深度学习:Pytorch最全面学习率调整策略lr_scheduler
深度学习:Pytorch最全面学习率调整策略lr_scheduler
- lr_scheduler.LambdaLR
- lr_scheduler.MultiplicativeLR
- lr_scheduler.StepLR
- lr_scheduler.MultiStepLR
- lr_scheduler.ConstantLR
- lr_scheduler.LinearLR
- lr_scheduler.ExponentialLR
- lr_scheduler.PolynomialLR
- lr_scheduler.CosineAnnealingLR
- lr_scheduler.SequentialLR
- lr_scheduler.ChainedScheduler
- lr_scheduler.CyclicLR
- lr_scheduler.OneCycleLR
- lr_scheduler.CosineAnnealingWarmRestarts
- lr_scheduler.ReduceLROnPlateau
此篇博客最全面地展现了pytorch各种学习率调整策略的参数、用法以及对应的示例曲线,学习率调整的策略主要分为四大类:指定方法调整(MultiStepLR、LinearLR、CosineAnnealingLR、OneCycleLR等)、组合调整(SequentialLR和ChainedScheduler)、自定义调整(LambdaLR和MultiplicativeLR)、自适应调整(ReduceLROnPlateau)。
所有示例的参数配置:初始的学习率均为1,epoch从0开始,直到第200次结束。
lr_scheduler.LambdaLR
LambdaLR 提供了更加灵活的方式让使用者自定义衰减函数,完成特定的学习率曲线。LambdaLR通过将lambda函数的乘法因子应用到初始LR来调整学习速率。
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- lr_lambda ( function or list ) – 一个计算乘法因子的函数,或此类函数的列表
- last_epoch (int) – 最后一个epoch的索引,默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:
lambda1 = lambda epoch: np.cos(epoch/max_epoch*np.pi/2)
scheduler = LambdaLR(optimizer, lr_lambda=[lambda1])

lr_scheduler.MultiplicativeLR
MultiplicativeLR同样可以自定义学习率的变化,与LambdaLR不同的是MultiplicativeLR通过将lambda函数的乘法因子应用到前一个epoch的LR来调整学习速率。
torch.optim.lr_scheduler.MultiplicativeLR(optimizer, lr_lambda, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
lr_lambda (function or list) – A function which computes a multiplicative factor given an integer parameter epoch, or a list of such functions, one for each group in optimizer.param_groups. - last_epoch (int) – 最后一个epoch的索引,默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:
lmbda = lambda epoch: 0.95
scheduler = MultiplicativeLR(optimizer, lr_lambda=lmbda)

lr_scheduler.StepLR
每到达一定周期(step_size),学习率乘以一个系数 gamma。
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- step_size (int) – 学习率衰减的周期
- gamma (float) – 学习率衰减的乘法因子,默认值:0.1
- last_epoch (int) – 最后一个epoch的索引,默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:scheduler = StepLR(optimizer, step_size=30, gamma=0.5)

lr_scheduler.MultiStepLR
StepLR 的 Step 是固定的,MultiStepLR 则可以设置每一个 step 的大小。
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=- 1, verbose=False)
参数:
optimizer (Optimizer) – 优化器
milestones (list) – epoch索引列表,必须增加
gamma (float) – 学习率衰减的乘法因子,默认值:0.1
last_epoch (int) – 最后一个epoch的索引,默认值:-1
verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:MultiStepLR(optimizer, milestones=[30,80,150], gamma=0.5)

lr_scheduler.ConstantLR
在total_iters轮内将optimizer里面指定的学习率乘以factor,total_iters轮外恢复原学习率。
torch.optim.lr_scheduler.ConstantLR(optimizer, factor=0.3333333333333333, total_iters=5, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- factor (float) – 学习率衰减的常数因子,默认值:1./3.
- total_iters (int) – 学习率衰减直到设定的epoch值,默认值:5.
- last_epoch (int) – 最后一个epoch的索引,默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:scheduler = ConstantLR(optimizer, factor=0.5, total_iters=50)

lr_scheduler.LinearLR
线性改变每个参数组的学习率,直到 epoch 达到预定义的值(total_iters)。
torch.optim.lr_scheduler.LinearLR(optimizer, start_factor=0.3333333333333333, end_factor=1.0, total_iters=5, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- start_factor (float) – 在开始时,学习率的值。默认值:1./3
- end_factor (float) – 在结束时,学习率的值。默认值:1.0
- total_iters (int) – 学习率衰减率变为1时的epoch值,默认值:5.
- last_epoch (int) – 最后一个epoch的索引,默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例: scheduler = LinearLR(optimizer, start_factor=1, end_factor=1/2, total_iters=200)

lr_scheduler.ExponentialLR
每个时期将每个参数组的学习率衰减 gamma。
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- gamma (float) – 学习率衰减的乘法因子
- last_epoch (int) – 最后一个epoch的索引,默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:scheduler = ExponentialLR(optimizer, gamma=0.9)

lr_scheduler.PolynomialLR
多项式函数衰减学习率。
torch.optim.lr_scheduler.PolynomialLR(optimizer, total_iters=5, power=1.0, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- total_iters (int) – 衰减学习率的步数,默认值:5
- power (int) – The power of the polynomial. Default: 1.0.
- last_epoch (int) – 多项式的幂,默认值:1.0
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:
scheduler = PolynomialLR(optimizer, total_iters=100, power=2)

lr_scheduler.CosineAnnealingLR
余弦学习率衰减方法相对于线性学习率衰减方法来说,可以更快地达到最佳效果,更好地保持模型的稳定性,同时也可以改善模型的泛化性能。余弦学习率衰减前期衰减慢,中期衰减快,后期衰减慢,和模型的学习有相似之处。
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- T_max (int) – 最大迭代次数
- eta_min (float) – 最小的学习率值. Default: 0.
- last_epoch (int) – 最后一个epoch的索引,默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:scheduler = CosineAnnealingLR(optimizer, T_max=200, eta_min=0.5)

lr_scheduler.SequentialLR
可以将多种衰减方式以串联的方式进行组合。
torch.optim.lr_scheduler.SequentialLR(optimizer, schedulers, milestones, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- schedulers (list) – 学习率调整策略(scheduler)的列表
- milestones (list) – 策略变化的epoch转折点,整数列表
- last_epoch (int) – 最后一个epoch的索引,默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:
scheduler1 = LinearLR(optimizer, start_factor=1, end_factor=1/2, total_iters=100)
scheduler2 = CosineAnnealingLR(optimizer, T_max=100, eta_min=0.5)
schedulers = [scheduler1, scheduler2]
milestones = [100]
scheduler = SequentialLR(optimizer, schedulers, milestones)

lr_scheduler.ChainedScheduler
ChainedScheduler和SequentialLR类似,也是按照顺序调用多个串联起来的学习率调整策略,不同的是ChainedScheduler里面的学习率变化是连续的。
torch.optim.lr_scheduler.ChainedScheduler(schedulers)
参数:
schedulers (list) – 学习率调整策略(scheduler)的列表
示例:
scheduler1 = ConstantLR(optimizer, factor=0.1, total_iters=10)
scheduler2 = ExponentialLR(optimizer, gamma=0.9)
scheduler = ChainedScheduler([scheduler1,scheduler2])

lr_scheduler.CyclicLR
CyclicLR循环地调整学习率。
torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr, max_lr, step_size_up=2000, step_size_down=None, mode='triangular', gamma=1.0, scale_fn=None, scale_mode='cycle', cycle_momentum=True, base_momentum=0.8, max_momentum=0.9, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- base_lr (float or list) – 初始学习率,它是每个循环中学习率的下限值
- max_lr (float or list) – 每个循环中学习率的上限
- step_size_up (int) – 递增周期中的训练迭代次数,默认值:2000
- step_size_down (int) – 递减少周期中的训练迭代次数,如果step_size_down为None,则设置为step_size_up。默认值:无
- mode (str) – {triangular, triangular2, exp_range}其中之一,学习率递增递减变化策略,如果scale_fn不是None,则忽略此参数。默认值:“triangular”
- gamma (float) – ‘exp_range’ 缩放函数中的常量,默认值:1.0
- scale_fn (function) – 由 lambda 函数定义的自定义衰减策略,其中 0 <= scale_fn(x) <= 1 对于所有 x >= 0。如果指定,则忽略 ‘mode’。默认值:无
- scale_mode (str) – {‘cycle’, ‘iterations’}. 定义是否根据cycle或iterations(自循环开始以来的训练迭代)评估scale_fn。默认值:‘cycle’
- cycle_momentum (bool) – 如果True,动量在 ‘base_momentum’ 和 ‘max_momentum’ 之间以与学习率相反的方向循环。默认值:True
- base_momentum (float or list) – 每次循环中的动量下限,请注意,动量的循环与学习率成反比;在一个周期的峰值,动量为“base_momentum”,学习率为“max_lr”。默认值:0.8
- max_momentum (float or list) – 每次循环中的动量上限,请注意,动量的循环与学习率成反比;在一个周期开始时,动量为“max_momentum”,学习率为“base_lr”,默认值:0.9
- last_epoch (int) – 最后一个epoch的索引,该参数在恢复训练时使用,由于应在每个batch之后而不是每个epoch之后调用step() ,因此该数字表示计算的batch总数,而不是计算的epoch总数。当last_epoch=-1时,调度从头开始。默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例
scheduler = CyclicLR(optimizer, base_lr=0.1, max_lr=1, step_size_up=50)

lr_scheduler.OneCycleLR
OneCycleLR是CyclicLR的一周期版本。
torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, total_steps=None, epochs=None, steps_per_epoch=None, pct_start=0.3, anneal_strategy='cos', cycle_momentum=True, base_momentum=0.85, max_momentum=0.95, div_factor=25.0, final_div_factor=10000.0, three_phase=False, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- max_lr (float or list) – 最大学习率
- total_steps (int) – 总的迭代次数,请注意,如果此处未提供值,则必须通过提供 epochs 和 steps_per_epoch 的值来推断,所以必须为total_steps 提供一个值,或者为epochs 和steps_per_epoch 提供一个值。,默认值:无
- epochs (int) – 训练的 epoch 数,默认值:无
- steps_per_epoch (int) – 每个epoch训练的步数,默认值:无
- pct_start (float) – 学习率上升部分所占比例,默认值:0.3
- anneal_strategy (str) – {‘cos’, ‘linear’} 指定退火策略:“cos”表示余弦退火,“linear”表示线性退火。默认值:‘cos’
- cycle_momentum (bool) – 如果True,动量在 ‘base_momentum’ 和 ‘max_momentum’ 之间以与学习率相反的方向循环。默认值:True
- base_momentum (float or list) – 每次循环中的动量下限,请注意,动量的循环与学习率成反比;在一个周期的峰值,动量为“base_momentum”,学习率为“max_lr”。默认值:0.85
- max_momentum (float or list) – 每次循环中的动量上限,请注意,动量的循环与学习率成反比;在一个周期开始时,动量为“max_momentum”,学习率为“base_lr”,默认值:0.95
- div_factor (float) – 通过initial_lr = max_lr/div_factor 确定初始学习率,默认值:25
- final_div_factor (float) – 通过 min_lr = initial_lr/final_div_factor 确定最小学习率 默认值:1e4
- three_phase (bool) – 如果True,则使用计划的第三阶段根据 ‘final_div_factor’ 消除学习率,而不是修改第二阶段(前两个阶段将关于 ‘pct_start’ 指示的步骤对称)。默认值:False
- last_epoch (int) – 最后一个epoch的索引,该参数在恢复训练时使用,由于应在每个batch之后而不是每个epoch之后调用step() ,因此该数字表示计算的batch总数,而不是计算的epoch总数。当last_epoch=-1时,调度从头开始。默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:
scheduler = OneCycleLR(optimizer, max_lr=1, steps_per_epoch=10, epochs=20)

lr_scheduler.CosineAnnealingWarmRestarts
CosineAnnealingWarmRestartsLR类似于CosineAnnealingLR,但它可以循环从初始LR重新开始LR的衰减。
torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0, T_mult=1, eta_min=0, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- T_0 (int) – 重新开始衰减的epoch次数
- T_mult (int, optional) – T_0的递增变化值,默认值:1
- eta_min (float, optional) – 学习率下限,默认值:0
- last_epoch (int) – 最后一个epoch的索引,默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:
scheduler = CosineAnnealingWarmRestarts(optimizer, T_0=30, T_mult=2)
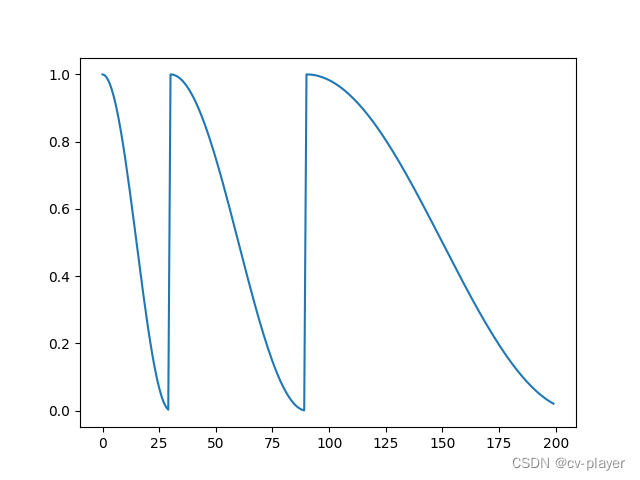
lr_scheduler.ReduceLROnPlateau
当指度量指标(例如:loss、precision等)停止改进时,ReduceLROnPlateau会降低学习率。其功能是自适应调节学习率,它在step的时候会观察验证集上的loss或者准确率情况,loss当然是越低越好,准确率则是越高越好,所以使用loss作为step的参数时,mode为min,使用准确率作为参数时,mode为max。
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- mode (str) – min、max之一。在min模式下,当监测的数量停止减少时,lr将减少;在max模式下,当监控的数量停止增加时,lr将减少。默认值:“min”
- factor (float) – 每次学习率下降的比例, new_lr = lr * factor. 默认值:0.1
- patience (int) – patience是能够容忍的次数,当patience次后,网络性能仍未提升,则会降低学习率,默认值:10
- threshold (float) – 测量最佳值的阈值,一般只关注相对大的性能提升,默认值:1e-4
- threshold_mode (str) – 选择判断指标是否达最优的模式,有两种模式, rel 和 abs。
当 threshold_mode == rel,并且 mode == max 时, dynamic_threshold = best * ( 1 +threshold );
当 threshold_mode == rel,并且 mode == min 时, dynamic_threshold = best * ( 1 -threshold );
当 threshold_mode == abs,并且 mode== max 时, dynamic_threshold = best + threshold ;
当 threshold_mode == rel,并且 mode == max 时, dynamic_threshold = best - threshold; - cooldown (int) – 冷却时间,当调整学习率之后,让学习率调整策略保持不变,让模型再训练一定epoch后再重启监测模式。默认值:0
- min_lr (float or list) – 最小学习率,默认值:0
- eps (float) – lr 的最小衰减。如果新旧lr之差小于eps,则忽略更新,默认值:1e-8
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
相关文章:
深度学习:Pytorch最全面学习率调整策略lr_scheduler
深度学习:Pytorch最全面学习率调整策略lr_scheduler lr_scheduler.LambdaLRlr_scheduler.MultiplicativeLRlr_scheduler.StepLRlr_scheduler.MultiStepLRlr_scheduler.ConstantLRlr_scheduler.LinearLRlr_scheduler.ExponentialLRlr_scheduler.PolynomialLRlr_sched…...
【uniapp】更改富文本编辑器图片大小
代码块 //<view v-html"productDetails"></view><rich-text :nodes"productDetails"></rich-text>// 假设htmlContent字段是后台返回的富文本字段var htmlContent res.result.productDetailsconst regex new RegExp(<img, gi…...
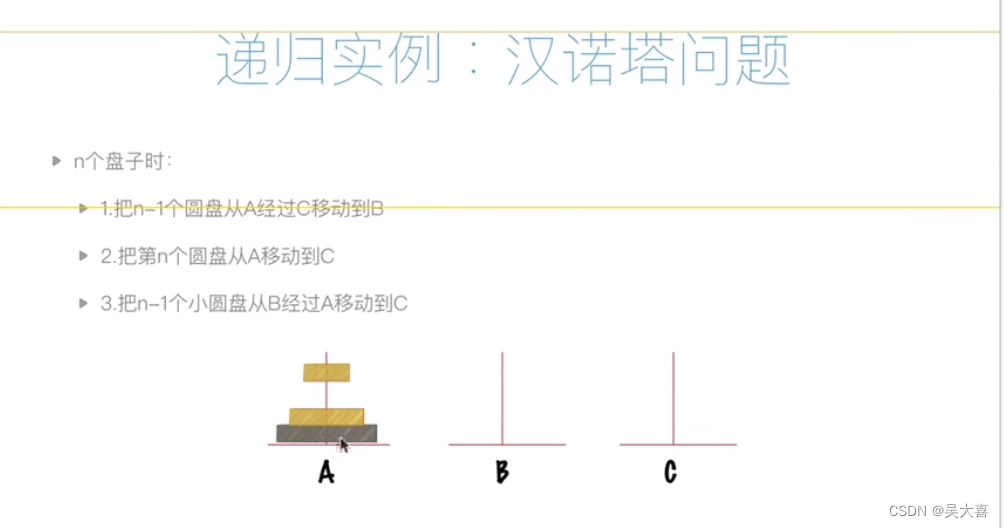
数据结构和算法一(空间复杂度、时间复杂度等算法入门)
时间复杂度: 空间复杂度: 时间比空间重要 递归: 递归特征: 递归案例: 汉诺塔问题: def hanoi(n,A,B,C):if n>0:hanoi(n-1,A,C,B)print("moving from %s to %s"%(A,C))hanoi(n-1,B,A,C)hanoi…...
Pytorch深度学习-----神经网络的基本骨架-nn.Module的使用
系列文章目录 PyTorch深度学习——Anaconda和PyTorch安装 Pytorch深度学习-----数据模块Dataset类 Pytorch深度学习------TensorBoard的使用 Pytorch深度学习------Torchvision中Transforms的使用(ToTensor,Normalize,Resize ,Co…...

QT开发快捷键
QT开发快捷键 alt enter // 自动创建类的定义 Ctrl / 注释当前行 或者选中的区域 Ctrl R 运行程序 Ctrl B Build 项目 CtrlShiftF 查找内容 F5 开始调试 ShiftF5 停止调试 F9 设置和取消断点 F10 单步前进 F11 单步进入函数 Shift F11 单步跳出函数 F1 // 查看帮助&#…...
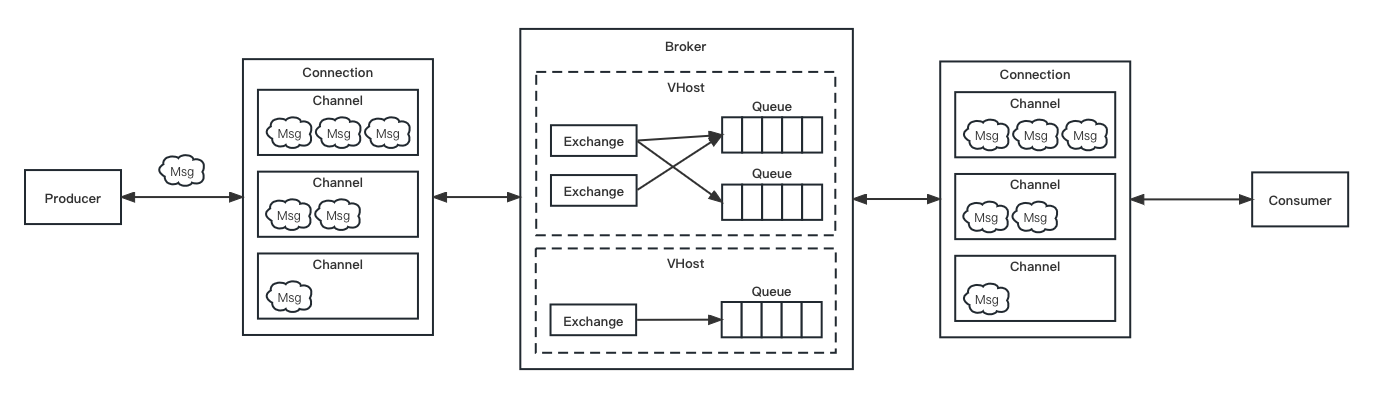
RabbitMQ 教程 | RabbitMQ 入门
👨🏻💻 热爱摄影的程序员 👨🏻🎨 喜欢编码的设计师 🧕🏻 擅长设计的剪辑师 🧑🏻🏫 一位高冷无情的编码爱好者 大家好,我是 DevO…...
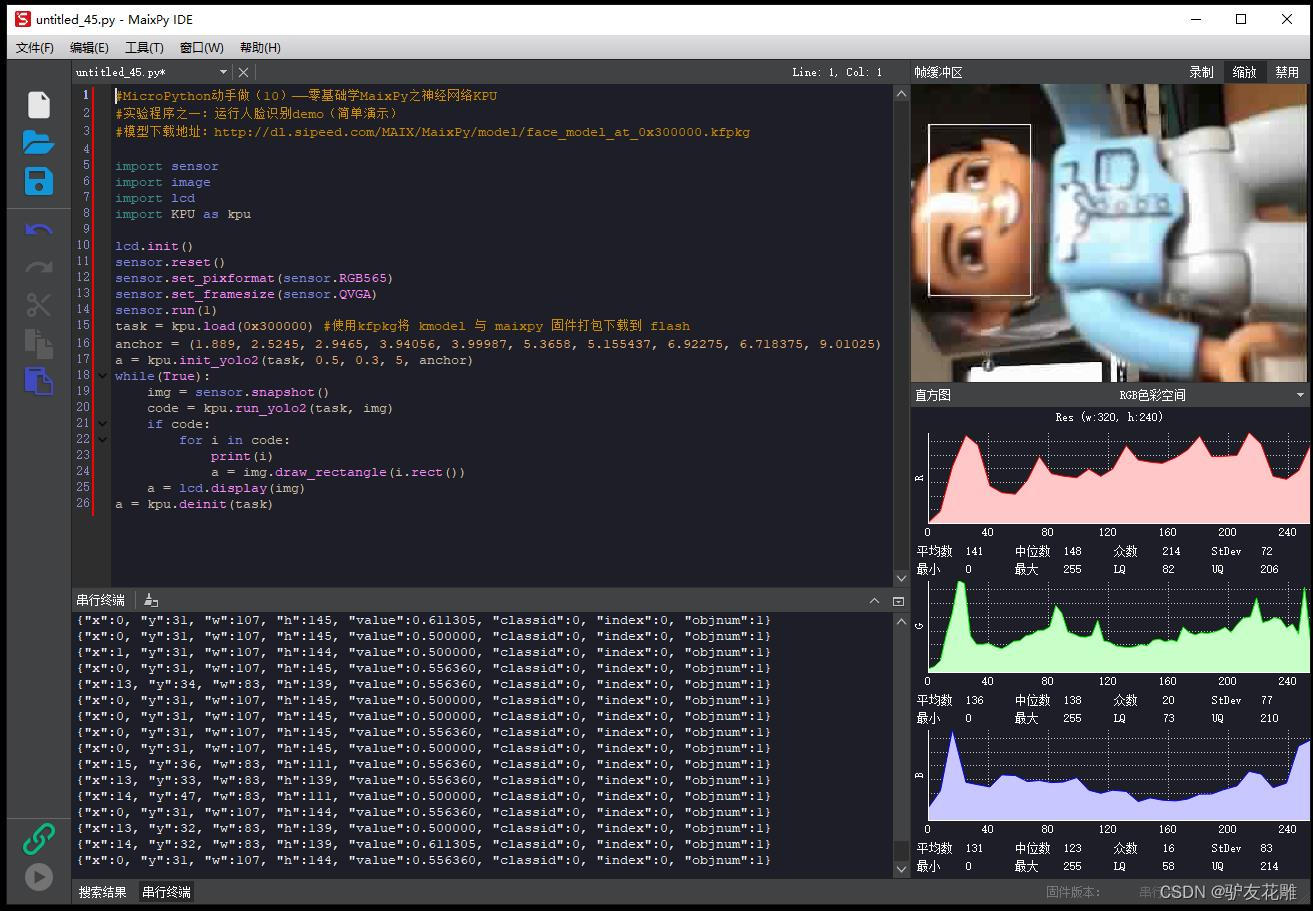
【雕爷学编程】MicroPython动手做(10)——零基础学MaixPy之神经网络KPU2
KPU的基础架构 让我们回顾下经典神经网络的基础运算操作: 卷积(Convolution):1x1卷积,3x3卷积,5x5及更高的卷积 批归一化(Batch Normalization) 激活(Activate) 池化&…...
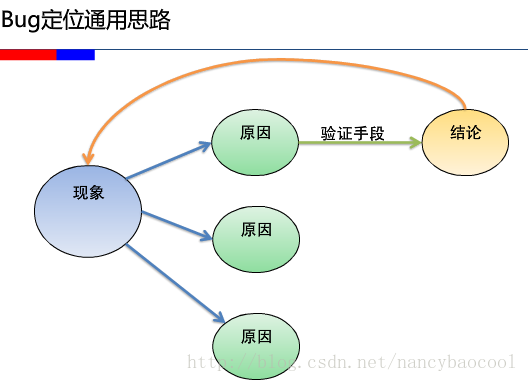
BUG分析以及BUG定位
一般来说bug大多数存在于3个模块: 1、前台界面,包括界面的显示,兼容性,数据提交的判断,页面的跳转等等,这些bug基本都是一眼可见的,不太需要定位,当然也不排除一些特殊情况…...
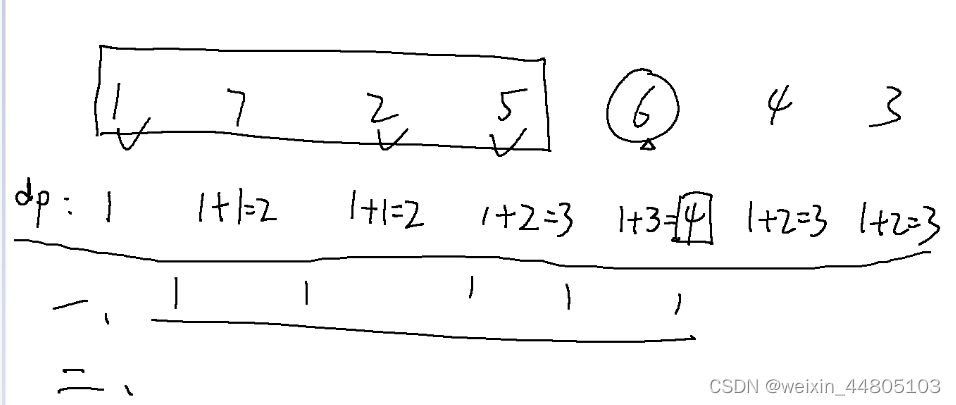
Day46 算法记录| 动态规划 13(子序列)
这里写目录标题 300.最长递增子序列 674. 最长连续递增序列718. 最长重复子数组 300.最长递增子序列 视频解析: 第一层for循环遍历每一个元素, ------- 第二层for循环找到当前元素前面有几个小于该值的元素 结尾需要统计最多的个数 class Solution {pu…...
)
结构型-桥接模式(Bridge Pattern)
概述 桥接模式(Bridge Pattern)是一种结构型设计模式,将抽象部分和实现部分分离,使它们可以独立地变化。桥接模式通过将继承关系转化为关联关系,将抽象部分和实现部分分离开来,从而使它们可以独立地变化。…...
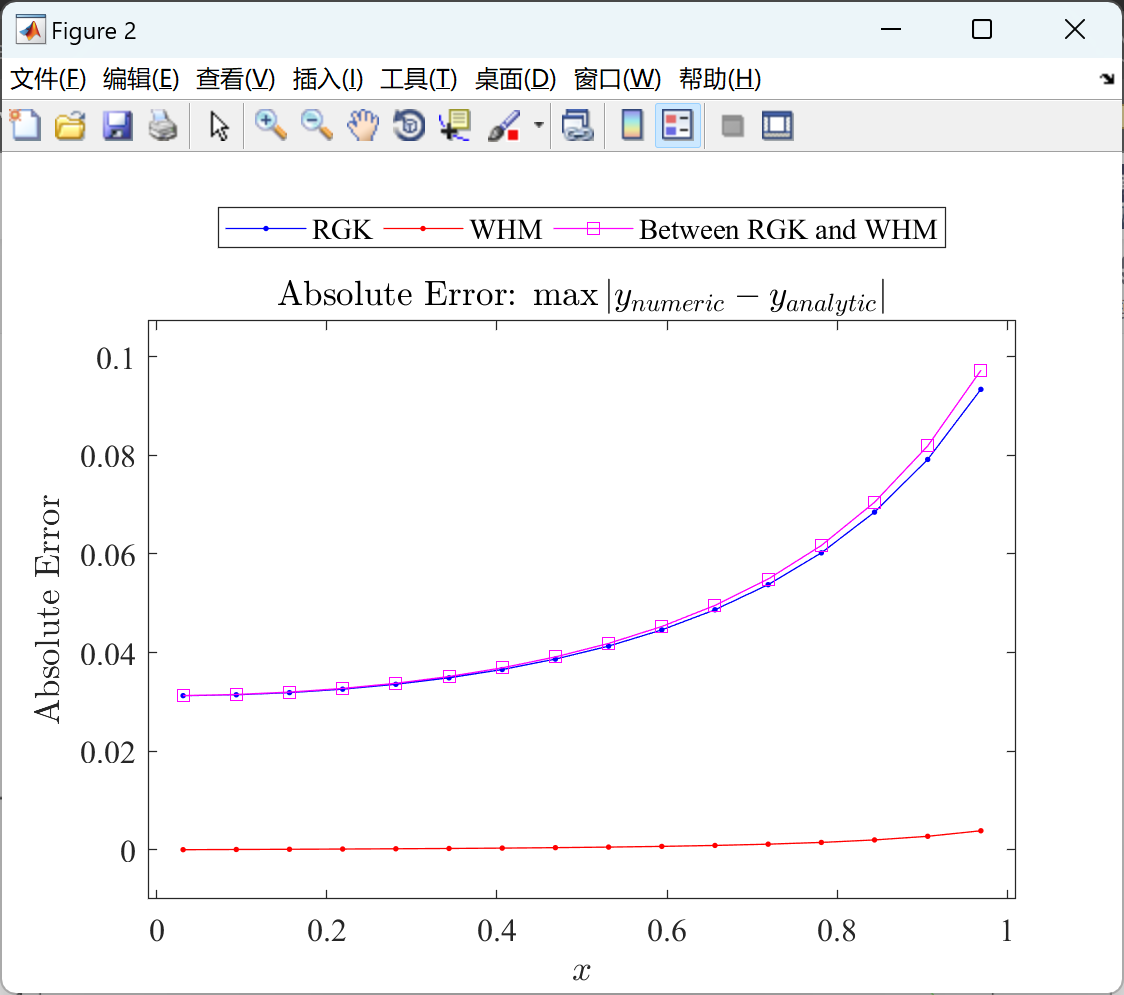
基于小波哈尔法(WHM)的一维非线性IVP测试问题的求解(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 🌈4 Matlab代码实现 💥1 概述 小波哈尔法(WHM)是一种求解一维非线性初值问题(IVP)的数值方法。它基于小波分析的思想…...
如何读取本地配置文件)
前端(Electron Nodejs)如何读取本地配置文件
使用electron封装了前端界面之后,最终打包为一个客户端(exe)。但是,最近项目组内做CS(c开发)的,想把所有的配置都放进安装目录的配置文件中(比如config.json)。这做法&am…...

没有 telnet 不能测试端口?容器化部署最佳的端口测试方式
写在前面 生产中遇到,整理笔记在容器中没有 telnet ,如何测试远程端口理解不足小伙伴帮忙指正 他的一生告诉我们,不能自爱就不能爱人,憎恨自己也必憎恨他人,最后也会像可恶的自私一样,使人变得极度孤独和悲…...
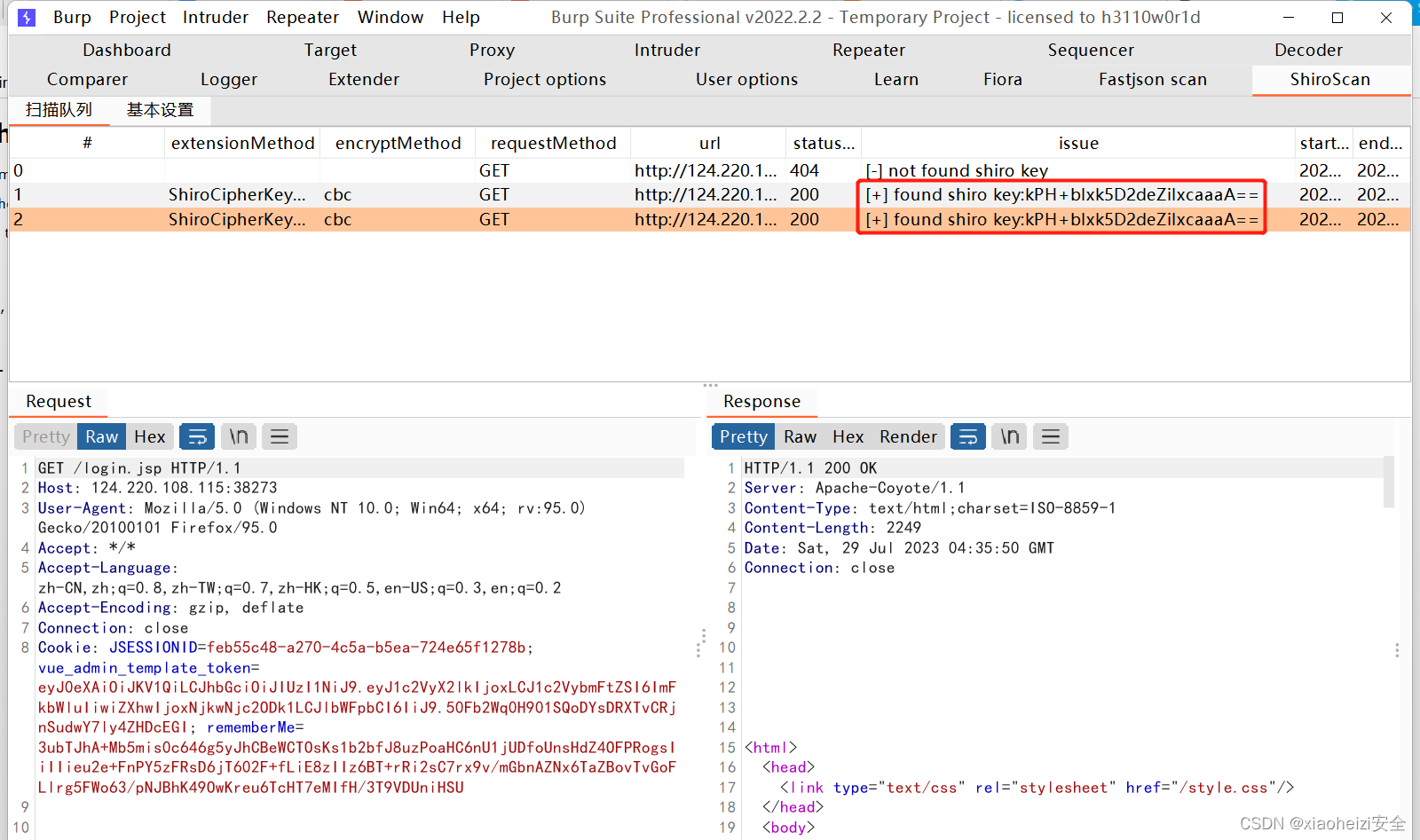
漏洞发现-BurpSuite插件-Fiora+Fastjson+Shiro
BurpSuite插件安装 插件:Fiora Fiora是LoL中的无双剑姬的名字,她善于发现对手防守弱点,实现精准打击。该项目为PoC框架nuclei提供图形界面,实现快速搜索、一键运行等功能,提升nuclei的使用体验。 该程序即可作为burp插…...
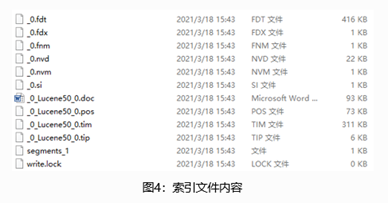
Elasticsearch-倒排索引
Elasticsearch和Lucene的关系 Lucene 是一个开源、免费、高性能、纯 Java 编写的全文检索引擎,可以算作是开源领域最好的全文检索工具包。ElasticSearch 是基于Lucene实现的一个分布式、可扩展、近实时性的高性能搜索与数据分析引擎。 Lucene索引层次结构 Lucene的…...

pagehelper与mybatis-plus冲突的解决办法
背景: springcloud项目开发新功能时因想使用mybatis-plus,原有功能只使用了mybatis,但在开发时发现某个公共模块使用了com.github.pagehelper,且很多模块都集成了该模块依赖(为了保证原有功能不发生问题,…...

解决使用Timer时出现Task already scheduled or cancelled异常的问题
在使用java.util.Timer和java.util.TimerTask执行定时任务时,如果在调用Timer的schedule或scheduleAtFixedRate方法时,报错如下: java.lang.IllegalStateException: Task already scheduled or cancelled 说明当前Timer对象已经执行结束或被取…...

P1175 后缀表达式
题意 传送门 P1175 表达式的转换 题解 编码运算符的优先级,线性复杂度将中缀表达式转换为后缀表达式。为了方便输出,可以用类似对顶栈的结构,初始时右侧栈为后缀表达式;对于每一步计算,右侧栈不断弹出数字到左侧栈&…...

【HashMap】49. 字母异位词分组
49. 字母异位词分组 解题思路 创建一个哈希容器 key是每一个字母异位词 排序之后的词 List是所有的字母异位词因为所有的字母异位词排序之后的结果都是一样的增强for循环遍历字符串数组将每一个字符串转换为字符数组因为字母异位词排序之后 都是一样的将排序之后的字符数组 转…...

golang实现多态
Go 通过接口来实现多态。在 Go 语言中,我们是隐式地实现接口。一个类型如果定义了接口所声明的全部方法,那它就实现了该接口。现在我们来看看,利用接口,Go 是如何实现多态的。 package mainimport "fmt"type Income in…...

除了ulimit -c unlimited:深入理解Linux core dump机制与高级配置指南
深入Linux核心转储:从基础配置到生产环境实战指南当服务器上的关键应用突然崩溃时,系统管理员最需要的就是一份完整的"事故现场记录"。Linux的core dump机制正是为此而生,它能保存程序崩溃时的内存状态、寄存器值和调用堆栈&#x…...
)
保姆级教程:在CentOS 7上用达梦8搭建DCA练习环境(附ulimit、VNC、ODBC全配置)
达梦8 DCA认证实战:CentOS 7环境搭建与调优全指南 在国产数据库技术快速发展的今天,达梦数据库作为核心产品之一,其DCA认证已成为众多从业者提升竞争力的重要选择。与理论为主的认证不同,DCA更注重实际操作能力,而一个…...
)
别再乱用npm install了!手把手教你用npx only-allow为项目指定包管理器(支持pnpm/yarn/npm)
用only-allow统一团队包管理器:从配置到CI的全流程指南 你是否曾经在拉取一个新项目后,面对npm install、yarn还是pnpm i的抉择感到困惑?或者更糟的是,团队成员混用不同包管理器导致node_modules结构不一致,引发各种诡…...

关于psthon问题
我想问问各位 我python可以查到 但是我的bit文件查不到python怎么回事...

【深度解析】AI Coding 模型竞速:从 Claude Mythos 安全编码到 GPT-5.6 传闻,如何落地代码审查智能体
摘要 AI 编码模型正在从“代码补全”进入“复杂代码库理解、漏洞发现与自动修复”阶段。本文结合 Claude Mythos、Claude Opus 4.8 与 GPT-5.6 相关信息,解析新一代 Coding Agent 的技术趋势,并给出基于大模型 API 的代码安全审查实战方案。背景介绍&…...

终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理
终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension 想要在浏览网页、处理文档的同时继续观看视频内容吗…...

Gazebo Sim多旋翼控制:四轴飞行器动力学建模与PID调参
Gazebo Sim多旋翼控制:四轴飞行器动力学建模与PID调参 【免费下载链接】gz-sim Open source robotics simulator. The latest version of Gazebo. 项目地址: https://gitcode.com/gh_mirrors/gz/gz-sim Gazebo Sim是一款功能强大的开源机器人模拟器ÿ…...

告别DLL缺失烦恼!Visual C++运行库合集一键搞定Windows应用依赖问题
告别DLL缺失烦恼!Visual C运行库合集一键搞定Windows应用依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在打开某个软件或游戏时…...
,锁定雾浓度≤0.38的7个关键阈值参数)
【云雾效果商业级交付标准】:基于Adobe Sensei图像雾度分析报告(N=1,247张MJ生成图),锁定雾浓度≤0.38的7个关键阈值参数
更多请点击: https://intelliparadigm.com 第一章:云雾效果商业级交付标准的定义与行业意义 云雾效果在现代数字体验中已超越视觉装饰范畴,成为空间感知建模、沉浸式交互与品牌情绪传达的核心媒介。商业级交付标准并非仅关注“是否可见雾气”…...

3步快速部署:智能茅台抢购平台的终极自动化解决方案
3步快速部署:智能茅台抢购平台的终极自动化解决方案 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gi…...