英伟达 H100 vs. 苹果M2,大模型训练,哪款性价比更高?

M1芯片 | Uitra | AMD | A100
M2芯片 | ARM | A800 | H100
关键词:M2芯片;Ultra;M1芯片;UltraFusion;ULTRAMAN;RTX4090、A800;A100;H100;LLAMA、LM、AIGC、CHATGLM、LLVM、LLM、LLMs、GLM、NLP、ChatGPT、AGI、HPC、GPU、CPU、CPU+GPU、英伟达、Nvidia、英特尔、AMD、高性能计算、高性能服务器、蓝海大脑、多元异构算力、高性能计算、大模型训练、大型语言模型、通用人工智能、GPU服务器、GPU集群、大模型训练GPU集群、大语言模型
摘要:训练和微调大型语言模型对于硬件资源的要求非常高。目前,主流的大模型训练硬件通常采用英特尔的CPU和英伟达的GPU。然而,最近苹果的M2 Ultra芯片和AMD的显卡进展给我们带来了一些新的希望。
苹果的M2 Ultra芯片是一项重要的技术创新,它为苹果设备提供了卓越的性能和能效。与此同时,基于AMD软硬件系统的大模型训练体系也在不断发展,为用户提供了更多选择。尽管英伟达没有推出与苹果相媲美的200G显卡,但他们在显卡领域的竞争仍然激烈。对比苹果芯片与英伟达、英特尔、AMD的最新硬件和生态建设,我们可以看到不同厂商在性价比方面带来了全新的选择。
蓝海大脑为生成式AI应用提供了极具吸引力的算力平台,与英特尔紧密协作,为客户提供强大的大模型训练和推理能力,加速AIGC创新步伐、赋力生成式AI产业创新。

基于英特尔CPU+英伟达GPU大模型训练基础架构
一、深度学习架构大模型的主要优势
当前主流大模型架构都是基于深度学习transformer的架构模型,使用GPU训练深度学习架构的大模型主要有以下优势:
1、高性能计算
深度学习中的大部分计算都是浮点计算,包括矩阵乘法和激活函数的计算。GPU在浮点计算方面表现出色,具有高性能计算能力。
2、并行计算能力
GPU具有高度并行的计算架构,能够同时执行多个计算任务。深度学习模型通常需要执行大量的矩阵乘法和向量运算,这些操作可以高度并行的方式进行,从而提高深度学习模型训练效率。
3、高内存带宽
GPU提供高达几百GB/s的内存带宽,满足深度学习模型对数据大容量访问需求。这种高内存带宽能够加快数据传输速度,提高模型训练的效率。

二、当前大多数大模型采用英特尔的CPU加英伟达的GPU作为计算基础设施的原因
尽管GPU在训练大模型时发挥着重要作用,但单靠GPU远远不够。除GPU负责并行计算和深度学习模型训练外,CPU在训练过程中也扮演着重要角色,其主要负责数据的预处理、后处理以及管理整个训练过程的任务。通过GPU和CPU之间的协同工作,可以实现高效的大规模模型训练。
1、强大的性能
英特尔最新CPU采用Alder Lake架构,具备出色的通用计算能力。而英伟达最新GPU H100拥有3.35TB/s的显存带宽、80GB的显存大小和900GB/s的显卡间通信速度,对大数据吞吐和并行计算提供友好的支持。
2、广泛的支持和生态系统
基于英特尔CPU提供的AVX2指令集和基于英伟达GPU提供的CUDA并行计算平台和编程模型,构建优秀的底层加速库如PyTorch等上层应用。
3、良好的兼容性和互操作性
在硬件和软件设计上考虑彼此配合使用的需求,能够有效地协同工作。这种兼容性和互操作性使得英特尔的CPU和英伟达的GPU成为流行的组合选择,在大规模模型训练中得到广泛应用。
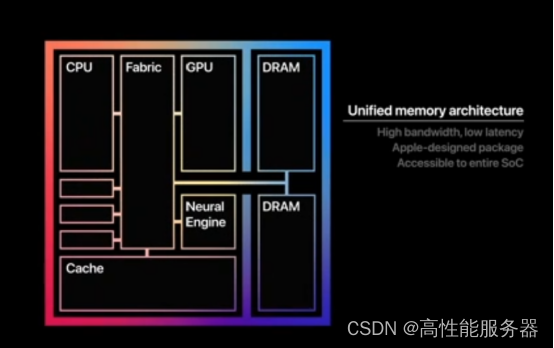
苹果的M2 Ultra统一内存架构
在WWDC2023开发者大会上苹果推出M2 Ultra芯片,以及搭载该芯片的新款Mac Studio和Mac Pro。这款芯片采用了第二代5nm制程工艺技术,是苹果迄今为止最大且最强大的芯片。
去年3月,苹果展示了一种将两块M1芯片“粘”在一起的设计,发布集成1140亿颗晶体管、20核CPU、最高64核GPU、32核神经网络引擎、2.5TB/s数据传输速率、800GB/s内存带宽、128GB统一内存的“至尊版”芯片M1 Ultra。延续M1 Ultra的设计思路,M2 Ultra芯片通过采用突破性的UltraFusion架构,将两块M2 Max芯片拼接到一起,拥有1340亿个晶体管,比上一代M1 Ultra多出200亿个。


UltraFusion是苹果在定制封装技术方面的领先技术,其使用硅中介层(interposer)将芯片与超过10000个信号连接起来,从而提供超过2.5TB/s的低延迟处理器间带宽。基于这一技术,M2 Ultra芯片在内存方面比M1 Ultra高出了50%,达到192GB的统一内存,并且拥有比M2 Max芯片高两倍的800GB/s内存带宽。以往由于内存不足,即使是最强大的独立GPU也无法处理大型模型。然而,苹果通过将超大内存带宽集成到单个SoC中,实现单台设备可以运行庞大的机器学习工作负载,如大型Transformer模型等。

AMD的大模型训练生态
除苹果的M2 Ultra在大模型训练方面取得了显著进展之外,AMD的生态系统也在加速追赶。
据7月3日消息,NVIDIA以其显著的优势在显卡领域获得了公认的地位,无论是在游戏还是计算方面都有着显著的优势,而在AI领域更是几乎垄断。然而,有好消息传来,AMD已经开始发力,其MI250显卡性能已经达到了NVIDIA A100显卡的80%。 AMD在AI领域的落后主要是因为其软件生态无法跟上硬件发展的步伐。尽管AMD的显卡硬件规格很高,但其运算环境与NVIDIA的CUDA相比仍然存在巨大的差距。最近,AMD升级了MI250显卡,使其更好地支持PyTorch框架。
MosaicML的研究结果显示,MI250显卡在优化后的性能提升显著,大语言模型训练速度已达到A100显卡的80%。AMD指出,他们并未为MosaicML进行这项研究提供资助,但表示将继续与初创公司合作,以优化软件支持。 但需要注意的是,NVIDIA A100显卡是在2020年3月发布的,已经是上一代产品,而NVIDIA目前最新的AI加速卡是H100,其AI性能有数倍至数十倍的提升。AMD的MI250显卡也不是最新产品,其在2021年底发布,采用CDNA2架构,6nm工艺,拥有208个计算单元和13312个流处理器核心,各项性能指标比MI250X下降约5.5%,其他规格均未变动。


AMD体系的特点如下:
一、LLM训练非常稳定
使用AMD MI250和NVIDIA A100在MPT-1B LLM模型上进行训练时,从相同的检查点开始,损失曲线几乎完全相同。
二、性能与现有的A100系统相媲美
MosaicML对MPT模型的1B到13B参数进行了性能分析发现MI250每个GPU的训练吞吐量在80%的范围内与A100-40GB相当,并且与A100-80GB相比在73%的范围内。随着AMD软件的改进,预计这一差距将会缩小。
三、基本无需代码修改
得益于PyTorch对ROCm的良好支持,基本上不需要修改现有代码。
英伟达显卡与苹果M2 Ultra 相比性能如何
一、英伟达显卡与M2 Ultra 相比性能如何
在传统英特尔+英伟达独立显卡架构下,CPU与GPU之间的通信通常通过PCIe进行。最强大的H100支持PCIe Gen5,传输速度为128GB/s,而A100和4090则支持PCIe 4,传输速度为64GB/s。
另一个重要的参数是GPU的显存带宽,即GPU芯片与显存之间的读写速度。显存带宽是影响训练速度的关键因素。例如,英伟达4090显卡的显存带宽为1.15TB/s,而A100和H100的显存带宽分别为1.99TB/s和3.35TB/s。
最后一个重要的参数是显存大小,它指的是显卡上的存储容量。目前,4090是消费级显卡的顶级选择,显存大小为24GB,而A100和H100单张显卡的显存大小均为80GB。这个参数对于存储大规模模型和数据集时非常重要。
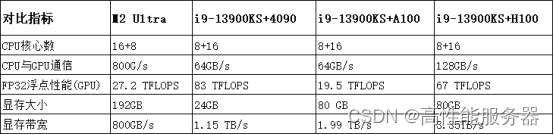

M2 Ultra的芯片参数和4090以及A100的对比(CPU采用英特尔最新的i9-13900KS)
从这些参数来看,苹果的M2 Ultra相对于英伟达的4090来说性能稍低,与专业级显卡相比则较为逊色。然而,M2 Ultra最重要的优势在于统一内存,即CPU读写的内存可以直接被显卡用作显存。因此,拥有192GB的显存几乎相当于8个4090或者2.5个A100/H100的显存。这意味着单个M2 Ultra芯片可以容纳非常大的模型。例如,当前开源的LLaMA 65B模型需要120GB的显存才能进行推理。这意味着苹果的M2 Ultra可以直接适用于LLaMA 65B,而目前没有其他芯片能够单独承载如此庞大的模型,甚至包括最新的H100。
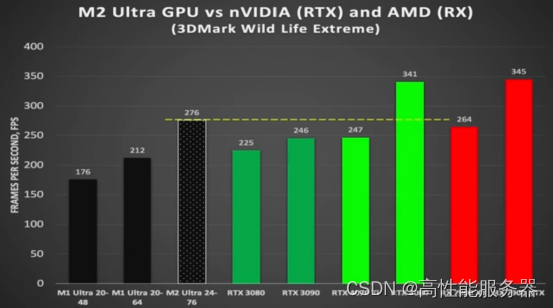

从上述参数对比来看,M2 Ultra在其他指标接近4090的情况下,显存大小成为其最大的优势。尽管M2 Ultra并非专为大模型训练而设计,但其架构非常适合进行大模型训练。
在上层生态方面,进展也非常良好。2022年5月18日,PyTorch宣布支持苹果芯片,并开始适配M1 Ultra,利用苹果提供的芯片加速库MPS进行加速Ultra上使用PyTorch进行训练。以文本生成图片为例,它能够一次性生成更多且更高精度的图片。
二、NVIDIA为什么不推出一款200GB显存以上的GPU?
主要原因可以分为以下几点:
1、大语言模型火起来还没多久;
2、显存容量和算力是要匹配的,空有192GB显存,但是算力不足并无意义;
3、苹果大内存,适合在本地进行推理,有希望引爆在端侧部署AI的下一轮热潮。
从2022年11月ChatGPT火起来到现在,时间也不过才半年时间。从项目立项,到确定具体的规格,再到设计产品,并且进行各种测试,最终上市的全流程研发时间至少在一年以上。客观上讲,大语言模型形成全球范围的热潮,一定会带动对于显存容量的需求。英伟达未来显存容量的升级速度一定会提速。
过去之所以消费级显卡的显存容量升级较慢,根本原因是没有应用场景。8GB的消费级显卡用来打游戏足矣,加速一些视频剪辑也绰绰有余。更高的显存容量,只能服务于少量科研人员,而且大多都去买了专业卡专门应用。现在有了大语言模型,可以在本地部署一个开源的模型。有了对于显存的明确需求,未来一定会快速提升显存容量的。
其次,苹果有192GB的统一内存可以用于大语言模型的“训练”。这个认知是完全错误的。AI模型可以分为训练(train)、微调(fine-tune)和推理(inference)。简单来说,训练就是研发人员研发AI模型的过程,推理就是用户部署在设备上来用。从算力消耗上来说,是训练>微调>推理,训练要比推理的算力消耗高至少3个数量级以上。
训练也不纯粹看一个显存容量大小,而是和芯片的算力高度相关的。因为实际训练的过程当中,将海量的数据切块成不同的batch size,然后送入显卡进行训练。显存大,意味着一次可以送进更大的数据块。但是芯片算力如果不足,单个数据块就需要更长的等待时间。
显存和算力,必须要相辅相成。在有限的产品成本内,两者应当是恰好在一个平衡点上。现阶段英伟达的H100能够广泛用于各大厂商的真实模型训练,而不是只存在于几个自媒体玩具级别的视频里面,说明H100能够满足厂商的使用需要。
要按苹果的显存算法,一块Grace Hopper就超过了啊。一块Grace Hopper的统一内存高达512GB,外加Hopper还有96GB的独立显存,早就超了。
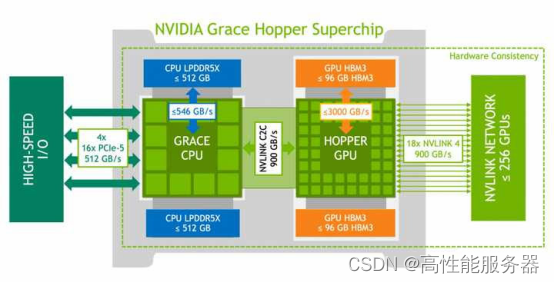

使用NVIDIA H100训练ChatGPT大模型仅用11分钟
AI技术的蓬勃发展使得NVIDIA的显卡成为市场上备受瞩目的热门产品。尤其是高端的H100加速卡,其售价超过25万元,然而市场供不应求。该加速卡的性能也非常惊人,最新的AI测试结果显示,基于GPT-3的大语言模型训练任务刷新了记录,完成时间仅为11分钟。

据了解,机器学习及人工智能领域的开放产业联盟MLCommons发布了最新的MLPerf基准评测。包括8个负载测试,其中就包含基于GPT-3开源模型的LLM大语言模型测试,这对于评估平台的AI性能提出了很高的要求。
参与测试的NVIDIA平台由896个Intel至强8462Y+处理器和3584个H100加速卡组成,是所有参与平台中唯一能够完成所有测试的。并且,NVIDIA平台刷新了记录。在关键的基于GPT-3的大语言模型训练任务中,H100平台仅用了10.94分钟,与之相比,采用96个至强8380处理器和96个Habana Gaudi2 AI芯片构建的Intel平台完成同样测试所需的时间为311.94分钟。
H100平台的性能几乎是Intel平台的30倍,当然,两套平台的规模存在很大差异。但即便只使用768个H100加速卡进行训练,所需时间仍然只有45.6分钟,远远超过采用Intel平台的AI芯片。
H100加速卡采用GH100 GPU核心,定制版台积电4nm工艺制造,拥有800亿个晶体管。它集成了18432个CUDA核心、576个张量核心和60MB的二级缓存,支持6144-bit HBM高带宽内存以及PCIe 5.0接口。
![]()


H100计算卡提供SXM和PCIe 5.0两种样式。SXM版本拥有15872个CUDA核心和528个Tensor核心,而PCIe 5.0版本则拥有14952个CUDA核心和456个Tensor核心。该卡的功耗最高可达700W。
就性能而言,H100加速卡在FP64/FP32计算方面能够达到每秒60万亿次的计算能力,而在FP16计算方面达到每秒2000万亿次的计算能力。此外,它还支持TF32计算,每秒可达到1000万亿次,是A100的三倍。而在FP8计算方面,H100加速卡的性能可达每秒4000万亿次,是A100的六倍。
蓝海大脑大模型训练平台
蓝海大脑大模型训练平台提供强大的支持,包括基于开放加速模组高速互联的AI加速器。配置高速内存且支持全互联拓扑,满足大模型训练中张量并行的通信需求。支持高性能I/O扩展,同时可以扩展至万卡AI集群,满足大模型流水线和数据并行的通信需求。强大的液冷系统热插拔及智能电源管理技术,当BMC收到PSU故障或错误警告(如断电、电涌,过热),自动强制系统的CPU进入ULFM(超低频模式,以实现最低功耗)。致力于通过“低碳节能”为客户提供环保绿色的高性能计算解决方案。主要应用于深度学习、学术教育、生物医药、地球勘探、气象海洋、超算中心、AI及大数据等领域。
![]()


一、为什么需要大模型?
1、模型效果更优
大模型在各场景上的效果均优于普通模型
2、创造能力更强
大模型能够进行内容生成(AIGC),助力内容规模化生产
3、灵活定制场景
通过举例子的方式,定制大模型海量的应用场景
4、标注数据更少
通过学习少量行业数据,大模型就能够应对特定业务场景的需求
二、平台特点
1、异构计算资源调度
一种基于通用服务器和专用硬件的综合解决方案,用于调度和管理多种异构计算资源,包括CPU、GPU等。通过强大的虚拟化管理功能,能够轻松部署底层计算资源,并高效运行各种模型。同时充分发挥不同异构资源的硬件加速能力,以加快模型的运行速度和生成速度。
2、稳定可靠的数据存储
支持多存储类型协议,包括块、文件和对象存储服务。将存储资源池化实现模型和生成数据的自由流通,提高数据的利用率。同时采用多副本、多级故障域和故障自恢复等数据保护机制,确保模型和数据的安全稳定运行。
3、高性能分布式网络
提供算力资源的网络和存储,并通过分布式网络机制进行转发,透传物理网络性能,显著提高模型算力的效率和性能。
4、全方位安全保障
在模型托管方面,采用严格的权限管理机制,确保模型仓库的安全性。在数据存储方面,提供私有化部署和数据磁盘加密等措施,保证数据的安全可控性。同时,在模型分发和运行过程中,提供全面的账号认证和日志审计功能,全方位保障模型和数据的安全性。
三、常用配置
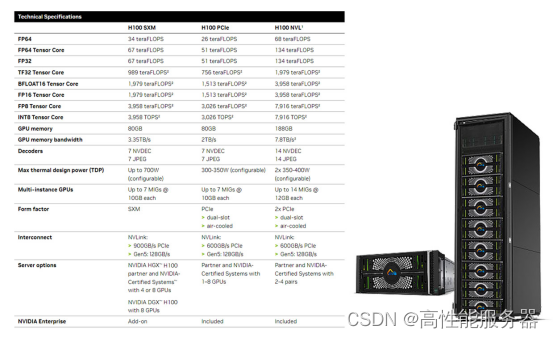
目前大模型训练多常用H100、H800、A800、A100等GPU显卡,其中H100 配备第四代 Tensor Core 和 Transformer 引擎(FP8 精度),与上一代产品相比,可为多专家 (MoE) 模型提供高 9 倍的训练速度。通过结合可提供 900 GB/s GPU 间互连的第四代 NVlink、可跨节点加速每个 GPU 通信的 NVLINK Switch 系统、PCIe 5.0 以及 NVIDIA Magnum IO™ 软件,为小型企业到大规模统一 GPU 集群提供高效的可扩展性。
搭载 H100 的加速服务器可以提供相应的计算能力,并利用 NVLink 和 NVSwitch 每个 GPU 3 TB/s 的显存带宽和可扩展性,凭借高性能应对数据分析以及通过扩展支持庞大的数据集。通过结合使用 NVIDIA Quantum-2 InfiniBand、Magnum IO 软件、GPU 加速的 Spark 3.0 和 NVIDIA RAPIDS™,NVIDIA 数据中心平台能够以出色的性能和效率加速这些大型工作负载。
1、H100工作站常用配置
CPU:英特尔至强Platinum 8468 48C 96T 3.80GHz 105MB 350W *2
内存:动态随机存取存储器64GB DDR5 4800兆赫 *24
存储:固态硬盘3.2TB U.2 PCIe第4代 *4
GPU :Nvidia Vulcan PCIe H100 80GB *8
平台 :HD210 *1
散热 :CPU+GPU液冷一体散热系统 *1
网络 :英伟达IB 400Gb/s单端口适配器 *8
电源:2000W(2+2)冗余高效电源 *1
2、A800工作站常用配置
CPU:Intel 8358P 2.6G 11.2UFI 48M 32C 240W *2
内存:DDR4 3200 64G *32
数据盘:960G 2.5 SATA 6Gb R SSD *2
硬盘:3.84T 2.5-E4x4R SSD *2
网络:双口10G光纤网卡(含模块)*1
双口25G SFP28无模块光纤网卡(MCX512A-ADAT )*1
GPU:HV HGX A800 8-GPU 8OGB *1
电源:3500W电源模块*4
其他:25G SFP28多模光模块 *2
单端口200G HDR HCA卡(型号:MCX653105A-HDAT) *4
2GB SAS 12Gb 8口 RAID卡 *1
16A电源线缆国标1.8m *4
托轨 *1
主板预留PCIE4.0x16接口 *4
支持2个M.2 *1
原厂质保3年 *1
3、A100工作站常用配置
CPU:Intel Xeon Platinum 8358P_2.60 GHz_32C 64T_230W *2
RAM:64GB DDR4 RDIMM服务器内存 *16
SSD1:480GB 2.5英寸SATA固态硬盘 *1
SSD2:3.84TB 2.5英寸NVMe固态硬盘 *2
GPU:NVIDIA TESLA A100 80G SXM *8
网卡1:100G 双口网卡IB 迈络思 *2
网卡2:25G CX5双口网卡 *1
4、H800工作站常用配置
CPU:Intel Xeon Platinum 8468 Processor,48C64T,105M Cache 2.1GHz,350W *2
内存 :64GB 3200MHz RECC DDR4 DIMM *32
系统硬盘: intel D7-P5620 3.2T NVMe PCle4.0x4 3DTLCU.2 15mm 3DWPD *4
GPU: NVIDIA Tesla H800 -80GB HBM2 *8
GPU网络: NVIDIA 900-9x766-003-SQO PCle 1-Port IB 400 OSFP Gen5 *8
存储网络 :双端口 200GbE IB *1
网卡 :25G网络接口卡 双端口 *1
相关文章:
英伟达 H100 vs. 苹果M2,大模型训练,哪款性价比更高?
M1芯片 | Uitra | AMD | A100 M2芯片 | ARM | A800 | H100 关键词:M2芯片;Ultra;M1芯片;UltraFusion;ULTRAMAN;RTX4090、A800;A100;H100;LLAMA、LM、AIGC、CHATGLM、LLVM、LLM、LLM…...

var、let和const的区别
先简单了解一下 var声明的变量会挂载在window上,而let和const声明的变量不会: var a 100; console.log(a,window.a); // 100 100let b 10; console.log(b,window.b); // 10 undefinedconst c 1; console.log(c,window.c); // 1 undefined v…...

(css)AI智能问答页面布局
(css)AI智能问答页面布局 效果: html <!-- AI框 --><div class"chat-top"><div class"chat-main" ref"chatList"><div v-if"!chatList.length" class"no-message"><span>欢迎使…...
 函数)
【Pytorch学习】pytorch中的isinstance() 函数
描述 isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。 isinstance() 与 type() 区别: type() 不会认为子类是一种父类类型,不考虑继承关系。 isinstance() 会认为子类是一种父类类型,考虑继承关系。 如果要判…...
(树) 剑指 Offer 07. 重建二叉树 ——【Leetcode每日一题】
❓剑指 Offer 07. 重建二叉树 难度:中等 输入某二叉树的 前序遍历 和 中序遍历 的结果,请构建该二叉树并返回其根节点。 假设输入的前序遍历和中序遍历的结果中都不含重复的数字。 示例 1: Input: preorder [3,9,20,15,7], inorder [9,3,15,20,7] …...
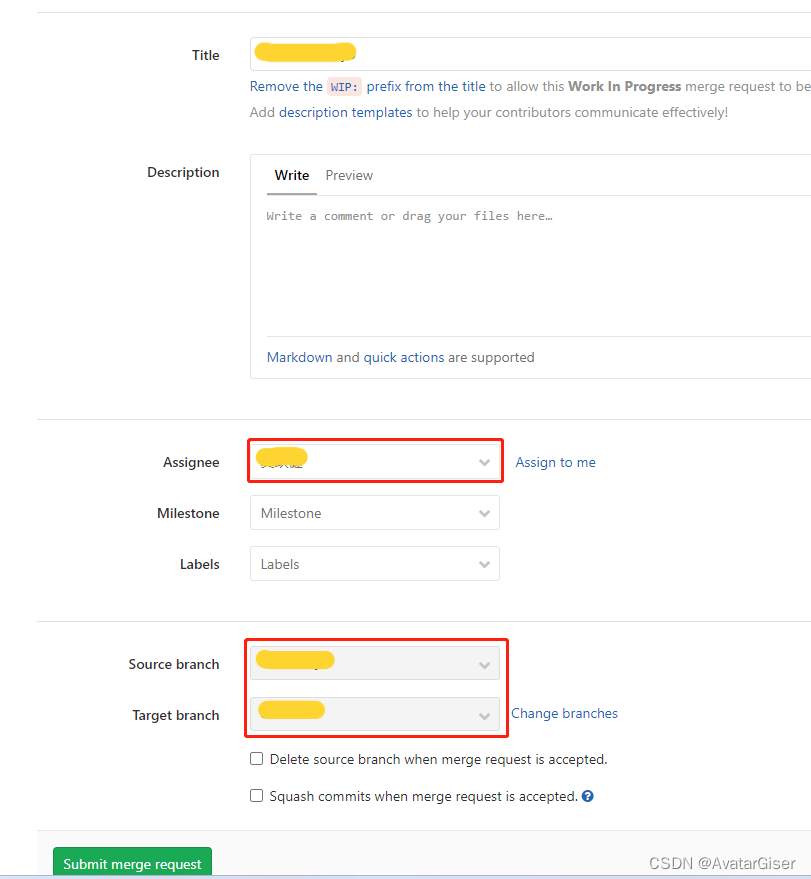
Gitlab 合并分支与请求合并
合并分支 方式一:图形界面 使用 GitGUI,右键菜单“GitExt Browse” - 菜单“命令” - 合并分支 方式二:命令行 在项目根目录下打开控制台,注意是本地 dev 与远程 master 的合并 // 1.查看本地分支,确认当前分支是否…...
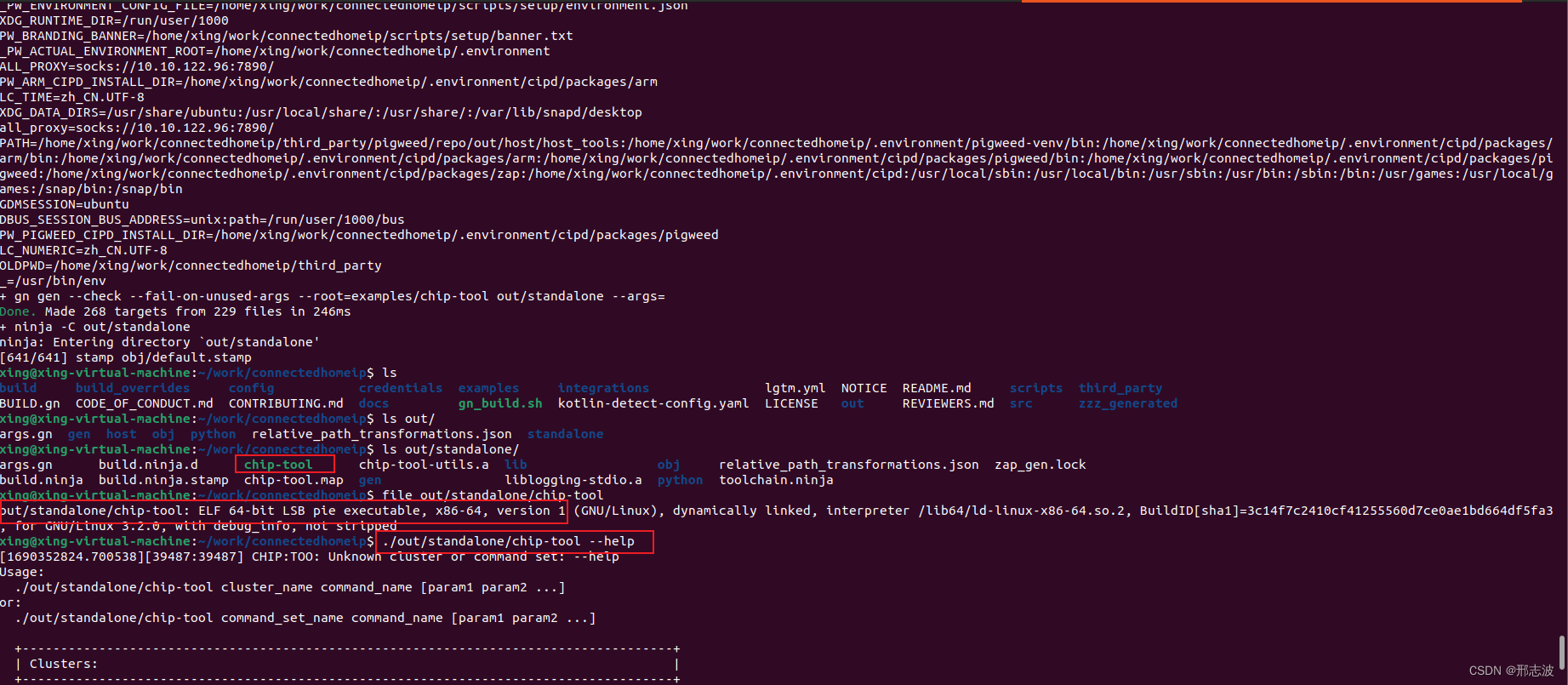
【Matter】基于Ubuntu 22.04 编译chip-tool工具
前言 编译过程有点曲折,做下记录,过程中,有参考别人写的博客,也看github 官方介绍,终于跑通了~ 环境说明: 首先需要稳定的梯子,可以访问“外网”ubuntu 环境,最终成功实验在Ubunt…...

将 MongoDB 的 List<Document> 转换为对象列表
当我们使用 MongoDB 存储数据时,经常会涉及到将 MongoDB 的文档对象转换为对象列表的需求。在 Java 中,我们可以使用 MongoDB 的 Java 驱动程序和自定义类来实现这一转换过程。 本篇博客将介绍如何将 MongoDB 中的 List<Document> 转换为对象列表。…...
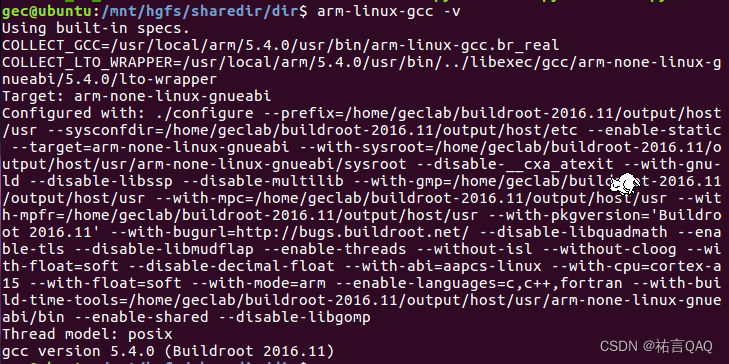
【Linux下6818开发板(ARM)】SecureCRT串口和交叉编译工具(巨细版!)
(꒪ꇴ꒪ ),hello我是祐言博客主页:C语言基础,Linux基础,软件配置领域博主🌍快上🚘,一起学习!送给读者的一句鸡汤🤔:集中起来的意志可以击穿顽石!作者水平很有限,如果发现错误&#x…...
应届生如何快速找Java开发工程师,先学会这17个基础问题
一、Java 基础 JDK 和 JRE 有什么区别? JDK:Java Development Kit 的简称,java 开发工具包,提供了 java 的开发环境和运行环境。 JRE:Java Runtime Environment 的简称,java 运行环境,为 java 的…...
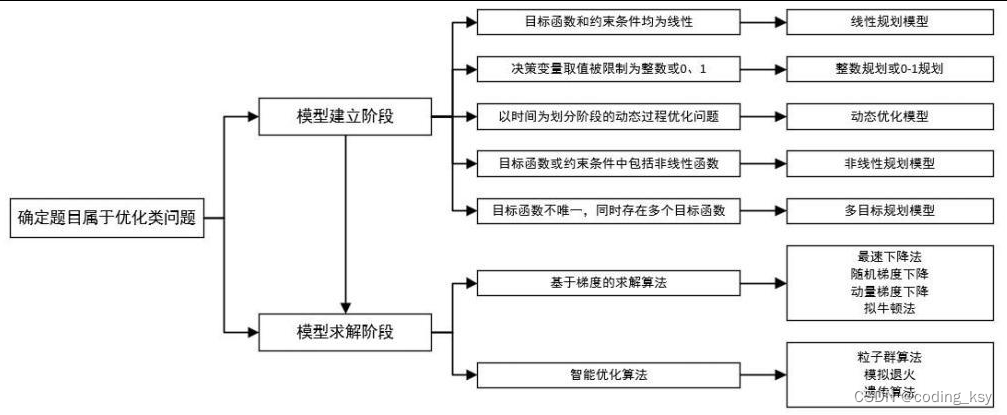
数学建模学习(5):数学建模各类题型及解题方案
一、数学建模常见的题型 总体来说,数学建模赛题类型主要分为:评价类、预测类和优化类三种,其中优化类是最常见的赛题类 型,几乎每年的地区赛或国赛美赛等均有出题,必须要掌握并且熟悉。 二、评价类赛题 综合评价是数学…...
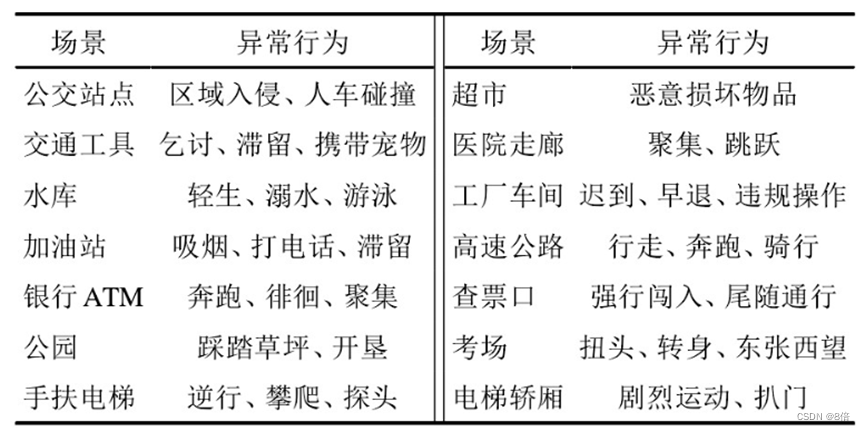
【学习笔记】视频检测方法调研
目录 1 引言2 方法2.1 视频目标跟踪2.1.1 生成式模型方法2.1.2 判别式模型方法2.1.2.1 基于相关滤波跟踪2.1.2.2 基于深度学习跟踪 2.2 视频异常检测2.2.1 基于重构方法2.2.2 基于预测方法2.2.3 基于分类方法2.2.4 基于回归方法 2.3 深度伪造人脸视频检测2.3.1 基于RNN时空融合…...
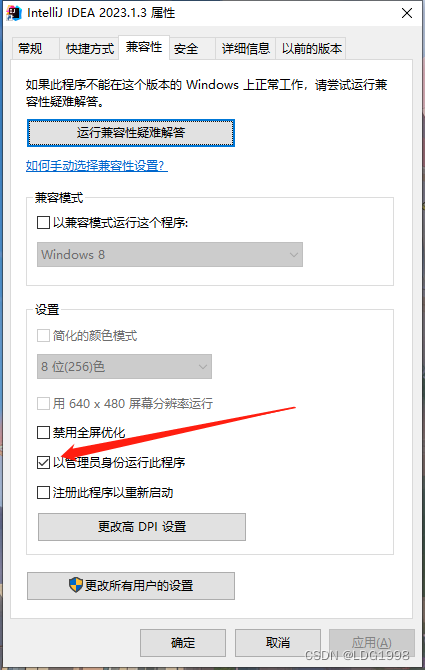
idea terminal npm指令无效
文章目录 一、修改setting二、修改启动方式 一、修改setting 菜单栏:File->Settings 二、修改启动方式 快捷方式->右键属性->兼容性->勾选管理员身份运行...
低代码开发平台源码
什么是低代码开发平台? 低代码来源于英文“Low Code,它意指一种快速开发的方式,使用最少的代码、以最快的速度来交付应用程序。通俗的来说,就是所需代码数量低,开发人员门槛低,操作难度低。一般采用简单的图…...
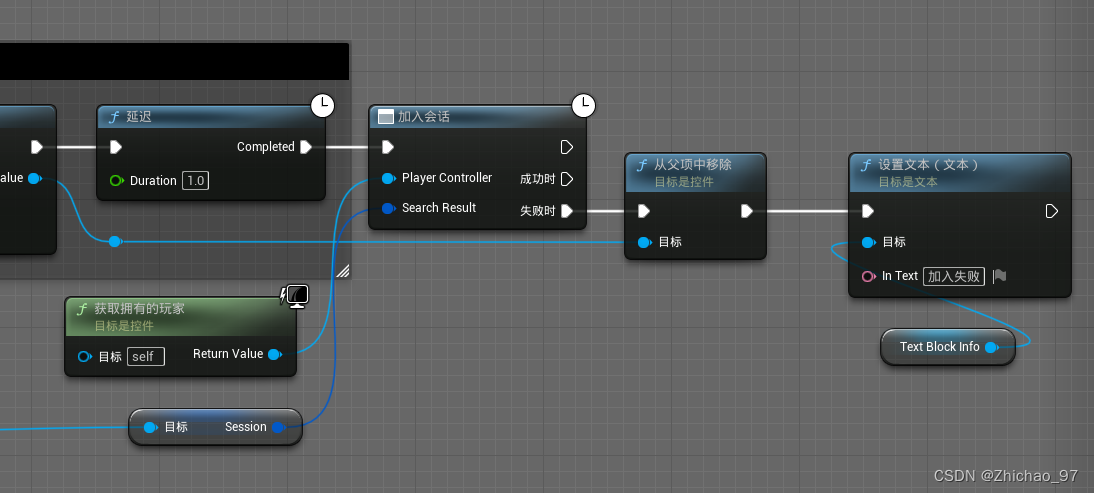
【UE5 多人联机教程】04-加入游戏
效果 步骤 1. 新建一个控件蓝图,父类为“USC_Button_Standard” 控件蓝图命名为“UMG_Item_Room”,用于表示每一个搜索到的房间的界面 打开“UMG_Item_Room”,在图表中新建一个变量,命名为“Session” 变量类型为“蓝图会话结果…...
-[大型语言模型(LLMs):缓存LLM的调用结果])
自然语言处理从入门到应用——LangChain:模型(Models)-[大型语言模型(LLMs):缓存LLM的调用结果]
分类目录:《自然语言处理从入门到应用》总目录 from langchain.llms import OpenAI在内存中缓存 import langchain from langchain.cache import InMemoryCachelangchain.llm_cache InMemoryCache()# To make the caching really obvious, lets use a slower mode…...

Python 算法基础篇之图的遍历算法:深度优先搜索和广度优先搜索
Python 算法基础篇之图的遍历算法:深度优先搜索和广度优先搜索 引言 1. 图的遍历概述2. 深度优先搜索( DFS )2.1 DFS 的实现2.2 DFS 的应用场景 3. 广度优先搜索( BFS )3.1 BFS 的实现3.2 BFS 的应用场景 4. 示例与实例…...

文本缩略 文本超出显示省略号 控制超出省略的行数
文本缩略 .abb{//超出一行省略overflow:hidden; white-space:nowrap; text-overflow:ellipsis; }超出2行省略 .abb2{display: -webkit-box !important;-webkit-box-orient: vertical;//超出2行省略-webkit-line-clamp:2;overflow: hidden; }控制超出省略的行数 .txt-over{/*控…...
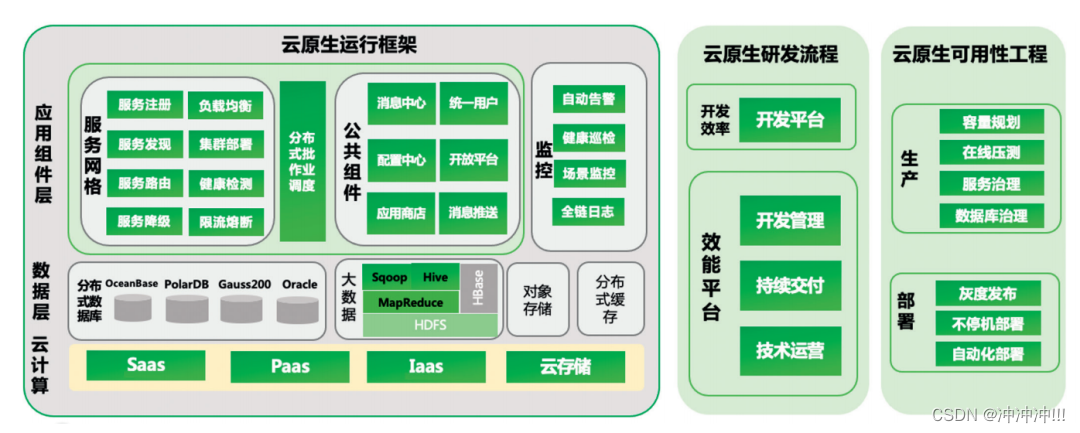
云原生架构
1. 何为云原生? 很多IT业内小伙伴会经常听到这个名词,那么什么是云原生呢?云原生是在云计算环境中构建、部署和管理现代应用程序的软件方法。 当今时代,众多企业希望构建高度可扩展、灵活且有弹性的应用程序,以便能够快…...

Java 生成随机数据
文章目录 1. Java-faker依赖demo 2. common-random依赖demo 1. Java-faker 依赖 <dependency><groupId>com.github.javafaker</groupId><artifactId>javafaker</artifactId><version>1.0.2</version> </dependency>https://…...

2026专业护眼产品深度评测:告别眼干涩疲劳,哪款才是“医用级“长效养护的选择?
屏幕时代,眼睛正在为我们的工作和生活"买单"。从早起看手机的那一刻,到深夜关灯前最后一次刷屏,多数人每天面对电子屏幕的时间早已超过10小时。干涩、疲劳、视力模糊、异物感……这些曾经只出现在中老年人身上的困扰,正…...

GLM-OCR在跨境电商中的应用:多语言商品说明书OCR→自动翻译预处理
GLM-OCR在跨境电商中的应用:多语言商品说明书OCR→自动翻译预处理 1. 项目概述与背景 跨境电商卖家经常面临一个共同难题:来自不同国家的商品说明书语言各异,手动翻译不仅耗时耗力,还容易出错。传统OCR工具虽然能识别文字&#…...

Univer:企业级协作平台开发实战
Univer:企业级协作平台开发实战 【免费下载链接】univer Build AI-native spreadsheets. Univer is a full-stack framework for creating and editing spreadsheets on both web and server. With Univer Platform, Univer Spreadsheets is driven directly throug…...
)
告别手动爆肝:用AiScan-N自动化你的CTF Web漏洞测试(SQL注入/文件上传实战)
智能渗透测试革命:AiScan-N在CTF中的实战应用与效率跃升 当凌晨三点的CTF比赛进入白热化阶段,你的眼皮开始打架,而对手却像永动机般不断提交flag——这种场景下,传统手动渗透测试的局限性暴露无遗。我曾亲眼见证一位资深红队成员…...
)
CF1249D2 Too Many Segments (hard version)
给你 条线段,每条线有起始点 和终止点 ,线段会覆盖一个直线上的 到 的所有点,问你取消多少条线段后可以使每一个点都不被大于 的数量的线段覆盖。 ## 前置知识 考虑对于第 个点,之前的所有点都满足了要求,如果 …...

告别繁琐操作:用快马AI定制你的智能FileZilla,实现自动化文件管理
告别繁琐操作:用快马AI定制你的智能FileZilla,实现自动化文件管理 作为一个经常需要处理文件传输的开发人员,我深知传统FTP工具的局限性。每次都要重复配置服务器信息,手动同步文件夹,还要花时间筛选文件,…...

智能电动汽车芯片全景解析:从MCU到SoC的技术跃迁
1. 智能电动汽车的芯片革命:从机械控制到数字大脑 十年前打开汽车引擎盖,看到的是一堆机械部件和少量电子控制单元;现在掀开一辆特斯拉的"前备箱",映入眼帘的却是布满芯片的电路板。这个直观变化背后,是汽车…...

Local SDXL-Turbo保姆级教程:导出为ONNX格式进一步优化推理速度
Local SDXL-Turbo保姆级教程:导出为ONNX格式进一步优化推理速度 1. 引言:为什么需要导出ONNX? 如果你已经体验过Local SDXL-Turbo那“打字即出图”的畅快感,可能会想:这速度已经很快了,还能不能再快一点&…...

千问3.5-2B在VSCode中的集成应用:基于CodeX的智能编程助手搭建
千问3.5-2B在VSCode中的集成应用:基于CodeX的智能编程助手搭建 1. 引言 作为一名开发者,你是否经常在编码过程中遇到这些问题:记不清某个API的具体用法?需要快速生成重复性代码片段?遇到报错信息却找不到清晰的解释&…...

StructBERT中文语义匹配实战:一键部署+可视化进度条,小白也能用
StructBERT中文语义匹配实战:一键部署可视化进度条,小白也能用 1. 工具概览:你的中文句子"CT扫描仪" 想象一下,你手上有两份用户反馈:"这个手机电池很耐用"和"这款设备续航能力超强"。…...