强化学习数学原理(三)——值迭代
一、值迭代过程
上面是贝尔曼最优公式,之前我们说过,f(v)=v,贝尔曼公式是满足contraction mapping theorem的,能够求解除它最优的策略和最优的state value,我们需要通过一个最优v*,这个v*来计算状态pi*,而vk通过迭代,就可以求出唯一的这个v*,而这个算法就叫做值迭代。V(s)是状态s的最优价值,R是在状态s时执行动作a可获得的,y是折扣因子(衰减系数),还有状态概率矩阵P
1.1 初始化状态价值函数
我们说过,这个函数有两个未知量。v与pi,因此要计算最优策略,我们就需要先假设一个初始值。选择一个初始值先来表示每个状态的价值。假设我们就可以设置所有价值V(s)都为0
1.2 迭代更新价值函数
使用贝尔曼最优方程更新状态价值函数,对于与每个状态s,计算改状态下所有可能的动作a下的期望值,然后选择最大值作为新的状态价值函数。Vk是第k次迭代时s的状态,他会更新为k+1,直到k+1是最优时刻为止,具体的更新公式为:
这上面就包含了所说了两个步骤
第一步 ploicy update:
第二部 value update:
每次更新一个pik+1之后代入,就可以得到迭代后的vk+1,但是这里有个点,迭代过程中,左侧他是vk+1,所以他并不是我们所说的state value,他是一个值,
1.2.1 Ploicy update
我们把上面的公式具体的拆成每个状态对应的element,得到
vk是已知的(假设了v0,假设现在就是v0,求pi1),那么qk(s,a) (q1)是已知的,最优策略,就会选取qk最大时的action,其他行动为0,这样就只与q(s,a)相关,那么pik+1就知道了,就是pik+1(s)最大的一个
1.2.2 Value update
对于其elementwise form
按照迭代顺序写出每一个值,从1.2.1,我们就可以知道,qk(s,a)是能求出的,注意一点,策略迭代里面,求出了最大的value对应的state,那么我们就知道这个pik+1,求出最后的结果
1.3 判断收敛性
每次迭代后,检查状态价值函数的变化。如果状态价值变化小于某个阈值(例如 ϵ\epsilonϵ),则认为收敛,可以终止迭代。常见的收敛条件是:
通常 是一个小的正数,用于表示精度要求。如果状态价值函数的变化足够小,算法收敛。
根据例子,给出一个python代码
import numpy as np# 初始化参数
gamma = 0.9 # 折扣因子
epsilon = 1e-6 # 收敛阈值
max_iterations = 1000 # 最大迭代次数
S = 4 # 状态空间大小
A = 5 # 动作空间大小# 转移概率矩阵 P(s'|s, a) - 4x5x4 的三维矩阵
P = np.zeros((S, A, S))## 顺时针行动
# 奖励函数 R(s, a) - 4x5 的矩阵
R = np.array([[-1, 4, -1, -1, -1],[-1, 4, -1, -1, -1],[4, -1, -1, -1, -1],[-1, -1, -1, -1, 1]])# 转移概率矩阵
# 动作 a=1
P[:, 0, :] = np.array([[0.8, 0.1, 0.1, 0],[0.1, 0.8, 0.1, 0],[0.2, 0.2, 0.6, 0],[0, 0, 0, 1]])# 动作 a=2
P[:, 1, :] = np.array([[0.6, 0.3, 0.1, 0],[0.1, 0.7, 0.2, 0],[0.3, 0.3, 0.4, 0],[0, 0, 0, 1]])# 动作 a=3
P[:, 2, :] = np.array([[0.7, 0.2, 0.1, 0],[0.1, 0.8, 0.1, 0],[0.2, 0.2, 0.6, 0],[0, 0, 0, 1]])# 动作 a=4
P[:, 3, :] = np.array([[0.5, 0.4, 0.1, 0],[0.2, 0.7, 0.1, 0],[0.4, 0.4, 0.2, 0],[0, 0, 0, 1]])# 动作 a=5
P[:, 4, :] = np.array([[0.9, 0.05, 0.05, 0],[0.05, 0.9, 0.05, 0],[0.1, 0.1, 0.8, 0],[0, 0, 0, 1]])# 初始化状态价值函数 V(s)
V = np.zeros(S)# 记录最优策略
pi = np.zeros(S, dtype=int)# 值迭代算法
for k in range(max_iterations):V_new = np.zeros(S)delta = 0 # 最大值变化# 遍历每个状态for s in range(S):# 对每个动作计算期望回报value = -float('inf') # 当前最大回报(初始化为负无穷)for a in range(A):# 计算该动作下的期望回报expected_return = R[s, a] + gamma * np.sum(P[s, a, :] * V)value = max(value, expected_return) # 保持最大的期望回报# 更新当前状态的价值V_new[s] = valuedelta = max(delta, abs(V_new[s] - V[s])) # 计算状态价值的变化# 更新状态价值V = V_new# 如果变化小于 epsilon,认为收敛if delta < epsilon:break# 根据最优状态价值函数计算最优策略
for s in range(S):max_value = -float('inf')best_action = -1for a in range(A):# 计算每个动作下的期望回报expected_return = R[s, a] + gamma * np.sum(P[s, a, :] * V)if expected_return > max_value:max_value = expected_returnbest_action = api[s] = best_action# 输出结果
print("最优状态价值函数 V*(s):")
print(V)print("最优策略 pi*(s):")
print(pi)
MATLAB实现:
% 初始化参数
gamma = 0.9; % 折扣因子
epsilon = 1e-6; % 收敛阈值
max_iterations = 1000; % 最大迭代次数
S = 4; % 状态空间大小
A = 5; % 动作空间大小% 转移概率矩阵 P(s'|s, a) - 4x5x4 的三维矩阵
P = zeros(S, A, S);% 奖励函数 R(s, a) - 4x5 的矩阵
R = [-1, 4, -1, -1, -1;-1, 4, -1, -1, -1;4, -1, -1, -1, -1;-1, -1, -1, -1, 1];% 转移概率矩阵
% 动作 a=1
P(:, 1, :) = [0.8, 0.1, 0.1, 0; 0.1, 0.8, 0.1, 0; 0.2, 0.2, 0.6, 0; 0, 0, 0, 1];% 动作 a=2
P(:, 2, :) = [0.6, 0.3, 0.1, 0;0.1, 0.7, 0.2, 0;0.3, 0.3, 0.4, 0;0, 0, 0, 1];% 动作 a=3
P(:, 3, :) = [0.7, 0.2, 0.1, 0;0.1, 0.8, 0.1, 0;0.2, 0.2, 0.6, 0;0, 0, 0, 1];% 动作 a=4
P(:, 4, :) = [0.5, 0.4, 0.1, 0;0.2, 0.7, 0.1, 0;0.4, 0.4, 0.2, 0;0, 0, 0, 1];% 动作 a=5
P(:, 5, :) = [0.9, 0.05, 0.05, 0;0.05, 0.9, 0.05, 0;0.1, 0.1, 0.8, 0;0, 0, 0, 1];% 初始化状态价值函数 V(s)
V = zeros(S, 1);% 记录最优策略
pi = zeros(S, 1);% 值迭代算法
for k = 1:max_iterationsV_new = zeros(S, 1);delta = 0; % 最大值变化% 遍历每个状态for s = 1:S% 对每个动作计算期望回报value = -Inf; % 当前最大回报(初始化为负无穷)for a = 1:A% 计算该动作下的期望回报expected_return = R(s, a) + gamma * sum(squeeze(P(s, a, :)) .* V);value = max(value, expected_return); % 保持最大的期望回报end% 更新当前状态的价值V_new(s) = value;delta = max(delta, abs(V_new(s) - V(s))); % 计算状态价值的变化end% 更新状态价值V = V_new;% 如果变化小于 epsilon,认为收敛if delta < epsilonbreak;end
end% 根据最优状态价值函数计算最优策略
for s = 1:Smax_value = -Inf;best_action = -1;for a = 1:A% 计算每个动作下的期望回报expected_return = R(s, a) + gamma * sum(squeeze(P(s, a, :)) .* V');if expected_return > max_valuemax_value = expected_return;best_action = a;endendpi(s) = best_action;
end% 输出结果
disp('最优状态价值函数 V*(s):');
disp(V);disp('最优策略 pi*(s):');
disp(pi);
修改奖励与衰减系数可得到不同V

相关文章:
强化学习数学原理(三)——值迭代
一、值迭代过程 上面是贝尔曼最优公式,之前我们说过,f(v)v,贝尔曼公式是满足contraction mapping theorem的,能够求解除它最优的策略和最优的state value,我们需要通过一个最优v*,这个v*来计算状态pi*&…...

探索人工智能在计算机视觉领域的创新应用与挑战
一、引言 1.1 研究背景与意义 在科技飞速发展的当下,人工智能(Artificial Intelligence, AI)已然成为引领新一轮科技革命和产业变革的重要驱动力。作为 AI 领域的关键分支,计算机视觉(Computer Vision, CV࿰…...
:利用图神经网络进行图分类)
动手学图神经网络(4):利用图神经网络进行图分类
利用图神经网络进行图分类:从理论到实践 引言 在之前的学习中,大家了解了如何使用图神经网络(GNNs)进行节点分类。本次教程将深入探讨如何运用 GNNs 解决图分类问题。图分类是指在给定一个图数据集的情况下,根据图的一些结构属性对整个图进行分类,而不是对图中的节点进…...
转html的解决方案)
关于java实现word(docx、doc)转html的解决方案
最近在研究一些关于文档转换格式的方法,因为需要用在开发的一个项目上,所以投入了一些时间,给大家聊下这块逻辑及解决方案。 一、关于word转换html大致都有哪些方法? (1)使用 Microsoft Word 导出 其实该…...

Padas进行MongoDB数据库CRUD
在数据处理的领域,MongoDB作为一款NoSQL数据库,以其灵活的文档存储结构和高扩展性广泛应用于大规模数据处理场景。Pandas作为Python的核心数据处理库,能够高效处理结构化数据。在MongoDB中,数据以JSON格式存储,这与Pandas的DataFrame结构可以很方便地互相转换。通过这篇教…...

DeepSeek-R1:强化学习驱动的推理模型
1月20日晚,DeepSeek正式发布了全新的推理模型DeepSeek-R1,引起了人工智能领域的广泛关注。该模型在数学、代码生成等高复杂度任务上表现出色,性能对标OpenAI的o1正式版。同时,DeepSeek宣布将DeepSeek-R1以及相关技术报告全面开源。…...

scratch变魔术 2024年12月scratch三级真题 中国电子学会 图形化编程 scratch三级真题和答案解析
目录 scratch变魔术 一、题目要求 1、准备工作 2、功能实现 二、案例分析 1、角色分析 2、背景分析 3、前期准备 三、解题思路 1、思路分析 2、详细过程 四、程序编写 五、考点分析 六、 推荐资料 1、入门基础 2、蓝桥杯比赛 3、考级资料 4、视频课程 5、py…...

信息学奥赛一本通 2110:【例5.1】素数环
【题目链接】 ybt 2110:【例5.1】素数环 【题目考点】 1. 深搜回溯 2. 质数 【解题思路】 1~n的数字构成一个环,要求相邻数字加和必须是质数。 该题最终输出的是一个序列,只不过逻辑上序列最后一个数字的下一个数字就是序列的第一个数字…...

MyBatis框架基础学习及入门案例(2)
目录 一、数据库建表(tb_user)以及添加数据。 (1)数据库与数据表说明。 (2)字段与数据说明。 二、创建模块(或工程)、导入对应所需依赖坐标。 三、编写MyBatis核心主配置文件。(解决JDBC中"硬编码"问题) (1&…...
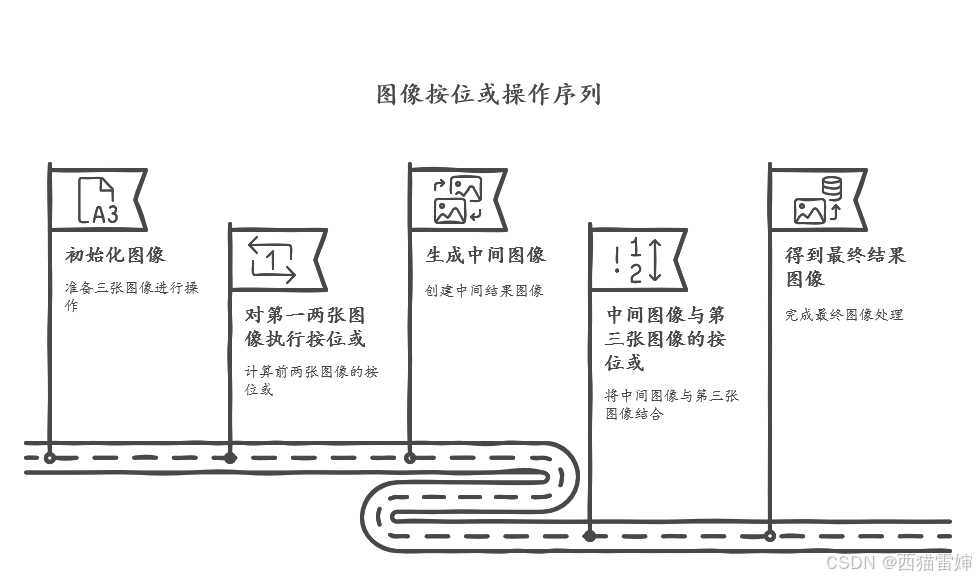
python学opencv|读取图像(四十六)使用cv2.bitwise_or()函数实现图像按位或运算
【0】基础定义 按位与运算:全1取1,其余取0。按位或运算:全0取0,其余取1。 【1】引言 前序学习进程中,已经对图像按位与计算进行了详细探究,相关文章链接如下: python学opencv|读取图像&…...

蓝桥杯省一
四个月从c,cpp,算法一起学到省一(考研原因没参加国赛) 有疑问可以关注私信哦 帖子后续也会持续更新,分享算法竞赛(ccpc,天梯赛,蓝桥杯,浙大pta)相关知识...

【ProxyBroker】用Python打破网络限制的利器
ProxyBroker 1. 什么是ProxyBroker2. ProxyBroker的功能3. ProxyBroker的优势4. ProxyBroker的使用方法5. ProxyBroker的应用场景6.结语项目地址: 1. 什么是ProxyBroker ProxyBroker是一个开源工具,它可以异步地从多个来源找到公共代理,并同…...

C++ 新特性实现 ThreadPool
序言 在之前我们实现过线程池,但是非常基础。答题思路就是实现一个安全的队列,再通过 ThreadPool 来管理队列和线程,对外提供一个接口放入需要执行的函数,但是这个函数是无参无返回值的。 参数的问题我们可以使用 bind 来封装&a…...
【数据结构】_以SLTPushBack(尾插)为例理解单链表的二级指针传参
目录 1. 第一版代码 2. 第二版代码 3. 第三版代码 前文已介绍无头单向不循环链表的实现,详见下文: 【数据结构】_不带头非循环单向链表-CSDN博客 但对于部分方法如尾插、头插、任意位置前插入、任意位置前删除的相关实现,其形参均采用了…...

本地Harbor仓库搭建流程
Harbor仓库搭建流程 本文主要介绍如何搭建harbor仓库,推送本地镜像供其他机器拉取构建服务 harbor文档:Harbor 文档 | 配置 Harbor YML 文件 - Harbor 中文 github下载离线安装包 Releases goharbor/harbor 这是harbor的GitHub下载地址,…...

Android vendor.img中文件执行权问题
问题 Android 9、11往vendor.img增加文件,烧写到设备后发现增加的可执行文件没有执行权限。经过漫长查找,终于找到了问题的根源,谨以此篇献给哪些脚踏实地的人们。 根本原因 system/core/libcutils/fs_config.cpp文件,fs_confi…...

环境搭建--vscode
vscode官网下载合适版本 安装vscode插件 安装 MinGW 配置环境变量 把安装目录D:\mingw64 配置在用户的环境变量path里即可 选择用户环境变量path 点确定保存后开启cmd输入g,如提示no input files 则说明Mingw64 安装成功,如果提示g 不是内…...

30289_SC65XX功能机MMI开发笔记(ums9117)
建立窗口步骤: 引入图片资源 放入图片 然后跑make pprj new job8 可能会有bug,宏定义 还会有开关灯报错,看命令行注释掉 接着把ture改成false 然后命令行new一遍,编译一遍没报错后 把编译器的win文件删掉, 再跑一遍虚拟机命令行…...
IDEA工具下载、配置和Tomcat配置
1. IDEA工具下载、配置 1.1. IDEA工具下载 1.1.1. 下载方式一 官方地址下载 1.1.2. 下载方式二 官方地址下载:https://www.jetbrains.com/idea/ 1.1.3. 注册账户 官网地址:https://account.jetbrains.com/login 1.1.4. JetBrains官方账号注册…...

【10.2】队列-设计循环队列
一、题目 设计你的循环队列实现。 循环队列是一种线性数据结构,其操作表现基于 FIFO(先进先出)原则并且队尾被连接在队首之后以形成一个循环。它也被称为“环形缓冲器”。 循环队列的一个好处是我们可以利用这个队列之前用过的空间。在一个普…...

多人-多agent协同可能会挑战维纳的反馈
在多人-多Agent协同系统中,维纳的经典反馈机制将面临新的挑战,而协同过程中的“算计”(策略性决策与协调)成为实现高效协作的核心。 1、非线性与动态性 维纳的反馈理论(尤其是在控制理论中)通常假设系统的动…...
)
JS 时间格式大全(含大量示例)
在 JS 中,处理时间和日期是常见的需求。无论是展示当前时间、格式化日期字符串,还是进行时间计算,JavaScript 都提供了丰富的 API 来满足这些需求。本文将详细介绍如何使用 JavaScript 生成各种时间格式,从基础到高级,…...

HarmonyOS简介:应用开发的机遇、挑战和趋势
问题 更多的智能设备并没有带来更好的全场景体验 连接步骤复杂数据难以互通生态无法共享能力难以协同 主要挑战 针对不同设备上的不同操作系统,重复开发,维护多套版本 多种语言栈,对人员技能要求高 多种开发框架,不同的编程…...
)
区间选点(贪心)
给定 NN 个闭区间 [ai,bi][ai,bi],请你在数轴上选择尽量少的点,使得每个区间内至少包含一个选出的点。 输出选择的点的最小数量。 位于区间端点上的点也算作区间内。 输入格式 第一行包含整数 NN,表示区间数。 接下来 NN 行,…...

深度学习|表示学习|卷积神经网络|输出维度公式|15
如是我闻: 在卷积和池化操作中,计算输出维度的公式是关键,它们分别可以帮助我们计算卷积操作和池化操作后的输出大小。下面分别总结公式,并结合解释它们的意义: 1. 卷积操作的输出维度公式 当我们对输入图像进行卷积时…...
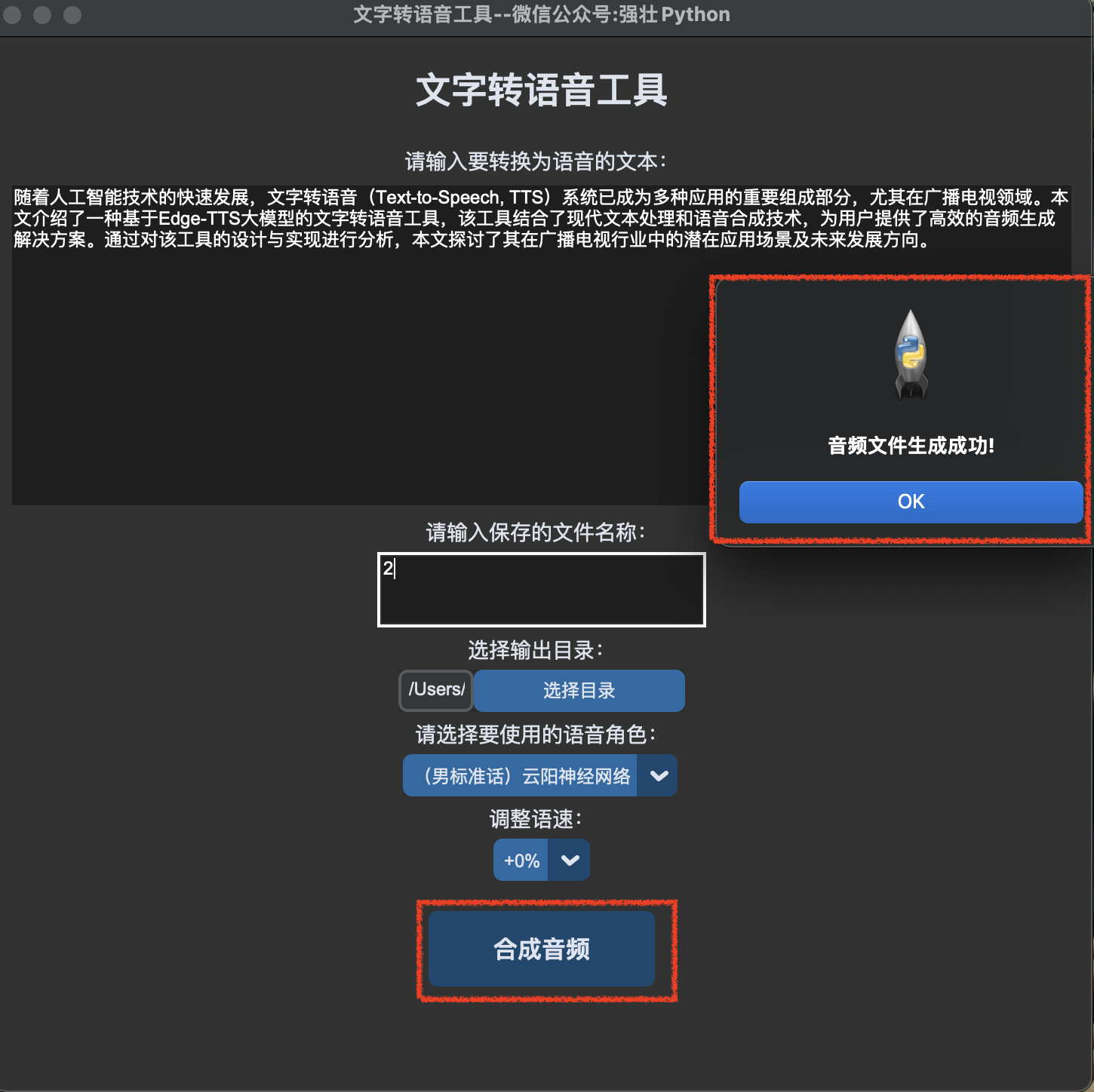
Edge-TTS在广电系统中的语音合成技术的创新应用
Edge-TTS在广电系统中的语音合成技术的创新应用 作者:本人是一名县级融媒体中心的工程师,多年来一直坚持学习、提升自己。喜欢Python编程、人工智能、网络安全等多领域的技术。 摘要 随着人工智能技术的快速发展,文字转语音(Te…...

2025课题推荐——USBL与DVL数据融合的实时定位系统
准确的定位技术是现代海洋探测、海洋工程和水下机器人操作的基础。超短基线(USBL)和多普勒速度计(DVL)是常用的水下定位技术,但单一技术难以应对复杂环境。因此,USBL与DVL的数据融合以构建实时定位系统&…...

RK3588平台开发系列讲解(ARM篇)ARM64底层中断处理
文章目录 一、异常级别二、异常分类2.1、同步异常2.2、异步异常三、中断向量表沉淀、分享、成长,让自己和他人都能有所收获!😄 一、异常级别 ARM64处理器确实定义了4个异常级别(Exception Levels, EL),分别是EL0到EL3。这些级别用于管理处理器的特权级别和权限,级别越高…...

MyBatis最佳实践:提升数据库交互效率的秘密武器
第一章:框架的概述: MyBatis 框架的概述: MyBatis 是一个优秀的基于 Java 的持久框架,内部对 JDBC 做了封装,使开发者只需要关注 SQL 语句,而不关注 JDBC 的代码,使开发变得更加的简单MyBatis 通…...
Three.js实战项目02:vue3+three.js实现汽车展厅项目
文章目录 实战项目02项目预览项目创建初始化项目模型加载与展厅灯光加载汽车模型设置灯光材质设置完整项目下载实战项目02 项目预览 完整项目效果: 项目创建 创建项目: pnpm create vue安装包: pnpm add three@0.153.0 pnpm add gsap初始化项目 修改App.js代码&#x…...