【雕爷学编程】MicroPython动手做(10)——零基础学MaixPy之神经网络KPU2
KPU的基础架构
让我们回顾下经典神经网络的基础运算操作:
卷积(Convolution):1x1卷积,3x3卷积,5x5及更高的卷积
批归一化(Batch Normalization)
激活(Activate)
池化(Pooling)
矩阵运算(Matrix Calculate):矩阵乘,加
对于基础的神经网络结构,仅具备1,2,3,4 四种操作;
对于新型网络结构,比如ResNet,在卷积结果后会加一个变量,就需要使用第五种操作,矩阵运算。
对于MAIX的主控芯片K210来说,它内置实现了 卷积,批归一化,激活,池化 这4钟基础操作的硬件加速,但是没有实现一般的矩阵运算,所以在实现的网络结构上有所限制。
对于需要额外操作的网络结构,用户必须在硬件完成基础操作后,手工插入CPU干预的处理层实现,会导致帧数降低,所以建议用户优化自己的网络结构到基础网络形式。
所幸的是,该芯片的第二代将支持通用矩阵计算,并固化更多类型的网络结构。
在KPU中,上述提到的4种基础操作并非是单独的加速模块,而是合成一体的加速模块,有效避免了CPU干预造成的损耗,但也丧失了一些操作上的灵活性。
从standalone sdk/demo 以及 Model Compiler 中分析出 KPU加速模块的原理框图如下,看图即懂。

#MicroPython动手做(10)——零基础学MaixPy之神经网络KPU
#实验程序之一:运行人脸识别demo(简单演示)
#模型下载地址:http://dl.sipeed.com/MAIX/MaixPy/model/face_model_at_0x300000.kfpkg
下载后模型文件夹内有二个文件


打开kflash_gui
使用kfpkg将 二个模型文件 与 maixpy 固件打包下载到 flash

打包kfpkg时出错,好像是文件地址范围不同…

尝试多次一直不行,两者不兼容。后来干脆不打包了,只烧录模型文件kfpkg(原来烧录过MaixPy固件V0.4.0),没想到可以了,这下明白了,固件和模型分开烧录也行。

#MicroPython动手做(10)——零基础学MaixPy之神经网络KPU
#实验程序之一:运行人脸识别demo(简单演示)
#模型下载地址:http://dl.sipeed.com/MAIX/MaixPy … l_at_0x300000.kfpkg
#MicroPython动手做(10)——零基础学MaixPy之神经网络KPU
#实验程序之一:运行人脸识别demo(简单演示)
#模型下载地址:http://dl.sipeed.com/MAIX/MaixPy ... l_at_0x300000.kfpkgimport sensor
import image
import lcd
import KPU as kpulcd.init()
sensor.reset()
sensor.set_pixformat(sensor.RGB565)
sensor.set_framesize(sensor.QVGA)
sensor.run(1)
task = kpu.load(0x300000) #使用kfpkg将 kmodel 与 maixpy 固件打包下载到 flash
anchor = (1.889, 2.5245, 2.9465, 3.94056, 3.99987, 5.3658, 5.155437, 6.92275, 6.718375, 9.01025)
a = kpu.init_yolo2(task, 0.5, 0.3, 5, anchor)
while(True):img = sensor.snapshot()code = kpu.run_yolo2(task, img)if code:for i in code:print(i)a = img.draw_rectangle(i.rect())a = lcd.display(img)
a = kpu.deinit(task)

串口输出了大量数据
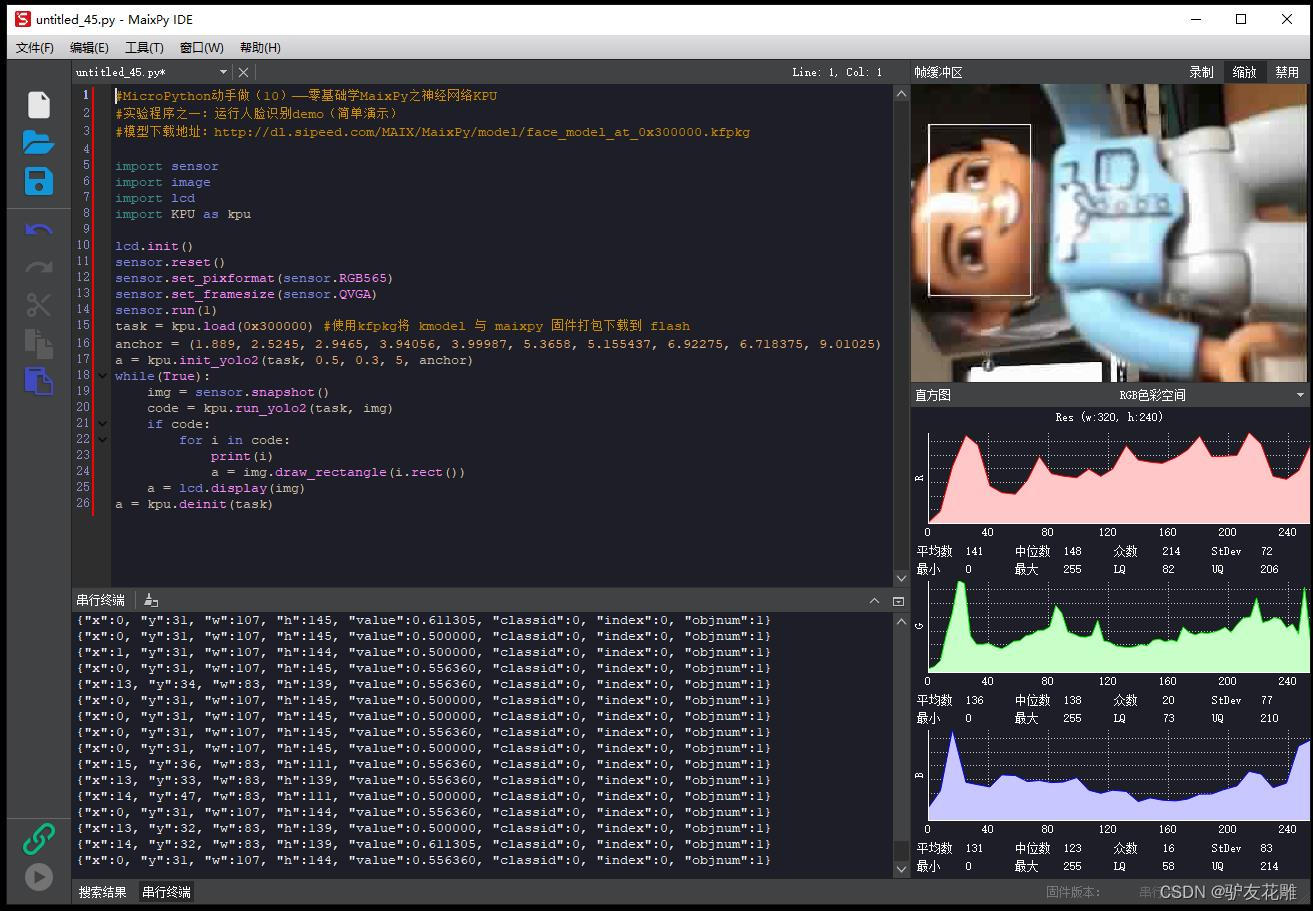
{“x”:0, “y”:31, “w”:107, “h”:145, “value”:0.611305, “classid”:0, “index”:0, “objnum”:1}
{“x”:0, “y”:31, “w”:107, “h”:145, “value”:0.500000, “classid”:0, “index”:0, “objnum”:1}
{“x”:1, “y”:31, “w”:107, “h”:144, “value”:0.500000, “classid”:0, “index”:0, “objnum”:1}
{“x”:0, “y”:31, “w”:107, “h”:145, “value”:0.556360, “classid”:0, “index”:0, “objnum”:1}
{“x”:13, “y”:34, “w”:83, “h”:139, “value”:0.556360, “classid”:0, “index”:0, “objnum”:1}
{“x”:0, “y”:31, “w”:107, “h”:145, “value”:0.500000, “classid”:0, “index”:0, “objnum”:1}
{“x”:0, “y”:31, “w”:107, “h”:145, “value”:0.500000, “classid”:0, “index”:0, “objnum”:1}
{“x”:0, “y”:31, “w”:107, “h”:145, “value”:0.556360, “classid”:0, “index”:0, “objnum”:1}
{“x”:0, “y”:31, “w”:107, “h”:145, “value”:0.500000, “classid”:0, “index”:0, “objnum”:1}
{“x”:15, “y”:36, “w”:83, “h”:111, “value”:0.556360, “classid”:0, “index”:0, “objnum”:1}
{“x”:13, “y”:33, “w”:83, “h”:139, “value”:0.556360, “classid”:0, “index”:0, “objnum”:1}
{“x”:14, “y”:47, “w”:83, “h”:111, “value”:0.500000, “classid”:0, “index”:0, “objnum”:1}
{“x”:0, “y”:31, “w”:107, “h”:144, “value”:0.556360, “classid”:0, “index”:0, “objnum”:1}
{“x”:13, “y”:32, “w”:83, “h”:139, “value”:0.500000, “classid”:0, “index”:0, “objnum”:1}
{“x”:14, “y”:32, “w”:83, “h”:139, “value”:0.611305, “classid”:0, “index”:0, “objnum”:1}
{“x”:0, “y”:31, “w”:107, “h”:144, “value”:0.556360, “classid”:0, “index”:0, “objnum”:1}
KPU是通用的神经网络处理器,它可以在低功耗的情况下实现卷积神经网络计算,时时获取被检测目标的大小、坐标和种类,对人脸或者物体进行检测和分类。KPU模块方法:
- 加载模型
从flash或者文件系统中加载模型
import KPU as kpu
task = kpu.load(offset or file_path)
参数
offtset: 模型在 flash 中的偏移大小,如 0xd00000 表示模型烧录在13M起始的地方
file_path: 模型在文件系统中为文件名, 如 “/sd/xxx.kmodel”
返回
kpu_net: kpu 网络对象
- 初始化yolo2网络
为yolo2网络模型传入初始化参数
import KPU as kpu
task = kpu.load(offset or file_path)
anchor = (1.889, 2.5245, 2.9465, 3.94056, 3.99987, 5.3658, 5.155437, 6.92275, 6.718375, 9.01025)
kpu.init_yolo2(task, 0.5, 0.3, 5, anchor)
参数
kpu_net: kpu 网络对象
threshold: 概率阈值
nms_value: box_iou 门限
anchor_num: 锚点数
anchor: 锚点参数与模型参数一致
- 反初始化
import KPU as kpu
task = kpu.load(offset or file_path)
kpu.deinit(task)
参数
kpu_net: kpu_load 返回的 kpu_net 对象
- 运行yolo2网络
import KPU as kpu
import image
task = kpu.load(offset or file_path)
anchor = (1.889, 2.5245, 2.9465, 3.94056, 3.99987, 5.3658, 5.155437, 6.92275, 6.718375, 9.01025)
kpu.init_yolo2(task, 0.5, 0.3, 5, anchor)
img = image.Image()
kpu.run_yolo2(task, img)
参数
kpu_net: kpu_load 返回的 kpu_net 对象
image_t:从 sensor 采集到的图像
返回
list: kpu_yolo2_find 的列表
- 网络前向运算(forward)
计算已加载的网络模型到指定层数,输出目标层的特征图
import KPU as kpu
task = kpu.load(offset or file_path)
……
fmap=kpu.forward(task,img,3)
参数
kpu_net: kpu_net 对象
image_t: 从 sensor 采集到的图像
int: 指定计算到网络的第几层
返回
fmap: 特征图对象,内含当前层所有通道的特征图
- fmap 特征图
取特征图的指定通道数据到image对象
img=kpu.fmap(fmap,1)
参数
fmap: 特征图 对象
int: 指定特征图的通道号】
返回
img_t: 特征图对应通道生成的灰度图
- fmap_free 释放特征图
释放特征图对象
kpu.fmap_free(fmap)
参数
fmap: 特征图 对象
返回
无
- netinfo
获取模型的网络结构信息
info=kpu.netinfo(task)
layer0=info[0]
参数
kpu_net: kpu_net 对象
返回
netinfo list:所有层的信息list, 包含信息为:
index:当前层在网络中的层数
wi:输入宽度
hi:输入高度
wo:输出宽度
ho:输出高度
chi:输入通道数
cho:输出通道数
dw:是否为depth wise layer
kernel_type:卷积核类型,0为1x1, 1为3x3
pool_type:池化类型,0不池化; 1:2x2 max pooling; 2:…
para_size:当前层的卷积参数字节数
KPU寄存器配置说明
芯片厂家没有给出寄存器手册,我们从kpu.c, kpu.h, Model Compiler中分析各寄存器定义。KPU的寄存器配置写在 kpu_layer_argument_t 结构体中,我们取standalone demo中的kpu demo中的gencode.c来分析.(https://github.com/kendryte/kend … pu/gencode_output.c)
//层参数列表,共16层kpu_layer_argument_t la[] __attribute__((aligned(128))) = {
// 第0层{
.kernel_offset.data = {.coef_row_offset = 0, //固定为0.coef_column_offset = 0 //固定为0
},
.image_addr.data = { //图像输入输出地址,一个在前,一个在后,下一层运算的时候翻过来,可以避免拷贝工作。.image_dst_addr = (uint64_t)0x6980, //图像输出地址,int((0 if idx & 1 else (img_ram_size - img_output_size)) / 64).image_src_addr = (uint64_t)0x0 //图像加载地址
},
.kernel_calc_type_cfg.data = {.load_act = 1, //使能激活函数,必须使能(硬件设计如此),不使能则输出全为0.active_addr = 0, //激活参数加载首地址,在kpu_task_init里初始化为激活折线表.row_switch_addr = 0x5, //图像宽占用的单元数,一个单元64Byte. ceil(width/64)=ceil(320/64)=5.channel_switch_addr = 0x4b0, //单通道占用的单元数. row_switch_addr*height=5*240=1200=0x4b0.coef_size = 0, //固定为0.coef_group = 1 //一次可以计算的组数,因为一个单元64字节,//所以宽度>32,设置为1;宽度17~32,设置为2;宽度<=16,设置为4
},
.interrupt_enabe.data = {.depth_wise_layer = 0, //常规卷积层,设置为0.ram_flag = 0, //固定为0.int_en = 0, //失能中断.full_add = 0 //固定为0
},
.dma_parameter.data = { //DMA传输参数.dma_total_byte = 307199, //该层输出16通道,即 19200*16=308200.send_data_out = 0, //使能输出数据.channel_byte_num = 19199 //输出单通道的字节数,因为后面是2x2 pooling, 所以大小为160*120=19200
},
.conv_value.data = { //卷积参数,y = (x*arg_x)>>shr_x.arg_x = 0x809179, //24bit 乘法参数.arg_w = 0x0,.shr_x = 8, //4bit 移位参数.shr_w = 0
},
.conv_value2.data = { //arg_add = kernel_size * kernel_size * bw_div_sw * bx_div_sx =3x3x?x?.arg_add = 0
},
.write_back_cfg.data = { //写回配置.wb_row_switch_addr = 0x3, //ceil(160/64)=3.wb_channel_switch_addr = 0x168, //120*3=360=0x168.wb_group = 1 //输入行宽>32,设置为1
},
.image_size.data = { //输入320*240,输出160*120.o_col_high = 0x77,.i_col_high = 0xef,.i_row_wid = 0x13f,.o_row_wid = 0x9f
},
.kernel_pool_type_cfg.data = {.bypass_conv = 0, //硬件不能跳过卷积,固定为0.pad_value = 0x0, //边界填充0.load_para = 1, //硬件不能跳过归一化,固定为1.pad_type = 0, //使用填充值.kernel_type = 1, //3x3设置为1, 1x1设置为0.pool_type = 1, //池化类型,步长为2的2x2 max pooling.dma_burst_size = 15, //dma突发传送大小,16字节;脚本中固定为16.bwsx_base_addr = 0, //批归一化首地址,在kpu_task_init中初始化.first_stride = 0 //图像高度不超过255;图像高度最大为512。
},
.image_channel_num.data = {.o_ch_num_coef = 0xf, //一次性参数加载可计算的通道数,16通道。4K/单通道卷积核数//o_ch_num_coef = math.floor(weight_buffer_size / o_ch_weights_size_pad) .i_ch_num = 0x2, //输入通道,3通道 RGB.o_ch_num = 0xf //输出通道,16通道
},
.kernel_load_cfg.data = {.load_time = 0, //卷积加载次数,不超过72KB,只加载一次.para_size = 864, //卷积参数大小864字节,864=3(RGB)*9(3x3)*2*16.para_start_addr = 0, //起始地址.load_coor = 1 //允许加载卷积参数
}
},//第0层参数结束……
};上表中还有些结构体内容没有填充,是在KPU初始化函数中填充:```kpu_task_t* kpu_task_init(kpu_task_t* task){
la[0].kernel_pool_type_cfg.data.bwsx_base_addr = (uint64_t)&bwsx_base_addr_0; //初始化批归一化表
la[0].kernel_calc_type_cfg.data.active_addr = (uint64_t)&active_addr_0; //初始化激活表
la[0].kernel_load_cfg.data.para_start_addr = (uint64_t)¶_start_addr_0; //初始化参数加载
…… //共16层参数,逐层计算
task->layers = la;
task->layers_length = sizeof(la)/sizeof(la[0]); //16层
task->eight_bit_mode = 0; //16bit模式
task->output_scale = 0.12349300010531557; //输出的缩放,偏置
task->output_bias = -13.528212547302246;
return task;
}```
相关文章:
【雕爷学编程】MicroPython动手做(10)——零基础学MaixPy之神经网络KPU2
KPU的基础架构 让我们回顾下经典神经网络的基础运算操作: 卷积(Convolution):1x1卷积,3x3卷积,5x5及更高的卷积 批归一化(Batch Normalization) 激活(Activate) 池化&…...
BUG分析以及BUG定位
一般来说bug大多数存在于3个模块: 1、前台界面,包括界面的显示,兼容性,数据提交的判断,页面的跳转等等,这些bug基本都是一眼可见的,不太需要定位,当然也不排除一些特殊情况…...
Day46 算法记录| 动态规划 13(子序列)
这里写目录标题 300.最长递增子序列 674. 最长连续递增序列718. 最长重复子数组 300.最长递增子序列 视频解析: 第一层for循环遍历每一个元素, ------- 第二层for循环找到当前元素前面有几个小于该值的元素 结尾需要统计最多的个数 class Solution {pu…...
)
结构型-桥接模式(Bridge Pattern)
概述 桥接模式(Bridge Pattern)是一种结构型设计模式,将抽象部分和实现部分分离,使它们可以独立地变化。桥接模式通过将继承关系转化为关联关系,将抽象部分和实现部分分离开来,从而使它们可以独立地变化。…...
基于小波哈尔法(WHM)的一维非线性IVP测试问题的求解(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 🌈4 Matlab代码实现 💥1 概述 小波哈尔法(WHM)是一种求解一维非线性初值问题(IVP)的数值方法。它基于小波分析的思想…...
如何读取本地配置文件)
前端(Electron Nodejs)如何读取本地配置文件
使用electron封装了前端界面之后,最终打包为一个客户端(exe)。但是,最近项目组内做CS(c开发)的,想把所有的配置都放进安装目录的配置文件中(比如config.json)。这做法&am…...

没有 telnet 不能测试端口?容器化部署最佳的端口测试方式
写在前面 生产中遇到,整理笔记在容器中没有 telnet ,如何测试远程端口理解不足小伙伴帮忙指正 他的一生告诉我们,不能自爱就不能爱人,憎恨自己也必憎恨他人,最后也会像可恶的自私一样,使人变得极度孤独和悲…...
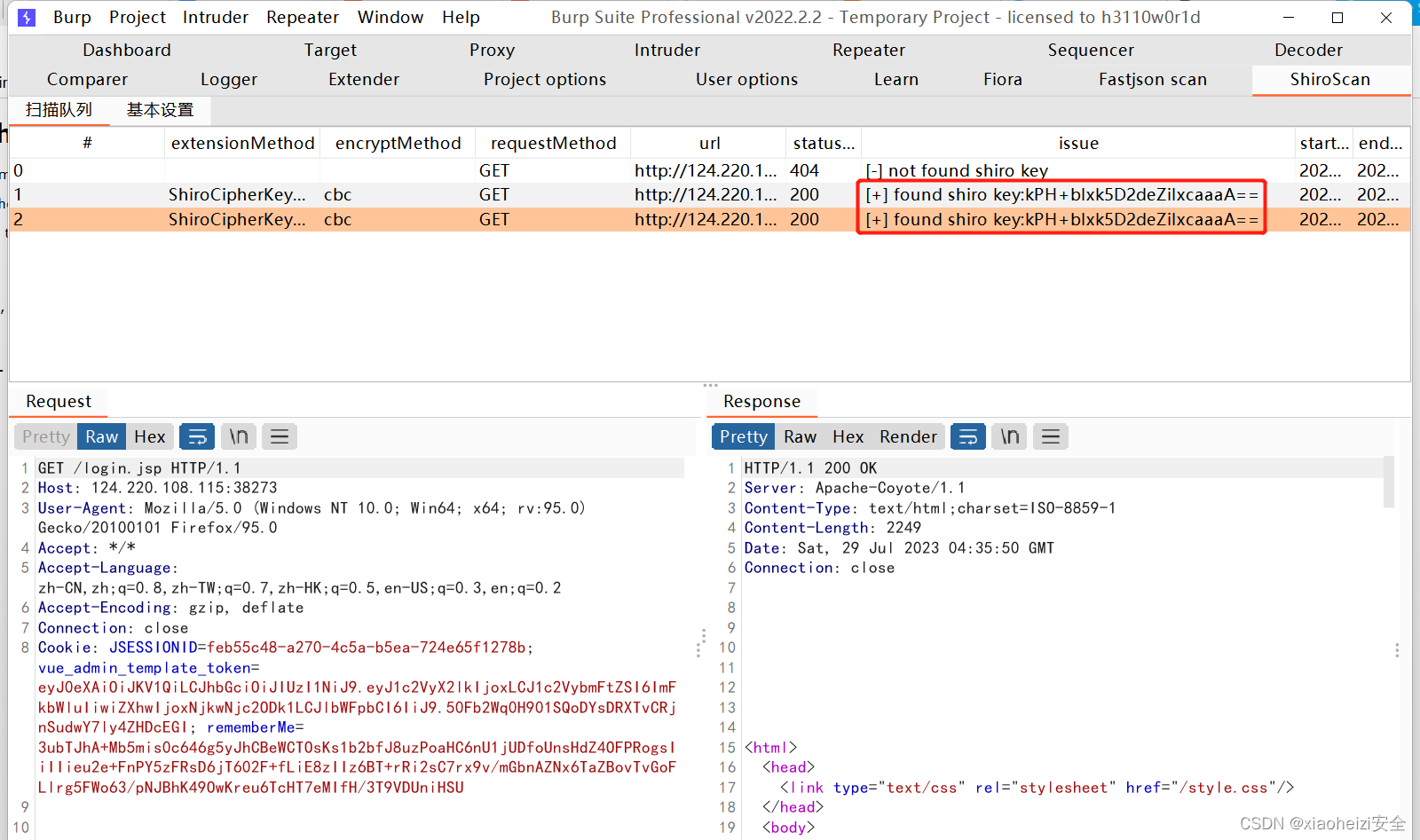
漏洞发现-BurpSuite插件-Fiora+Fastjson+Shiro
BurpSuite插件安装 插件:Fiora Fiora是LoL中的无双剑姬的名字,她善于发现对手防守弱点,实现精准打击。该项目为PoC框架nuclei提供图形界面,实现快速搜索、一键运行等功能,提升nuclei的使用体验。 该程序即可作为burp插…...
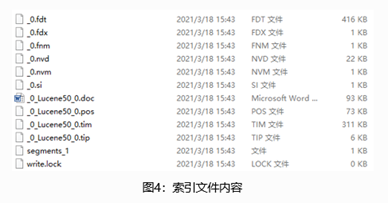
Elasticsearch-倒排索引
Elasticsearch和Lucene的关系 Lucene 是一个开源、免费、高性能、纯 Java 编写的全文检索引擎,可以算作是开源领域最好的全文检索工具包。ElasticSearch 是基于Lucene实现的一个分布式、可扩展、近实时性的高性能搜索与数据分析引擎。 Lucene索引层次结构 Lucene的…...

pagehelper与mybatis-plus冲突的解决办法
背景: springcloud项目开发新功能时因想使用mybatis-plus,原有功能只使用了mybatis,但在开发时发现某个公共模块使用了com.github.pagehelper,且很多模块都集成了该模块依赖(为了保证原有功能不发生问题,…...

解决使用Timer时出现Task already scheduled or cancelled异常的问题
在使用java.util.Timer和java.util.TimerTask执行定时任务时,如果在调用Timer的schedule或scheduleAtFixedRate方法时,报错如下: java.lang.IllegalStateException: Task already scheduled or cancelled 说明当前Timer对象已经执行结束或被取…...

P1175 后缀表达式
题意 传送门 P1175 表达式的转换 题解 编码运算符的优先级,线性复杂度将中缀表达式转换为后缀表达式。为了方便输出,可以用类似对顶栈的结构,初始时右侧栈为后缀表达式;对于每一步计算,右侧栈不断弹出数字到左侧栈&…...

【HashMap】49. 字母异位词分组
49. 字母异位词分组 解题思路 创建一个哈希容器 key是每一个字母异位词 排序之后的词 List是所有的字母异位词因为所有的字母异位词排序之后的结果都是一样的增强for循环遍历字符串数组将每一个字符串转换为字符数组因为字母异位词排序之后 都是一样的将排序之后的字符数组 转…...

golang实现多态
Go 通过接口来实现多态。在 Go 语言中,我们是隐式地实现接口。一个类型如果定义了接口所声明的全部方法,那它就实现了该接口。现在我们来看看,利用接口,Go 是如何实现多态的。 package mainimport "fmt"type Income in…...
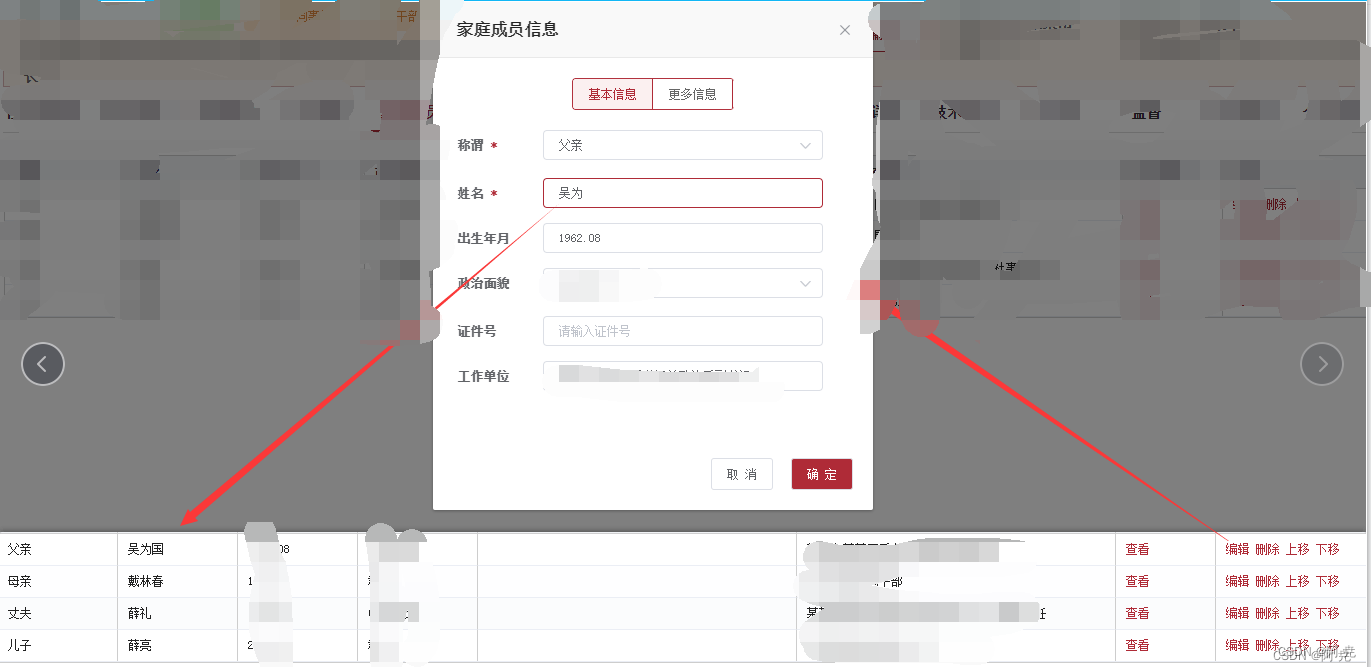
formatter的用法,深拷贝, Object.assign 方法实战。
1. :formatter的用法 :formatter 接受一个函数作为参数,这个函数有三个参数:row,column 和 cellValue。row 是当前行的数据,column 是当前列的数据,cellValue 是当前单元格的值。 <el-table-column prop"SYS…...

Windows上安装和使用git到gitoschina和github上_亲测
Windows上安装和使用git到gitoschina和github上_亲测 git介绍与在windows上安装创建SSHkey在gitoschina使用 【git介绍与在windows上安装】 Git是一款免费、开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。 相关介绍可以参考 <百度百科>…...

MATLAB算法实战应用案例精讲-【深度学习】预训练模型GPTXLNet
目录 GPT 1. 介绍 1.1 GPT的动机 2. 模型结构 3. GPT训练过程 3.1 无监督的预训练...

Spring data JPA常用命令
简介 Spring Data JPA是Spring框架的一部分,它提供了一个简化的方式来与关系型数据库进行交互。JPA代表Java持久化API,它是Java EE规范中定义的一种对象关系映射(ORM)标准。Spring Data JPA在JPA的基础上提供了更高级的抽象&…...
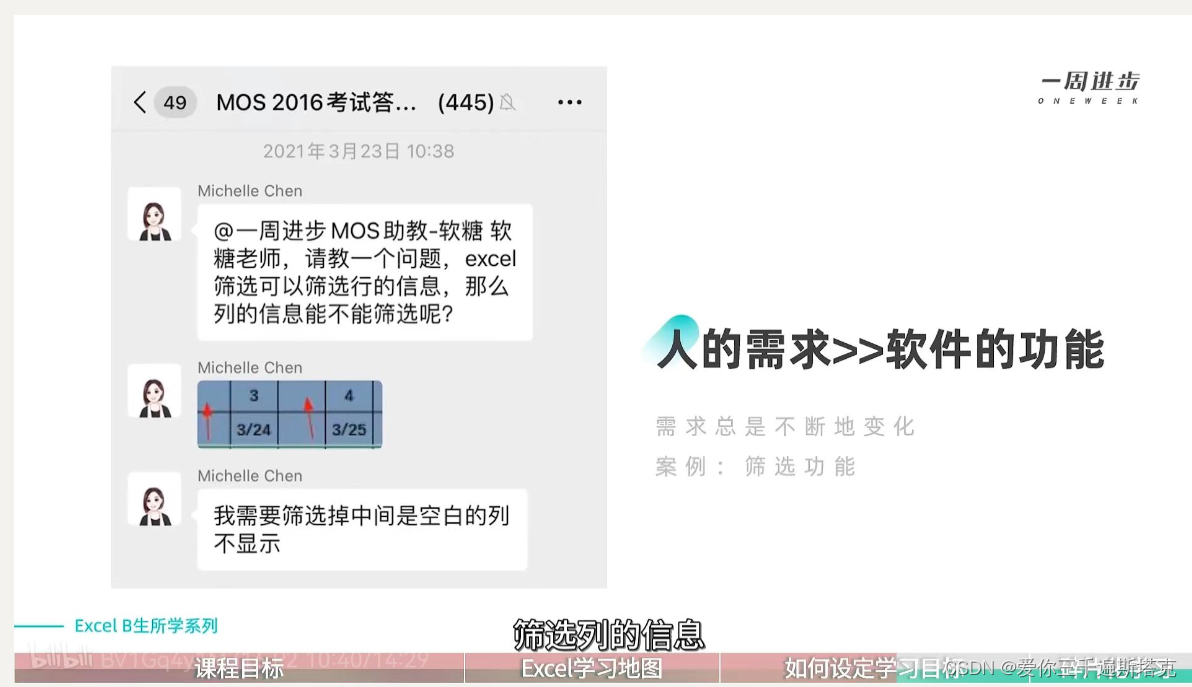
Excel的使用
1.EXCEL诞生的意义 1.1 找到想要的数据 1.2 提升输入速度 2.数据分析与可视化操作 目的是提升数据的价值和意义 3.EXCEL使用的内在意义和外在形式 4.EXCEL的价值 4.1 解读及挖掘数据价值 4.2 协作板块 4.3 展示专业度 4.4 共享文档内容 5.人的需求》》软件功能...
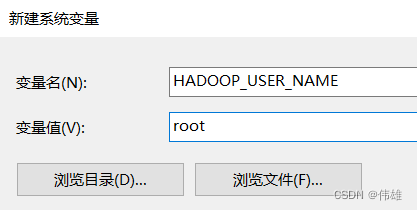
大数据课程D4——hadoop的MapReduce
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解MapReduce的作用和特点; ⚪ 掌握MapReduce的组件; ⚪ 掌握MapReduce的Shuffle; ⚪ 掌握MapReduce的小文件问题; ⚪ 掌握MapReduce的压缩机制; ⚪ 掌握MapReduce的推测执行机制…...

Visual Studio 项目属性页开发完全教程:从基础到高级
Visual Studio 项目属性页开发完全教程:从基础到高级 【免费下载链接】project-system The .NET Project System for Visual Studio 项目地址: https://gitcode.com/gh_mirrors/pr/project-system Visual Studio 项目属性页是开发者管理项目配置的核心界面&a…...

Spring Cloud AWS 实战教程:构建高可用 SQS 消息队列应用 [特殊字符]
Spring Cloud AWS 实战教程:构建高可用 SQS 消息队列应用 🚀 【免费下载链接】spring-cloud-aws The New Home for Spring Cloud AWS 项目地址: https://gitcode.com/gh_mirrors/sp/spring-cloud-aws Spring Cloud AWS 是一个强大的开源框架&…...

Taurus多执行器对比实战:JMeter/Gatling/Locust统一压测方案
1. 为什么选Taurus做多执行器对比——不是为了炫技,而是为了少踩坑在性能测试领域,我见过太多团队卡在“选型”这一步:刚招来一个会写JMeter脚本的工程师,项目突然要压测WebSocket接口,发现JMeter原生支持弱、插件维护…...
)
别再乱用npm install了!手把手教你用npx only-allow为项目指定包管理器(支持pnpm/yarn/npm)
用only-allow统一团队包管理器:从配置到CI的全流程指南 你是否曾经在拉取一个新项目后,面对npm install、yarn还是pnpm i的抉择感到困惑?或者更糟的是,团队成员混用不同包管理器导致node_modules结构不一致,引发各种诡…...

【UniApp小程序开发】解决无法使用Vue自定义指令的完美替代方案:权限组件封装
在 UniApp 开发中,你是否遇到过这样的困惑:明明在 Vue Web 项目中用得顺手的 v-permission 自定义指令,一到小程序端就完全失效?本文将深入剖析其原因,并提供一套可直接复用的组件化解决方案,让你在小程序中…...

13456
12356...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...
:这份内部测试SOP已被3家头部科技公司紧急采购)
DeepSeek-R1补全能力封测倒计时(仅剩72小时开放API灰度权限):这份内部测试SOP已被3家头部科技公司紧急采购
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1代码补全能力封测全景概览 DeepSeek-R1 是深度求索(DeepSeek)推出的高性能开源推理模型,在代码补全场景中展现出显著的上下文理解力与多语言泛化能力。本…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...

Owl-Alpha 新手快速上手指南
在处理大规模数据或构建高性能应用时,我们常常会遇到一个棘手的问题:如何在不阻塞主线程的情况下,高效地执行耗时任务?无论是处理图像、解析大型文件,还是进行复杂的数学运算,传统的单线程模式往往会让界面…...