【MySQL】复合查询
复合查询目录
- 一、基本查询
- 二、多表查询
- 三、自连接
- 四、子查询
- 4.1 单行子查询
- 4.2 多行子查询
- 4.3 多列子查询
- 4.4 在from子句中使用子查询
- 4.5 合并查询
- 4.5.1 union
- 4.5.2 union all
- 五、实战OJ
一、基本查询
--查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J
mysql> select * from emp where (sal>500 or job='MANAGER')and ename like 'J%';
+--------+-------+---------+------+---------------------+---------+------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+-------+---------+------+---------------------+---------+------+--------+
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 007900 | JAMES | CLERK | 7698 | 1981-12-03 00:00:00 | 950.00 | NULL | 30 |
+--------+-------+---------+------+---------------------+---------+------+--------+
2 rows in set (0.00 sec)
--按照部门号升序而雇员的工资降序排序
mysql> select * from emp order by deptno, sal desc;
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| 007839 | KING | PRESIDENT | NULL | 1981-11-17 00:00:00 | 5000.00 | NULL | 10 |
| 007782 | CLARK | MANAGER | 7839 | 1981-06-09 00:00:00 | 2450.00 | NULL | 10 |
| 007934 | MILLER | CLERK | 7782 | 1982-01-23 00:00:00 | 1300.00 | NULL | 10 |
| 007788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 |
| 007902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 |
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 007876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | NULL | 20 |
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 |
| 007698 | BLAKE | MANAGER | 7839 | 1981-05-01 00:00:00 | 2850.00 | NULL | 30 |
| 007499 | ALLEN | SALESMAN | 7698 | 1981-02-20 00:00:00 | 1600.00 | 300.00 | 30 |
| 007844 | TURNER | SALESMAN | 7698 | 1981-09-08 00:00:00 | 1500.00 | 0.00 | 30 |
| 007521 | WARD | SALESMAN | 7698 | 1981-02-22 00:00:00 | 1250.00 | 500.00 | 30 |
| 007654 | MARTIN | SALESMAN | 7698 | 1981-09-28 00:00:00 | 1250.00 | 1400.00 | 30 |
| 007900 | JAMES | CLERK | 7698 | 1981-12-03 00:00:00 | 950.00 | NULL | 30 |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
14 rows in set (0.00 sec)--使用年薪进行降序排序
mysql> select ename,sal*12+ifnull(comm,0) as 年薪 from emp order by 年薪 desc;
+--------+----------+
| ename | 年薪 |
+--------+----------+
| KING | 60000.00 |
| SCOTT | 36000.00 |
| FORD | 36000.00 |
| JONES | 35700.00 |
| BLAKE | 34200.00 |
| CLARK | 29400.00 |
| ALLEN | 19500.00 |
| TURNER | 18000.00 |
| MARTIN | 16400.00 |
| MILLER | 15600.00 |
| WARD | 15500.00 |
| ADAMS | 13200.00 |
| JAMES | 11400.00 |
| SMITH | 9600.00 |
+--------+----------+
14 rows in set (0.00 sec)
--显示工资最高的员工的名字和工作岗位
mysql> select ename,job from emp where sal=(select max(sal) from emp);
+-------+-----------+
| ename | job |
+-------+-----------+
| KING | PRESIDENT |
+-------+-----------+
1 row in set (0.01 sec)
--显示工资高于平均工资的员工信息
mysql> select * from emp where sal>(select avg(sal) from emp);
+--------+-------+-----------+------+---------------------+---------+------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+-------+-----------+------+---------------------+---------+------+--------+
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 007698 | BLAKE | MANAGER | 7839 | 1981-05-01 00:00:00 | 2850.00 | NULL | 30 |
| 007782 | CLARK | MANAGER | 7839 | 1981-06-09 00:00:00 | 2450.00 | NULL | 10 |
| 007788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 |
| 007839 | KING | PRESIDENT | NULL | 1981-11-17 00:00:00 | 5000.00 | NULL | 10 |
| 007902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 |
+--------+-------+-----------+------+---------------------+---------+------+--------+
6 rows in set (0.00 sec)
--显示每个部门的平均工资和最高工资
mysql> select deptno,format(avg(sal),2),max(sal) from emp group by deptno;
+--------+--------------------+----------+
| deptno | format(avg(sal),2) | max(sal) |
+--------+--------------------+----------+
| 10 | 2,916.67 | 5000.00 |
| 20 | 2,175.00 | 3000.00 |
| 30 | 1,566.67 | 2850.00 |
+--------+--------------------+----------+
3 rows in set (0.01 sec)
--显示平均工资低于2000的部门号和它的平均工资
mysql> select deptno,avg(sal) as avg_sal from emp group by deptno having avg_sal<2000;
+--------+-------------+
| deptno | avg_sal |
+--------+-------------+
| 30 | 1566.666667 |
+--------+-------------+
1 row in set (0.00 sec)
--显示每种岗位的雇员总数,平均工资
mysql> select job,count(*),format(avg(sal),2) from emp group by job;
+-----------+----------+--------------------+
| job | count(*) | format(avg(sal),2) |
+-----------+----------+--------------------+
| ANALYST | 2 | 3,000.00 |
| CLERK | 4 | 1,037.50 |
| MANAGER | 3 | 2,758.33 |
| PRESIDENT | 1 | 5,000.00 |
| SALESMAN | 4 | 1,400.00 |
+-----------+----------+--------------------+
5 rows in set (0.00 sec)二、多表查询
实际开发中往往数据来自不同的表,所以需要多表查询。本节我们用一个简单的公司管理系统,有三张表EMP,DEPT,SALGRADE来演示如何进行多表查询。(笛卡尔积)
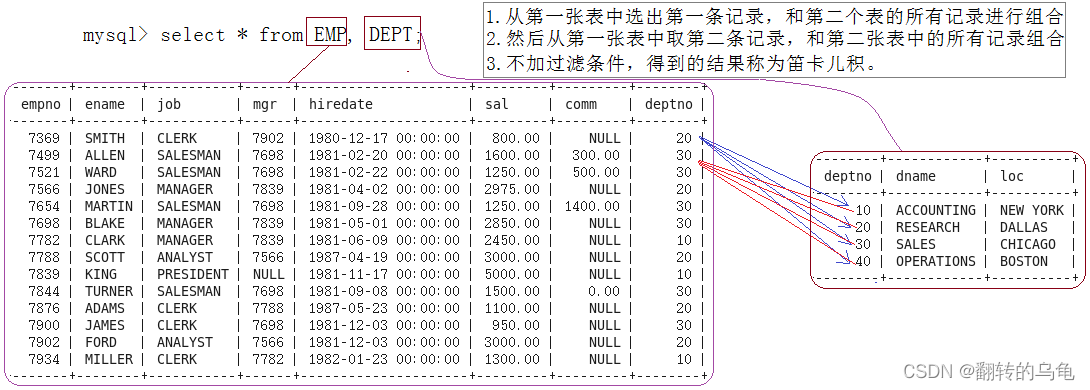
案例:
--显示雇员名、雇员工资以及所在部门的名字因为上面的数据来自EMP和DEPT表,因此要联合查询
mysql> select ename,sal,dname from emp,dept where emp.deptno=dept.deptno;
+--------+---------+------------+
| ename | sal | dname |
+--------+---------+------------+
| SMITH | 800.00 | RESEARCH |
| ALLEN | 1600.00 | SALES |
| WARD | 1250.00 | SALES |
| JONES | 2975.00 | RESEARCH |
| MARTIN | 1250.00 | SALES |
| BLAKE | 2850.00 | SALES |
| CLARK | 2450.00 | ACCOUNTING |
| SCOTT | 3000.00 | RESEARCH |
| KING | 5000.00 | ACCOUNTING |
| TURNER | 1500.00 | SALES |
| ADAMS | 1100.00 | RESEARCH |
| JAMES | 950.00 | SALES |
| FORD | 3000.00 | RESEARCH |
| MILLER | 1300.00 | ACCOUNTING |
+--------+---------+------------+
14 rows in set (0.00 sec)-- 显示部门号为10的部门名,员工名和工资
mysql> select dept.deptno,dname,ename,sal from emp,dept where dept.deptno=emp.deptno and dept.deptno=10;
+--------+------------+--------+---------+
| deptno | dname | ename | sal |
+--------+------------+--------+---------+
| 10 | ACCOUNTING | CLARK | 2450.00 |
| 10 | ACCOUNTING | KING | 5000.00 |
| 10 | ACCOUNTING | MILLER | 1300.00 |
+--------+------------+--------+---------+
3 rows in set (0.00 sec)-- 显示各个员工的姓名,工资,及工资级别mysql> select ename,sal,grade,losal,hisal from salgrade,emp where emp.sal between losal and hisal;
+--------+---------+-------+-------+-------+
| ename | sal | grade | losal | hisal |
+--------+---------+-------+-------+-------+
| SMITH | 800.00 | 1 | 700 | 1200 |
| ALLEN | 1600.00 | 3 | 1401 | 2000 |
| WARD | 1250.00 | 2 | 1201 | 1400 |
| JONES | 2975.00 | 4 | 2001 | 3000 |
| MARTIN | 1250.00 | 2 | 1201 | 1400 |
| BLAKE | 2850.00 | 4 | 2001 | 3000 |
| CLARK | 2450.00 | 4 | 2001 | 3000 |
| SCOTT | 3000.00 | 4 | 2001 | 3000 |
| KING | 5000.00 | 5 | 3001 | 9999 |
| TURNER | 1500.00 | 3 | 1401 | 2000 |
| ADAMS | 1100.00 | 1 | 700 | 1200 |
| JAMES | 950.00 | 1 | 700 | 1200 |
| FORD | 3000.00 | 4 | 2001 | 3000 |
| MILLER | 1300.00 | 2 | 1201 | 1400 |
+--------+---------+-------+-------+-------+
14 rows in set (0.00 sec)三、自连接
上述的笛卡尔积是两个不同的表进行的查询,自连接是指在同一张表连接查询
案例:
显示员工FORD的上级领导的编号和姓名(mgr是员工领导的编号–empno)
- 使用的子查询
mysql> select ename,empno from emp where empno=(select mgr from emp where ename='FORD');
+-------+--------+
| ename | empno |
+-------+--------+
| JONES | 007566 |
+-------+--------+
1 row in set (0.00 sec)- 使用多表查询(自查询)
mysql> select t2.ename,t2.empno from emp as t1,emp as t2 where t1.ename='FORD' and t1.mgr=t2.empno;
+-------+--------+
| ename | empno |
+-------+--------+
| JONES | 007566 |
+-------+--------+
1 row in set (0.00 sec)四、子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
4.1 单行子查询
返回一行记录的子查询
- 显示SMITH同一部门的员工
mysql> select * from emp where deptno=(select deptno from emp where ename='SMITH');
+--------+-------+---------+------+---------------------+---------+------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+-------+---------+------+---------------------+---------+------+--------+
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 |
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 007788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 |
| 007876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | NULL | 20 |
| 007902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 |
+--------+-------+---------+------+---------------------+---------+------+--------+
5 rows in set (0.00 sec)4.2 多行子查询
返回多行记录的子查询
in关键字:
查询和10号部门的工作岗位相同的雇员的名字,岗位,工资,部门号,但是不包含10自己的
mysql> select ename,job,sal,deptno from emp where job in(select distinct job from emp where deptno=10) and deptno!=10;
+-------+---------+---------+--------+
| ename | job | sal | deptno |
+-------+---------+---------+--------+
| JONES | MANAGER | 2975.00 | 20 |
| BLAKE | MANAGER | 2850.00 | 30 |
| SMITH | CLERK | 800.00 | 20 |
| ADAMS | CLERK | 1100.00 | 20 |
| JAMES | CLERK | 950.00 | 30 |
+-------+---------+---------+--------+
5 rows in set (0.00 sec)
查询和10号部门的工作岗位相同的雇员的名字,岗位,工资,部门名字,但是不包含10自己的
首先将上述的查询结构当做一张临时表,再和dept表做笛卡尔积
mysql> select ename,job,sal,dept.deptno,dname from(select ename,job,sal,deptno from emp where job in(select diistinct job from emp where deptno=10) and deptno!=10) as tmp,dept where tmp.deptno=dept.deptno;
+-------+---------+---------+--------+----------+
| ename | job | sal | deptno | dname |
+-------+---------+---------+--------+----------+
| SMITH | CLERK | 800.00 | 20 | RESEARCH |
| JONES | MANAGER | 2975.00 | 20 | RESEARCH |
| ADAMS | CLERK | 1100.00 | 20 | RESEARCH |
| BLAKE | MANAGER | 2850.00 | 30 | SALES |
| JAMES | CLERK | 950.00 | 30 | SALES |
+-------+---------+---------+--------+----------+
5 rows in set (0.00 sec)all关键字:
显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
mysql> select * from emp where sal>(select max(sal) from emp where deptno=30);
+--------+-------+-----------+------+---------------------+---------+------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+-------+-----------+------+---------------------+---------+------+--------+
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 007788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 |
| 007839 | KING | PRESIDENT | NULL | 1981-11-17 00:00:00 | 5000.00 | NULL | 10 |
| 007902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 |
+--------+-------+-----------+------+---------------------+---------+------+--------+
4 rows in set (0.00 sec)mysql> select * from emp where sal > all(select distinct sal from emp where deptno=30);
+--------+-------+-----------+------+---------------------+---------+------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+-------+-----------+------+---------------------+---------+------+--------+
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 007788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 |
| 007839 | KING | PRESIDENT | NULL | 1981-11-17 00:00:00 | 5000.00 | NULL | 10 |
| 007902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 |
+--------+-------+-----------+------+---------------------+---------+------+--------+
4 rows in set (0.00 sec)any关键字;显示工资比部门30的任意员工的工资高的员工的姓名、工资和部门号(包含自己部门的员工)
mysql> select * from emp where sal>any(select distinct sal from emp where deptno=30 );
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| 007499 | ALLEN | SALESMAN | 7698 | 1981-02-20 00:00:00 | 1600.00 | 300.00 | 30 |
| 007521 | WARD | SALESMAN | 7698 | 1981-02-22 00:00:00 | 1250.00 | 500.00 | 30 |
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 007654 | MARTIN | SALESMAN | 7698 | 1981-09-28 00:00:00 | 1250.00 | 1400.00 | 30 |
| 007698 | BLAKE | MANAGER | 7839 | 1981-05-01 00:00:00 | 2850.00 | NULL | 30 |
| 007782 | CLARK | MANAGER | 7839 | 1981-06-09 00:00:00 | 2450.00 | NULL | 10 |
| 007788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 |
| 007839 | KING | PRESIDENT | NULL | 1981-11-17 00:00:00 | 5000.00 | NULL | 10 |
| 007844 | TURNER | SALESMAN | 7698 | 1981-09-08 00:00:00 | 1500.00 | 0.00 | 30 |
| 007876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | NULL | 20 |
| 007902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 |
| 007934 | MILLER | CLERK | 7782 | 1982-01-23 00:00:00 | 1300.00 | NULL | 10 |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
12 rows in set (0.00 sec)4.3 多列子查询
单行子查询是指子查询只返回单列,单行数据;
多行子查询是指返回单列多行数据,都是针对单列而言的;
多列子查询则是指查询返回多个列数据的子查询语句
- 查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人
mysql> select * from emp where (deptno,job)=(select deptno,job from emp where ename='SMITH') and ename!='SMITHH';
+--------+-------+-------+------+---------------------+---------+------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+-------+-------+------+---------------------+---------+------+--------+
| 007876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | NULL | 20 |
+--------+-------+-------+------+---------------------+---------+------+--------+
1 row in set (0.00 sec)4.4 在from子句中使用子查询
子查询语句出现在from子句中。这里要用到数据查询的技巧,把一个子查询当做一个临时表使用
显示每个高于【自己】部门平均工资的员工的姓名、部门、工资、平均工资
1.首先查出每个部门的平均工资,并将查询结果当做临时表tmp
2.联合查询emp表与tmp表
mysql> select emp.ename,emp.deptno,sal,avgsal from emp,(select deptno,avg(sal)avgsal from emp group by deptno) t1 where emp.depttno=t1.deptno and emp.sal>t1.avgsal;
+-------+--------+---------+-------------+
| ename | deptno | sal | avgsal |
+-------+--------+---------+-------------+
| ALLEN | 30 | 1600.00 | 1566.666667 |
| JONES | 20 | 2975.00 | 2175.000000 |
| BLAKE | 30 | 2850.00 | 1566.666667 |
| SCOTT | 20 | 3000.00 | 2175.000000 |
| KING | 10 | 5000.00 | 2916.666667 |
| FORD | 20 | 3000.00 | 2175.000000 |
+-------+--------+---------+-------------+
6 rows in set (0.00 sec)查找每个部门工资最高的人的姓名、工资、部门、最高工资
mysql> select emp.ename,emp.sal,emp.deptno,t1.maxsal from(select deptno,max(sal)maxsal from emp group by deptno) t1,emp where emp.sal=t1.maxsal and emp.deptno=t1.deptno;
+-------+---------+--------+---------+
| ename | sal | deptno | maxsal |
+-------+---------+--------+---------+
| BLAKE | 2850.00 | 30 | 2850.00 |
| SCOTT | 3000.00 | 20 | 3000.00 |
| KING | 5000.00 | 10 | 5000.00 |
| FORD | 3000.00 | 20 | 3000.00 |
+-------+---------+--------+---------+
4 rows in set (0.00 sec)显示每个部门的信息(部门名,编号,地址)和人员数量
--多表
mysql> select dept.dname,dept.deptno,dept.loc,count(*) 部门人数 from emp,dept where emp.deptno=dept.deptno group by dept.deptno,dept.dname,dept.loc;
+------------+--------+----------+--------------+
| dname | deptno | loc | 部门人数 |
+------------+--------+----------+--------------+
| ACCOUNTING | 10 | NEW YORK | 3 |
| RESEARCH | 20 | DALLAS | 5 |
| SALES | 30 | CHICAGO | 6 |
+------------+--------+----------+--------------+
3 rows in set (0.00 sec)
--子查询
mysql> select dept.deptno,dname,cnt,loc from dept,(select count(*)cnt,deptno from emp group by deptno)tmp where dept.deptno=tmp.deptno;
+--------+------------+-----+----------+
| deptno | dname | cnt | loc |
+--------+------------+-----+----------+
| 10 | ACCOUNTING | 3 | NEW YORK |
| 20 | RESEARCH | 5 | DALLAS |
| 30 | SALES | 6 | CHICAGO |
+--------+------------+-----+----------+
3 rows in set (0.00 sec)4.5 合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all
4.5.1 union
union:该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行
将工资大于2500或职位是MANAGER的人找出来
mysql> select * from emp where sal>2500 union select * from emp where job='MANAGER';
+-------+-------+-----------+------+---------------------+---------+------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+-------+-------+-----------+------+---------------------+---------+------+--------+
| 7566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 00:00:00 | 2850.00 | NULL | 30 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 00:00:00 | 5000.00 | NULL | 10 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 |
| 7782 | CLARK | MANAGER | 7839 | 1981-06-09 00:00:00 | 2450.00 | NULL | 10 |
+-------+-------+-----------+------+---------------------+---------+------+--------+
6 rows in set (0.00 sec)4.5.2 union all
union all:该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
mysql> select * from emp where sal>2500 union all select * from emp where job='MANAGER';
+-------+-------+-----------+------+---------------------+---------+------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+-------+-------+-----------+------+---------------------+---------+------+--------+
| 7566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 00:00:00 | 2850.00 | NULL | 30 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 00:00:00 | 5000.00 | NULL | 10 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 |
| 7566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 00:00:00 | 2850.00 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-06-09 00:00:00 | 2450.00 | NULL | 10 |
+-------+-------+-----------+------+---------------------+---------+------+--------+
8 rows in set (0.00 sec)
五、实战OJ
查找所有员工入职时候的薪水情况

select s.emp_no,s.salary
from salaries s,employees e
where e.emp_no=s.emp_no and e.hire_date=s.from_date
order by e.emp_no desc;
获取所有非manager的员工emp_no
select emp_no from employees
where emp_no not in(select emp_no from dept_manager); 相关文章:
【MySQL】复合查询
复合查询目录 一、基本查询二、多表查询三、自连接四、子查询4.1 单行子查询4.2 多行子查询4.3 多列子查询4.4 在from子句中使用子查询4.5 合并查询4.5.1 union4.5.2 union all 五、实战OJ 一、基本查询 --查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的…...

JavaScript中的this指向及绑定规则
在JavaScript中,this是一个特殊的关键字,用于表示函数执行的上下文对象,也就是当前函数被调用时所在的对象。由于JavaScript的函数调用方式多种多样,this的指向也因此而变化。本文将介绍JavaScript中this的指向及绑定规则…...

css中预编译理解,它们之间区别
css预编译? css预编译器用一种专门的编程语言,它可以对web页面样式然后再编译成正常css文件,可以更加方便和高效的编写css代表。主要作用就是为css提供了变量,函数,嵌套,继承,混合等功能&#…...

如何使用Java处理JSON数据?
在Java中,您可以使用许多库来处理JSON数据。以下是使用一种常见的库 Gson 的示例: 首先,确保您已经将 Gson 库添加到您的项目中。您可以在 Maven 中添加以下依赖项: <dependency><groupId>com.google.code.gson<…...
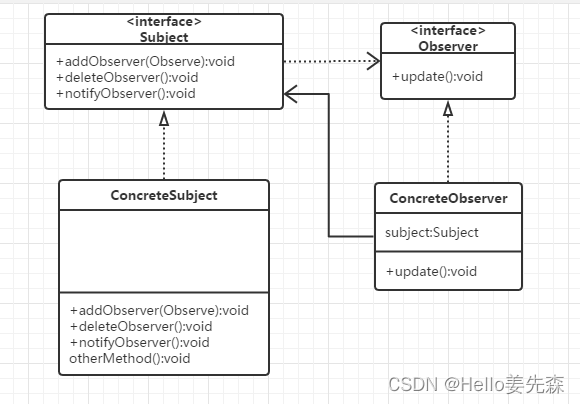
java设计模式-观察者模式
什么是观察者模式 观察者模式(Observer)是软件设计中的一种行为模式。 它定义了对象之间的一对多关系,其中如果一个对象改变了状态,所有依赖它的对象都会自动被通知并更新。 这种模式包含了两种主要的角色,即被观察…...

HiveSQL SparkSQL中常用知识点记录
目录 0. 相关文章链接 1. hive中多表full join主键重复问题 2. Hive中选出最新一个分区中新增和变化的数据 3. Hive中使用sort_array函数解决collet_list列表排序混乱问题 4. SQL中对小数位数很多的数值转换成文本的时候不使用科学计数法 5. HiveSQL & SparkSQL中炸裂…...

mac不识别移动硬盘导致无法拷贝资源
背景 硬盘插入到Mac电脑上之后,mac不识别移动硬盘导致无法拷贝资源。 移动硬盘在Mac上无法被识别的原因可能有很多,多数情况下,是硬盘的格式与Mac电脑不兼容。 文件系统格式不兼容 macOS使用的文件系统是HFS或APFS,如果移动硬盘是…...

Opencv的Mat内容学习
来源:Opencv的Mat内容小记 - 知乎 (zhihu.com) 1.Mat是一种图像容器,是二维向量。 灰度图的Mat一般存放<uchar>类型 RGB彩色图像一般存放<Vec3b>类型。 (1)单通道灰度图数据存放样式: (2)RGB三通道彩色图存放形式不同&#x…...

MySQL~数据库的设计
二、数据库的设计 1、多表之间的关系 1.1 三种分类 一对一: 分析:一个人只有一个身份证,一个身份证只能对应一个人 如:人和身份证 一对多: 如:部门和员工 分析:一个部门有多个员工ÿ…...
开源了!最强原创图解八股文面试网来袭
强烈推荐 Github上业内新晋的一匹黑马—Java图解八股文面试网—Java2Top.cn,图解 Java 大厂面试题,深入全面,真的强烈推荐~ 这是一个二本逆袭阿里的大佬根据自己秋招上岸所看过的相关专栏,面经,课程,结合自…...

微信小程序开发6
一、分包-基础概念 1.1、什么是分包 分包指的是把一个完整的小程序项目,按照需求划分为不同的子包,在构建时打包成不同的分包,用户在使用时按需进行加载。 1.2、分包的好处 对小程序进行分包的好处主要有以下两点: 可以优化小程序…...

JS 根据身份证号获取年龄、性别、出生日期
先说一代身份证和二代身份证的区别: 1.编号位数不同,第一代身份证为15位号码,第二代证是18位号码 2.编码规则不同,第一代身份证在前6位号码后没有完整出生年份,而二代的有完整的出生年份,一代身份证将年份前二位省略…...
)
Python+Mongo+LSTM(GTP生成)
下面是一个简单的示例来展示如何使用Python和MongoDB来生成LSTM预测算法。 首先,我们需要安装pymongo和tensorflow库,可以使用以下命令进行安装: pip install pymongo tensorflow接下来,我们连接到MongoDB数据库并获取需要进行预…...
关于idea如何成功运行web项目
导入项目 如图 依次选择 file - new - Project from Existing Sources 选择存放的项目目录地址 如图 导入完成 点击ok 如图 依次选择 Create project from existing sources 点击next如图 ,此处默认即可 点击 next如图 点击next有该提示 是因为之前导入过…...

python读取json文件
import json# 文件路径(同目录文件名即可,不同目录需要绝对路径) path 1.json# 读取JSON文件 with open(path, r, encodingutf-8) as file:data json.load(file)#data为字典 print(data) print(type(data))...

迁移学习、微调、计算机视觉理论(第十一次组会ppt)
@TOC 数据增广 迁移学习 微调 目标检测和边界框 区域卷积神经网络R—CNN...
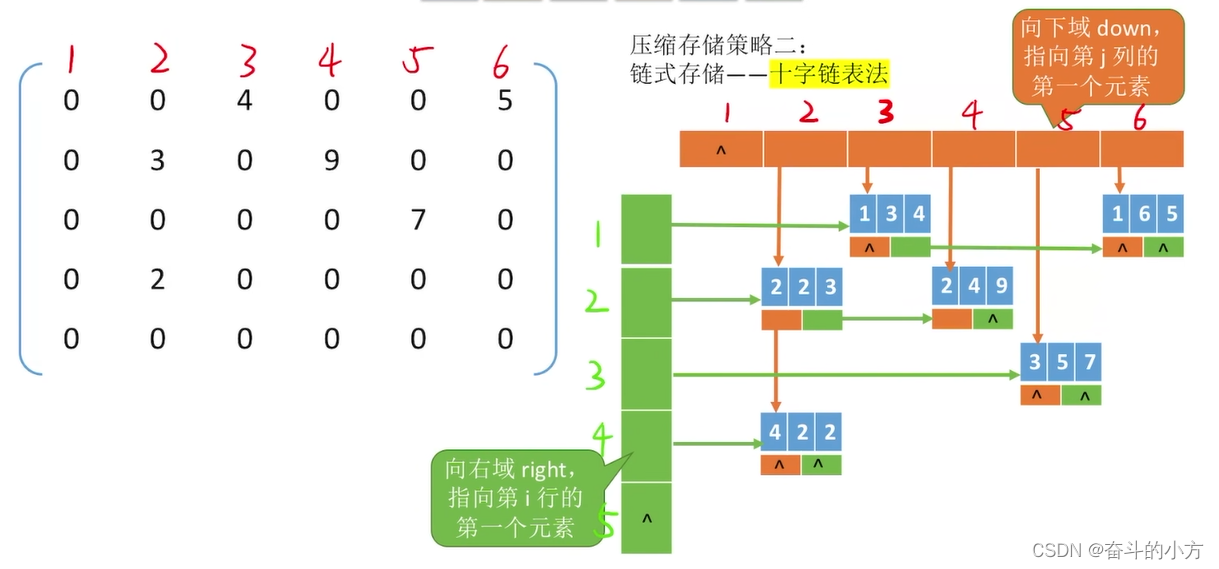
特殊矩阵的压缩存储
1 数组的存储结构 1.1 一维数组 各数组元素大小相同,且物理上连续存放。第i个元素的地址位置是:a[i] LOC i*sizeof(ElemType) (LOC为起始地址) 1.2 二维数组 对于多维数组有行优先、列优先的存储方法 行优先:先行后列,先存储…...
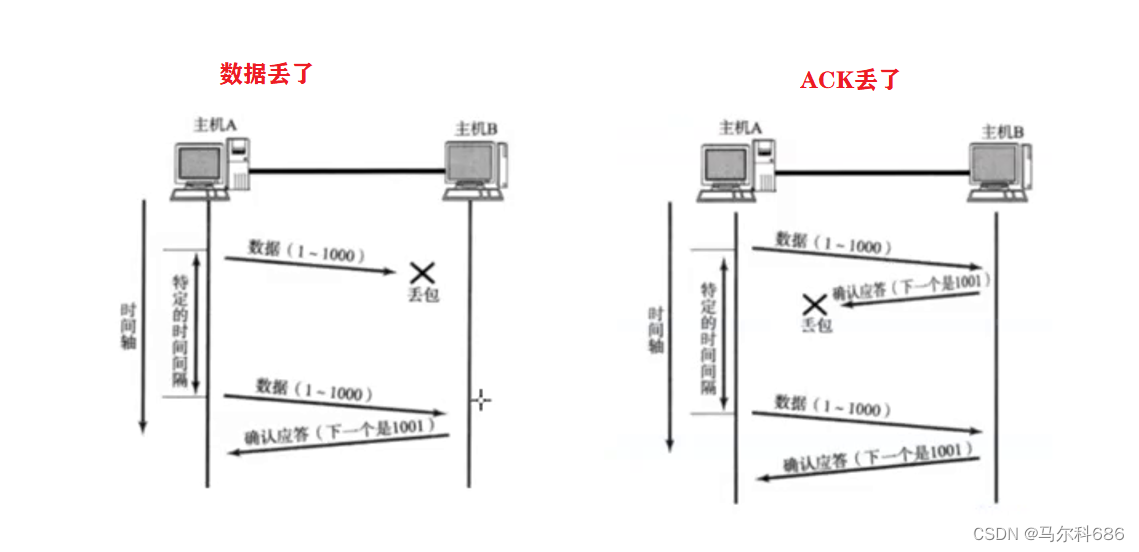
【网络原理】 (1) (应用层 传输层 UDP协议 TCP协议 TCP协议段格式 TCP内部工作机制 确认应答 超时重传 连接管理)
文章目录 应用层传输层UDP协议TCP协议TCP协议段格式TCP内部工作机制确认应答超时重传 网络原理部分我们主要学习TCP/IP协议栈这里的关键协议(TCP 和 IP),按照四层分别介绍.(物理层,我们不涉及). 应用层 我们需要学会自定义一个应用层协议. 自定义协议的原因? 当前的软件(应用…...

【SQL语句】
目录 一、SQL语句类型 1.DDL 2.DML 3.DLL 4.DQL 二、数据库操作 1.查看 2.创建 2.1 默认字符集 2.2 指定字符集 3.进入 4.删除 5.更改 5.1 库名称 5.2 字符集 三、数据表操作 1.数据类型 1.1 数值类型(常见,下同) 1.1.1 T…...

自动驾驶和机器人学习和总结专栏汇总
汇总如下: 一. 器件选型心得(系统设计)--1_goldqiu的博客-CSDN博客 一. 器件选型心得(系统设计)--2_goldqiu的博客-CSDN博客 二. 多传感器时间同步方案(时序闭环)--1 三. 多传感器标定方案&…...

PostgreSQL CASE语句深度解析:性能、类型与NULL安全实战指南
1. 为什么你必须真正吃透 PostgreSQL 的 CASE 语句——它远不止是 SQL 里的“if-else”翻译器在 PostgreSQL 实战中,我见过太多人把CASE当成一个语法糖:写几个WHEN...THEN,加个ELSE,再套个END,就以为搞定了。结果呢&am…...

AX-MES生产制造管理系统-总览
前言说起 MES 就不得不说 ERP,但是 ERP 大家基本上都知道,MES 就不一定了,常见的 ERP 系统包括 SAP、金蝶、用友等,ERP的流程相对来说也比较统一;MES就不同了,基本上熟悉业务流程的软件公司都可以开发并实施…...
)
放弃编码器!纯靠MPU6050和PID算法,手把手教你用TT马达实现平衡小车稳定控制(STM32F103C8T6实战)
纯MPU6050STM32F103的TT马达平衡车实战:无编码器PID控制全解析当大多数平衡小车方案都在强调编码器对速度反馈的不可或缺性时,我们决定挑战一个更极简的配置:仅用5美元的TT马达、9轴的MPU6050和STM32F103C8T6最小系统板,完全舍弃编…...

孤舟笔记 互联网常用框架篇二 Dubbo服务请求失败怎么处理?集群容错策略你用过几种
文章目录先说结论Failover:换家店试试Failfast:不行就算了Failsafe:忘了这事Failback:回头再说Forking:同时点几家Broadcast:通知所有人怎么选择回答技巧与点评加分回答面试官点评个人网站分布式系统中&…...
)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战) 在游戏开发团队中,版本控制系统是协作的基石,但传统工具如SVN往往让非技术成员望而生畏。当美术资源频繁更新、策划案不断迭代时&…...

收藏干货|2026 版企业 AI 落地实操指南,程序员小白入门避坑必备
如今人工智能早已脱离概念炒作阶段,全面扎根企业实际业务场景,成为技术从业者与企业管理者无法回避的发展课题。各行各业都加速布局AI赛道,行业心态也从初期观望试探,彻底转变为实打实的落地攻坚。 不少企业高层主动牵头统筹AI规划…...

特定任务需求场景下的过约束并联机构构型设计与控制方法【附代码】
✨ 长期致力于曲面加工、构型综合、运动学和动力学建模、性能评价、多目标优化、滑模控制、鲁棒控制、视觉传感技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (…...

基于Cynthion逆向USB协议,为DP100电源开发Linux控制软件
1. 项目概述:用Cynthion嗅探USB,为DP100电源打造Linux软件作为一名长期在Linux环境下折腾硬件和嵌入式开发的爱好者,我经常遇到一个头疼的问题:很多不错的桌面小设备,比如电源、示波器、逻辑分析仪,它们的官…...

独立开发者利用taotoken模型广场为不同任务选择性价比最优模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者利用taotoken模型广场为不同任务选择性价比最优模型 对于独立开发者而言,在有限的预算内高效完成多样化的开…...

告别依赖冲突:在Debian12上为特定项目搭建Python2.7.18独立运行环境
告别依赖冲突:在Debian12上为特定项目搭建Python2.7.18独立运行环境 当现代Linux系统已全面拥抱Python3的时代,突然需要维护一个仅支持Python2.7的遗留项目,这种场景对开发者而言无异于一场噩梦。本文将带你用工程化的思维,在Deb…...