等于一个月的开窗)特性拼接特征和标签。线上拼接采用大开窗的形式需要耗费大量机器资源,所以我们采用并发 Upsert 支持,允许样本追新、标签回填、特征调研同时进行,可以直接在成本较低的离线猛犸湖上进行特征和标签的拼接。
其核心在于将容忍并发写冲突的选择权交给用户,提供多种 MOR 策略满足业务需求:First-write-win 最先写入的留下、Last-write-win 最后写入的留下、拼接到列表、自定义读时合并容忍并发 Upsert 冲突。对于业务无法容忍并发的场景也支持分区级、桶级的乐观冲突检测。同时对于 Upsert 回流到早前分区的数据按数据冷热进行 Compact,避免小文件带来的性能损耗。
介绍完核心特性,我们也针对海量样本为 Iceberg 数据湖做了不少优化,也逐渐在将一些效果不错的包贡献给社区。这里我们挑重点的内容简单介绍一下。
其他优化与实践

-
特征淘汰
某些情况下对于合并到主干上的特征直接物理删除后可能会有遗漏,或者对下游任务产生影响。针对这种情况可以通过对特征列重命名实现逻辑删除。由于训练侧是基于特征名字来读,重命名后就读不到了。如果有算法同学发现对模型有影响,将其重命名回来就好,过了一段时间没有影响后就可以稳妥地物理删除该特征。
-
回滚 & 撤销
当数据源/流水线出现问题时,如果入湖的特征存在问题就会影响训练模型效果导致线上数据流故障。针对这种情况,常见的做法是回滚,将有问题的写入快照版本回滚,如此做法也会把后面正常写入的快照版本一起回滚了,可能会影响后续下游的一些训练/样本处理。所以我们开发了撤销功能,可以针对某个快照的操作在元数据层面进行撤销,不影响后续正常写入的特征,对下游任务更友好。
-
脏数据跳过
面对海量样本,经常会出现脏数据如数据丢块、损坏等,这是数据量级增大后必然出现的现象。因此我们支持针对脏数据的重试,比如支持切换节点重试、支持只跳过一定比例等。
-
大元数据优化
面对海量样本,元数据也变成了 Big Metadata,即大元数据。它也需要像大数据那样去对待、瘦身和优化。如在机器学习场景下,绝大部分的读数据方式是 Scan 扫描,这时我们可以把 Iceberg 元数据中记录的大量列统计信息去掉,有效减少元数据大小、特别是大宽表场景,只留一些必要的比如分区、主键 Min-max 等。从而大大减少任务 Plan 计划耗时,避免 AM、Driver OOM 超内存。
-
大元数据提速
对于大元数据的提速,传统上往往都是用单点处理元数据的计算方式,这种处理方式在面对大元数据时也会力不从心。这时我们可以通过裁剪 IO、分布式处理大元数据来提速。对于依赖全表扫描的作业如 Compaction,也采用分布式 Planning 提速、避免超内存问题。
总结与展望
本文总结
本次分享介绍了强化版 Iceberg 的整体架构、核心特性及优化与实践,简单总结前面分享的内容主要包括:
-
通过推动业务切换列存格式、复用特征数据大幅减少样本存储空间,减少存储成本;
-
通过向量化读时合并引擎提速特征读吞吐,使 GPU 训练中的数据读取可以不成为瓶颈,充分利用好算力;
-
基于更新、Upsert 和分支的能力进行大规模特征工程和调研,使模型迭代效率更快。
近期对于 LLM 大语言模型的思考
我们前面提到了很多特征调研、特征工程相关的技术,那未来会不会不需要特征工程了呢?这里结合最近比较火的 LLM 大语言模型,也基于一些公开的信息还有论文知识分享下我的一些想法:
目前大语言模型基本都沿用了 Transformer 架构实现,虽然学习特征的能力已经很强了,但目前还需要分词组件辅助将文字转换为模型理解的形式,并且分词的好坏也会一定程度影响模型的效果。而现阶段各个大语言模型的分词算法还不一样,距离完全的端到端还有一定距离,基本都是能实现自动化的。当然也有新的研究和论文比如 Megabyte 尝试完全端到端的方式做分词和训练架构,也取得了不错的效果,但是还需要期待更大规模的效果验证。所以说当前短时间内如果需要重新研发一个大语言模型,分词、特征工程还是必经之路。
当然出于成本考虑很多公司和机构不会从头开始重新研发一个大语言模型,一般会基于某个已有的大语言模型进行微调,针对下游、垂直任务进行优化,所以特征工程也还是值得考虑的。比如:利用人工反馈给 AI 问答排序、打分让它对齐人类的喜好还有社会法律规范;添加一些额外的特征辅助 AI 理解当前上下文并做出更恰当的回答等。现在也出现了一些新的技术比如 Low-Rank Adaptation(LoRA)把需要微调的参数量大幅减少,不需要更新基础大模型的参数,让微调训练更快完成、也让输入的 Token 更少来大大减少计算成本。
对于提示词工程和上下文学习确实不太需要关注底层的特征工程了,也都不需要训练了、可以直接让 AI 结合上下文信息来习得知识并作答。目前业界已经出现不少应用,结合词向量搜索、把 AI 需要的上下文信息提供出来回答之前没训练过的内容。这是一个全新的方向,很多正确性要求不高的场景都适用,极大的降低了 AI 模型的研发门槛、潜力十足。但因为每次接口调用都要提供上下文信息、而现在的一些大语言模型计费标准是按输入输出 Token 数计费的,使用成本较高,如果能微调的一下的话可以节省不少成本的、效果也可以更好。其次提示词工程会更适用于参数千亿级的大模型,它的思维链、涌现能力更好;对于参数少的还可以通过微调来达到持平、甚至更好的表现。而目前需要微调的话,特征工程还有机会进入提升效果。总体来说会像开头提到趋势一样:特征工程会越来越简化,将来它的存在也不再需要投入很多时间精力去手工操作了。
未来展望与规划
最后分享未来对数据湖、样本存储的一些展望。
-
“湖流一体”
首先是湖流一体化。在“湖流一体”的架构中,数据湖和消息队列、流式计算可以相互连接,可以通过计算框架提供统一的历史批式、追新流式的管理和接口,同时服务于低延迟的在线流式训练、高吞吐的离线批式训练;并且将消息队列闲置的计算资源用来满足数据湖的数据管理,节省资源成本。
-
下一代数据格式
常见的列存文件格式编码算法较少、而且多为支持 Primitive 原始类型。而训练样本里边的数据类型多是嵌套、Tensor 向量类的,我们可以探索更丰富的编码算法来更好的优化机器学习特征的存储和成本,同时采用更丰富的索引支持来为训练提速。
-
云原生
最后一点,对于企业来说采用云原生架构已经成为一种趋势和必要选择,可以帮助企业更好地应对业务变化和市场挑战,提高业务竞争力和创新能力。强化版 Iceberg 也具备企业级能力,能为用户带来计算和存储收益,降本增效。
相关文章:
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
深度学习的模型规模越来越庞大,其训练数据量级也成倍增长,这对海量训练数据的存储方案也提出了更高的要求:怎样更高性能地读取训练样本、不使数据读取成为模型训练的瓶颈,怎样更高效地支持特征工程、更便捷地增删和回填特征。本文…...

CentOS 安装Mysql8
1.检查是否已经安装mysql,停止mysql服务,删除mysql ps -ef | grep -i mysql systemctl stop mysqld rpm -e mysql 2.配置仓库 更新秘钥 rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022 安装mysql8的yum源 rpm -Uvh https://dev.mysql.…...

3-Linux实操
Linux实践操作 开关机、重启、用户登陆注销关机&重启用户登陆和注销 用户管理添加用户修改用户密码删除用户查询用户信息切换用户查看当前用户用户组的添加和删除用户和组相关文件 实用指令指定运行级别init 命令帮助指令文件目录类时间日期类搜索查找类🔍压缩和…...

Yarn 集群的架构和工作原理
Yarn 的基本设计思想是将 MapReduce V1 中的 JobTracker 拆分为两个独立的服务:ResourceManager 和 ApplicationMaster。 ResourceManager 负责整个系统的资源管理和分配,ApplicationMaster 负责单个应用程序的管理。 ResourceManager RM 是一个全局的资…...

PostgreSQL-视图-03-查询对象依赖关系视图-dba_dependencies
PostgreSQL查询对象依赖关系视图 -- PostgreSQL查询对象依赖关系视图drop view if exists tzq.dba_dependencies; create view tzq.dba_dependencies as with source_obj as (select sp.oid,sp.proname,unnest(string_to_array(regexp_replace(regexp_replace(lower(sp.prosrc…...
Vue style中的 scoped 属性
Vue 中存在 scoped 属性,HTML5中也存在一个 scoped 属性,而且,这两者都是针对 css 样式处理的属性,所以很多文章在 解释 Vue scoped 的时候,都会把两者混为一谈,直接进把 HTML5 scoped 的定义搬到 Vue scop…...
移动端适配rem
1.安装amfe-flexible和postcss-pxtorem, npm install amfe-flexible --save npm install postcss-pxtorem5.1.1 (这里我使用的postcss-pxtorem是5.1.1版本)或者在pageage.json中写入 "amfe-flexible": "^2.2.1","postcss-pxtorem": …...

Go语言开发小技巧易错点100例(八)
往期回顾: Go语言开发小技巧&易错点100例(一)Go语言开发小技巧&易错点100例(二)Go语言开发小技巧&易错点100例(三)Go语言开发小技巧&易错点100例(四)Go…...
100个网络安全测试面试题
1、Burpsuite常用的功能是什么? 2、reverse_tcp和bind_tcp的区别? 3、拿到一个待检测的站或给你一个网站,你觉得应该先做什么? 4、你在渗透测试过程中是如何敏感信息收集的? 5、你平时去哪些网站进行学习、挖漏洞提交到…...

7.26 作业 QT
1.继续完善登录框,当登录成功时,关闭登录界面,跳转到新的界面中: 结果图: second.h: #define SECOND_H#include <QWidget> #include<QDebug> //信息调试类,用于打印输出的 #inc…...
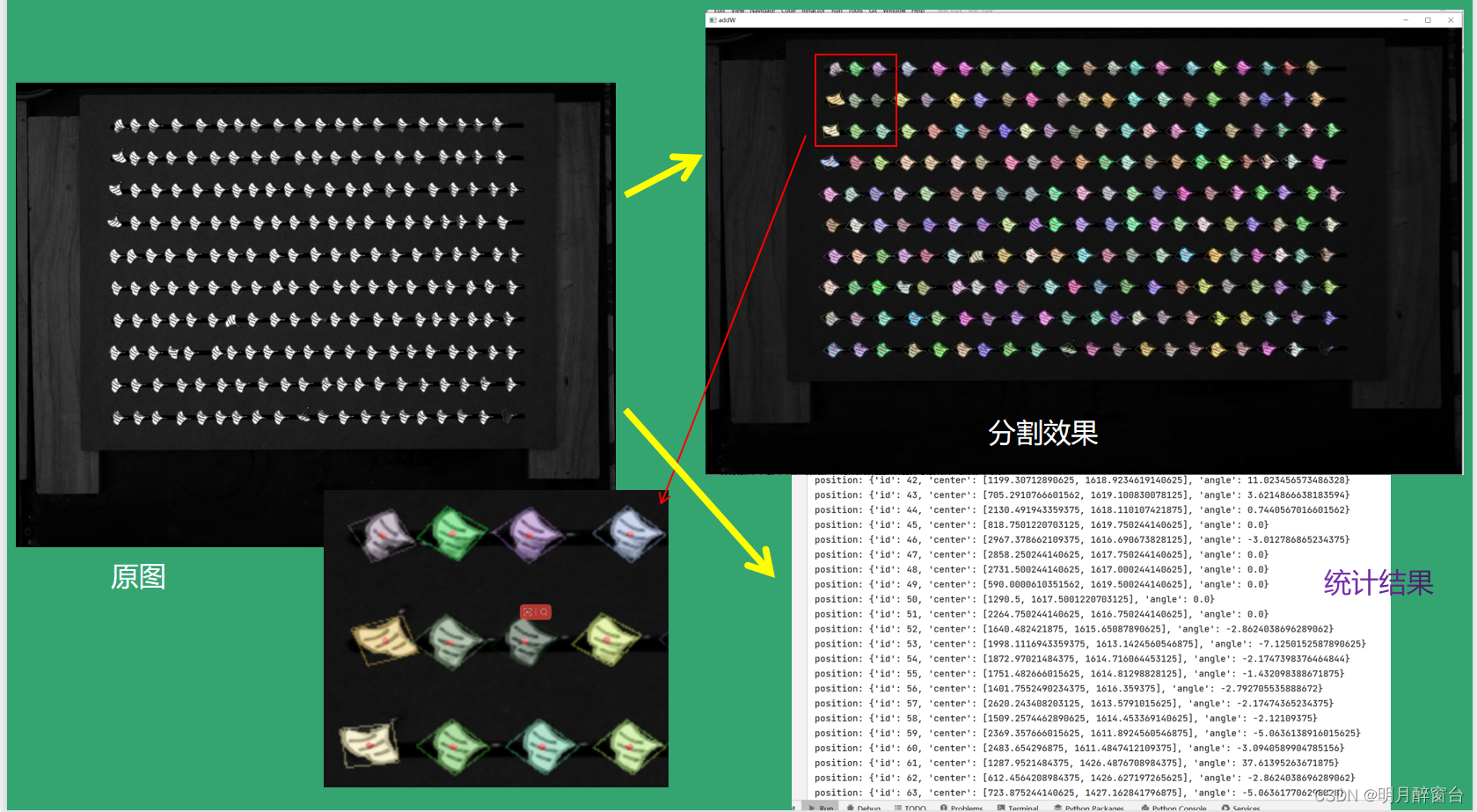
Python - Opencv应用实例之树叶自动分割、标签及统计分析系统
Python - Opencv应用实例之树叶自动分割、标签及统计分析系统 本文通过Python+opencv 实现这样的需求:输出位置和角度(x, y, r),并标记出轮廓基于传统图像处理算法实现,算法原理:输入图像 -> 灰度化 -> 二值化 -> 形态学处理 -> 轮廓提取 -> 树叶中心定位 -…...

IC设计工程师,参加IC面试应该注意哪些细节?
秋招已至,诸多IC设计企业,比如联发科、长鑫、大疆、燧原、地平线、复旦微、兆易创新、百度昆仑芯等,都已经陆续开启了提前批招聘。 很多人对各种关于秋招、面试、简历的比较感兴趣,所以今天就来跟大家分享关于秋招求职面试中的一…...

java poi导入Excel、导出excel
java poi导入Excel、导出excel 导出meven架包 <dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>4.1.1</version></dependency>导入Excel public void uploadFile(HttpServletRequ…...
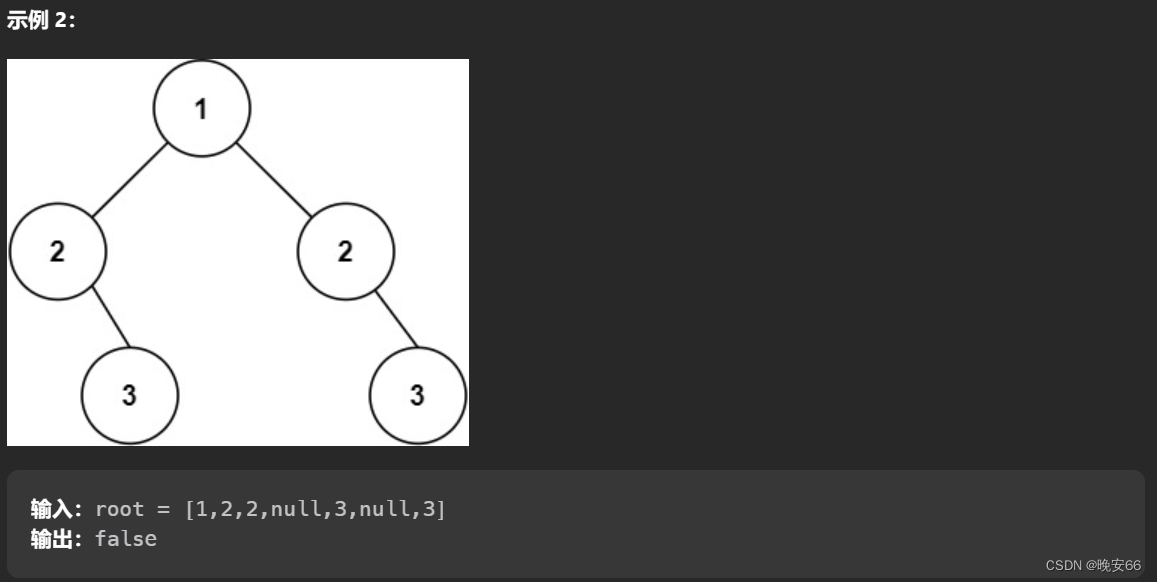
【算法与数据结构】101、LeetCode对称二叉树
文章目录 一、题目二、递归法三、迭代法三、完整代码 所有的LeetCode题解索引,可以看这篇文章——【算法和数据结构】LeetCode题解。 一、题目 二、递归法 思路分析:这道题目标就是要对比左右两半的树是否对称,因此对比不是左右节点是否相等&…...

【N32L40X】学习笔记04-gpio中断库
gpio中断 该函数库的目的就是在统一的地方配置,将配置的不同项放置在一个结构体内部使用一个枚举来定义一个的别名 NVIC 寄存器 NVIC 相关的寄存器定义了可以在 core_cm4.h 文件中找到。我们直接通过程序的定义来分 析 NVIC 相关的寄存器,其定义如下…...

Godot 4 着色器 - Shader调试
我之前用OpenCV进行图像相关处理,觉得已经很不错,结合GDI可以实现流畅的动画效果 直到近来用Shader后才发现,着色器更上一层楼,原来这是入了GPU的坑 Shader编程限制很多,各种不支持,看在它性能不错功能炫…...
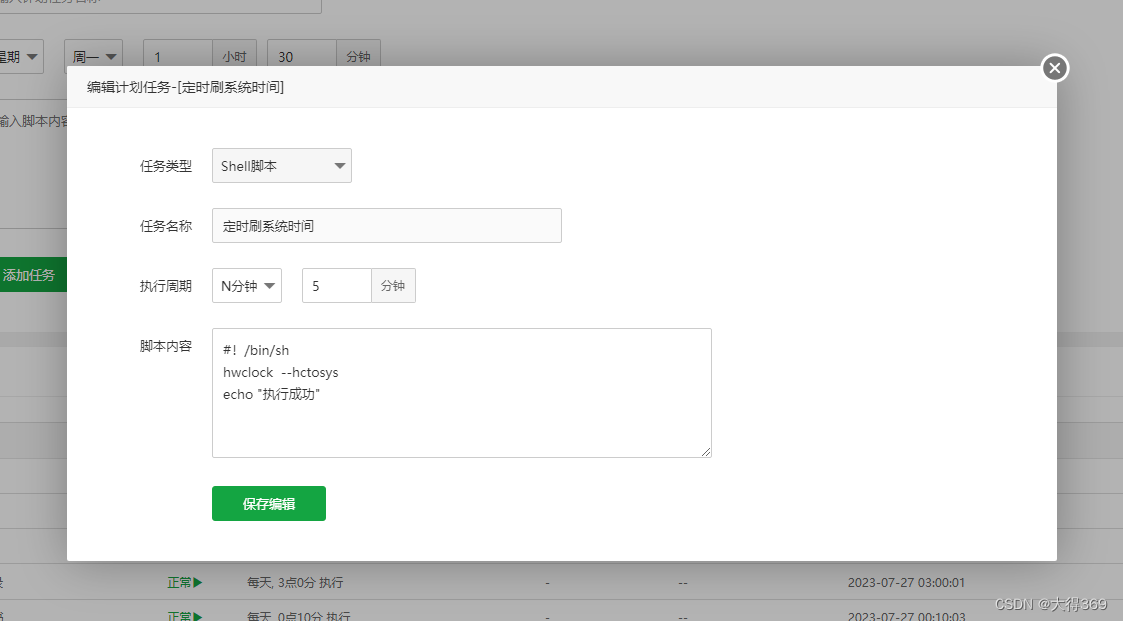
liunx时间慢几分钟,定时更新系统时间
#!/bin/sh hwclock --hctosys echo "执行成功" 定时5分钟执行一次...
C# 委托详解
一.委托的概念 C#中委托也叫代理,委托提供了后期绑定机制(官方解释),功能类似于C中的函数指针,它存储的就是一系列具有相同签名和返回类型的方法的地址,调用委托的时候,它所包含的所有方法都会被执行。 二.委托的用法…...
chatGPT 学习分享:内含PPT分享下载
InstructGPT论文地址: Training language models to follow instructions with human feedbackchatGPT地址:openAI个人整理的PPT(可编辑),下载地址:chatGPT学习分享PPT...
使用CRM进行数据分析的四大好处
使用CRM数据分析系统够帮助企业更好地了解客户需求和行为习惯,提供个性化的服务,从而提高客户满意度和忠诚度。使用CRM数据分析系统可以为企业带来一些好处,包括提高客户洞察力、加强营销策略、提高运营效率等。 1.提高客户洞察力:…...

亚马逊卖家公开信息数据提取:反爬攻防战与 Python 批量采集实战
摘要: 批量获取亚马逊(Amazon)第三方卖家的商业名称、信用代码和注册地址等信息,对于跨境 B2B 拓客和供应链分析具有重要意义。然而,亚马逊的 Cloudflare 盾和 Robot 验证码构成了极高的反爬门槛。本文将深度解析亚马逊…...

用数字逻辑门复刻柏林钟:从二进制编码到硬件实现
1. 项目概述:用数字电路复刻“柏林钟”作为一个在柏林长大的孩子,我从小就对库达姆大街上的那座“柏林钟”着迷。它不像传统时钟那样用指针或数字告诉你时间,而是通过几排不同颜色的发光方块,以一种近乎艺术的方式呈现时间。这种独…...

基于可解释机器学习的城市人口流动空间降尺度分析实践
1. 项目概述:从宏观到微观,解码城市脉搏在城市的肌理中,人口的流动如同血液的循环,承载着经济活力、社会互动与空间结构的全部信息。无论是城市规划师优化公交线路,还是商业分析师评估店铺选址,亦或是公共卫…...

1901-2022年中国气温变化分析实战:用这份1km栅格数据我们能发现什么?
1901-2022年中国气温变化分析实战:如何从1km栅格数据中挖掘气候演变规律当一份覆盖122年、分辨率精确到1公里的气温栅格数据摆在面前时,我们看到的不仅是数字矩阵,更是一部写在经纬度坐标里的气候变迁史诗。这份由逐月数据聚合生成的逐年气温…...

MongoDB Limit 与 Skip 方法详解
MongoDB Limit 与 Skip 方法详解 引言 MongoDB 是一个高性能、可伸缩的文档存储系统,它提供了强大的数据存储和查询功能。在处理大量数据时,Limit 与 Skip 方法是 MongoDB 中常用的查询优化工具。本文将详细介绍 MongoDB 中的 Limit 与 Skip 方法,包括其基本用法、性能影响…...

基于ESP8266与MQTT的家庭水压自动控制系统设计与实现
1. 项目概述与核心需求解析家里水压不稳、供水时断时续,这大概是很多朋友都遇到过的烦心事。我所在的城市供水情况就很不理想,为了解决这个问题,我不得不自己动手,搭建了一套基于ESP8266微控制器的家庭水压增压与储水自动控制系统…...

从零构建FOC轮腿机器人:开源平衡机器人完整指南
从零构建FOC轮腿机器人:开源平衡机器人完整指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software development. | 一个…...

在Node.js服务中集成Taotoken实现稳定的大模型能力调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现稳定的大模型能力调用 对于需要在后端服务中集成AI功能的Node.js开发者而言,直接对接…...

机器学习在犬类癌症筛查中的性能极限与挑战:基于血液数据的多癌种分析
1. 项目概述:当机器学习遇见犬类癌症筛查作为一名长期关注数据科学在生命科学领域应用的从业者,我常常被问及一个充满希望的问题:我们能否像分析人类健康数据一样,利用宠物的常规体检数据,通过机器学习提前发现癌症的蛛…...
)
微信聊天图片丢了别慌!保姆级教程:找回并解密DAT文件(支持新旧版微信路径)
微信DAT图片恢复实战:从文件定位到批量解密的完整指南 微信聊天记录中的图片突然消失?别急着放弃!那些看似无法打开的DAT文件里,可能藏着您的重要回忆或工作资料。本文将带您深入微信存储机制,手把手完成从文件定位到…...