机器学习基础 数据集、特征工程、特征预处理、特征选择 7.27
机器学习基础
1. 数据集
2. 特征工程
3. 学习分类
4. 模型
5. 损失函数
6. 优化
7. 过拟合
8. 欠拟合
数据集
又称资料集、数据集合或者资料集合,是一种由数据所组成的集合
特征工程
1. 特征需求
2. 特征设计
3. 特征处理特征预处理、特征选择、特征降维
4. 特征验证
特征预处理
特征预处理:1.无量纲化2.信息提取3.信息数据化4.缺失补全5.信息利用率均衡
无量纲化
1.标准化
import numpy as np
# 从sklearn框架的 preprocessing预处理模块中导入StandardScaler类
from sklearn.preprocessing import StandardScaler# 准备7个点的x坐标
x = np.arange(7).reshape(7, 1)
# 准备7个点的y坐标
y = np.array([2, 10, 35, 100, 45, 20, 5]).reshape(7, 1)
# 将x和y合并成一个二维数组,代表7个点的数据,每行代表一个点的(x, y)坐标值
# x_data就成为 机器学习的数据集
x_data = np.hstack((x, y))
print(x_data)# 数学公式 :x = (x - x_mean)/x_std 数学公式的标准化处理
# np.mean() : 求平均值
# np.std() : 求方差,标准差
xx = (x_data - np.mean(x_data))/np.std(x_data)
print(xx)# 实例标准化处理的类对象
scaler = StandardScaler()
# 通过类对象标准化处理数据 fit_transform() : 处理数据
xx = scaler.fit_transform(x_data)
print(xx)
"""标准化使用前提:让数据处理后处于同一规格,并且任然呈现 正态分布1、数据的规格或者单位不一致2、数据成正态分布
"""D:\Anaconda\anaconda\envs\tf\python.exe D:\pycharm\python\day6\1.特征预处理\1.无量纲化\1.标准化.py
[[ 0 2][ 1 10][ 2 35][ 3 100][ 4 45][ 5 20][ 6 5]]
[[-0.64175426 -0.56625376][-0.60400401 -0.26425176][-0.56625376 0.67950451][-0.52850351 3.13327081][-0.49075326 1.05700702][-0.45300301 0.11325075][-0.41525276 -0.45300301]]
[[-1.5 -0.91367316][-1. -0.66162539][-0.5 0.12602388][ 0. 2.173912 ][ 0.5 0.44108359][ 1. -0.34656568][ 1.5 -0.81915524]]进程已结束,退出代码0
2.归一化
import numpy as np
# 从sklearn框架的 preprocessing预处理模块中导入Normalizer归一化处理类
from sklearn.preprocessing import Normalizer# 准备7个点的x坐标
x = np.arange(7).reshape(7, 1)
# 准备7个点的y坐标
y = np.array([2, 10, 35, 60, 100, 200, 250]).reshape(7, 1)x_data = np.hstack((x, y))
# 数学公式 : x = (x - x_mean)/(x_max - x_min)
xx = (x_data - np.mean(x_data)) / (np.max(x_data) - np.min(x_data))
print(x_data)
print(xx)normalizer = Normalizer()
xx = normalizer.fit_transform(x_data)
print(xx)"""归一化处理前提:处理后的数据处于同一量级,并且被缩放到[0, 1]之间1.数据规格或者单位不一致2.数据没有呈现正态分布,呈现线性变化
"""D:\Anaconda\anaconda\envs\tf\python.exe D:\pycharm\python\day6\1.特征预处理\1.无量纲化\2.归一化.py
[[ 0 2][ 1 10][ 2 35][ 3 60][ 4 100][ 5 200][ 6 250]]
[[-0.19371429 -0.18571429][-0.18971429 -0.15371429][-0.18571429 -0.05371429][-0.18171429 0.04628571][-0.17771429 0.20628571][-0.17371429 0.60628571][-0.16971429 0.80628571]]
[[0. 1. ][0.09950372 0.99503719][0.05704979 0.99837133][0.04993762 0.99875234][0.03996804 0.99920096][0.02499219 0.99968765][0.02399309 0.99971212]]进程已结束,退出代码0信息数据化
1.特征二值化
import numpy as np# 从框架的 预处理模块导入 特征二值化处理类 Binarizer
from sklearn.preprocessing import Binarizerx = np.array([20, 35, 40, 75, 60, 55, 50]).reshape(-1, 1)# 构造二值化对象,设定分类的阈值 threshold=50
scaler = Binarizer(threshold=50)
# 处理数据
xx = scaler.fit_transform(x)
print(xx)D:\Anaconda\anaconda\envs\tf\python.exe D:\pycharm\python\day6\1.特征预处理\2.信息数据化\1.特征二值化.py
[[0][0][0][1][1][1][0]]
2. Ont-hot编码
"""ont-hot编码,又称独热编码。目的是保证每个数据 距远点相同位置。每个可能出现的结果概率相同
"""
import numpy as np
from sklearn.preprocessing import OneHotEncoder
y = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]).reshape(-1, 1)# 构造ont-hot编码对象,指定sparse存储方式:稀疏存储方式False
scaler = OneHotEncoder(sparse=False)
yy = scaler.fit_transform(y)
print(yy)D:\Anaconda\anaconda\envs\tf\python.exe D:\pycharm\python\day6\1.特征预处理\2.信息数据化\ont-hot编码.py
[[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.][0. 1. 0. 0. 0. 0. 0. 0. 0. 0.][0. 0. 1. 0. 0. 0. 0. 0. 0. 0.][0. 0. 0. 1. 0. 0. 0. 0. 0. 0.][0. 0. 0. 0. 1. 0. 0. 0. 0. 0.][0. 0. 0. 0. 0. 1. 0. 0. 0. 0.][0. 0. 0. 0. 0. 0. 1. 0. 0. 0.][0. 0. 0. 0. 0. 0. 0. 1. 0. 0.][0. 0. 0. 0. 0. 0. 0. 0. 1. 0.][0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]]3.缺失数据补全
import numpy as np
# 缺失数据补全
from sklearn.impute import SimpleImputer
x = np.array([[1, 2, 3, 4],[1, np.nan, 5, 6],[7, 2, np.nan, 11],[np.nan, 25, 25, 16]])
# 构造补全法的类对象,指定补全的方法
"""补全方法 strategy:1.“mean”:平均数补齐法。当前特征列其余数据的平均值2."median":中位数补全法。数据从小到大中间的数据3."most_frequent":出现次数最多的数据补全。如果出现次数都一样,则取第一个
"""xx = SimpleImputer(strategy="mean").fit_transform(x)
xx = SimpleImputer(strategy="median").fit_transform(x)
xx = SimpleImputer(strategy="most_frequent").fit_transform(x)
xx = SimpleImputer(strategy="constant").fit_transform(x)print(xx)D:\Anaconda\anaconda\envs\tf\python.exe D:\pycharm\python\day6\1.特征预处理\2.信息数据化\缺失数据补全.py
[[ 1. 2. 3. 4.][ 1. 0. 5. 6.][ 7. 2. 0. 11.][ 0. 25. 25. 16.]]
特征选择
1.方差选择法
import numpy as np# 从框架的 特征选择模块导入 VarianceThreshold方差选择法
from sklearn.feature_selection import VarianceThreshold
x = np.array([[78, 23, 12, 34, 98],[23, 22, 13, 56, 71],[10, 21, 14, 31, 60],[5, 29, 26, 30, 40]])# 计算各特征列的方差值
# x.shape --> (4, 5) x.shape[1] ==> 5
for i in range(x.shape[1]):# np.var() :计算数据的方差print("第{}列的方差值为{}" .format(i, np.var(x[:, i])))
# 方差值越小说明该特征列的数据发散性不好,对于机器学习没有什么意义,因此需要省略
# 构造方差选择法的对象,指定筛选的方差阈值为100,保留方差值大于100的特征列
feature = VarianceThreshold(threshold=100)
xx = feature.fit_transform(x)
print(xx)
# variances_:该属性返回 各特征列的方差值
print(feature.variances_)"""方差选择法:特征列数据越发散,特征就越明显,方差值就越大1.特征选择法,可以让预处理后的特征数据量减小,提升机器学习的效率2.特征量少了,特征值反而更明显,机器学习的准确性更强
"""D:\Anaconda\anaconda\envs\tf\python.exe D:\pycharm\python\day6\2.特征选择\1.方差选择法.py
第0列的方差值为843.5
第1列的方差值为9.6875
第2列的方差值为32.1875
第3列的方差值为113.1875
第4列的方差值为438.6875
[[78 34 98][23 56 71][10 31 60][ 5 30 40]]
[843.5 9.6875 32.1875 113.1875 438.6875]
2.相关系数法
"""相关系数法:判断特征数据对于目标(结果)的相关性。相关性越强说明特征越明显
"""
import numpy as np
from sklearn.feature_selection import SelectKBestx = np.array([[78, 23, 12, 34, 98],[23, 22, 13, 56, 71],[10, 21, 14, 31, 60],[5, 29, 26, 30, 40]])
# 准备数据集的目标(标签):数据集有4条数据,标签就应该有4个, 只能用0和1表示
y = np.array([1, 1, 1, 0])# 构造 相关系数选择法的对象,指定相关性最强的 k列数据保存
k = SelectKBest(k=3)
xx = k.fit_transform(x, y)
# pvalues : 相关系数 p值,p值越小相关性越强;
# scores_ : 相关系数 s值,s值越小,相关性越弱
print(k.pvalues_)
print(k.scores_)
print(xx)D:\Anaconda\anaconda\envs\tf\python.exe D:\pycharm\python\day6\2.特征选择\2.相关系数法.py
[0.5229015 0.02614832 0.00779739 0.5794261 0.24884702]
[ 0.58940905 36.75 126.75 0.42978638 2.5895855 ]
[[23 12 98][22 13 71][21 14 60][29 26 40]]
相关文章:

机器学习基础 数据集、特征工程、特征预处理、特征选择 7.27
机器学习基础 1. 数据集 2. 特征工程 3. 学习分类 4. 模型 5. 损失函数 6. 优化 7. 过拟合 8. 欠拟合数据集 又称资料集、数据集合或者资料集合,是一种由数据所组成的集合特征工程 1. 特征需求 2. 特征设计 3. 特征处理特征预处理、特征选择、特征降维 4. 特征验…...

Sass 常用的功能!
Sass 常用功能 Sass 功能有很多,这边只列举一些比较常用的。 嵌套规则 (Nested Rules) Sass 允许将一套 CSS 样式嵌套进另一套样式中,内层的样式将它外层的选择器作为父选择器。 编译前 .box {.box1 {background-color: red;}.box2 {background-col…...

chmod命令详细使用说明
chmod命令详细使用说明 chmod是Unix和类Unix系统上用于更改文件或目录权限的命令。它是"change mode"的缩写。在Linux和其他类Unix操作系统中,文件和目录具有权限位,用来控制哪些用户可以访问、读取、写入或执行它们。chmod命令允许用户修改这…...

ICC2如何计算Gate Count?
我正在「拾陆楼」和朋友们讨论有趣的话题,你⼀起来吧?知识星球入口 我们认为gate count等于standard cell(非physical only)总面积 / 最小驱动二输入与非门面积。 ICC2没有专门的命令去报告gate count,只能自己计算,使用report_d…...
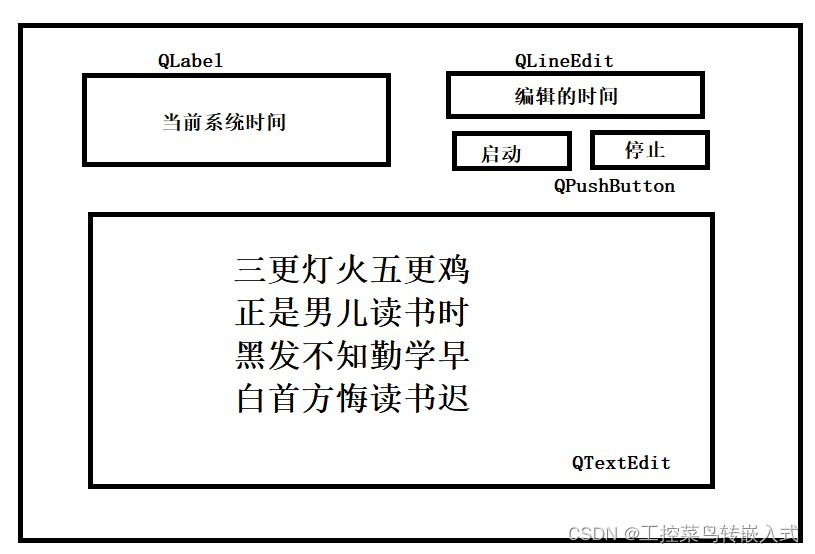
Qtday3作业
作业 头文件 #ifndef WIDGET_H #define WIDGET_H#include <QPushButton> #include <QTextToSpeech> #include <QWidget> #include <QDebug> #include <QTimer> //定时器类 #include <QTime> //时间类 #include <QTimerEvent>…...

全球程序员需要知道的50+网址,有多少你第一次听说?
作为程序员,需要知道的50网址,有多少你第一次听说 GitHub (github.com): 最大的代码托管平台,开源项目和代码分享的社区。程序员可以在这里找到各种有趣的项目,参与开源贡献或托管自己的代码。 Stack Overflow (stackoverflow.co…...
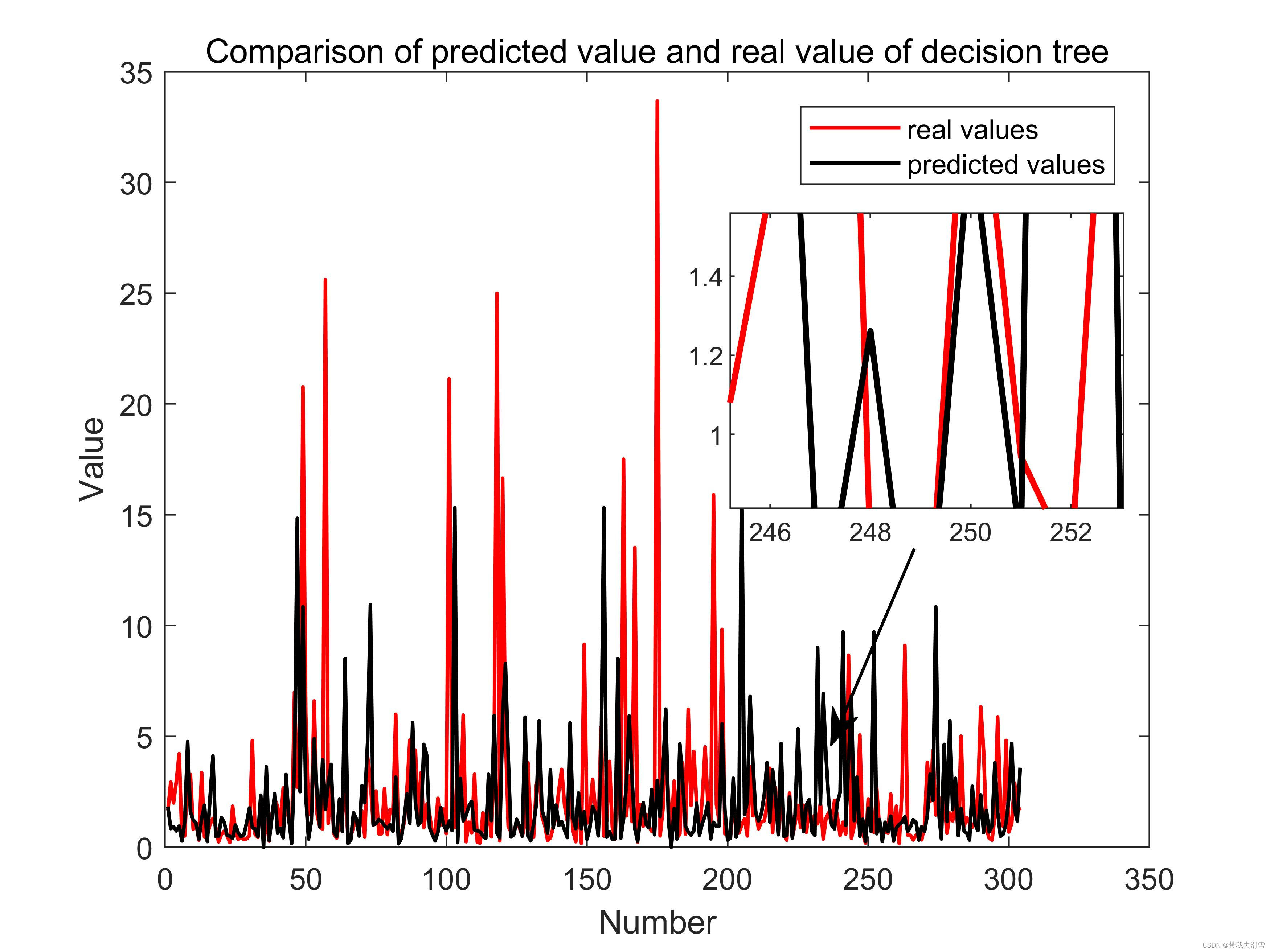
Matlab中实现对一幅图上的局部区域进行放大
大家好,我是带我去滑雪! 局部放大图可以展示图像中的细节信息,使图像更加直观和精美,此次使用magnify工具实现对绘制的figure选择区域绘制,图像效果如下: 1、基本图像绘制 这里选择绘制一个散点图ÿ…...
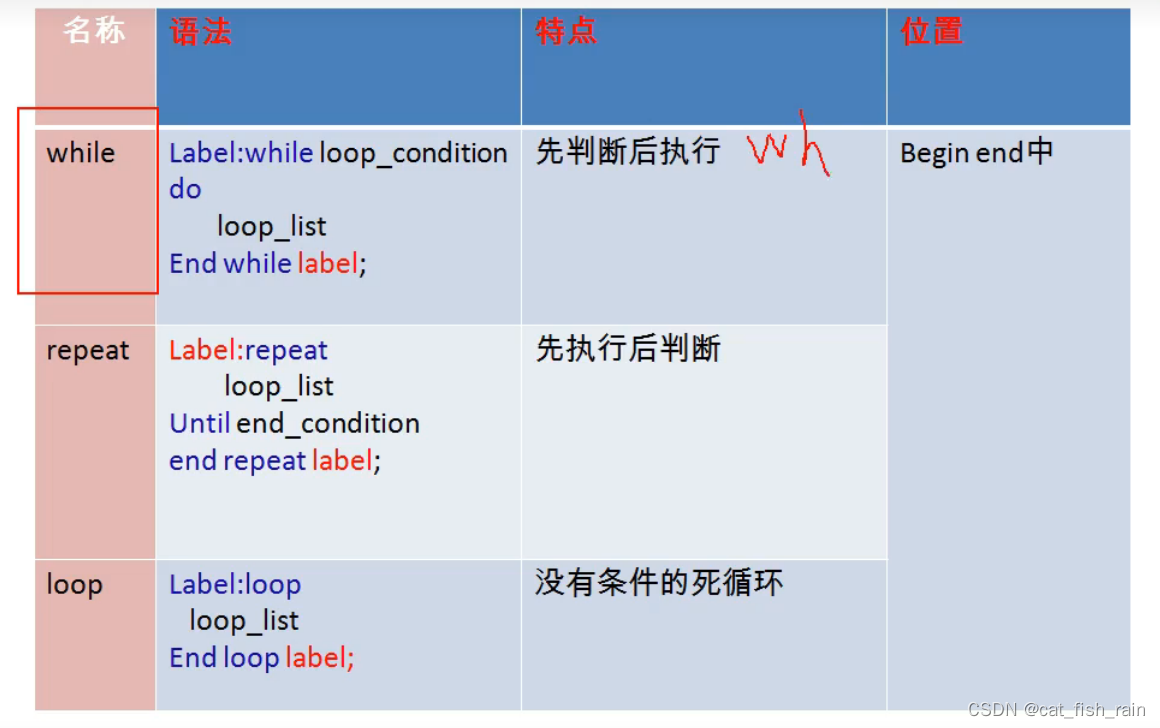
mysql-速成补充
目录 1.演示事务 编辑 1.1 read-uncommitted 1.2 read-committed 1.3 repeatable read 1.4 幻读 1.5 serializable 1.6 savepoint 2 变量 2.1 语法 2.2 举例 3 存储过程和函数 3.1 特点和语法 3.2 举例 4.函数 4.1 语法 4.2 举例 5 流程控制 5.1 分…...
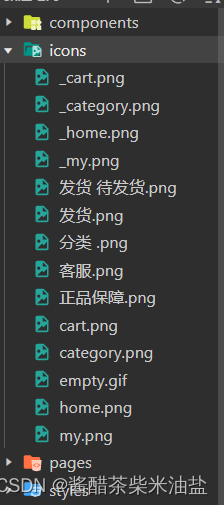
微信小程序,商城底部工具栏的实现
效果演示: 前提条件: 去阿里云矢量图标,下载8个图标,四个黑,四个红,如图: 新建文件夹icons,把图标放到该文件夹,然后把该文件夹移动到该项目的文件夹里面。如图所示 app…...
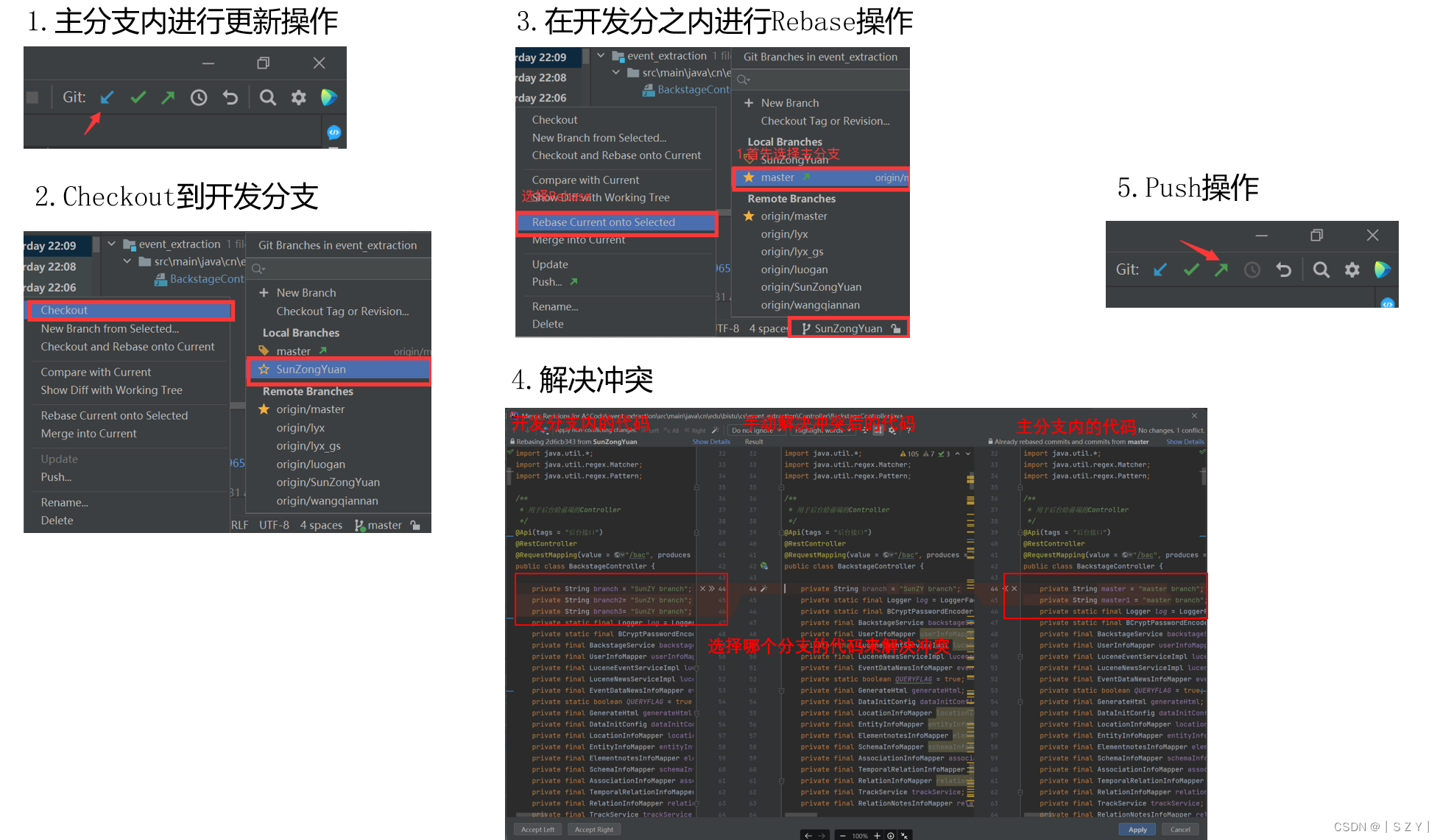
Lab———Git使用指北
Lab———Git使用指北 🤖:使用IDEA Git插件实际工作流程 💡 本文从实际使用的角度出发,以IDEA Git插件为基本讲述了如果使用IDEA的Git插件来解决实际开发中的协作开发问题。本文从 远程仓库中拉取项目,在本地分支进行开发&#x…...

ChatGPT的工作原理:从输入到输出
🌷🍁 博主 libin9iOak带您 Go to New World.✨🍁 🦄 个人主页——libin9iOak的博客🎐 🐳 《面试题大全》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~ἳ…...
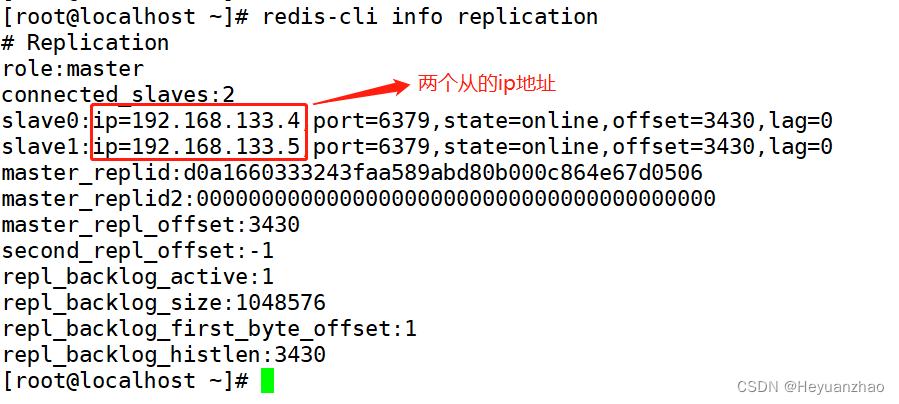
redis数据库与主从复制
目录 一 基本操作 二 执行流程 三 reids持久化 四 rdb和aof持久化的过程 五 为什么会有内存碎片 六 redis组从复制 一 基本操作 set :存放数据 例如 set 键值 内容 set k kokoko k就是键值 kokoko就是内容 get:获取数据 例如 get k 就会出来 k对应的数据 keys 查询键…...
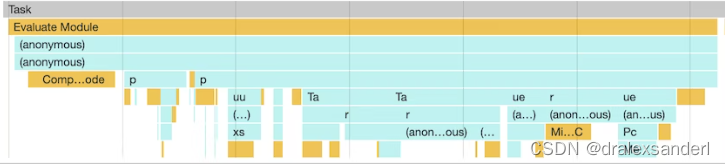
js加载和长任务
js加载和长任务 本文将讲解以下浏览器如何加载js,并介绍一些可以提高网页加载速度的方法。 Evaluate Script 如果我们在devtools的performance中分析过网站的加载性能,可能会看到一个很长的任务,叫做Evaluate Script. 在这种情况下&#x…...

利用Stable diffusion Ai 制作艺术二维码超详细参数和教程
大家有没有发现最近这段时间网上出现了各种各样的AI艺术二维码,这种二维码的出现,简直是对二维码的“颠覆式创新”,直接把传统的二维码提升了一个维度!作为设计师的我们怎么可以不会呢? 今天就教大家怎么制作这种超有艺…...
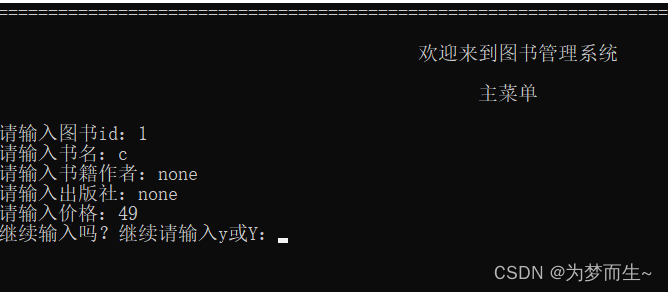
【C语言课程设计】图书管理系统
引言: 图书管理系统是一个重要的信息管理系统,对于图书馆和书店等机构来说,它能够方便地管理图书的录入、显示、查询、修改和删除等操作。本实验基于C语言开发了一个简单的图书管理系统,通过账户名和密码进行系统访问和权限控制&a…...
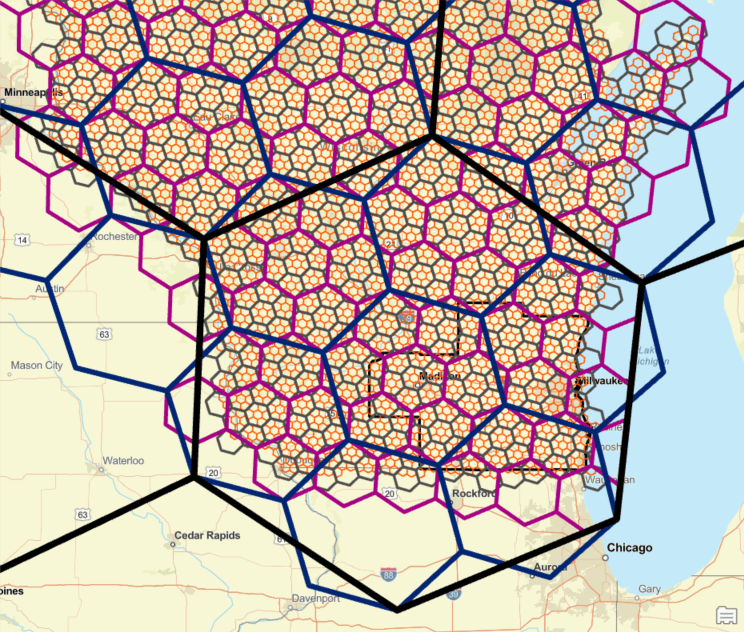
在 ArcGIS Pro 中使用 H3 创建蜂窝六边形
H3是Uber开发的分层索引系统,它使用六边形来平铺地球表面。H3在二十面体(一个具有20个三角形面和12个顶点的形状)上构建其六边形网格。由于仅用六边形不可能平铺二十面体,因此每个分辨率需要12个五边形来完成网格。分层索引网格意味着每个六边形都可以细分为子单元六边形。…...
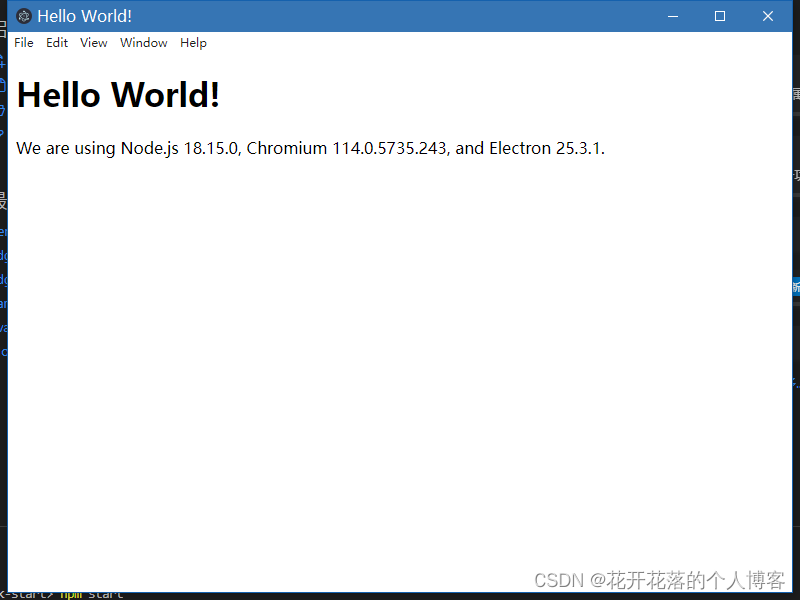
创建Electron项目
一、使用vite 构建 electron项目 npm init vitelatest Need to install the following packages:create-vitelatest Ok to proceed? (y) y √ Project name: ... CertificateDownload √ Package name: ... certificatedownload √ Select a framework: Vue √ Select a var…...
Spring Boot实践一
一、Spring Boot简介 Spring Boot是一个基于Spring框架的快速开发应用程序的工具。它提供了一种快速、方便的方式来创建基于Spring的应用程序,而无需繁琐的配置。Spring Boot通过自动配置和约定大于配置的方式,使得开发者可以更加专注于业务逻辑的实现&…...

简单认识NoSQL的Redis配置与优化
文章目录 一、关系型数据库与非关系型数据库1、关系型数据库:2、非关系型数据库3、关系型数据库和非关系型数据库区别:4、非关系型数据库应用场景 二.Redis1、简介2、优点:3、Redis为什么这么快? 三、Redis 安装部署1、安装配置2、…...

开发一个RISC-V上的操作系统(二)—— 系统引导程序(Bootloader)
目录 文章传送门 一、什么是Bootloader 二、简单的启动程序 三、上板测试 文章传送门 开发一个RISC-V上的操作系统(一)—— 环境搭建_riscv开发环境_Patarw_Li的博客-CSDN博客 开发一个RISC-V上的操作系统(二)—— 系统引导…...

用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑
用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑 当你第一次面对"换硬币"这类组合问题时,那种既兴奋又困惑的感觉我至今记忆犹新。作为C语言初学者,理解多重循环的运作机制就像在迷宫中寻找出口——每次你以为找到了…...

LizzieYzy:你的智能围棋教练,让AI分析变得简单有趣 [特殊字符]
LizzieYzy:你的智能围棋教练,让AI分析变得简单有趣 🎯 【免费下载链接】lizzieyzy LizzieYzy - GUI for Game of Go 项目地址: https://gitcode.com/gh_mirrors/li/lizzieyzy 还在为复盘找不到关键点而烦恼吗?想提升棋力却…...

终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理
终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension 想要在浏览网页、处理文档的同时继续观看视频内容吗…...
:3类高危使用场景+2个监管红线预警)
Claude SWOT分析(内部风控文档流出版):3类高危使用场景+2个监管红线预警
更多请点击: https://intelliparadigm.com 第一章:Claude SWOT分析(内部风控文档流出版):3类高危使用场景2个监管红线预警 高危使用场景识别 在企业级AI应用中,Claude模型若未经严格风控适配,…...

万星easy-vibe:描述需求即发布 零基础无需学语法
开源Easy-Vibe是一套开源AI编程学习方案,把学习顺序从先学语法再做项目翻转为直接做项目。文章拆解了项目驱动、提示词编写、AI编辑器和多Agent协作的完整流程,解释了为什么想法比语法更重要。 github上datawhalechina/easy-vibe:它在GitHub…...

3分钟告别英文恐惧:Android Studio中文界面轻松切换指南
3分钟告别英文恐惧:Android Studio中文界面轻松切换指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 你是否曾经因…...

SpeakingURL版本升级指南:从旧版本迁移到最新版本的完整教程
SpeakingURL版本升级指南:从旧版本迁移到最新版本的完整教程 【免费下载链接】speakingurl Generate a slug – transliteration with a lot of options 项目地址: https://gitcode.com/gh_mirrors/sp/speakingurl SpeakingURL是一款强大的URL友好化工具&…...

Godot 2D随机地图三大静默故障:黑屏、穿墙、寻路失败的根源与修复
1. 为什么刚上手Godot做2D随机地图就总卡在“生成出来是黑的”“角色穿墙”“房间连不通”这三件事上?如果你是刚从Unity或GameMaker转来Godot,或者第一次用GDScript写程序逻辑的新手,大概率已经在2D随机地图生成这个环节反复摔过跟头——不是…...

ComfyUI-WD14-Tagger:AI智能图像标签提取的终极完整指南
ComfyUI-WD14-Tagger:AI智能图像标签提取的终极完整指南 【免费下载链接】ComfyUI-WD14-Tagger A ComfyUI extension allowing for the interrogation of booru tags from images. 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-WD14-Tagger 在AI图像…...

Safe Exam Browser虚拟机绕过实战:深度解析与安全研究指南
Safe Exam Browser虚拟机绕过实战:深度解析与安全研究指南 【免费下载链接】safe-exam-browser-bypass A VM and display detection bypass for SEB. 项目地址: https://gitcode.com/gh_mirrors/sa/safe-exam-browser-bypass 在数字化教育快速发展的今天&…...