BeautifulSoup文档4-详细方法 | 用什么方法对文档树进行搜索?
4-详细方法 | 用什么方法对文档树进行搜索?
- 1 过滤器
- 1.1 字符串
- 1.2 正则表达式
- 1.3 列表
- 1.4 True
- 1.5 可以自定义方法
- 2 find_all()
- 2.1 参数原型
- 2.2 name参数
- 2.3 keyword 参数
- 2.4 string 参数
- 2.5 limit 参数
- 2.6 recursive 参数
- 3 find()
- 4 find_parents()和find_parent()
- 5 find_next_siblings() 和 find_next_sibling()
- 6 find_previous_siblings() 和 find_previous_sibling()
- 7 find_all_next() 和 find_next()
- 8 find_all_previous() 和 find_previous()
- 9 本文涉及的源码
BeautifulSoup的文档搜索方法有很多,官方文档中重点介绍了两个方法:
find() 和 find_all()
- 下文中的实例,依旧是官网的例子:
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p><p class="story">...</p>
"""from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'html.parser')
1 过滤器
- 在介绍文档搜索方法之前,先了解下各种过滤器。
1.1 字符串
- 即在搜索方法中传如一个字符串参数;
BeautifulSoup会查找与字符串完全匹配的内容;- 如查找
b标签:
print(soup.find_all('b'))
- 输出为:
[<b>The Dormouse's story</b>]
1.2 正则表达式
- 传入正则表达式作为参数;
Beautiful Soup会通过正则表达式的match()来匹配内容;- 如找出所有以
b开头的标签:
import re
for tag in soup.find_all(re.compile("^b")):print(tag.name)
- 输出为:
body
b
1.3 列表
- 传入列表参数;
Beautiful Soup会将与列表中任一元素匹配的内容返回;- 如找到文档中所有
a标签和b标签:
print(soup.find_all(["a", "b"]))
- 输出为:
[<b>The Dormouse's story</b>,
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
1.4 True
True可以匹配任何值;- 如查找到所有的
tag:
for tag in soup.find_all(True):print(tag.name)
- 输出为:
html
head
title
body
p
b
p
a
a
a
p
1.5 可以自定义方法
- 如果没有合适过滤器,那么还可以定义一个方法;
- 方法只接受一个元素参数;
- 如果这个方法返回
True表示当前元素匹配并且被找到,如果不是则反回False;
2 find_all()
- 搜索当前
tag的所有tag子节点,并判断是否符合过滤器的条件。 - 比如:
print(soup.find_all("title"))
- 输出为:
[<title>The Dormouse's story</title>]
2.1 参数原型
find_all( name , attrs , recursive , string , **kwargs )
2.2 name参数
- 查找所有名字为
name的tag; - 如:
print(soup.find_all("title")),输出为:[<title>The Dormouse's story</title>]。
2.3 keyword 参数
- 如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字
tag的属性来搜索; - 如:
print(soup.find_all(id='link2')),输出为:
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
- 按照
CSS搜索,可以通过class_参数搜索有指定CSS类名的tag; - 如:
print(soup.find_all("a", class_="sister")),输出为:
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
2.4 string 参数
- 通过
string参数可以搜文档中的字符串内容.与name参数的可选值一样; - 如:
print(soup.find_all(string="Elsie")),输出为:['Elsie'];
2.5 limit 参数
- 可以使用
limit参数限制搜索返回结果的数量,避免返回结果很大速度很慢; - 如:
soup.find_all("a", limit=2),输出为:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
2.6 recursive 参数
- 只搜索
tag的直接子节点,可以使用参数recursive=False; - 如:
<html><head><title>The Dormouse's story</title></head>
...
- 不使用
recursive参数:
print(soup.html.find_all("title"))
- 输出为:
[<title>The Dormouse's story</title>]
- 使用
recursive参数:
print(soup.html.find_all("title", recursive=False))
- 输出为:
[]
3 find()
find_all()方法的返回结果是值包含一个元素的列表,而find()方法直接返回结果;find_all()方法没有找到目标是返回空列表,find()方法找不到目标时,返回None。- 如:
print(soup.find("nosuchtag")),输出为:None。 - 参数原型:
find( name , attrs , recursive , string , **kwargs )
4 find_parents()和find_parent()
- 参数原型:
find_parents( name , attrs , recursive , string , **kwargs )
find_parent( name , attrs , recursive , string , **kwargs )
find_parents() 和 find_parent()用来搜索当前节点的父辈节点;find_all() 和 find()只搜索当前节点的所有子节点,孙子节点等;- 如:
a_string = soup.find(string="Lacie")
print(a_string)
print(a_string.find_parents("a"))
- 输出为:
Lacie
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
5 find_next_siblings() 和 find_next_sibling()
- 参数原型:
find_next_siblings( name , attrs , recursive , string , **kwargs )
find_next_sibling( name , attrs , recursive , string , **kwargs )
- 这2个方法通过
.next_siblings属性对当tag的所有后面解析的兄弟tag节点进行迭代; find_next_siblings()方法返回所有符合条件的后面的兄弟节点;find_next_sibling()只返回符合条件的后面的第一个tag节点;- 如:
first_link = soup.a
print(first_link)
print(first_link.find_next_siblings("a"))
first_story_paragraph = soup.find("p", "story")
print(first_story_paragraph.find_next_sibling("p"))
- 输出为:
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
<p class="story">...</p>
6 find_previous_siblings() 和 find_previous_sibling()
- 参数原型:
find_previous_siblings( name , attrs , recursive , string , **kwargs )
find_previous_sibling( name , attrs , recursive , string , **kwargs )
- 这2个方法通过
.previous_siblings属性对当前tag的前面解析的兄弟tag节点进行迭代; find_previous_siblings()方法返回所有符合条件的前面的兄弟节点;find_previous_sibling()方法返回第一个符合条件的前面的兄弟节点。
7 find_all_next() 和 find_next()
- 参数原型:
find_all_next( name , attrs , recursive , string , **kwargs )
find_next( name , attrs , recursive , string , **kwargs )
- 这2个方法通过
.next_elements属性对当前tag的之后的tag和字符串进行迭代; find_all_next()方法返回所有符合条件的节点;find_next()方法返回第一个符合条件的节点。
8 find_all_previous() 和 find_previous()
- 参数原型:
find_all_previous( name , attrs , recursive , string , **kwargs )
find_previous( name , attrs , recursive , string , **kwargs )
- 这2个方法通过
.previous_elements属性对当前节点前面的tag和字符串进行迭代; find_all_previous()方法返回所有符合条件的节点;find_previous()方法返回第一个符合条件的节点。
9 本文涉及的源码
# -*- coding:utf-8 -*-
# 作者:NoamaNelson
# 日期:2023/2/17
# 文件名称:bs04.py
# 作用:beautifulsoup的应用
# 联系:VX(NoamaNelson)
# 博客:https://blog.csdn.net/NoamaNelsonfrom bs4 import BeautifulSouphtml_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p><p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
# ====== 过滤器 ======
# 字符串
print(soup.find_all('b'))
# 正则表达式
import re
for tag in soup.find_all(re.compile("^b")):print(tag.name)
# 列表
print(soup.find_all(["a", "b"]))
# True
for tag in soup.find_all(True):print(tag.name)# ====== find_all() ======
print(soup.find_all("title"))
print(soup.find_all(id='link2'))
print(soup.find_all("a", class_="sister"))
print(soup.find_all(string="Elsie"))
print(soup.find_all("a", limit=2))
print(soup.html.find_all("title", recursive=False))# ====== find() ======
print(soup.find("nosuchtag"))
a_string = soup.find(string="Lacie")
print(a_string)
print(a_string.find_parents("a"))
first_link = soup.a
print(first_link)
print(first_link.find_next_siblings("a"))
first_story_paragraph = soup.find("p", "story")
print(first_story_paragraph.find_next_sibling("p"))
相关文章:

BeautifulSoup文档4-详细方法 | 用什么方法对文档树进行搜索?
4-详细方法 | 用什么方法对文档树进行搜索?1 过滤器1.1 字符串1.2 正则表达式1.3 列表1.4 True1.5 可以自定义方法2 find_all()2.1 参数原型2.2 name参数2.3 keyword 参数2.4 string 参数2.5 limit 参数2.6 recursive 参数3 find()4 find_parents()和find_parent()5…...

初识Tkinter界面设计
目录 前言 一、初识Tkinter 二、Label控件 三、Button控件 四、Entry控件 前言 本文简单介绍如何使用Python创建一个界面。 一、初识Tk...

软件测试面试题中的sql题目你会做吗?
目录 1.学生表 2.一道SQL语句面试题,关于group by表内容: 3.表中有A B C三列,用SQL语句实现:当A列大于B列时选择A列否则选择B列,当B列大于C列时选择B列否则选择C列 4. 5.姓名:name 课程:subject 分数&…...

VS实用调试技巧
一.什么是BUG🐛Bug一词的原意是虫子,而在电脑系统或程序中隐藏着的一些未被发现的缺陷或问题,人们也叫它"bug"。这是为什么呢?这就要追溯到一个程序员与飞蛾的故事了。Bug的创始人格蕾丝赫柏(Grace Murray H…...
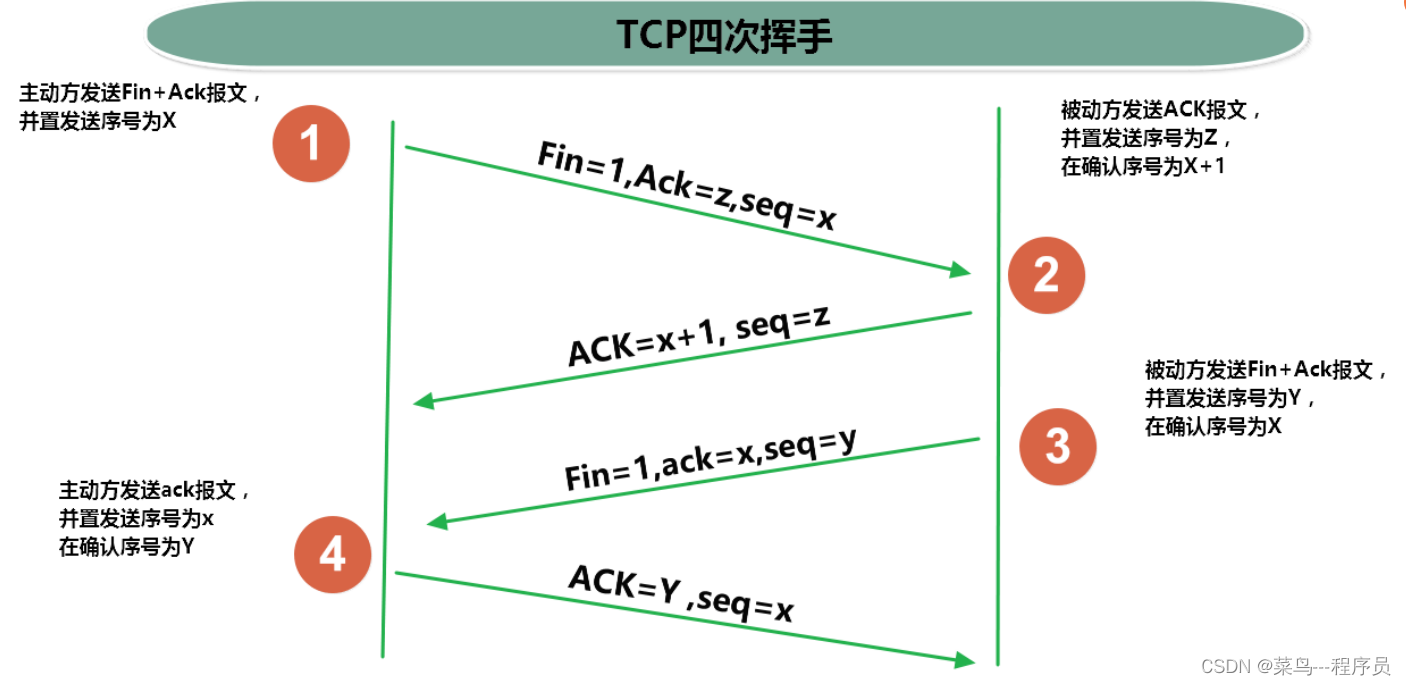
通俗易懂理解三次握手、四次挥手(TCP)
文章目录1、通俗语言理解1.1 三次握手1.2 四次挥手2、进一步理解三次握手和四次挥手2.1 三次握手2.2 四次挥手1、通俗语言理解 1.1 三次握手 C:客户端 S:服务器端 第一次握手: C:在吗?我要和你建立连接。 第二次握手ÿ…...
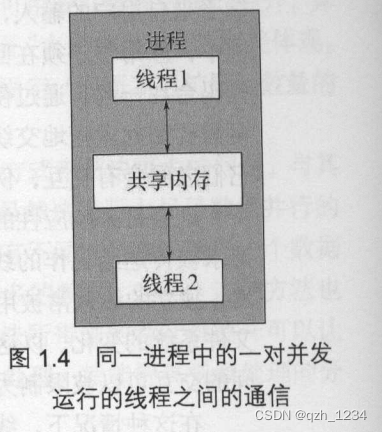
1.1 什么是并发
1.1 什么是并发 并发:指两个或更多独立的活动同时发生。并发在生活中随处可见。我们可以一边走路一边说话,也可以两只手同时做不同的动作。 1.1.1 计算机系统中的并发 当我们提到计算机术语的“并发”,指的是在单个系统里同时执行多个独立…...

万字讲解你写的代码是如何跑起来的?
今天我们来思考一个简单的问题,一个程序是如何在 Linux 上执行起来的? 我们就拿全宇宙最简单的 Hello World 程序来举例。 #include <stdio.h> int main() {printf("Hello, World!\n");return 0; } 我们在写完代码后,进行…...

034.Solidity入门——21不可变量
Solidity 中的不可变量是在编译时就被确定的常量,也称为常量变量(constant variable)或只读变量(read-only variable)。这些变量在定义时必须立即初始化,并且在整个合约中都无法被修改,可以在函…...
Vulnhub 渗透练习(四)—— Acid
环境搭建 环境下载 kail 和 靶机网络适配调成 Nat 模式,实在不行直接把网络适配还原默认值,再重试。 信息收集 主机扫描 没扫到,那可能端口很靠后,把所有端口全扫一遍。 发现 33447 端口。 扫描目录,没什么有用的…...

C++ 在线工具
online编译器https://godbolt.org/Online C Compiler - online editor (onlinegdb.com) https://www.onlinegdb.com/online_c_compilerC Shell (cpp.sh) https://cpp.sh/在线文档Open Standards (open-std.org)Index of /afs/cs.cmu.edu/academic/class/15211/spring.96/wwwC P…...

使用MMDetection进行目标检测、实例和全景分割
MMDetection 是一个基于 PyTorch 的目标检测开源工具箱,它是 OpenMMLab 项目的一部分。包含以下主要特性: 支持三个任务 目标检测(Object Detection)是指分类并定位图片中物体的任务实例分割(Instance Segmentation&a…...
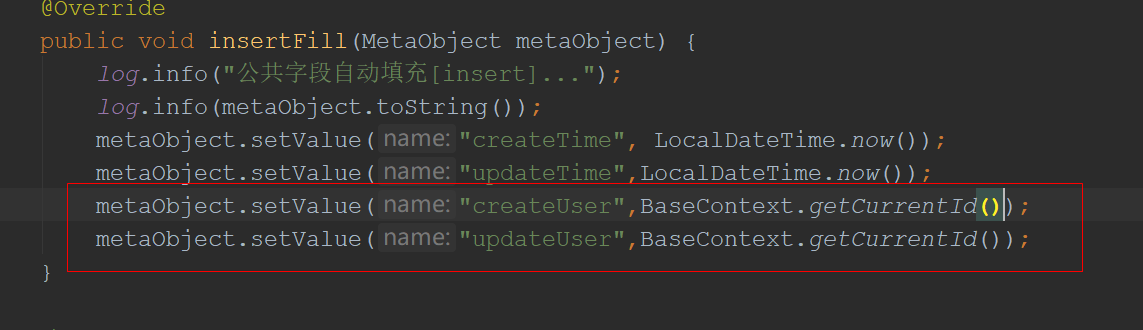
使用ThreadLocal实现当前登录信息的存取
有志者,事竟成 文章持续更新,可以关注【小奇JAVA面试】第一时间阅读,回复【资料】获取福利,回复【项目】获取项目源码,回复【简历模板】获取简历模板,回复【学习路线图】获取学习路线图。 文章目录一、使用…...

高通平台开发系列讲解(Android篇)AudioTrack音频流数据传输
文章目录 一、音频流数据传输通道创建1.1、流程描述1.2、流程图解二、音频数据传输2.1、流程描述2.2、流程图解沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇章主要图解AudioTrack音频流数据传输 。 一、音频流数据传输通道创建 1.1、流程描述 AudioTrack在set函…...

BUUCTF-firmware1
题目下载:下载 新题型,记录一下 题目给出了flag形式,md5{网址:端口},下载发现是一个.bin文件 二进制文件,其用途依系统或应用而定。一种文件格式binary的缩写。一个后缀名为".bin"的文件&#x…...

【C++之容器篇】二叉搜索树的理论与使用
目录前言一、二叉搜索树的概念二、二叉搜素树的模拟实现(增删查非递归实现)1. 二叉搜素树的结点2. 二叉搜索树的实现(1). 二叉搜索树的基本结构(2)构造函数(3)查找函数(4…...

爬虫神级解析工具之XPath:用法详解及实战
一、XPATH是什么 Xpath最初被设计用来搜寻XML文档,但它同样适用于HTML文档的搜索。通过简洁明了的路径选择表达式,它提供了强大的选择功能;同时得益于其内置的丰富的函数,它可以匹配和处理字符串、数值、时间等数据格式,几乎所有节点我们都可以通过Xpath来定位。 在Pyth…...
Markdown编辑器
这里写自定义目录标题欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注…...
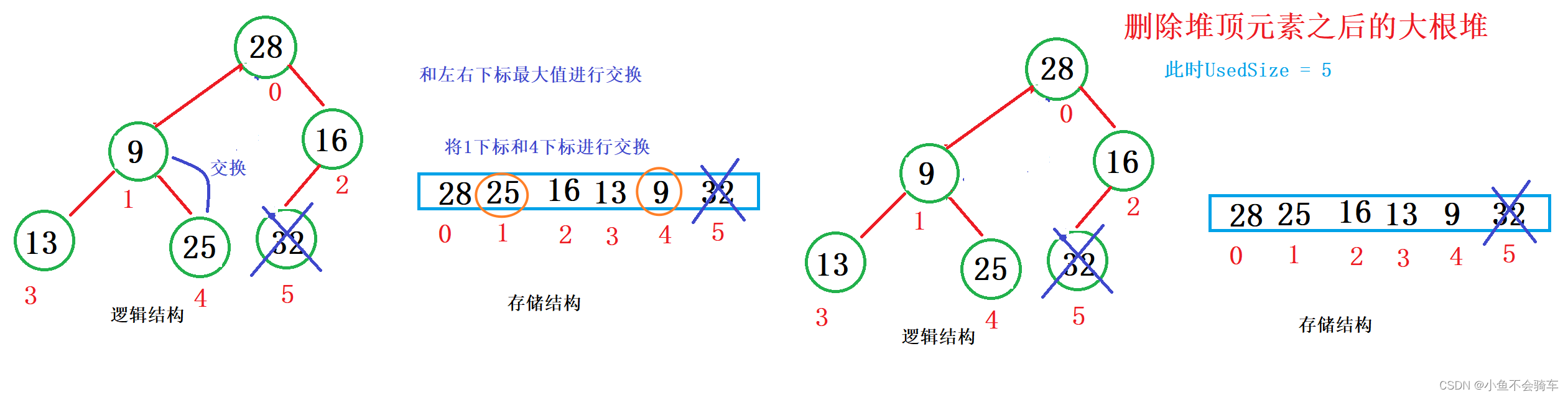
数据结构<堆>
🎇🎇🎇作者: 小鱼不会骑车 🎆🎆🎆专栏: 《数据结构》 🎓🎓🎓个人简介: 一名专科大一在读的小比特,努力学习编程是我唯一…...
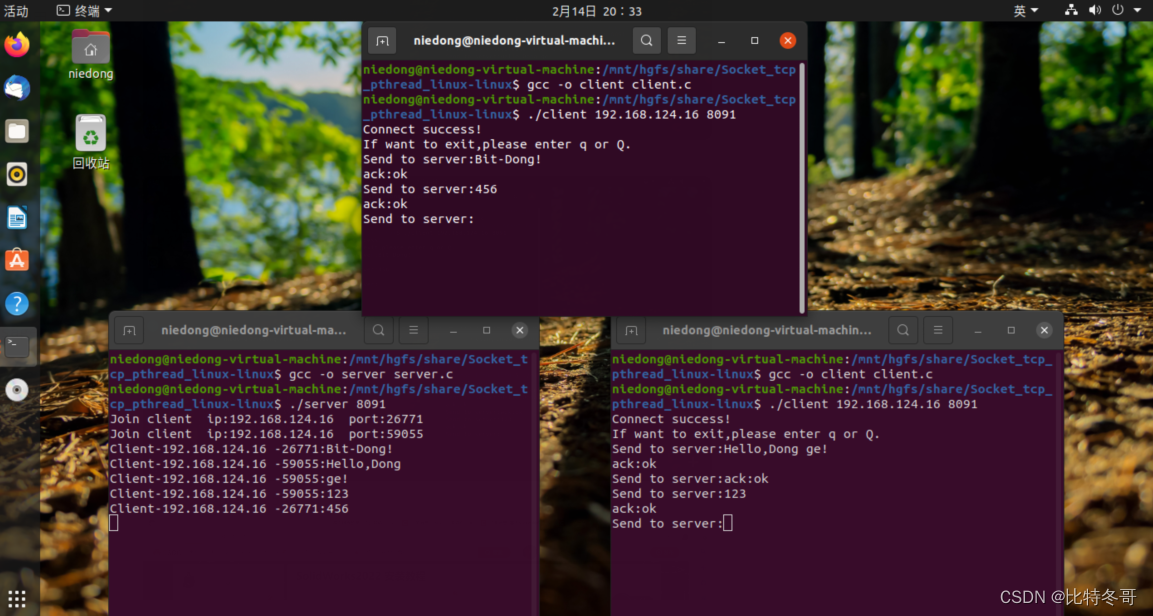
Linux下Socket编程利用多进程实现一台服务器与多台客户端并发通信
文章目录前言一、服务器 server二、客户端 client三、并发通信演示四、程序源码前言 前些日子同“ Linux应用编程 ”专栏中发布过的TCP及UDP在Linux或Windows下的通信都为单进程下的Socket编程,若还存在一些套接字相关函数模糊不清,读者可移步“Socket编…...

【MySQL】数据库基础
目录 1、什么是数据库 2、 数据库基本操作 2.1 查看当前数据库 2.2 创建一个数据库 2.3 选中数据库 2.4 删除数据库 3、常见的数据类型 3.1 数值类型 3.2 字符串类型 3.3 日期类型 4、表的操作 4.1 创建表 4.2 查看指定数据库下的所有表 4.3 查看表的结构 4.…...

Arduino与MAX4080S联手:打造高精度微安级电流监测方案
1. 为什么需要微安级电流监测? 在开发低功耗设备时,电流监测就像给设备装上了"健康监测仪"。我做过一个智能手环项目,发现待机状态下整机电流只有23微安,用普通万用表根本测不准,数值跳得跟心电图似的。这时…...

别再盲目刷LeetCode了!先把这5个编程基础打牢
文章目录前言一、代码规范:不是“洁癖”,是保命的底线二、函数式编程:不是玄学,是现代开发的通用语言三、Python基础工具:sys模块与可变参数,效率提升10倍的利器四、任务拆解能力:从“写代码”到…...

GitLab实战指南:从零到一的团队协作与项目管理
1. GitLab入门:从注册到组织搭建 第一次接触GitLab时,很多人会被它丰富的功能搞得晕头转向。作为一个长期使用GitLab管理技术团队的老鸟,我想分享一套真正实用的入门方法。GitLab本质上是一个集代码托管、项目管理、CI/CD于一体的DevOps平台&…...

JavaScript零基础到精通
📚 教程定位与目标 本教程专为零基础学习者设计,覆盖从语法入门到现代JavaScript精通的完整路径,内容严格遵循ES2026标准,融合MDN、freeCodeCamp、W3Schools权威结构,并适配中文学习者习惯。…...

MagiskBoot深度解析:Android启动镜像处理机制与实战应用
MagiskBoot深度解析:Android启动镜像处理机制与实战应用 【免费下载链接】Magisk The Magic Mask for Android 项目地址: https://gitcode.com/GitHub_Trending/ma/Magisk MagiskBoot作为Magisk项目中的核心工具,专门负责Android启动镜像的解析、…...

PonyAgent 试用笔记:当 LangGraph 太重、Dify 太黑盒,中小企业的第三条路,一个很实用的智能体框架
PonyAgent 试用笔记:当 LangGraph 太重、Dify 太黑盒,中小企业的第三条路 TL;DR:PonyAgent 是一个用 Python 写的极简智能体框架,单文件入口、.env 一处配置、Redis 挂了能自动降级到内存模式。我用 5 分钟在 Windows 上把它跑了起…...

番茄小说下载器完整指南:如何轻松搭建个人离线图书馆
番茄小说下载器完整指南:如何轻松搭建个人离线图书馆 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 还在为网络不稳定无法畅读番茄小说而烦恼吗?番茄小…...

FanControl终极指南:Windows电脑风扇智能控制软件完全解析
FanControl终极指南:Windows电脑风扇智能控制软件完全解析 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...

测试测量工程师必读:从EMC暗室到传感器选型的实战解析
1. 项目概述:一场关于测试测量知识的“周五挑战”又到了周五下午,手头的项目报告写得差不多了,代码也调试得告一段落,是不是感觉大脑需要换个频道放松一下?作为一名在电子工程和测试测量领域摸爬滚打了十几年的老工程师…...

从游戏角色到人脸分析:聊聊‘摇头、点头、转头’背后的欧拉角与万向节死锁
游戏角色控制与人脸分析的奇妙交汇:解码欧拉角与万向节死锁 想象一下你在玩一款3A级开放世界游戏:按下左摇杆,角色开始左右张望;推动右摇杆,角色抬头望向天空中的飞龙;同时扳动两个摇杆,角色做出…...