如何复现o1模型,打造医疗 o1?
如何复现o1模型,打造医疗 o1?
- o1 树搜索
- 一、起点:预训练规模触顶与「推理阶段(Test-Time)扩展」的动机
- 二、Test-Time 扩展的核心思路与常见手段
- 1. Proposer & Verifier 统一视角
- 方法1:纯 Inference Scaling
- 方法2:推理能力增强
- 2. 只看最终答案:Best-of-N、Best-of-N Weighted
- 3. 关注中间过程:引入过程奖励模型 (PRM)
- 4. 自改进(Self-Improve / Revision)的思路
- 三、如何提升多步推理?
- 四、进一步:MCTS 与 AlphaZero-Like 搜索
- 五、PRM 在推理与训练中的多种用途
- 六、左右互博 Self-Play 与 Self-Improve
- 七、OpenR 框架
- 八、整体结论与思考
- 4 种解法拆解
- 子解法 A:纯增加推理计算量(“多样采样 + 验证”)
- 子解法 B:过程奖励模型(PRM)与搜索式推理(Beam Search / Lookahead / 等)
- 子解法 C:多轮 Revision / Self-Improve(自修正)
- 子解法 D:MCTS / AlphaZero-like 思路(结合自对弈 / RL 训练)
- o1 医疗:树搜索、医疗数据蒸馏
- DeepSeek-R1 医疗数据蒸馏
- 各种 o1 方法对比
- PRM:医疗 step-by-step 数据标注怎么做?
论文汇总:https://github.com/hijkzzz/Awesome-LLM-Strawberry?tab=readme-ov-file
o1 树搜索
├── 1 总览【背景与动机】
│ ├── 1.1 预训练Scaling Law遇到瓶颈【描述问题】
│ │ ├── 语言模型尺寸增大收益渐减【模型规模扩展的困难】
│ │ └── 预训练算力投入与性能不再线性增长【性能触顶】
│ └── 1.2 转向推理阶段的潜能挖掘【提出新方向】
│ └── o1推理/推理优化方法出现【多种推理强化方案】├── 2 Scaling LLM Test Time【在推理阶段扩展计算以提升性能】
│ ├── 2.1 概述【核心思路】
│ │ ├── 通过增加推理时间或算力来提升回答质量【Test-Time Scaling】
│ │ └── 对比单纯提升模型参数量【对照关系】
│ ├── 2.2 纯推理扩展方案 (Method a)【无需额外训练】
│ │ ├── Best-of-N / Rejection Sampling【多次采样后筛选】
│ │ ├── Self-Consistency (SC)【统计最常见答案】
│ │ └── 计算量与收益的取舍【并行采样可行性】
│ ├── 2.3 结合部分训练的推理扩展 (Method b)【非RL】
│ │ ├── Proposer & Verifier框架【提供过程与结果判别】
│ │ ├── Process Reward Model (PRM)与Outcome Reward Model (ORM)对比【过程奖励与结果奖励】
│ │ └── 多种搜索策略:Beam Search / Lookahead Search【基于PRM评分】
│ ├── 2.4 进一步结合Self-Improve (Method c)【推理与改写】
│ │ ├── Revision Model【对错误答案进行修正】
│ │ ├── 多轮迭代式Refine【输入分布动态改变】
│ │ └── 与并行采样融合【效率对比与收益】
│ ├── 2.5 小模型 vs. 大模型【计算量交换率】
│ │ ├── 何时“小模型+更多推理时间”能胜过“大模型贪心解码”【条件与难度】
│ │ ├── 简单/中等难度题:搜索可以弥补模型不足【搜索有效】
│ │ └── 高难度题:搜索收益有限【本身推理能力不足】
│ └── 2.6 小结【实验与结论】
│ ├── Test-Time算力可在中等难题上胜过贪心大模型【可行性】
│ └── 瓶颈仍在模型本身的推理水平【必须提高Reasoning能力】├── 3 MCTS与LLM结合 (MCTS-LLM)【基于价值搜索的推理框架】
│ ├── 3.1 基础概念【背景】
│ │ ├── 强化学习 (RL)中的蒙特卡洛树搜索 (MCTS)【Value-Based方法】
│ │ ├── AlphaGo / AlphaZero启示【自博弈与搜索】
│ │ └── LLM中动作空间庞大导致难以直接迁移【技术挑战】
│ ├── 3.2 与LLM结合的思路【如何应用】
│ │ ├── 将LLM生成的每一步/每个token当作节点【步骤或令牌级动作】
│ │ ├── 使用Value或Reward模型 (PRM/ORM)评估节点质量【评估节点】
│ │ └── 探索-利用平衡:UCB或其变体【控制搜索分支】
│ ├── 3.3 工程实现难点【实践限制】
│ │ ├── 计算开销大【深度与广度搜索的FLOPs消耗】
│ │ └── KV Cache与Tree结构管理复杂【缓存与并行】
│ └── 3.4 典型方案【AlphaZero-Like Tree Search等】
│ ├── 在推理时做搜索【纯Inference】
│ └── 在训练时纳入搜索数据【结合PPO或自监督】├── 4 Process Reward Model (PRM)【过程奖励模型】
│ ├── 4.1 定义与用途【区别于ORM】
│ │ ├── PRM对多步推理的中间步骤打分【信号更密集】
│ │ ├── 可用于剪枝或引导推理路径【搜索友好】
│ │ └── 适合数学、代码等有客观对错的过程【正确性判断】
│ ├── 4.2 数据标注方法【如何获得step-by-step标签】
│ │ ├── 人工标注:Let’s Verify Step by Step【三分类(正确/错误/中立)】
│ │ ├── Math-Shepherd:基于Rollout估计Step正确率【自动标注】
│ │ └── OmegaPRM:二分搜索减少Rollout次数【提升标注效率】
│ ├── 4.3 PRM在推理中的应用【PRM-Search】
│ │ ├── step-by-step 检测并剪枝【无效步骤判定】
│ │ ├── Best-of-N + PRM重打分【挑选最优回答】
│ │ └── Beam Search / Lookahead + PRM【扩展与剪枝结合】
│ └── 4.4 与RL训练的结合【可替代或增强传统ORM方式】
│ ├── 对每一步进行即时奖励【减小奖励稀疏问题】
│ └── AlphaZero风格中充当Value网络【鼓励正确中间过程】├── 5 Reasoning能力提升【模型自身推理水平】
│ ├── 5.1 Self-Improve / Revision【自我改写与多轮推理】
│ │ ├── 通过将错误回答并入上下文促使模型修正【隐式/显式修改输入分布】
│ │ ├── 训练阶段可并行收集修正数据【SFT或RL】
│ │ └── 多轮迭代会大幅增加token消耗【效率与效果折中】
│ ├── 5.2 STaR【Self-Taught Reasoner】
│ │ ├── 自动生成Rationale并判断正确性【可持续优化】
│ │ └── 正确解答反向加入训练数据【自举式训练】
│ ├── 5.3 SCoRE【Self-Correction via RL】
│ │ ├── 多回合回答 (y1, y2…) 的奖励对比【修正前后】
│ │ └── 采用PPO与reward shaping【阶段式优化】
│ ├── 5.4 Self-Critique / CriticGPT【引入批评者角色】
│ │ ├── 额外LLM作为批评器【对生成过程显式指出错误】
│ │ └── 将批评信息整合到生成模型【改进下一轮答案】
│ └── 5.5 Consistency & Verification【一致性和自验证】
│ ├── 引入多种思路提升稳健性【Best-of-N, Majority Vote, 等】
│ └── Step-Aware或Token-Level验证【颗粒度更精细】├── 6 Self-Play与对抗式生成【数据自洽与迭代提升】
│ ├── 6.1 概念与动机【AlphaGo Zero启示】
│ │ ├── 不依赖人类标注,模型相互博弈产生数据【自对弈】
│ │ └── 适用于游戏/棋盘类任务,也可扩展到复杂推理【自生成数据】
│ ├── 6.2 rSTaR / Mutual Reasoning【小模型互相审查】
│ │ ├── 采用预先设计动作集简化搜索【避免巨大token空间】
│ │ └── 迭代判断一致答案或修正答案【提高结果可信度】
│ └── 6.3 OpenR等开源实践【结合MCTS与Self-Play】
│ ├── 训练阶段:利用MCTS和PRM标注产生数据【数据增广】
│ ├── 推理阶段:利用Beam/Tree Search或Best-of-N【组合策略】
│ └── 尚存大规模计算与工程优化挑战【Speculative Decoding等】└── 7 结论与展望【知识收敛与下一步方向】├── 7.1 Scaling Test-Time与模型自身能力需结合【双管齐下】├── 7.2 小模型+推理搜索可在中等难度题上节省参数但难解高难度【取舍】├── 7.3 自动化PRM标注与MCTS为解决复杂多步推理提供思路【过程监督】├── 7.4 自我改写、对抗自博弈、多模型协同将成未来趋势【不断迭代】└── 7.5 工程落地尚需优化大规模计算与搜索开销【并行化与缓存管理等】
一、起点:预训练规模触顶与「推理阶段(Test-Time)扩展」的动机
-
预训练规模的瓶颈
- 以 Llama 等模型为例,随着参数规模增大,预训练在通用语料上的收益递减,预训练的 Scaling Law(规模定律) 面临“天花板”。
- 这驱动了研究者将关注点从“如何进一步放大预训练”转向“如何在**推理阶段(Test-Time)**投入更多算力来提升模型表现”,即 Scaling LLM Test-Time(推理阶段扩展)。
-
“推理阶段扩展”意味着什么?
- 传统的推理:给定一个提示(prompt),模型一次性或顺序地生成答案,往往用 贪心(Greedy)或少量 Beam/Search 采样等常规方法,一次性地生成答案。
在这种模式下,你主要依靠的是“模型本身的巨大知识与能力”来一次性就把问题解对。
推理阶段扩展(Scaling Test-Time) 则不再止步于“一次性”生成答案,而是允许更多计算、迭代、搜索或验证:
- 多路并行采样(Best-of-N):对同一个问题,让模型尝试生成 N 个不同的结果,然后通过某种评分标准(可能是一个验证器/判题器/外部测试)选出最优解。
- 带验证器(Verifier)的搜索:先生成不同候选答案,用一个内置或外部的验证模块对这些候选答案进行打分筛选,不断迭代改进。
- 自改进(Self-Improve):模型自己对自己的输出进行评估与反思,再次修改答案,如“先答一版,再根据反馈或自检做第二、第三轮修改”。
与其把更多算力用在“训练/模型规模”上,不如把算力放到“推理时的搜索/迭代过程”上,也许可以在某些(尤其是难度中等或较简单)任务上取得与“大模型+一次性推理”相当的效果。
“推理阶段扩展”简单来说就是:让模型在测试/推理时不仅做“一次性解码”,而是可以多轮生成、搜索、筛选、验证,或者配合其他外部工具(如判题器、编译器、搜索引擎等)迭代改进答案。
二、Test-Time 扩展的核心思路与常见手段
在推理阶段“增加算力/改进策略”的做法,核心是**Proposer(提议者) & Verifier(验证者)**框架下的各种搜索/重排策略。
-
Proposer(提议者)
- 主要指大模型本身(或多模型体系中的“生成”部分)。
- 负责在每一步“提出”一个可能的推理步骤或整个最终答案。
-
Verifier(验证者)
- 可以是一个外部模块(Reward Model / 评分模型 / 判题器 / 符号检查器 / 真实环境执行器 等),也可以是另一个语言模型或同一模型在不同模式下对答案进行评估。
- 用来评价 Proposer 的输出质量,打分或给出“对/错”判断。
- 不仅可以对“最终结果”打分,也可对“中间过程”进行逐步评估。
这一框架能够把许多不同的推理阶段增强方法,统一到“(Proposer)做生成 + (Verifier)做评价+筛选”的闭环中去。
整体我们可以用“Proposer & Verifier”这一统一视角,将不同方法分为:
- 只关注最终结果 (ORM / Outcome Reward Model) 的策略
- 关注中间过程 (PRM / Process Reward Model) 的策略
- 自改进 (Self-Improve) 这一更迭代化的策略
1. Proposer & Verifier 统一视角
- Proposer(提议者):通常是语言模型本身,负责“生成”可能的答案路径;若是多步推理任务,就会依次生成步骤 (step by step)。
- Verifier(验证者):对已有生成进行打分或判断,必要时回退错误步骤或筛选最优答案。
- ORM (Outcome Reward Model):“结果级别”的打分模型,只关心最终答案对不对/好不好。
- PRM (Process Reward Model):“过程级别”的打分模型,可对推理过程中每个步骤给出奖励信号。

方法1:纯 Inference Scaling
-
核心思路:
- 不改变模型的参数,也不额外进行(或仅进行极少量)再训练,而是通过增加推理阶段的算力或时间来提升性能。
- “推理阶段”也称 Test-Time 或 Inference 阶段,常用策略是一次性多条答案采样、对答案或中间步骤进行筛选,从而选出更优解。
-
常见做法:
- Best-of-N / 拒绝采样:一次生成 ( N ) 条回答,用一个判别方式(如奖励模型、判别器或投票)选取最优答案。
- 优点:易于并行;只要采样次数足够大,有时能大幅提高正确率。
- 缺点:当问题过于困难、模型本身能力不足时,增大 ( N ) 依旧可能无效;采样量增加会带来更多计算。
- 束搜索 (Beam Search):逐步扩展多个候选路径,选“分数”更高(例如用 PRM 评分)的束进行下一步生成。
- 优点:在低并行度、资源有限的设备上往往更“精打细算”,有时小计算预算下效果优于 Best-of-N。
- 缺点:需要串行地维护和更新候选路径;若搜索深度大,整体推理仍消耗较多时间。
- Lookahead / 前瞻搜索:在每一步还要多向前“试探”若干步再评分,以期更好地评估当下决策。
- 优点:类似启发式的“向前看几步”,避免局部决策失误。
- 缺点:若没有回溯或精细的搜索算法(如完整的 MCTS),收益不一定显著,且推理算量变大。
- Best-of-N / 拒绝采样:一次生成 ( N ) 条回答,用一个判别方式(如奖励模型、判别器或投票)选取最优答案。
-
支持工具:
- 过程奖励模型(PRM):可对“中间推理步骤”逐步给出正确/错误的反馈或分数,帮助在推理中更早筛除错误分支。
- 结果奖励模型(ORM):只对“最终答案”给出分数,常用于 Best-of-N 的最终答案筛选;若问题长、步骤多,会比较稀疏。
- 将 PRM/ORM 与搜索相结合,可以更精细地在推理过程中“选优”。
-
适用场景与局限:
- 适用场景:
- 中等或以下难度的任务:只要用多路采样或搜索方法,一定概率能找到正确解;PRM/ORM 能很好地鉴别对错。
- 有较多并行算力或“可以接受多条候选”的应用场景(如文案创作)。
- 主要局限:
- 当模型“内在推理”能力有限、或者问题非常复杂时,单纯扩大推理计算量无法显著提高正确率;会遇到收益天花板。
- 计算成本(FLOPs)随 ( N ) 或搜索深度呈指数增长,且对特别难的问题增益不大。
- 适用场景:
方法2:推理能力增强
-
核心思路:
- 通过改变模型本身的“推理能力”来获得性能提升。包括 (1)改进输入分布(Prompt、多轮提问等)和 (2)改进模型参数(监督微调、RLHF 等两种维度)。
-
常见做法:
- 修改输入分布(提示工程):
- 少样本示例 (Few-Shot Prompt)、链式思考 (Chain-of-Thought) 等;让模型在推理时更倾向输出更完整的推理过程。
- 多轮修正 (Self-Improve / Revision):让模型先给出一个回答,再把这个“回答 + 原问题”作为新的输入,提示它“这有哪里不对?重新回答或改进”,不断迭代生成。
- 仅在推理阶段就能实现,但如果模型先前从未学会如何“反思式”改写,单纯地多轮对话也不一定能得到显著提升。
- 再训练(改变模型参数):
- 监督微调 (SFT):在新的数据上(如带有推理步骤或多轮修正的数据)进行微调,让模型学会“如何在上下文中改进自己输出”或“如何利用外部反馈”。
- 强化学习 (RL):使用奖励模型(ORM 或 PRM)来对语言模型进行策略优化(如 PPO),让模型本身会“迭代改进答案”,逐渐提升推理水平。
- 也可结合“自我监督”的数据来源(例如自己合成的多轮修正对话、过程标注)做持续训练。
- 修改输入分布(提示工程):
-
支持工具:
- Revision Model / Self-Improve 模型:专门学习“给出初版回答后,如何基于上下文改进答案”。
- Critic / 审稿人模型:一个辅助的模型或同一个模型的另一个角色,批评或审查初版答案并给出改进提示(显式/隐式)。
- 自一致性 / 自反馈:鼓励模型自审,在多个答案里选取共同之处;或先批评再改写。
-
适用场景与局限:
- 适用场景:
- 需要解决较复杂推理且偏好在部署前就提升模型能力的情境。
- 训练和部署算力资源相对充足,可以支持一次性再训练或持续迭代。
- 主要局限:
- 需要额外的训练数据或人工/自动标注(如过程监督、奖励模型训练等),成本上升。
- 对一些领域极度复杂、非常专业的问题,模型依然可能遇到上限,需要更多有效数据或算法(例如真正的专家水平推理)。
- 适用场景:
2. 只看最终答案:Best-of-N、Best-of-N Weighted
Best-of-N(或 Rejection Sampling):一次性采样 N 条回答,用一个判别方式(如奖励模型或统计一致性)选出最优。
-
做法:
- 从同一个提示 (prompt) 出发,令 Proposer 并行或快速生成 N 条候选答案。
- 用 Verifier (通常只对最终答案做判分) 选出一个最高分 / 最优解输出。
-
优势:
- 易实现:只需做 N 次推理,然后统一打分或做简单判别/投票。
- 可并行:多条候选的生成基本上可以并行进行,不耽误时间。
- 对简单中等难度任务有效:多次随机采样往往能找到相对更好的解。
-
劣势:
- N 增大时收益递减:当 N 较小时,能显著提高正确率,但再大时边际收益不明显。
- 无法对过程中的“局部错误”进行精细纠正:只能在最终结果里挑优,没有指导生成过程的机制。
Best-of-N Weighted:不仅只选最高得分的单条,还可做多条候选分数的加权或投票来决定最终输出。
-
做法:
- 生成 N 条答案后,不是只选最佳,而是对每个答案进行评分,根据分数做加权融合(例如投票、概率加权)来得到最终答案。
-
典型场景:
- 当答案可以用某种“统计方式”集合(例如多次采样得到多个自然语言解释,再做少数服从多数的融合)。
- 或者在抽象问答、情感分析任务中,把多条候选的预测结果加权后得到更可靠的输出。
-
优劣:
- 类似普通 Best-of-N,但在决策时可能更精细;需要有合适的“融合”方法,且并不适用所有需要精确唯一解的任务(如数学题往往只有一个正确解)。
3. 关注中间过程:引入过程奖励模型 (PRM)
- 为什么需要 PRM
- 结果级别(ORM)常见问题:只在最终答案对/错时给反馈,反馈可能过于粗糙不精细;对复杂多步推理来说,不知道哪个步骤出了问题。
PRM (Process Reward Model) 的优势:
-
能对推理过程中的每个步骤给出更细粒度的打分,从而在搜索时“及时纠偏”。
-
有助于在多步生成阶段筛选错误路径,保留正确路径,从而大幅减少无效探索。
PRM 数据如何标注?
- 人工标注 (OpenAI “Let’s verify step-by-step” 风格):让人对每步推理做“正确 / 错误 / 可接受”打分,用于训练 PRM。

- 自动化标注 (Math-Shepherd 思路):用蒙特卡洛采样/rollout 来估计当前 step 之后能走向正确答案的概率(reward-to-go)。
用 o1 Pro 生成 step-by-step 的标注:

- 二分搜索式高效标注 (OmegaPRM):在每条解题链上二分查找首个错误 Step,减少大量 rollouts。
传统的方法标注太多了,每个 step 都需要 N 次 rollout。
做了一个假设:如果答案是对的,那么之前的过程就是对的; 如果当前步骤答案是错的,后面的步骤都是错的。
rollout 就像树搜索中的“向前模拟”,用于判断从当前状态(某一推理步骤)出发,最终能否得到正确答案、可能的奖励是多少。
在推理过程中从某个中间步骤继续往后生成完整解答、并评估结果的过程。
因此,在 OmegaPRM 中,为了找出“最先出错的具体步骤”,我们可以用“二分查找”的方式反复进行“部分推理 + rollout 验证”。
之所以这么做,是为了减少对整个解题链做全量多次生成的开销,用更少的测试就能定位问题出在哪一步。
PRM-Searching:在 PRM 后设计搜索算法。
论文:Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters

PRM 在推理时的常见搜索
-
Best-of-N + PRM: 仍是并行地生成 N 条不同推理链,但这次对于每条链不只看最终结果,而是可以用 PRM 对过程评分,最终选出过程分数最高的链。
-
Beam Search + PRM: 逐步扩展束宽,每一步都要用 PRM 给每个分支打分,然后保留 top-k 路径继续扩展,直到生成完整解;再选最高分作为最终答案。
-
Lookahead Search: 类似 Beam Search 的前瞻式搜索,也是一种“多步后评估”的策略。
- 可以在每一步都做前瞻式多分支扩展、估算后续可能的最高得分,挑选最优走向。
- 这种方法在推理层面更像 MCTS(蒙特卡洛树搜索)思路,过程奖励就像模拟中棋局评分一样。
适用场景与优劣
-
适合:
- 多步推理、过程可能非常冗长的复杂任务(数学题、程序生成、逻辑推导等)。
- 需要在中间就能识别关键错误,避免浪费大量计算在错误路径上。
-
挑战:
- 需要有一个可靠的过程奖励模型,如果 PRM 自己也经常误判,就会把搜索带到错误方向去。
- 训练 PRM 的高质量数据通常获取成本也不低。
4. 自改进(Self-Improve / Revision)的思路
为什么需要 Self-Improve?
语言模型单次输出容易埋下局部错误,加上缺乏中间纠偏环节,导致在复杂任务上难以保证答案正确性。
- 单纯依赖搜索,若模型本身推理能力有限,还是无法触及高难度问题的真正正确解。
- 搜索策略更多是“从头到尾”进行多次生成和筛选;
- 自改进则偏向在生成后对已有答案进行后续修订或重写。
- 有时模型一次性产物并不是“完全错误”,而是局部有 bug,借由“再思考 / 再校正”可以修正。
- 自改进也可以看做是:反复调用 Proposer,每轮输入都带着前一次的输出与错误信息,让模型“对症下药”地修改答案。
人类做复杂决策时倾向于“分阶段测试+迭代修正”,而非一次性给出终极答案;这种模式可不断聚拢正确解。
高难度任务对“局部错误的容忍度”极低。
一旦多步链式推理中任何关键节点出错,就会导致后续推导全面崩溃;如果没有后续改正机制,最终结果几乎必然出错。
语言模型在一次性推理中难免犯下局部错误,高难度任务对错误的容忍度又极低;只有通过多轮修订与验证,才能在实践中有效地将正确率推高。
数据采集 & 训练
- 有时要专门训练一个 “Revision Model”,学习如何在给定“错误回答”的上下文下进行改写或修正。
- 输入是“初版答案 + (可选)错误标注 + 原始问题”,输出新的改进答案。
采集数据可结合并行 (parallel) 与顺序 (sequential) 的多次生成,筛出最优修正答案,用于 SFT 或 RL 训练。
- 让模型生成多条答案(可能包含错误)。
- 收集人类或自动判题器对错误点的反馈。
- 将 “(初版答案, 错误点, 原题)” -> “(正确答案)” 这一过程作为监督训练样本。
- 或者在 RL 场景下,通过多次探索与修正,以逐步提高最终得分。
- 优点:
- 克服小模型的“记忆不足”:如果它在第一版输出中体现出了部分思路,后续可以保留正确片段、修正错误处。
- 相同推理 FLOPs 下,往往比单纯多路采样 (Best-of-N) 效果更好:因为 Revision 是有针对性地修补错误,而不是纯粹随机多次输出。
- 缺点:
- 工程复杂度更高:需要有合适的“反馈机制”告诉模型哪里错了(Verifier 筛选规则),以及如何把旧答案嵌入新上下文再生成(如何将错误答案融入新 Prompt);“多轮对话式”场景更适用,但实现需要更好的 Prompt 设计和场景管理。
- 对高难度任务仍有瓶颈:如果问题本身需要远超模型容量的大量知识或高级推理能力,即使能不断修订,小模型也可能反复出错、难以真正摸到正确解。
三、如何提升多步推理?
「Reasoning」本质上是让大模型能够“多步思考”或“逻辑推导”,从而解答复杂问题(如数学推理、代码调试、逻辑推断等)。传统的贪心或一次性生成往往对复杂推理不足,因此衍生了各种增强策略:自一致性 (Self-Consistency)、自我改进 (Self-Improve / Revision)、搜索 + 验证 (Search + Verifier)、多轮推理 (Multi-turn) 等。本章主要介绍几种核心思路与其在实际项目中常见的用法。
STaR:Self-Taught Reasoner
-
动机
- 希望让模型能自主地产生“带推理步骤的解答 (rationale)”,并根据最终答案正确与否来筛选/回流数据,逐步提升模型的推理能力。
-
核心思路
- 先让模型在给定的题目上生成一个“推理过程 (rationale) + 最终答案 (answer)”;
- 如果答案是对的,就把这一组 (问题, 推理过程, 答案) 作为新的训练样本,用于微调模型;
- 如果答案是错的,则可以修改 prompt(例如增加“CORRECT”提示、给出一部分正确信息等),再生成新的推理过程与答案,然后同样筛选并加入训练集,形成自举式的迭代(bootstrapping)。
-
数据增广
- 通过一次次的自动生成与筛选,让模型得到更多带“过程标注”的数据,称之为 Self-Taught。对那些难度不高但能自动判断对错的题目,能快速扩充上千乃至上万条高质量示例。
-
效果
- 比仅仅做有监督微调(SFT)能更好地学到“多步推理”的模式;
- 缺点是对错判断往往只看最终答案,需要题目“有明确正确答案”才能做自动筛选。
SCoRE:Self-Correction via Reinforcement Learning
-
问题背景
- 类似地,希望模型能在回答之后,再进行“自我修正” (revision),而不仅仅只产生一次回答就停止。
-
核心机制
- 将“初次回答 (y₁)”和“修正回答 (y₂)”都纳入 RL 的训练框架:
- 阶段 1(Stage I):只要求 y₂ 的奖励最大化,同时约束 y₁ 与原参考策略相近;
- 阶段 2(Stage II):鼓励 y₂ 超越 y₁,甚至两者都变好,包括用 shaped reward 做差分 (r(y₂) - r(y₁))。
- 这样可逐步学到“如何在已有错误或不完善回答的基础上进行自我改进”。
- 将“初次回答 (y₁)”和“修正回答 (y₂)”都纳入 RL 的训练框架:
-
与纯搜索的区别
- 不是在推理时简单地多生成几条候选,而是通过 RL 训练出“自我修正策略”,让模型习惯于先产出一个回答,再读入自己的答案并做思考,产出修订版回答。
-
关键点
- 需要“合理的奖励函数 (reward)”,可基于自动判分(如数学)或人类标注(如偏好或正确性);
- 多轮自我修订不一定无限有效,通常在 2~3 轮后收敛或收益变小。
Self-Critique / CriticGPT
-
自我批评 (Self-Critique) 的思路
- 让同一个大模型或者一个专门的“批评模型 (Critic Model)”来检查已生成的答案,指出可能的错误并给出修改建议。
-
与 Self-Improve / Self-Correction 区别
- Self-Critique 更强调显式地让模型说出“这段回答的不足之处在哪里”,从而帮助下一个阶段的回答。
- Self-Correction 侧重在产生新版回答;Self-Critique 先做“批评/诊断”,再配合一个 Revision 模块进行修订。
-
CriticGPT
- 可以把“批评者 (Critic)”也看作一个大模型,通过 prompt 让它阅读候选答案并产出批评。
- 若批评有效,则将这些批评点注入上下文,再让“解答者 (Solver)”对答案做相应修改。
-
数据构造
- 可以先用已有正确/错误示例,半自动地生成“批评文本”,再对 Critic 模型进行微调。
- 也可在推理阶段在线调用 Critic 模型,对错误回答做诊断,然后引导下一轮回答。
其它自反馈与多步推理技术
-
Self-Feedback / Internal Consistency
- 让模型多次独立生成回答,再相互对比,若不一致就挖掘原因或投票统计。
- 自一致性 (Self-Consistency) 也是类似思路:对同一问题多次采样推理链,统计最高频的结论作为最终答案。
-
STaR / rSTaR
- STaR:前面提到的自教 (self-taught) 方式;
- rSTaR:在多轮迭代中引入“自监督的提示”或“对错标记”,再做反向训练;可以看作引入更多自动收集的正确解答来改进模型。
-
结合搜索 (Search) 与过程奖励 (PRM)
- 将自我修订、批评或自一致等多轮思路,与 Beam Search / MCTS / PRM-Verifier 等结合,可得到更强的“全局搜索 + 局部改进”推理流程。
Reasoning 的体系与趋势
-
要素
- 逻辑推理往往需要多步展开(chain-of-thought),但大模型可能一开始并不会主动地“拆解思路”。需要在训练或推理时主动引导模型产生显式/隐式的中间步骤。
- 在每步或每轮回答后,都可以利用外部/内部的验证器(如 PRM、ORM、代码执行器)、自检(Self-Critique)、自修订(Self-Correction)等手段来强化结果。
-
结构
- “基础模型 (Proposer / Generator)”:负责生成初步回答;
- “验证器 / 批评者 (Verifier / Critic / PRM)”:评估或诊断回答质量;
- “修订模型 / 自一致模块 / 搜索过程” 等:基于验证反馈,生成更优答案。
- 若再配合 RL 训练或搜索树探索,可完成多轮迭代式改进。
-
系统化应用
- 自举 (bootstrapping):如 STaR,用多轮生成+筛选来扩充高质量训练数据;
- 在线推理:用 Self-Critique / Self-Improve / Best-of-N / MCTS 等组合,让模型在推理时就动态修正错误;
- 训练 + 搜索:在 RLHF 或 PRM 训练中,配合树搜索或并行采样,不断把高分回答回流到下一轮模型中。
-
未来趋势
- 更灵活的“代理式 (Agent)”设计:可在推理过程中插入检查、外部工具调用、与其他子模型协作;
- 提升“自纠错”与“自一致”效率:结合并行采样、多模块协同,大幅减少重复 Token 生成;
- 与真实应用结合:如自动数学解题、代码修正、长文本内容编辑等,通过多步推理大幅提高答案正确率与可解释性。
参考与延伸
- Self-Improve / Revision:
- Recursive Introspection: Teaching Language Model Agents How to Self-Improve
- STaR:
- STaR: Bootstrapping Reasoning with Reasoning
- CriticGPT / Self-Critique:
- Self-critiquing models for assisting human evaluators
- LLM Critics Help Catch LLM Bugs
- SCoRE:
- Training Language Models to Self-Correct via Reinforcement Learning
- Self-Consistency:
- Self-Consistency Improves Chain of Thought Reasoning in Language Models
「Reasoning」部分聚焦让大模型在多步推理场景中“更稳健、更准确、更可控”地生成答案。
核心方法多围绕自举训练 (STaR)、自我修正 (Self-Correction)、自我批评 (Self-Critique)、自一致性 (Self-Consistency) 等策略展开,并可与过程奖励模型 (PRM)、搜索解码 (Beam/MCTS) 相结合,实现从生成到验证、再到修订或搜索的闭环。
这类闭环思路在数学推理、代码生成与复杂聊天应用中日益常见,也形成了大模型“自动纠错、自动演进”的重要发展方向。
四、进一步:MCTS 与 AlphaZero-Like 搜索
当我们谈到“树搜索”在 LLM 推理中的应用时,会联想到下列主题:
-
蒙特卡洛树搜索 (MCTS)
- 在围棋(AlphaGo、AlphaZero)中,MCTS 能基于“状态、动作、价值估计”等机制高效搜索。
- 若把多步推理问题视为“从空白状态开始,一步步产出文字(动作),直到答案状态”,理论可引入 MCTS。
-
AlphaZero-Like Tree Search 与 LLM
- 不同之处在于语言生成的动作空间极大(往往是 Token 级别),导致计算代价极高;可能需做Step 级搜索或人工限制动作空间。
- 也可结合 PRM (过程价值估计) 取代围棋中的价值网络;在推理中进行搜索回溯、剪枝。
- 若再做 RL 训练 (PPO/Policy Gradient) + MCTS,就对应“AlphaZero-LLM”的思路(比如 OpenR 框架、AlphaMath 等)。
-
工程挑战
- 超大动作空间的并行搜索需要精心的缓存管理(KV-Cache)、加速解码(Speculative Decoding)等。
- 算力投入非常庞大;更多处于学术前沿或大厂内部探索阶段,尚未广泛普及。
复现 o1 的方案:

借助 MCTS 来在推理阶段搜索最优解答,并通过一个“Value 模型(或称 PRM/Reward/价值头)”对生成进行打分。
这与“AlphaZero-Like Tree Search”非常相似。
AlphaZero-Like MCTS + 一个Critic值模型,只不过将“围棋局面”换成了“LLM 逐步生成的文本状态”,把“赢/输”换成了正确/错误或reward。
MCTS(Tree Search) + (过程)价值模型来进行多步推理搜索。
五、PRM 在推理与训练中的多种用途
-
推理阶段
- PRM + Beam Search、Best-of-N、MCTS 等,用来实时筛选“下一步生成”或最终答案;精细化过程监督比只看最终结果更可靠。
-
训练阶段 (替换 RLHF 中的 ORM)
- 传统 RLHF 用人类偏好数据训练一个 Outcome Reward Model (ORM),对完整回答打分。
- PRM 则提供每个中间步骤的奖励,更像强化学习里的 dense reward,有时能加速收敛并减少“错误信息的回传延迟”。
-
数据合成
- 通过 PRM 对大量采样进行打分,把得分高的中间推理轨迹当作训练数据(自监督或 RL),实现自动数据增广。
- 相比人工逐步标注正确/错误,自动化方法可 Scale,但需要可靠的自动标注(如 Math-Shepherd / OmegaPRM / 结合外部执行器等)。
六、左右互博 Self-Play 与 Self-Improve
-
自我对弈 (Self-Play)
- 类 AlphaGo-Zero:没有人类棋谱数据,完全通过模型自己对自己对弈产生数据并迭代训练。
- 对 LLM 而言,“自我生成问题 + 自我解答”或“多模型交互”,可在代码/数学等有确定性检验场景中滚雪球式地产生训练数据。
-
自我修改 (Self-Improve / Revision)
- 更聚焦“拿到错误回答后,如何在新 Prompt 中集成这些错误提示或思路,进而得到正确答案”;
- 可以不使用 RL,而在推理时多轮迭代生成(修正),或专门训练“Revision Model”。
“Self-Play” 最初源于强化学习在棋类游戏(如 AlphaGo、AlphaZero)中的成功应用:通过让同一个或相似的模型左右互博(self-play),不断收集对局数据并更新策略,在没有大量人类专家数据的情况下依然能获得强大性能。
对于大模型来说,若能把某些推理或决策问题设定为“可自我对局、可自我评估”的形式,就有机会用类似自我博弈的过程产生高质量数据,并迭代优化模型的策略或价值估计。
Self-Play 的核心要素
-
自对局 (Self-Play) 的本质
- 在没有外部标注数据或专家指导时,模型自己产生“状态—动作—收益”序列;
- 通过与“自我”或“副本模型”对抗,或者对同一个问题做多种解答/立场,然后根据“胜负/对错”进行打分与训练。
-
可行的自博弈场景
- 棋盘游戏、策略决策:比如围棋、国际象棋等,AlphaZero 证明了纯自博弈即可学到超强策略;
- 代码/数学推理:某种场景下可让模型生成多种推理路径来竞争或互相检验;
- 对话/角色扮演:两种聊天代理互相对话,或在文本环境中完成特定任务(如谈判、博弈等)。
-
与普通多轮采样的区别
- 自博弈带有明确的“对抗”或“竞争”目标;
- 模型在这个对抗过程中,既产生成长所需的数据,也能避免过度依赖人工示例。
- 若仅仅是多轮自修订 (self-improve),并不一定有对抗性,而 self-play 常常强调双边 / 多边策略竞争或评估。
Self-Play 与 MCTS (蒙特卡洛树搜索)
-
AlphaZero 式框架
- 关键要点:
- 策略网络 (Policy):用于给出下一步动作或在搜索中做先验;
- 价值网络 (Value):估计从当前状态到终局胜率;
- MCTS:在对局/推理时,通过多次模拟搜索提高决策质量。
- 自博弈:模型在自己与自己的对局中,反复更新策略和价值网络。
- 关键要点:
-
迁移到 LLM 的思路
- 若把多步文字推理视为“状态—动作”序列,也可借助 MCTS 进行多路径拓展,并用价值函数 (PRM / Value Model) 来评估路径质量;
- 在无外部监督数据时,可以让模型通过自博弈(如对同一问题给出多解法、相互验证或竞争)来生成更多训练样本:
- 对于“推理类”任务,可将正确答案看做“胜利”,错误答案看做“失败”;
- 或在对抗式场景里,每一方都尝试使对方失败 / 自己成功。
-
挑战
- 语言任务的状态与动作空间极大;
- 策略改进和价值估计需要稳定的训练流程(类似 AlphaZero 的自博弈 + MCTS + 神经网络迭代更新)。
- 工程上还得解决海量 Token 消耗、并行效率、缓存管理等问题。
Self-Play 在开放式推理或问答中的尝试
-
rSTaR / Mutual Reasoning
- 有些研究会让两个不同的 LLM(或同一个模型的两个角色)互相提问、回答或者互相审核。例如:
- 生成者 (Generator):尝试给出解答;
- 鉴别者 (Discriminator):尝试改写问题或要求一致性验证;
- 只有能通过一致性检验的答案才被模型采用并记入训练数据。
- 这在一定程度上体现“自对局”概念:两个子模型互为对手或互为合作方,相互推动生成更优解。
- 有些研究会让两个不同的 LLM(或同一个模型的两个角色)互相提问、回答或者互相审核。例如:
-
Self-Play vs. Self-Improve
- Self-Improve 通常指同一个模型在多轮中迭代修订自己的回答,但不一定是对抗或博弈;
- Self-Play 强调可有两个或多个策略、角色、对抗机制,从而产生胜负或竞争概念,进而激发策略演化。
-
OpenR 框架
- 提到的一些开源框架 (如 OpenR),希望把自博弈(对抗式生成)和 PRM 价值模型结合,形成类似 AlphaZero 的“自举式迭代”;
- 这样能进一步减少对人类标注的依赖:模型在自我对局中既是“数据生产者”又是“学习者”,在每次迭代中更新策略与价值函数。
整体结构与系统化
-
要素
- 游戏/推理环境:定义清晰的状态、动作、以及胜负(或奖励)规则;
- 策略模型 (Policy):通常由 LLM 或多任务模型承担,生成下一步动作/文本;
- 价值模型 (Value / PRM):判别这条推理路径或对局结果的好坏;
- 搜索/对局机制 (MCTS 或简化的并行采样):在推理或训练中多次模拟对局或多路径生成;
- 自对局数据回放:将对局数据(带奖励信号)反过来训练策略和价值模型,迭代提升。
-
与 RL 训练的结合
- Self-Play 收集到的大量“(s, a, r, s_next)”样本,用于强化学习(如 PPO / Q-learning / Policy Gradient 等)或监督微调;
- 在语言模型场景,可能依赖过程奖励(PRM)替代单一的胜负标签,给出多步推理中更丰富的反馈。
-
应用难点
- 开放式问题定义不清:若无法定义明确的“胜负”或“奖励”,就很难做真正自对局;
- 采样 Token 开销大:大模型多次自对局、MCTS 或多轮搜索需要消耗大量计算;
- 工程实现复杂:包括缓存管理、多 GPU 并行、回合式生成等,对推理基础设施要求高。
-
典型收益
- 当人类标注数据缺乏,或者问题具有客观“优/劣”评价标准时 (如游戏胜负、编程题 AC/RE、数学题对错),“Self-Play + 搜索 + 强化学习” 能达到快速迭代;
- 有望让模型在特定领域实现类似 AlphaZero 在围棋上那样的“从零自学”级别突破。
- Self-Play 在语言模型领域是一条颇具潜力但仍具挑战的思路。
- 它的核心是让模型在没有或很少的人工监督下,自发地产生高质量训练数据,并通过对抗或互补的方式迭代提升策略。
- 结合 MCTS、PRM 及 AlphaZero-Style 方法,可以形成完整的自举式解决方案:模型既是数据生产者,也是训练与推理过程的执行者,逐渐提升其推理水平。
- 工程化落地需要大量优化与分布式并行技术,但从长期看,“自对局 + 价值评估 + 策略更新” 可能成为 LLM 高级推理能力演进的一条重要路径。
简而言之,Self-Play 拓展了纯“采样-重排”或“多次修订”的范式,融入更明显的对抗或博弈思想。
它对于那些可以清晰定义“胜负/对错”标准的任务尤其有效,可大幅减少人类标注需求,并通过迭代更新策略与价值函数,让大模型像 AlphaZero 那样在封闭或半开放的环境中不断自学和进化。
七、OpenR 框架
链接:https://github.com/openreasoner/openr
- OpenR:一个开源的 LLM 高级推理研究框架,尝试把“过程奖励(PRM)+ 搜索 + 自我迭代训练”结合起来。
- 训练阶段:
- 用 MCTS / PRM 做数据增广(收集每个 step 的“正确性/成功率”),得到更多高质量步骤级监督;
- 训练出 PRM (value function);
- 对语言模型则可采用 PPO/Policy Iteration,在搜索生成的数据基础上进一步训练。
- 推理阶段:
- 也可以结合 PRM 指导“哪条解题路径”继续扩展;
- 对于最终多条候选答案,则可用 Majority Vote / RM-MAX / RM-Vote 等方式选出最佳。
OpenR 是一个开源框架,旨在将「大语言模型 (LLM) + 过程奖励模型 (PRM) + 搜索 (如 MCTS) + 强化学习 (RL)」集成到一个完整系统中,用于多步推理、数据增广和模型持续迭代训练。
它的核心思路是:在推理或训练时,使用带有 PRM 的搜索来生成高质量过程数据,再用这些数据更新模型(策略/价值),形成一个自举式迭代循环。
OpenR 在做什么?
-
框架目标
-
将多个核心组件整合到同一个工作流:
- LLM(基础语言模型):生成候选答案或推理步骤;
- PRM (过程奖励模型):对每个推理步骤或中间状态评估正确性;
- 搜索算法(如 Beam Search、MCTS):在推理时利用 PRM 分数筛选/扩展出更优路径;
- 强化学习 (RL) 或策略更新:将搜索或采样到的高分数据回流训练,从而改善模型性能。
-
其灵感来源于 AlphaGo/AlphaZero:先用搜索算法(MCTS)提高决策质量,再通过价值评估(PRM)给出反馈,反过来优化策略模型,形成闭环。
-
-
数据增广 (Data Augmentation)
- 通过引入过程奖励模型 (PRM),以及类似 MCTS/Beam Search 的方法,从模型自身生成的多种推理路径中,挑选正确或高质量的步骤,得到可用于训练的更多样本。
- 这些样本再结合原有数据,或进行微调 (SFT)、或进行 PPO 等 RL 训练,提升模型的推理能力。
-
推理阶段 (Inference) 的主要思路
- 可选不同的搜索方法:
- Best-of-N:并行采样 N 条完整答案,用 PRM 或 ORM 打分、重排;
- Beam Search:逐步扩展有限束宽,每一步利用 PRM 筛选路径;
- MCTS(在代码中已有部分实现但尚未完整公开可直接运行脚本):更精细地在搜索树中回溯、更新节点价值。
- 可选不同的搜索方法:
-
训练阶段 (Training) 的主要思路
- 先用 PRM 给步骤级别打分,然后:
- 离线数据:把搜索得到的高分路径作为示例,训练模型;
- 在线数据:在 RLHF 或 PPO 场景中,实时利用 PRM 进行奖励,更新模型策略;
- 这样能够代替或部分减少人类偏好标注,改用自动化或半自动化的过程奖励信号来迭代优化。
- 先用 PRM 给步骤级别打分,然后:
OpenR 的意义与优点
-
统一了多步推理与 RL 训练
- 往常很多项目只做“推理时搜素 + 重排”,未必与训练环节互相联动;也有的项目只做单步 RLHF。
- OpenR 试图提供一个能够“双向打通”的框架:既可在推理中用搜索提升答案质量,又能把搜索出来的好序列送回训练流程,不断强化模型。
-
减少对纯人工数据依赖
- 与 AlphaZero 类似,“自举式 (self-play / self-improve) + 过程奖励”可让模型合成大量训练数据。只要有一定初始能力,后续就能自动增强。
-
可拓展性
- 该框架可对接更多搜索方法、更多类型的奖励模型 (ORM/PRM/PAV),或与外部工具(比如代码执行器)结合,做更复杂的推理。
目前的局限与结论
-
尚未完全成熟
- 仓库中的 MCTS 等功能并未全部释放可直接运行的脚本,需要自行查看源码(如
reason/guided_search/tree.py)并做适配。 - 部分算法思路仍在开发,官方文档或示例可能不够完备。
- 仓库中的 MCTS 等功能并未全部释放可直接运行的脚本,需要自行查看源码(如
-
工程挑战
- 多步搜索和过程监督会大幅增加推理 Token 消耗与计算开销,需较强的多 GPU 并行及缓存管理。
- 模型从搜索数据中训练时,如何保证收敛和稳定也需要更多实验验证。
-
总体结论
- OpenR 证明了“AlphaZero-like 搜索 + PRM + LLM”在多步推理场景的可行性:可以在有限或无人工数据时,通过自举式的数据增广和策略更新来提升模型。
- 但同时也表明,这种方法对工程实现要求高,需要进一步优化搜索效率、分布式执行,并改进训练流程的稳定性。
OpenR 展示了在大语言模型中,如何借助过程奖励 (PRM) 和搜索 (MCTS/Beam Search) 构建类似 AlphaZero 的自举式推理与训练闭环:一方面,它在推理中可生成更优答案,另一方面,也能将高分过程数据回流强化模型,从而减少对人工标注依赖并持续提升复杂推理能力。但目前框架仍在初期阶段,尚需更多工程化打磨与功能完善。
八、整体结论与思考
- Test-Time 扩展(搜索、并行采样、迭代修正) 对中等难度问题能带来显著收益,甚至可在相同 FLOPs 下让“小模型 + 大推理”超过“大模型 + 贪心”。
- 纯推理扩展的极限:若任务过难,模型本身的推理能力不足时,光靠推理阶段搜索/修正也无法弥补差距。
- 过程奖励(PRM) 在数学、代码、程序执行等确定性场景有显著优势,极大提升了搜索的效率和可靠性;但需要精巧的数据标注或自动标注方案来支持。
- MCTS/AlphaZero-Like 思路虽然在理论上令人兴奋,但在自然语言生成中动作空间极大,真实落地面临高昂算力和工程难度,需要探索各种加速/剪枝/并行技术。
- 自改进(Self-Improve / Self-Play) 是另一条重要路径:借助迭代式或多模型交互,用自生成数据不断细化模型推理能力,摆脱对人工监督的强依赖。
- 从研发角度看,这些方法通常既可用于推理阶段(提升场上表现),也可用于训练或数据增广(提升模型本身实力),两者往往结合更佳。
如果想进一步提升大模型的多步推理能力,可以将 MCTS 引入训练或推理,配合 PRM/Value Model 做搜索指导。
但真正落地需要高水平的工程优化,并面对“PRM 标注数据有限”“搜索计算成本高”等现实挑战。
4 种解法拆解
┌── 子解法 A: 并行采样 (N 条候选)│ ↓
用户问题 --> 语言模型 --> 验证/打分 (ORM/PRM) --> 选出最优回答│ \│ └─> ① step-by-step Beam Search + PRM (子解法 B1)│ / \│ / \ Lookahead Search or其他剪枝 (B2)│ ↓│ 得到若干条多步路径(选最优)│└── 子解法 C: 多轮revision自修正↓(可结合 A、B 的采样或搜索,进行多次迭代修正)[可选] 子解法 D(MCTS/AlphaZero-like Search + 自对弈/强化训练)
- 训练时:搜索结合价值/策略网络,不断迭代
- 推理时:执行 MCTS 进行深度扩展
从整体来看,“解法”可概括为:在预训练规模触顶时,通过「在推理阶段(Test Time)对语言模型进行多种扩展和改进」来提升复杂推理能力。
为便于拆解,我们将这个大解法拆成以下四大子解法(每个子解法又可以再细化成更小的子步骤,直到不可继续拆解):
子解法 A:纯增加推理计算量(“多样采样 + 验证”)
- 对应特征:依赖现成的大语言模型,不重新训练或只做极少量微调;主要通过在生成时多次采样、然后用验证器筛选结果,来提高正确率。
- 核心思路:一次提问时,从同一个 Prompt 并行生成 N 条答案(常称为 Best-of-N 或 Rejection Sampling),然后利用判别模型(Verifier)选出最优回答。
- 为什么可行:
- 语言模型的输出分布是随机的,多生成若干候选后,总有一部分答案可能更接近正确解。
- 验证模型(例如基于 Outcome Reward Model/Process Reward Model 的打分)可以帮助挑出更优回答。
- 进一步细分:
- Best-of-N / Rejection Sampling:生成 N 条完整答案,只在最后一步用奖励模型挑选。
- Self-Consistency:采样多条 Chain of Thought 答案,再统计投票出现频率最高的最终结论。
- Best-of-N Weighted:不仅看哪个答案得分最高,也可以看答案族的“加权”或“平均得分”来选出最后答案。
- 举个例子:做一道数学题,设置 N=16 并行解码,最后仅将 16 条解答都传给一个判分器(ORM 或 PRM 的最后一步分数)来打分,最高分的就是最终回答。
进一步的子级拆解:
- Proposer(提议者):语言模型本体负责生成。
- Verifier(验证者): 结果奖励模型 (ORM) 或 过程奖励模型 (PRM)。
- 如何聚合:
- 只看最后一步打分(Last-step 的奖励);
- 或者看整条推理链各步奖励之和,再挑出累计最高者。
子解法 B:过程奖励模型(PRM)与搜索式推理(Beam Search / Lookahead / 等)
- 对应特征:在多步推理中,每一步都可能对最终正确性产生影响,需要更密集的“过程级”奖励来指导搜索。
- 核心思路:
- 将问题拆解为多步解答,每步解答都用 PRM 来打分(即对当前解答步骤的“合理性”/“正确性”进行二分类或多分类),分数越高表示这一步走得更正确。
- 利用搜索(如 Beam Search、Lookahead Search),在每一步都根据 PRM 分数筛选或扩展最优路径。
- 为什么可行:
- 对于复杂推理而言,最终答案的对错并不足以指导整条推理链;过程中若走偏,最后一刻才给奖励会导致搜索开销大。
- 过程奖励可以让我们“剪枝”掉错误或不靠谱的中间步骤,缩小大规模搜索空间。
- 进一步细分:
- Beam Search + PRM:每个搜索层保留 top-k 条高分 partial 解答再往下展开,直到抵达终止。
- Lookahead Search:在当前步先 rollout k 步,得到未来 k 步的价值,再用该价值回传到当前节点决定扩展方向。
- OmegaPRM:针对如何自动化给每一步打标注的效率改进(如二分搜索找“首个错误步”)等。
- 举个例子:数学题共 5 步推理,每一步都可并行采样 3 个子分支,然后用 PRM 打分,保留得分最高的若干条分支继续生成,最后在所有完整路径中再选出分数最高的一条做输出。
子解法 C:多轮 Revision / Self-Improve(自修正)
- 对应特征:同一个模型在推理阶段就能自我质疑、修正错误,逐轮迭代地提高输出质量;或借助外部提示来修改回答。
- 核心思路:
- 先生成一个初步答案 (y₁),如果判定不够好,就把 (x, y₁) 作为新的输入上下文,再次调用模型生成修正后的答案 y₂;
- 这一修正过程可以多次叠加,每一轮都基于前一轮回答中暴露的错误信息来 refine。
- 若配合训练(如 SFT 或 PPO)让模型学会“如何读懂自身错误并改进”,则称为 Self-Improve (或 self-correction)。
- 为什么可行:
- 二次以上回答使得模型可以显式或隐式地“改变输入分布”,减少重复错误;
- 在一定程度上模拟了人类做题时的“回看、反思、再改写”的流程。
- 进一步细分:
- Sequential Revision:先顺序产生多轮回答 y₁ → y₂ → … → yₖ,每一轮都依赖上一轮答案。
- Parallel + Iterative:可并行产生多条解答链,各链再进行多轮自修正,然后用 Verifier 选最优结果。
- Self-Critique / CriticGPT:将“批评角色”与“生成角色”在对话里拆分,由批评者显式标注错误原因,生成者再修正。
- 举个例子:如果第一次回答漏考虑某个约束条件,模型在第二轮就可以从“第一轮答案+提示错误点”出发,做针对性改写。
子解法 D:MCTS / AlphaZero-like 思路(结合自对弈 / RL 训练)
- 对应特征:借鉴 AlphaGo、AlphaZero 这种“搜索 + 神经网络”范式,模型既可在训练时用自我博弈(Self-Play)不断迭代变强,也可在推理时先使用蒙特卡洛树搜索(MCTS)来决定最优路径。
- 核心思路:
- 将问题的多步推理视为一棵树,状态为“已生成的部分答案”,动作为“继续生成的下一步解答”。
- 借助 MCTS 的“多次模拟 + 价值回溯 + 策略更新”找到高价值路径。
- 在训练期间,模型策略网络(Policy)与价值网络(Value 或 PRM)互相促进;在推理阶段则执行若干次树搜索来提升精确度。
- 为什么可行:
- MCTS 在复杂决策空间里能有效探索,并避免局部贪心;
- 过程奖励或价值网络可以像 AlphaGo-Zero 一样提供“当前状态的胜率估计”,从而有效扩展优质节点。
- 进一步细分:
- AlphaGo 式:先基于外部示例(相当于人类棋谱)做初步监督,再在搜索中逐渐优化;
- AlphaZero 式:纯自对弈起家,多轮迭代增强;
- rSTaR / OpenR:实际工程实现中往往需要减少动作空间(比如只在“step”级别进行搜索,而非“token”级别)。
- 举个例子:给定一个推理任务可以走 5 步;每步可以选 3 种思路(动作)。MCTS 反复模拟→ 回溯更新每个节点的价值 → 最终选出在搜索树中综合价值最高的整条推理路径。这种自对弈式数据还可继续拿来做 RL 训练,让策略网络更“懂”如何选对分支。
- 子解法之间的逻辑链条与结构
整体上,这四类子解法更像一个“网络”式的选择树,而不只是单线的链式流程。
- 子解法 A(纯增加并行采样 + 最终挑选)是最直观、最容易上手的做法;
- 子解法 B(PRM + 搜索)实际上可以接在子解法 A 之后,用更精细的过程级验证来剪枝不良路径;
- 子解法 C(多轮 Revision)则可与 A、B 并行或结合,即既能在每一轮生成中多样采样,也能对每一步做 PRM 评估,并在不满意时再回到模型进行“修正扩展”;
- 子解法 D(MCTS / AlphaZero-like)则可视为在子解法 B 的搜索思路上,进一步引入 RL 和自对弈来迭代强化模型本身。
- 分析是否有隐性方法(关键步骤没有直接被命名,但在解法中扮演重要角色)
在以上所有子解法中,往往会出现一些**“并未在文献标题或常规名词”中直接出现,但确实起重要作用的做法**。
这里列举几个常见的“隐性方法”:
-
动态 Prompt 改写
- 在子解法 C(Self-Improve)中,第二轮生成时并不仅仅是简单地“在旧回答后再写一句”。往往我们会对 Prompt 进行更有针对性的改写,如明确提示上一轮错误原因或让模型自我思考应该如何修正。这种提示工程(Prompt Engineering)往往是隐含的。
-
Answer Aggregation 策略
- 当 N 条答案相似度很高时,如何合并成一个最终答案?可能会用“加权投票”或“只要大多数一致就选这一项”之类,这些聚合步骤在论文中常常是一两句话带过,但对实际应用很重要。
-
解码加速手段
- 大规模并行的 Best-of-N、Beam Search、或 MCTS 都对推理速度有额外开销。实际落地时,可能会用到像 Speculative Decoding、分块 KV-Cache 复用、或者 VLLM 等库来加速大批量解码。很多时候这些工程手段在论文里并未详述,但在大规模部署中至关重要。
-
过程标签的自动化生成
- 比如 Math-Shepherd / OmegaPRM 中,利用蒙特卡洛 Rollout 或二分搜索去估计每一步正确率,这些自动标注步骤(用不同配置的并行采样)往往非常繁琐,但在文章中却被一两句概括为“自动得到 step-by-step label”。这是一个典型“隐形方法”。
- 分析是否有隐性特征(不在问题或条件中,而是解题中间才显露)
许多“特征”只有在对推理链进行观察、或在搜索过程中看到某些现象时才会被我们意识到:
-
推理难度分级
- “题目难度”其实并非题面直接告诉我们,而是通过大量采样发现:LLM 对某些问题 100 次采样都无法答对,才推断这是模型所定义的“难题”。这可被视为一个“隐性特征”:它并不写在问题描述里,而是通过多次试错才显露。
-
路径一致性
- 在过程奖励模型 (PRM) 的多步验证里,如果第 k 步就出现了明显矛盾,后续步骤也大概率出错。这在搜索空间中是“隐性剪枝特征”:不在明面条件(比如题目)出现,却在生成过程中发现“已矛盾应终止扩展”。
-
PRM/ORM 对输入的敏感性
- 有时同一道问题,不同形式的提示(例如额外的解释文本、不同格式的中间步骤)会显著改变 PRM/ORM 的打分。这些差异并非题目本身的显式设定,而是推理中间过程对模型分数产生的“隐性影响”。
-
方法可能存在哪些潜在局限性
-
计算/资源开销大
- Best-of-N、Beam Search、MCTS 都会增加推理时的 Token 级生成量。一旦 N 或搜索深度很大,推理延迟和 GPU 算力都会成倍增加。
-
收益递减
- 对特别难的任务,纯粹堆叠推理算力(子解法 A 或 B)也未必能显著提升准确率;若模型本身 Reasoning 能力不足,再多采样也可能都错。
-
标注或验证器质量
- 如果使用 PRM,需要训练过程级奖励模型;但过程级别标注本就十分昂贵或难以自动化(虽然有 Math-Shepherd/OmegaPRM 等技巧,也依旧很耗时)。标注质量不足,会导致 PRM 无法准确筛选。
-
Prompt 稳定性
- 自修正 (Self-Improve) 强烈依赖模型对自己错误的“觉察力”,有时可能出现“越改越糟”或再次重复同类错误的情况。Prompt 稍微改写,可能导致答案完全变动。
-
策略空间过大
- MCTS/AlphaZero-like 方法如果直接在 token 级展开,会面临天文数字的分支,必须要做降维或动作空间离散化,否则搜索难以进行。
综上所述,“Scaling LLM Test Time + 搜索式推理 + 自修正 + RL 训练”构成了一个大的“多路并行”网络解法,不同子解法之间可以组合、互补或为对方提供数据和反馈。
- 子解法 A(纯多样采样 + 验证)最易上手,但在复杂推理上潜力有限;
- 子解法 B(PRM + 多种搜索)可更精准筛选,但需要过程奖励建模;
- 子解法 C(Revision / Self-Improve)提高了模型在推理阶段的动态纠错能力;
- 子解法 D(MCTS / AlphaZero)将以上方法进一步放大,允许训练和推理的搜索循环结合,构造自对弈式迭代进化。
在实际应用中,我们往往会综合这些思路,并辅以必要的“隐性方法”(如 Prompt 改写、解码加速、自动标注等),来根据任务的规模与难度做取舍。
每种方法也都伴随着相应限制,主要集中在算力、标注和搜索空间规模这三大方面。
o1 医疗:树搜索、医疗数据蒸馏
DeepSeek-R1 医疗数据蒸馏
论文:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning

DeepSeek-R1 所谓“慢系统”,本质是让模型自然写出超长推理链 (因为 RL 回合数够多,Reward 主要看最终对错+格式),相当于一种纯后验策略:一边生成 COT,一边计算结果能不能通过,让模型在训练中逐渐形成了“先多想一会再回答”的习惯。
过程里会自然涌现出非常长的 CoT、reflection、检测错误等高级推理特征。
其训练方式不依赖过程级别奖励 PRM,也不做 MCTS + Value 的自我搜索(上文方法)。
现在开源的模型,都是那么大的参数。提取数据,将医疗的数据保留,其他参数不需要,它就是一个医疗 R1 参数更小,更专。
现在都流行“数据蒸馏”,训练的话,对数据集要求很高。
算力要求:推理要2台机、96g 8卡、一天3千左右,硬件成本。
如果是树搜索,不用这么多算力,但数据要求高。
各种 o1 方法对比


- 训练思路与适配度
- DeepSeek-R1 与 HuatuoGPT-o1 均属于“让模型直接学习多步推理链”的思路,前者靠大规模 Outcome-based RL,后者靠“生成正确思路+Verifier”的多阶段监督与RL。
- Baichuan-M1-14B 强调的是“多阶段数据+ELO/TDPO/PPO”全流程优化,通过分段式的训练与对齐,从语言通识到医学进阶,层层递进并注重思维链优化,是更“系统化”的多步推理实现。
- O1 Replication 偏向“推理时增强”,适合直接拿已有较强模型做少量改动,快速提升答案质量;若底层模型弱,就收效有限。
- MCTS+过程价值 理想最优,但几乎没有大规模工业化先例,且对医疗数据、搜索框架、实时评估等要求过高。
- 数据需求与实现难度
- DeepSeek-R1 最依赖大规模、可自动判对错的数据,且需要庞大算力来支撑RL反复训练。
- HuatuoGPT-o1 与 Baichuan-M1-14B 均在可控规模的医疗数据上即可(几万~十万量级),但需保证数据或偏序对(preference pairs)质量、训练流程成熟。
- O1 Replication 在训练上几乎“零改动”,但基础模型需要先有足够的医疗知识。
- MCTS+过程价值 在定义过程Reward与搭建搜索系统上,难度极高。
- 推理性能与可解释性
- DeepSeek-R1 若训练充分,推理性能可极高;但需要保证自动判分“对错”足够准确。
- HuatuoGPT-o1 已在多项医疗基准测试中表现不俗,一次生成的长链思路也易于解释;在真实诊断场景中有一定可行性。
- Baichuan-M1-14B 通过多阶段的思维链优化与偏好对齐,兼顾推理的连贯性和用户偏好;在通用与医疗场景都有较好表现,且仅 14B 参数就能体现较强效果,推理效率和可解释性兼具。
- O1 Replication 多次抽样投票虽能提升准确率,但推理时开销上升,长思路的合理性也要看底层模型能力。
- MCTS+过程价值 理论上可最优且过程可解释,但在医疗复杂度和实现难度面前,尚难大规模落地。
PRM:医疗 step-by-step 数据标注怎么做?
方案一:
openai 先从模型里采集 step-by-step 级别的数据,再对每个step进行标注二分类 {正确 1, 错误 0}标注;
采样技巧,让模型先 step-by-step 输出一条正确的路径(Q,S1,S2,S3,S4,A},每个步骤标注label为1(正确),那么再逐步采集错误的答案Q;
S1 -> S2(错误)
Q S1 S2 -> S'3 (错误)
Q S1 S2 S3 -> S'4 (错误)
0 S1 S2 S3 S4 -> A'(错误)
另外这个错误step也可以人工来写,成本更高。
医疗决策常常不是简单二元对错,可以考虑引入“安全性”“有效性”“合规性”等多个维度的标签,以帮助模型更精细地学到「合规问诊」。
方案二:
DeepMind 是这样想的,你遇到的选择都是大差不差的路径,一个路径正确概率 51%,另一个正确概率 49%,你要一直选择概率最高那个。
能够判断棋盘上大致的胜率,每走出若干步之后,如果这个代理认为对于胜率有所提升,那么就说明这个方向是对的。
Alpha Go的训练程序其实很难判断单一一步的胜率变化,但是能够判断若干步累计下来的整体变化,然后它再反过来给每一步走法一个反馈。
把大模型的输出过程拆成多步(step by step);
针对每一个步的输出,都估计一个“如果当前这一步做对了,对最终答案(或最终目标)有多大助益”的价值,即“局部价值”或“到达最终正确答复的剩余价值”;
把“每一步的价值”拿来当作训练或指导模型改进的信号,类似强化学习中的“收益估计”(Value Function)。
先用模型生成多条「解题步骤」(Rollout),并统计这些步骤序列里正确答案的比例,从而给某个具体 step打一个“正确率”或“价值估计”;
用这个每步的正确率或价值估计,来做 PRM (Policy/Reward Model) 的训练,指导模型下次更好地输出正确的下一步。
就是“从当前步骤起往后看,最终能得到正确解(或好结果)的概率”或者“剩余收益”,所以不同步骤可能对应不同的 reward 值。
将这一套思路转到医疗问诊场景,核心逻辑不会变,只是:
- 每一步输出 就是“问诊对话”中的下一段回复,比如给病人一个进一步的问题、一个解释、或者一个检查建议;
- reward-to-go 变成 “从当前这一步开始,如果对了/合理了,对后续诊断或治疗方案成功率有多大提升”;
- 在实际实现中,你需要大量的多条对话「rollout」来判断“这个回复是否合理、会不会导致最终误诊/正确诊断?”。
- 例如可以先设一个「地面真实病情(模拟) + 答案」作为正确目标,模型从当前对话继续延伸多种可能的问诊路径,看看每条分支最终能不能正确诊断或合理用药;
- 若其中 2/3 的对话路径都能走到正确诊断,就给当前这一步一个 2/3 的分数,这就是“step reward”。
不过在医疗场景里,“正确率”评估往往远比数学题复杂:
- 需要临床知识、病情模拟、对长期结果的判断;
- 有时中途一个不恰当的问题或诊断就会影响后续判断,甚至造成严重后果。
所以如果真要做“基于 step 的自动标注”,往往还得有一个相对靠谱的“模拟环境”或“自动评估器”来判断“这一整条对话是否导致正确诊断/治疗”,而不是光靠最后一问一答对不对就能衡量。
基本概念:前向 vs. 后向
-
前向(Forward)PRM
- 核心:在做第 (k) 步决策(或输出)时,仅使用「前面的上下文(问题 + 前几步)」来判断该步是否“合理/正确”。
- 代表:OpenAI 早期在 ChatGPT 监督/奖励模型中多采用此思路;一旦当前步或回答看上去是合理的,就会得到更高分。
-
后向(Backward)PRM
- 核心:在做第 (k) 步决策时,考虑「如果这一步这样输出,会不会导致后续最终答案正确/成功?」换言之,用“到达最终正确答案的概率”来衡量当前步的价值。
- 代表:Alpha Go 思路,往往通过多条后续 Rollout 来计算这一步对最终结果的贡献度(正确率、成功率等)。
实施思路比较
-
前向 PRM
- 实现:对每个 step,结合已知信息(题目 Q、已生成 S1, S2, …, S{k-1}),用一个判别器/奖励模型来判断“当前输出 S{k} 的质量”。
- 训练数据:往往是“已知正确或高质量”的对话/解题步骤 vs. “错误或质量差”的步骤。人工或自动标注时,主要看本步表达是否逻辑通顺、有错误知识点、不符合医疗规范等。
- 优点:
- 评估流程简单,只需要看当前步骤与前面上下文是否匹配/合理。
- 标注和计算都相对直接,不必进行大量后续推理就能给出一份评分。
- 局限:
- 有时一个看似“正确”或“无害”的局部决策,可能会在后续导致错误;前向 PRM 未必能捕捉到这种“延迟影响”。
- 不适合那些最终答案才是唯一评价指标的复杂场景(如数学题的最后答案正确与否、医疗问诊是否给出安全诊断)。
-
后向 PRM
- 实现:在第 (k) 步输出后,继续 Rollout 或模拟后续所有步骤,看最终答案/结果是否正确,然后据此给第 (k) 步一个“导致最终成功的概率”作为奖励。
- 训练数据:通过完整的多步推理过程(例如 S1, S2, …, SN => A),统计最终正确率或成功率,再将这份统计值“分摊”或“归因”到每个 step 的贡献。
- 优点:
- 能够捕捉真正“对结果有贡献”的步骤。如果一个 step 大幅提高后续成功率,就能获得高分;相反则得低分。
- 更适合目标导向、可明确判定成功/失败的任务(解题正确性、医疗诊断是否到达安全有效的结论等)。
- 局限:
- 计算开销大:要进行多次后续推理/模拟,才能知道这一步对最终结果的影响。
- 标注或自动评估更复杂:在医疗场景下,后续走向往往包含极多不确定性,且需要专业知识来判断整个问诊是否“最终正确”。
计算与标注成本
-
前向:
- 标注/评估:人工或自动判定“这一步”本身是否合理即可;做一次评分就行。
- 成本:标注量相对小,但对「远期影响」衡量不足,需要额外策略(如在后续步骤再做矫正)。
-
后向:
- 标注/评估:必须展开后续完整推理(或多路 Rollout)才知道结局;可能对每步都要跑若干次对话/推理路径。
- 成本:计算量与人工审阅量显著增大,尤其当后续步骤很多、场景复杂(如医疗问诊)。
- 优点:可以一次性获取“全局贡献度”,在强化学习或生成式任务中往往更精准。
应用到「医疗问诊」时的对比
-
前向 PRM 在医疗问诊中的使用
- 典型做法:对模型当前给出的诊断建议/询问内容,判断是否逻辑清晰、无明显知识错误、安全合规(如不建议危险药物、不违反医疗法规等)。
- 优点:符合医疗场景的逐步评审逻辑,可以快速筛除显而易见的错误或违规信息。
- 缺点:并不能完全保证最终诊断就正确;有时当前对话看似正确,但其实在更长链路后暴露问题。
-
后向 PRM 在医疗问诊中的使用
- 需要给定完整的“问诊—诊断—治疗”流程,并评估是否成功(正确诊断/安全用药)。
- 优点:更好地评估「对最终医疗结论的贡献」,因为医疗中最终正确诊断/治疗结果才是核心指标。
- 缺点:需要大规模模拟(或者有真实临床数据)来确定某个中间问诊步骤是否对成功诊疗真的有帮助。标注也需要专家反复评估,耗时且昂贵。
典型场景与适用性
-
前向 PRM
- 更适合:回答质量、对话礼貌性、局部逻辑检查等“就地”判断即可的任务;
- 典型例子:OpenAI 可能会用它来控制对话内容的安全合规、无歧视性、不涉及隐私等。
-
后向 PRM
- 更适合:需要“全局成功/正确”来定义奖励的复杂任务,比如多步数学推理、医疗诊断、策略规划等;
- 典型例子:Math-Shepherd 通过后向看最终答案是否正确给 step 打分,或者强化学习中 Agent 要达到终点才算成功。
结论与建议
- 两种 PRM 并非互斥,可以结合使用。例如:
- 先用「前向 PRM」筛除明显错误/不合理的中间步骤;
- 再用「后向 PRM」进行更深层次的全局优化(比如对已筛过的候选进行多条后续推理,计算最终成功率)。
- 在医疗问诊中:
- 单纯前向判断或单纯后向判断都可能有偏颇;
- 理想情况是又能实时判断“每一步是否存在重大安全风险”,又能评估“最终确诊率/治疗成功率”。
- 做到这一点通常需要更加复杂的多维度标签或自定义评估流程(安全性、合规性、诊断准确性等多项指标共同评分)。
简而言之,前向 PRM更偏向「即时、局部」判断,易操作但难以保证全局最优;后向 PRM更贴近「真正目标」(最终正确与否),但实现门槛和成本高。
假设我们有一个虚构的患者“小王”,他在问诊中向医生(或医疗助手系统)描述了自己的症状、经历等信息;系统需要逐步进行推理,排查可能的诊断或建议下一步检查。
示例对话:
【患者】我最近一直感觉胸闷、气短,已经持续两周了。偶尔还有心慌的感觉。
【医生助理(系统)】好的,让我先了解一下您的基本情况……
(后续若干轮对话,包含多个“推理步骤”)
在这个对话背后,如果我们想对“每一步医疗推理或分析”进行准确性判定,就需要类似 PRM (Process Reward Model) 的方法,给每个步骤打上“正确/错误/不确定”的标签,或者用数值评分,帮助系统学习何时给出恰当的问诊思路、检查建议等。
为什么需要“step-by-step 标注”?
- 医疗对话的推理链往往很长: 从询问症状(如胸闷、头痛)、既往病史、家族史,到可能的诊断假设,再到进一步检查或治疗方案,每一步都可能出现疏漏或失误。
- 仅用“最终诊断是否正确”难以快速定位问题: 如果系统在开头步骤就问错了问题或忽略了关键病史,到最后才给一个“错误结论”,那只依赖最终结果的奖励(ORM)难以及时给出反馈。
- 过程监督 (step-by-step) 能提供更密集、更及时的反馈信号: 系统哪一步问诊思路正确,哪一步有误,都可以被标记出来,为后续搜索或训练提供更细粒度的指引。
核心思路:将对话过程拆分为“推理步骤”并标注
在对话式医疗问诊中,“步骤 (step)”通常对应系统针对患者信息给出的一个分析或操作,例如:
- 询问某个重要的症状或体征;
- 根据病人已有症状推断某一可能诊断方向;
- 决定下一步进行哪项检查/化验;
- 判断是否需要紧急处理或会诊等等。
我们可以在模型生成的文字中,用特殊的分隔符(如 \n 或“【Step X】”)来划分每个思路/结论,然后对这些步骤进行逐个判断和标注。
如何进行“非人工”的自动标注?
当缺少充分的专业人工标注时,可以考虑借助某些“自动化”的方法来近似完成标注,类似于在数学推理任务中所做的“rollout + 检验”方式。思路如下:
-
准备一个参考标准或工具:
- 在医疗场景,可能包含:
- 医疗知识库 / 临床指南检索器;
- 专业医疗辅助决策系统;
- 或者由更高级别的验证模型(Expert Model) 来对每个推理步骤的合理性打分。
- 这里就好比“在数学题里用正确答案或蒙特卡洛采样的方式估计每个步骤的正确性”。
- 在医疗场景,可能包含:
-
对同一个“问诊场景”做多次采样 (Best-of-N) / 多条对话路径:
- 为了估计“某一步诊断思路或检查建议是否合理”,可以让系统针对同样的病人信息,多次生成或“rollout”相同位置的步骤,并查看下游是否能够得到“正确倾向”(如更合理的诊断结论);在数学里对应“若后续求解可得正确答案,则该步骤倾向正确”。
- 在医疗场景可以对应“若该思路后续检验、证据符合临床指南,或者最终与专家诊断一致,则可判断这一步思路较好”。
-
计算“胜率”或“正确率”来打分:
- 如果某个“第 k 步”推理在 10 条不同后续推理分支里,有 7 条最终与专家判定相符,可为此步骤打一个 0.7 的得分;若只有 2 条正确,则得 0.2。
- 这样,就能为每一个中间步骤,自动估计“是否正确”。
- 注意:在医疗领域中,这种自动化方法必须非常谨慎,胜率仅是对模型自身的统计估计,仍会有偏差;若有条件,最好结合专业审核或更准确的外部验证机制。
-
前向建模 vs. 后向建模:
- 前向建模:只基于当前上下文和当前步骤本身的医学合理性来打分(“这一步问得对不对?”“此时给的治疗建议违不违法则?”等)。
- 后向建模:看该步骤往后若干轮在最终诊断/管理决策上的表现;如果后续都能收敛到正确诊断,则该步骤被判为正向,否则负向或较低分数。
PRM(Process Reward Model)在医疗场景的建模示例
- 数据形式:
- 将整个问诊对话拆分成多个段落(Step),如下示例(仅演示):
问诊对话示例: [Patient] 最近两周持续胸闷气短…… --- [System] Step1: 询问是否有胸痛、咳嗽等伴随症状 [System] Step2: 推测患者可能存在心血管或呼吸系统问题 [System] Step3: 建议先做心电图和胸部X线检查 [System] Step4: 如有心悸明显,考虑心脏超声排查心功能问题 [System] Step5: 最终判断或建议 ...
- 将整个问诊对话拆分成多个段落(Step),如下示例(仅演示):
- 标注:
- 对于
[System] Step1到[System] Step5的输出,每一步都匹配一个“正确/错误”标签,或者用数值分数表示。 - 标注可以来自:
- 人工专家:临床医生检查每一步询问或推测是否合规;
- 自动化(rollout):重复生成多次,若后续走向了正确诊断方向,认为该步骤是正确的概率更高;若大多错误,则认为此处偏离常识。
- 标注格式示例:
[System] Step1: 询问是否有胸痛、咳嗽等伴随症状 -> label: 1 (合理的问诊方向) [System] Step2: 推测心血管或呼吸系统问题 -> label: 1 (大概率恰当的临床思路) [System] Step3: 建议先做心电图、胸部X线 -> label: 1 (常规且合理的检查) [System] Step4: 建议检查其他部位(荒谬的检查) -> label: 0 (这一步可能明显不合逻辑) [System] Step5: … -> label: …
- 对于
- 训练:
- 和数学/代码类 PRM 相似,让一个语言模型(或分类器)去学习:“给定之前所有对话内容 + 当前步骤文本”,输出该步骤是否正确或合理的概率分布。
- 使用交叉熵损失(或其他分类损失)进行训练。
小结与注意事项
-
可行但需谨慎:
- 在医疗场景中,纯粹用模型自身的多路采样或语言学回溯来自动判定“医疗是否正确”存在隐患。医学往往需要专业人士把关。
- 如果能引入专业知识库或专家规则,再配合少量人工审阅,自动标注过程会更可靠。
-
step-by-step 标注的价值:
- 提供更密集的奖励信号,使系统能更快识别“在哪一步出错”。
- 对后续的搜索算法 (如 Beam Search / MCTS) 或训练过程 (如 PPO) 更友好,能及时终止明显错误的分支。
-
“前向”还是“后向”评估:
- 医学中经常需要根据后续结果(包括后续检查、专家结论)来反证某一步是否正确,因此后向评估非常常见;
- 但若能结合前向的医学常识检查,如“是否违背基本诊疗原则、有没有忽视重要危险信号”等,也可大大减少对后续完整结局的依赖。
以上就是将 step-by-step 奖励标注 (PRM) 的通用思路,迁移到“医疗问诊”场景下的大致做法。最关键的一点在于,每一个推理步骤都要有相对清晰的衡量标准(人工或自动),这样才能在模型训练或推理时,通过对局部错误的早期发现来提高整体对话质量。
再次声明:本示例仅为技术说明,不代表任何真实临床指引,医疗最终决策应交由专业医生进行。
相关文章:
如何复现o1模型,打造医疗 o1?
如何复现o1模型,打造医疗 o1? o1 树搜索一、起点:预训练规模触顶与「推理阶段(Test-Time)扩展」的动机二、Test-Time 扩展的核心思路与常见手段1. Proposer & Verifier 统一视角方法1:纯 Inference Sca…...

PostgreSQL TRUNCATE TABLE 操作详解
PostgreSQL TRUNCATE TABLE 操作详解 引言 在数据库管理中,经常需要对表进行操作以保持数据的有效性和一致性。TRUNCATE TABLE 是 PostgreSQL 中一种高效删除表内所有记录的方法。本文将详细探讨 PostgreSQL 中 TRUNCATE TABLE 的使用方法、性能优势以及注意事项。 什么是 …...

【JavaWeb06】Tomcat基础入门:架构理解与基本配置指南
文章目录 🌍一. WEB 开发❄️1. 介绍 ❄️2. BS 与 CS 开发介绍 ❄️3. JavaWeb 服务软件 🌍二. Tomcat❄️1. Tomcat 下载和安装 ❄️2. Tomcat 启动 ❄️3. Tomcat 启动故障排除 ❄️4. Tomcat 服务中部署 WEB 应用 ❄️5. 浏览器访问 Web 服务过程详…...

【NOI】C++程序结构入门之循环结构三-计数求和
文章目录 前言一、计数求和1.导入2.计数器3.累加器 二、例题讲解问题:1741 - 求出1~n中满足条件的数的个数和总和?问题:1002. 编程求解123...n问题:1004. 编程求1 * 2 * 3*...*n问题:1014. 编程求11/21/3...1/n问题&am…...

[Linux]Shell脚本中以指定用户运行命令
前言 当我们为Linux设置了用户自启动的shel脚本,默认会使用root用户执行启动脚本中的命令,那么我们如何在启动脚本中切换为指定用户指定命令呢。 命令 以下将列出两条命令,两条命令都可以实现以指定用户运行命令,凭喜好选择使用…...

通过 NAudio 控制电脑操作系统音量
根据您的需求,以下是通过 NAudio 获取和控制电脑操作系统音量的方法: 一、获取和控制系统音量 (一)获取系统音量和静音状态 您可以使用 NAudio.CoreAudioApi.MMDeviceEnumerator 来获取系统默认音频设备的音量和静音状态&#…...

新项目上传gitlab
Git global setup git config --global user.name “FUFANGYU” git config --global user.email “fyfucnic.cn” Create a new repository git clone gitgit.dev.arp.cn:casDs/sawrd.git cd sawrd touch README.md git add README.md git commit -m “add README” git push…...

【异步编程基础】FutureTask基本原理与异步阻塞问题
文章目录 一、FutureTask 的桥梁作用二、Future 模式与异步回调三、 FutureTask获取异步结果的逻辑1. 获取异步执行结果的步骤2. 举例说明3. FutureTask的异步阻塞问题 Runnable 用于定义无返回值的任务,而 Callable 用于定义有返回值的任务。然而,Calla…...

原生 Node 开发 Web 服务器
一、创建基本的 HTTP 服务器 使用 http 模块创建 Web 服务器 const http require("http");// 创建服务器const server http.createServer((req, res) > {// 设置响应头res.writeHead(200, { "Content-Type": "text/plain" });// 发送响应…...
—— 1.两数之和)
LeetCode热题100(一)—— 1.两数之和
LeetCode热题100(一)—— 1.两数之和 题目描述代码实现思路解析 你好,我是杨十一,一名热爱健身的程序员在Coding的征程中,不断探索与成长LeetCode热题100——刷题记录(不定期更新) 此系列文章用…...

二叉树高频题目——下——不含树型dp
一,普通二叉树上寻找两个节点的最近的公共祖先 1,介绍 LCA(Lowest Common Ancestor,最近公共祖先)是二叉树中经常讨论的一个问题。给定二叉树中的两个节点,它的LCA是指这两个节点的最低(最深&…...

vue事件总线(原理、优缺点)
目录 一、原理二、使用方法三、优缺点优点缺点 四、使用注意事项具体代码参考: 一、原理 在Vue中,事件总线(Event Bus)是一种可实现任意组件间通信的通信方式。 要实现这个功能必须满足两点要求: (1&#…...

PyCharm介绍
PyCharm的官网是https://www.jetbrains.com/pycharm/。 以下是在PyCharm官网下载和安装软件的步骤: 下载步骤 打开浏览器,访问PyCharm的官网https://www.jetbrains.com/pycharm/。在官网首页,点击“Download”按钮进入下载页面。选择适合自…...

《CPython Internals》读后感
一、 为什么选择这本书? Python 是本人工作中最常用的开发语言,为了加深对 Python 的理解,更好的掌握 Python 这门语言,所以想对 Python 解释器有所了解,看看是怎么使用C语言来实现Python的,以期达到对 Py…...

音频入门(一):音频基础知识与分类的基本流程
音频信号和图像信号在做分类时的基本流程类似,区别就在于预处理部分存在不同;本文简单介绍了下音频处理的方法,以及利用深度学习模型分类的基本流程。 目录 一、音频信号简介 1. 什么是音频信号 2. 音频信号长什么样 二、音频的深度学习分…...
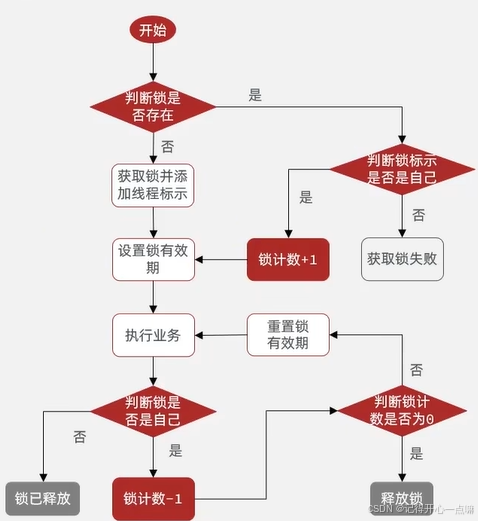
Redis --- 分布式锁的使用
我们在上篇博客高并发处理 --- 超卖问题一人一单解决方案讲述了两种锁解决业务的使用方法,但是这样不能让锁跨JVM也就是跨进程去使用,只能适用在单体项目中如下图: 为了解决这种场景,我们就需要用一个锁监视器对全部集群进行监视…...

用C++编写一个2048的小游戏
以下是一个简单的2048游戏的实现。这个实现使用了控制台输入和输出,适合在终端或命令行环境中运行。 2048游戏的实现 1.游戏逻辑 2048游戏的核心逻辑包括: • 初始化一个4x4的网格。 • 随机生成2或4。 • 处理玩家的移动操作(上、下、左、…...

【设计模式-行为型】状态模式
一、什么是状态模式 什么是状态模式呢,这里我举一个例子来说明,在自动挡汽车中,挡位的切换是根据驾驶条件(如车速、油门踏板位置、刹车状态等)自动完成的。这种自动切换挡位的过程可以很好地用状态模式来描述。状态模式…...

CentOS/Linux Python 2.7 离线安装 Requests 库解决离线安装问题。
root@mwcollector1 externalscripts]# cat /etc/os-release NAME=“Kylin Linux Advanced Server” VERSION=“V10 (Sword)” ID=“kylin” VERSION_ID=“V10” PRETTY_NAME=“Kylin Linux Advanced Server V10 (Sword)” ANSI_COLOR=“0;31” 这是我系统的版本,由于是公司内网…...

【flutter版本升级】【Nativeshell适配】nativeshell需要做哪些更改
flutter 从3.13.9 升级:3.27.2 nativeshell组合库中的 1、nativeshell_build库替换为github上的最新代码 可以解决两个问题: 一个是arg("--ExtraFrontEndOptions--no-sound-null-safety") 在新版flutter中这个构建参数不支持了导致的build错误…...

使用 Vue 3 的 watchEffect 和 watch 进行响应式监视
Vue 3 的 Composition API 引入了 <script setup> 语法,这是一种更简洁、更直观的方式来编写组件逻辑。结合 watchEffect 和 watch,我们可以轻松地监视响应式数据的变化。本文将介绍如何使用 <script setup> 语法结合 watchEffect 和 watch&…...

使用shell命令安装virtualbox的虚拟机并导出到vagrant的Box
0. 安装virtualbox and vagrant [rootolx79vagrant ~]# cat /etc/resolv.conf #search 114.114.114.114 nameserver 180.76.76.76-- install VirtualBox yum install oraclelinux-developer-release-* wget https://yum.oracle.com/RPM-GPG-KEY-oracle-ol7 -O /etc/pki/rpm-g…...
:排序查询和条件查询)
MySQL 基础学习(3):排序查询和条件查询
MySQL 查询与条件操作:详解与技巧 在本文中,我们将探讨 MySQL 中的查询操作及其相关功能,包括别名、去重、排序查询和条件查询等,并总结一些最佳实践和注意事项。 一、使用别名(AS) 在查询中,…...

2025数学建模美赛|赛题翻译|E题
2025数学建模美赛,E题赛题翻译 更多美赛内容持续更新中......

solidity高阶 -- 继承
Solidity是一种面向区块链的智能合约编程语言,广泛应用于以太坊等区块链平台。继承是Solidity中一个非常重要的特性,它允许开发者通过创建子合约来扩展父合约的功能,从而实现代码的复用和层次化设计。本文将通过具体实例详细介绍Solidity语言…...

SpringBoot统一数据返回格式 统一异常处理
统一数据返回格式 & 统一异常处理 1. 统一数据返回格式1.1 快速入门1.2 存在问题1.3 案列代码修改1.4 优点 2. 统一异常处理 1. 统一数据返回格式 强制登录案例中,我们共做了两部分⼯作 通过Session来判断⽤⼾是否登录对后端返回数据进⾏封装,告知前端处理的结果 回顾 后…...

C语言学习强化
前言 数据的逻辑结构包括: 常见数据结构: 线性结构:数组、链表、队列、栈 树形结构:树、堆 图形结构:图 一、链表 链表是物理位置不连续,逻辑位置连续 链表的特点: 1.链表没有固定的长度…...

反馈驱动、上下文学习、多语言检索增强等 | Big Model Weekly 第55期
点击蓝字 关注我们 AI TIME欢迎每一位AI爱好者的加入! 01 A Bayesian Approach to Harnessing the Power of LLMs in Authorship Attribution 传统方法严重依赖手动特征,无法捕捉长距离相关性,限制了其有效性。最近的研究利用预训练语言模型的…...

Redis 详解
简介 Redis 的全称是 Remote Dictionary Server,它是一个基于内存的 NoSQL(非关系型)数据库,数据以 键值对 存储,支持各种复杂的数据结构 为什么会出现 Redis? Redis 的出现是为了弥补传统数据库在高性能…...

git reset (取消暂存,保留工作区修改)
出现这种情况的背景:我不小心把node_modules文件添加到暂存区了,由于文件过大,导致不能提交,所以我想恢复之前的状态,但又不想把修改的代码恢复为之前的状态,所以使用这个命令可以只恢复暂存区的状态&#…...