Emvirus: 基于 embedding 的神经网络来预测 human-virus PPIs【Biosafety and Health,2023】

研究背景:
- Human-virus PPIs 预测对于理解病毒感染机制、病毒防控等十分重要;
- 大部分基于 machine-learning 预测 human-virus PPIs 的方法利用手动方法处理序列特征,包括统计学特征、系统发育图谱、理化性质等;
- 本文作者提出了一个名为
Emvirus的方法,它利用Doc2Vec获取蛋白序列特征,并将序列特征输入到由 CNN 和 Bi-LSTM 构成的网络中预测 human-virus PPIs;
数据集构成:
- 正样本 human-virus PPIs 来自 Yang et.al 收集的多个来源(包括 PHISTO,VirHostNet,VirusMentha,HPIDB,PDB以及一些实验数据)的 PPIs,去掉重复的和无统计学显著性的 PPIs 之后,最终得到 27493 对正样本 PPIs。
- 负样本 human-virus PPIs 来自 Yang et.al 中使用的基于 dissimilarity‐based negative sampling method 构建的负样本 PPIs。
- 正样本:负样本 = 1:10
- 训练集:测试集 = 20:1
- 对于数据集中样本类别不平衡的处理办法:作者利用 SMOTE 方法对正样本进行过采样,构建 balanced training datasets。
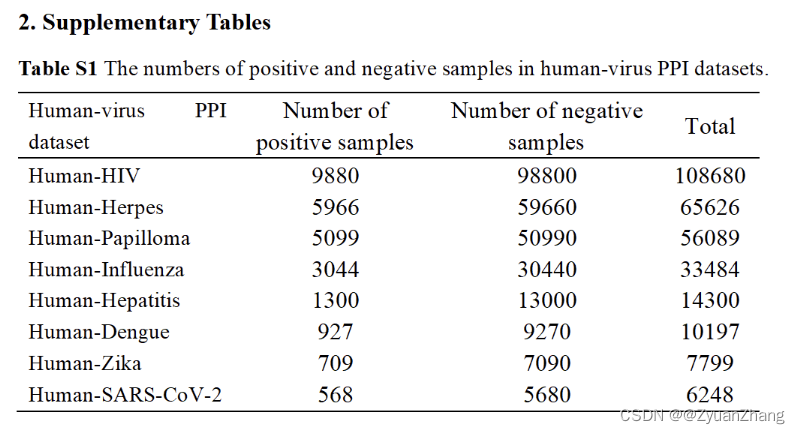
研究思路和方法:
论文代码:https://github.com/hongjiala/PPIs
1. 利用 Doc2vec 获取蛋白质序列的特征向量:
Doc2vec 是NLP中Word2vec方法的拓展,相比于 Word2vec,Doc2vec 可以从不同长度的蛋白序列中学到固定长度的序列特征表示。
(至于图中蛋白向量形状为 1x3000,暂时没想清楚怎么来的)
#【本段代码来自 作者提供的 doc2vec/doc2vec.py,我只是添加了一些注释信息。】# -*- coding: utf-8 -*-
"""
Created on Tue May 26 18:19:53 2022@author: xiepengfei
"""import numpy as np
from Bio import SeqIO
from nltk import trigrams, bigrams,ngrams ## 用来给氨基酸序列进行分词
from keras.preprocessing.text import Tokenizer
from gensim.models import Word2Vec
import re
from gensim.models.doc2vec import Doc2Vec, TaggedDocument ## 用于 embedding
from gensim.test.utils import get_tmpfilenp.set_printoptions(threshold=np.inf)## 将 每条氨基酸序列 划分成小片段,之间以空格分开,并将每一个病毒中的所有的序列保存在 texts 列表中
names = ["DENV","Hepatitis","Herpes","HIV","Influenza","Papilloma","SARS2","ZIKV"] ## 有这些病毒的序列,每个病毒序列都单独处理,训练embdding模型
for name in names:texts = []for index, record in enumerate(SeqIO.parse('fasta/%s.fasta'%name, 'fasta')):tri_tokens = ngrams(record.seq,6) ## 将蛋白质序列连续分割成长度为6的片段temp_str = ""for item in ((tri_tokens)): ## item 就是每一条氨基酸序列的片段,格式 ("A","B","C","D","E","F"), ("B","C","D","E","F","G"), ("C","D","E","F","G","H")# print(item),items = "" ## items 就是将每个片段中的氨基酸残基字符拼接成一个字符串,即 "ABCDEF", "BCDEFG", "CDEFGH"for strs in item:items = items+strstemp_str = temp_str + " " + items ## 将氨基酸片段字符串拼起来,之间以空格分开,即 "ABCDEF BCDEFG CDEFGH"#temp_str = temp_str + " " +item[0]texts.append(temp_str) ## 将 temp_str 保存到 texts 中,格式:["ABCDEF BCDEFG CDEFGH", "ABCDEF BCDEFG"]## 将 texts 中保存的氨基酸序列中的一些特殊字符(stop中列举的特殊字符)去掉,结果保存在 seq 中 (seq中的内容和texts中的内容的区别就是前者没有那些特殊字符)seq=[]stop = '[’!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~]+'for doc in texts:doc = re.sub(stop, '', doc)seq.append(doc.split())documents = [TaggedDocument(doc, [i]) for i, doc in enumerate(seq)] ## 将 seq 列表中的每条序列转化为 TaggedDocument对象,words就是每条序列doc,tags就是序列的索引[i]model = Doc2Vec(documents , vector_size=1000, window=500, min_count=1, workers=12) ## 构建 Doc2vec 模型model.train(documents ,total_examples=model.corpus_count, epochs=50) ## 训练模型#model.save("autodl-tmp/my_doc2vec_model.model") # you can continue training with the loaded model!#model.dv.save_word2vec_format('%s.vector'%name)# test_seq = ['MRQGCKFRGSSQKIRWSRSPPSSLLHTLRPRLLSAEITLQTNLPLQSPCCRLCFLRGTQAKTLK']# # test_text = ngrams(test_seq,6)# # temp_str_test = ""# # for item in ((test_text)):# # # print(item),# # print(item)# # items = ""# # for strs in item:# # items = items+strs# # temp_str = temp_str_test + " " + items# inferred_vector_dm = model.infer_vector(test_seq)# print(inferred_vector_dm)np.save("vec/new_%s_vector.npy"%name,model.dv.vectors) ## 保存特征向量
2. 将 human-virus PPI pairs 转化为 feature vector pairs
将 human 的蛋白向量、virus 的蛋白向量、标签放到一起。
如下代码所示:(详情见:https://github.com/hongjiala/PPIs/blob/master/pair/form_pair_data.py)
3. 用 SMOTE 方法对正样本进行过采样:
这部分代码是用MATLAB写的,看不太懂。详情见:https://github.com/hongjiala/PPIs/tree/master/smote
关于SMOTE的原理(参考:arXiv:1106.1813):
This paper shows that a combination of our method of over-sampling the minority (abnormal) class and under-sampling the majority (normal) class can achieve better classifier performance (in ROC space) than only under-sampling the majority class.
This approach is inspired by a technique that proved successful in handwritten character recognition (Ha & Bunke, 1997). They created extra training data by performing certain operations on real data. In their case, operations like rotation and skew were natural ways to perturb the training data.
We generate synthetic examples in a less application-specific manner, by operating in “feature space” rather than “data space”.
The minority class is over-sampled by taking each minority class sample and introducing synthetic examples along the line segments joining any/all of the k minority class nearest neighbors. Depending upon the amount of over-sampling required, neighbors from the k nearest neighbors are randomly chosen.

简单来说的话就是:在原始样本的 “feature space” 中某个样本点 i i i的最近邻的 k k k个样本点中随机的一个点 n n nn nn,计算 n n nn nn和 i i i在 “feature space” 中的特征差值 d i f dif dif,然后生成0-1之间随机数 g a p gap gap,则新生成的样本点 n e w i n d e x newindex newindex的特征值 = i i i的特征值 + g a p gap gap * d i f dif dif
4. 构建模型:
由 CNN、Attention 和 Bi-LSTM 构建模型,详情见(https://github.com/hongjiala/PPIs/blob/master/train/model_protein.py)

5. 训练并测试模型:
详情见:https://github.com/hongjiala/PPIs/tree/master/train
实验结果及讨论:
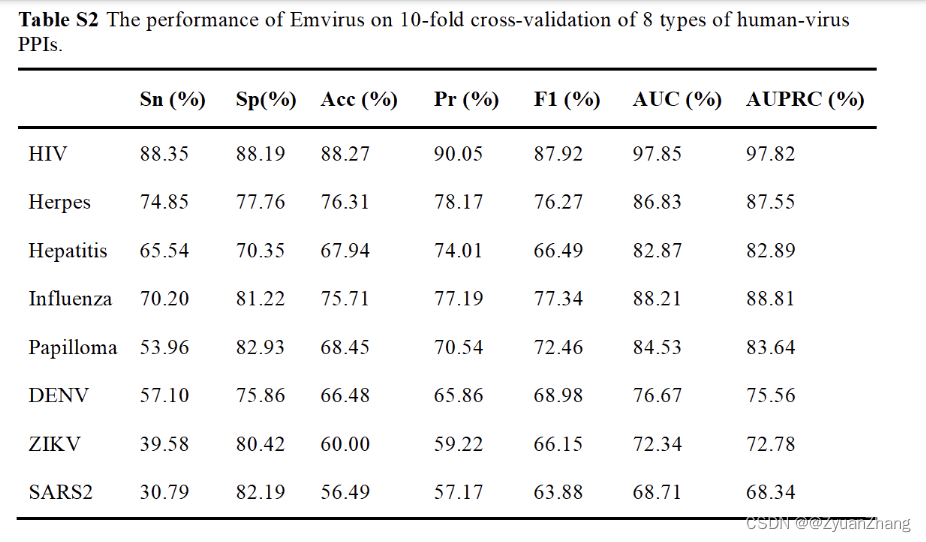
作者对每一种病毒都用相同的神经网络框架分别训练了一个模型,每个病毒对应的模型的预测结果:
1. 各模型对各自的 human-virus PPIs 预测结果:
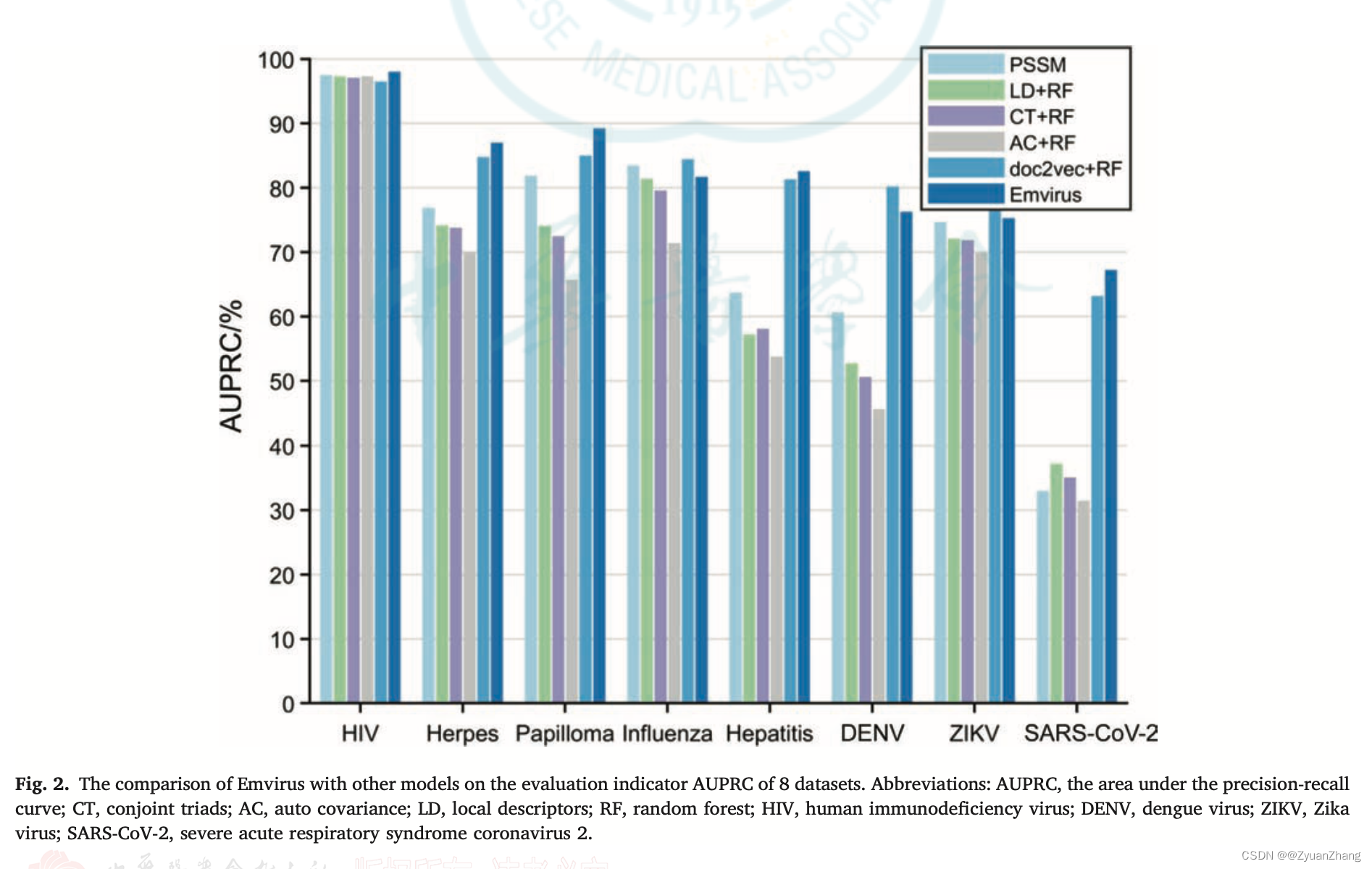
2. 不同特征及不同模型对各病毒的 human-virus PPIs 预测结果:
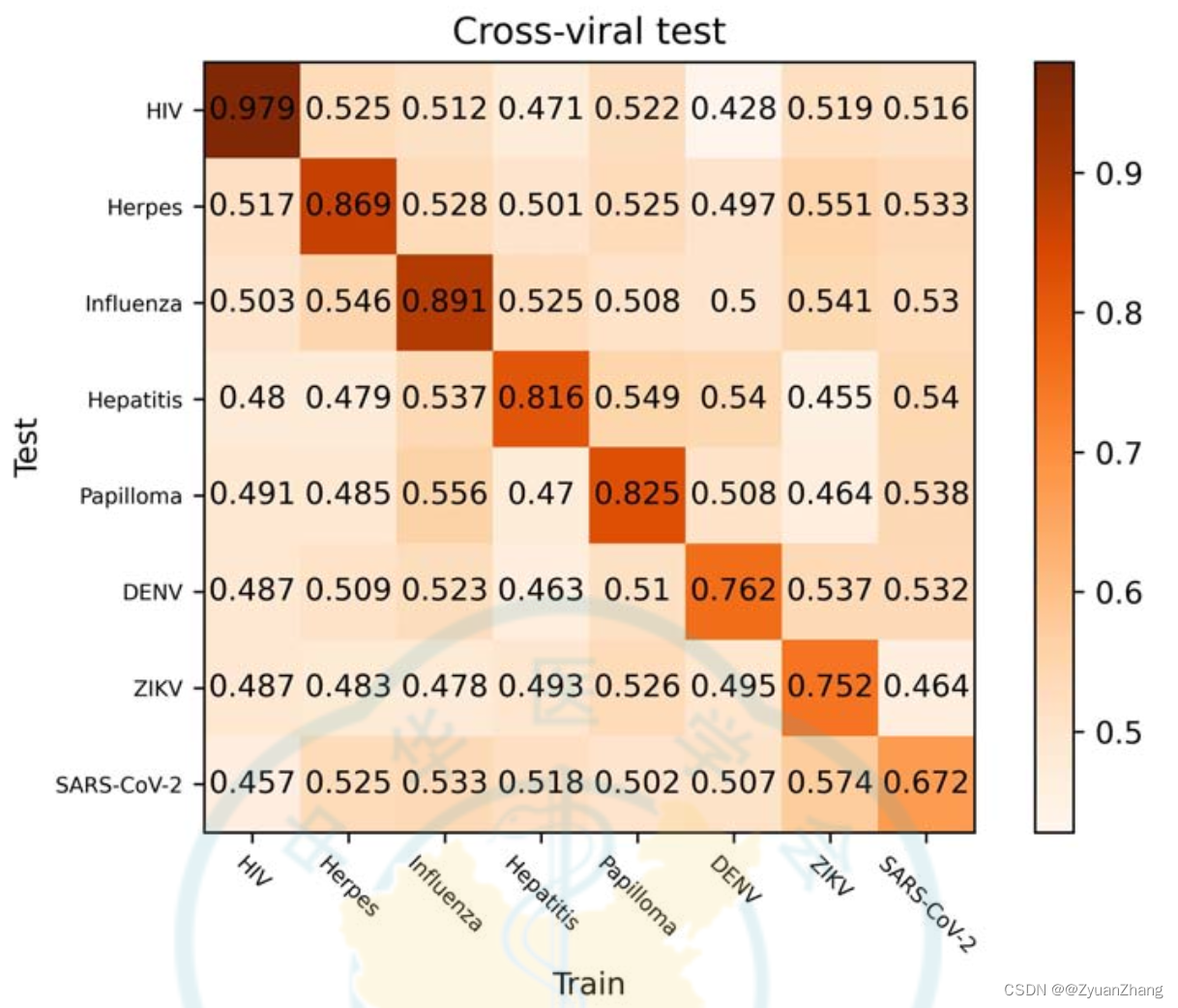
3. 各模型跨病毒的 human-virus PPIs 预测结果:
讨论:
- 基于 Doc2Vec + CNN + Bi-LSTM 的方法构建的模型,并以不同病毒的 human-virus PPIs 数据分别对模型进行训练,除了某些病毒以外,大部分的病毒的模型的预测效果挺好的。
- 与手动抽取序列特征的方法(如 PSSM,LD,CT,AC等)相比,用 Doc2Vec 可以更好地获取序列特征。
- 用不同病毒的 PPIs 数据训练的模型在进行跨病毒的 human-virus PPIs 预测的时候,模型基本没有分辨能力,即模型的泛化能力较差,可能是由于不同病毒的 human-virus PPIs 的数据分布或者特征组成差别较大导致的。
- 整体上而言,Doc2Vec + LSTM 可以对某些特定的病毒实现比较好的 human-virus PPIs 预测。
相关文章:
Emvirus: 基于 embedding 的神经网络来预测 human-virus PPIs【Biosafety and Health,2023】
研究背景: Human-virus PPIs 预测对于理解病毒感染机制、病毒防控等十分重要;大部分基于 machine-learning 预测 human-virus PPIs 的方法利用手动方法处理序列特征,包括统计学特征、系统发育图谱、理化性质等;本文作者提出了一个…...

安全文件传输:如何降低数据丢失的风险
在当今数字化时代,文件传输是必不可少的一项工作。但是,数据丢失一直是一个令人头疼的问题。本文将探讨一些减少数据丢失风险的方法,包括加密、备份和使用可信的传输协议等。采取这些措施将有助于保护数据免受意外丢失的危险。 一、加密保护数…...

AI绘画StableDiffusion实操教程:可爱头像奶茶小女孩(附高清图片)
本教程收集于:AIGC从入门到精通教程汇总 今天继续分享AI绘画实操教程,如何用lora包生成超可爱头像奶茶小女孩 放大高清图已放到教程包内,需要的可以自取。 欢迎来到我们这篇特别的文章——《AI绘画StableDiffusion实操教程:可爱…...

java8 GroupingBy 用法大全
java8中,Collectors.groupingBy 会用得比较多,对其常见用法做一个汇总 1,模拟数据 Item import java.math.BigDecimal;public class Item {private String name;private Integer quantity;private BigDecimal price;public Item(String nam…...

vue_router__WEBPACK_IMPORTED_MODULE_1__.default is not a constructor
你所建立的项目 是 vue2x ,但是却下载了 vue-router4x 而 vue-router4x 适用于 vue3x 所以你需要卸载 vue-router4x,重新下载 vue-router3x 卸载: npm uninstall vue-router 安装:(3版本) npm i vue-router3...

前端html2canvas和dom-to-image实现截图功能
目录 需求 历劫过程 截图知识点 html2canvas 文档地址 封装 使用教程 dom-to-image-more 文档地址 封装 使用教程 解决跨域问题 以下是我花了大把时间,薅秃头得出来的最终结果, dom-to-image-more截图时间快到可以让复杂的页面仅需2-3S就能完成截图,内容有点多…...
)
Hadoop平台集群之间Hive表和分区的导出和导入迁移(脚本)
要编写Shell脚本实现两个Hadoop平台集群之间Hive表和分区的导出和导入迁移 你可以使用Hive的EXPORT和IMPORT命令结合Hadoop的DistCp命令。下面是一个示例脚本: #!/bin/bash# 导出源Hive表的数据到HDFS source_hive_table"source_db.source_table" targe…...

Linux C语言实践eBPF
手动编译了解过程 通过对关键步骤make Msamples/bpf的实践,我们已经可以编译出内核源码中提供的ebpf样例。但这还不够我们充分地理解这个编译过程,我们将这编译过程拆解一下,拆解成可以一步步执行的那种,首先是环境准备ÿ…...
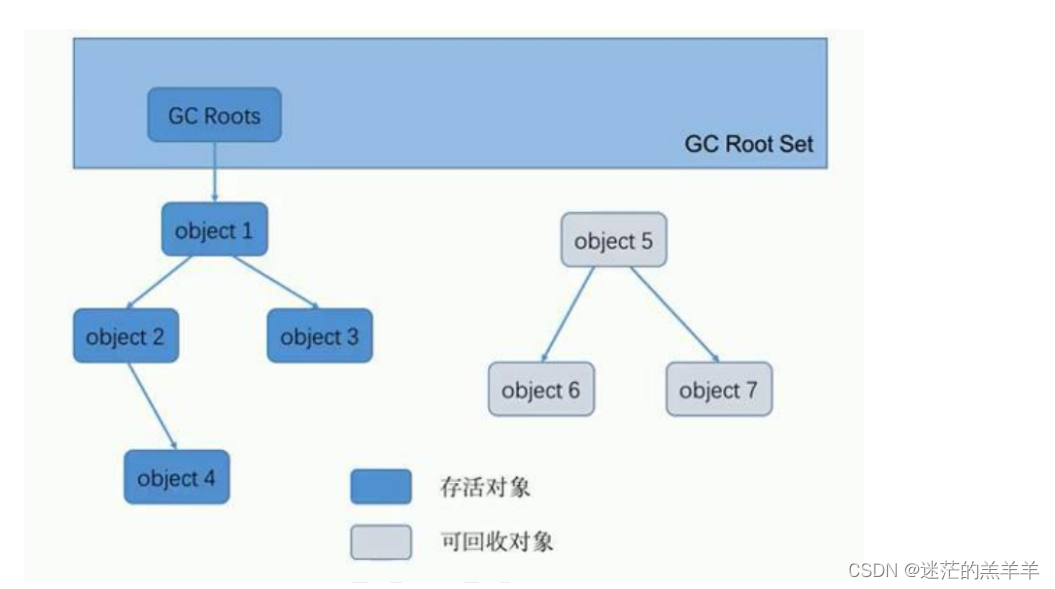
垃圾回收标记阶段算法
1.标记阶段的目的 主要是在GC在前,判断出哪些是有用的对象,哪些是需要回收的对象,只有被标记为垃圾对象,GC才会对其进行垃圾回收。判断对象是否为垃圾对象的两种方式:引用计数算法和可达性分析算法。 2.引用计数算法…...

泰晓科技发布 Linux Lab v1.2 正式版
导读近日消息,Linux Lab 是一套用于 Linux 内核学习、开发和测试的即时实验室,官方称其“可以极速搭建和使用,功能强大,用法简单”。 自去年 12 月份发布 Linux Lab v1.1 后,v1.2 正式版目前已经发布于 GitHub 及 Gite…...

王道数据结构-代码实操1(全注解版)
#include<stdio.h>void loveyou(int n){ // 传入参数类型为int型,在此函数中表示为n;返回值类型为void,即没有返回值; int i1; //定义了一个整数型变量i,且只在loveyou函数中有用;while(i…...
flink写入到kafka 大坑解析。
1.kafka能不能发送null消息? 能! 2 flink能不能发送null消息到kafka? 不能! public static void main(String[] args) throws Exception {StreamExecutionEnvironment env StreamExecutionEnvironment.getExecutionEnvironment(…...

MATLAB算法实战应用案例精讲-【深度学习】预训练模型-Subword
目录 前言 Subword 1. Subword介绍 分词器是做什么的? 为什么需要分词? 分词方法...
)
【HarmonyOS】实现从视频提取音频并保存到pcm文件功能(API6 Java)
【关键字】 视频提取类Extractor、视频编解码、保存pcm文件 【写在前面】 在使用API6开发HarmonyOS应用时,通常会开发一些音视频媒体功能,这里介绍如何从视频中提取音频保存到pcm文件功能,生成pcm音频文件后,就可使用音频播放类…...
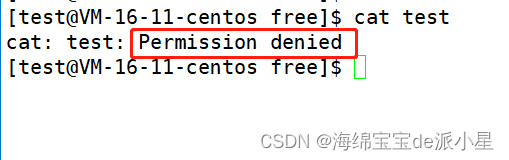
Linux:shell命令运行原理和权限的概念
文章目录 shell和kernelshell的概念和原理Linux的权限文件的权限文件的类型文件的权限管理权限的实战应用 shell和kernel 从狭义上来讲,Linux是一个操作系统,我们叫它叫kernel,意思是核心,核心的意思顾名思义,就是最关…...

Javascript -- 数组prototype方法探究
一、数组prototype方法探究 1、不改变原数组 1. concat() 这个是数组拼接方法,可以将两个数组或多个数组拼接并返回一个包含两个数组或多个数组内容的新数组,不会改变原数组 方法里面理论上可以写入n个参数, const arr [1,2]; var str …...
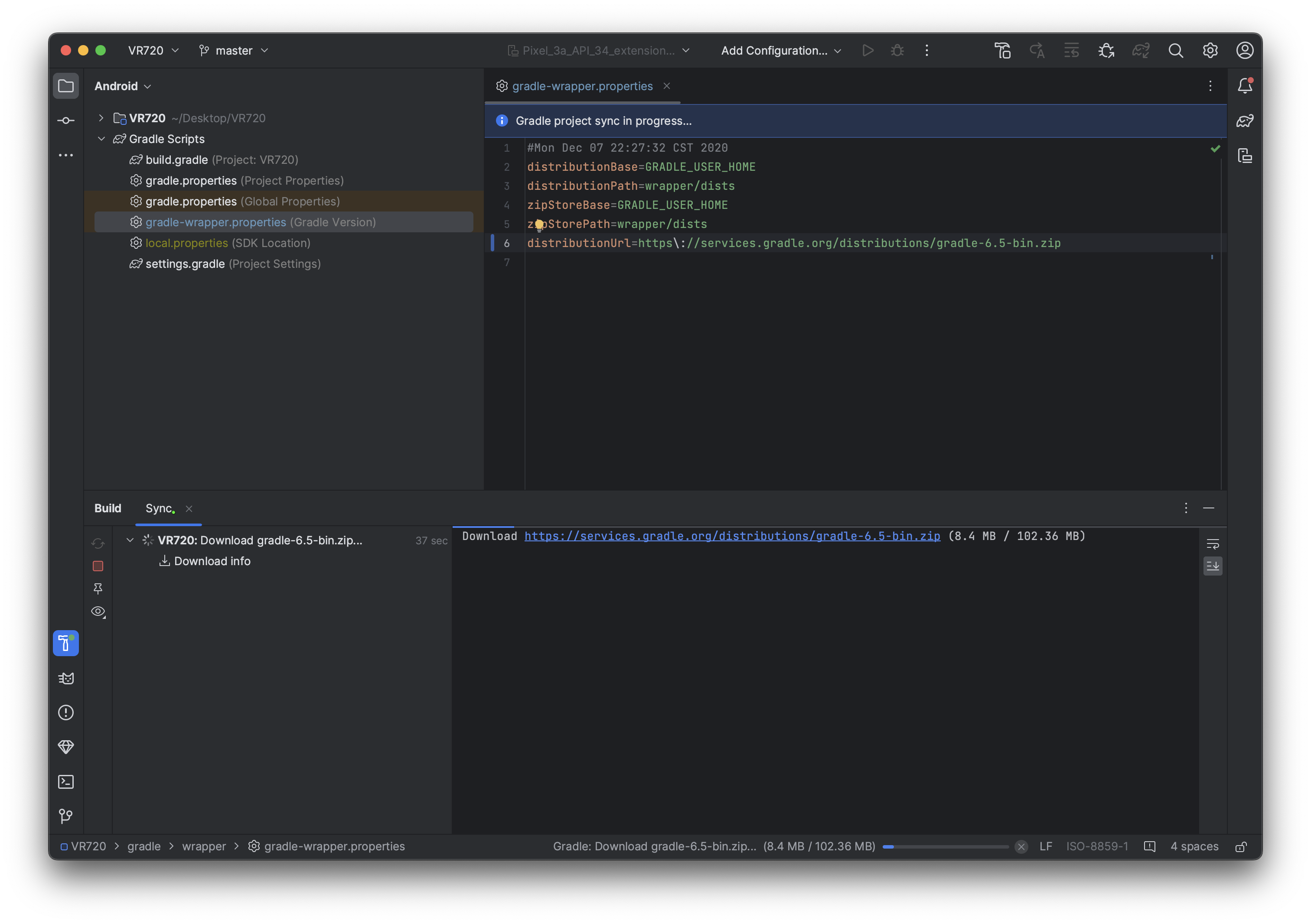
android stduio 打开工程后直接报Connection refused解决
报错如下:Connection refused 解决方案: 打开gradle-wrapper.properties修改distributionUrl 将: distributionUrlhttp\://localhost/gradle/distributions/gradle-6.5-bin.zip 替换为: distributionUrlhttps\://services.gradle.org/distributions/gradle-6.5-bin.zip 错…...

搜索与图论(一)
一、DFS与BFS 1.1深度优先搜索(DFS) DFS不具有最短性 //排列数字问题 #include<iostream> using namespace std;const int N 10; int n; int path[N]; bool st[N];void dfs(int u) {if(u n){for(int i 0;i < n;i) printf("%d",path[i]);puts("&qu…...

百题千解计划【CSDN每日一练】“小明投篮,罚球线投球可得一分”(附解析+多种实现方法:Python、Java、C、C++、C#、Go、JavaScript)
这个心上人,还不知道在哪里,感觉明天就会出现。 🎯作者主页: 追光者♂🔥 🌸个人简介: 💖[1] 计算机专业硕士研究生💖 🌟[2] 2022年度博客之星人工智能领域TOP4🌟 🏅[3] 阿里云社区特邀专家博主🏅 🏆[4] CSDN-人工智能领域优质创作者�…...

lemon框架开发笔记
lemon框架开发笔记 JudgeUtils.isBlank() 字符串为 null 或者 "" ----返回true JudgeUtils.isNotBlankAll() 字符串全部不为 null 或者 "" ----返回true JudgeUtils.isBlankAll() 字符串全部为 null 或者 "" ----返回true// isBlank 是在isEmpt…...

Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南
Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南 【免费下载链接】Qwen3-Coder-30B-A3B-Instruct-FP8 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8 在当今AI代码生成领域,Qwen3-Coder-30B-…...

从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤
从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤在当今数据驱动的时代,对象存储已成为现代应用架构中不可或缺的一部分。MinIO作为高性能、兼容S3协议的开源对象存储解决方案,凭借其轻量级和易用性赢得了众多…...

亚马逊卖家公开信息数据提取:反爬攻防战与 Python 批量采集实战
摘要: 批量获取亚马逊(Amazon)第三方卖家的商业名称、信用代码和注册地址等信息,对于跨境 B2B 拓客和供应链分析具有重要意义。然而,亚马逊的 Cloudflare 盾和 Robot 验证码构成了极高的反爬门槛。本文将深度解析亚马逊…...

串口通信粘包问题:成因深度解析与项目实战解决方案
在嵌入式开发、工业工控、上位机下位机交互项目中,串口(RS232/RS485)是最基础、最常用的通信方式。绝大多数开发者都遇到过这样的问题:串口接收的数据偶尔错乱、解析报错、数据拼接异常,单次接收的数据时而半包、时而多…...

告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF
告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF 【免费下载链接】caj2pdf Convert CAJ (China Academic Journals) files to PDF. 转换中国知网 CAJ 格式文献为 PDF。佛系转换,成功与否,皆是玄学。 项目地址: https://gitcode.com/…...

告别元素变动导致的报错:探索自动化测试脚本的 AI“自愈”能力
前言:一个所有测试人都经历过的噩梦 周三晚上十一点,CI/CD流水线再次亮起红灯。 你打开日志,满屏的NoSuchElementException扑面而来。仔细一看——前端团队在昨天的版本中重构了登录页面的DOM结构,原本的#login-btn变成了#signin-button-v2,30个测试用例因此全军覆没。 …...

CUDA并行计算与FSR框架优化实践
1. CUDA并行计算与FSR框架概述在GPU加速计算领域,CUDA(Compute Unified Device Architecture)作为NVIDIA推出的并行计算平台和编程模型,已经成为高性能计算的事实标准。其核心设计理念是将计算任务分解为网格(Grid&…...

什么情况下会核销贷款
贷款核销的核心前提是:贷款被认定为 “损失类” 且经 “穷尽追偿” 仍无法收回,银行按监管与会计规则从账面冲销,但债权不消灭、仍可追偿。一、核心认定条件(满足其一即可)破产 / 注销 / 吊销:借款人和担保…...

基于SMD与贝壳的微型音频装置:从电路设计到嵌入式开发的完整实践
1. 项目概述:一个藏在贝壳里的声音世界你小时候有没有捡起一个海螺壳,把它贴在耳边,然后听到里面传来“呜呜”的海风声?那个瞬间,仿佛整个海洋都被装进了小小的贝壳里。今天这个项目,就是把那个童年的魔法&…...

LeagueAkari:英雄联盟终极自动化助手革命性指南
LeagueAkari:英雄联盟终极自动化助手革命性指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否在英雄联盟游戏中反复经历这…...