【多模态】18、ViLD | 通过对视觉和语言知识蒸馏来实现开集目标检测(ICLR2022)

文章目录
- 一、背景
- 二、方法
- 2.1 对新类别的定位 Localization
- 2.2 使用 cropped regions 进行开放词汇检测
- 2.3 ViLD
- 三、效果
论文:Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
代码:https://github.com/tensorflow/tpu/tree/master/models/official/detection/projects/vild
效果:
- 在 zero-shot 测试下,coco 达到了 36.6 AP,PASCAL VOC 达到了 72.2AP,Object365 达到了 11.8AP
本文提出了 Vision and Language knowledge Distillation(ViLD):
- 通过将预训练的开集分类模型作为 teacher model,来蒸馏两阶段目标检测器 student model
- 即使用 teacher model 来对 category texts 和 proposal region进行编码
- 然后训练 student detector 来对齐 text 和 region embedding
一、背景
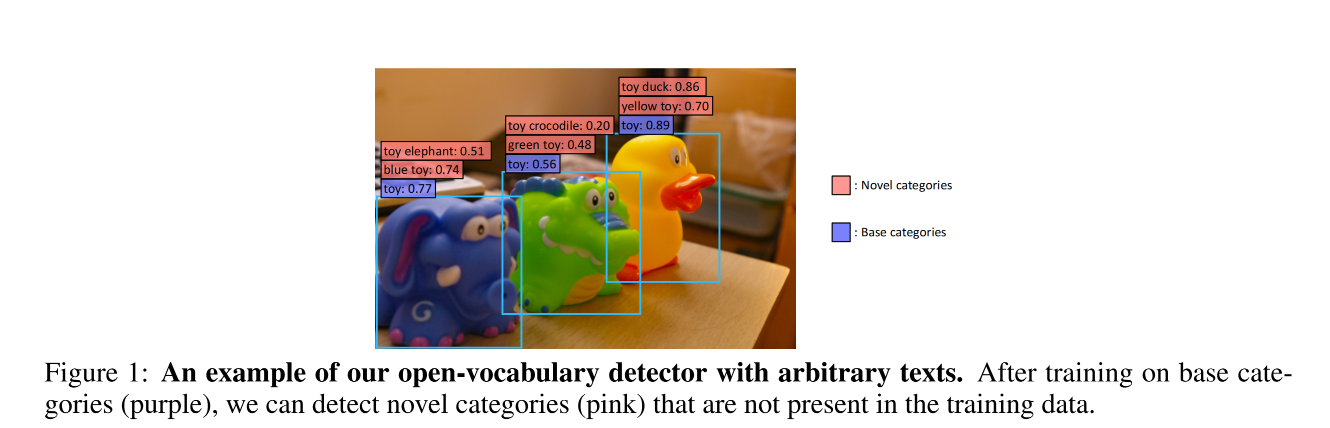
如图 1 所示,作者思考,目标检测器能否识别 base category 之外的类别?
所以,本文作者就构建了一个 open-vocabulary 目标检测器,用于检测从 text 输入的任意类别的目标
现有的目标检测方法都是只学习数据集中出现的类别,而扩充检测类别的方法就是收集更多的类别标注数据,如 LVIS 包括 1203 个类别,有较为丰富的词汇量,但也不够强大。
另外一方面,互联网上有丰富的 image-text pairs,CLIP 就尝试使用 4 亿图文对儿来联合训练模型,并且在 30 个数据集上展示了很好的效果
zero-shot 迁移的效果很大程度上来源于预训练的 text encoder 对任意类别文本的编码能力,尽管现在对 image-level 特征表达的编码能力已经被证明挺好的了,但还 object-level 的特征编码仍然很有挑战
所以,本文作者思考能否从开集分类模型中拿到一些能力来用于开集检测
作者首先从 R-CNN 类的方法入手,将开集目标检测也构建为两个子问题:
- object proposal 的生成
- open-vocabulary 图像分类
如何操作 R-CNN 类的模型:
- 先基于基础类别训练一个 region proposal model
- 然后使用预训练好的图像分类器来对 cropped object proposal 进行分类,可以包括新类和基础类
- 作者使用 LVIS 当做 benchmark,把 rare 类别作为 novel categories,将其他类当做 base categories
- 缺点:很慢,因为每个 object proposal 都是一个个的进入分类器来分类的
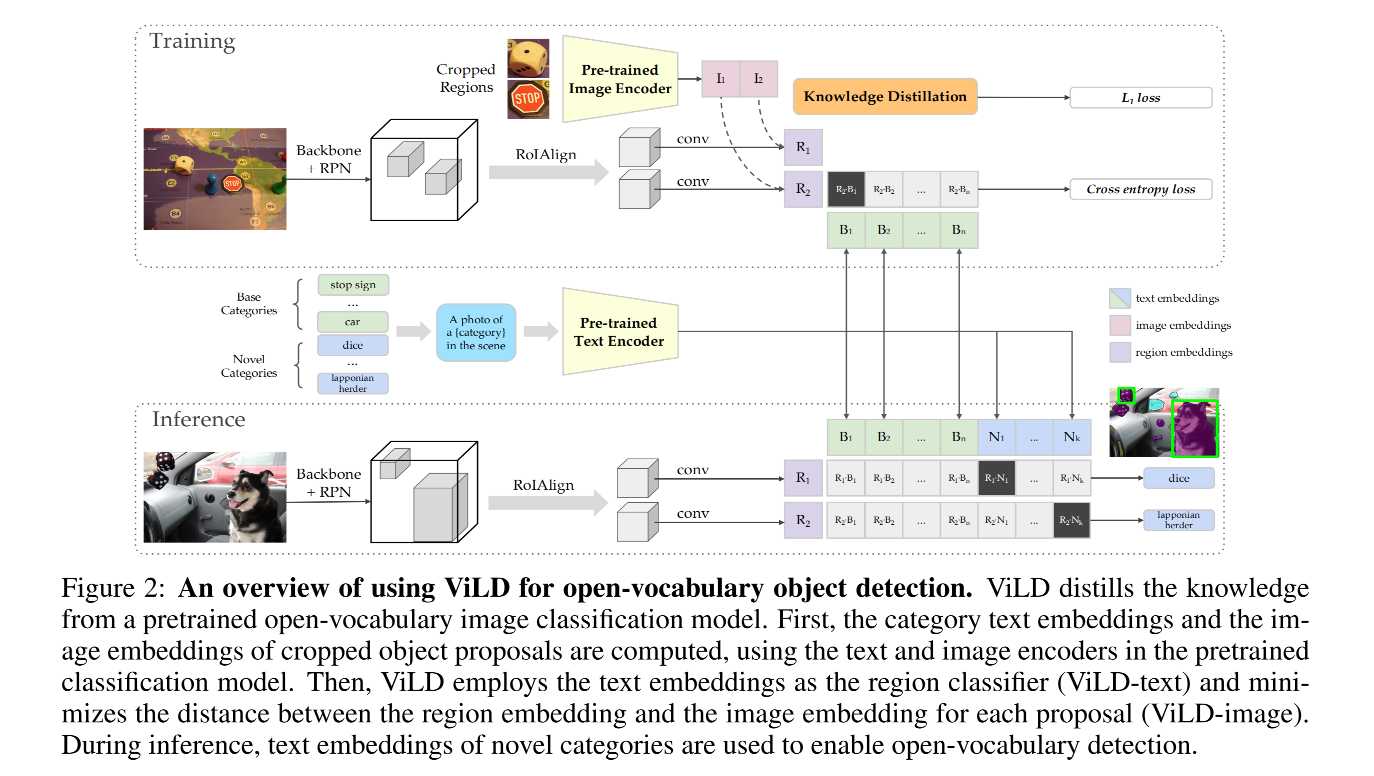
基于此,作者提出了 ViLD,来训练两阶段的开放词汇目标检测器,ViLD 包含两部分:从开集目标分类模型的输出中来学习 text embedding 和 image embedding
- ViLD-text:只会从基础类中蒸馏
- 首先,将类别名称输入预训练好的 text encoder 来得到 text embedding
- 然后,使用推理的 text embedding 结果来对检测到的 region 进行分类
- ViLD-image:会同时从基础类和新类中来蒸馏,因为 proposal 网络可能会检测到包含新类的区域
- 首先,将 object proposal 输入预训练好的 image encoder 来得到 image embedding
- 然后,训练一个 Mask R-CNN 来将 region embedding 和 image embedding 来对齐
二、方法
作者将检测数据集中的类别分类 base 和 novel:
- base: C B C_B CB,参与训练
- novel: C N C_N CN
编码器符号:
- T ( . ) T(.) T(.):text encoder
- V ( . ) V(.) V(.):image encoder
2.1 对新类别的定位 Localization
开放词汇目标检测的第一个挑战就是对新类别目标的定位
作者以 Mask RCNN 为例,作者使用 class-agnostic 模块替换了 class-specific 定位模块,对每个 RoI,模型只能对所有类别预测一个 bbox 和一个 mask,而不是每个类别都会预测一个,所以,使用 class-agnostic 的模块可以扩展到用于新类别的定位
2.2 使用 cropped regions 进行开放词汇检测
一旦对目标候选区域定位成功,就可以使用预训练好的分类器来对区域进行分类
Image embedding:
- 作者基于基础类别 C B C_B CB 训练了一个 proposal 网络,来提取感兴趣区域
- 首先 crop 并 resize proposal,然后输入 image encoder 中计算 image embedding
- 作者使用了两种 crop 区域的 resize 方式:1x 和 1.5x,1.5x 的用于提供更多的上下文信息,整合后的 embedding 然后会被归一化
Text embedding:
- 作者会使用 prompt 模版(如 “a photo of {} in the scene”)来送入 text encoder,并得到 text embedding
相似度:
- 计算完两个 embedding 之后,作者使用 cosine similarities 来计算 image embedding 和 text embedding 的相似程度,然后使用 softmax 激活和类内的 NMS 来得到最终的检测结果
效率:
- 由于每个 cropped region 都会被送入 image encoder 来提取 image embedding,所以效率很低
2.3 ViLD
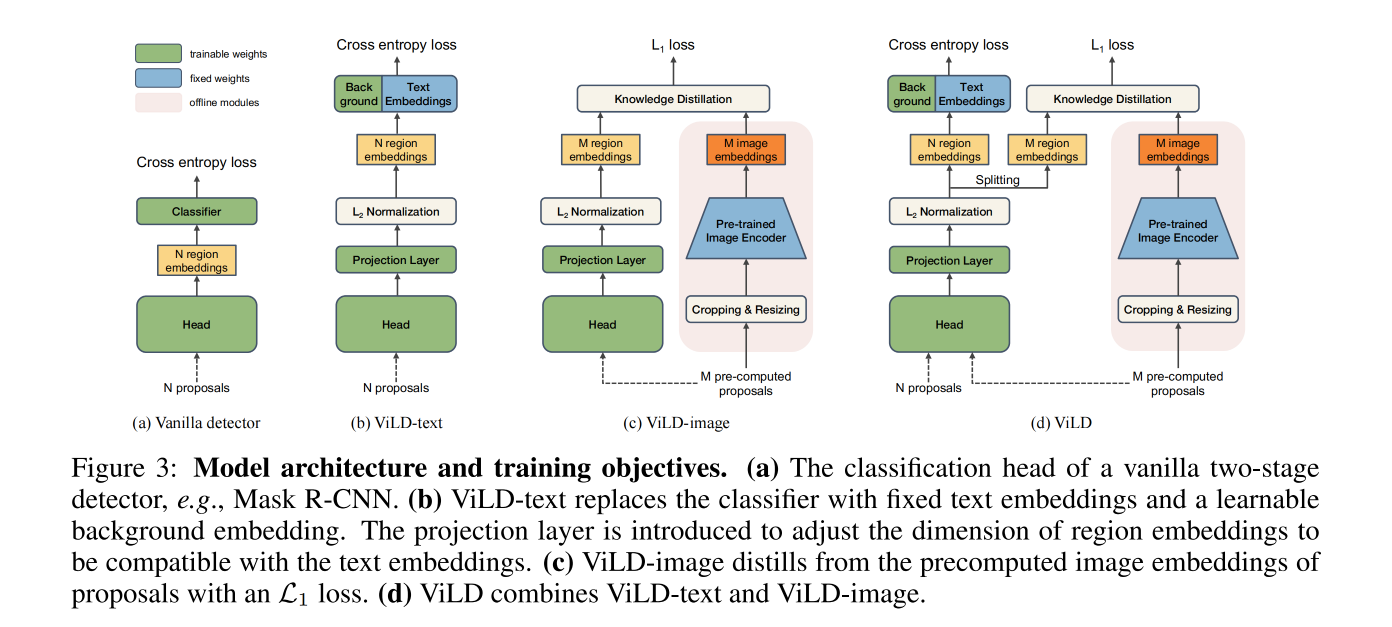
作者提出了 ViLD 来缓解上面提到的效率低的问题
使用 text embedding 来代替分类器:
- 首先,引入了 ViLD-text,目标是训练一个可以使用 text embedding 来分类的 region embedding
- 如图 3b 展示了训练的目标函数,使用 text embedding 来代替了如图 3a 的分类器,只有 text embedding 用于训练
- 对于没有匹配到任何 gt 的 proposal,被分配到背景类别,可以学习其自己的编码 e b g e_{bg} ebg,
- 对所有类别编码,都计算 region embedding 和 category embedding 的余弦相似性,包括前景和背景 e b g e_{bg} ebg,
- 然后,计算带温度参数的 softmax 激活后的分布并计算 cross-entropy loss
- 为了训练第一个阶段,也就是 region proposal 网络,作者在线抽取 region proposal r,并且从头开始使用 ViLD-text 来训练
ViLD-text 的 loss 如下:
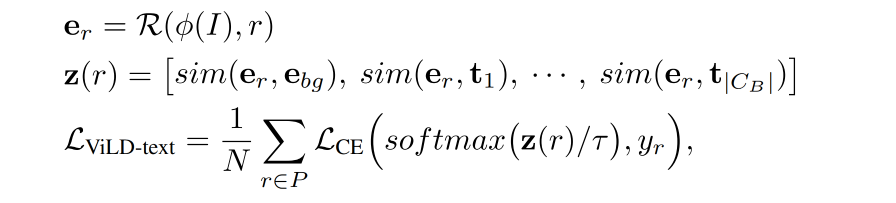
蒸馏 image embedding:
训练 ViLD-image 时,主要是从 teacher model 来蒸馏到 student model 上,也就是将 region embedding 和 image embedding 对齐
为了提升训练速度,对每个 training image 先离线抽取 M 个 proposal,并且计算其对应的 image embedding
这些 proposal 包含了基础类和新类,所以网络是可以扩展的
但 ViLD-text 只能从基础类学习
ViLD-image loss 是 region embedding 和 image embedding 的 L1 loss:
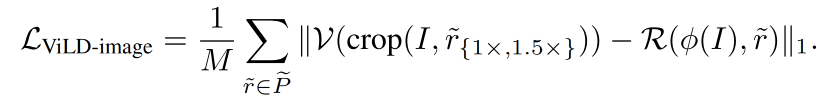
ViLD 的整个训练 loss 如下:w 是超参数
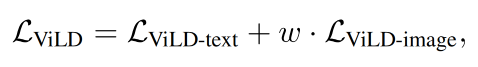
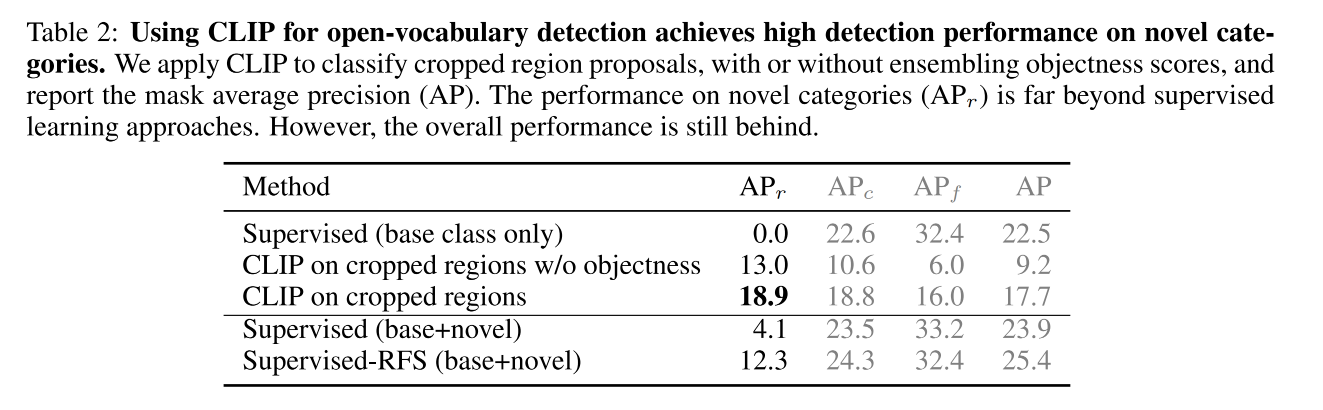
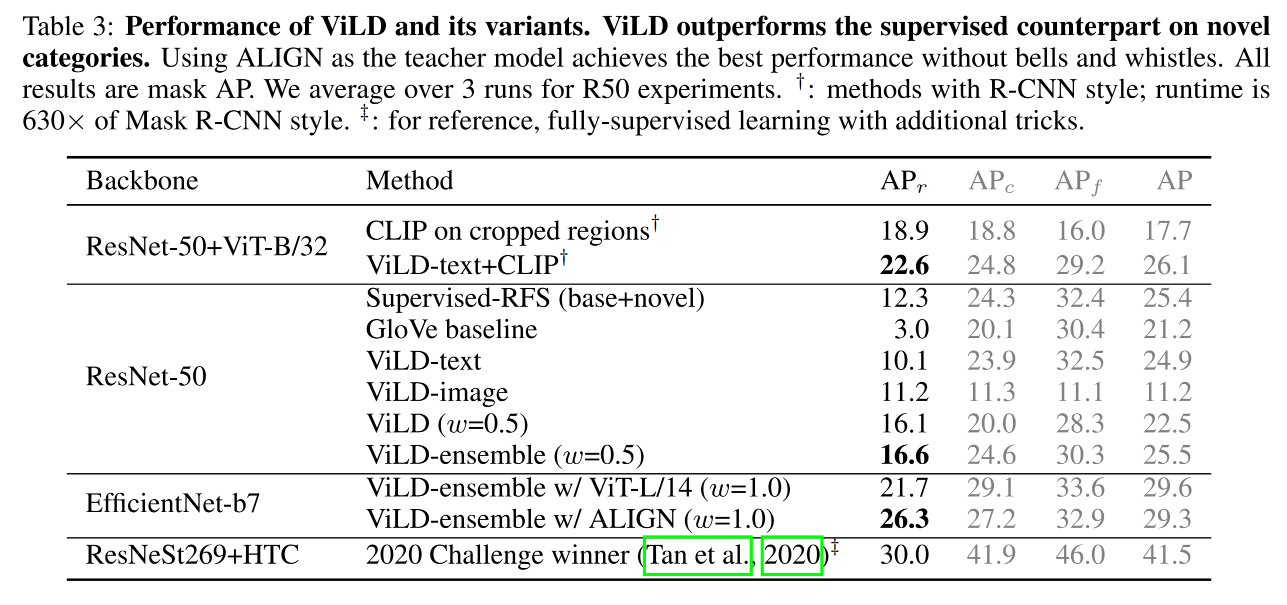
三、效果

相关文章:
【多模态】18、ViLD | 通过对视觉和语言知识蒸馏来实现开集目标检测(ICLR2022)
文章目录 一、背景二、方法2.1 对新类别的定位 Localization2.2 使用 cropped regions 进行开放词汇检测2.3 ViLD 三、效果 论文:Open-vocabulary Object Detection via Vision and Language Knowledge Distillation 代码:https://github.com/tensorflo…...
【AGI】Copilot AI编程辅助工具安装教程
1. 基础激活教程 GitHub和OpenAI联合为程序员们送上了编程神器——GitHub Copilot。 但是,Copilot目前不提供公开使用,需要注册账号通过审核,我也提交了申请:这里第一期记录下,开启教程,欢迎大佬们来讨论…...
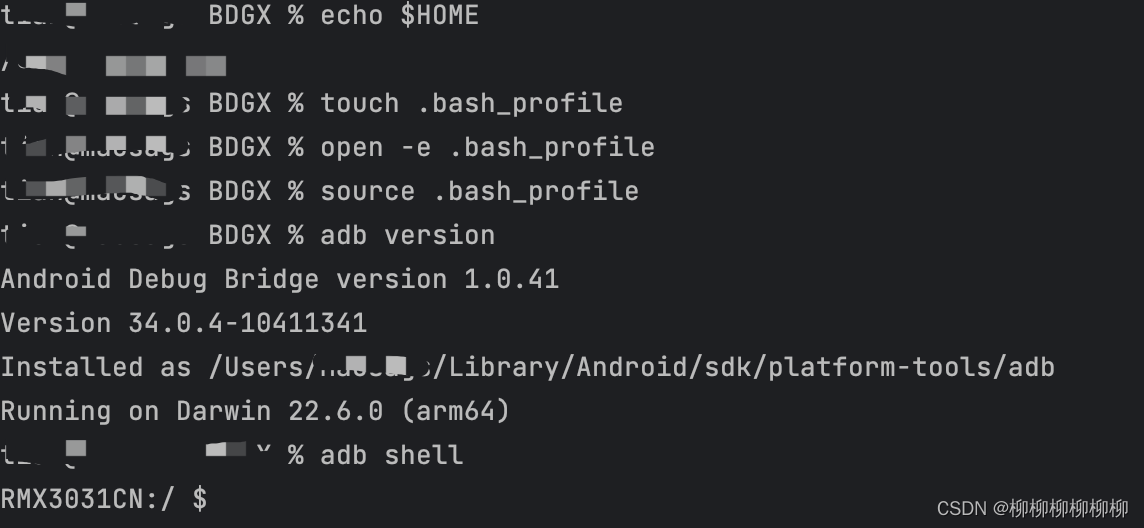
Mac配置android studio的终端terminal
一共6步 首先打开terminal 1.echo $HOME 2.touch .bash_profile 3.open -e .bash_profile 4.在弹出框中输入 export PATH${PATH}:你电脑sdk的路径/tools:你电脑sdk的路径/platform-tools 5.source .bash_profile 6.adb version 出现类似上图即为成功...
第八次CCF计算机软件能力认证
第一题:最大波动 小明正在利用股票的波动程度来研究股票。 小明拿到了一只股票每天收盘时的价格,他想知道,这只股票连续几天的最大波动值是多少,即在这几天中某天收盘价格与前一天收盘价格之差的绝对值最大是多少。 输入格式 输入…...
)
MATLAB RANSAC平面拟合 (29)
MATLAB RANSAC平面拟合 (29) 一、算法简介二、函数介绍三、算法实现四、效果展示一、算法简介 将一个平面与一个从内点到平面的最大允许距离的点云相匹配。该函数返回描述平面的几何模型。该函数采用 M- 估计量样本一致性(MSAC)算法求解平面。MSAC 算法是随机样本一致性(RAN…...

铁路关基保护新规:优先采购安全可信的网络产品和服务!
《征求意见稿》第十四条提到:运营者应当加强供应链安全保护,优先采购安全可信的网络产品和服务;采购网络产品和服务影响或者可能影响国家安全的,运营者应当预判网络产品和服务投入使用后可能带来的国家安全风险,按照国…...

Kafka在大数据处理中的应用
Kafka在大数据处理中的应用 一、Kafka简介1. 基础概念2. Kafka的主要功能3. Kafka的特点 二、应用场景1. 数据采集和消费2. 数据存储和持久化3. 实时数据处理和流计算4. 数据通信和协同 三、技术融合1. Kafka与Hadoop生态技术的融合1) 使用Kafka作为Hadoop的数据源2) 使用Hadoo…...

Linux Day03
一、基础命令(在Linux Day02基础上补充) 1.10 find find 搜索路径 -name 文件名 按文件名字搜索 find 搜索路径 -cmin -n 搜索过去n分钟内修改的文件 find 搜索路径 -ctime -n搜索过去n分钟内修改的文件 1)按文件名字 2)按时间 1.11 grep 在文件中过…...
)
OpenCV 对轮廓进行多边形逼近(Polygon Approximation)
在 OpenCV 中,cv::approxPolyDP 是一个函数,用于对轮廓进行多边形逼近(Polygon Approximation)。它可以将复杂的轮廓逼近为简化的多边形,从而减少轮廓的数据点,使轮廓更加紧凑。 函数原型如下:…...
Docker的数据管理和Dockerfile的指令
Docker的数据管理 一、Docker数据的概念1、数据卷2、数据卷容器 二、端口映射三、容器互联(使用centos镜像)四、Docker 镜像的创建1、基于现有镜像创建(1)首先启动一个镜像,在容器里做修改(2)然…...

[SQL挖掘机] - 交叉连接: cross join
介绍: 交叉连接是一种多表连接方式,它返回两个表的笛卡尔积,即将一个表的每一行与另一个表的每一行进行组合。换句话说,交叉连接会生成一个包含所有可能组合的结果集。 交叉连接的工作原理如下:它会将左表的每一行与右表的每一行…...
Python web实战 | 使用 Django 搭建 Web 应用程序 【干货】
概要 从社交媒体到在线购物,从在线银行到在线医疗,Web 应用程序为人们提供了方便快捷的服务。Web 应用程序已经成为了人们日常生活中不可或缺的一部分。搭建一个高效、稳定、易用的 Web 应用程序并不是一件容易的事情。本文将介绍如何使用 Django 快速搭…...
)
UE5自定义蓝图节点(二)
继承于UBlueprintAsyncActionBase的类,异步输出节点的实现方法,代码测试正常 .h // Fill out your copyright notice in the Description page of Project Settings.#pragma once#include "CoreMinimal.h" #include "Kismet/BlueprintA…...

Bean容器中的ThreadPoolTaskExecutor需要手动关闭吗
ThreadPoolTaskExecutor 是 Spring 提供的一个方便的线程池实现,用于异步执行任务或处理并发请求。 在使用 ThreadPoolTaskExecutor 作为 Spring Bean 注册到容器中后,Spring 会负责在应用程序关闭时自动关闭所有注册的线程池,所以不需要手动…...
——Redis的Java客户端)
Redis学习路线(3)——Redis的Java客户端
一、如何使用Redis的Java客户端 官方文档: https://redis.io/docs/clients/java/ Java-Redis客户端使用场景Jeids 以Redis命令作为方法名称,学习成本低,简单实现,但是Jedis实例是线程不安全的,多线程环境下需要基于连…...
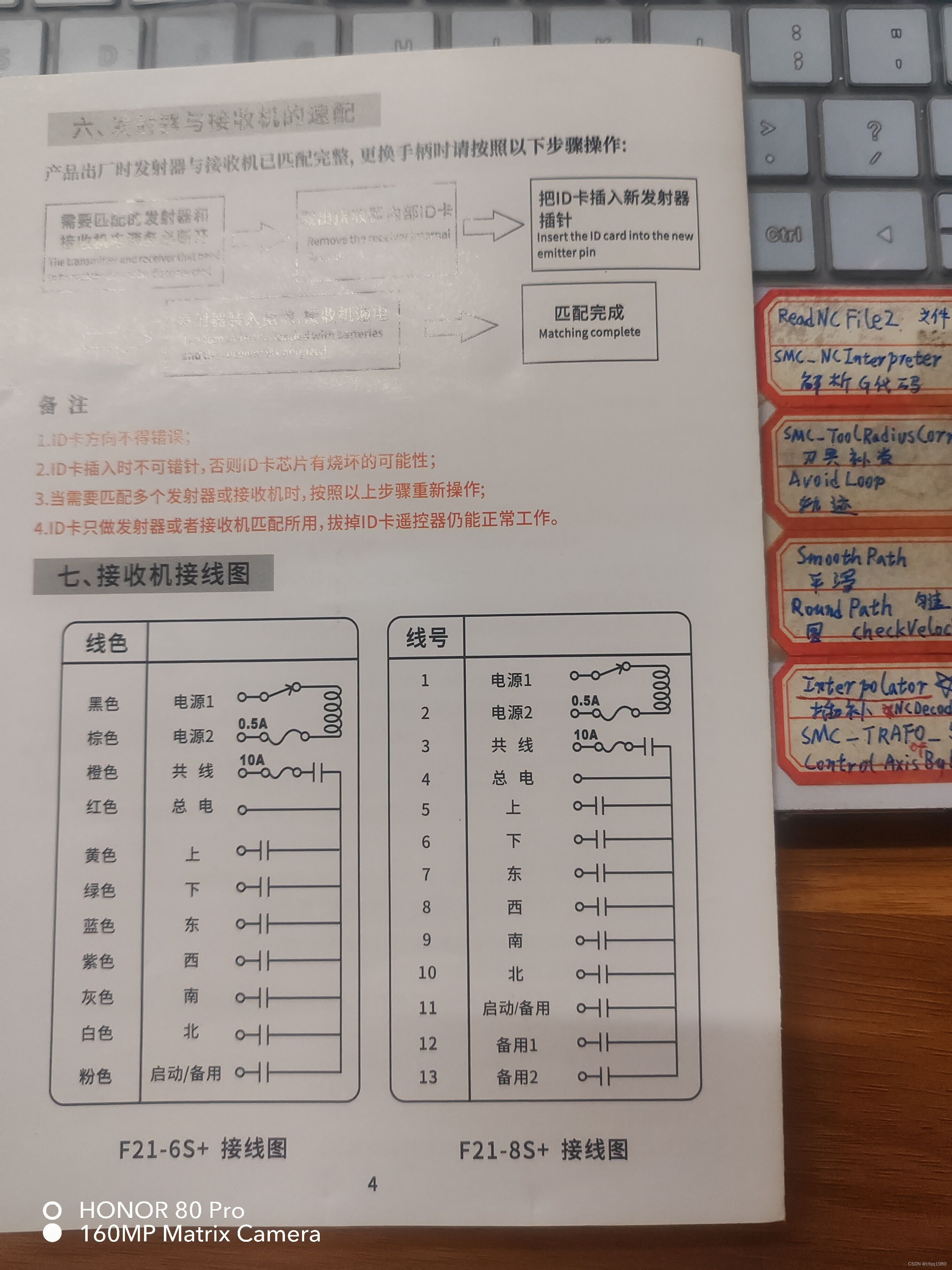
行车遥控接线图
这个一般只有电工才会用。 主要是 【共线和总电】让人疑惑。 这图实际就是PLC的梯形图。 共电:接主电源。【它串联10A保险丝,再到继电器】 总电:它是所有继电器的公共端。【共电的继电器吸合,共电和总电就直通了。】共电的继电器…...

区块链实验室(11) - PBFT耗时与流量特征
以前面仿真程序为例,分析PBFT的耗时与流量特征。实验如下,100个节点构成1个无标度网络,节点最小度为5,最大度为38. 从每个节点发起1次交易共识。统计每次交易的耗时以及流量。本文所述的流量见前述仿真程序的说明:区块链实验室(3)…...
环境变量 位置变量 系统内置变量)
Shell编程基础(三)环境变量 位置变量 系统内置变量
环境变量 & 环境变量环境变量范围父子进程之间有效指定用户有效所有用户有效 位置变量系统内置变量 环境变量 在脚本种直接定义的变量,只能在当前shell进程中使用 若想要在其他shell进程中使用,可以将变量声明为 环境变量 export 变量名 ÿ…...

P5718 【深基4.例2】找最小值
题目描述 给出 n n n 和 n n n 个整数 a i a_i ai,求这 n n n 个整数中最小值是什么。 输入格式 第一行输入一个正整数 n n n,表示数字个数。 第二行输入 n n n 个非负整数,表示 a 1 , a 2 … a n a_1,a_2 \dots a_n a1,a2……...
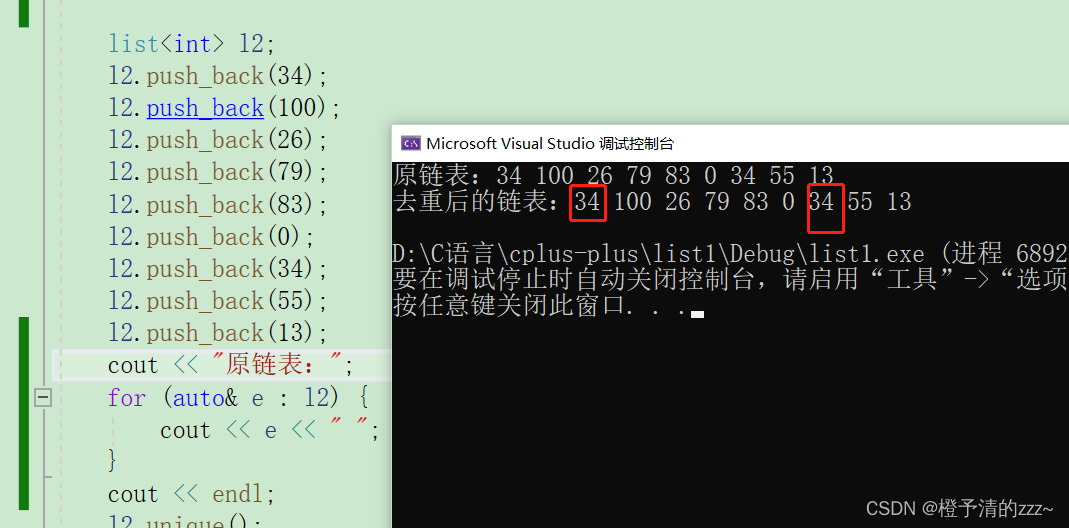
C++——STL容器之list链表的讲解
目录 一.list的介绍 二.list类成员函数的讲解 2.2迭代器 三.添加删除数据: 3.1添加: 3.2删除数据 四.排序及去重函数: 错误案例如下: 方法如下: 一.list的介绍 list列表是序列容器,允许在序列内的任何…...

对称与负电源测试:动态直流电子负载的设计、原理与应用
1. 项目概述:对称与负电源的静态与动态直流负载在电子实验室里,测试一个电源的性能,尤其是它的动态响应能力,是件既基础又关键的事。我们常说的“直流电子负载”就是这个领域的核心工具。我之前设计并分享过一个用于正电源测试的静…...
)
别再只测accuracy!DeepSeek集成测试必须监控的5个隐性指标(P99首token延迟、context bleed率、tool-call schema漂移)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试的核心范式演进 DeepSeek大模型的工程化落地对集成测试提出了全新挑战:传统基于接口响应码与字段校验的测试范式已难以覆盖语义一致性、推理链鲁棒性、上下文敏感度等高阶质…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...

ComfyUI-WD14-Tagger:3分钟实现AI智能图像标签提取,效率提升10倍
ComfyUI-WD14-Tagger:3分钟实现AI智能图像标签提取,效率提升10倍 【免费下载链接】ComfyUI-WD14-Tagger A ComfyUI extension allowing for the interrogation of booru tags from images. 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-WD14-…...

ubuntu环境下为python项目配置taotoken多模型api密钥与端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Ubuntu环境下为Python项目配置Taotoken多模型API密钥与端点 1. 准备工作 在Ubuntu系统上为Python项目接入Taotoken,首…...

ComfyUI-WD14-Tagger:AI智能图像标签提取的终极完整指南
ComfyUI-WD14-Tagger:AI智能图像标签提取的终极完整指南 【免费下载链接】ComfyUI-WD14-Tagger A ComfyUI extension allowing for the interrogation of booru tags from images. 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-WD14-Tagger 在AI图像…...

用Arduino改造TDA7010T FM收音机:数字调谐与自动搜台实战
1. 项目概述:当复古芯片遇上现代微控制器翻出抽屉角落里那个积灰的Kemo B156N套件时,我压根没想到它会变成一个如此有趣的周末项目。这个套件的核心,是一颗来自上世纪八十年代的FM收音机芯片——TDA7010T。当年,它和它的前身TDA70…...

Windows安卓应用安装终极指南:APK Installer让你的电脑变身安卓平台
Windows安卓应用安装终极指南:APK Installer让你的电脑变身安卓平台 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为无法在Windows电脑上直接安装安卓…...

谷歌CEO承认Coding落后了
梦瑶 发自 凹非寺量子位 | 公众号 QbitAI谷歌CEO皮查伊这次真没藏着掖着,直接一个真心话大放送了:在Coding这事儿上,我们家Gemini确实有点了落后哈…..(Gemini:怎么这话还从我自家老板嘴里说出来了呢!&…...

基于ZYNQ MPSoC 在多轴伺服电机驱动器中的架构设计与工程实践
一、引言在工业机器人、数控机床、导弹舵机、相控阵列天线、自动化产线等高精工业场景中,多轴伺服电机独立控制 高精度同步是核心刚需。目前行业主流两种传统方案都存在明显瓶颈:纯 DSP 软件方案:串行中断执行,单 DSP 算力有限&a…...