常用InnoDB参数介绍
常用InnoDB参数介绍
- 1 状态参数
- 1.1 InnoDB 缓冲池状态监控
- 1.1.1 Innodb_buffer_pool_pages_total
- 1.1.2 Innodb_buffer_pool_pages_data
- 1.1.3 Innodb_buffer_pool_bytes_data
- 1.1.4 Innodb_buffer_pool_pages_dirty
- 1.1.5 Innodb_buffer_pool_bytes_dirty
- 1.1.6 Innodb_buffer_pool_pages_free
- 1.1.7 Innodb_buffer_pool_pages_misc
- 1.1.8 Innodb_buffer_pool_pages_flushed
- 1.1.9 Innodb_buffer_pool_read_ahead_rnd
- 1.1.10 Innodb_buffer_pool_read_ahead
- 1.1.11 Innodb_buffer_pool_read_ahead_evicted
- 1.1.12 Innodb_buffer_pool_read_requests
- 1.1.13 Innodb_buffer_pool_reads
- 1.1.14 Innodb_buffer_pool_wait_free
- 1.1.15 Innodb_buffer_pool_write_requests
- 1.2 InnoDB 数据操作状态监控
- 1.2.1 Innodb_data_fsyncs
- 1.2.2 Innodb_data_pending_fsyncs
- 1.2.3 Innodb_data_pending_reads
- 1.2.4 Innodb_data_pending_writes
- 1.2.5 Innodb_data_read
- 1.2.6 Innodb_data_reads
- 1.2.7 Innodb_data_writes
- 1.2.8 Innodb_data_written
- 1.3 InnoDB 双重写缓冲区状态监控
- 1.3.1 双重写缓冲区介绍
- 1.3.2 Innodb_dblwr_pages_written
- 1.3.3 Innodb_dblwr_writes
- 1.4 InnoDB 日志状态监控
- 1.4.1 Innodb_log_waits
- 1.4.2 Innodb_log_write_requests
- 1.4.3 Innodb_log_writes
- 1.4.4 Innodb_os_log_fsyncs
- 1.4.5 Innodb_os_log_pending_fsyncs
- 1.4.6 Innodb_os_log_pending_writes
- 1.4.7 Innodb_os_log_written
- 1.5 InnoDB 行锁状态监控
- 1.5.1 Innodb_row_lock_current_waits
- 1.5.2 Innodb_row_lock_time
- 1.5.3 Innodb_row_lock_time_avg
- 1.5.4 Innodb_row_lock_time_max
- 1.5.5 Innodb_row_lock_waits
- 1.6 InnoDB 数据的 INSERT、UPDATE、SELECT、DELETE 状态监控
- 1.6.1 Innodb_rows_deleted
- 1.6.2 Innodb_rows_inserted
- 1.6.3 Innodb_rows_read
- 1.6.4 Innodb_rows_updated
- 1.7 数据页状态监控
- 1.7.1 Innodb_page_size
- 1.7.2 Innodb_pages_created
- 1.7.3 Innodb_pages_read
- 1.7.4 Innodb_pages_written
- 1.8 其他状态监控
- 1.8.1 Innodb_num_open_files
- 1.8.2 Innodb_truncated_status_writes
- 1.8.3 Innodb_available_undo_logs
- 2 变量参数
- 2.1 自适应刷新和自适应哈希索引
- 2.1.1 innodb_adaptive_flushing
- 2.1.2 innodb_adaptive_flushing_lwm
- 2.1.3 innodb_adaptive_hash_index
- 2.1.4 innodb_adaptive_hash_index_parts
- 2.1.5 innodb_adaptive_max_sleep_delay
- 2.2 缓冲池参数
- 2.2.1 innodb_buffer_pool_chunk_size
- 2.2.2 innodb_buffer_pool_dump_at_shutdown
- 2.2.3 innodb_buffer_pool_dump_now
- 2.2.4 innodb_buffer_pool_dump_pct
- 2.2.5 innodb_buffer_pool_instances
- 2.2.6 innodb_buffer_pool_load_abort
- 2.2.7 innodb_buffer_pool_load_at_startup
- 2.2.8 innodb_buffer_pool_load_now
- 2.2.9 innodb_buffer_pool_size
- 2.3 磁盘 IO 与读写线程
- 2.3.1 innodb_write_io_threads
- 2.3.2 innodb_read_io_threads
- 2.3.3 innodb_thread_sleep_delay
- 2.3.4 innodb_io_capacity
- 2.3.5 innodb_io_capacity_max
- 2.4 其他参数
- 2.4.1 innodb_flush_log_at_trx_commit
1 状态参数
1.1 InnoDB 缓冲池状态监控
1.1.1 Innodb_buffer_pool_pages_total
这个变量表示整个 InnoDB 缓冲池的页数。
缓冲池是 InnoDB 存储引擎用于缓存数据和索引页的地方。增加缓冲池的大小可以提高对热数据的访问速度,从而提高整体的性能。
通过观察这个变量的值,你可以了解当前配置的 InnoDB 缓冲池的页数。通常情况下,你希望这个值足够大,以便缓存尽可能多的数据和索引页,但又不能过大,以免占用过多的内存资源。
1.1.2 Innodb_buffer_pool_pages_data
这个状态表示已经分配出去,正在被使用页的数量,包括脏页,单位是page。
1.1.3 Innodb_buffer_pool_bytes_data
这个状态表示 InnoDB 缓冲池当前占用的字节数。
此系统变量可以用来了解 InnoDB 缓冲池中当前使用的数据页的占用情况。它可以帮助你监视和调整 InnoDB 缓冲池的大小,以确保适当的分配内存并优化数据库性能。
1.1.4 Innodb_buffer_pool_pages_dirty
这个状态表示脏页但没有被flush除去的页面数。单位是page。
此系统变量可以帮助你了解缓冲池中的脏数据页数量。脏页的增加可能表示有大量修改操作正在进行,但尚未被写入到磁盘。
高脏页数量可能会影响性能和系统的稳定性,因此需要确保适当地进行脏页的刷新和写回操作。
1.1.5 Innodb_buffer_pool_bytes_dirty
这个状态表示 InnoDB 缓冲池中脏页占用的字节数。
使用该值可以帮助你监控和调整 InnoDB 缓冲池的大小,以确保适当分配内存并优化数据库性能。
较小的脏页占用可以减少磁盘写入压力,并提高系统的响应能力。
1.1.6 Innodb_buffer_pool_pages_free
这个状态表示 InnoDB 缓冲池中当前可用的空闲页数。
缓冲池是用于缓存数据和索引的内存区域,如果有足够的空闲页,可以更快地存取数据而不需要从磁盘读取。
通过观察这个变量的值,你可以了解缓冲池中还有多少可用的空闲页。如果空闲页数较少,可能表示缓冲池的容量不足,需要考虑增加缓冲池的大小来提高性能。如果空闲页数较多,可能表示缓冲池大小超过了实际需要的范围,可以适当减小缓冲池的大小以释放内存资源。
1.1.7 Innodb_buffer_pool_pages_misc
这个状态表示缓冲池中不属于数据和索引页的其他页数,如内部数据结构、锁信息以及其他元数据所占用的页数。
通过观察这个变量的值,你可以了解缓冲池中用于其他目的的页数。如果这个值较高,可能表示某些操作或特定的工作负载正在使用大量的额外内存。
1.1.8 Innodb_buffer_pool_pages_flushed
这个状态表示自启动或上次重置以来已刷新到磁盘的 InnoDB 缓冲池脏页数。
通过观察这个变量的变化,你可以了解到 InnoDB 缓冲池页的刷新频率。如果该值较高,可能表示有大量的写操作或者缓冲池的容量不足。反之,如果该值过低,可能表示有大量的脏数据滞留在缓冲池中未写入磁盘。
1.1.9 Innodb_buffer_pool_read_ahead_rnd
这个变量表示从磁盘读取数据时,在 InnoDB 缓冲池中预取的随机读块数。
当 InnoDB 发现一系列的随机读操作时,它会尝试预取相邻的块,以提高读取性能。
通过观察这个变量的值,可以了解到当前有多少次随机读操作触发了预取操作。较高的值意味着系统可能存在较多的随机读操作,并且 InnoDB 正在尝试通过预取操作来优化读取性能。
1.1.10 Innodb_buffer_pool_read_ahead
这个变量表示从磁盘读取数据时,在 InnoDB 缓冲池中预取的读块数。
当 InnoDB 预见到将来可能会使用的数据块时,它会提前将这些数据块加载到缓冲池中,以便后续的读操作可以更快地完成。
通过观察这个变量的值,你可以了解到当前有多少次读操作触发了预取操作。较高的值意味着系统可能存在较多的读操作,并且 InnoDB 正在尝试通过预取操作来优化读取性能。
1.1.11 Innodb_buffer_pool_read_ahead_evicted
这个表示行预取操作的过程中,由于内存空间不足或其他原因,一些预取的数据块被驱逐出缓冲池的次数。InnoDB 缓冲池空间有限并且无法容纳所有的预取数据块时,就会发生驱逐操作。通过观察这个变量的值,你可以了解到在预取操作中有多少次发生了数据块被驱逐的情况。较高的值可能意味着缓冲池的大小不足或者预取操作设置不合理,导致频繁的数据块驱逐。
1.1.12 Innodb_buffer_pool_read_requests
这个变量表示从 InnoDB 缓冲池中读取数据的请求数量。
当查询需要读取数据时,InnoDB 首先会尝试从缓冲池中获取所需的数据,这样可以避免从磁盘读取数据,从而提供更快的响应时间。这个变量记录了从缓冲池中成功读取数据的请求数量。
通过观察这个变量的值,你可以了解到在一段时间内有多少次查询能够从缓冲池中获取到所需的数据,即命中缓冲池的次数。
1.1.13 Innodb_buffer_pool_reads
这个变量表示从磁盘读取数据到 InnoDB 缓冲池的次数。
当查询需要读取数据时,如果数据在缓冲池中不存在,InnoDB 就需要从磁盘读取相应的数据块到缓冲池中,使其可供后续查询使用。这个变量记录了这个过程发生的次数。
较低的 Innodb_buffer_pool_reads 值意味着大部分查询所需的数据块都能够从缓冲池中获取,这说明缓冲池的命中率较高,系统的性能较好。相反,较高的 Innodb_buffer_pool_reads 值可能意味着缓冲池较小或者查询访问的数据集大于缓冲池的容量,导致频繁从磁盘中读取数据,这可能会影响系统的性能。
如果 Innodb_buffer_pool_reads 值较高,你可以考虑增加 InnoDB 缓冲池的大小,以减少从磁盘读取数据的次数,提高查询响应速度。
1.1.14 Innodb_buffer_pool_wait_free
这个变量表示需要等待 InnoDB 缓冲池的空闲页面的次数。
当查询需要从磁盘读取数据块到缓冲池中时,如果缓冲池没有足够的空闲页面来容纳这些数据块,查询就需要等待,直到有足够的空闲页面可用为止。此时, Innodb_buffer_pool_wait_free 就会增加。
通过观察这个变量的值,你可以了解到在一段时间内有多少次查询需要等待空闲缓冲池页面。较低的 Innodb_buffer_pool_wait_free 值意味着缓冲池中很少发生页面等待的情况,这表明缓冲池的大小可能足够大,并且能够容纳大部分查询的数据块需求。相反,较高的 Innodb_buffer_pool_wait_free 值可能意味着缓冲池较小,无法满足查询所需的空闲页面,导致查询需要等待。
如果你发现 Innodb_buffer_pool_wait_free 值较高,你可以考虑增加 InnoDB 缓冲池的大小,以减少页面等待的次数,提高查询的响应速度。
1.1.15 Innodb_buffer_pool_write_requests
这个变量表示请求将数据写入 InnoDB 缓冲池的次数。
当插入、更新或删除数据时,InnoDB 引擎会首先将数据写入缓冲池中的数据页(buffer pool pages)。只有当数据页被修改后,才会将其刷新到磁盘上的数据文件。这个变量记录了每次写请求对缓冲池的操作,而不是实际将数据写入磁盘的次数。
通过观察这个变量的值,你可以了解到在一段时间内有多少次写请求被发送到了缓冲池。较高的 Innodb_buffer_pool_write_requests 值通常意味着大部分的写操作都在缓冲池中完成,减少了对磁盘的直接写入,从而提高数据库的性能。
1.2 InnoDB 数据操作状态监控
1.2.1 Innodb_data_fsyncs
这个变量表示执行 InnoDB 的数据页的数据文件同步到磁盘的操作次数。
数据文件同步操作是指将缓冲池中的数据页(buffer pool pages)写入到磁盘上的数据文件。在事务提交或页面脏数据刷新时,会执行数据文件同步操作,以确保数据的持久性和一致性。
这个变量的值可以用于评估数据库的写入负载和磁盘 IO 的使用情况。较高的值通常意味着有较频繁的数据文件同步操作,可能是因为有很多事务提交或者缓冲池中的数据页被刷新到磁盘。需要注意的是,高并发的写入操作和大量的事务提交可能导致 Innodb_data_fsyncs 增加。
可以通过调整 InnoDB 相关的参数,如调整事务的提交频率、调整缓冲池大小等来优化性能和减少数据文件同步操作的频率。
1.2.2 Innodb_data_pending_fsyncs
这个变量表示正在等待执行数据页写入磁盘的数据文件同步操作的数量。
当 InnoDB 需要将数据页写入到磁盘上的数据文件时,可能会由于磁盘 IO 限制或其他原因而导致同步操作被延迟。这些延迟的同步操作被记录在这个变量中。通过观察这个变量的值,你可以了解当前有多少个数据文件同步操作正在等待执行。
较高的 Innodb_data_pending_fsyncs 值可能表明磁盘 IO 限制或其他性能问题,可能需要优化数据库的配置或磁盘子系统。
需要注意的是,Innodb_data_pending_fsyncs 变量值的增加并不一定意味着性能问题,而是表示有一些同步操作正在等待执行。
1.2.3 Innodb_data_pending_reads
这个变量表示当前正在等待执行的磁盘数据页文件读取到缓冲池操作的数量。
当 InnoDB 需要从磁盘上的数据文件读取数据到缓冲池时,可能会由于磁盘 IO 限制或其他原因而导致读取操作被延迟。这些延迟的读取操作被记录在 Innodb_data_pending_reads 变量中。
通过观察这个变量的值,你可以了解当前有多少个数据文件读取操作正在等待执行。较高的 Innodb_data_pending_reads 值可能表明磁盘 IO 限制或其他性能问题,可能需要优化数据库的配置或磁盘子系统。
需要注意的是,Innodb_data_pending_reads 变量值的增加并不一定意味着性能问题,而是表示有一些读取操作正在等待执行。
1.2.4 Innodb_data_pending_writes
这个变量表示当前正在等待执行的数据文件从缓冲池数据页写入磁盘操作的数量。
当 InnoDB 需要将数据页写入到磁盘上的数据文件时,可能会由于磁盘 IO 限制或其他原因而导致写入操作被延迟。这些延迟的写入操作被记录在 Innodb_data_pending_writes 变量中。
通过观察这个变量的值,你可以了解当前有多少个数据文件写入操作正在等待执行。较高的 Innodb_data_pending_writes 值可能表明磁盘 IO 限制或其他性能问题,可能需要优化数据库的配置或磁盘子系统。
需要注意的是,Innodb_data_pending_writes 变量值的增加并不一定意味着性能问题,而是表示有一些写入操作正在等待执行。
1.2.5 Innodb_data_read
这个变量表示自启动以来从磁盘读取到内存的 InnoDB 数据量,以字节(bytes)为单位。
这包括数据文件、索引文件、重做日志等。通过观察这个变量的值,你可以了解到目前为止从磁盘读取到内存的数据量。这对于监控数据库的读取活动和评估性能很有帮助。
1.2.6 Innodb_data_reads
这个变量表示自启动以来从磁盘读取到内存的 InnoDB 数据页数量。
一个数据页通常是16KB大小,InnoDB 数据文件被划分为许多数据页。当需要读取数据页时,InnoDB 将它们从磁盘读取到内存,以供后续查询和操作使用。
通过观察这个变量的值,你可以了解到目前为止从磁盘读取到内存的数据页数量。这对于监控数据库的读取活动和评估性能很有帮助。
1.2.7 Innodb_data_writes
这个变量表示自启动以来从内存写入磁盘的 InnoDB 数据页数量。
当对数据进行修改时,InnoDB 将修改的数据页写回磁盘,以保持数据的持久性。
通过观察这个变量的值,你可以了解到目前为止从内存写入磁盘的数据页数量。这对于监控数据库的写入活动和评估性能很有帮助。
1.2.8 Innodb_data_written
这个变量表示自启动以来从内存写入到磁盘的 InnoDB 数据量,以字节(bytes)为单位。
它统计了所有数据的写入操作,包括数据页的修改、事务的提交等。
通过观察这个变量的值,你可以了解到目前为止从内存写入磁盘的数据量。这对于监控数据库的写入活动、评估磁盘使用和性能很有帮助。
1.3 InnoDB 双重写缓冲区状态监控
1.3.1 双重写缓冲区介绍
双重写缓冲区是 InnoDB 存储引擎的一项关键技术,用于提高数据的持久性和可靠性。当数据页从内存写入到磁盘时,首先会被写入到双重写缓冲区,然后再写入到磁盘的数据文件中。如果发生故障或写入中断,双重写缓冲区可以帮助恢复数据的一致性。
1.3.2 Innodb_dblwr_pages_written
这个状态表示自启动以来写入到双重写缓冲区的 InnoDB 数据页数量。
这个变量的增加表示有新的数据页被写入到双重写缓冲区。通过观察这个变量的值,你可以了解到目前为止写入到双重写缓冲区的数据页数量。这对于了解双重写缓冲区的使用情况和评估可靠性很有帮助。
1.3.3 Innodb_dblwr_writes
这个变量表示自启动以来从双重写缓冲区写入磁盘的操作次数。
每次成功写入一个数据页到磁盘,该变量的值就会增加。
通过观察这个变量的值,你可以了解到目前为止从双重写缓冲区写入磁盘的操作次数。这对于了解双重写缓冲区的使用情况、评估可靠性以及监控写入活动很有帮助。
1.4 InnoDB 日志状态监控
InnoDB 存储引擎使用 redo log 来确保数据的持久性和一致性。在每次提交事务时,日志缓冲区中的日志条目会被刷新到磁盘的日志文件中。
1.4.1 Innodb_log_waits
这个变量表示自启动以来发生的等待日志刷新的次数。当日志缓冲区空间不足或者日志文件写入速度低于事务提交速度时,会发生日志刷新等待。每次发生等待时,该变量的值就会增加。
1.4.2 Innodb_log_write_requests
这个变量表示自启动以来请求 InnoDB 日志写入操作的次数。每次发出日志写入请求时,该变量的值就会增加。
1.4.3 Innodb_log_writes
这个变量表示自启动以来执行的 InnoDB 日志写入操作的次数。每次成功地将日志写入到磁盘时,该变量的值就会增加。
1.4.4 Innodb_os_log_fsyncs
这个变量表示自启动以来执行的 InnoDB 日志文件同步到磁盘操作的次数。每次成功执行日志同步操作时,该变量的值就会增加。
1.4.5 Innodb_os_log_pending_fsyncs
这个变量表示当前待处理的 InnoDB 日志文件同步到磁盘操作的数量。该变量的值反映了尚未完成的日志同步操作数量。
1.4.6 Innodb_os_log_pending_writes
这个变量表示当前待处理的 InnoDB 日志写入操作的数量。该变量的值反映了尚未完成的日志写入操作数量。
1.4.7 Innodb_os_log_written
这个变量表示自启动以来从 InnoDB 存储引擎写入到磁盘的日志文件的总字节数。这个值可以用来评估系统的日志写入负载以及磁盘的使用情况。
1.5 InnoDB 行锁状态监控
1.5.1 Innodb_row_lock_current_waits
这个状态表示当前正在等待行锁的数量。当多个事务同时尝试获取相同的行锁时,除了一个事务能够成功获取锁外,其他的事务都需要等待锁的释放。Innodb_row_lock_current_waits 就是表示当前正在等待锁的事务数量。
1.5.2 Innodb_row_lock_time
这个状态表示自启动以来 InnoDB 存储引擎等待行锁的总时间。
1.5.3 Innodb_row_lock_time_avg
这个状态表示自启动以来每次等待行锁所平均花费的时间。它通过将累计的行锁等待时间除以行锁等待次数来计算得出。
1.5.4 Innodb_row_lock_time_max
这个参数表示自启动以来 InnoDB 存储引擎等待行锁的最长时间。当某个事务等待行锁时,如果等待的时间超过了设定的超时时间(通常是由 innodb_lock_wait_timeout 参数指定),则该事务会被取消,并返回相应的错误消息。
1.5.5 Innodb_row_lock_waits
这个参数表示自启动以来 InnoDB 存储引擎等待行锁的次数。每当一个事务由于锁竞争而被阻塞时,就会增加这个计数器。
1.6 InnoDB 数据的 INSERT、UPDATE、SELECT、DELETE 状态监控
1.6.1 Innodb_rows_deleted
这个状态表示自启动以来 InnoDB 存储引擎删除的行数。当你执行 DELETE 语句或在具有外键约束的表中执行更新操作时,InnoDB 存储引擎会删除相关的行,并将删除行数累加到 Innodb_rows_deleted 中。
1.6.2 Innodb_rows_inserted
这个状态表示自启动以来 InnoDB 存储引擎插入的行数。当你执行 INSERT 语句或将新行插入具有自增主键的表时,InnoDB 存储引擎会将插入的行数累加到 Innodb_rows_inserted 中。
1.6.3 Innodb_rows_read
这个状态表示自启动以来 InnoDB 存储引擎读取的行数。当你执行 SELECT 语句或其他查询操作时,InnoDB 存储引擎会读取相应的行,并将读取的行数累加到 Innodb_rows_read 中。
1.6.4 Innodb_rows_updated
这个状态表示自启动以来 InnoDB 存储引擎更新的行数。当你执行 UPDATE 语句或其他修改数据的操作时,InnoDB 存储引擎会对相应的行进行更新,并将更新的行数累加到 Innodb_rows_updated 中。
1.7 数据页状态监控
1.7.1 Innodb_page_size
这个状态表示 InnoDB 存储引擎使用的页大小。InnoDB 存储引擎将数据存储在固定大小的页中。每个页的大小会对存储引擎的性能和存储占用产生影响。
1.7.2 Innodb_pages_created
这个状态表示自启动以来 InnoDB 存储引擎创建的页的数量。InnoDB 使用固定大小的页来存储表数据和索引。创建新的页是在数据库中插入新数据或者增加索引时发生的。
1.7.3 Innodb_pages_read
这个状态表示自启动以来 InnoDB 存储引擎读取的页的数量。InnoDB 存储引擎会根据查询需求从数据文件中读取页来获取数据。每当读取一个页时,Innodb_pages_read 的值就会增加。
1.7.4 Innodb_pages_written
这个状态表示自启动以来 InnoDB 存储引擎写入的页的数量。当数据被修改并需要将其持久化到磁盘时,InnoDB 将修改的数据页写入到数据文件中。每当写入一个页时,Innodb_pages_written 的值就会增加。
1.8 其他状态监控
1.8.1 Innodb_num_open_files
这个状态表示当前在 InnoDB 存储引擎中打开的文件数量。这包括 InnoDB 数据文件、日志文件、临时文件等。
1.8.2 Innodb_truncated_status_writes
这个状态是 InnoDB 存储引擎的一个计数器,用于表示在为了保持系统状态文件的一致性而截断的状态写入数量。
当 InnoDB 存储引擎执行系统状态写入时,它会在写入完成之前进行缓冲。为了保持一致性,当发生重要操作(如崩溃恢复或完全关闭)时,引擎可能会截断已缓冲的状态写入。
Innodb_truncated_status_writes 计数器记录了被截断的状态写入的数量。通过监视该计数器的值,可以了解到数据库发生了多少次系统状态写入的截断。
1.8.3 Innodb_available_undo_logs
这个状态用于指定 InnoDB 存储引擎可用的撤消日志的数量。撤消日志(Undo Log)是 InnoDB 存储引擎用于实现事务的特性之一。它记录了事务对数据库所做的修改,以便在需要回滚事务或恢复数据库时使用。
2 变量参数
2.1 自适应刷新和自适应哈希索引
2.1.1 innodb_adaptive_flushing
这个参数是一个用于配置 InnoDB 存储引擎的参数,用于控制自适应刷新的行为。自适应刷新是一种机制,它可以根据系统负载和性能需求来自动调整 InnoDB 存储引擎的刷新策略。刷新指的是将内存中的数据写入磁盘,以确保数据持久化。
当 innodb_adaptive_flushing 参数值为 ON 时,InnoDB 会根据系统负载和性能需求来自动调整刷新策略。它会根据以下因素动态调整刷新频率:
1. 系统 IO 活动的水平
2. 数据库缓冲池的空闲比例
3. 预期的磁盘写入速度
4. 预期的磁盘写入延迟
自适应刷新可以提高数据库性能,并提供更好的吞吐量。它会根据当前的系统状态对刷新频率进行智能调整,以避免过度刷新或不足刷新。
默认情况下,innodb_adaptive_flushing 参数的值是 ON,即启用自适应刷新。可以通过如下命令修改这个参数为OFF。
-- 关闭自适应刷新
set global innodb_adaptive_flushing = 0;
-- 打开自适应刷新
set global innodb_adaptive_flushing = 1;
2.1.2 innodb_adaptive_flushing_lwm
这个参数用于配置自适应刷新的低水位线。
自适应刷新通过动态调整刷新策略来优化数据库性能。innodb_adaptive_flushing_lwm 参数定义了一个低水位线,表示当脏页的比例低于这个水位线时,自适应刷新会降低刷新频率以减少磁盘写入操作。
脏页是指内存中已被更改但尚未写入磁盘的页。当脏页的比例超过 innodb_adaptive_flushing_lwm 参数定义的低水位线时,自适应刷新会增加刷新频率以确保数据持久化。
默认情况下,innodb_adaptive_flushing_lwm 参数的值是 10(表示10%脏页比例)。这意味着当脏页的比例低于10%时,自适应刷新会降低刷新频率。你可以根据你的需求调整该参数的值。
调整 innodb_adaptive_flushing_lwm 参数的值可能会影响数据库的性能和写入延迟。较高的水位线可能导致更频繁的刷新操作,从而增加写入延迟。较低的水位线可能减少刷新操作,但可能会增加数据持久性的风险。
-- 调整自适应刷新低水位线为20%
set global innodb_adaptive_flushing_lwm = 20;
2.1.3 innodb_adaptive_hash_index
这个参数它用于控制 InnoDB 自适应哈希索引的使用。
InnoDB 的自适应哈希索引是一种数据结构,用于加速表的索引访问。它在内存中构建一个哈希索引,以提供更高效的读取操作。这个哈希索引是基于表的辅助索引或主键索引,而不是所有的索引。
当 innodb_adaptive_hash_index 参数值为 ON 时,InnoDB 会启用自适应哈希索引功能,并且尝试在内存中构建适当的哈希索引。这可以加速对表的索引访问,特别是对于访问频率高的小范围查询。
当 innodb_adaptive_hash_index 参数值为 OFF 时,禁用自适应哈希索引功能。这意味着 InnoDB 将不会在内存中构建哈希索引,而仅依赖于 B+ 树索引结构来处理索引访问。
默认情况下,innodb_adaptive_hash_index 参数的值为 ON,即启用自适应哈希索引。但是,在某些情况下,禁用自适应哈希索引可能会提供更好的性能,特别是对于具有大量写入操作或表数据变动频繁的情况。
-- 禁用自适应哈希索引
set global innodb_adaptive_hash_index = 0;
-- 启用自适应哈希索引
set global innodb_adaptive_hash_index = 1;
2.1.4 innodb_adaptive_hash_index_parts
这个参数用于控制自适应哈希索引分区的数量。
InnoDB 的自适应哈希索引使用一个哈希表结构,将索引数据存储在内存中以提高查询性能。为了优化内存使用和索引查询速度,自适应哈希索引会将数据分割成多个分区。每个分区都会有自己的哈希表。
innodb_adaptive_hash_index_parts 参数定义了自适应哈希索引使用的分区数量。默认情况下,该参数的值是 8,表示会将自适应哈希索引分成 8 个分区。
增加分区的数量可以改善并发查询的性能,因为查询可以并行访问多个索引分区。然而,较多的分区可能会占用更多的内存空间。因此,根据你的实际应用和硬件资源,你可以根据需要调整 innodb_adaptive_hash_index_parts 的值。
这个参数要修改的话需要修改my.cf配置文件然后重启服务生效。
2.1.5 innodb_adaptive_max_sleep_delay
这个参数用于控制自适应哈希索引调整的最大睡眠延迟。
自适应哈希索引调整是指 InnoDB 在运行时根据查询的模式和数据访问模式来动态地调整自适应哈希索引结构。为了避免频繁地修改哈希索引结构,InnoDB 引入了睡眠延迟机制。当需要进行调整时,引擎会等待一段时间,这段时间就是睡眠延迟。
innodb_adaptive_max_sleep_delay 参数用于限制自适应哈希索引调整的最大睡眠延迟。它定义了 InnoDB 引擎在进行调整时最长的等待时间。如果调整过程需要的时间超过了这个值,引擎将会在达到最大睡眠延迟后继续执行。
默认情况下,innodb_adaptive_max_sleep_delay 的值为 150000,单位是微秒。也就是说,InnoDB 引擎最多会等待 0.15 秒来进行自适应哈希索引的调整。你可以根据自己的需求和工作负载的特点来调整这个值。
增加 innodb_adaptive_max_sleep_delay 的值可以降低自适应哈希索引调整的频率,减少不必要的开销。但同时,如果设置得太大,可能会导致索引结构在变化时对查询性能产生较长时间的不稳定。
-- 调整最大睡眠延迟
set global innodb_adaptive_max_sleep_delay = 150000;
2.2 缓冲池参数
InnoDB 缓冲池是 InnoDB 存储引擎中用于缓存数据和索引的内存区域。它通过将数据页划分为固定大小的块(默认为16KB),以便更有效地管理内存和数据的读写。
InnoDB 缓冲池是一个位于内存中的缓存区域,用于存储数据库表和索引的数据。当查询需要读取或修改表中的数据时,InnoDB 存储引擎首先会检查缓冲池中是否已经存在相应的数据页,如果存在,则能够快速完成操作,而不需要访问磁盘。
2.2.1 innodb_buffer_pool_chunk_size
这个参数用于控制 InnoDB 缓冲池的分块大小。每个块都是一块连续的内存,用于存储一个或多个数据页。这个参数的默认值是 128MB。
调整 innodb_buffer_pool_chunk_size 的值可能会对系统性能产生一定的影响。较小的块大小可以使 InnoDB 缓冲池更紧凑,减少内存碎片,从而更有效地利用内存。然而,较小的块大小也会导致更多的内存分配和管理开销。
相反,较大的块大小可以减少内存分配和管理的开销,但会增加内存碎片的可能性。此外,更大的块大小对于大型数据库系统可能更具优势,因为它可以减少锁争用和减少内存页的访问次数。
要调整 innodb_buffer_pool_chunk_size 的值,你需要在配置文件中指定它,并重启 MySQL 服务器才能生效。
2.2.2 innodb_buffer_pool_dump_at_shutdown
这个参数用于控制 MySQL 服务器在关闭时是否将 InnoDB 缓冲池的内容转储到磁盘。
当设置为 ON(默认值)时,MySQL 在关闭时会将 InnoDB 缓冲池中的数据页转储到磁盘的共享表空间文件 。这样,在下次启动 MySQL 时,可以通过加载这些转储文件来恢复 InnoDB 缓冲池中的数据页,从而减少系统启动时间。
当设置为 OFF 时,MySQL 在关闭时不会执行这样的转储操作。
根据系统的需求和运行状况,你可以根据业务和性能考虑来选择是否启用 innodb_buffer_pool_dump_at_shutdown 参数。如果你的系统对于启动时间非常敏感,你可能希望启用此参数以减少启动时间。然而,如果你的系统在启动时已经具有较好的性能,你可以考虑禁用此参数以避免不必要的磁盘写入和额外的系统开销。
要更改 innodb_buffer_pool_dump_at_shutdown 参数的值,你需要编辑配置文件,将其设置为所需的值,并重启 MySQL 服务器才能生效。
2.2.3 innodb_buffer_pool_dump_now
这个参数使用它来立即将 InnoDB 缓冲池的内容转储到磁盘。默认情况下禁用此功能。
-- 立即将 InnoDB 缓冲池的内容转储到磁盘
SET GLOBAL innodb_buffer_pool_dump_now = 1;
-- 禁用此功能
SET GLOBAL innodb_buffer_pool_dump_now = 0;
2.2.4 innodb_buffer_pool_dump_pct
这个参数用于控制在 MySQL 服务器关闭时,将缓冲池内容转储到磁盘的百分比。
该参数的默认值是 25,表示在关闭服务器时,将最多转储缓冲池内容的 25%。这个百分比可以通过配置文件或动态修改来调整。
例如,如果你希望在关闭服务器时转储更多的缓冲池内容,你可以将 innodb_buffer_pool_dump_pct 值设置为更高的百分比,例如 50。这样可以确保更多的数据被转储到磁盘,但同时也会增加关闭时间和资源消耗。
在使用 innodb_buffer_pool_dump_pct 参数时,需要注意以下几点:
1. 这个参数只影响在 MySQL 服务器关闭时的转储操作,而不影响其他时刻的转储行为。
2. 较高的转储百分比会增加关闭时间,并且可能对服务器性能产生一定的影响。因此,在调整该值时,要权衡转储需要和服务器关闭时间之间的关系,并根据具体情况选择合适的百分比。
3. 转储到磁盘的数据可以在下次启动 MySQL 服务器时被重新加载到缓冲池中,从而提高读取性能。
2.2.5 innodb_buffer_pool_instances
这个参数用于指定缓冲池(buffer pool)的实例数量。
缓冲池是 InnoDB 存储引擎用于缓存数据和索引的关键组件之一。通过将缓冲池分成多个实例,可以提高并发访问性能,并降低锁竞争。
默认情况下,innodb_buffer_pool_instances 的值为 1,这意味着缓冲池会被分成 1 个独立的实例。但是,这个值也可以根据你的系统配置和需求进行调整。
当你调整 innodb_buffer_pool_instances 时,你需要考虑以下几点:
1. 内存分配:每个缓冲池实例都需要占用一定的内存。因此,你的系统需要有足够的可用内存来容纳所有实例。通常情况下,可以根据服务器的总内存量和其他内存需求来合理设置缓冲池实例的数量。
2. 并发性能:增加缓冲池实例的数量有助于提高并发访问性能。对于较大、高并发的数据库服务器,将 innodb_buffer_pool_instances 增加到更高的值可能会获得更好的性能。
3. 锁竞争:缓冲池实例的增加也会增加锁竞争的可能性。如果你的系统在高并发负载下经常出现锁竞争问题,你可能需要减少缓冲池实例的数量,或者采取其他调整措施来缓解锁竞争。
要更改 innodb_buffer_pool_instances 参数的值,你需要编辑配置文件,将其设置为所需的值,并重启 MySQL 服务器才能生效。
2.2.6 innodb_buffer_pool_load_abort
这个参数用于控制在加载缓冲池数据时的中止行为。
当 MySQL 服务器启动时,InnoDB 存储引擎会尝试加载之前转储到磁盘的缓冲池数据。这个过程可以帮助提高系统的启动性能,因为数据可以直接从磁盘加载到内存中的缓冲池,而不需要重新读取磁盘上的数据文件。
innodb_buffer_pool_load_abort 参数的默认值为 0,表示加载缓冲池数据的操作不会被中止。然而,你可以将该参数的值设置为非零数值以启用加载过程的中止。
当 innodb_buffer_pool_load_abort 的值大于 0 时,如果加载缓冲池数据的操作耗时超过指定的时间(单位为秒),系统会中止这个操作。这样可以防止加载操作持续过久,从而影响服务器启动时间。
需要注意的是,在某些情况下,加载缓冲池数据可能需要一定的时间,特别是当缓冲池的大小很大或者磁盘性能较低时。所以在设置 innodb_buffer_pool_load_abort 参数时,需要根据具体情况权衡加载时间和服务器启动的时间。
如果你希望在服务器启动时尽可能加载完整的缓冲池数据,可以将 innodb_buffer_pool_load_abort 参数设置为较大的值,或者将其设置为 0 以禁用中止行为。
set global innodb_buffer_pool_load_abort = 0;
2.2.7 innodb_buffer_pool_load_at_startup
这个参数用于控制服务器启动时是否加载缓冲池中的数据。
当 MySQL 服务器进行启动时,InnoDB 存储引擎默认会尝试加载之前转储到磁盘的缓冲池数据。这个过程可以帮助提高系统的启动性能,因为数据可以直接从磁盘加载到内存中的缓冲池,而不需要重新读取磁盘上的数据文件。
innodb_buffer_pool_load_at_startup 参数的默认值为 1,表示在服务器启动时加载缓冲池数据。设置为 0 则表示不加载缓冲池数据。
如果你不希望在服务器启动时加载缓冲池数据,可以将 innodb_buffer_pool_load_at_startup 参数设置为 0。
需要注意的是,如果你禁用了缓冲池数据的加载,那么服务器启动后第一次对表的查询可能会更加缓慢,因为它需要从磁盘读取数据。然而,随着服务器正常运行,缓冲池会自动填充数据,并提高查询性能。
2.2.8 innodb_buffer_pool_load_now
如果服务启动没有加载缓冲池中的数据,可以通过如下的命令设置手动加载缓冲池中的数据。这个参数将触发 InnoDB 存储引擎立即尝试加载缓冲池数据。请注意,该操作可能需要一些时间,具体时间取决于缓冲池的大小和磁盘性能。
SET GLOBAL innodb_buffer_pool_load_now = 1;
2.2.9 innodb_buffer_pool_size
这个参数用于设置 InnoDB 缓冲池的大小。
innodb_buffer_pool_size 参数的单位是字节,默认值根据不同的 MySQL 版本和配置而有所不同。通常建议根据系统的可用内存设置合适的缓冲池大小。较大的缓冲池能够减少对磁盘的 I/O 操作,提高查询性能。可以通过如下命令设置缓冲池的大小。
对于大部分表都是InnoDB的数据库来说,如果服务器只安装了数据库,推荐设置为内存的60%。
set global innodb_buffer_pool_size = 134217728;
2.3 磁盘 IO 与读写线程
2.3.1 innodb_write_io_threads
这个参数用于指定用于处理写入IO操作的线程数量。
在 InnoDB 存储引擎中,写入IO 操作包括将数据页刷新到磁盘和执行日志写入等任务。通过使用多个线程来处理并发的写入 IO 操作,可以提高系统的吞吐量和性能。
innodb_write_io_threads 参数用于指定写入 IO 线程的数量。默认情况下,innodb_write_io_threads 的值为 4。您可以根据系统需求和负载情况来调整这个值。
在调整 innodb_write_io_threads 参数时,请考虑以下因素:
1. 系统的负载情况和磁盘性能。
2. 写入IO操作的并发性和吞吐量需求。
3. 其他 InnoDB 参数的相互影响和整体系统性能。
要更改 innodb_write_io_threads 参数的值,你需要编辑配置文件,将其设置为所需的值,并重启 MySQL 服务器才能生效。
2.3.2 innodb_read_io_threads
这个参数用于控制并行读取 I/O 操作的线程数量。
在 InnoDB 存储引擎中,读取数据时涉及到的 I/O 操作包括从磁盘读取数据页到内存中。通过增加 innodb_read_io_threads 参数的值,可以增加并行读取的线程数量,从而提高读取操作的性能。
参数 innodb_read_io_threads 的默认值为 4。通常情况下,适当调整这个参数的值可以在多核系统上提高读取性能。但是,过多的线程数量可能会导致竞争和资源消耗,因此在调整之前建议进行性能测试和评估。
要更改 innodb_read_io_threads 参数的值,你需要编辑配置文件,将其设置为所需的值,并重启 MySQL 服务器才能生效。
2.3.3 innodb_thread_sleep_delay
这个参数用于指定后台线程在没有任务可执行时的休眠时间。
在 InnoDB 存储引擎中,有多个后台线程用于处理不同的任务,例如刷新脏页、合并插入缓冲(Insert Buffer)、线程清理等等。当这些后台线程完成了当前的任务后,它们会检查是否有其他待处理的任务。如果没有,后台线程将进入休眠状态,在指定的时间间隔后再次检查是否有新的任务。
innodb_thread_sleep_delay 参数指定了后台线程休眠的时间间隔,默认值为 10000 毫秒(10 秒)。
在调整 innodb_thread_sleep_delay 参数之前,请考虑以下因素:
1. 系统的负载情况以及后台线程的任务类型和频率。
2. 与其他 InnoDB 参数的相互影响,以及对系统性能的整体影响。
-- 调整睡眠时间,单位为毫秒
set global innodb_thread_sleep_delay = 10000;
2.3.4 innodb_io_capacity
这个参数用于控制磁盘 IO 的性能。它定义了 InnoDB 存储引擎进行磁盘读取和写入操作时所能够使用的最大 IO 能力。
默认情况下,innodb_io_capacity 的值为 200。这意味着 InnoDB 存储引擎每秒最多可以执行 200 次 IO 操作。您可以根据系统的磁盘性能和负载情况来调整该参数。
需要注意的是,innodb_io_capacity 参数是一个整数值,且不能小于 100。过高的值可能会导致对磁盘资源的过度占用,对系统性能造成负面影响。
在调整 innodb_io_capacity 参数之前,建议您评估系统的磁盘子系统性能,并进行适当的测试和性能监控,以确定合适的值。
set global innodb_io_capacity = 200;
2.3.5 innodb_io_capacity_max
这个参数用于定义 InnoDB 存储引擎在执行 I/O 操作时所能够使用的最大 I/O 能力。它的默认值为 2000。
需要注意的是,innodb_io_capacity_max 参数的值必须大于或等于 innodb_io_capacity 参数的值,并且通常不需要手动调整该参数,因为默认值已经足够满足绝大多数的场景。
set global innodb_io_capacity_max = 2000;
2.4 其他参数
2.4.1 innodb_flush_log_at_trx_commit
这个参数用于控制事务日志缓冲区的刷新策略。
InnoDB 使用了一种叫做 “write-ahead logging”(预写式日志)的机制来确保事务的持久性和一致性。在每次事务提交时,相关的日志记录首先被写入到事务日志缓冲区(transaction log buffer)中。然后根据 innodb_flush_log_at_trx_commit 的配置,决定何时将日志缓冲区的内容刷新到磁盘。
innodb_flush_log_at_trx_commit 的值可以是以下三种配置之一:
1. 0:表示事务提交时不立即将日志缓冲区的内容刷新到磁盘。这个选项可以提供最好的性能,但也意味着在数据库崩溃的情况下,未刷新的事务日志可能会导致数据丢失。
2. 1:表示每次事务提交时都将日志缓冲区的内容立即刷新到磁盘。这样可以确保事务的持久性和一致性,但也会导致较高的磁盘写入开销。
3. 2:表示每次事务提交时将日志缓冲区的内容写入操作系统的缓冲区,并异步地将其刷新到磁盘。这种配置在遇到数据库崩溃时可能会导致一小段时间内的数据丢失,但相对于选项 1 能提供更好的性能。
大多数情况下,使用默认值 1 是推荐的做法,因为它确保了最高的事务持久性和一致性。但是,如果对性能非常敏感,并且可以容忍一些数据丢失的风险,可以考虑切换到选项 2 以提高性能。
set global innodb_flush_log_at_trx_commit = 1;
相关文章:

常用InnoDB参数介绍
常用InnoDB参数介绍 1 状态参数1.1 InnoDB 缓冲池状态监控1.1.1 Innodb_buffer_pool_pages_total1.1.2 Innodb_buffer_pool_pages_data1.1.3 Innodb_buffer_pool_bytes_data1.1.4 Innodb_buffer_pool_pages_dirty1.1.5 Innodb_buffer_pool_bytes_dirty1.1.6 Innodb_buffer_pool…...

云原生网关部署新范式丨 Higress 发布 1.1 版本,支持脱离 K8s 部署
作者:澄潭 版本特性 Higress 1.1.0 版本已经 Release,K8s 环境下可以使用以下命令将 Higress 升级到最新版本: kubectl apply -f https://github.com/alibaba/higress/releases/download/v1.1.0/customresourcedefinitions.gen.yaml helm …...

【通讯录】--C语言
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …...
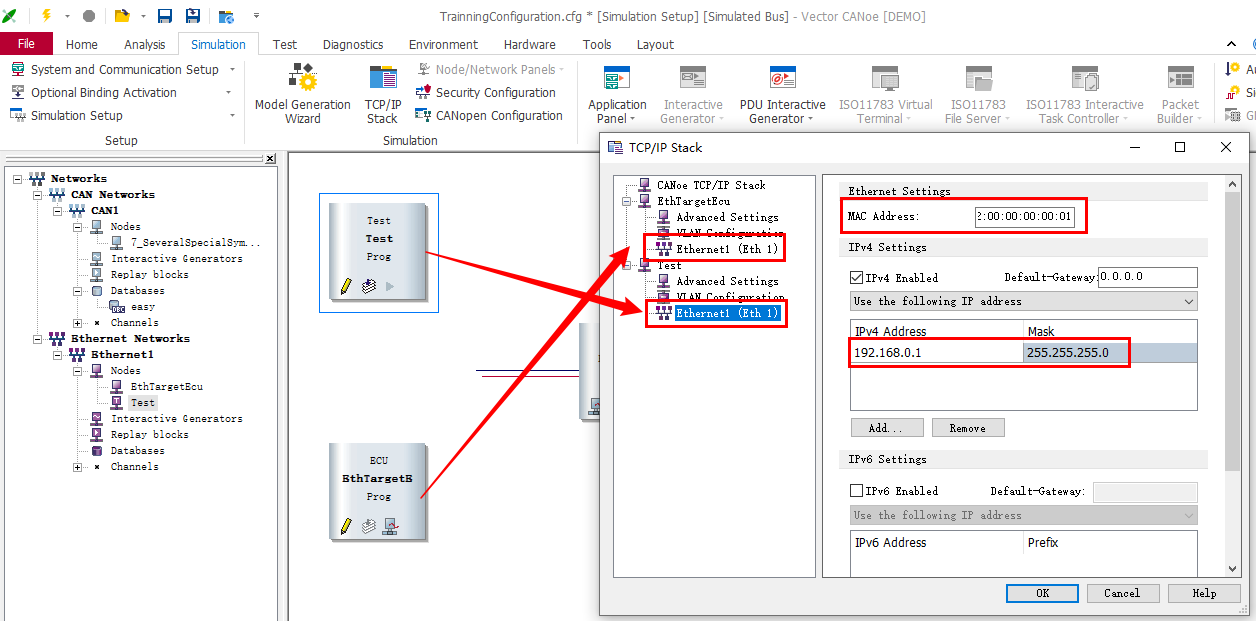
通过两种实现方式理解CANoe TC8 demo是如何判断接收的以太网报文里的字段的
假设有一个测试用例,需求是:编写一个测试用例,发送一条icmpv4 echo request报文给DUT,identifier字段设置为10。判断DUT能够回复icmpv4 echo reply报文,且identifier字段值为10。 实现:在canoe的simulation setup界面插入一个test节点,ip地址为:192.168.0.1,mac地址为…...

Mysql- 存储引擎
目录 1.Mysql体系结构 2.存储引擎简介 3.存储引擎特点 InnoDB MyISAM Memory 4.存储引擎选择 1.Mysql体系结构 MySQL整体的逻辑结构可以分为4层: 连接层:进行相关的连接处理、权限控制、安全处理等操作 服务层:服务层负责与客户层进行…...
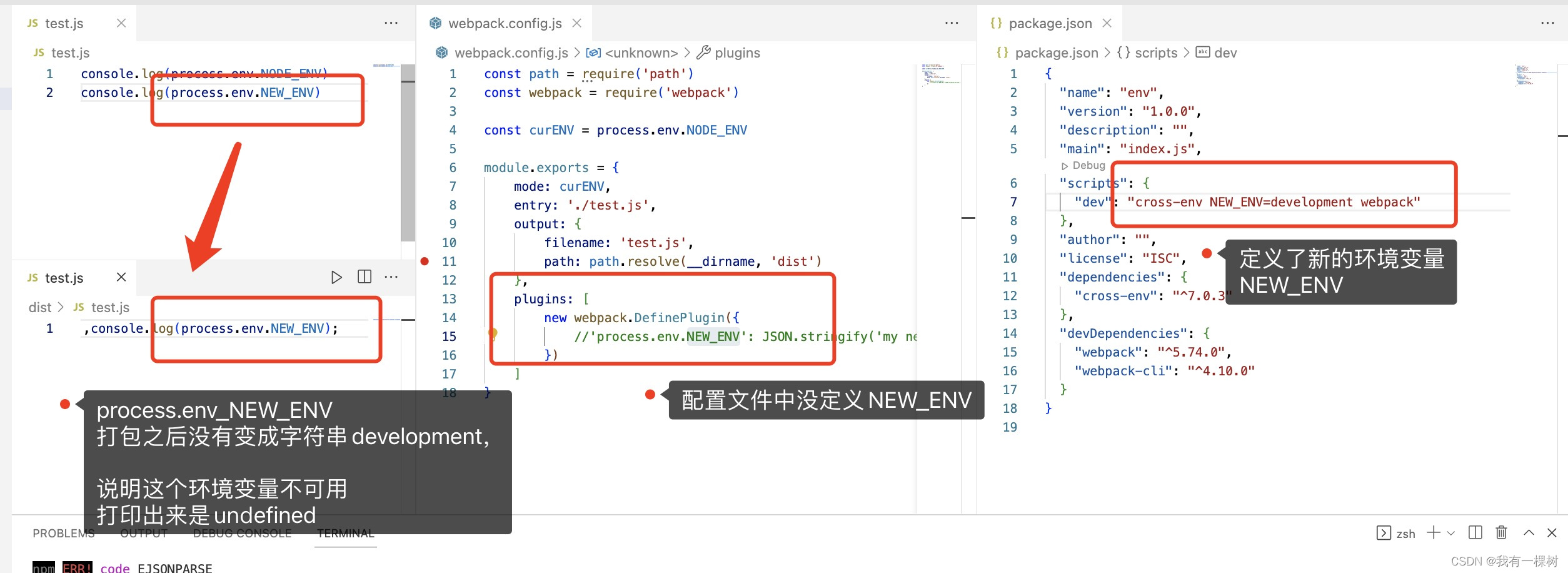
vite / nuxt3 项目使用define配置/自定义,可以使用process.env.xxx获取的环境变量
每日鸡汤:每个你想要学习的瞬间,都是未来的你向自己求救 首先可以看一下我的这篇文章了解一下关于 process.env 的环境变量。 对于vite项目,在我们初始化项目之后,在浏览器中打印 process.env,只有 NODE_ENV这个变量&…...
平台的binutils)
在Linux、Ubuntu中跨平台编译ARM(AARCH64)平台的binutils
Binutils 是GNU(https://www.gnu.org/)提供的一组二进制工具的集合。通常,在已经安装了Linux操作系统的个人电脑上,系统就已经自带了这个工具集。但在进行嵌入式开发的时候,可能会用到支持ARM64平台的Binutils,这时就需要用到交叉编译。 此前,在【1】我们已经介绍过Ubun…...
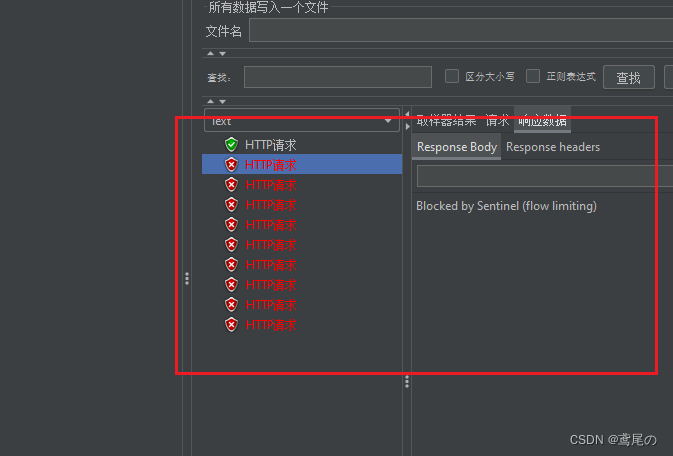
SpringCloudAlibaba微服务实战系列(五)Sentinel1.8.5+Nacos持久化
Sentinel数据持久化 前面介绍Sentinel的流控、熔断降级等功能,同时Sentinel应用也在面临着一个问题:我们在Sentinel后台管理界面中配置了一堆流控、降级规则,但是Sentinel一重启,这些规则全部消失了。那么我们就要考虑Sentinel的持…...

pytest中conftest的用法以及钩子基本使用
一、conftest是什么? conftest是pytest进阶中的高级应用,最近正好用到这一块儿,研究之后,向大家分享该高级应用。 二、使用步骤 1.conftest代码块 以全局性使用driver为主,只启动一次浏览器: pytest.fi…...

数据结构---顺序栈、链栈
特点 typedef struct Stack { int* base; //栈底 int* top;//栈顶 int stacksize //栈的容量; }SqStack; typedef struct StackNode { int data;//数据域 struct StackNode* next; //指针域 }StackNode,*LinkStack; 顺序栈 #define MaxSize 100 typedef struct Stack { int*…...

我的MacBook Pro:维护心得与实用技巧
文章目录 我的MacBook Pro:维护心得与实用技巧工作电脑概况:MacBook Pro 2019款 16 寸日常维护措施个人维护技巧其他建议 我的MacBook Pro:维护心得与实用技巧 无论是学习还是工作,电脑都是IT人必不可少的重要武器。一台好电脑除…...
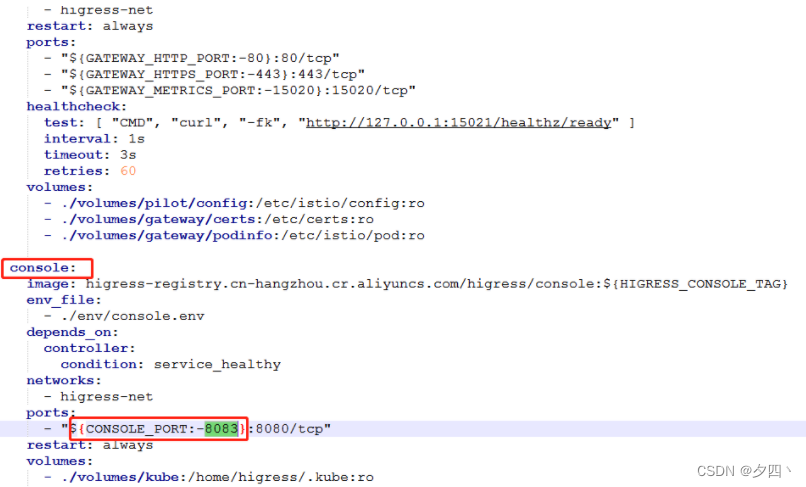
Higress非K8S安装
Higress非K8S安装 文章目录 Higress非K8S安装环境安装安装higress进入到higress 的目录下修改下nacos的地址启动Higress登录higress管理页面 Higress 是基于阿里内部构建的下一代云原生网关,官网介绍:https://higress.io/zh-cn/docs/overview/what-is-hi…...
QT--day4(定时器事件、鼠标事件、键盘事件、绘制事件、实现画板、QT实现TCP服务器)
QT实现tcpf服务器代码:(源文件) #include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this);//给服务器指针实例化空间server new QTc…...

hjm家族信托科技研究报告
目录 绪论 研究背景与意义 一、选题背景 二、选题意义 研究内容与主要研究方法 一、本文内容 二、研究方法 创新与不足 一、创新 二、不足之处 文献综述与理论基础 文献综述 国外研究现状国内研究现状国内外研究综述 理论基础 金融创新理论组合投资理论生命周期理论…...

[SQL挖掘机] - 视图相关操作
创建视图: create view view_name as select column1, column2, ... from table_name where condition;以上语句创建了一个名为view_name的视图,它基于table_name表格,并选择了列column1、column2等作为结果集。可以使用where子句来指定条件。 注意: 视…...

【Quartus FPGA】EMIF DDR3 读写带宽测试
在通信原理中,通信系统的有效性用带宽来衡量,带宽定义为每秒传输的比特数,单位 b/s,或 bps。在 DDR3 接口的产品设计中,DDR3 读/写带宽是设计者必须考虑的指标。本文主要介绍了 Quartus FPGA 平台 EMIF 参数配置&#…...
Flutter:flutter_local_notifications——消息推送的学习
前言 注: 刚开始学习,如果某些案例使用时遇到问题,可以自行百度、查看官方案例、官方github。 简介 Flutter Local Notifications是一个用于在Flutter应用程序中显示本地通知的插件。它提供了一个简单而强大的方法来在设备上发送通知&#…...
Spring AOP (面向切面编程)原理与代理模式—实例演示
一、AOP介绍和应用场景 Spring 中文文档 (springdoc.cn) Spring | Home 官网 1、AOP介绍(为什么会出现AOP ?) Java是一个面向对象(OOP)的语言,但它有一些弊端。虽然使用OOP可以通过组合或继承的方…...
什么是SCRUM认证体系 ?
Scrum认证是一个针对个人职业发展的认证体系,基础级认证主要面向Scrum的三个角色:Scrum Master、Scrum Product Owner 和 Developers。Scrum认证体系由Scrum官方机构—国际Scrum联盟(ScrumAlliance.org)制定和维护,Scr…...
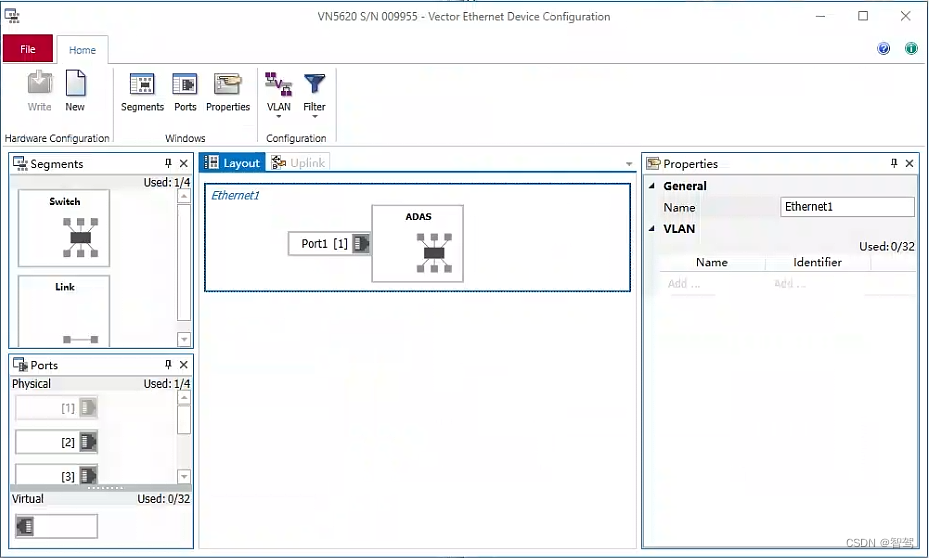
DoIP学习笔记系列:(二)VN5620 DoIP测试配置实践笔记
文章目录 1. 添加.cdd2. CAPL中调用接口发送DoIP请求3. “Ethernet Packet Builder”的妙用4. CANoe也可以做交互界面在进行测试前,先检查车载以太网硬件连线是否正确,需要注意连接两端的Master、Slave,100M、1000M等基本情况,在配置VN5620的时候就可以灵活处理了。成功安装…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

golang循环变量捕获问题
在 Go 语言中,当在循环中启动协程(goroutine)时,如果在协程闭包中直接引用循环变量,可能会遇到一个常见的陷阱 - 循环变量捕获问题。让我详细解释一下: 问题背景 看这个代码片段: fo…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

vue3 定时器-定义全局方法 vue+ts
1.创建ts文件 路径:src/utils/timer.ts 完整代码: import { onUnmounted } from vuetype TimerCallback (...args: any[]) > voidexport function useGlobalTimer() {const timers: Map<number, NodeJS.Timeout> new Map()// 创建定时器con…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

MacOS下Homebrew国内镜像加速指南(2025最新国内镜像加速)
macos brew国内镜像加速方法 brew install 加速formula.jws.json下载慢加速 🍺 最新版brew安装慢到怀疑人生?别怕,教你轻松起飞! 最近Homebrew更新至最新版,每次执行 brew 命令时都会自动从官方地址 https://formulae.…...

Ubuntu系统复制(U盘-电脑硬盘)
所需环境 电脑自带硬盘:1块 (1T) U盘1:Ubuntu系统引导盘(用于“U盘2”复制到“电脑自带硬盘”) U盘2:Ubuntu系统盘(1T,用于被复制) !!!建议“电脑…...

认识CMake并使用CMake构建自己的第一个项目
1.CMake的作用和优势 跨平台支持:CMake支持多种操作系统和编译器,使用同一份构建配置可以在不同的环境中使用 简化配置:通过CMakeLists.txt文件,用户可以定义项目结构、依赖项、编译选项等,无需手动编写复杂的构建脚本…...