PyTorch使用Transformer进行机器翻译
文章目录
- 简介
- 数据集
- 环境要求
- 实验代码
- 实验结果
- 参考来源
简介
本文使用PyTorch自带的transformer层进行机器翻译:从德语翻译为英语。从零开始实现Transformer请参阅PyTorch从零开始实现Transformer,以便于获得对Transfomer更深的理解。
数据集
Multi30k
环境要求
使用torch, torchtext,spacy,其中spacy用来分词。另外,spacy要求在虚拟环境中下载语言模型,以便于进行tokenize(分词)
# To install spacy languages do:
python -m spacy download en_core_web_sm
python -m spacy download de_core_news_sm
实验代码
代码来源请参考下方的GitHub链接
transformer_translation.py文件
# Bleu score 32.02
import torch
import torch.nn as nn
import torch.optim as optim
import spacy
from utils import translate_sentence, bleu, save_checkpoint, load_checkpoint
from torch.utils.tensorboard import SummaryWriter
from torchtext.datasets import Multi30k
from torchtext.data import Field, BucketIterator"""
To install spacy languages do:
python -m spacy download en_core_web_sm
python -m spacy download de_core_news_sm
"""
spacy_ger = spacy.load("de_core_news_sm")
spacy_eng = spacy.load("en_core_web_sm")def tokenize_ger(text):return [tok.text for tok in spacy_ger.tokenizer(text)]# 将英语进行分词
def tokenize_eng(text):return [tok.text for tok in spacy_eng.tokenizer(text)]german = Field(tokenize=tokenize_ger, lower=True, init_token="<sos>", eos_token="<eos>")english = Field(tokenize=tokenize_eng, lower=True, init_token="<sos>", eos_token="<eos>"
)train_data, valid_data, test_data = Multi30k.splits(exts=(".de", ".en"), fields=(german, english)
)german.build_vocab(train_data, max_size=10000, min_freq=2)
english.build_vocab(train_data, max_size=10000, min_freq=2)class Transformer(nn.Module):def __init__(self,embedding_size,src_vocab_size,trg_vocab_size,src_pad_idx,num_heads,num_encoder_layers,num_decoder_layers,forward_expansion,dropout,max_len,device,):super(Transformer, self).__init__()self.src_word_embedding = nn.Embedding(src_vocab_size, embedding_size)self.src_position_embedding = nn.Embedding(max_len, embedding_size)self.trg_word_embedding = nn.Embedding(trg_vocab_size, embedding_size)self.trg_position_embedding = nn.Embedding(max_len, embedding_size)self.device = deviceself.transformer = nn.Transformer(embedding_size,num_heads,num_encoder_layers,num_decoder_layers,forward_expansion,dropout,)self.fc_out = nn.Linear(embedding_size, trg_vocab_size)self.dropout = nn.Dropout(dropout)self.src_pad_idx = src_pad_idxdef make_src_mask(self, src):src_mask = src.transpose(0, 1) == self.src_pad_idx# (N, src_len)return src_mask.to(self.device)def forward(self, src, trg):src_seq_length, N = src.shapetrg_seq_length, N = trg.shapesrc_positions = (torch.arange(0, src_seq_length).unsqueeze(1).expand(src_seq_length, N).to(self.device))trg_positions = (torch.arange(0, trg_seq_length).unsqueeze(1).expand(trg_seq_length, N).to(self.device))embed_src = self.dropout((self.src_word_embedding(src) + self.src_position_embedding(src_positions)))embed_trg = self.dropout((self.trg_word_embedding(trg) + self.trg_position_embedding(trg_positions)))src_padding_mask = self.make_src_mask(src)trg_mask = self.transformer.generate_square_subsequent_mask(trg_seq_length).to(self.device)out = self.transformer(embed_src,embed_trg,src_key_padding_mask=src_padding_mask,tgt_mask=trg_mask,)out = self.fc_out(out)return out# We're ready to define everything we need for training our Seq2Seq model
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
load_model = False
save_model = True# Training hyperparameters
num_epochs = 10
learning_rate = 3e-4
batch_size = 32# Model hyperparameters
src_vocab_size = len(german.vocab)
trg_vocab_size = len(english.vocab)
embedding_size = 512
num_heads = 8
num_encoder_layers = 3
num_decoder_layers = 3
dropout = 0.10
max_len = 100
forward_expansion = 4
src_pad_idx = english.vocab.stoi["<pad>"]# Tensorboard to get nice loss plot
writer = SummaryWriter("runs/loss_plot")
step = 0train_iterator, valid_iterator, test_iterator = BucketIterator.splits((train_data, valid_data, test_data),batch_size=batch_size,sort_within_batch=True,sort_key=lambda x: len(x.src),device=device,
)model = Transformer(embedding_size,src_vocab_size,trg_vocab_size,src_pad_idx,num_heads,num_encoder_layers,num_decoder_layers,forward_expansion,dropout,max_len,device,
).to(device)optimizer = optim.Adam(model.parameters(), lr=learning_rate)scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, factor=0.1, patience=10, verbose=True
)pad_idx = english.vocab.stoi["<pad>"]
criterion = nn.CrossEntropyLoss(ignore_index=pad_idx)if load_model:load_checkpoint(torch.load("my_checkpoint.pth.tar"), model, optimizer)# 'a', 'horse', 'is', 'walking', 'under', 'a', 'bridge', 'next', 'to', 'a', 'boat', '.
sentence = "ein pferd geht unter einer brücke neben einem boot."for epoch in range(num_epochs):print(f"[Epoch {epoch} / {num_epochs}]")if save_model:checkpoint = {"state_dict": model.state_dict(),"optimizer": optimizer.state_dict(),}save_checkpoint(checkpoint)model.eval()translated_sentence = translate_sentence(model, sentence, german, english, device, max_length=50)print(f"Translated example sentence: \n {translated_sentence}")model.train()losses = []for batch_idx, batch in enumerate(train_iterator):# Get input and targets and get to cudainp_data = batch.src.to(device)target = batch.trg.to(device)# Forward propoutput = model(inp_data, target[:-1, :])# Output is of shape (trg_len, batch_size, output_dim) but Cross Entropy Loss# doesn't take input in that form. For example if we have MNIST we want to have# output to be: (N, 10) and targets just (N). Here we can view it in a similar# way that we have output_words * batch_size that we want to send in into# our cost function, so we need to do some reshapin.# Let's also remove the start token while we're at itoutput = output.reshape(-1, output.shape[2])target = target[1:].reshape(-1)optimizer.zero_grad()loss = criterion(output, target)losses.append(loss.item())# Back proploss.backward()# Clip to avoid exploding gradient issues, makes sure grads are# within a healthy rangetorch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1)# Gradient descent stepoptimizer.step()# plot to tensorboardwriter.add_scalar("Training loss", loss, global_step=step)step += 1mean_loss = sum(losses) / len(losses)scheduler.step(mean_loss)# running on entire test data takes a while
score = bleu(test_data[1:100], model, german, english, device)
print(f"Bleu score {score * 100:.2f}")utils.py文件
import torch
import spacy
from torchtext.data.metrics import bleu_score
import sysdef translate_sentence(model, sentence, german, english, device, max_length=50):# Load german tokenizerspacy_ger = spacy.load("de_core_news_sm")# Create tokens using spacy and everything in lower case (which is what our vocab is)if type(sentence) == str:tokens = [token.text.lower() for token in spacy_ger(sentence)]else:tokens = [token.lower() for token in sentence]# Add <SOS> and <EOS> in beginning and end respectivelytokens.insert(0, german.init_token)tokens.append(german.eos_token)# Go through each german token and convert to an indextext_to_indices = [german.vocab.stoi[token] for token in tokens]# Convert to Tensorsentence_tensor = torch.LongTensor(text_to_indices).unsqueeze(1).to(device)outputs = [english.vocab.stoi["<sos>"]]for i in range(max_length):trg_tensor = torch.LongTensor(outputs).unsqueeze(1).to(device)with torch.no_grad():output = model(sentence_tensor, trg_tensor)best_guess = output.argmax(2)[-1, :].item()outputs.append(best_guess)if best_guess == english.vocab.stoi["<eos>"]:breaktranslated_sentence = [english.vocab.itos[idx] for idx in outputs]# remove start tokenreturn translated_sentence[1:]def bleu(data, model, german, english, device):targets = []outputs = []for example in data:src = vars(example)["src"]trg = vars(example)["trg"]prediction = translate_sentence(model, src, german, english, device)prediction = prediction[:-1] # remove <eos> tokentargets.append([trg])outputs.append(prediction)return bleu_score(outputs, targets)def save_checkpoint(state, filename="my_checkpoint.pth.tar"):print("=> Saving checkpoint")torch.save(state, filename)def load_checkpoint(checkpoint, model, optimizer):print("=> Loading checkpoint")model.load_state_dict(checkpoint["state_dict"])optimizer.load_state_dict(checkpoint["optimizer"])实验结果
对下面的这句德文进行翻译
sentence = "ein pferd geht unter einer brücke neben einem boot."
翻译结果为
['a', 'horse', 'walks', 'underneath', 'a', 'bridge', 'next', 'to', 'a', 'boat', '.', '<eos>']
Bleu score为31.73
跑了10个Epoch,结果如下所示:
# Result
=> Loading checkpoint
[Epoch 0 / 10]
=> Saving checkpoint
Translated example sentence: ['a', 'horse', 'walks', 'under', 'a', 'boat', 'next', 'to', 'a', 'boat', '.', '<eos>']
[Epoch 1 / 10]
=> Saving checkpoint
Translated example sentence: ['a', 'horse', 'walks', 'underneath', 'a', 'bridge', 'beside', 'a', 'boat', '.', '<eos>']
[Epoch 2 / 10]
=> Saving checkpoint
Translated example sentence: ['a', 'horse', 'is', 'walking', 'beside', 'a', 'boat', 'under', 'a', 'bridge', '.', '<eos>']
[Epoch 3 / 10]
=> Saving checkpoint
Translated example sentence: ['a', 'horse', 'walks', 'under', 'a', 'bridge', 'next', 'to', 'a', 'boat', '.', '<eos>']
[Epoch 4 / 10]
=> Saving checkpoint
Translated example sentence: ['a', 'horse', 'walks', 'under', 'a', 'bridge', 'next', 'to', 'a', 'boat', '.', '<eos>']
[Epoch 5 / 10]
=> Saving checkpoint
Translated example sentence: ['a', 'horse', 'walks', 'beside', 'a', 'boat', 'next', 'to', 'a', 'boat', '.', '<eos>']
[Epoch 6 / 10]
=> Saving checkpoint
Translated example sentence: ['a', 'horse', 'is', 'walking', 'underneath', 'a', 'bridge', 'under', 'a', 'boat', '.', '<eos>']
[Epoch 7 / 10]
=> Saving checkpoint
Translated example sentence: ['a', 'horse', 'walks', 'under', 'a', 'bridge', 'next', 'to', 'a', 'boat', '.', '<eos>']
[Epoch 8 / 10]
=> Saving checkpoint
Translated example sentence: ['a', 'horse', 'walks', 'beneath', 'a', 'bridge', 'next', 'to', 'a', 'boat', '.', '<eos>']
[Epoch 9 / 10]
=> Saving checkpoint
Translated example sentence: ['a', 'horse', 'walks', 'underneath', 'a', 'bridge', 'next', 'to', 'a', 'boat', '.', '<eos>']
Bleu score 31.73
参考来源
[1] https://blog.csdn.net/weixin_43632501/article/details/98731800
[2] https://www.youtube.com/watch?v=M6adRGJe5cQ
[3] https://github.com/aladdinpersson/Machine-Learning-Collection/blob/master/ML/Pytorch/more_advanced/seq2seq_transformer/seq2seq_transformer.py
[4] https://blog.csdn.net/g11d111/article/details/100103208
相关文章:
PyTorch使用Transformer进行机器翻译
文章目录 简介数据集环境要求实验代码实验结果参考来源 简介 本文使用PyTorch自带的transformer层进行机器翻译:从德语翻译为英语。从零开始实现Transformer请参阅PyTorch从零开始实现Transformer,以便于获得对Transfomer更深的理解。 数据集 Multi30…...

LoadRunner使用教程
1. LoadRunner简介 LoadRunner是一款广泛使用的性能测试工具 可以对各种应用程序进行性能测试,包括Web应用程序、移动应用程序、企业级应用程序等。它提供了一个综合的性能测试解决方案,包括测试计划设计、脚本录制、测试执行、结果分析和报告生成等功…...
Zia和ChatGPT如何协同工作?
有没有集成ChatGPT的CRM系统推荐?Zoho CRM已经正式与ChatGPT集成。下面我们将从使用场景、使用价值和使用范围等方面切入讲述CRMAI的应用和作用。 Zia和ChatGPT如何协同工作? Zia和ChatGPT是不同的人工智能模型,在CRM中呈现出共生的关系。 …...

【位操作】——获取整数变量最低位为 1 的位置
获取整数变量最低位为 1 的位置 #define BIT_LOW_BIT(y) (((y)&BIT(0)) ? 0 : (((y)&BIT(1)) ? 1 : (((y)&BIT(2)) ? 2 : (((y)&BIT(3)) ? 3 : \(((y)&BIT(4)) ? 4 : (((y)&BIT(5)) ? 5 : (((y)&BIT(6)) ? 6 : (((y)&…...

gtest测试用例注册及自动化调度机制源代码流程分析
gtest的入门参见: 玩转Google开源C单元测试框架Google Test系列(gtest) gtest源码分析流程参见: gtest流程解析 测试用例注册流程分析要点:TEST_F宏替换、C静态成员的动态初始化。 自动化调度流程分析要点:UnitTest、UnitTestIm…...

IOS自动化测试环境搭建教程
目录 一、前言 二、环境依赖 1、环境依赖项 2、环境需求与支持 三、环境配置 1、xcode安装 2、Git安装 3、Homebrew安装(用brew来安装依赖) 4、npm和nodejs安装 5、libimobiledevice安装 6、idevicesinstaller安装 7、ios-deploy安装 8、Ca…...
常用API学习08(Java)
格式化 格式化指的是将数据按照指定的规则转化为指定的形式 。 那么为什么需要格式化?格式化有什么用? 以数字类为例,假设有一个比分牌,在无人得分的时候我们希望以:“00:00”的形式存在,那么…...
:什么是装饰器(decorators)?如何在 TypeScript 中使用它们?)
面试题-TS(八):什么是装饰器(decorators)?如何在 TypeScript 中使用它们?
面试题-TS(八):什么是装饰器(decorators)?如何在 TypeScript 中使用它们? 在TypeScript中,装饰器(Decorators)是一种用于增强代码功能的特殊类型声明。装饰器提供了一种在类、方法、…...
Jenkins 还可以支持钉钉消息通知?一个插件带你搞定!
Jenkins 作为最流行的开源持续集成平台,其强大的拓展功能一直备受测试人员及开发人员的青睐。大家都知道我们可以在 Jenkins 中安装 Email 插件支持构建之后通过邮件将结果及时通知到相关人员。 但其实 Jenkins 还可以支持钉钉消息通知,其主要通过 Ding…...

7.ES使用
ES多条件查询 and , or这种的 ES模糊查询 like这种的 {"wildcard": {"title.keyword": {"value": "*宣讲*"}}}说明: title是要匹配的关键字段名称keyword是属性,表示匹配的是关键字信息,如果不用.ke…...

Web安全基础
1、HTML基础 什么是 HTML HTML 是用来描述网页的一种语言。 HTML 指的是超文本标记语言 (Hyper Text Markup Language) HTML 不是一种编程语言,而是一种标记语言 (Markup language) 标记语言是一套标记标签 (Markup tag) HTML 使用标记标签来描述网页 总的来说&…...

jQueryAPI
文章目录 1.jQuery 选择器1.1 jQuery 基础选择器1.2 jQuery 层级选择器1.3 隐式迭代1.4 jQuery 筛选选择器1.5 jQuery 筛选方法1.6 jQuery 里面的排他思想1.7 链式编程 2.jQuery 样式操作2.1 操作 css 方法2.2 设置类样式方法2.3 类操作与className区别 3.jQuery 效果3.1 显示隐…...

如何将路径字符串数组(string[])转成树结构(treeNode[])?
原文链接:如何将路径字符串数组(string[])转成树结构(treeNode[])? 需求 这里的UI使用的是Element-Plus。 将一个路径字符串数组(当然也可能是其他目标字符串数组),渲染成树。 /*source:/a/b/c/d/e/a/b/e/f/g/a/b/h/a…...

中国工程院院士陈晓红一行莅临麒麟信安调研
7月20日下午,中国工程院院士、湘江实验室主任、湖南工商大学党委书记陈晓红,湘江实验室副主任、湖南工商大学副校长刘国权,湘江实验室副主任、湖南工商大学党委组织部统战部常务副部长胡春华等领导一行莅临麒麟信安调研。麒麟信安董事长杨涛&…...

解决Linux环境下启动idea服务,由于权限问题无法正常启动问题
问题: 在Linux环境下启动idea服务,一直提示: invalid registry store file /app/appuser/.dmf/dubbo,cause:failed to create directory /app/appuser! 原因:文件夹中没有操作权限。 解决: (1࿰…...
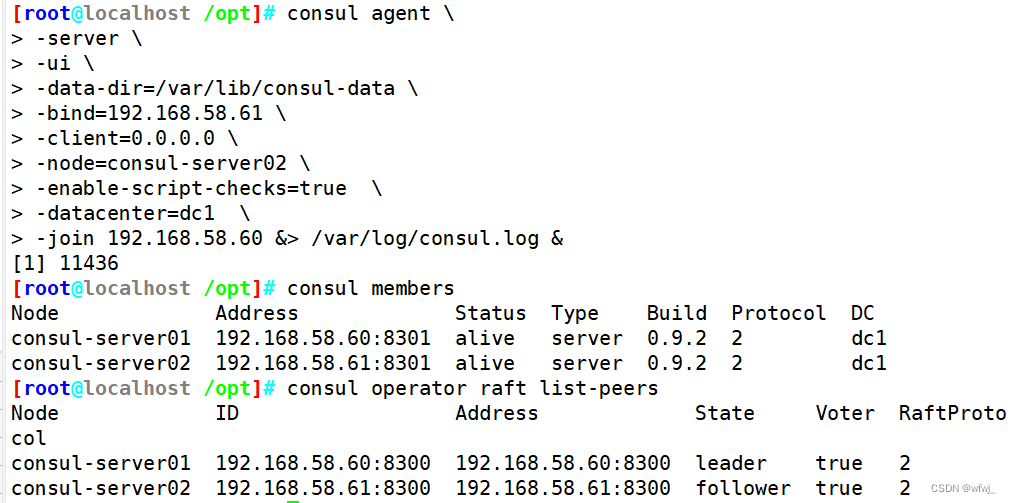
Linux6.16 Docker consul的容器服务更新与发现
文章目录 计算机系统5G云计算第四章 LINUX Docker consul的容器服务更新与发现一、consul 概述1.什么是服务注册与发现2.什么是consul 二、consul 部署1.consul服务器2.registrator服务器3.consul-template4.consul 多节点 计算机系统 5G云计算 第四章 LINUX Docker consul的…...
Redis学习2--使用java操作Redis
1、java操作Redis库的比较 Redis有各种语言的客户端可以来操作redis数据库,其中java语言主要有Jedis与lettuce ,Spring Data Redis封装了上边两个客户端,优缺点如下: 2、使用Jedis操作Redis Jedis使用的基本步骤: 引…...

[游戏数值] 常用刷新次数钻石消耗的设计
需满足要求 以一定规律增加能够在较少次数内增加到较大数值平滑增长 设计思路 增加值INT((当前序号-1)/X)*YZ X2,表示希望几个一组,通过INT()取整可获得0、0、1、1、2、2…这样的序列Y10,表示基础值,将上述序列变为0、0、10、1…...

rancher 2.5.7 证书过期处理方案
背景:现场搭建的单节点 rancher 问题:rancher的 ui 界面无法访问 排查:排查rancher容器日志报错 time“2021-12-29T08:27:32.616638402Z” levelinfo msg“Waiting for master node startup: resource name may not be empty” 2021-12-29 08…...

Tomcat中的缓存配置
Tomcat中的缓存配置通常是通过Web应用程序的context.xml文件或Tomcat的server.xml文件进行设置。下面提供一个简单的案例来说明如何在Tomcat中配置缓存。 假设您的Web应用程序名为"myapp",我们将在context.xml中添加缓存配置。 打开Tomcat安装目录&…...

无机布防火卷帘门价格怎么算?按尺寸定制,按需报价
无机布防火卷帘门作为建筑防火分区的核心设备,价格一直是工程采购的关注重点。很多用户在询价时,会发现不同厂家的报价差异较大,这是因为无机布防火卷帘门的价格并非按统一单价计算,而是完全根据项目的实际需求定制化核算。 &…...

Buzz音频转录完全指南:3大核心功能+5个实战场景,快速掌握本地语音转文字技术
Buzz音频转录完全指南:3大核心功能5个实战场景,快速掌握本地语音转文字技术 【免费下载链接】buzz Buzz transcribes and translates audio offline on your personal computer. Powered by OpenAIs Whisper. 项目地址: https://gitcode.com/GitHub_Tr…...

利用DiSEqC协议与AVR单片机驱动卫星天线电机改造户外设备
1. 项目概述:用卫星天线电机驱动一切如果你手头有一些需要承受风吹日晒、还得精确转动的设备,比如一个户外的大型定向天线,或者一个需要定期调整角度的太阳能板支架,甚至是一个坚固的监控云台,你可能会为驱动机构发愁。…...

基于LM22678的树莓派硬盘专用电源设计:解决供电不稳与电流冲击
1. 项目概述:为什么我们需要一个“专用”电源?如果你正在用树莓派搭配一块机械硬盘搭建一个家庭服务器或者个人云存储,可能已经遇到了一个不大不小的麻烦:供电不稳。树莓派官方推荐的5V/3A电源,单独带树莓派4B跑满负载…...

飞书远程控机:OpenClaw配置全攻略
本文详细介绍如何通过 OpenClaw 工具对接飞书开放平台,配置智能机器人实现 Windows 电脑的远程控制。主要内容涵盖文件管理和程序启动等核心功能的实现方法,并提供完整的配置指南与常见问题解决方案。 一、使用前提说明 1. 系统要求 仅适用于 Windows…...

对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异 对于个人开发者或项目管理者而言,在接入大模型服务时&a…...

中兴光猫终极管理指南:解锁工厂模式与Telnet权限的实战教程
中兴光猫终极管理指南:解锁工厂模式与Telnet权限的实战教程 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 掌握中兴光猫的设备管理和权限获取能力是网络管理员和技术爱好者…...
做电影评论情感分类)
告别数据饥荒:用PyTorch手把手实现原型网络(Prototypical Networks)做电影评论情感分类
告别数据饥荒:用PyTorch手把手实现原型网络做电影评论情感分类 在自然语言处理领域,情感分析一直是热门研究方向,但现实中的开发者常面临一个尴尬困境:标注数据太少。传统深度学习方法动辄需要成千上万的标注样本,而实…...

XML 服务器
XML 服务器 引言 XML(可扩展标记语言)服务器在现代互联网技术中扮演着至关重要的角色。它为数据的传输和处理提供了灵活且高效的方式。本文将深入探讨XML服务器的概念、工作原理、应用场景及其在软件开发中的重要性。 什么是XML服务器? XML服务器是一种用于存储、处理和…...

厨房空调技术白皮书:从风冷到水冷,制冷系统在厨房场景中的工程化演进
厨房空调是暖通行业近三年技术迭代最密集的细分品类。从最初的"凉霸"(本质是风扇),到风冷分体式,再到水冷一体式,每代技术都在解决上一代没有覆盖的用户痛点。本文以工程技术视角,梳理四代厨房制…...