SpringBoot 集成 Kafka
SpringBoot 集成 Kafka
- 1 安装 Kafka
- 2 创建 Topic
- 3 Java 创建 Topic
- 4 SpringBoot 项目
- 4.1 pom.xml
- 4.2 application.yml
- 4.3 KafkaApplication.java
- 4.4 CustomizePartitioner.java
- 4.5 KafkaInitialConfig.java
- 4.6 SendMessageController.java
- 5 测试
1 安装 Kafka
Docker 安装 Kafka
2 创建 Topic
创建两个topic:topic1、topic2,其分区和副本数都设置为1 (可以在Java代码中创建)
PS C:\Users\Administrator> docker exec -it kafka /bin/sh$ kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic topic1
Created topic topic1.$ kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic topic2
Created topic topic2.
3 Java 创建 Topic
package com.xu.mq.demo.test.service;import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import org.apache.kafka.clients.admin.NewTopic;/*** kafka 初始化配置类 创建 Topic** @author Administrator* @date 2023年2月17日11点30分*/
@Configuration
public class KafkaInitialConfig {public static final String AUDIO_UPLOAD_TOPIC = "AudioUploadTopic";public static final String TEXT_UPLOAD_TOPIC = "TextUploadTopic";@Beanpublic NewTopic audioUploadTopic() {return new NewTopic(AUDIO_UPLOAD_TOPIC, 1, (short) 1);}@Beanpublic NewTopic textUploadTopic() {return new NewTopic(TEXT_UPLOAD_TOPIC, 1, (short) 1);}}
4 SpringBoot 项目
4.1 pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.8</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.xu</groupId><artifactId>kafka</artifactId><version>0.0.1-SNAPSHOT</version><name>kafka</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version></properties><dependencies><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.12</version></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build></project>
4.2 application.yml
server:port: 8001spring:application:name: hello-kafkakafka:# 以逗号分隔的地址列表,用于建立与Kafka集群的初始连接(kafka 默认的端口号为9092)bootstrap-servers: 192.168.1.92:9092producer:# 发生错误后,消息重发的次数。retries: 0#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。batch-size: 16384# 设置生产者内存缓冲区的大小。buffer-memory: 33554432# 键的序列化方式key-serializer: org.apache.kafka.common.serialization.StringSerializer# 值的序列化方式value-serializer: org.apache.kafka.common.serialization.StringSerializer# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。acks: allconsumer:# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5Dauto-commit-interval: 1S# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录auto-offset-reset: earliest# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量enable-auto-commit: true# 键的反序列化方式key-deserializer: org.apache.kafka.common.serialization.StringDeserializer# 值的反序列化方式value-deserializer: org.apache.kafka.common.serialization.StringDeserializerlistener:# 在侦听器容器中运行的线程数。concurrency: 4
4.3 KafkaApplication.java
package com.xu.mq.demo;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.kafka.annotation.EnableKafka;/*** @author Administrator*/
@EnableKafka
@SpringBootApplication
public class KafkaApplication {public static void main(String[] args) {SpringApplication.run(DemoApplication.class, args);}}
4.4 CustomizePartitioner.java
package com.xu.kafka.config;import java.util.Map;import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;/*** @author Administrator*/
public class CustomizePartitioner implements Partitioner {/*** 自定义分区规则** @param topic The topic name* @param key The key to partition on (or null if no key)* @param keyBytes The serialized key to partition on( or null if no key)* @param value The value to partition on or null* @param valueBytes The serialized value to partition on or null* @param cluster The current cluster metadata* @return*/@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {return 0;}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}}
4.5 KafkaInitialConfig.java
package com.xu.kafka.config;import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import org.apache.kafka.clients.admin.NewTopic;/*** kafka 初始化配置类 创建 Topic** @author Administrator* @date 2023年2月17日11点30分*/
@Configuration
public class KafkaInitialConfig {public static final String AUDIO_UPLOAD_TOPIC = "AudioUploadTopic";public static final String TEXT_UPLOAD_TOPIC = "TextUploadTopic";@Beanpublic NewTopic audioUploadTopic() {return new NewTopic(AUDIO_UPLOAD_TOPIC, 1, (short) 1);}@Beanpublic NewTopic textUploadTopic() {return new NewTopic(TEXT_UPLOAD_TOPIC, 1, (short) 1);}}
4.6 SendMessageController.java
package com.xu.kafka.message.controller;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;import com.xu.kafka.config.KafkaInitialConfig;import cn.hutool.json.JSONUtil;/*** @author Administrator*/
@RequestMapping(value = "/kafka")
@RestController
public class SendMessageController {@Autowiredprivate KafkaTemplate template;/*** KafkaTemplate 发送消息** @param message*/@GetMapping("/test1/{message}")public void test1(@PathVariable("message") String message) {template.send(KafkaInitialConfig.AUDIO_UPLOAD_TOPIC, message);}/*** KafkaTemplate 发送消息 有回调** @param message*/@GetMapping("/test2/{message}")public void test2(@PathVariable("message") String message) {template.send(KafkaInitialConfig.AUDIO_UPLOAD_TOPIC, message).addCallback(success -> {System.out.println("发送成功\t" + success);}, fail -> {System.out.println("发送失败\t" + fail);});}
}
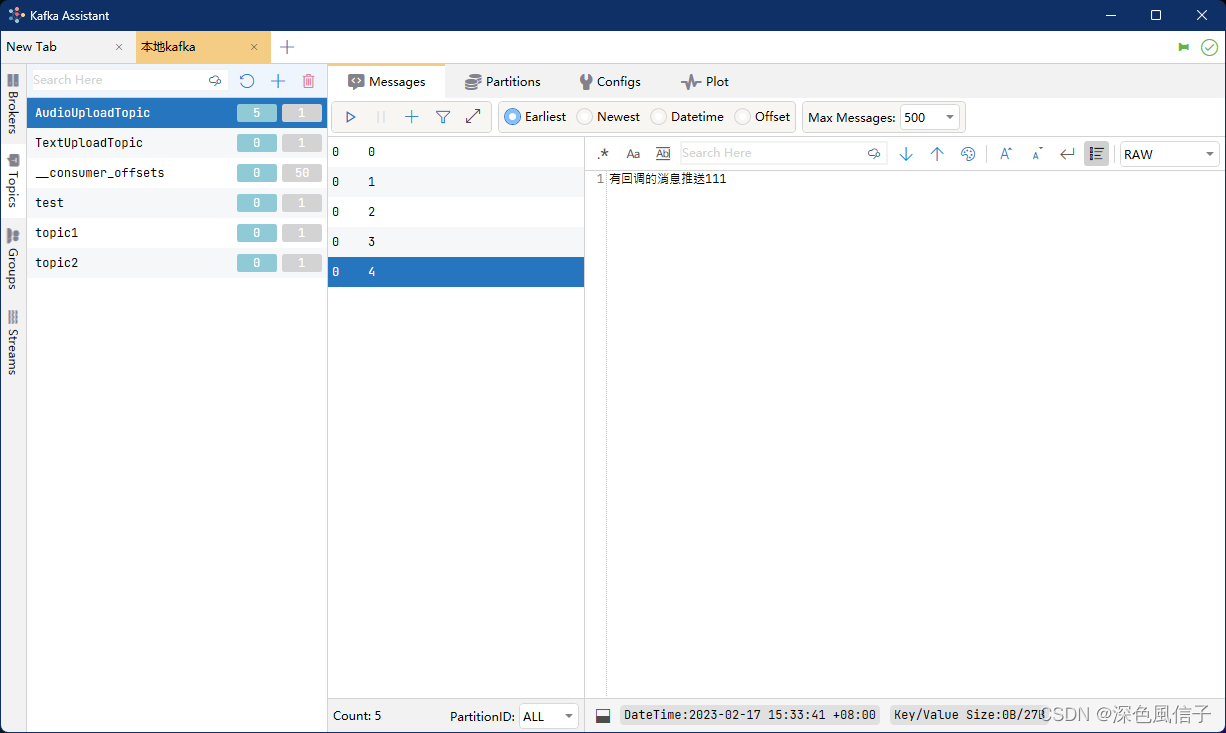
5 测试
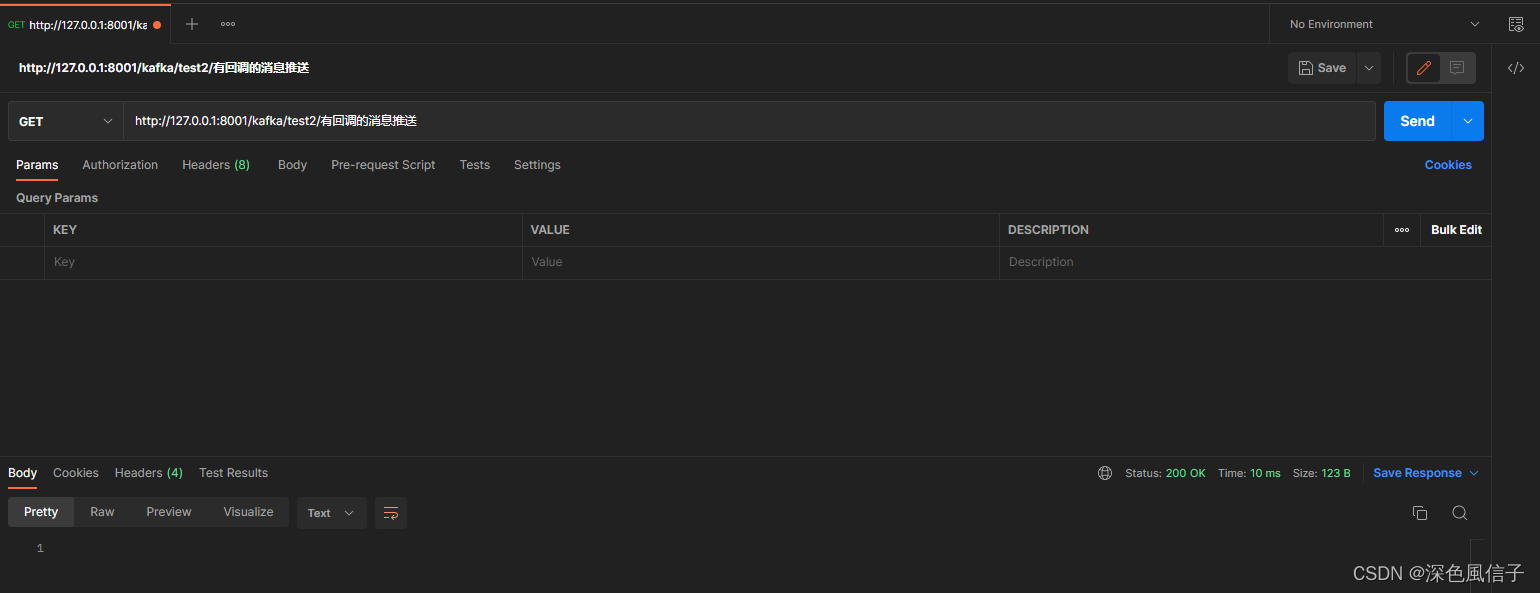
发送成功 SendResult [producerRecord=ProducerRecord(topic=AudioUploadTopic, partition=null, headers=RecordHeaders(headers = [], isReadOnly = true), key=null, value=有回调的消息推送111, timestamp=null), recordMetadata=AudioUploadTopic-0@4]
相关文章:
SpringBoot 集成 Kafka
SpringBoot 集成 Kafka1 安装 Kafka2 创建 Topic3 Java 创建 Topic4 SpringBoot 项目4.1 pom.xml4.2 application.yml4.3 KafkaApplication.java4.4 CustomizePartitioner.java4.5 KafkaInitialConfig.java4.6 SendMessageController.java5 测试1 安装 Kafka Docker 安装 Kafk…...

OpenCV 图像金字塔算子
本文是OpenCV图像视觉入门之路的第14篇文章,本文详细的介绍了图像金字塔算子的各种操作,例如:高斯金字塔算子 、拉普拉斯金字塔算子等操作。 高斯金字塔中的较高级别(低分辨率)是通过先用高斯核对图像进行卷积再删除偶…...

【自学Linux】Linux一切皆文件
Linux一切皆文件 Linux一切皆文件教程 Linux 中所有内容都是以文件的形式保存和管理的,即一切皆文件,普通文件是文件,目录是文件,硬件设备(键盘、监视器、硬盘、打印机)是文件,就连套接字&…...

CUDA C++扩展的详细描述
CUDA C扩展的详细描述 文章目录CUDA C扩展的详细描述CUDA函数执行空间说明符B.1.1 \_\_global\_\_B.1.2 \_\_device\_\_B.1.3 \_\_host\_\_B.1.4 Undefined behaviorB.1.5 __noinline__ and __forceinline__B.2 Variable Memory Space SpecifiersB.2.1 \_\_device\_\_B.2.2. \_…...

为什么重写equals必须重写hashCode
关于这个问题,看了网上很多答案,感觉都参差不齐,没有答到要点,这次就记录一下! 首先我们为什么要重写equals?这个方法是用来干嘛的? public boolean equals (Object object&#x…...

< 每日小技巧:N个很棒的 Vue 开发技巧, 持续记录ing >
每日小技巧:6 个很棒的 Vue 开发技巧👉 ① Watch 妙用> watch的高级使用> 一个监听器触发多个方法> watch 监听多个变量👉 ② 自定义事件 $emit() 和 事件参数 $event👉 ③ 监听组件生命周期常规写法hook写法ὄ…...

数据结构与算法之二分查找分而治之思想
决定我们成为什么样人的,不是我们的能力,而是我们的选择。——《哈利波特与密室》二分查找是查找算法里面是很优秀的一个算法,特别是在有序的数组中,这种算法思想体现的淋漓尽致。一.题目描述及其要求请实现无重复数字的升序数组的…...
训练自己的中文word2vec(词向量)--skip-gram方法
训练自己的中文word2vec(词向量)–skip-gram方法 什么是词向量 将单词映射/嵌入(Embedding)到一个新的空间,形成词向量,以此来表示词的语义信息,在这个新的空间中,语义相同的单…...

ubuntu系统环境配置和常用软件安装
系统环境 修改文件夹名称为英文 参考链接 export LANGen_US xdg-user-dirs-gtk-update 常用软件安装 常用工具 ping 和ifconfig工具 sudo apt install -y net-tools inetutils-ping 截图软件 sudo apt install -y net-tools inetutils-ping flameshot 录屏 sudo apt-get i…...
【1139. 最大的以 1 为边界的正方形】
来源:力扣(LeetCode) 描述: 给你一个由若干 0 和 1 组成的二维网格 grid,请你找出边界全部由 1 组成的最大 正方形 子网格,并返回该子网格中的元素数量。如果不存在,则返回 0。 示例 1&#…...
windows11安装sqlserver2022报错
window11安装SQL Server 2022 报错 糟糕… 无法安装SQL Server (setup.exe)。此 SQL Server安装程序介质不支持此OS的语言,或没有SQL Server英语版本的安装文件。请使用匹配的特定语言SQL Server介质;或安装两个特定语言MUI,然后通过控制面板的区域设置…...

Python快速上手系列--日志模块--详解篇
前言本篇主要说说日志模块,在写自动化测试框架的时候我们就需要用到这个模块了,方便我们快速的定位错误,了解软件的运行情况,更加顺畅的调试程序。为什么要用到日志模块,直接print不就好了!那得写多少print…...

【THREE.JS学习(1)】绘制一个可以旋转、放缩的立方体
学习新技能,做一下笔记。在使用ThreeJS的时候,首先创建一个场景const scene new THREE.Scene();接着,创建一个相机其中,THREE.PerspectiveCamera()四个参数分别为:1.fov 相机视锥体竖直方向视野…...
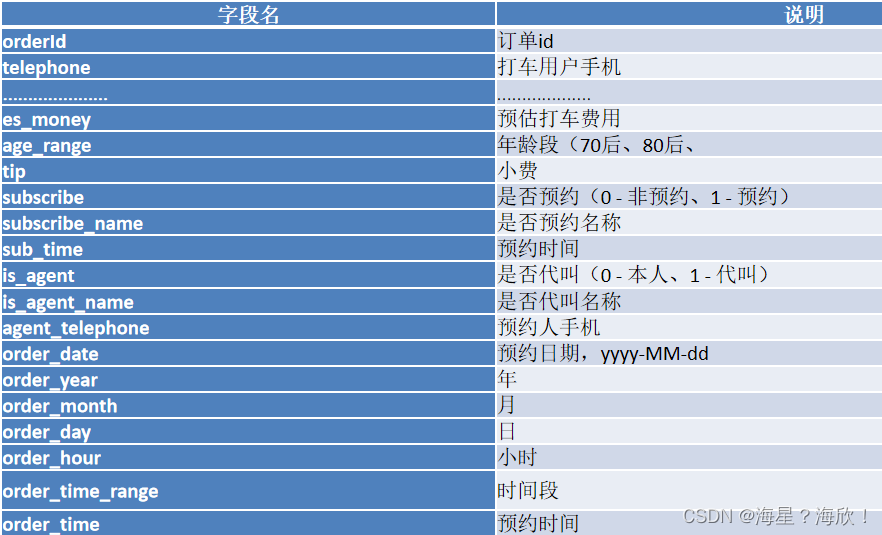
数仓实战 - 滴滴出行
项目大致流程: 1、项目业务背景 1.1 目的 本案例将某出行打车的日志数据来进行数据分析,例如:我们需要统计某一天订单量是多少、预约订单与非预约订单的占比是多少、不同时段订单占比等 数据海量 – 大数据 hive比MySQL慢很多 1.2 项目架…...
python虚拟环境与环境变量
一、环境变量 1.环境变量 在命令行下,使用可执行文件,需要来到可执行文件的路径下执行 如果在任意路径下执行可执行文件,能够有响应,就需要在环境变量配置 2.设置环境变量 用户变量:当前用户登录到系统,…...

BeautifulSoup文档4-详细方法 | 用什么方法对文档树进行搜索?
4-详细方法 | 用什么方法对文档树进行搜索?1 过滤器1.1 字符串1.2 正则表达式1.3 列表1.4 True1.5 可以自定义方法2 find_all()2.1 参数原型2.2 name参数2.3 keyword 参数2.4 string 参数2.5 limit 参数2.6 recursive 参数3 find()4 find_parents()和find_parent()5…...

初识Tkinter界面设计
目录 前言 一、初识Tkinter 二、Label控件 三、Button控件 四、Entry控件 前言 本文简单介绍如何使用Python创建一个界面。 一、初识Tk...

软件测试面试题中的sql题目你会做吗?
目录 1.学生表 2.一道SQL语句面试题,关于group by表内容: 3.表中有A B C三列,用SQL语句实现:当A列大于B列时选择A列否则选择B列,当B列大于C列时选择B列否则选择C列 4. 5.姓名:name 课程:subject 分数&…...

VS实用调试技巧
一.什么是BUG🐛Bug一词的原意是虫子,而在电脑系统或程序中隐藏着的一些未被发现的缺陷或问题,人们也叫它"bug"。这是为什么呢?这就要追溯到一个程序员与飞蛾的故事了。Bug的创始人格蕾丝赫柏(Grace Murray H…...
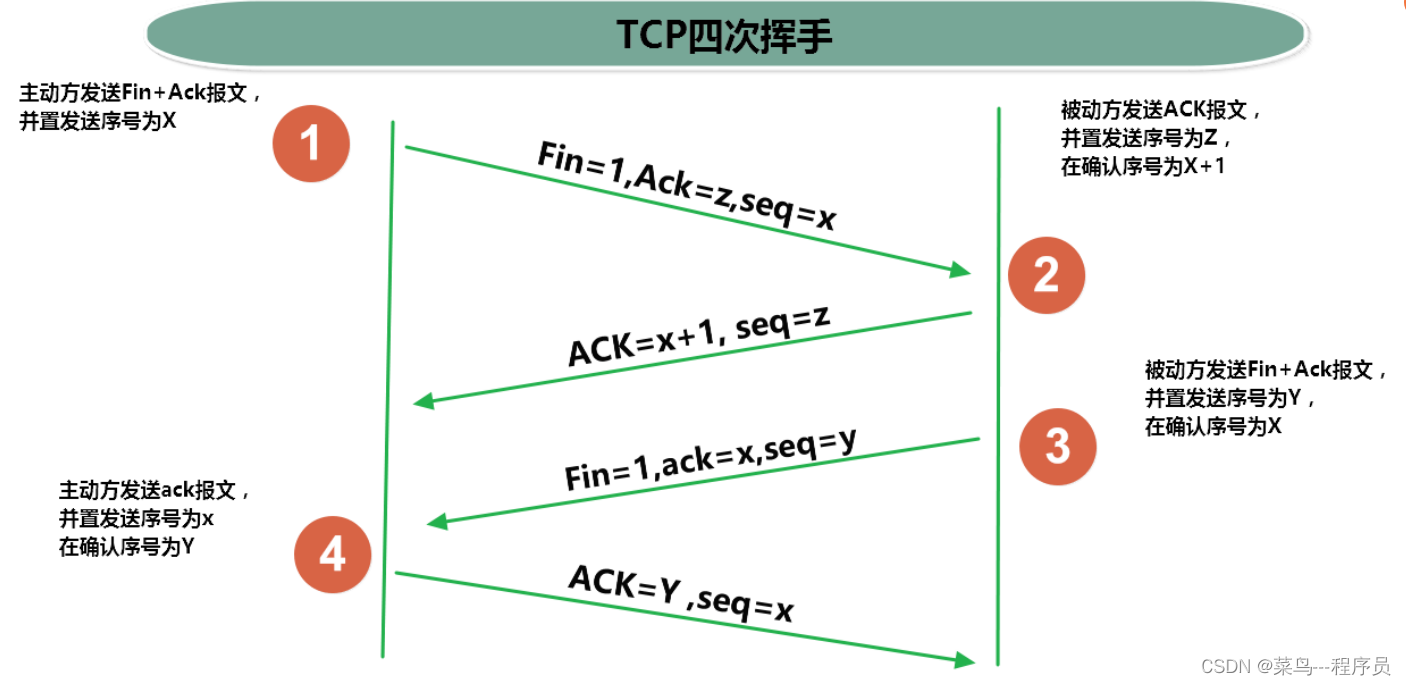
通俗易懂理解三次握手、四次挥手(TCP)
文章目录1、通俗语言理解1.1 三次握手1.2 四次挥手2、进一步理解三次握手和四次挥手2.1 三次握手2.2 四次挥手1、通俗语言理解 1.1 三次握手 C:客户端 S:服务器端 第一次握手: C:在吗?我要和你建立连接。 第二次握手ÿ…...

Firefly开源中文大模型:指令微调、部署与领域适配实战
1. 项目概述:一个专为中文优化的开源大语言模型最近在开源社区里,Firefly(流萤)这个项目引起了我的注意。它不是一个通用框架,而是一个经过精心指令微调的大语言模型系列。简单来说,你可以把它理解为一个“…...

数字时代的计划性抹杀:从强制升级到生态锁定的技术围剿
1. 数字时代的“计划性报废”:从凯迪拉克到小电驴的隐喻 前几天,我在网上申请一张信用卡,过程堪称一场荒诞剧。银行明明通过邮件联系我,也知道我的账号密码,甚至在我通过了“我不是机器人”的图片验证后,却…...
为你的五子棋项目加个‘智能大脑’)
从AlphaGo到你的小游戏:如何用MCTS(蒙特卡洛树搜索)为你的五子棋项目加个‘智能大脑’
从AlphaGo到你的小游戏:如何用MCTS为五子棋项目构建智能决策引擎 当你在手机上下棋输给AI时,是否好奇过这些"电子大脑"如何思考?2016年AlphaGo击败李世石的关键技术之一——蒙特卡洛树搜索(MCTS),…...

Claude Code 代码保存全攻略:告别丢失,高效管理开发成果
日常开发中,用 Claude Code 生成代码后,很多人都会遇到这些糟心事:生成的代码片段零散复制,换个会话就找不到;手动保存步骤繁琐,遗漏文件或格式错乱;切换不同 AI 模型时,代码记录无法…...

从磁路对称性到电感差异:深度解析永磁同步电机凸极与隐极的本质
1. 永磁同步电机的两种面孔:凸极与隐极 第一次拆解永磁同步电机时,我被转子铁芯上那些凹凸有致的磁极结构吸引了——有的像连绵的山丘(凸极),有的则平整得像镜面(隐极)。这两种结构看似只是外观…...

10分钟学会Appium:移动端自动化测试的终极指南
10分钟学会Appium:移动端自动化测试的终极指南 【免费下载链接】til :memo: Today I Learned 项目地址: https://gitcode.com/gh_mirrors/ti/til Appium是一款功能强大的开源移动端自动化测试工具,支持iOS和Android平台,让开发者和测试…...

如何利用WinRAR分卷压缩,轻松突破大文件传输限制
1. 为什么需要分卷压缩? 在日常工作和生活中,我们经常会遇到需要传输大文件的情况。比如设计师要发送PSD源文件给客户,程序员要分享开发环境的镜像,或者普通用户想通过邮件发送高清视频给亲友。但几乎所有主流传输平台都对单个文件…...

深度解析Layui formSelects:现代Web应用中的多选下拉框终极解决方案
深度解析Layui formSelects:现代Web应用中的多选下拉框终极解决方案 【免费下载链接】layui-formSelects Layui select多选小插件 项目地址: https://gitcode.com/gh_mirrors/la/layui-formSelects 在当今的Web开发领域,表单交互体验直接影响着用…...

告别英文界面:RedHat 6.3 桌面环境汉化原理与手动配置详解
从底层机制到实战:RedHat 6.3 桌面环境深度汉化指南 第一次在终端里看到满屏英文报错时,我盯着那个"Permission denied"愣了半天——明明昨天刚装好的系统,怎么连个中文提示都没有?这种经历恐怕是很多国内Linux用户的共…...

终极指南:掌握虚幻引擎资源逆向工程与UAssetGUI实战应用
终极指南:掌握虚幻引擎资源逆向工程与UAssetGUI实战应用 【免费下载链接】UAssetGUI A tool designed for low-level examination and modification of Unreal Engine game assets by hand. 项目地址: https://gitcode.com/gh_mirrors/ua/UAssetGUI 在游戏开…...