Spring data JPA常用命令
简介
Spring Data JPA是Spring框架的一部分,它提供了一个简化的方式来与关系型数据库进行交互。JPA代表Java持久化API,它是Java EE规范中定义的一种对象关系映射(ORM)标准。Spring Data JPA在JPA的基础上提供了更高级的抽象,使得开发人员能够更轻松地进行数据库操作。
使用Spring Data JPA,您可以通过定义实体类和Repository接口来执行CRUD操作和自定义查询。Repository接口提供了一组常用的方法,如保存、查找、删除等,而无需编写具体的实现。Spring Data JPA会根据方法的命名约定自动生成查询,并将查询结果映射到相应的实体类中。
此外,Spring Data JPA还提供了一些功能强大的特性。您可以通过注解和查询注解来定义一对多、多对一和多对多等关联关系。您还可以使用分页和排序等功能来处理大量的数据。另外,通过使用@Query注解,您可以编写自定义的查询语句。
Spring Data JPA支持各种关系型数据库,包括MySQL、PostgreSQL、Oracle等。它还可以与其他Spring项目(如Spring Boot)无缝集成,使得开发和配置变得更加简单和一致。可以通过简化了数据库层的操作,提高开发效率并降低样板代码的编写量。
总而言之,Spring Data JPA是一个强大而灵活的工具,使得与关系型数据库进行交互变得更加简单和高效。它可以帮助您快速开发功能强大的Java应用程序,并减少与数据库相关的繁琐工作。
基本步骤
当您使用Spring Data JPA时,它将为您提供一种简化数据库访问的方法。它通过自动生成查询和基本的CRUD操作来减少编写大量样板代码的工作量。下面是使用Spring Data JPA的一些基本步骤:
添加依赖:在您的项目中,您需要添加Spring Data JPA的依赖。您可以在项目的构建文件(如pom.xml或build.gradle)中添加适当的依赖项。
配置Maven依赖的命令如下:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId> </dependency>
配置数据源:您需要配置一个数据源,以使Spring能够连接到数据库。您可以在应用程序的配置文件(如application.properties或application.yml)中指定数据库的连接信息。
spring.datasource.url=jdbc:mysql://localhost:3306/db_name spring.datasource.username=username spring.datasource.password=passwordspring.jpa.database-platform=org.hibernate.dialect.MySQLDialect spring.jpa.generate-ddl=true
创建实体类:创建代表数据库表的实体类。每个实体类将映射到数据库中的一张表,并且每个实体类的属性将映射到表中的列。
import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.GenerationType; import javax.persistence.Id;@Entity public class User {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String name;private int age;// 省略构造函数、getter和setter方法 }
创建Repository接口:创建一个继承自JpaRepository或其他Spring Data提供的Repository接口的接口。这个接口将提供基本的CRUD操作,以及其他自定义的查询方法。
使用注解:可以使用注解来自定义Repository接口的行为。例如,使用@Query注解可以定义自定义的查询方法。
import org.springframework.data.jpa.repository.JpaRepository;public interface UserRepository extends JpaRepository<User, Long> {// 这里可以定义自定义查询方法 }
自动注入Repository:在需要访问数据库的地方,可以使用@Autowired或@Inject等注解将Repository接口自动注入到您的类中。
使用Repository方法:使用Repository接口中提供的方法来进行数据库操作。例如,可以使用save()方法来插入或更新数据,使用findById()方法来查找数据等等。
执行查询:Spring Data JPA将根据方法的命名约定自动生成查询,您也可以使用@Query注解来定义自己的查询。执行查询时,Spring Data JPA将帮助您将查询结果映射到相应的实体类中。
import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service;@Service public class UserService {@Autowiredprivate UserRepository userRepository;public void createUser(User user) {userRepository.save(user);}public User getUserById(Long id) {return userRepository.findById(id).orElse(null);}// 其他操作方法... }
增删查改
当使用Spring Data JPA进行基本数据库操作时,以下是一些常见的示例操作:
插入数据:
// 创建实体对象
User user = new User();
user.setName("John");
user.setAge(25);// 保存实体对象到数据库
userRepository.save(user);
更新数据:
// 根据ID获取实体对象
Optional<User> optionalUser = userRepository.findById(1L);
if (optionalUser.isPresent()) {User user = optionalUser.get();// 更新实体对象的属性user.setAge(30);// 保存更新后的实体对象到数据库userRepository.save(user);
}
删除数据:
// 根据ID删除实体对象
userRepository.deleteById(1L);
查询数据:
// 根据ID获取实体对象
Optional<User> optionalUser = userRepository.findById(1L);
if (optionalUser.isPresent()) {User user = optionalUser.get();System.out.println(user.getName());
}// 查询所有实体对象
List<User> userList = userRepository.findAll();
for (User user : userList) {System.out.println(user.getName());
}// 自定义查询方法
List<User> userList = userRepository.findByAgeGreaterThan(20);
for (User user : userList) {System.out.println(user.getName());
}
以上示例演示了基本的插入、更新、删除和查询操作。使用Spring Data JPA,您可以通过调用Repository接口中提供的方法来执行这些操作,而无需编写底层的SQL语句。您还可以根据自己的需求,使用注解和查询注解来定义更复杂的查询方法。
使用原生SQL:
// 利用原生的SQL进行查询操作
@Query(value = "select o.* from orders o ,user u where o.uid=u.id and u.name=?1", nativeQuery = true)
@Modifying
public List<Order> findOrderByName(String name);// 利用原生的SQL进行删除操作
@Query(value = "delete from orders where id=?1 ", nativeQuery = true)
@Modifying
public void deleteOrderById(int id);// 利用原生的SQL进行删除操作
@Query(value = "delete from orders where uid=?1 ", nativeQuery = true)
@Modifying
public void deleteOrderByUId(int uid);// 利用原生的SQL进行修改操作
@Query(value = "update orders set name=?1 where id=?2 ", nativeQuery = true)
@Modifying
public void updateOrderName(String name,int id);// 利用原生的SQL进行插入操作
@Query(value = "insert into orders(name,uid) value(?1,?2)", nativeQuery = true)
@Modifying
public void insertOrder(String name,int uid);这些命令用于在JPA中使用原生SQL进行数据库表的操作。
实现分页功能:
Page<User> findByNameNot(String name, Pageable pageable);
这个命令用于在JPA中实现根据条件分页查询。
那日观海,我从未看海
相关文章:

Spring data JPA常用命令
简介 Spring Data JPA是Spring框架的一部分,它提供了一个简化的方式来与关系型数据库进行交互。JPA代表Java持久化API,它是Java EE规范中定义的一种对象关系映射(ORM)标准。Spring Data JPA在JPA的基础上提供了更高级的抽象&…...
Excel的使用
1.EXCEL诞生的意义 1.1 找到想要的数据 1.2 提升输入速度 2.数据分析与可视化操作 目的是提升数据的价值和意义 3.EXCEL使用的内在意义和外在形式 4.EXCEL的价值 4.1 解读及挖掘数据价值 4.2 协作板块 4.3 展示专业度 4.4 共享文档内容 5.人的需求》》软件功能...
大数据课程D4——hadoop的MapReduce
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解MapReduce的作用和特点; ⚪ 掌握MapReduce的组件; ⚪ 掌握MapReduce的Shuffle; ⚪ 掌握MapReduce的小文件问题; ⚪ 掌握MapReduce的压缩机制; ⚪ 掌握MapReduce的推测执行机制…...

java策略模式
在Java中,策略模式(Strategy Design Pattern)用于定义一系列算法,并将每个算法封装成单独的类,使得它们可以互相替换,让客户端在使用算法时不需要知道具体的实现细节。策略模式是一种行为型设计模式&#x…...

Vue2封装自定义全局Loading组件
前言 在开发的过程中,点击提交按钮,或者是一些其它场景总会遇到Loading加载框,PC的一些UI库也没有这样的加载框,无法满足业务需求,因此可以自己自定义一个,实现过程如下。 效果图 如何封装? 第…...

docker 搭建jenkins
1、拉取镜像 docker pull jenkins/jenkins:2.4162、创建文件夹 mkdir -p /home/jenkins_mount chmod 777 /home/jenkins_mount3、运行并构建容器 docker run --restartalways -d -p 10240:8080 -p 10241:50000 -v /home/jenkins_mount:/var/jenkins_home -v /etc/localtime:…...

【Docker】Docker 部署 Mysql 并设置数据持久化
文章目录 1. Docker持久化MySQL2. 测试删除MySQL容器后新建容器,数据还在不在3. 参考资料 我们使用Docker的目的就是图它方便下载部署,不用常规的经历下载、配置、安装等等繁琐的步骤。但是与此同时Docker也存在一些缺点,像删除容器后数据就都…...

【ARM 常见汇编指令学习 5 -- arm64汇编指令 wzr 和 xzr】
文章目录 ARM64 zero registerARMv8 zero 寄存器的背景xzr 在寄存器读写操作中的使用 上篇文章:ARM 常见汇编指令学习 4 – ARM64 比较指令 cbnz 与 b.ne 区别 下篇文章:ARM 常见汇编指令学习 6 - bic(位清除), orr(位或), eor(异或) ARM64 zero registe…...

4.4 成员变量与局部变量的区别有哪些?
文章目录 4.5 创建一个对象用什么运算符?对象实体与对象引用有何不同?4.6 一个类的构造方法的作用是什么? 若一个类没有声明构造方法,该程序能正确执行吗? 为什么?4.7 构造方法有哪些特性?4.8 在调用子类构造方法之前会先调用父类没有参数的构造方法…...
)
学生管理系统-03项目案例(3)
一、用户列表 1、编写api接口 //导入封装后的axios import {instance} from /util/request export default{getUsers:params>instance.get(/users/getUsers,{params}) } 2、表格渲染 <template><el-card><!-- 当el-table元素中注入data对象数组后&#x…...

Banana Pi BPI-KVM – 基于 Rockchip RK3568 SoC 的 KVM over IP 解决方案
Banana Pi 已经开始开发基于 Rockchip RK3568 SoC 的 BPI-KVM 盒,但它不是迷你 PC,而是 KVM over IP 解决方案,旨在远程控制另一台计算机或设备,就像您在现场一样,例如能够打开和关闭连接的设备、访问 BIOS 等。 商业…...

面试:Spring Cloud和Kubernetes的优缺点
Spring Cloud 优点 spring cloud是从应用框架层面解决微服务架构的一部分,如网关、服务发现、负载平衡、配置管理、指标跟踪等,易于Java开发者上手。 缺点 缺乏打包、持续集成、伸缩、高可用和自我修复等,且局限于Java平台。 Kubernetes …...
TSINGSEE青犀视频安防监控视频平台EasyCVR新增密码复杂度提示
智能视频监控平台TSINGSEE青犀视频EasyCVR可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等,能对外分发RTSP、RTM…...

前端开发中的正则表达式:解密规则的魔法
引言 在前端开发中,正则表达式是一个强大且不可或缺的工具,它可以帮助我们处理和验证字符串数据。无论是表单验证、数据提取还是字符串替换,正则表达式都可以发挥巨大的作用。本篇博客将全面介绍前端开发中的正则表达式,包括基本…...

const的用法
目录 const的基本理解 C和C中const的区别 代码段 不初始化or初始化 常变量or常量 编译方式 备注开发环境:vscode通过ssh连接虚拟机中的ubuntu,ubuntu-20.04.3-desktop-amd64.iso const的基本理解 const修饰的变量不能作为左值 const修饰的变量初…...
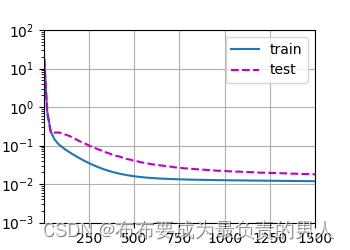
机器学习深度学习——模型选择、欠拟合和过拟合
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——多层感知机的简洁实现 📚订阅专栏:机器学习&&深度学习 希望文章对你们有…...

IP 服务级别协议监控
工作场所分布在全球多个地点的企业通过 WAN 链接共享和接收数据,这需要跨广泛的网络位置和路径持续监控网络质量,以实现优化的性能水平和不间断的服务交付。 IP 服务水平协议 IP 服务级别协议 (IP SLA) 是一种网络测量技术&…...
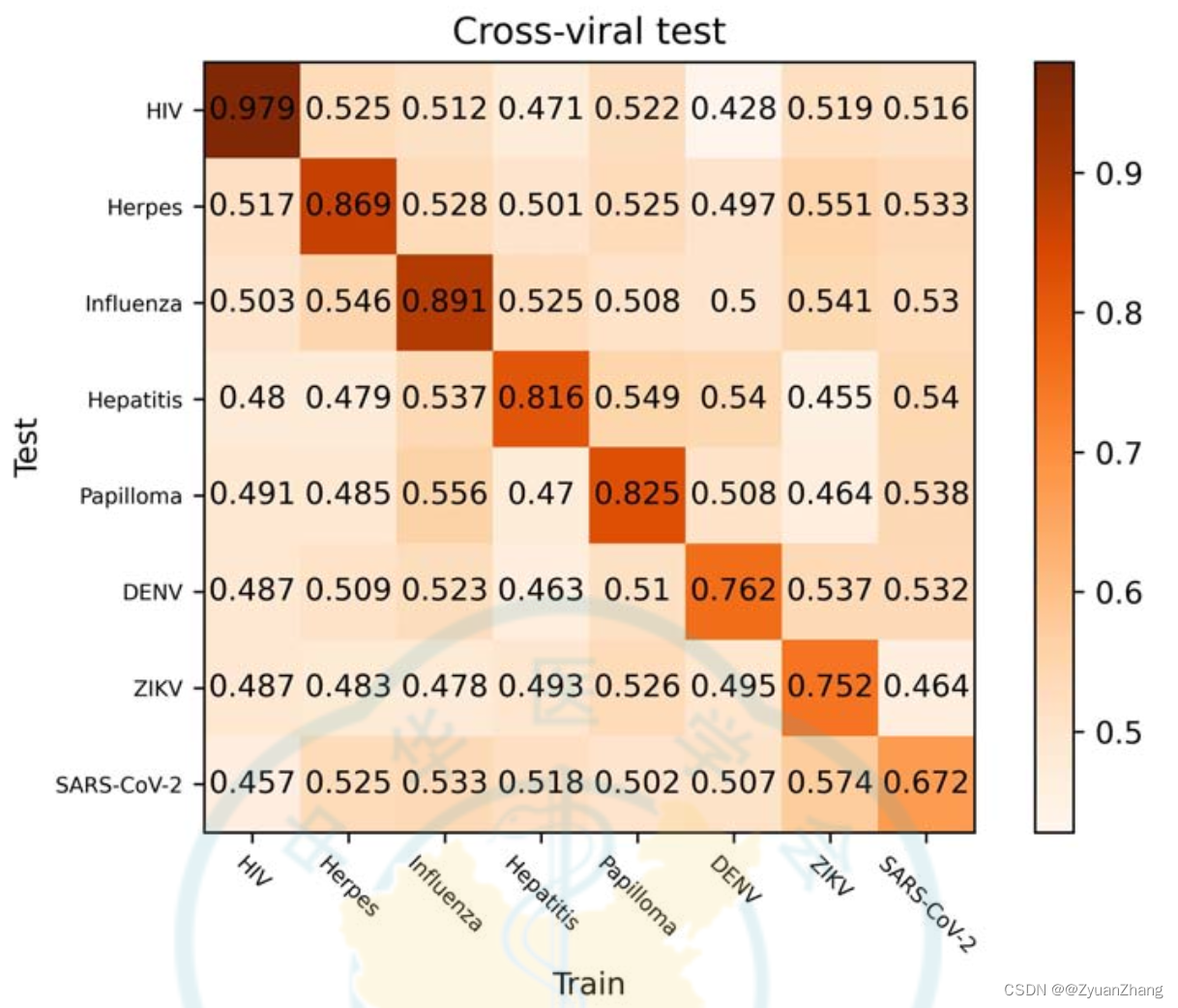
Emvirus: 基于 embedding 的神经网络来预测 human-virus PPIs【Biosafety and Health,2023】
研究背景: Human-virus PPIs 预测对于理解病毒感染机制、病毒防控等十分重要;大部分基于 machine-learning 预测 human-virus PPIs 的方法利用手动方法处理序列特征,包括统计学特征、系统发育图谱、理化性质等;本文作者提出了一个…...

安全文件传输:如何降低数据丢失的风险
在当今数字化时代,文件传输是必不可少的一项工作。但是,数据丢失一直是一个令人头疼的问题。本文将探讨一些减少数据丢失风险的方法,包括加密、备份和使用可信的传输协议等。采取这些措施将有助于保护数据免受意外丢失的危险。 一、加密保护数…...

AI绘画StableDiffusion实操教程:可爱头像奶茶小女孩(附高清图片)
本教程收集于:AIGC从入门到精通教程汇总 今天继续分享AI绘画实操教程,如何用lora包生成超可爱头像奶茶小女孩 放大高清图已放到教程包内,需要的可以自取。 欢迎来到我们这篇特别的文章——《AI绘画StableDiffusion实操教程:可爱…...

Python基础语法:访问器@property和修改器@xxx.setter
一、简介 访问器和修改器也是装饰器的一种。 property: 访问器,getter xxx.setter: 修改器,setter 访问器和修改器的根本目的是想将属性私有化,提供getter&setter去访问。 访问器和修改器能够做到访问属性其实在调用getter方法࿰…...

机器学习与深度学习在地球物理勘探中的应用:基于电阻率数据预测极化率模型
1. 项目概述与核心价值在花岗岩这类地质条件复杂的地区搞勘探,最头疼的就是地下情况“看不清”。传统的电阻率(ERT)和激发极化(IP)联合反演,就像用一把刻度模糊的尺子去量一块表面坑洼不平的石头——面对高…...

Obsidian PDF++:如何在Obsidian中实现PDF与笔记的无缝双向链接?
Obsidian PDF:如何在Obsidian中实现PDF与笔记的无缝双向链接? 【免费下载链接】obsidian-pdf-plus PDF: the most Obsidian-native PDF annotation & viewing tool ever. Comes with optional Vim keybindings. 项目地址: https://gitcode.com/gh_…...

深圳实体门店有必要做GEO AI代运营吗
深圳实体门店有必要做GEO AI代运营吗一、开篇引言2026年深圳本地实体商业竞争进入白热化阶段,全城数百万家线下实体门店涵盖本地生活、家装工装、汽车服务、餐饮娱乐、教育培训等全品类,传统线下地推、门店自然客流、传统团购平台引流效果持续下滑&#…...

用STM32CubeMX和HAL库快速上手WS2812B:告别手动计算延时,一键生成驱动框架
基于STM32CubeMX的WS2812B智能灯光控制:从零构建现代化驱动方案在智能硬件和物联网设备快速发展的今天,WS2812B可编程LED灯带因其丰富的色彩表现和简单的单线控制方式,成为创客和工程师们最喜爱的显示组件之一。然而,传统的寄存器…...

小米MIMO最新邀请码
欢迎使用,各得10元体验金...

MBTI性格测试
简介 MBTI(Myers‑Briggs Type Indicator,迈尔斯‑布里格斯类型指标)是基于荣格心理类型理论发展出的性格类型工具,由凯瑟琳库克布里格斯及其女儿伊莎贝尔布里格斯迈尔斯创建。它通过四对偏好维度将个体的认知与行为倾向归纳为 16…...

长期使用Taotoken聚合服务对项目月度账单的可预测性提升
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合服务对项目月度账单的可预测性提升 在AI驱动的项目开发与运营中,成本控制与预算规划是团队管理者…...

Linux服务器被挖矿木马劫持的五步应急处置指南
1. 这不是“中病毒”,是服务器被劫持成了矿机——先别慌,但必须立刻断网“服务器被黑客攻击,用来挖矿!”——这句话在运维圈里一出,比收到OOM告警还让人头皮发紧。它不像网页被挂马、数据库被拖库那样有明显业务影响&a…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...