Hadoop集成Hive
一、环境与软件准备
说明:服务器已用主机名代替,可根据自己的需求,改为IP地址
环境
| 服务器 | 组件 |
|---|---|
| master | NameNode、DataNode、Nodemanager、ResourceManager、Hive、Hive的metastore、Hive的hiveserver2、mysql |
| Secondary | SecondaryNameNode、DataNode、NodeManager |
| Datanode | DataNode、NodeManager、Hive的beeline访问方式 |
1、java版本1.8
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
linux$:] cd /soft
linux$:] tar -zxvf jdk-8u321-linux-x64.tar.gz
linux$:] cp -r jdk1.8.0_321 /usr/bin/jdklinux$:] vi /etc/profileexport JAVA_HOME=/usr/bin/jdk # jdk1.8.0_311为解压缩的目录名称
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/liblinux$:] source /etc/profile
2、Rsync CentOS中默认存在
3、zstd、openssl、autoconf、automake、libtool、ca-certificates安装
linux$:] yum -y install zstd,yum -y install openssl-devel autoconf automake libtool ca-certificates
4、ISA-L
下载地址:https://github.com/intel/isa-l
linux$:] cd /soft
linux$:] unzip master.zip
linux$:] cd master
linux$:] ./autogen.sh
linux$:] ./configure
linux$:] make && make install && make -f Makefile.unx
其它操作,可省略(后面有解释)
make check : create and run tests
make tests : create additional unit tests
make perfs : create included performance tests
make ex : build examples
make other : build other utilities such as compression file tests
make doc : build API manual
5、nasm与yasm
yasm组件
linux$:] curl -O -L http://www.tortall.net/projects/yasm/releases/yasm-1.3.0.tar.gz
linux$:] tar -zxvf yasm-1.3.0.tar.gz
linux$:] cd yasm
linux$:] ./configure;make -j 8;make install
nasm组件
linux$:] wget http://www.nasm.us/pub/nasm/releasebuilds/2.14.02/nasm-2.14.02.tar.xz
linux$:] cd nasm
linux$:] tar xf nasm-2.14.02.tar.xz
linux$:] ./configure;make -j 8;make install
6、ssh
linux$:] ssh-keygen -t rsa
所有主机之间互通后,本机与本机间也需要进行
linux$:] ssh-copy-id -i ~/.ssh/id_rsa.pub root@IP
7、hadoop
官网地址:https://hadoop.apache.org/
【Getting started】=>【Download】=>【Apache Download Mirrors】=>【HTTP】
linux$:] cd /soft
linux$:] wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
linux$:] tar -zxvf hadoop-3.3.1.tar.gz
linux$:] mv hadoop-3.3.1 hadoop
8、Linux环境变量配置
linux$:] vi /etc/hosts
IP地址 Master
IP地址 Secondary
IP地址 Datanodelinux$:] vi /etc/profile
export JAVA_HOME=/usr/bin/jdk
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib
export HADOOP_HOME=/soft/hadoop #配置Hadoop安装路径
export PATH=$HADOOP_HOME/bin:$PATH #配置Hadoop的hdfs命令路径
export PATH=$HADOOP_HOME/sbin:$PATH #配置Hadoop的命令路径
export HIVE_HOME=/soft/hive
export PATH=$PATH:$HIVE_HOME/bin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=rootlinux$:] source /etc/profile
9、hadoop的各类文件配置
配置文件信息
linux$:] vi /soft/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/bin/jdk配置文件信息【可一条命令启动以下全部机器start-all.sh/stop-all.sh】
linux$:] vi /soft/hadoop/etc/hadoop/workers
Master
Secondary
Datanode配置文件信息
linux$:] vi /soft/hadoop/etc/hadoop/core-site.xml
<configuration>
<!-- hdfs访问地址 --><property><name>fs.defaultFS</name><value>hdfs://Master:9000</value></property>
<!-- hadoop运行时临时文件存储路径 --><property><name>hadoop.tmp.dir</name><value>/hadoop/tmp</value></property>
<!-- hadoop验证 --><property><name>hadoop.security.authorization</name><value>false</value></property>
<!-- hadoop代理用户,主机用户是root,可自定义 --><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property>
<!-- hadoop代理用户组,主机用户组是root,可自定义 --><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>
</configuration>配置文件信息
linux$:] vi /soft/hadoop/etc/hadoop/hdfs-site.xml<configuration>
<!-- namenode Linux本地信息存储路径 --><property><name>dfs.namenode.name.dir</name><value>/hadoop/namenodedata</value></property>
<!-- 定义块大小 --><property><name>dfs.blocksize</name><value>256M</value></property>
<!-- namenode能处理的来之datanode 节点的Threads --><property><name>dfs.namenode.handler.count</name><value>100</value></property>
<!-- datanode Linux 本地存储路径 --><property><name>dfs.datanode.data.dir</name><value>/hadoop/datanodedata</value></property><property><name>dfs.replication</name><value>3</value></property>
<!-- hdfs启动时,不启动的机器 --><property><name>dfs.hosts.exclude</name><value>/soft/hadoop/etc/hadoop/workers.exclude</value></property>
<!-- 指定Secondary服务器,不指定则默认有NodeName同一主机 --><property><name>dfs.secondary.http.address</name><value>econdary:50070</value></property>
<!-- hdfs权限验证 --><property><name>dfs.permissions</name><value>false</value></property>
</configuration>配置文件信息
linux$:] vi /soft/hadoop/etc/hadoop/mapred-site.xml<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.map.memory.mb</name><value>125</value></property><property><name>mapreduce.map.java.opts</name><value>-Xmx512M</value></property><property><name>mapreduce.reduce.memory.mb</name><value>512</value></property><property><name>mapreduce.reduce.java.opts</name><value>-Xmx512M</value></property><property><name>mapreduce.task.io.sort.mb</name><value>125</value></property><property><name>mapreduce.task.io.sort.factor</name><value>100</value></property><property><name>mapreduce.reduce.shuffle.parallelcopies</name><value>50</value></property><property><name>mapreduce.jobhistory.address</name><value>Master:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>Master:19888</value></property><property><name>mapreduce.jobhistory.intermediate-done-dir</name><value>/hadoop/hislog</value></property><property><name>mapreduce.jobhistory.done-dir</name><value>/hadoop/hisloging</value></property>配置文件信息
linux$:] vi /soft/hadoop/etc/hadoop/yarn-site.xml<configuration><property><name>yarn.acl.enable</name><value>false</value></property><property><name>yarn.admin.acl</name><value>*</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.resourcemanager.address</name><value>Master:8032</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>Master:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>Master:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value>Master:8033</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>Master:8088</value></property><property><name>yarn.resourcemanager.hostname</name><value>Master</value></property><property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value></property><property><name>yarn.scheduler.minimum-allocation-mb</name><value>4</value></property><property><name>yarn.scheduler.maxmum-allocation-mb</name><value>125</value></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>2048</value></property><property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>2.1</value></property><property><name>yarn.nodemanager.local-dirs</name><value>/hadoop/temppackage</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value></property><property><name>yarn.log-aggregation.retain-seconds</name><value>-1</value></property><property><name>yarn.log-aggregation.retian-check-interval-seconds</name><value> -1 </value></property><property><name>yarn.resourcemanage.node.exclude-path</name><value>/soft/hadoop/etc/hadoop/workers.exclude</value></property>
</configuration>
二、启动hadoop集群
$HADOOP_HOME/bin/hdfs namenode -format
start-all.sh
$HADOOP_HOME/bin/yarn --daemon start proxyserver
$HADOOP_HOME/bin/mapred --daemon start historyserver
四、webapp访问
hdfs
http://Master:9870/
yarn_node
http://Master:8088/
三、Hive的安装
1、Mysql的安装
linux$:] touch /etc/yum.repos.d/mysql.repo
linux$:] cat >/etc/yum.repos.d/mysql.repo <<EOF
[mysql57-community]
name=MySQL 5.7 Community Server
baseurl=https://mirrors.cloud.tencent.com/mysql/yum/mysql-5.7-community-el7-x86_64/
enabled=1
gpgcheck=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql
EOF
linux$:] yum clean all
linux$:] yum makecache
linux$:] yum -y install mysql-community-server
linux$:] systemctl start mysqld
linux$:] systemctl enable mysqld
linux$:] grep "temporary password is generated" /var/log/mysqld.log
linux$:] mysql -uroot -p
Mysql 5.7.6以后的版本用下面的命令进行账号密码初始化SQL>ALTER USER USER() IDENTIFIED BY 'Twcx@2023';SQL>FLUSH PRIVILEGES;
linux$:] systemctl restart mysqld
linux$:] ystemctl enable mysqld
2、Hive安装
linux$:] cd /soft
linux$:] wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
linux$:] tar -zxvf apache-hive-3.1.3-bin.tar.gz
linux$:] mv apache-hive-3.1.3-bin hive
linux$:] cd /soft/hive/conf
linux$:] mv hive-env.sh.template hive-env.sh
linux$:] echo '' > hive-env.sh
linux$:] mv hive-default.xml.template hive-site.xml
linux$:] echo '' > hive-site.xml解决hadoop与hive包之间jar冲突的问题
linux$:] cd /soft/hive/lib
linux$:] rm -rf guava-19.0.jar
linux$:] cp /soft/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar ./解决Mysql 关联,依赖包
mysql驱动下载地址
https://dev.mysql.com/downloads/connector/j/
mysql 8.0驱动下载地址
linux$:] wget https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-java-8.0.11.tar.gz
linux$:] tar -zxvf mysql-connector-java-8.0.11.tar.gz
linux$:] cd mysql-connector-java-8.0.11
linux$:] cp mysql-connector-java-8.0.11.jar /soft/hive/lib/mysql 5.7驱动下载地址[当前用的此驱动]
linux$:] wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/6.0.6/mysql-connector-java-6.0.6.jar
linux$:] cp mysql-connector-java-6.0.6.jar /soft/hive/lib/
3、Hive配置
配置文件
linux$:] vi /soft/hive/conf/hive-env.sh
export HADOOP_HOME=/soft/hadoop
export HIVE_CONF_DIR=/soft/hive/conf
export HIVE_AUX_JARS_PATH=/soft/hive/lib配置日志文件,可以更改级别为DEBUG,用于调试
linux$:] vi /soft/hive/conf/hive-log4j2.properties
linux$:] cp hive-log4j2.properties.template hive-log4j2.properties
linux$:] vi hive-log4j2.properties
property.hive.log.dir = /user/hive/log配置文件:
注意:配置mysql访问的时候,就算是指定了字符集,mysql初始化时的字符集依然为latin
linux$:] vi /soft/hive/conf/hive-site.xml<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://Master:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>pyroot</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>Twcx@2023</value></property><property><name>hive.metastore.uris</name><value>thrift://Master:9083</value></property><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property><property><name>hive.metastore.schema.verification</name><value>false</value></property><property><name>hive.server2.thrift.bind.host</name><value>Master</value></property><property><name>hive.server2.thrift.port</name><value>10000</value></property><property><name>hive.cli.print.header</name><value>true</value></property><property><name>hive.cli.print.current.db</name><value>true</value></property><property><name>beeline.hs2.connection.user</name><value>root</value></property><property><name>beeline.hs2.connection.password</name><value>root</value></property>
</configuration>
4、启动Hive
说明:
命令行客户端:
bin/hive 不推荐使用,是shell客户端
bin/beeline
强烈推荐使用,是jdbc的客户端,可以在嵌入式与远程客户端使用,且访问的hiveServer2,通过hiveServer2访问metastore,再Hive mysql数据。
HiveServer2支持多客户端的并发和身份证认证,旨在为开发API客户端如JDBC,ODBC提供更好的支持
重启hdfs
linux$:] stop-all.sh
linux$:] start-all.sh初始化hive元数据信息到mysql中
linux$:] schematool -dbType mysql -initSchema #初始化schema检查mysql是否存在hive库,hive库的74张表
linux$:] mysql -uroot -pSQL> show databases;SQL> use hiveSQL> show tables;启动metastore
linux$:] mkdir -p /soft/hive/metastorelog
linux$:] cd /soft/hive/metastorelog
linux$:] nohup hive --service metastore --hiveconf hive.root.logger=DEBUG,console &启动hiveserver2
linux$:] mkdir -p /soft/hive/hiveserver2log
linux$:] cd /soft/hive/hiveserver2log
linux$:] nohup $HIVE_HOME/bin/hive --service hiveserver2 &
5、远程测试metastore与hiveserver2【可在Datanode主机上搭建客户端】
安装Hive软件
linux$:] cd /soft
linux$:] wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
linux$:] tar -zxvf apache-hive-3.1.3-bin.tar.gz
linux$:] mv apache-hive-3.1.3-bin hive解决hadoop与hive包之间jar冲突的问题
linux$:] cd /soft/hive/lib
linux$:] rm -rf guava-19.0.jar
linux$:] cp /soft/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar ./驱动部署,远程可不需要
linux$:] wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/6.0.6/mysql-connector-java-6.0.6.jar
linux$:] cp mysql-connector-java-6.0.6.jar /soft/hive/lib/配置Hive文件
配置文件
linux$:] vi /soft/hive/conf/hive-env.sh
export HADOOP_HOME=/soft/hadoop
export HIVE_CONF_DIR=/soft/hive/conf
export HIVE_AUX_JARS_PATH=/soft/hive/lib配置文件
linux$:] vi /soft/hive/conf/hive-site.xml
<configuration><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property><property><name>hive.metastore.uris</name><value>thrift://Master:9083</value></property>
</configuration>测试metastore,不加主机与IP,默认是访问的metastore的暴露端口 9083
linux$:] beeline -u jdbc:hive2://
> show databases;测试hiveserver2,端口10000,是访问的是hiverserver2的暴露端口
linux$:] beeline -u jdbc:hive2://Master:10000
> show databases;其它测试:
win 环境,下载DBeaver,通过10000号进行访问链接。账号默认为hive,密码为空或者填入hive。
6、webapp的访问
http://Master:10002/
相关文章:

Hadoop集成Hive
一、环境与软件准备 说明:服务器已用主机名代替,可根据自己的需求,改为IP地址 环境 服务器组件masterNameNode、DataNode、Nodemanager、ResourceManager、Hive、Hive的metastore、Hive的hiveserver2、mysqlSecondarySecondaryNameNode、D…...
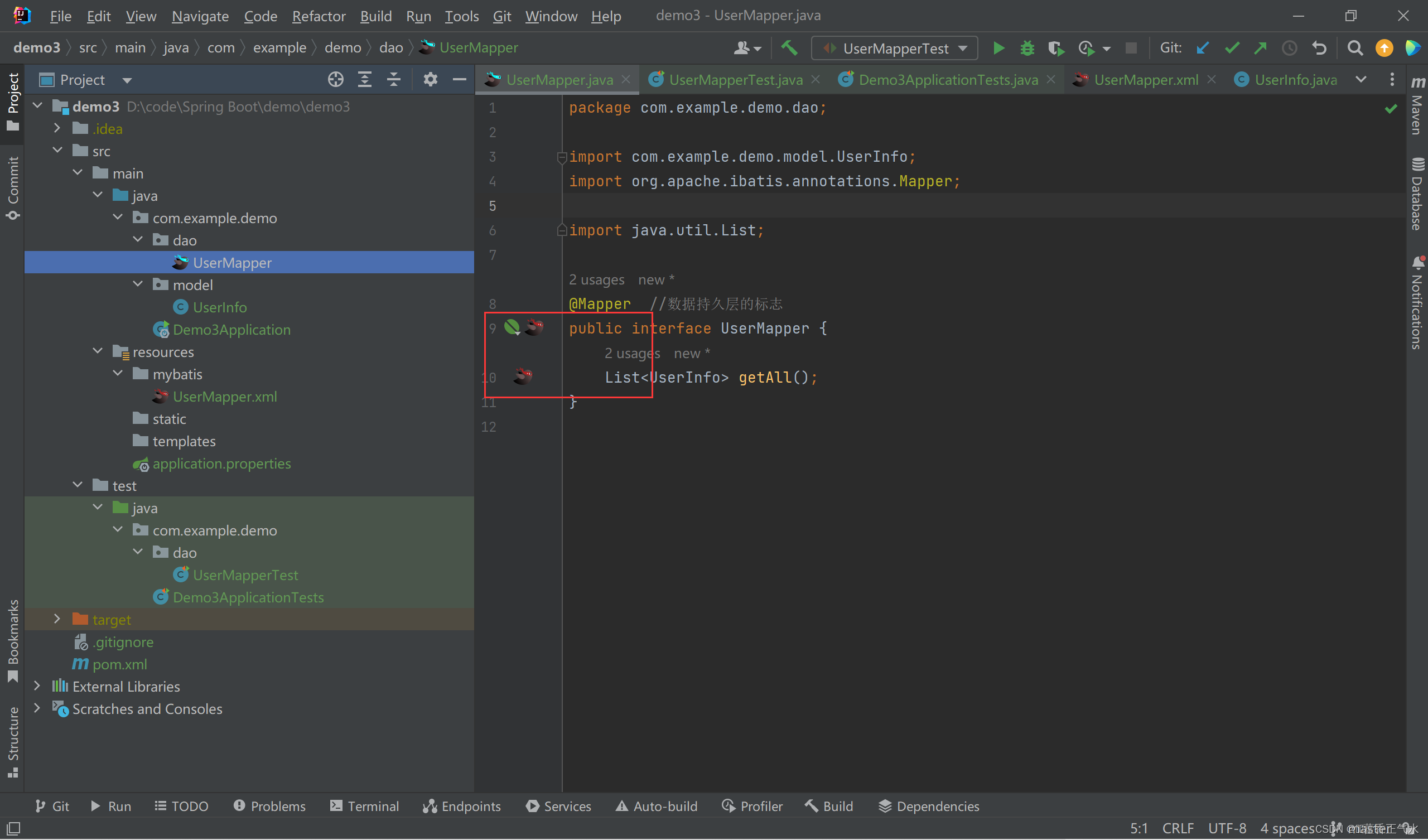
MyBatis查询数据库
目录 一、什么是MyBatis 二、搭建MyBatis开发环境 🍅添加MyBatis依赖 🍅在数据库添加数据 🍅设置MyBatis配置 🎈数据库的相关连接信息🎈xml的保存和设置路径 三、使用MyBatis模式和语法操作数据库 ἴ…...

RVM问题记录 - Error running ‘__rvm_make -j10‘
文章目录 前言开发环境问题描述问题分析解决方案最后 前言 公司新到一台电脑需要配置开发环境,在用RVM安装Ruby时遇到了一个奇怪的问题。 开发环境 RVM: 1.29.12OpenSSL: 3.1.1 问题描述 执行命令安装Ruby 3.0版本: rvm install ruby-3.0.0在编译阶…...
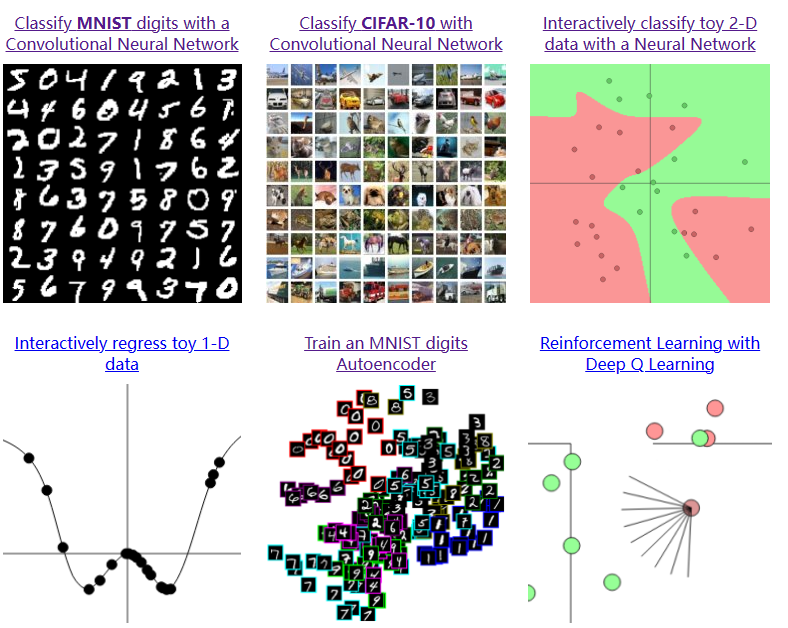
VIS for AI :ConvNetJS
1.简单介绍: ConvNetJS是由斯坦福大学计算机科学系的Andrej Karpathy开发的一个深度学习框架,用于在浏览器中运行卷积神经网络(ConvNet)。ConvNetJS可以帮助开发人员在客户端(浏览器)上进行深度学习任务&a…...

【Python入门系列】第二十篇:Python区块链和加密货币
文章目录 前言一、区块链基础知识1.1 什么是区块链1.2 区块链的工作原理 1.3 区块链的优势和应用场景二、Python实现区块链2.1 创建区块类2.2 创建区块链类2.3 添加区块和验证区块链 三、加密货币基础知识3.1 什么是加密货币3.2 加密货币的工作原理3.3 加密货币的挖矿和交易 四…...

MySQL 服务器的调优策略
点击上方↑“追梦 Java”关注,一起追梦! 在工作中,我们发现慢查询一般有2个途径,一个是被动的,一个是主动的。被动的是当业务人员反馈某个查询界面响应的时间特别长,你才去处理。主动的是通过通过分析慢查询…...
)
Educational Codeforces Round 152 (Rated for Div. 2)
B这个题目在20分钟的时候发现了取模的规律,但是在写法上我竟然犹豫了,这影响了我后面题目的心态 过于可惜了 但是没关系,现在不会,之后就会写了 这里强调一下,sort不会改变原先的顺序,就是说如果两个相等的…...

CSPM难度大吗?对比pmp怎么样?
CSPM证书是刚出来的,难度不会很大,大家都知道 PMP 证书是从国外引进的,近几年很热门,持证人数已经高达 90 余万了,但是目前我们和老美关系大家有目共睹,一直推国际标准和美国标准感觉有点奇怪。 现在新出台…...

Android.mk中的LOCAL_OVERRIDES_PACKAGES用法
Android.mk中的LOCAL_OVERRIDES_PACKAGES用法_mk local_over_觅风者的博客-CSDN博客 Android.mk中的LOCAL_OVERRIDES_PACKAGES的用法说明可以参考以下文章: Android.mk覆盖替换LOCAL_OVERRIDES_PACKAGES 此变量可以使其他的模块不加入编译 项目中遇到的问题&…...

Matlab遍历文件及直方图统计
参考链接: 使用MATLAB遍历文件 strtrim用法 strsplit用法 cell单元数据使用{} close all; dir_path C:/Users/; fileFolder ls(dir_path); fileNum length(fileFolder(:,1)) - 2; for i 3:(3fileNum-1)file_path strcat(dir_path, strtrim(fileFolder(i,:)))…...

为什么要格式化硬盘?硬盘格式化了数据怎么恢复
在计算机维护和数据管理中,格式化硬盘是一个常见的操作。本文将探讨为什么需要对硬盘进行格式化以及当数据丢失时如何恢复。 ▌格式化硬盘是什么意思: 硬盘格式化是对磁盘或其分区进行初始化的一种操作,它会清除磁盘或分区中的所有文件。因此…...

PHP注册、登陆、6套主页-带Thinkphp目录解析-【白嫖项目】
强撸项目系列总目录在000集 PHP要怎么学–【思维导图知识范围】 文章目录 本系列校训本项目使用技术 上效果图主页注册,登陆 phpStudy 设置导数据库项目目录如图:代码部分:控制器前台的首页 其它配套页面展示直接给第二套方案的页面吧第三套…...

antDesignMobile中Switch配合Form使用无效解决方案
介绍 Form和Switch合起来使用无效的原因就是因为Form.Item给Switch的是value值,而Switch中监听的是checked;所以说我们只需要做一层二次封装即可。非常简单~如下本文以antd-mobile举例,其他antd框架解决方案一致!!&am…...

记录springboot在k8s下无法读取文件问题
//加载配置文件 File file ResourceUtils.getFile("classpath:/template/job.yaml"); /对象映射 V1Job v1Job (V1Job) Yaml.load(file); 开发的时候使用上面的方法可以读取文件数据,但是部署到k8s容器中之后,读取文件出现报错,…...

数据湖如何为企业带来9%的高增长?可否取代数据仓库?
什么是数据湖? 数据湖是一个集中的存储库,允许您以任何规模存储所有结构化和非结构化数据。您可以按原样存储数据,而不必首先构造数据,并运行不同类型的分析—从仪表板和可视化到大数据处理、实时分析和机器学习,以指…...

P2669 [NOIP2015 普及组] 金币
题目背景 NOIP2015 普及组 T1 题目描述 国王将金币作为工资,发放给忠诚的骑士。第一天,骑士收到一枚金币;之后两天(第二天和第三天),每天收到两枚金币;之后三天(第四、五、六天&a…...

【2023】华为OD机试真题Java CC++ Python JS Go-题目0250-选修课
题目0250-选修课 题目描述 现有两门选修课,每门选修课都有一部分学生选修,每个学生都有选修课的成绩,需要你找出同时选修了两门选修课的学生,先按照班级进行划分,班级编号小的先输出,每个班级按照两门选修课成绩和的降序排序,成绩相同时按照学生的学号升序排序。 输入…...
lama cleaner
这里写自定义目录标题 安装参数包含的额外plugins 代码结构FreehandBackground RemovalInteractiveSeg 安装 conda create --name lamacleaner python3.10 pip install -r requirements.txt pip install gfpgan pip install realesrgan pip install rembg pip install .如果…...
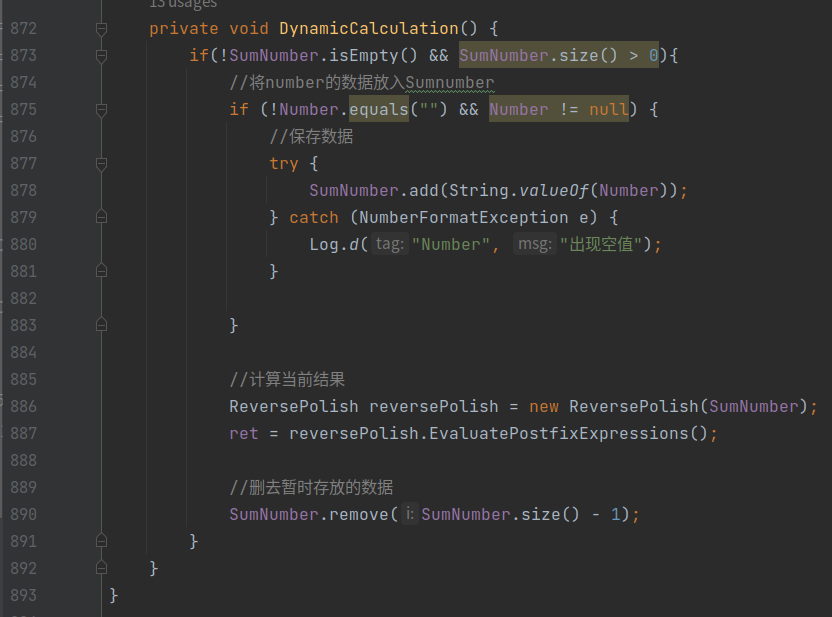
制作一个简易的计算器app
github项目地址:https://github.com/13008451162/AndroidMoblieCalculator 1、Ui开发 笔者的Ui制作的制作的比较麻烦仅供参考,在这里使用了多个LinearLayout对屏幕进行了划分。不建议大家这样做最好使用GridLayout会更加快捷简单 笔者大致划分是这样的…...
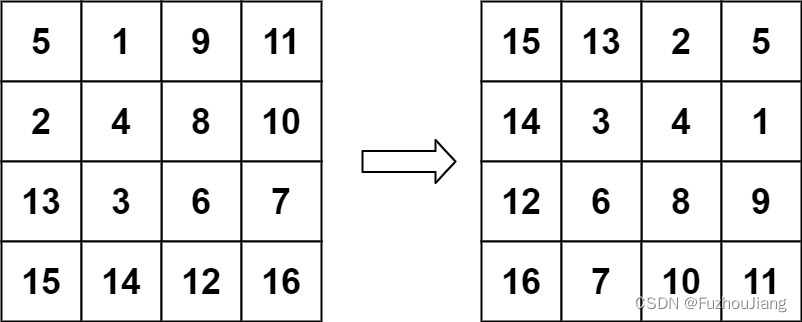
48. 旋转图像
题目介绍 给定一个 n n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在** 原地** 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。 示例 1: 输入:matrix [[1,2,3],[4,5,6]…...

身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南
#身份证OCR, #OCR接口, #API接入, #Python示例, #Java示例, #PHP示例, #踩坑指南, #石榴智能, #实名认证, #图片识别 身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南 作者:石榴智能技术团队 一、前言 身份证OCR识别已经不是什…...

AI智能体到底强在哪?为什么大家开始从“养龙虾”转向“养马”
那么AI智能体的核心能力是什么? 1、理解需求 它能分析你的真实意图,而不是只看表面的文字,比如让它整理这个月的消费情况,它明白之后,会读取账单,做分类统计,生成总结,最后输出图表。…...

为什么鸿蒙 App 最终都会走向状态驱动?
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...

终极指南:5步快速掌握免费的3D点云标注工具labelCloud
终极指南:5步快速掌握免费的3D点云标注工具labelCloud 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 想要为自动驾驶、机器人视觉或3D目标检测…...

CUDA并行计算与FSR框架优化实践
1. CUDA并行计算与FSR框架概述在GPU加速计算领域,CUDA(Compute Unified Device Architecture)作为NVIDIA推出的并行计算平台和编程模型,已经成为高性能计算的事实标准。其核心设计理念是将计算任务分解为网格(Grid&…...

如何快速掌握Avidemux:新手完整入门指南与5个核心技巧
如何快速掌握Avidemux:新手完整入门指南与5个核心技巧 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 Avidemux是一款功能强大且完全开源的专业视频编辑工具,专为快速剪辑、…...

微信小程序项目实战:从npm安装Vant Weapp到解决样式冲突的完整避坑指南
微信小程序工程化实战:Vant Weapp集成与样式冲突解决方案全解析 第一次在小程序里引入Vant Weapp时,我对着满屏错位的组件样式发呆了半小时——原本优雅的按钮变成了扭曲的色块,表单元素叠在一起像抽象画。这不是个例,根据社区反…...

基于TESS光变曲线与深度学习的O型星物理参数预测研究
1. 项目概述与核心挑战在恒星天体物理研究中,大质量O型星扮演着至关重要的角色。它们不仅是宇宙中光度最高的天体之一,其强烈的辐射、恒星风和最终的超新星爆发,更是驱动星系化学演化和能量注入星际介质的关键引擎。然而,深入理解…...

SpeakingURL版本升级指南:从旧版本迁移到最新版本的完整教程
SpeakingURL版本升级指南:从旧版本迁移到最新版本的完整教程 【免费下载链接】speakingurl Generate a slug – transliteration with a lot of options 项目地址: https://gitcode.com/gh_mirrors/sp/speakingurl SpeakingURL是一款强大的URL友好化工具&…...

WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求?
WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求? 【免费下载链接】WMPFDebugger Yet another WeChat miniapp debugger on Windows 项目地址: https://gitcode.com/gh_mirrors/wm/WMPFDebugger 在Windows平台的微信小程序开发中&#…...