elasticsearch查询操作(DSL语句方式)
说明:本文介绍在kibana,es的可视化界面上对文档的查询操作;
添加数据
先使用API,创建索引库,并且把数据从MySQL中查出来,传到ES上,参考(http://t.csdn.cn/NaTHg)
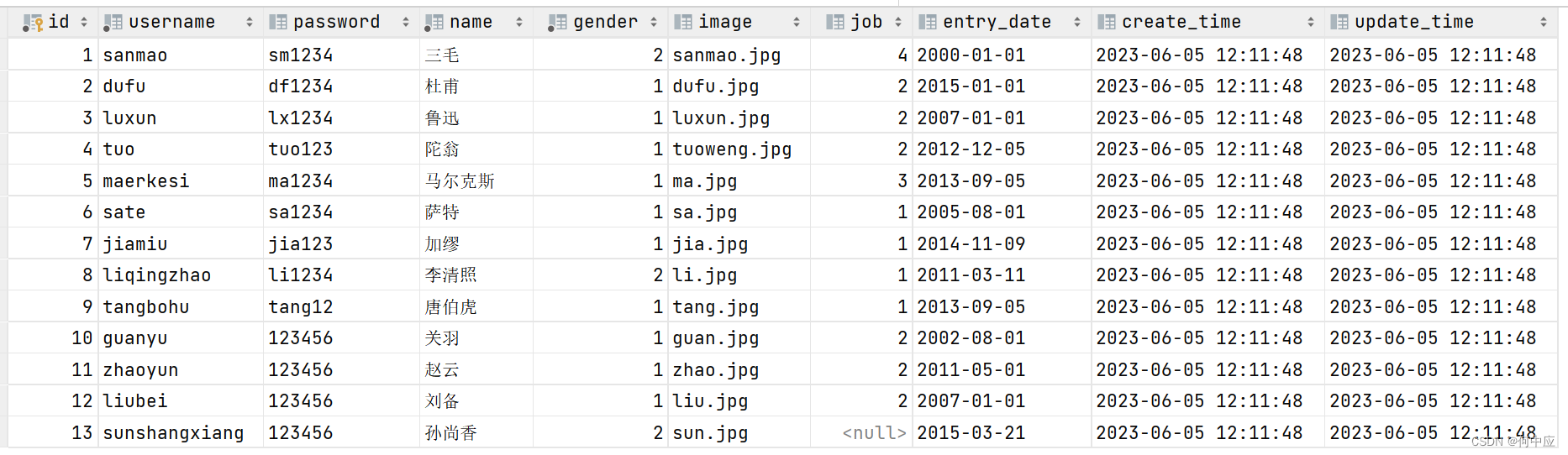
索引库(student)结构;
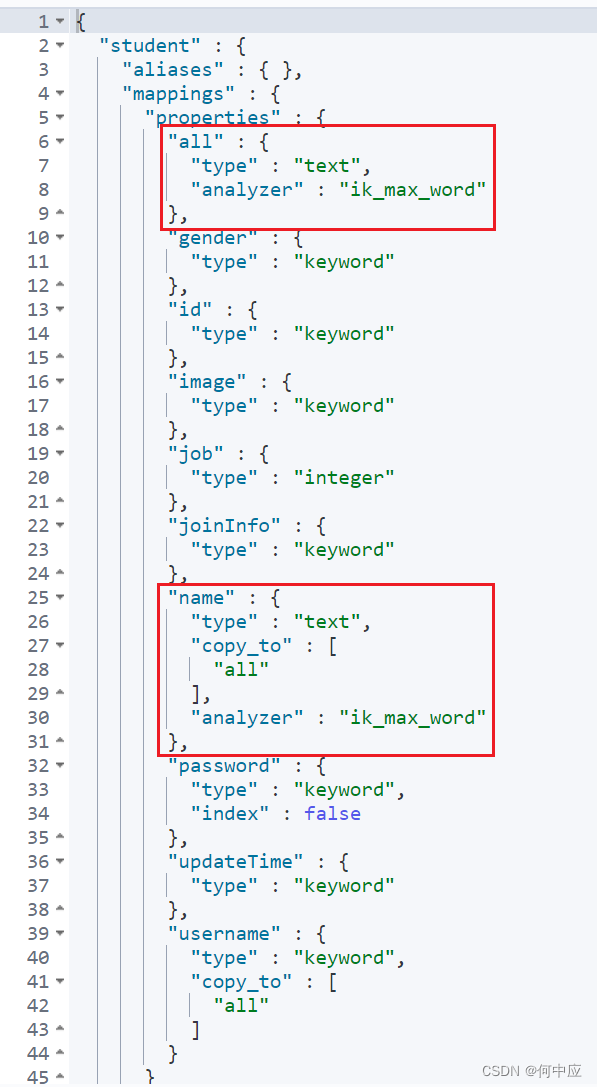
1、模糊查询
模糊查询,是指字段类型是“text”,参与分词的字段,如name、all字段;
(1)全部查询;
格式:
# 1.1 全部查询
GET /索引库名/_search
{"query": {"match_all": {}}
}
可以看到,13条文档都查询出来了;
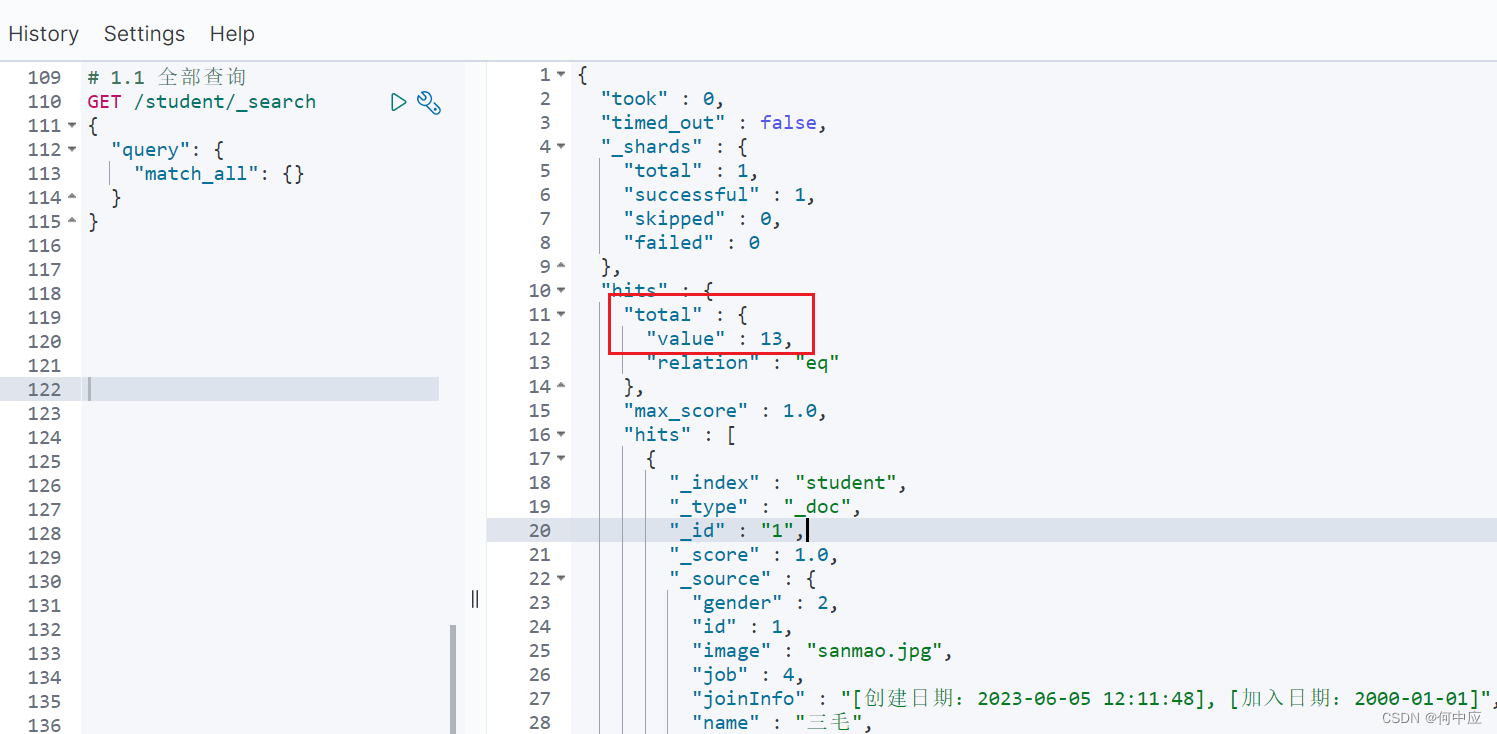
(2)单字段查询;
格式:
# 1.2 单字段查询
GET /索引库名/_search
{"query": {"match": {"字段名": "字段值"}}
}
查询结果:
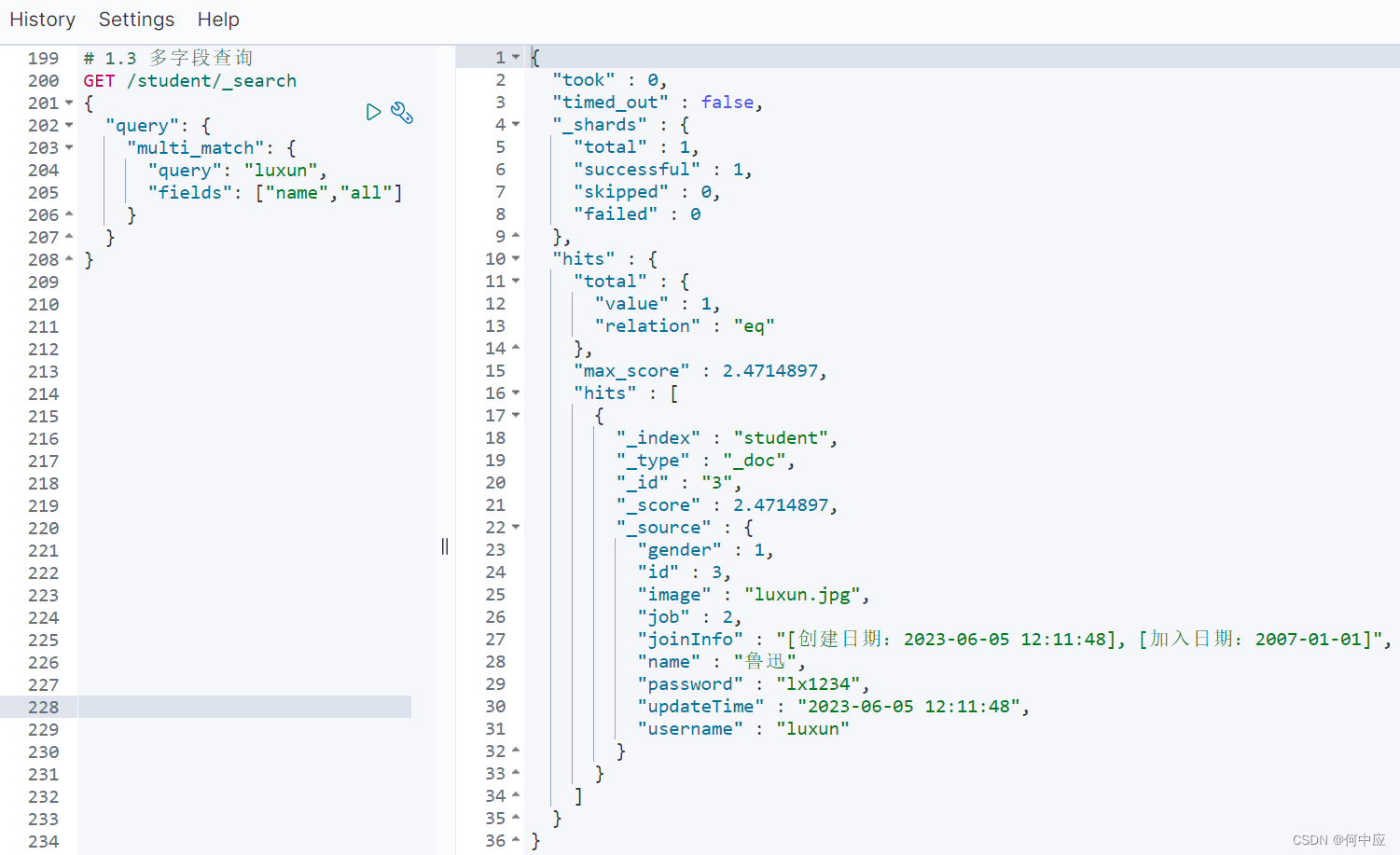
(3)多字段查询;
格式:
# 1.3 多字段查询
GET /索引库名/_search
{"query": {"multi_match": {"query": "字段值","fields": ["字段名1","字段名2"]}}
}
查询结果:
2、精确查询
精确查询,用于等值判断的文档,即查询的值等于文档中对应字段的值,有两种,分别是term、range;
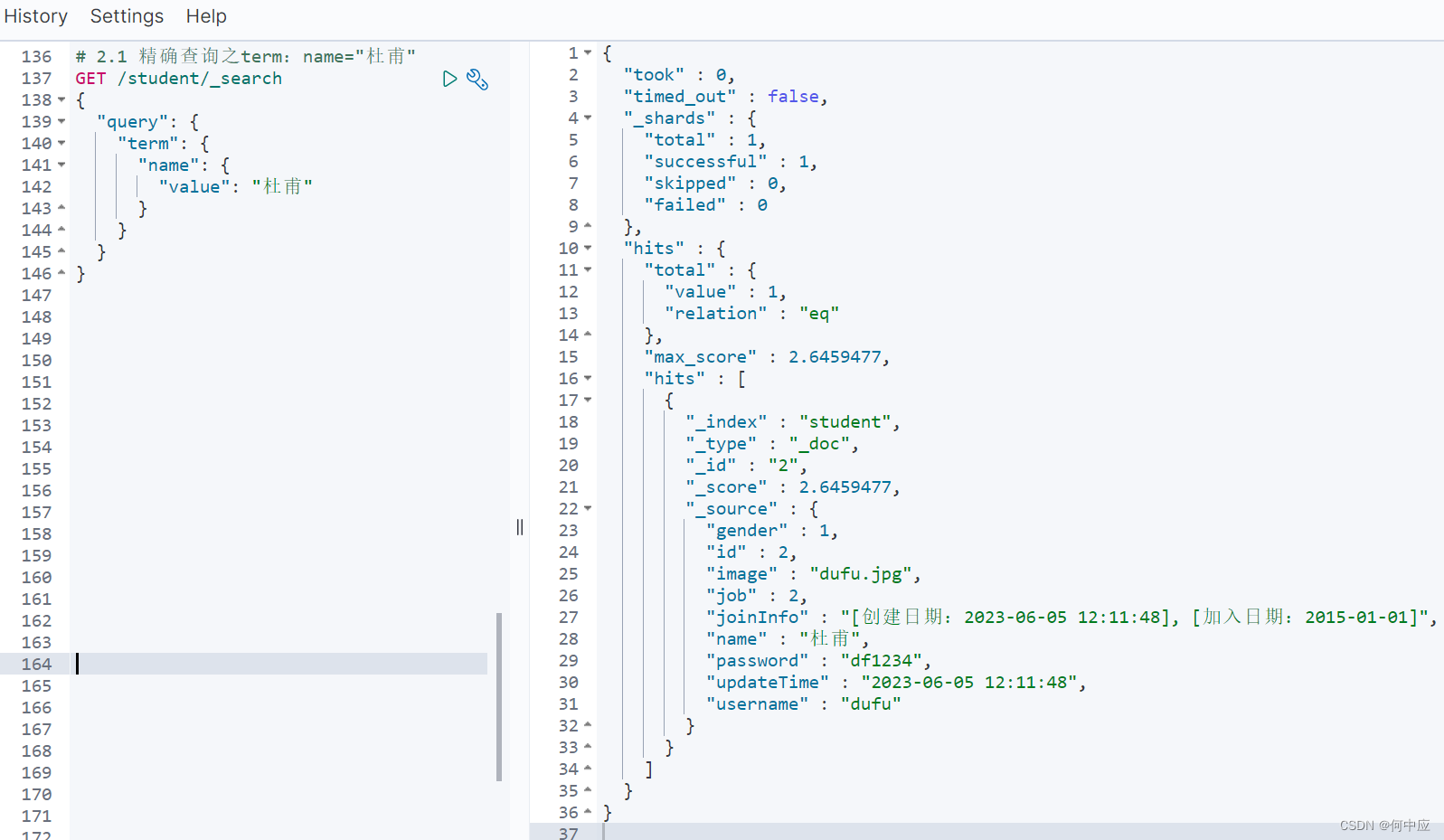
(1)term查询;
格式:
GET /索引库/_search
{"query": {"term": {"字段名": {"value": "字段值"}}}
}
查询结果:
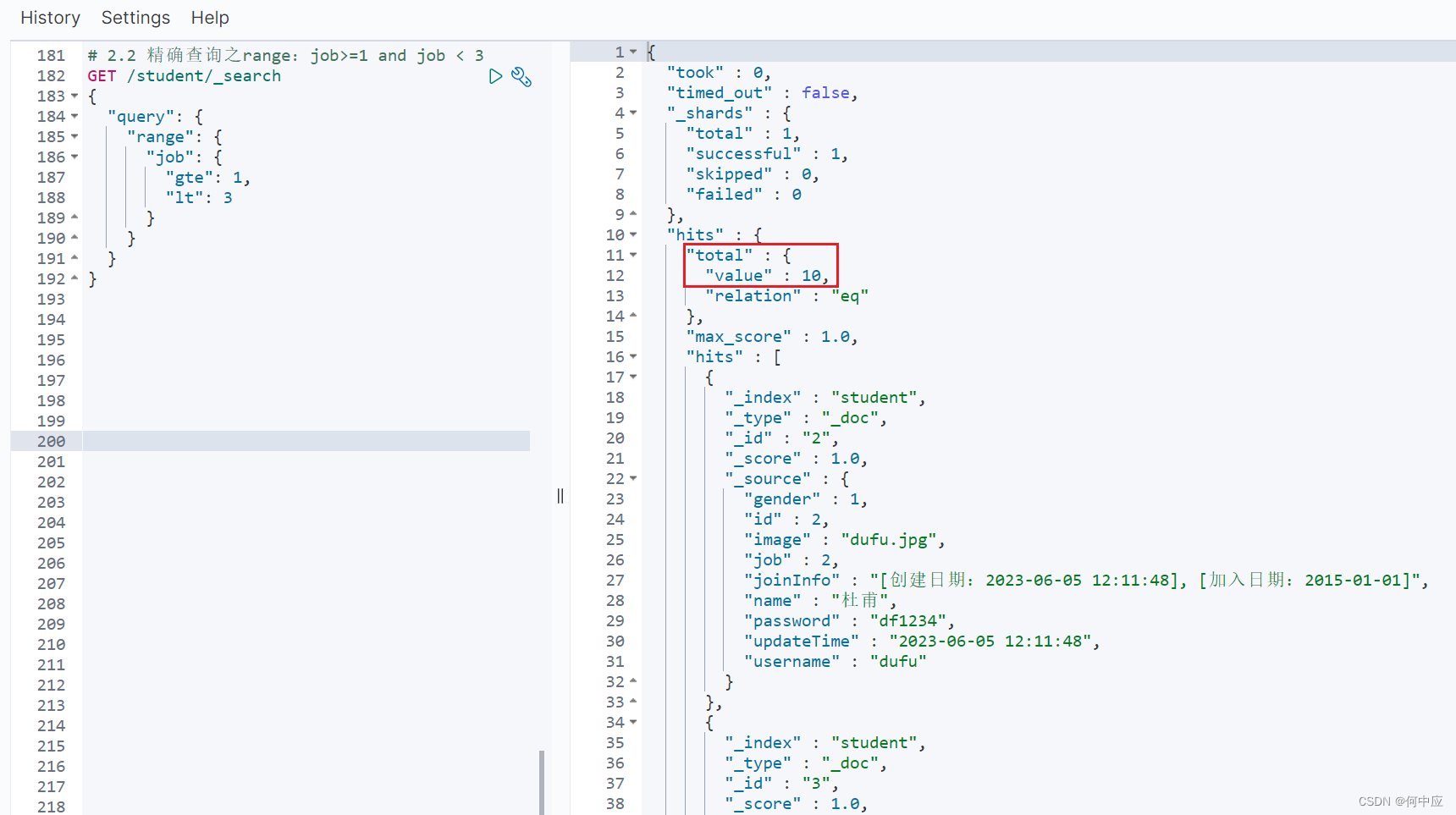
(2)range查询;
格式:
# 2.2 精确查询之range:job>=1 and job < 3
GET /索引库名/_search
{"query": {"range": {"字段名": {"gte": 字段值≥,"lt": 字段值<}}}
}
查询结果:
3、地理坐标查询
es提供了地理坐标数据类型(如geo_point),如果文档中有由经纬度组成的位置数据,可以针对文档中的经纬度坐标查询,有两种方式:
(1)矩形范围;
根据提供的两个位置,画出一个矩形,查询位置在这个矩形内的文档;
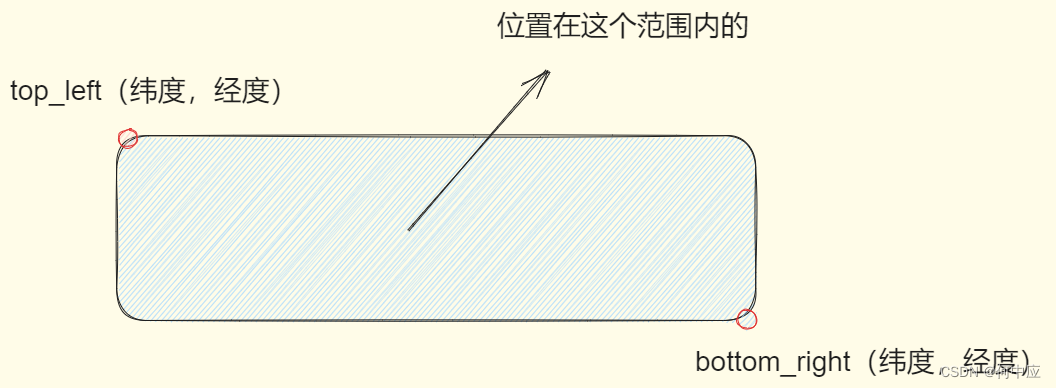
格式:
GET /索引库名/_search
{"query": {"geo_bounding_box":{"location":{"top_left":{"lat":左上角位置纬度,"lon":左上角位置经度},"bottom_right":{"lat":右下角位置纬度,"lon":右下角位置经度}}}}
}
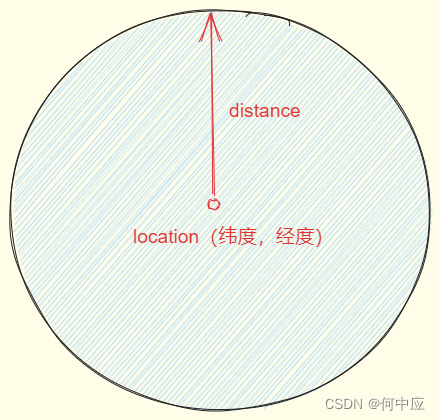
(2)方圆范围;
根据提供的一个位置,一个距离,以位置为圆心,距离为半径,查询该位置方圆范围的文档;
格式:
# 3.2 地理查询值geo_distance
GET /索引库名/_search
{"query": {"geo_distance":{"distance":"距离","location":"纬度,经度"}}
}
距离可以可以写任意长度单位,如15km,15000m;
4、复合查询
(1)算分查询;
查询的每条文档都会有一个分值,这个分值是ES根据BM25公式计算得出的,查询结果会按照分值从高到低排序,我们可以根据文档中的条件,来手动调整该分值,使分值高的文档排在最前面;
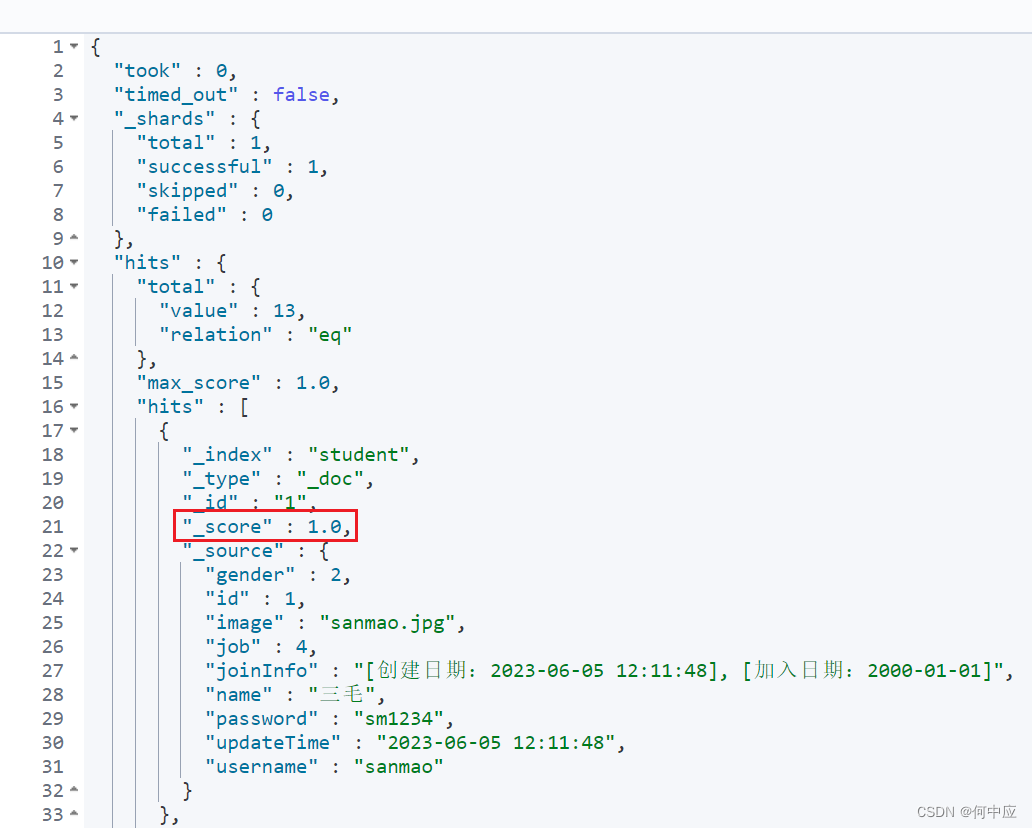
比如,我们把ID为13的文档,手动修改分值,使其排在最前面;
格式:
# 4.1 算分查询
GET /student/_search
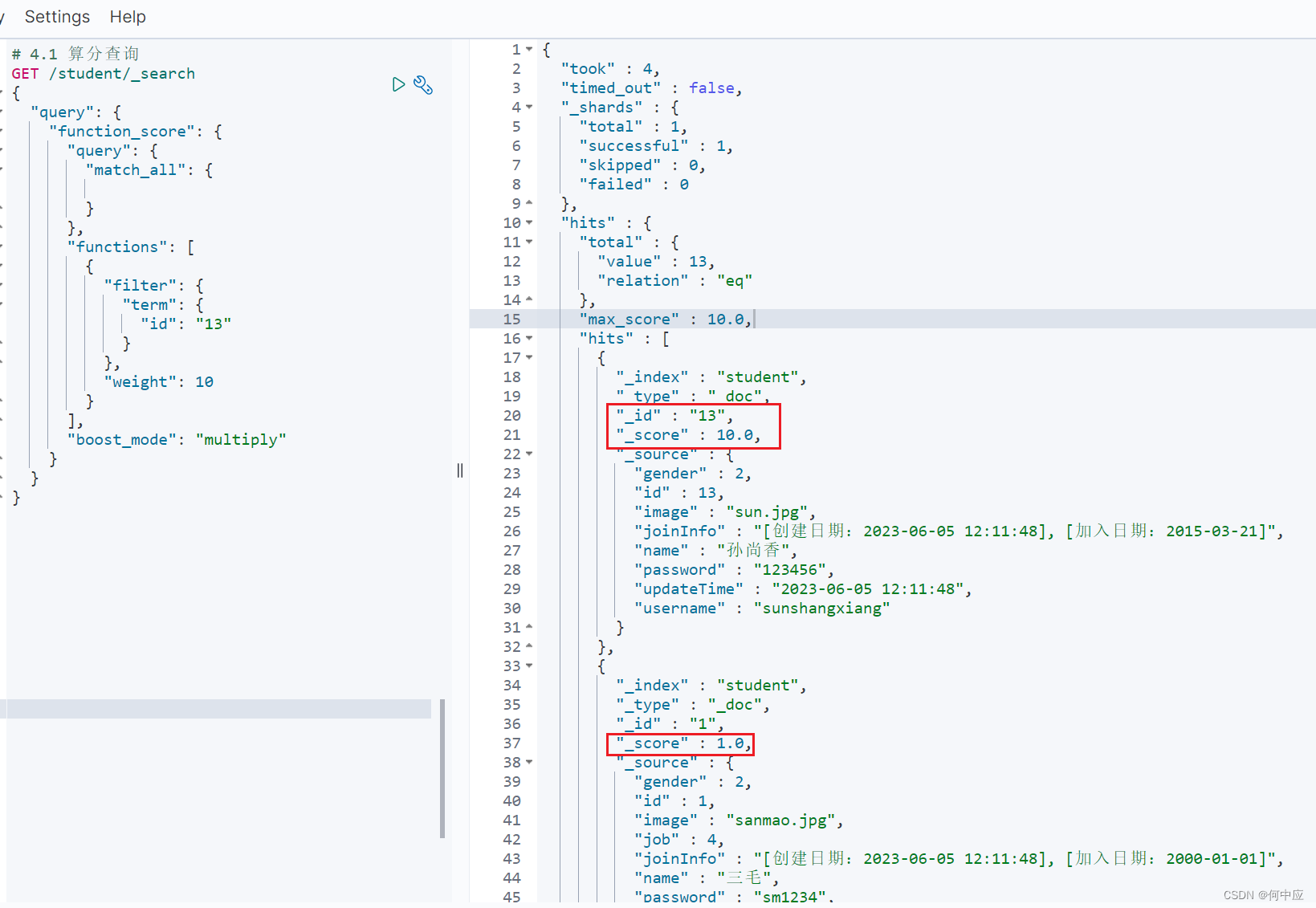
{"query": {"function_score": {"query": {# 查询"match_all": {}},"functions": [{"filter": {# 过滤"term": {"id": "13"}},# 设置权重"weight": 10}],# 加权模式,即最终分值 = 查询分值 ? 权重的运算符,multiply为乘"boost_mode": "multiply"}}
}
boost_mode常见的有multiply(乘),sum(加),replace(替换,即使用权重替换掉查询分值);
(2)布尔查询;
布尔查询也叫复合查询,指多条件的查询,该查询下有以下四个子查询,可根据实际需要添加:
-
must:必须匹配的子查询,类似“与”;
-
should:选择性匹配子查询,类似“或”;
-
must_not:必须不匹配,不参与算分,类似“非”;
-
filter:必须匹配,不参与算分;
如查询性别为“1”,job不在(2,4]区间内,id为11的文档,all字段可以为123456,DSL语句如下:
# 4.2 布尔查询
GET /student/_search
{"query": {"bool": {# 必须匹配的子查询"must": [{"match": {"gender": "1"}}],# 必须不能匹配的子查询"must_not": [{"range": {"job": {"gt": 2,"lte": 4}}}],# 可以匹配的子查询"should": [{"match": {"all": "123456"}}],# 必须匹配的子查询"filter": [{"term": {"id": "11"}}]}}
}
must、should参与算分,即分值高低决定排序前后顺序;
must_not、filter不参与算分,分值高低无所谓;
5、排序
(1)按位置排序
如果文档字段中有位置/坐标相关的字段,可将查询结果按照位置排序,距离越近排序越靠前;
表示按照提供的位置,距离该位置越近,排序越靠前,当然这取决于order是不是升序(asc);
# 5.1 按照坐标排序
GET /索引库名/_search
{"query": {"match_all": {}}, "sort": [{"_geo_distance": {# 文档中位置相关的字段名、字段值"字段名": {"lat": 纬度,"lon": 经度},# 升序"order": "asc",# 距离单位"unit": "km"}}]
}
(2)按字段值排序
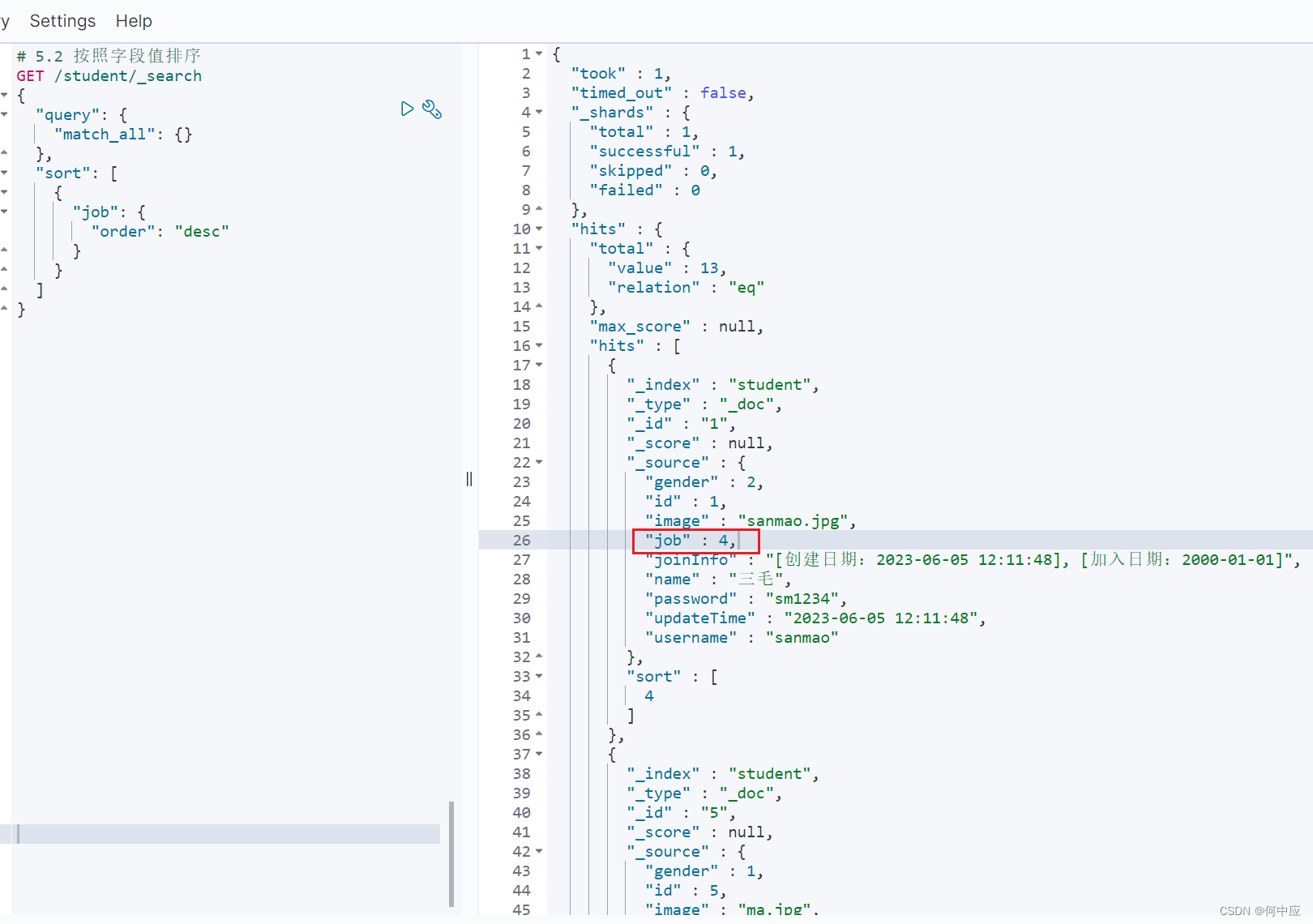
如按照job的值降序,越高排序越靠前;
格式:
# 5.2 按照字段值排序
GET /索引库名/_search
{"query": {"match_all": {}},"sort": [{"字段名": {"order": "desc"}}]
}
查询结果,job越高排序越靠前;
(3)按多个字段值排序
如果有多个值参与排序,可在sort里面按照顺序写多个值;
如按照job降序,job相同再按照gender升序;
格式:
# 5.3 按照多个字段值排序
GET /索引库名/_search
{"query": {"match_all": {}},"sort": [{"字段值1": {"order": "desc"},"字段值2": {"order": "asc"}}]
}
也可以写在外面的大括号里面,效果一样,如下:
# 5.3 按照多个字段值排序
GET /索引库名/_search
{"query": {"match_all": {}},"sort": [{"字段值1": {"order": "desc"}},{"字段值2": {"order": "asc"}}]
}
6、分页
es默认查询只显示前10条,可以使用分页输出,输出更多内容;目前es常用的分页有两种方式:
-
方式一:指定起始(from)、条数分页(size);
-
方式二:基于上一次查询(search_after)的结果,取值作为参数,设置条数,分页查询;
(1)方式一:
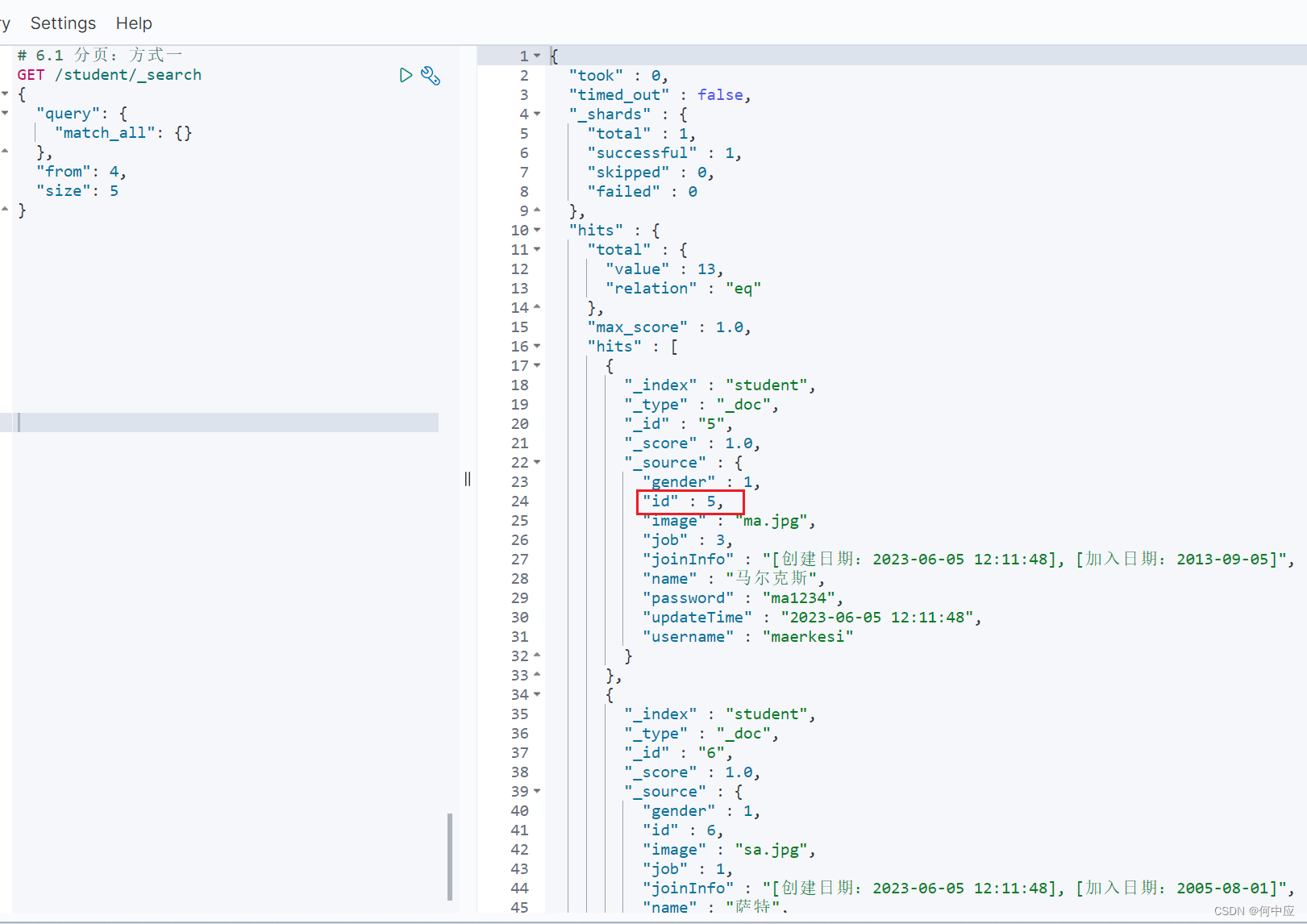
如查询起始ID为5,条数为5的文档内容;
# 6.1 分页:方式一
GET /student/_search
{"query": {"match_all": {}},"from": 起始位置,"size": 条数
}
注意from的值是从0开始计算的,所以需要 - 1;
(2)方式二
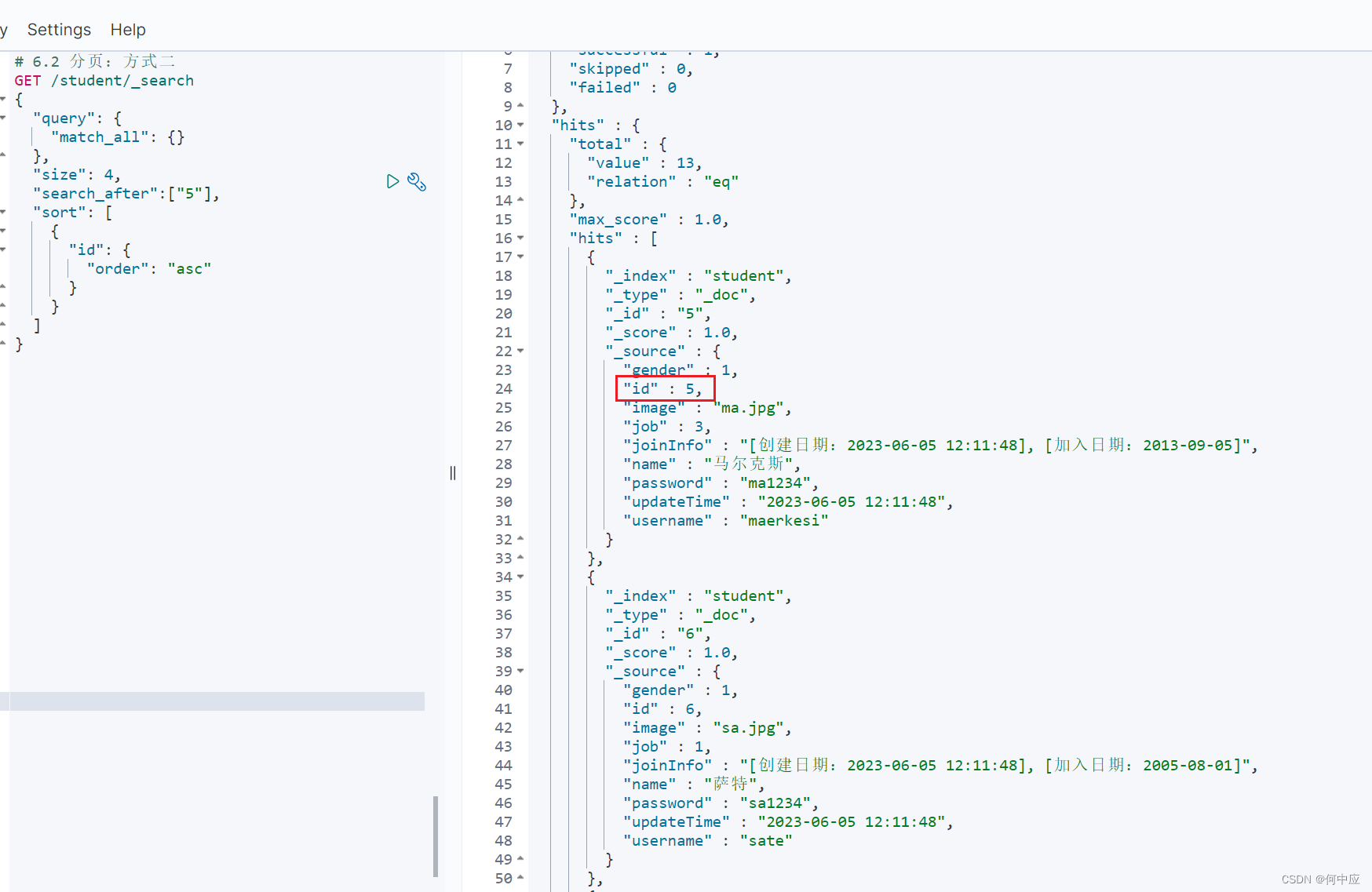
如方式一中,可以取出查询结果中的ID值,作为search_after的参数,往后查询4条
# 6.2 分页:方式二
GET /student/_search
{"query": {"match_all": {}},"size": 4,"search_after":["5"],"sort": [{"id": {"order": "asc"}}]
}
查询结果:
小结
- 方式一查询,需要注意 from + size不能超过10000 ,不然会报错;
(4 + 9996 = 10000 不会报错)
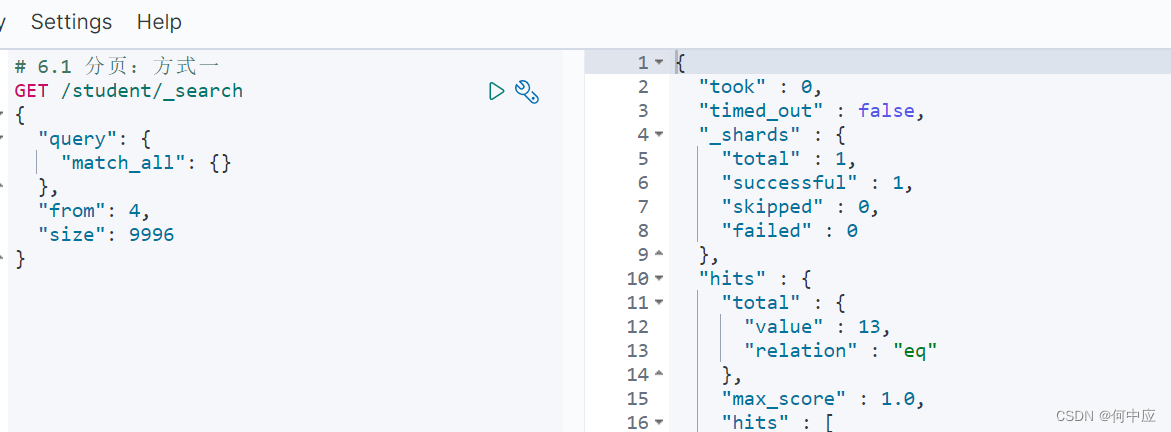
(4 + 9997 = 10001 超过10000报错)

方式二(search_after)分页查询,需要注意,字段尽量使用主键字段或者唯一字段,不然在设置上次查询的值时,该值如果在上次查询的结果中有多条,会选择最后一条文档作为search_after的位置,这样可能会跳过一些文档。
7、高亮
高亮是指对查询的结果,可选择字段特殊显示。如百度中查询的结果,关键字会呈红色字体显示,具体实现就是把关键词前后加一个css样式;
例如我这里把查询的结果,name字段斜体显示,如下:
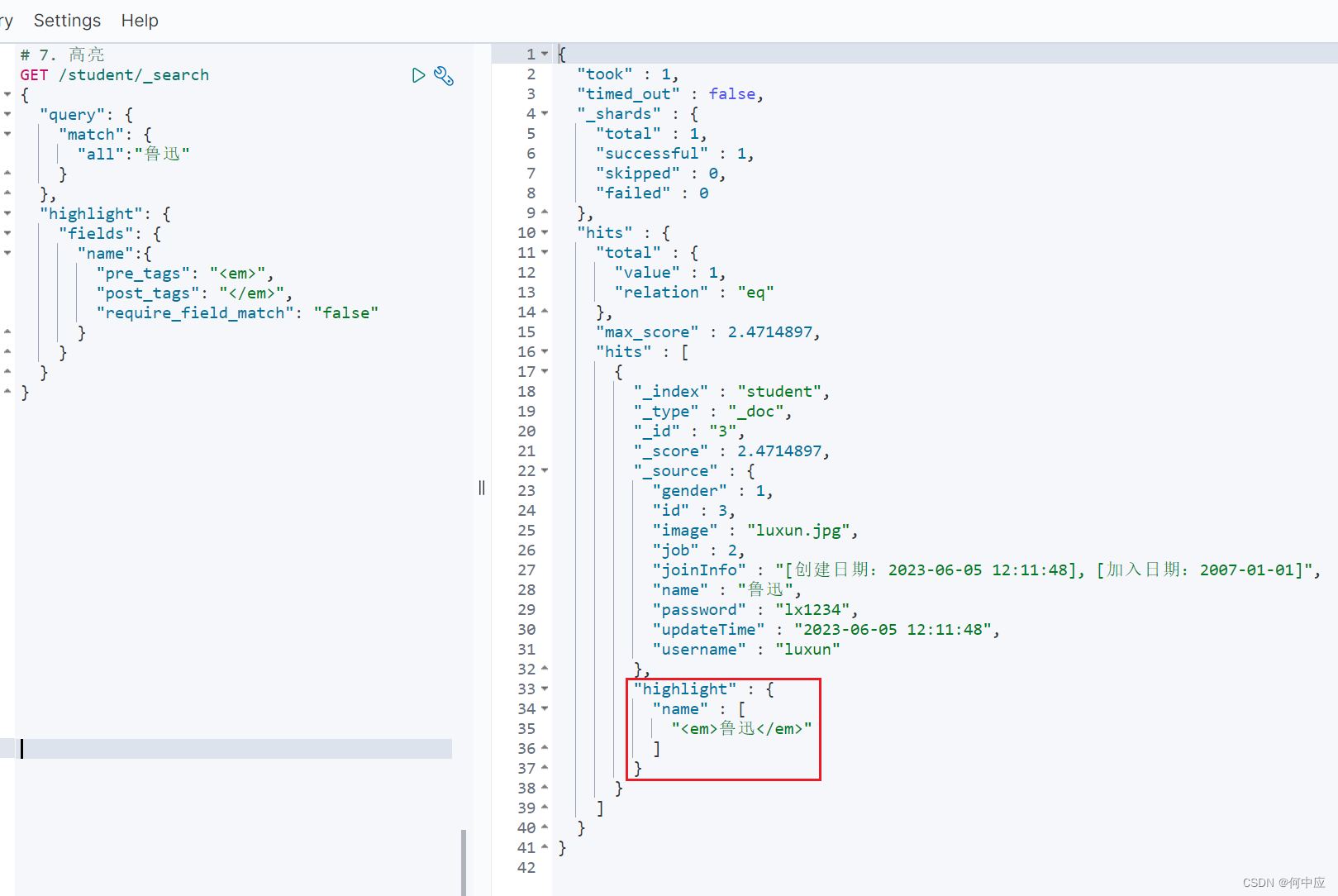
# 7. 高亮
GET /student/_search
{"query": {"match": {"all":"鲁迅"}},"highlight": {"fields": {"name":{# 关键词前"pre_tags": "<em>",# 关键词后"post_tags": "</em>",# 此字段是否为match匹配的字段,选择false,因为我上面没有按照name进行匹配查找"require_field_match": "false"}}}
}
查询结果可以看到,鲁迅前后被em标签包裹
总结
以上DSL语句不可直接复制使用
相关文章:
elasticsearch查询操作(DSL语句方式)
说明:本文介绍在kibana,es的可视化界面上对文档的查询操作; 添加数据 先使用API,创建索引库,并且把数据从MySQL中查出来,传到ES上,参考(http://t.csdn.cn/NaTHg) 索引库…...

JavaScript详解
目录 一、JavaScript是什么? 1.1、JavaScript 和 HTML 和 CSS 之间的关系 1.2、JavaScript 运行过程 1.3、JavaScript 的组成 二、JavaScript 的书写形式 1. 行内式 2. 内嵌式 3、外部式 注释 三、输入输出 输入: prompt 输出: alert 输出: …...
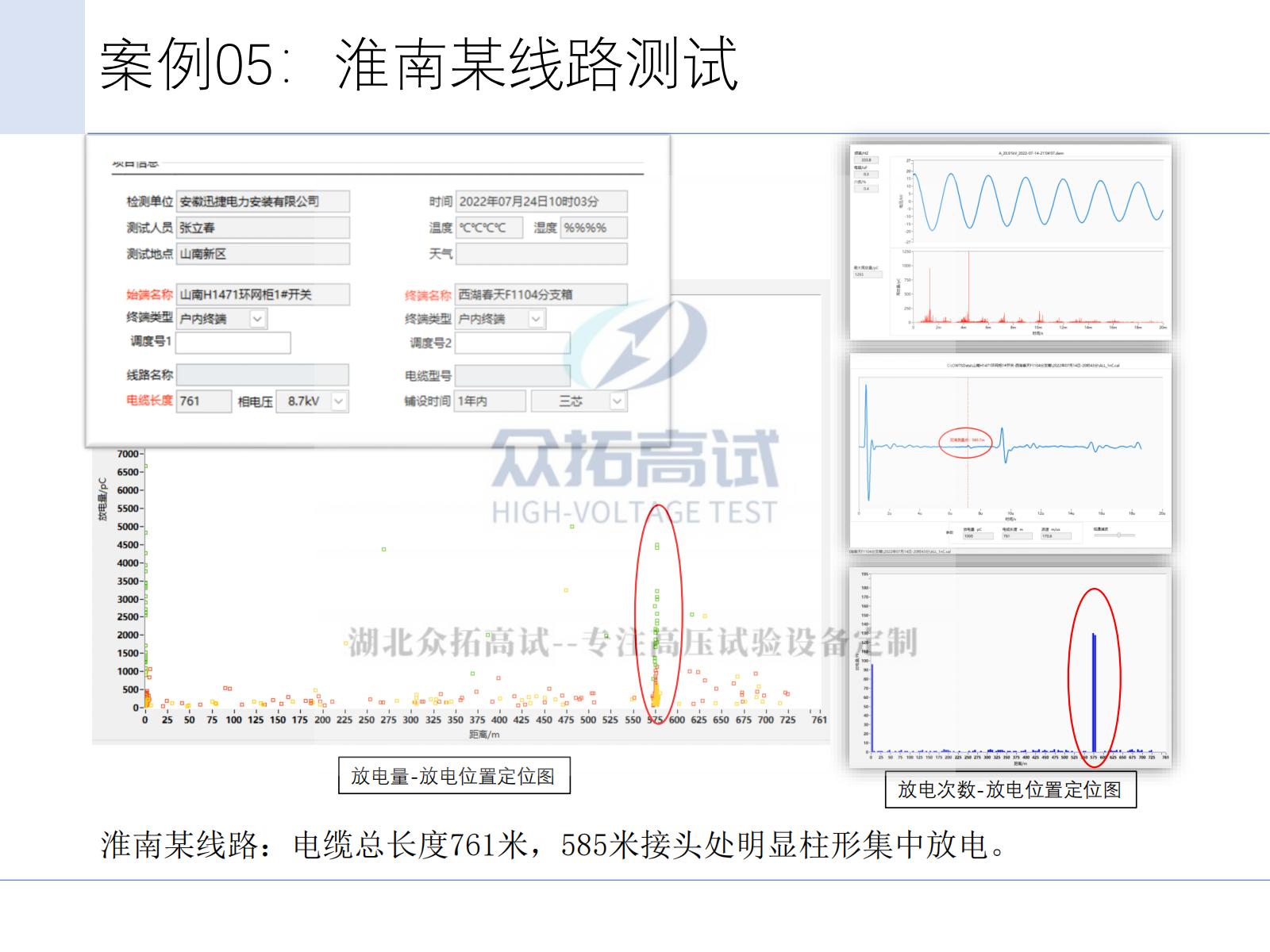
电缆振荡波局部放电检测定位技术
电缆振荡波检测技术主要用于交联聚乙烯电力电缆检测,是属于离线检测的一种有效形式 。该技术基于LCR阻尼振荡原理,在完成电缆直流充电的基础上,通过内置的高压电抗器、高压实时固态开关与试品电缆形成阻尼振荡电压波,在试品电缆上…...
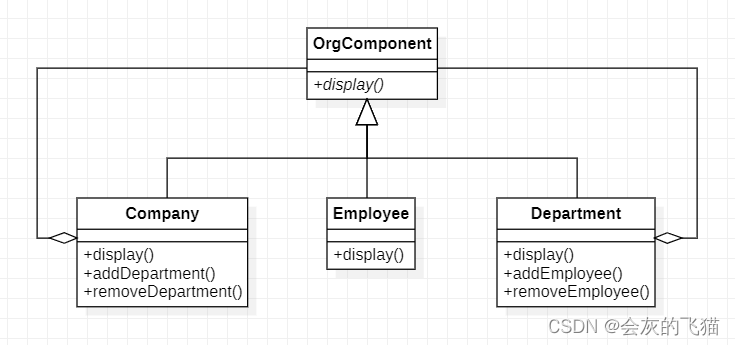
AI Chat 设计模式:10. 组合模式
本文是该系列的第八篇,采用问答式的方式展开,问题由我提出,答案由 Chat AI 作出,灰色背景的文字则主要是我的一些思考和补充。 问题列表 Q.1 给我介绍一下组合模式A.1Q.2 好的,给我举一个组合模式的例子,使…...
【Nginx12】Nginx学习:HTTP核心模块(九)浏览器缓存与try_files
Nginx学习:HTTP核心模块(九)浏览器缓存与try_files 浏览器缓存在 Nginx 的 HTTP 核心模块中其实只有两个简单的配置,这一块也是 HTTP 的基础知识。之前我们就一直在强调,学习 Nginx 需要的就是各种网络相关的基础知识&…...

【1】-Locust性能测试工具介绍与安装
Locust介绍 locust是一个开源的压测工具,其官网地址是Locust - A modern load testing framework,通过编写Python代码,可以轻松实现百万级的并发,相对于我们熟悉的Jmeter来说,其对压测机的要求更低,而且使…...
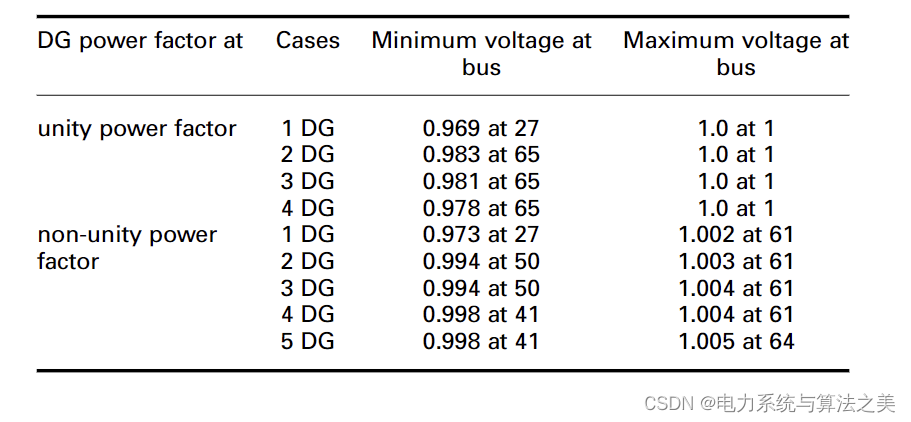
基于拉格朗日-遗传算法的最优分布式能源DG选址与定容(Matlab代码实现)
目录 1 概述 2 数学模型 2.1 问题表述 2.2 DG的最佳位置和容量(解析法) 2.3 使用 GA 进行最佳功率因数确定和 DG 分配 3 仿真结果与讨论 3.1 33 节点测试配电系统的仿真 3.2 69 节点测试配电系统仿真 4 结论 1 概述 为了使系统网损达到最低值&a…...
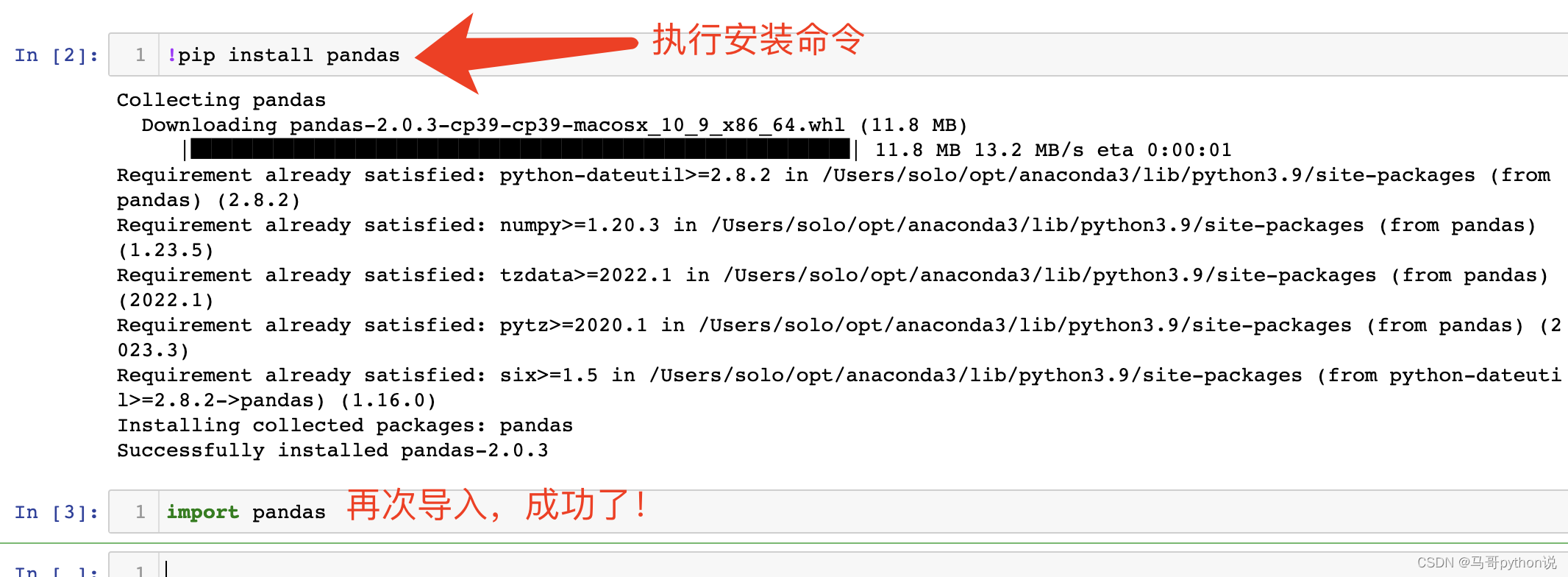
【已解决】jupyter notebook里已经安装了第三方库,还是提示导入失败
在jupyter notebook中运行Python代码,明明已经安装了第三方库,还是提示导入失败。 以导入pandas库为例,其他库同理: 报错代码: import pandas报错原因: 电脑上存在多个python运行环境(比如&a…...
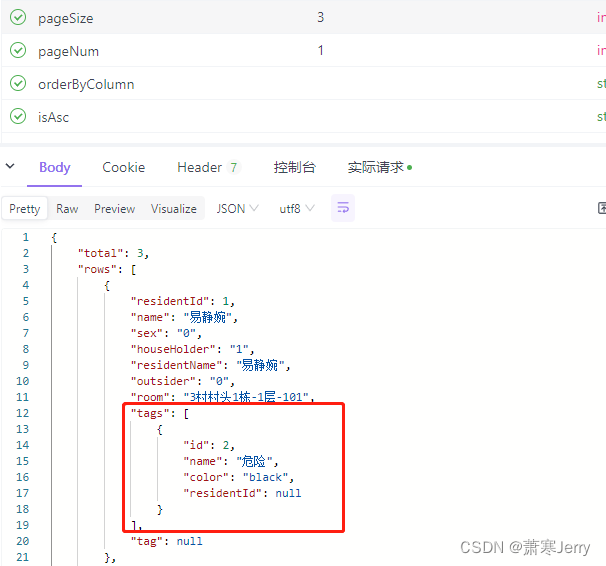
Mybatis使用collection映射一对多查询分页问题
场景:页面展示列表,需要查询多的字段,和一的字段。并且还要分页。 这时候直接想到的是手写sql。 /*** 标签*/private List<BasicResidentTags> tags;Data TableName("basic_resident_tags") public class BasicResidentTag…...

Linux/Windows路由管理
本文主要介绍如果通过linux/Windows命令添加IPV6地址,查看添加IPV6默认路由,查看IPV6邻居缓存 一、Linux 1、查看地址 IPV4: route netstat -route ip route IPV6: ip -6 route show route -A inet6 route -62、添加IPV6地址 ip -6 addr add <…...

openpnp - 设备矫正的零碎记录
文章目录 openpnp - 设备矫正的零碎记录概述笔记设备内部不能有任何强干扰源相机就选100W像素的就行, 没有特殊要求openpnp软件的选择视觉归位必须禁止轴的赤隙矫正不用做运行openpnp软件的计算机, 必须是台式机校验完成后, 数据占用的体积END openpnp - 设备矫正的零碎记录 概…...

Linux内核中的链表、红黑树和KFIFO
lLinux内核代码中广泛使用了链表、红黑树和KFIFO。 一、 链表 linux内核代码大量使用了链表这种数据结构。链表是在解决数组不能动态扩展这个缺陷而产生的一种数据结构。链表所包含的元素可以动态创建并插入和删除。链表的每个元素都是离散存放的,因此不需要占用连…...

【C++】做一个飞机空战小游戏(二)——利用getch()函数实现键盘控制单个字符移动
[导读]本系列博文内容链接如下: 【C】做一个飞机空战小游戏(一)——使用getch()函数获得键盘码值 【C】做一个飞机空战小游戏(二)——利用getch()函数实现键盘控制单个字符移动 在【C】做一个飞机空战小游戏(一)——使用getch()函数获得键盘码值一文中介绍了如何利用…...
)
Android 设备兼容性使用(详细版)
经典好文推荐,通过阅读本文,您将收获以下知识点: 一、设备兼容性分类 二、硬件设备兼容 三、软件 APP 兼容 四、兼容不同语言 五、兼容不同分辨率 六、兼容不同屏幕方向布局 七、兼容不同硬件 Feature 八、兼容不同SDK平台 一、设备兼容性分类 Android设计用于运行在许多不同…...

React 中的常见 API 和生命周期函数
目录 useStateuseEffectuseRefdangerouslySetInnerHTML生命周期函数 constructorcomponentDidMountstatic getDerivedStateFromPropsshouldComponentUpdatecomponentDidUpdatecomponentWillUnmount useState useState 是 React 的一个 Hook,用于在函数组件中添加…...
)
神经网络中遇到的 python 函数(Pytorch)
1.getattr() 函数用于返回一个对象属性值。 def getattr(object, name, defaultNone): # known special case of getattr"""getattr(object, name[, default]) -> valueGet a named attribute from an object; getattr(x, y) is equivalent to x.y.When a …...
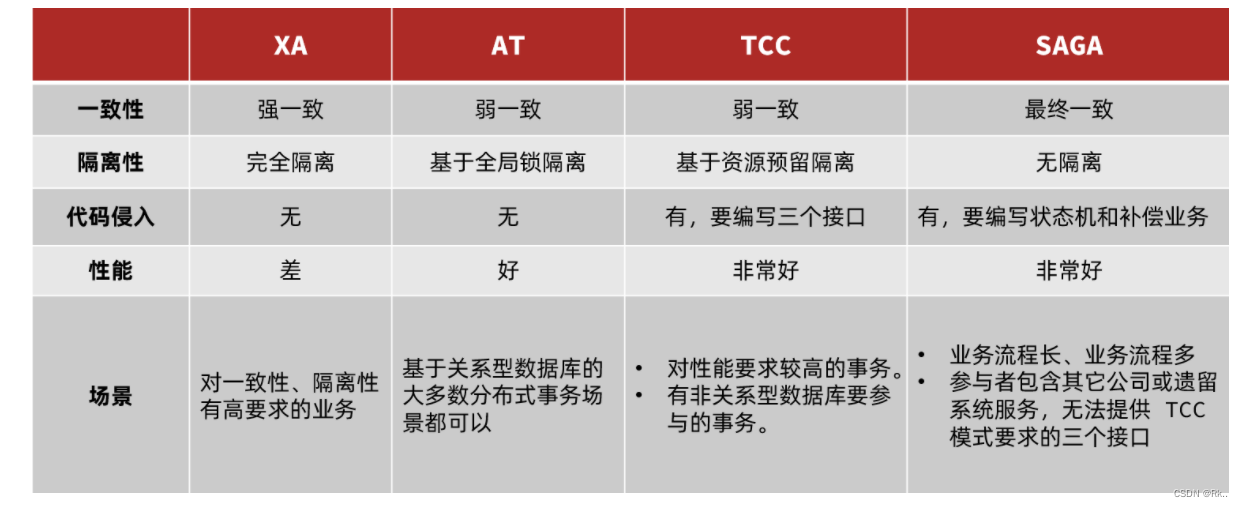
分布式事务及解决方案
1、分布式事务 分布式事务就是在一个交易中各个服务之间的相互调用必须要同时成功或者同时失败,保持一致性和可靠性。在单体项目架构中,在多数据源的情况下也会发生 分布式事务问题。本质上来说,分布式事务就是为了保证不同数据库的数据一致性…...

【宏定义】——编译时校验
文章目录 编译时校验功能描述代码实现示例代码正常编译示例编译错误示例预处理之后的结果 代码解析!!estruct {int:-!!(e); }sizeof(struct {int:-!!(e); }) 参考代码 编译时校验 功能描述 用于在编译时检查一个条件是否为真,如果条件为真则会编译失败,…...

C#学习系列之System.Windows.Data Error: 40报错
C#学习系列之System.Windows.Data Error: 40报错 前言报错内容解决总结 前言 在用户界面使用上,代码运行没有问题,但是后台报错,仔细研究了报错内容,解决问题,所以记录一下。 报错内容 System.Windows.Data Error: 4…...
【java安全】RMI
文章目录 【java安全】RMI前言RMI的组成RMI实现Server0x01 编写一个远程接口0x02 实现该远程接口0x03 Registry注册远程对象 Client 小疑问RMI攻击 【java安全】RMI 前言 RMI全称为:Remote Method Invocation 远程方法调用,是java独立的一种机制。 RM…...

Visual Paradigm 17.0 团队协作新功能实测:手把手教你用项目模板和文件夹管理提效
Visual Paradigm 17.0 团队协作实战指南:从模板配置到文件夹管理的高效工作流在敏捷开发团队中,项目启动速度和资产管理的规范性往往直接影响整体效率。Visual Paradigm 17.0针对这一痛点推出的团队协作增强功能,特别是服务器端项目模板和文件…...

HFSS仿真结果怎么看?以T型波导为例,读懂S参数与电场动态图
HFSS仿真结果深度解析:从S参数到电场动态图的实战指南当你第一次在HFSS中完成T型波导仿真后,面对满屏的曲线和彩色云图,是否感到既兴奋又困惑?那些起伏的S参数曲线究竟告诉你什么信息?电场图中跳跃的颜色又代表怎样的物…...

如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南
如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software developme…...

《我看见的世界:李飞飞自传》第1-6章阅读笔记:从移民少女到AI教母的“看见“之旅
前言 当我们谈论人工智能时,我们谈论的是算法、数据、算力,是那些冰冷的代码和复杂的模型。但在《我看见的世界:李飞飞自传》中,李飞飞用她独特的视角告诉我们:AI的本质,是人类对"看见"世界的渴望…...

FT231XQ USB串口桥接板设计解析与实战应用指南
1. 项目概述:从FT232R到FT231XQ的USB串口桥接板演进在嵌入式开发和硬件调试的日常工作中,一个可靠、小巧且功能清晰的USB转串口(UART)桥接板(Breakout Board, 简称BoB)几乎是工程师手边的标配工…...

Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件
Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件在游戏开发中,UI交互的流畅性和多样性直接影响玩家的游戏体验。想象一下,当你在开发一个RPG游戏的背包系统时,需要实现道具的单击查看详情、双击快速使用、…...

厨房空调技术白皮书:从风冷到水冷,制冷系统在厨房场景中的工程化演进
厨房空调是暖通行业近三年技术迭代最密集的细分品类。从最初的"凉霸"(本质是风扇),到风冷分体式,再到水冷一体式,每代技术都在解决上一代没有覆盖的用户痛点。本文以工程技术视角,梳理四代厨房制…...

百度文心一言开发者如何通过Taotoken低成本接入多模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 百度文心一言开发者如何通过Taotoken低成本接入多模型API 对于已经熟悉并正在使用百度文心一言等国产大模型API的开发者而言&#…...

基于ESP8266与MQTT的家庭水压自动控制系统设计与实现
1. 项目概述与核心需求解析家里水压不稳、供水时断时续,这大概是很多朋友都遇到过的烦心事。我所在的城市供水情况就很不理想,为了解决这个问题,我不得不自己动手,搭建了一套基于ESP8266微控制器的家庭水压增压与储水自动控制系统…...

基于PIC32的嵌入式MIDI合成器:从波表合成到硬件实现
1. 项目概述:一个基于嵌入式微控制器的MIDI声音合成器如果你对电子音乐制作、嵌入式开发,或者DIY硬件合成器感兴趣,那么“REMI Synth”这个项目绝对值得你花时间深入了解。它本质上是一个数字单音MIDI控制的声音合成器,核心是一块…...