Kafka在大数据处理中的应用
Kafka在大数据处理中的应用
- 一、Kafka简介
- 1. 基础概念
- 2. Kafka的主要功能
- 3. Kafka的特点
- 二、应用场景
- 1. 数据采集和消费
- 2. 数据存储和持久化
- 3. 实时数据处理和流计算
- 4. 数据通信和协同
- 三、技术融合
- 1. Kafka与Hadoop生态技术的融合
- 1) 使用Kafka作为Hadoop的数据源
- 2) 使用Hadoop作为Kafka的消费者
- 2. Kafka与Spark、Flink等流处理框架的融合
- 3. Kafka与Elasticsearch等日志搜索引擎的融合
- 四、性能优化
- 1. Kafka性能调优主要过程
- 2. 生产者性能调优
- 2.1 批量发送消息
- 2.2 压缩消息
- 2.3 异步发送消息
- 3. 消费者性能调优
- 3.1 提高分区数和消费者数
- 3.2 提高拉取数据大小
- 3.3 提高拉取数据间隔
- 4. 集群性能调优
- 4.1 提高恢复速度
- 4.2 分配分区均衡
- 五、存储管理
- 1. 消息压缩配置
- 2. 存储清理策略
- 3. 消息存储和检索原理
- 六、Kafka安全性
- 1. 认证、授权和加密
- 2. SSL/TLS加密保证数据传输安全
- 3. ACL机制实现细粒度授权管理
- 七、Kafka管理工具
- 1. ZooKeeper集群管理工具
- 1.1 ZooKeeper简介
- 1.2 ZooKeeper与Kafka
- 2. Kafka自带的管理工具
- 2.1 Kafka Manager
- 2.2 Kafka Connect
- 3. 第三方Kafka监控工具
- 3.1 Burrow
- 3.2 Kafka Web Console
一、Kafka简介
1. 基础概念
Kafka是一种高可用的分布式消息系统,主要负责支持在不同应用程序之间进行可靠且持续的消息传输。这一过程中,消息数据的分摊、均衡和存储都是由Kafka负责完成的。
2. Kafka的主要功能
Kafka的主要功能包括消息的生产和消费。在消息生产方面,Kafka支持将消息发送到多个接收端,实现了应用程序之间的高效传输;在消息消费方面,Kafka可以对消费进度进行控制,确保每个消费者都能够按照其预期的方式接收到消息。
3. Kafka的特点
Kafka具有如下几个特点:
- 高可用:支持分区和副本机制,可以保障高可用性。
- 高伸缩性:支持水平扩展,可支持PB级别的数据处理。
- 持久性:消息被持久化到磁盘上,并且在一定时间内不会失效。
- 高性能:Kafka的IO实现采用了顺序读写的方式,有很高的读写速度,能够满足高吞吐量的需求。
- 多语言支持:Kafka提供了诸如Java、C++、Python等多种语言的API,适用于各种不同的开发场景。
二、应用场景
1. 数据采集和消费
Kafka作为一种高效的消息传输机制,在数据采集过程中有着广泛的应用。数据生产者可以将原始的数据发送到Kafka中,各种数据消费者再通过Kafka进行消费,从而构建起一个完整的数据采集和传输系统。
下面展示如何对Kafka进行生产和消费操作:
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.clients.consumer.*;public class KafkaDemo {public static void main(String[] args) throws Exception {// 生产者Properties producerProps = new Properties();producerProps.put("bootstrap.servers", "localhost:9092");producerProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");producerProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(producerProps);producer.send(new ProducerRecord<>("test_topic", "key", "value"));// 消费者Properties consumerProps = new Properties();consumerProps.put("bootstrap.servers", "localhost:9092");consumerProps.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");consumerProps.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");Consumer<String, String> consumer = new KafkaConsumer<>(consumerProps);consumer.subscribe(Arrays.asList("test_topic"));while (true) {ConsumerRecords<String, String> records = consumer.poll(100);for (ConsumerRecord<String, String> record : records) {System.out.println(record.key() + ":" + record.value());}}}
}
2. 数据存储和持久化
Kafka还可以作为一种高效的数据存储和持久化机制。利用Kafka提供的持久化机制,可以将不同类型的数据以日志形式存储到Kafka Broker中,并在需要的时候进行查找、检索。
3. 实时数据处理和流计算
Kafka通过支持流数据架构(Streaming Data Architecture)来进行实时数据处理和流计算。用户可以使用Kafka Streams API来实现实时应用程序,同时Kafka也支持一些流式处理框架(如Storm和Flink)的集成。
4. 数据通信和协同
Kafka作为一种强大的消息队列系统,可以支持不同分布式组件之间的数据通信和协同。例如,用户可以使用Kafka将数据发送到各个端点,从而实现不同组件之间的互动。
三、技术融合
1. Kafka与Hadoop生态技术的融合
Kafka作为一个高吞吐量的分布式发布-订阅消息系统,可以很好地与Hadoop生态技术融合。常用的两种方式为:
1) 使用Kafka作为Hadoop的数据源
我们可以将Kafka作为Hadoop的数据源,用于数据采集、数据传输等场景:
import org.apache.spark.streaming.kafka.KafkaUtils;
import org.apache.spark.streaming.kafka.*;
import kafka.serializer.StringDecoder;public class KafkaStreamingApp {public static void main(String[] args) throws Exception {String brokers = "localhost:9092";String topics = "testTopic";SparkConf conf = new SparkConf().setAppName("KafkaStreamingApp").setMaster("local[2]");JavaStreamingContext context = new JavaStreamingContext(conf, Durations.seconds(10));Map<String, String> kafkaParams = new HashMap<>();kafkaParams.put("metadata.broker.list", brokers);Set<String> topicsSet = new HashSet<>(Arrays.asList(topics.split(",")));JavaPairInputDStream<String, String> stream = KafkaUtils.createDirectStream(context,String.class,String.class,StringDecoder.class,StringDecoder.class,kafkaParams,topicsSet);stream.print();context.start();context.awaitTermination();}
}
2) 使用Hadoop作为Kafka的消费者
在Hadoop中使用Kafka作为数据源后,我们还可以将Hadoop中的数据通过Kafka发送给其他消费者:
import org.apache.kafka.clients.producer.*;
import java.util.Properties;public class KafkaProducerExample {public static void main(String[] args) throws Exception{String topicName = "testTopic";String key = "Key1";String value= "Value-99";Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(props);ProducerRecord<String, String> record = new ProducerRecord<>(topicName,key,value);producer.send(record);producer.close();System.out.println("A message has been successfully sent!");}
}
2. Kafka与Spark、Flink等流处理框架的融合
Kafka可以很好地与流处理框架如Spark、Flink等进行融合。在这些流处理框架中,Kafka被广泛用于数据输入源和输出源,并且具有高效率和稳定性。下面以Spark Streaming为例:
import org.apache.spark.streaming.api.java.*;
import org.apache.spark.streaming.kafka.*;
import kafka.serializer.DefaultDecoder;
import scala.Tuple2;import java.util.*;public class KafkaStreamingApp {public static void main(String[] args) throws InterruptedException {String brokers = "localhost:9092";//设置Kafka连接信息 String topics = "testTopic";//设置订阅的主题名称 SparkConf conf = new SparkConf().setAppName("KafkaStreamingApp").setMaster("local[2]");//设置Spark配置信息 JavaStreamingContext jssc = new JavaStreamingContext(conf, new Duration(2000));//设置数据流间隔时间 Map<String, String> kafkaParams = new HashMap<String, String>();kafkaParams.put("metadata.broker.list", brokers);//设置连接的Kafka Broker地址列表Set<String> topicsSet = new HashSet<String>(Arrays.asList(topics.split(",")));//设置订阅主题集合 JavaPairInputDStream<byte[], byte[]> messages = KafkaUtils.createDirectStream(jssc,byte[].class,byte[].class,DefaultDecoder.class,DefaultDecoder.class,kafkaParams,topicsSet);//创建输入数据流 JavaDStream<String> lines = messages.map(new Function<Tuple2<byte[], byte[]>, String>() {public String call(Tuple2<byte[], byte[]> tuple2) {//将元组转化为字符串 return new String(tuple2._2());}});lines.print();//打印数据流中的数据 jssc.start();//开始运行Spark Streaming应用程序 jssc.awaitTermination();//等待应用程序终止}
}
3. Kafka与Elasticsearch等日志搜索引擎的融合
Kafka可以很好地与日志搜索引擎如Elasticsearch进行融合,用于实时处理和搜索。在使用过程中,我们需要使用Kafka Connect来连接Kafka和Elasticsearch,并对数据进行批量处理和导入,具体代码如下:
import org.apache.kafka.connect.data.Schema;
import org.apache.kafka.connect.data.SchemaBuilder;
import org.apache.kafka.connect.json.JsonConverter;
import org.apache.kafka.connect.runtime.standalone.StandaloneConfig;
import org.apache.kafka.connect.sink.SinkConnector;
import org.apache.kafka.connect.sink.SinkRecord;
import org.apache.kafka.connect.sink.SinkTask;import java.util.*;public class ElasticsearchSinkExample implements SinkConnector {private Map<String, String> configProps;public void start(Map<String, String> props) {this.configProps = props;}public Class<? extends Task> taskClass() {return ElasticsearchSinkTask.class;}public List<Map<String, String>> taskConfigs(int i) {List<Map<String, String>> configs = new ArrayList<>(i);for (int x = 0; x < i; x++) {configs.add(configProps);}return configs;}public void stop() {}public ConfigDef config() {return new ConfigDef();}public String version() {return "1";}public static class ElasticsearchSinkTask extends SinkTask {private String hostname;private int port;private String indexPrefix;public String version() {return "1";}public void start(Map<String, String> props) {hostname = props.get("address");port = Integer.parseInt(props.get("port"));indexPrefix = props.get("index");// Connect to Elasticsearch and create index if not exists//...}public void put(Collection<SinkRecord> records) {// Convert records to JSONSchema schema = SchemaBuilder.struct().name("record").version(1).field("id", Schema.STRING_SCHEMA).field("name", Schema.STRING_SCHEMA).field("age", Schema.INT32_SCHEMA).build()JsonConverter converter = new JsonConverter();converter.configure(new HashMap<>(), false);List<Map<String, String>> convertedRecords = new ArrayList<>(records.size());for (SinkRecord record: records) {String json = converter.fromConnectData("topic", schema, record.value())Map<String, String> convertedRecord = new HashMap<>();convertedRecord.put("id", record.key().toString());convertedRecord.put("json", json);convertedRecords.add(convertedRecord);}// Write records to Elasticsearch//...}public void flush(Map<TopicPartition, OffsetAndMetadata> offsets) {}public void stop() {}}
}
四、性能优化
Kafka在高并发、大流量场景下,需要进行性能优化才能保障其稳定性和可靠性。本文将讨论Kafka的性能调优过程,包括生产者、消费者、以及集群中的性能参数调整。
1. Kafka性能调优主要过程
Kafka性能调优主要分为以下两个过程:
- 确定当前瓶颈:在进行任何性能调优之前,首先需要明确当前的瓶颈是什么。比如,是由于网络传输速度慢导致的吞吐量下降,还是由于消息生产和消费速度不匹配造成的堆积情况。
- 调整性能参数:当明确了当前的瓶颈之后,就需要根据具体情况进行性能参数调整,在优化瓶颈的同时提高Kafka的性能。
2. 生产者性能调优
2.1 批量发送消息
生产者在向Kafka发送消息时,可以一次性发送多条消息,而不是一条一条地发送。这样可以减少网络传输和IO的开销,从而提高吞吐量。我们可以通过设置batch.size参数来控制批量发送的消息数量。
2.2 压缩消息
压缩消息也能大幅降低网络传输的开销,从而提高吞吐量。Kafka支持多种压缩算法,如gzip、snappy和lz4等。我们可以通过设置compression.type参数来控制要使用哪种压缩算法。
2.3 异步发送消息
在生产者发送消息时,可以选择同步方式和异步方式,同步方式会阻塞线程直到消息发送成功,而异步方式则不会。异步方式可以极大地提高吞吐量,但是会增加消息传递时失败的风险。我们可以通过设置linger.ms参数来调整异步发送消息的时间间隔。
3. 消费者性能调优
3.1 提高分区数和消费者数
在Kafka的消费者群组中,每个消费者实例只能处理某些分区的消息,如果某个分区数量过多,可能会影响消费者的效率。我们可以通过增加分区数和消费者数来提高消费者的效率。
3.2 提高拉取数据大小
在消费者获取数据的过程中,每次拉取的数据大小也会对性能产生影响,一般情况下,拉取的数据越多,消费者的吞吐量就越高。我们可以通过设置 fetch.max.bytes 参数来增大每次拉取数据的大小。
3.3 提高拉取数据间隔
在消费者获取数据的过程中,每个消费者拉取数据的间隔也是可以调整的。我们可以通过设置 fetch.max.wait.ms 参数来调整拉取数据的时间间隔。
4. 集群性能调优
4.1 提高恢复速度
Kafka的集群由多个Broker组成,在其中一个Broker宕机时,Kafka需要进行数据的恢复工作。为了提高恢复速度,我们可以采用同步副本的方式,使得副本和主节点之间的数据一致性更加保障,在主节点宕机时能够快速切换到副本节点上。
4.2 分配分区均衡
在Kafka的集群中,存在多个Broker和多个Topic,为了保证各个Broker上的分区数相对均衡,我们可以使用Kafka的工具包来处理分区的分配问题,确保每个Broker负载均衡。
五、存储管理
1. 消息压缩配置
在 Kafka 中可以对消息进行压缩以节省磁盘空间和网络带宽。Kafka 支持多种压缩算法,包括 GZIP、Snappy 和 LZ4。当 Kafka Broker 接收到写入的消息时,可以根据 Kafka Producer 的配置对消息进行压缩。当 Consumer 从 Kafka 中读取消息时,Kafka 会自动解压缩消息,并将其传递给 Consumer 进行处理。
以下是一个使用 Java API 配置消息压缩的示例:
Properties props = new Properties();
props.put("compression.type", "gzip"); // 设置压缩类型为 GZIP
Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());
2. 存储清理策略
Kafka 的消息是存储在 Broker 上的,如果消息不断写入而不进行删除,会导致磁盘空间占用越来越大。因此,Kafka 提供了几种存储清理策略来控制 Broker 上的消息存储量。
Kafka 支持两种存储清理策略:删除策略和压缩策略。删除策略会删除一些老的或过期的消息,从而释放磁盘空间;而压缩策略则会对数据进行压缩,进一步节省磁盘空间。
以下是一个使用 Java API 配置存储清理策略的示例:
Properties props = new Properties();
props.put("log.cleanup.policy", "delete"); // 设置清理策略为删除策略
props.put("log.retention.hours", "24"); // 设置留存的小时数为 24 小时
props.put("log.cleanup.policy", "compact"); // 设置清理策略为压缩策略
Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());
3. 消息存储和检索原理
Kafka 的消息存储和检索原理非常简单。在 Kafka 中,每个 Topic 都被分成多个 Partition。当 Producer 往某个 Topic 写入消息时,Kafka 会将消息存储到该 Topic 指定的一个或多个 Partition 上。每个 Partition 中的消息都按顺序进行存储,并且每个消息都有一个唯一的 offset。Consumer 可以从任意 offset 开始读取消息,这使得 Consumer 可以逐条处理消息、实现重复消费等功能。
Kafka 的消息存储方式为日志型存储。在 Kafka 中,每个 Partition 都维护了一个消息日志(Message Log),该日志是一个按时间排序的消息集合,所有的消息都以追加方式写入该日志中。由于消息的写入操作只涉及追加操作,而不涉及修改和删除操作,因此能够实现高效的数据写入和读取。
Kafka 通过 mmap 操作将消息日志映射到内存中,从而实现高效的消息读取。此外,Kafka 在数据组织上采用了时间序列索引的方式,可以快速地定位某个 offset 对应的消息。
六、Kafka安全性
Kafka提供了多种安全特性,包括认证、授权和加密。其中SSL/TLS加密用于保证数据传输的安全,ACL机制实现了细粒度的授权管理。
1. 认证、授权和加密
在Kafka中,认证、授权和加密是允许配置的。其中,认证和授权的实现主要依赖于Jaas(Java Authentication and Authorization Service)框架,而加密使用SSL/TLS协议。
认证可以使用Kafka内置的认证方式或者自定义的方式,例如使用LDAP或者Kerberos等。授权则是通过ACL(access control lists)机制实现的,用于限制用户对Kafka集群、topic、partition等资源的访问权限。
2. SSL/TLS加密保证数据传输安全
Kafka提供了SSL/TLS协议加密数据传输,在网络传输过程中保护数据的安全性。可以通过配置SSL证书、私钥等参数启用SSL/TLS功能。
下面是一个使用SSL/TLS传输数据的示例代码:
Properties props = new Properties();
props.setProperty("bootstrap.servers", "kafka1.example.com:9093");
props.setProperty("security.protocol", "SSL");
props.setProperty("ssl.truststore.location", "/path/to/truststore");
props.setProperty("ssl.truststore.password", "password");Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());producer.send(new ProducerRecord<>("my-topic", "my-message"));
在此示例代码中,我们设置了security.protocol为“SSL”,并指定了SSL证书所在的路径和密码。通过这些配置,我们可以使用SSL/TLS协议传输数据。
3. ACL机制实现细粒度授权管理
Kafka的ACL机制提供了细粒度的授权管理,可以限制用户对不同资源的访问权限。ACL机制是基于资源的,可以对Kafka集群、topic、partition等资源进行授权管理。
下面是一个使用ACL机制进行授权管理的示例代码:
Properties props = new Properties();
props.setProperty("bootstrap.servers", "kafka1.example.com:9092");AdminClient adminClient = KafkaAdminClient.create(props);ResourcePattern pattern = new ResourcePattern(ResourceType.TOPIC, "my-topic");
AccessControlEntry entry = new AccessControlEntry("User:alice", "*", AclOperation.READ, AclPermissionType.ALLOW);
KafkaPrincipal principal = new KafkaPrincipal(KafkaPrincipal.USER_TYPE, "alice");
Resource resource = new Resource(pattern.resourceType().name(), pattern.name());Set<AclBinding> acls = new HashSet<>();
acls.add(new AclBinding(resource, entry));adminClient.createAcls(acls);
在此示例代码中,我们创建了一个名为“my-topic”的topic,并为用户“alice”授予了对该topic的读取权限。使用ACL机制,我们可以实现对用户在Kafka集群中的操作进行细粒度的控制和管理。
七、Kafka管理工具
1. ZooKeeper集群管理工具
1.1 ZooKeeper简介
ZooKeeper是一个分布式的开放源代码的分布式应用程序协调服务,它是Google的Chubby一个开源的实现,是Hadoop和Kafka等分布式系统的重要组件之一。
1.2 ZooKeeper与Kafka
在Kafka中,ZooKeeper负责管理broker的状态信息,以及选举controller,管理Topic和Partition的元数据等。ZooKeeper对于Kafka的正常运行至关重要,一旦ZooKeeper出现异常或故障,会导致Kafka集群不可用。
2. Kafka自带的管理工具
2.1 Kafka Manager
Kafka Manager是由Yahoo开发的一个基于Web的Kafka管理工具,能够方便地查看和管理Kafka集群中的Topic、Broker、Partition等信息。用户可以使用Kafka Manager来监控Kafka集群的健康状况,并根据需要对其进行配置和管理。
2.2 Kafka Connect
Kafka Connect是Kafka提供的一个统一的数据传输框架,用于将Kafka与其他数据源或数据存储系统进行连接。用户可以通过Kafka Connect快速地从数据源或到数据存储系统中读取或写入数据,并将数据直接注入到Kafka中。
3. 第三方Kafka监控工具
3.1 Burrow
Burrow是由Linkedin开发的一个先进的Kafka Consumer监控工具,可以用于监控和管理Kafka Consumer Group的健康状况以及消息处理的进度状态等信息。Burrow能够提供非常详细的分区信息、已消费消息数量、剩余消息数量等数据信息。
3.2 Kafka Web Console
Kafka Web Console是一款免费、开源、基于Web的Kafka管理工具,可以方便地查看和管理Kafka集群的Topic、Broker、Partition等信息。用户可以通过Kafka Web Console随时了解集群的状态并进行相关配置和管理操作。
相关文章:

Kafka在大数据处理中的应用
Kafka在大数据处理中的应用 一、Kafka简介1. 基础概念2. Kafka的主要功能3. Kafka的特点 二、应用场景1. 数据采集和消费2. 数据存储和持久化3. 实时数据处理和流计算4. 数据通信和协同 三、技术融合1. Kafka与Hadoop生态技术的融合1) 使用Kafka作为Hadoop的数据源2) 使用Hadoo…...

Linux Day03
一、基础命令(在Linux Day02基础上补充) 1.10 find find 搜索路径 -name 文件名 按文件名字搜索 find 搜索路径 -cmin -n 搜索过去n分钟内修改的文件 find 搜索路径 -ctime -n搜索过去n分钟内修改的文件 1)按文件名字 2)按时间 1.11 grep 在文件中过…...
)
OpenCV 对轮廓进行多边形逼近(Polygon Approximation)
在 OpenCV 中,cv::approxPolyDP 是一个函数,用于对轮廓进行多边形逼近(Polygon Approximation)。它可以将复杂的轮廓逼近为简化的多边形,从而减少轮廓的数据点,使轮廓更加紧凑。 函数原型如下:…...
Docker的数据管理和Dockerfile的指令
Docker的数据管理 一、Docker数据的概念1、数据卷2、数据卷容器 二、端口映射三、容器互联(使用centos镜像)四、Docker 镜像的创建1、基于现有镜像创建(1)首先启动一个镜像,在容器里做修改(2)然…...

[SQL挖掘机] - 交叉连接: cross join
介绍: 交叉连接是一种多表连接方式,它返回两个表的笛卡尔积,即将一个表的每一行与另一个表的每一行进行组合。换句话说,交叉连接会生成一个包含所有可能组合的结果集。 交叉连接的工作原理如下:它会将左表的每一行与右表的每一行…...
Python web实战 | 使用 Django 搭建 Web 应用程序 【干货】
概要 从社交媒体到在线购物,从在线银行到在线医疗,Web 应用程序为人们提供了方便快捷的服务。Web 应用程序已经成为了人们日常生活中不可或缺的一部分。搭建一个高效、稳定、易用的 Web 应用程序并不是一件容易的事情。本文将介绍如何使用 Django 快速搭…...
)
UE5自定义蓝图节点(二)
继承于UBlueprintAsyncActionBase的类,异步输出节点的实现方法,代码测试正常 .h // Fill out your copyright notice in the Description page of Project Settings.#pragma once#include "CoreMinimal.h" #include "Kismet/BlueprintA…...

Bean容器中的ThreadPoolTaskExecutor需要手动关闭吗
ThreadPoolTaskExecutor 是 Spring 提供的一个方便的线程池实现,用于异步执行任务或处理并发请求。 在使用 ThreadPoolTaskExecutor 作为 Spring Bean 注册到容器中后,Spring 会负责在应用程序关闭时自动关闭所有注册的线程池,所以不需要手动…...
——Redis的Java客户端)
Redis学习路线(3)——Redis的Java客户端
一、如何使用Redis的Java客户端 官方文档: https://redis.io/docs/clients/java/ Java-Redis客户端使用场景Jeids 以Redis命令作为方法名称,学习成本低,简单实现,但是Jedis实例是线程不安全的,多线程环境下需要基于连…...
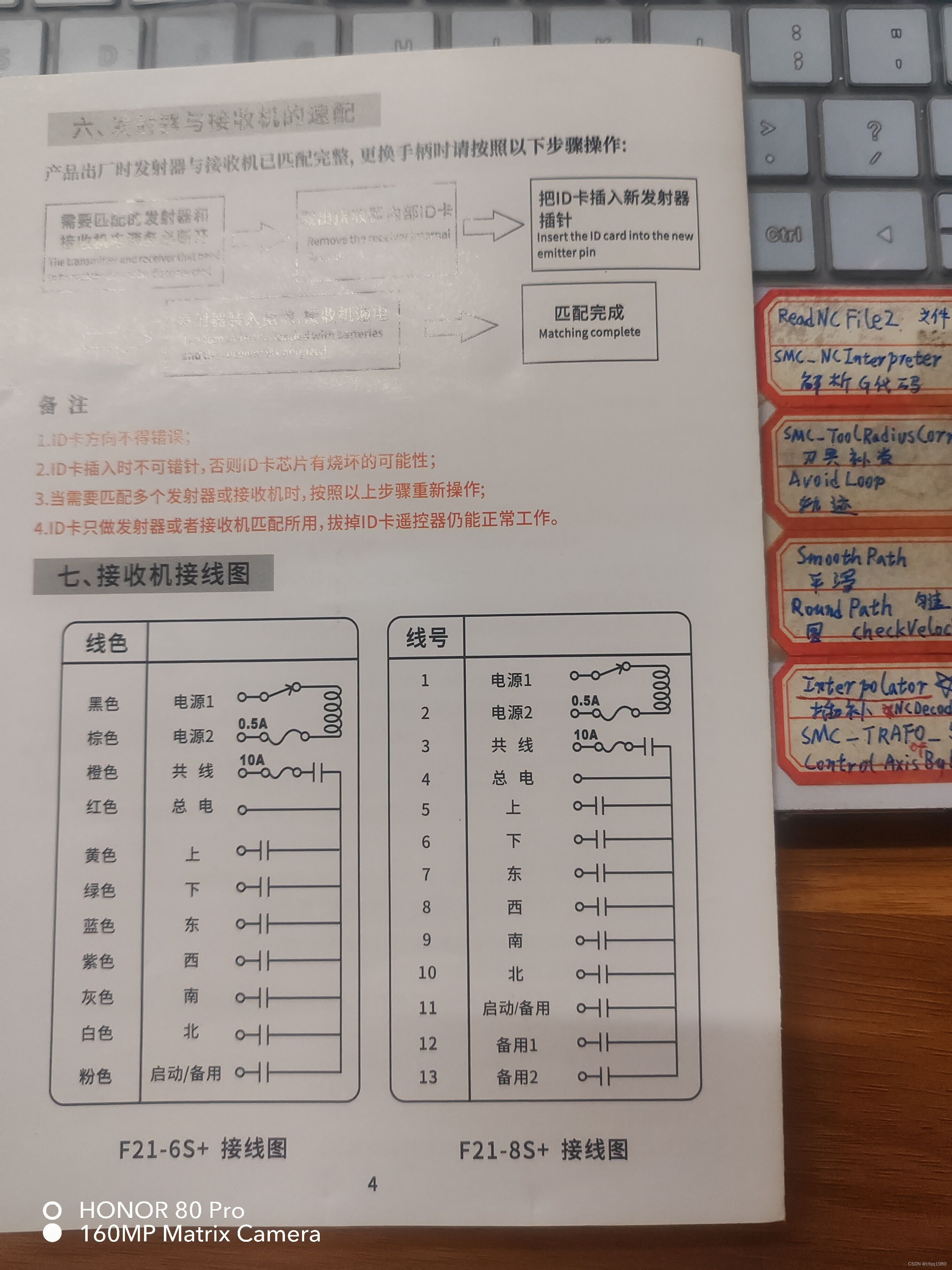
行车遥控接线图
这个一般只有电工才会用。 主要是 【共线和总电】让人疑惑。 这图实际就是PLC的梯形图。 共电:接主电源。【它串联10A保险丝,再到继电器】 总电:它是所有继电器的公共端。【共电的继电器吸合,共电和总电就直通了。】共电的继电器…...

区块链实验室(11) - PBFT耗时与流量特征
以前面仿真程序为例,分析PBFT的耗时与流量特征。实验如下,100个节点构成1个无标度网络,节点最小度为5,最大度为38. 从每个节点发起1次交易共识。统计每次交易的耗时以及流量。本文所述的流量见前述仿真程序的说明:区块链实验室(3)…...
环境变量 位置变量 系统内置变量)
Shell编程基础(三)环境变量 位置变量 系统内置变量
环境变量 & 环境变量环境变量范围父子进程之间有效指定用户有效所有用户有效 位置变量系统内置变量 环境变量 在脚本种直接定义的变量,只能在当前shell进程中使用 若想要在其他shell进程中使用,可以将变量声明为 环境变量 export 变量名 ÿ…...

P5718 【深基4.例2】找最小值
题目描述 给出 n n n 和 n n n 个整数 a i a_i ai,求这 n n n 个整数中最小值是什么。 输入格式 第一行输入一个正整数 n n n,表示数字个数。 第二行输入 n n n 个非负整数,表示 a 1 , a 2 … a n a_1,a_2 \dots a_n a1,a2……...
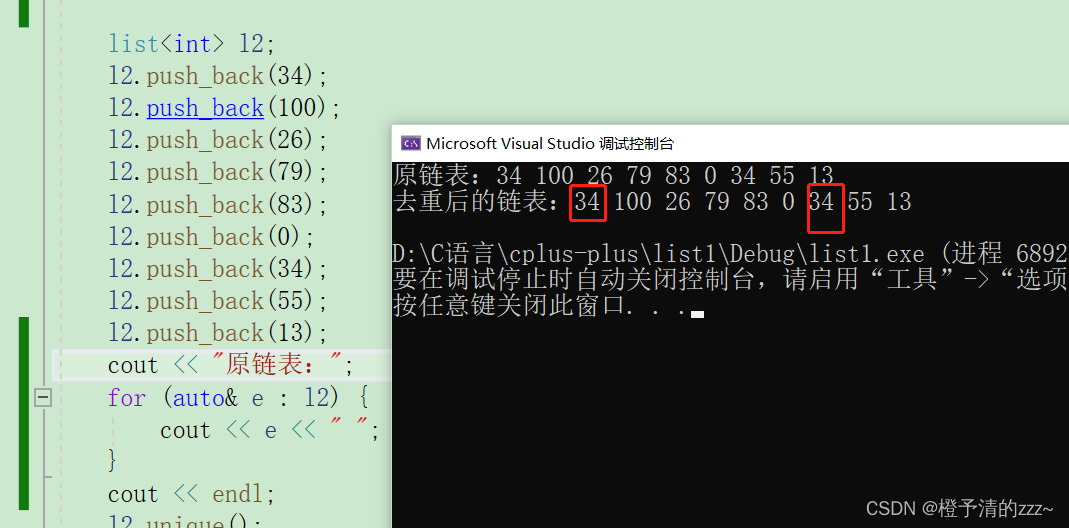
C++——STL容器之list链表的讲解
目录 一.list的介绍 二.list类成员函数的讲解 2.2迭代器 三.添加删除数据: 3.1添加: 3.2删除数据 四.排序及去重函数: 错误案例如下: 方法如下: 一.list的介绍 list列表是序列容器,允许在序列内的任何…...

使用for循环输出左上三角、右上三角、左下三角、右下三角、上下三角
1、输出如下图形: #include<stdio.h> int main() {/*输出图形 666666666666666*/for(int i1;i<5;i){for(int j1;j<i;j){putchar(6);}printf("\n"); } return 0; } 2、输出如下图形: #include<stdio.h> int main() {/*输出图…...
CAXA中.exb或者.dwg文件保存为PDF
通常CAXAZ中的文件为.exb或者.dwg格式,我们想打印或者保存为PDF文件格式,那么就用一下的方法: CAXA文件如图所示: 框选出你要打印的图纸!!!! 我们选择"菜单"->"…...

华为刷题:HJ3明明随机数
import java.util.Scanner;// 注意类名必须为 Main, 不要有任何 package xxx 信息 public class Main {public static void main(String[] args) {Scanner scan new Scanner(System.in);int N scan.nextInt();int[] arr new int[N];for (int i 0; i < N; i) {int n sca…...
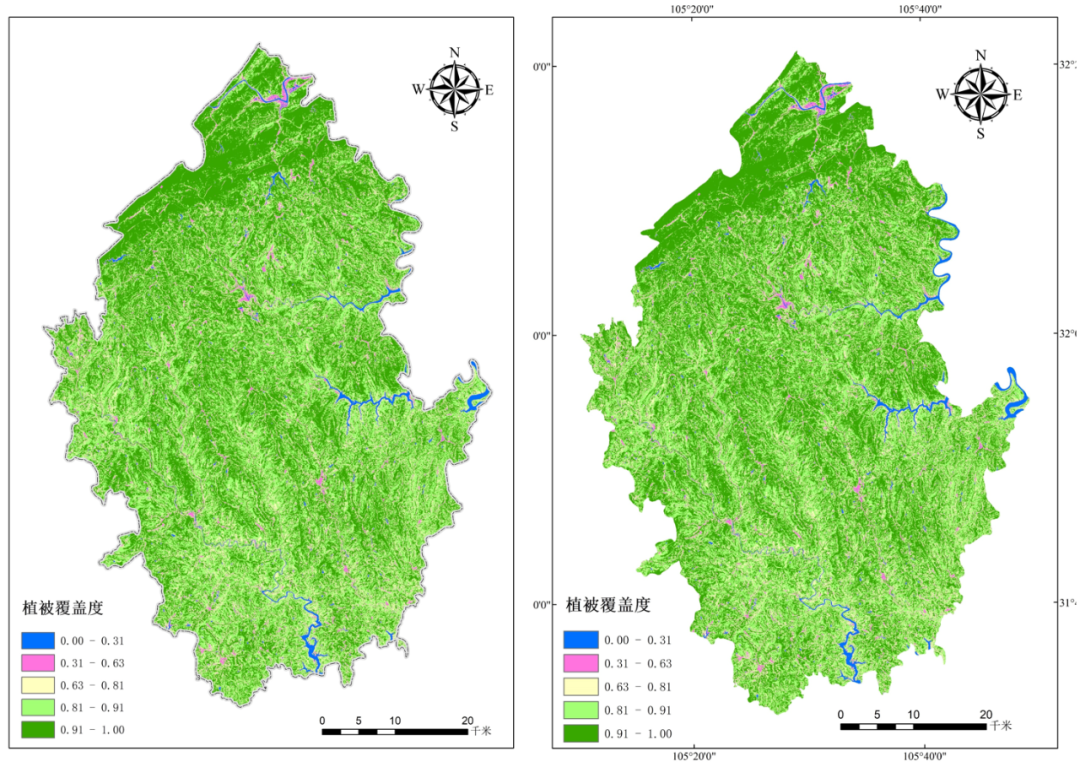
ENVI提取NDVI与植被覆盖度估算
目标是通过ENVI计算植被覆盖度结合ArcGIS出图得到植被覆盖图。 一、植被覆盖度的定义: 植被覆盖度( FractionalVegetation Cover,FVC) 通常定义为植被( 包括叶、茎、枝) 在地面的垂直投影面积占统计区总面积的百分比,它量化了植被的茂密程度,反应了植被的生长态势,是刻画…...

Arm 扩大开源合作伙伴关系,加强投入开放协作
作者:Arm 开源软件副总裁 Mark Hambleton Arm 和我们的生态系统的关键信念之一是与开源社区合作,共创一个高度发达的 Arm 架构,使软件的落地更加稳定,从而让全球数百万开发者能够测试并创建自己的应用。 为此,Arm 支…...

Kubernetes 的核心概念:Pod、Service 和 Namespace 解析
🌷🍁 博主 libin9iOak带您 Go to New World.✨🍁 🦄 个人主页——libin9iOak的博客🎐 🐳 《面试题大全》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~ἳ…...

Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 [特殊字符]
Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 🚀 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一个基于HTML5的雪碧图生成器,它采…...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...

PDF 可视化签名盖章页技术解析
本文是我在设备检测系统项目开发中,无设备检测的技术实现备忘录,记载实现过程。 本文以 PC 端页面 sign-pdf.vue 为主线,说明「无设备报检」在报告审批环节如何通过前后端协作,完成报告/记录 PDF 上的签名、印章、报告编号拖放定位,并在审批通过后由后端合并生成带签章的正…...

为内部知识库问答机器人接入Taotoken多模型增强回答效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人接入Taotoken多模型增强回答效果 构建一个高效的企业内部知识库问答机器人,核心挑战在于如何让…...

Windows终极PDF处理工具:3步免费安装Poppler完整指南
Windows终极PDF处理工具:3步免费安装Poppler完整指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 你是否曾经为在Windows上处理PDF文…...

科华UPS电源全品类汇总:选型与场景适配指南
科华UPS电源作为国内智慧电能领域的主流产品,覆盖家用、办公、机房、工业等全场景,产品系列丰富、规格齐全,但多数用户在选型时,常因分不清系列差异、功率适配、架构类型而踩坑。本文系统汇总科华UPS电源的核心分类、主流系列、核…...

基于雷达与光敏传感器的低功耗智能窗防设备设计与实现
1. 项目概述:一个基于雷达与光敏的智能窗防设备几年前,我因为一次短暂的出差,家里空置了几天,回来后就一直琢磨着怎么给家里的窗户加点“动静”。市面上的智能安防摄像头固然好,但要么需要复杂的布线,要么云…...

如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型
如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型 【免费下载链接】DeepPurpose A Deep Learning Toolkit for DTI, Drug Property, PPI, DDI, Protein Function Prediction (Bioinformatics) 项目地址: https://gitcode.com/gh_mirrors/de…...
--脚本介绍)
二十六.签名与脚本(1)--脚本介绍
1.区块链脚本介绍在之前的章节中,我们了解了签名与验证相关,但是btc的交易数据,签名和验证,不是单纯的,还有脚本深度参与其中。我们从开始来:bool SendMoney(CScript scriptPubKey, int64 nValue, CWalletT…...

Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现
Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现 【免费下载链接】vue2-verify vue的验证码插件 项目地址: https://gitcode.com/gh_mirrors/vu/vue2-verify 在当今Web应用开发中,验证码作为防止自动化攻击的关键安全组件&…...