django------模糊查询
1.常用模糊查询的方法
queryset中支持链式操作
book=Book.objects.all().order_by('-nid').first()只要返回的是queryset对象就可以调用其他的方法,直到返回的是对象本身
大于、大于等于、小于、小于等于:
# __gt 大于>
# __gte 大于等于>=
# __lt 小于<
# __lte 小于等于<=Student.objects.filter(age__gt=10) # 查询年龄大于10岁的学生
Student.objects.filter(age__gte=10) # 查询年龄大于等于10岁的学生
Student.objects.filter(age__lt=10) # 查询年龄小于10岁的学生
Student.objects.filter(age__lte=10) # 查询年龄小于等于10岁的学生
- 特别注意:这里的下划线是双下划线
不等于/不包含于:
Student.objects.filter().excute(age=10) # 查询年龄不为10的学生
Student.objects.filter().excute(age__in=[10, 20]) # 查询年龄不在 [10, 20] 的学生
数据库 like操作 模糊查询常用的操作
# __exact 精确等于 like 'aaa'
# __iexact 精确等于 忽略大小写 ilike 'aaa'
# __contains 包含 like '%aaa%'
# __icontains 包含,忽略大小写 ilike '%aaa%',但是对于sqlite来说,contains的作用效果等同于icontains。
# __startswith 以…开头
# __istartswith 以…开头 忽略大小写
# __endswith 以…结尾
# __iendswith 以…结尾,忽略大小写
# __range 在…范围内
# __year 日期字段的年份
# __month 日期字段的月份
# __day 日期字段的日# 用法:
Book.objects.filter(title__exact="python")
# 等价于 title like 'python'
Book.objects.filter(title__contains="python")
# 等价于 title like '%python%'
Book.objects.filter(title__icontains="python")
# 忽略大小写
Book.objects.filter(title__startswith="py")
# 等价于 title like 'py%'
Book.objects.filter(title__endswith="aa")
# 等价于 title like '%aa'Book.objects.filter(pub_date__year=2012)
# 日期字段的2012年份Student.objects.filter().excute(age=10) # 查询年龄不为10的学生
Student.objects.filter().excute(age__in=[10, 20]) # 查询年龄不在 [10, 20] 的学生
是否为空
User.objects.filter(username__isnull=True) # 查询用户名为空的用户
User.objects.filter(username__isnull=False) # 查询用户名不为空的用户# a)判等 条件名:exact。
# 例:查询名字为abc的图书。
BookInfo.objects.filter(name="abc") #等同于 BookInfo.objects.filter(name__exact="abc") 名称严格等于 "abc" 的人
BookInfo.objects.filter(name__iexact="abc") # 名称为 abc 但是不区分大小写,可以找到 ABC, Abc, aBC,这些都符合条件# b)模糊查询(相当于sql的 like)
# 例:查询书名包含'传'的图书。contains
BookInfo.objects.filter(btitle__contains='传')
# 例:查询书名以'部'结尾的图书 endswith 开头:startswith
BookInfo.objects.filter(btitle__endswith='部')# c)空查询 isnull
# 例:查询书名不为空的图书。isnull
select * from booktest_bookinfo where btitle is not null;
BookInfo.objects.filter(btitle__isnull=False)# d)范围查询 in
# 例:查询id为1或3或5的图书。
select * from booktest_bookinfo where id in (1,3,5);
BookInfo.objects.filter(id__in = [1,3,5])# e)比较查询 gt(greate than) lt(less than) gte(equal) 大于等于
# lte 小于等于
# 例:查询id大于3的图书。
Select * from booktest_bookinfo where id>3;
BookInfo.objects.filter(id__gt=3)# f)日期查询
# 例:查询1980年发表的图书。
BookInfo.objects.filter(bpub_date__year=1980)
# 例:查询1980年1月1日后发表的图书。
from datetime import date
BookInfo.objects.filter(bpub_date__gt=date(1980,1,1))# g)range在...范围内
BookInfo.objects.filter(name__regex="^abc") # 正则表达式查询
BookInfo.objects.filter(name__iregex="^abc") # 正则表达式不区分大小写# exclude(返回不满足条件的数据。)方法示例:
# 例:查询id不为3的图书信息。
BookInfo.objects.exclude(id=3)
User.objects.filter().excute(age=10) // 查询年龄不为10的用户
User.objects.filter().excute(age__in=[10, 20]) // 查询年龄不为在 [10, 20] 的用户# order_by(对查询结果进行排序)方法示例:
# 作用:进行查询结果进行排序。默认是升序,在条件里加“-”表示降序
# 例:查询所有图书的信息,按照id从小到大进行排序。
BookInfo.objects.all().order_by('id')# 例:查询所有图书的信息,按照id从大到小进行排序。
BookInfo.objects.all().order_by('-id')# 例:把id大于3的图书信息按阅读量从大到小排序显示。
BookInfo.objects.filter(id__gt=3).order_by('-bread')
多表连接查询:
class A(models.Model):name = models.CharField(u'名称')class B(models.Model):aa = models.ForeignKey(A)B.objects.filter(aa__name__contains='searchtitle')
# 查询B表中外键aa所对应的表中字段name包含searchtitle的B表对象。
总结
- exclude(): ---------不包含
# exclude(**kwargs)
# 返回一个新的QuerySet,它包含不满足给定的查找参数的对象Student.objects.exclude(age__gt=20, name='lin')#排除所有年龄大于20岁且名字为“lin”的学员集
2.annotate(): ---------------------聚合函数需要用到
annotate(args, *kwargs)# 使用提供的聚合表达式查询对象。
# 表达式可以是简单的值、对模型(或任何关联模型)上的字段的引用或者聚合表达式(平均值、总和等)。
# annotate()的每个参数都是一个annotation,它将添加到返回的QuerySet每个对象中。
# 关键字参数指定的Annotation将使用关键字作为Annotation 的别名。 匿名参数的别名将基于聚合函数的名称和模型的字段生成。 只有引用单个字段的聚合表达式才可以使用匿名参数。 其它所有形式都必须用关键字参数。
# 例如,如果正在操作一个Blog列表,你可能想知道每个Blog有多少Entry:
>>> from django.db.models import Count
>>> q = Blog.objects.annotate(Count('entry'))
# The name of the first blog
>>> q[0].name
'Blogasaurus'
# The number of entries on the first blog
>>> q[0].entry__count
42
- order_by(): 排序
order_by(*fields)# 默认情况下,根据模型的Meta类中的ordering属性对QuerySet中的对象进行排序
Student.objects.filter(school="阳关小学").order_by('-age', 'name')
# 上面的结果将按照age降序排序,然后再按照name升序排序。"-age"前面的负号表示降序顺序。 升序是默认的。 要随机排序,使用"?",如下所示:
Student.objects.order_by('?')
- reverse(): -------反向排序
# reverse()
# 反向排序QuerySet中返回的元素。 第二次调用reverse()将恢复到原有的排序。
# 如要获取QuerySet中最后五个元素,可以这样做:
my_queryset.reverse()[:5]
# 这与Python直接使用负索引有点不一样。 Django不支持负索引。
distinct() ---------去重
distinct(*fields)
# 去除查询结果中重复的行。
# 默认情况下,QuerySet不会去除重复的行。当查询跨越多张表的数据时,QuerySet可能得到重复的结果,这时候可以使用distinct()进行去重。
values()
values(fields, *expressions)# 返回一个包含数据的字典的queryset,而不是模型实例。# 每个字典表示一个对象,键对应于模型对象的属性名称。如:# 列表中包含的是Student对象
>>> Student.objects.filter(name__startswith='Lin')
<QuerySet [<Student: Lin Student>]># 列表中包含的是数据字典
>>> Student.objects.filter(name__startswith='Lin').values()
<QuerySet [{'id': 1, 'name': 'Linxiao', 'age': 20}]># 另外该方法接收可选的位置参数*fields,它指定values()应该限制哪些字段。如果指定字段,每个字典将只包含指定的字段的键/值。如果没有指定字段,每个字典将包含数据库表中所有字段的键和值。如下:
>>> Student.objects.filter(name__startswith='Lin').values()
<QuerySet [{'id': 1, 'name': 'Linxiao', 'age': 20}]>>>> Blog.objects.values('id', 'name')
<QuerySet [{'id': 1, 'name': 'Linxiao'}]>
values_list()
values_list(*fields, flat=False)# 与values()类似,只是在迭代时返回的是元组而不是字典。每个元组包含传递给values_list()调用的相应字段或表达式的值,因此第一个项目是第一个字段等。 像这样:
>>> Student.objects.values_list('id', 'name')
<QuerySet [(1, 'Linxiao'), ...]
相关文章:

django------模糊查询
1.常用模糊查询的方法 queryset中支持链式操作 bookBook.objects.all().order_by(-nid).first() 只要返回的是queryset对象就可以调用其他的方法,直到返回的是对象本身 大于、大于等于、小于、小于等于: # __gt 大于> # __gte 大于等于> # __lt 小于< …...

AVFoundation - 音视频组合编辑
文章目录 一、简要说明二、使用1、音频和视频合成2、视频的拼接一、简要说明 相关类 AVMutableCompositionAVMutableCompositionTrack二、使用 1、音频和视频合成 - (void)testCom1{AVMutableComposition *mutableComposition = [AVMutableComposition composition];AVMu...
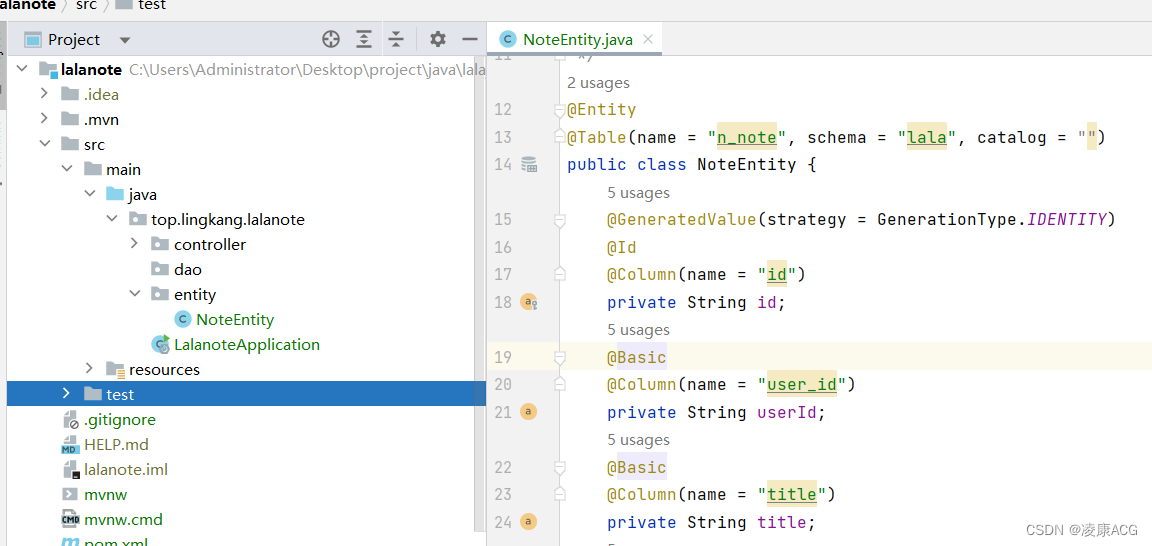
jpa生成实体类,jpa根据数据库表生成实体类
jpa生成实体类,jpa根据数据库表生成实体类jpa根据数据库表结构生成实体idea下SpringbootJPA从数据库自动生成实体类JPA用数据库表直接生成实体类Spring boot整合jpa(一),根据表生成实体IDEA下SpringData-JPA根据数据库表生成实体类idea怎么根据数据库表自动生成JPA实…...

嵌入式Linux系统组成
嵌入式Linux系统的组成 文章目录 嵌入式Linux系统的组成一、发行版Linux系统VS嵌入式Linux系统二、嵌入式Linux系统架构一、发行版Linux系统VS嵌入式Linux系统 1.产品 发行版Linux系统产品:服务器、消费平板、消费手提电脑 嵌入式Linux系统产品:扫地机器人,小米机顶盒特定场…...
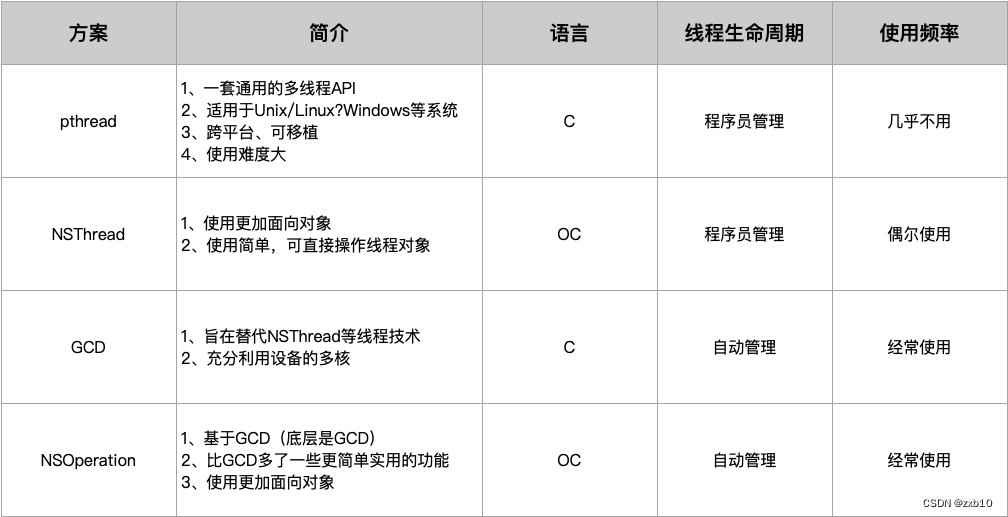
【iOS】—— RunLoop和多线程相关问题总结
RunLoop 1. 讲讲RunLoop,项目中有用到过吗? RunLoop 的基本作用:保持程序的持续运行,节省 CPU 的资源,提高程序的性能 ( 没有事情,就请休眠,不要功耗。有事情,就处理&a…...
)
在CSDN学Golang云原生(gitlab)
一,基于Docker安装gitlab runner 在Golang中,基于Docker安装GitLab Runner需要以下步骤: 首先,您需要安装Docker和Docker Compose。这可以通过访问官方网站来完成。接下来,您需要创建一个名为docker-compose.yml的文…...

cv2抛出异常 “install libgtk2.0-dev and pkg-config, then re-run cmake or configure”
背景: linux中使用cv2显示图片的时候,运行提示异常: 处理方式: 网友的推荐操作: 切换至root模式安装 apt-get install libgtk2.0-dev进入OpenCV下载目录,重新编译 cd /home/XXX/opencv mkdir release …...
C#..上位机软件的未来是什么?
C#是一种流行的编程语言,广泛应用于桌面应用程序和上位机软件开发。未来,C#上位机软件将继续不断发展和创新,以满足用户日益增长的需求。以下是我认为C#上位机软件未来可能会涉及的一些方向: 更加智能化:随着人工智能…...
CentOS 搭建 GitLab Git
本文目录 1. CentOS7 搭建 Gitlab1. 安装 sshd1. 安装 sshd 依赖2. 启动并设置开机自启3. 安装防火墙4. 开启防火墙5. 开放 ssh 以及 http 服务 2. 安装 postfix1. 安装 postfix2. 启动并设置开机自启3. 几个补充知识 3. 下载并安装 gitlab1. 在线下载安装包2. 安装 4. 修改 gi…...

【MTK平台】【wpa_supplicant】关于wpa_supplicant_8/src/p2p/p2p_go_neg.c文件的介绍
本文主要介绍external/wpa_supplicant_8/src/p2p/p2p_go_neg.c文件 这里主要介绍2个方法 1. p2p_connect_send接受来自 p2p.c 文件中调用p2p_connect方法发送的GON Request帧 2. p2p_process_go_neg_resp处理来自GON Response帧的处理流程 先看下p2p_connect_send方法 int p…...
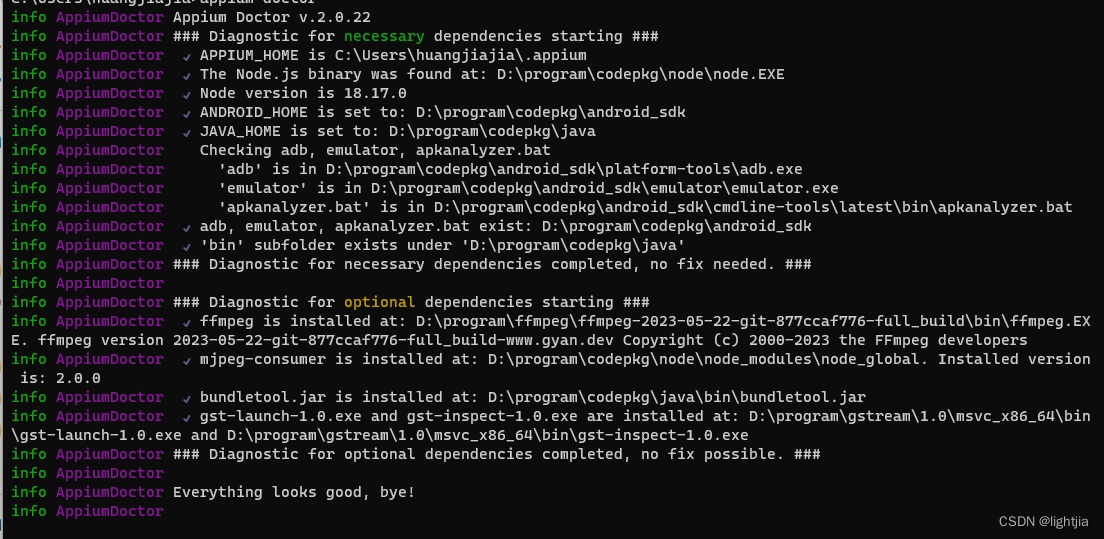
win11安装appium
node安装 node下载网址: Download | Node.js 安装后对node安装包路径进行配置 npm config set prefix “E:\nodejs\node_global” //设置全局包目录 npm config set cache “E:\nodejs\node_cache” //设置缓存目录npm config list //查看npm配置npm install -g appium //安…...

数据科学、统计学、商业分析
数据科学、统计学、商业分析是在各方面有着不同的侧重和方向的领域。 1.专业技能 数据科学(Data Science):数据科学涉及从大量数据中提取有价值的信息、模式和洞察力的领域。它使用多种技术和领域知识,如统计学、机器学习、数据库…...
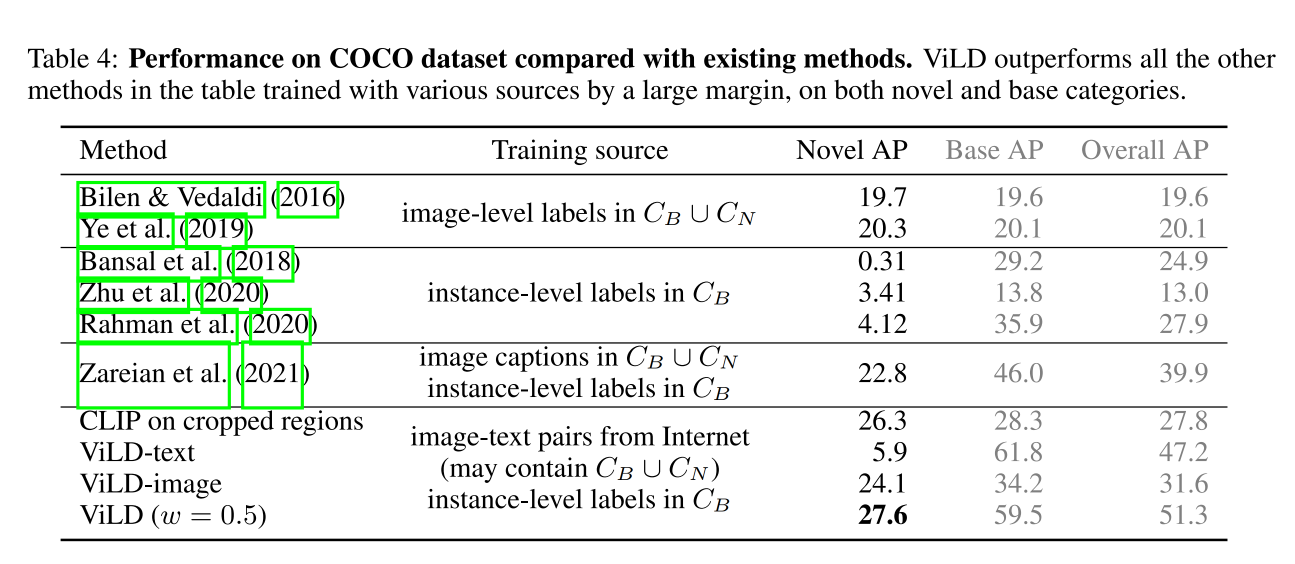
【多模态】18、ViLD | 通过对视觉和语言知识蒸馏来实现开集目标检测(ICLR2022)
文章目录 一、背景二、方法2.1 对新类别的定位 Localization2.2 使用 cropped regions 进行开放词汇检测2.3 ViLD 三、效果 论文:Open-vocabulary Object Detection via Vision and Language Knowledge Distillation 代码:https://github.com/tensorflo…...
【AGI】Copilot AI编程辅助工具安装教程
1. 基础激活教程 GitHub和OpenAI联合为程序员们送上了编程神器——GitHub Copilot。 但是,Copilot目前不提供公开使用,需要注册账号通过审核,我也提交了申请:这里第一期记录下,开启教程,欢迎大佬们来讨论…...
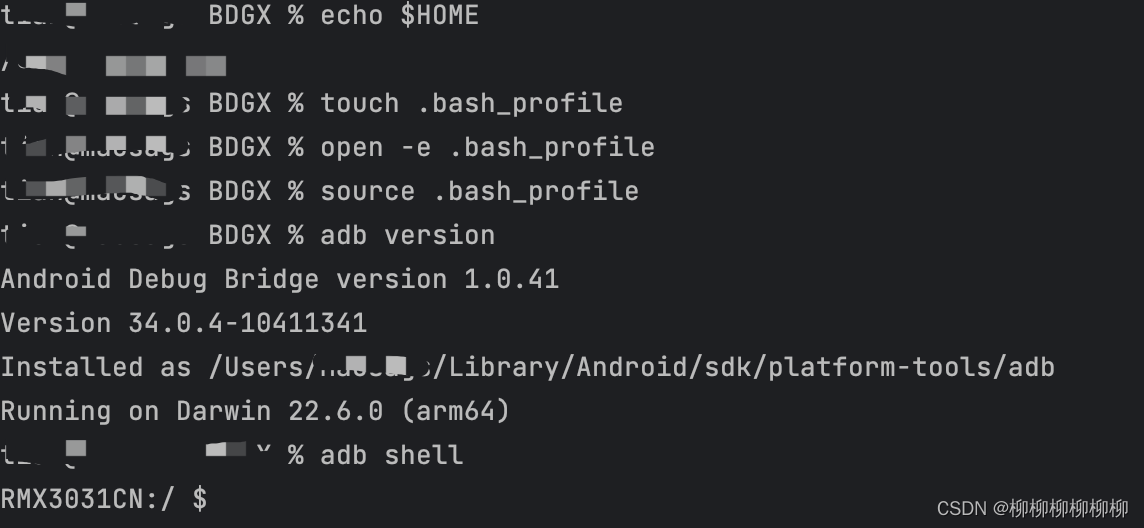
Mac配置android studio的终端terminal
一共6步 首先打开terminal 1.echo $HOME 2.touch .bash_profile 3.open -e .bash_profile 4.在弹出框中输入 export PATH${PATH}:你电脑sdk的路径/tools:你电脑sdk的路径/platform-tools 5.source .bash_profile 6.adb version 出现类似上图即为成功...
第八次CCF计算机软件能力认证
第一题:最大波动 小明正在利用股票的波动程度来研究股票。 小明拿到了一只股票每天收盘时的价格,他想知道,这只股票连续几天的最大波动值是多少,即在这几天中某天收盘价格与前一天收盘价格之差的绝对值最大是多少。 输入格式 输入…...
)
MATLAB RANSAC平面拟合 (29)
MATLAB RANSAC平面拟合 (29) 一、算法简介二、函数介绍三、算法实现四、效果展示一、算法简介 将一个平面与一个从内点到平面的最大允许距离的点云相匹配。该函数返回描述平面的几何模型。该函数采用 M- 估计量样本一致性(MSAC)算法求解平面。MSAC 算法是随机样本一致性(RAN…...

铁路关基保护新规:优先采购安全可信的网络产品和服务!
《征求意见稿》第十四条提到:运营者应当加强供应链安全保护,优先采购安全可信的网络产品和服务;采购网络产品和服务影响或者可能影响国家安全的,运营者应当预判网络产品和服务投入使用后可能带来的国家安全风险,按照国…...

Kafka在大数据处理中的应用
Kafka在大数据处理中的应用 一、Kafka简介1. 基础概念2. Kafka的主要功能3. Kafka的特点 二、应用场景1. 数据采集和消费2. 数据存储和持久化3. 实时数据处理和流计算4. 数据通信和协同 三、技术融合1. Kafka与Hadoop生态技术的融合1) 使用Kafka作为Hadoop的数据源2) 使用Hadoo…...

Linux Day03
一、基础命令(在Linux Day02基础上补充) 1.10 find find 搜索路径 -name 文件名 按文件名字搜索 find 搜索路径 -cmin -n 搜索过去n分钟内修改的文件 find 搜索路径 -ctime -n搜索过去n分钟内修改的文件 1)按文件名字 2)按时间 1.11 grep 在文件中过…...

从零搭建Vulnstack内网靶场:一次完整的渗透测试实战复盘
1. 环境准备与靶场搭建 第一次接触Vulnstack靶场时,我完全被内网渗透的复杂性震撼到了。这个靶场模拟了真实企业内网环境,包含域控制器、Web服务器和普通办公主机等多种设备。搭建过程就像拼装一台精密仪器,每个部件都要准确定位。 靶机环境需…...

深入解析SerialPort:从硬件流控制到实战串口通信
1. 串口通信基础:从水管到数据流 第一次接触串口通信时,我盯着电脑上的COM接口发呆了半小时。这玩意儿看起来就像老式打印机接口,但它却是连接硬件世界的魔法通道。串口通信就像用一根水管在两个水桶之间传递水,只不过我们传递的…...

ThinkPad X1 Tablet Gen3 vs Gen2键盘对比:为何Gen3更适合改装Type-C?
ThinkPad X1 Tablet Gen3键盘Type-C改装全解析:为何它成为DIY玩家的终极选择? 在移动办公设备轻量化与模块化设计成为主流的今天,ThinkPad X1 Tablet系列凭借其独特的二合一形态和标志性键盘手感,始终保持着特殊地位。特别是第三代…...

Ollama部署LFM2.5-1.2B-Thinking:轻量模型在边缘设备上的真实性能报告
Ollama部署LFM2.5-1.2B-Thinking:轻量模型在边缘设备上的真实性能报告 1. 模型介绍:专为边缘设备设计的智能助手 LFM2.5-1.2B-Thinking是一个专门为设备端部署优化的文本生成模型,它在LFM2架构基础上进行了深度改进。这个模型最大的特点就是…...

解决ModelScope与datasets版本兼容性问题的最佳实践
1. 为什么ModelScope和datasets版本兼容性这么重要? 第一次用ModelScope加载数据集时,我就被报错整懵了。明明按照官方文档安装了最新版,却提示"ImportError: cannot import name _FEATURE_TYPES from datasets"。后来才发现是Mode…...

数字电路实战:基于Multisim的74LS161计数器设计与应用
1. 从零认识74LS161计数器 第一次接触数字电路时,看到74LS161这个编号可能会觉得头大。其实它就是个非常实用的4位二进制同步计数器芯片,就像我们生活中常见的里程表一样,能够按照固定规律进行计数。我在实验室里第一次用它做实验时ÿ…...

告别手动配置!CCSv9.3一键导入MSP430F5529LP驱动库的两种高效方法
CCSv9.3高效配置指南:MSP430F5529LP驱动库的自动化管理方案 每次新建CCS工程都要重复添加库文件路径?这种低效操作早该被淘汰了。作为TI官方推荐的开发环境,Code Composer Studio其实隐藏着许多能大幅提升工作效率的高级功能。本文将彻底改变…...

OpenClaw技能扩展:基于百川2-13B开发自定义文件处理器
OpenClaw技能扩展:基于百川2-13B开发自定义文件处理器 1. 为什么需要自定义文件处理技能 上周我在整理项目文档时,发现一个重复性痛点:每天需要手动将同事发来的各种格式文件(PDF、Word、Markdown)按内容分类存储。当…...

3大突破 Koodo Reader 2.1.8:跨设备同步引擎重新定义数字阅读体验
3大突破 Koodo Reader 2.1.8:跨设备同步引擎重新定义数字阅读体验 【免费下载链接】koodo-reader A modern ebook manager and reader with sync and backup capacities for Windows, macOS, Linux and Web 项目地址: https://gitcode.com/GitHub_Trending/koo/ko…...

供应链需求预测系统:Granite TimeSeries FlowState R1助力库存优化
供应链需求预测系统:Granite TimeSeries FlowState R1助力库存优化 每次大促过后,仓库里总是一片狼藉。畅销品早早断货,客服电话被打爆;而另一堆商品却纹丝不动,占满了宝贵的库位,资金就这么被“冻”在了货…...