手撕Diffusion系列 - 第十一期 - lora微调 - 基于Stable Diffusion(代码)
手撕Diffusion系列 - 第十一期 - lora微调 - 基于Stable Diffusion(代码)
目录
- 手撕Diffusion系列 - 第十一期 - lora微调 - 基于Stable Diffusion(代码)
- Stable Diffusion 原理图
- Stable Diffusion的原理解释
- Stable Diffusion 和Diffusion 的Unet对比
- Lora 微调原理
- Stable Diffusion 添加lora微调代码
- Part1 添加lora.py文件 - 用于设置lora层以及替换
- 1. 引入相关库函数
- 2. 定义LoraLayer的类
- 3. lora层的替换
- Part2 添加lora_finetune.py,用于参数微调训练得到lora参数.pt文件
- 1. 引入相关库函数
- 2. 替换模型中的注意力机制里面的Wq, Wk, Wv,替换线性层
- Part3 修改 denoise.py,修改测试的时候的lora参数加入
- 1. 引入相关库函数
- 2. 定义去噪的函数
- 3. 测试-去噪
- 参考
Stable Diffusion 原理图
Stable Diffusion的原理解释
Stable Diffusion的网络结构图如下图所示:

- 改动1:利用 AE,VAE,VQVAE 等自编码器,进行了图像特征提取,利用正确提取特征后的图像作为自己原本在Diffusion中的图像。
- 改动2:在训练过程中,额外添加了一些引导信息,促使图像生成,往我们所希望的方向去走,这里添加信息的方式主要是利用交叉注意力机制(这里我看图应该是只用交叉注意力就行,但是我看视频博主用的代码以及参照的Stable-Diffusion Unet图上都是利用的Transoformer的编码器,也就是得到注意力值之后还得进行一个feedforward层)。
- **改动3:**利用 AE,VAE,VQVAE 等自编码器进行解码。(这个实质上和第一点是重复的)
- **注意:**本次的代码改动先只改动第二个,也就是添加引导信息,对于编码器用于减少计算量,本次改进先不参与(555~,因为视频博主没教),后续可能会进行添加(因为也比较简单)。
Stable Diffusion 和Diffusion 的Unet对比


- 我们可以发现,两者之间的区别主要在于,在卷积完了之后添加了一个Transformer的模块,也就是其编码器将两个信息进行了融合,其他并没有改变。
- 所以主要区别在卷积后的那一部分,如下图。

- 这个ResnetBlock就是之前的卷积模块,作为右边的残差部分,所以这里写成 了ResnetBlock。
- 因此,如果我们将Tranformer模块融入到Restnet模块里面,并且保持其输入卷积的图像和transformer输出的图像形状一致的话,那么就其他部分完全不需要改变了,只不过里面多添加了一些引导信息(MNIST数据集中是label,但是也可以添加文本等等引导信息) 而已。
Lora 微调原理
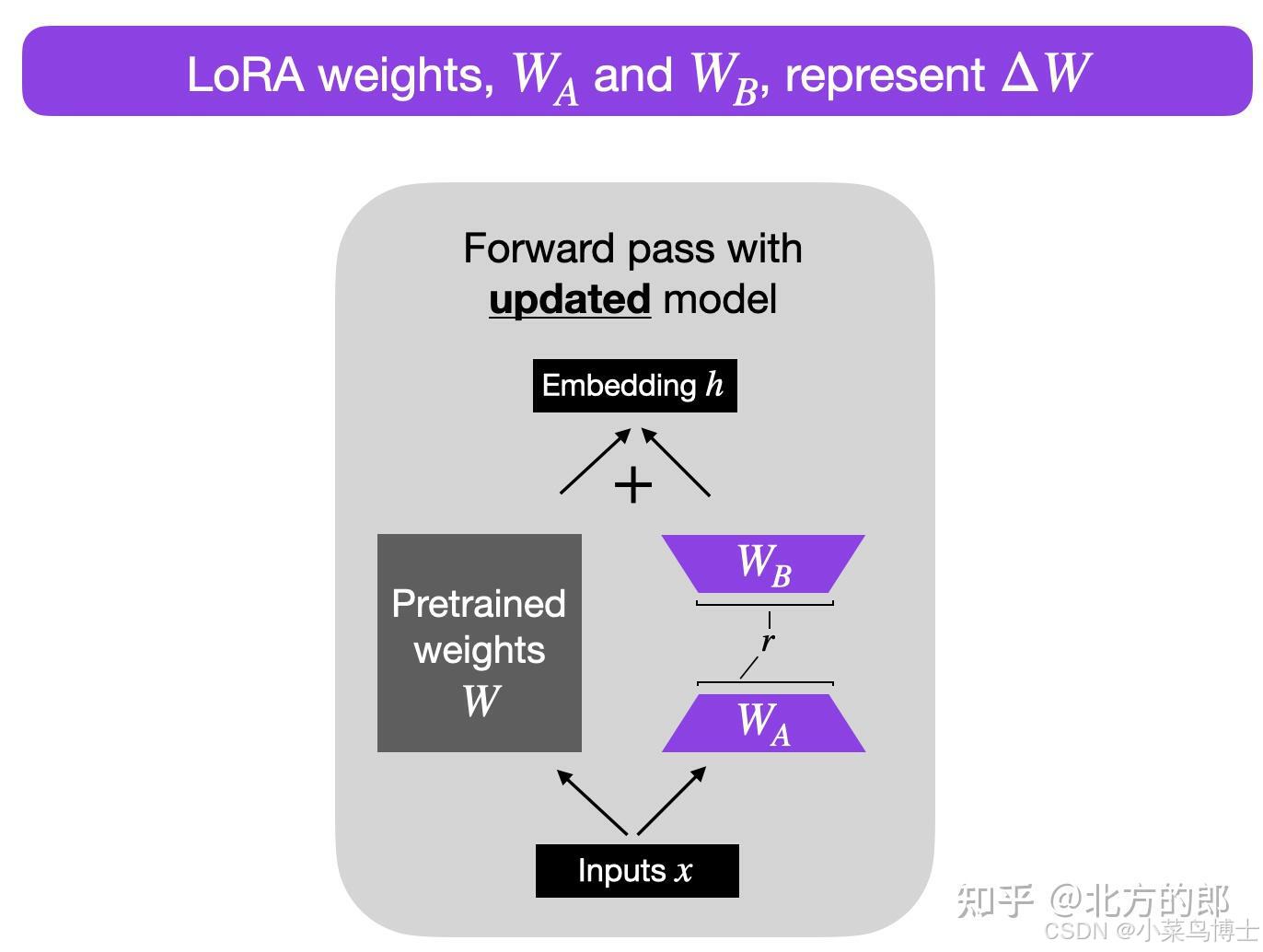
- LoRA算法

- 算法过程:对于原先的参数不改变,通过右边添加一个参数矩阵来进行微调,也就是利用新的参数矩阵来微调拟合新领域的参数和初始参数的差距。也就是ΔW。
理论:预训练大型语言模型在适应新任务时具有较低的“内在维度” , 所以当对于一个预训练模型来说,原先的参数是有非常多的冗余的,因此我们可以利用低维空间(也就是降维)去表示目标参数和原先参数之间的距离。因此ΔW是相对W来说维度非常小的,减少了非常多的参数量。
-
因为要保证输入和输出的维度和原本的参数W一样,所以一般参数输入的维度还是相同的,但是中间的维度小很多,从而达到减少参数量的结果。比如原本是100x100的参数量,现在变为100x5(r)x2,减少了10倍。
- 其中r就是低秩的那个秩数。可以自定义。
o u t p u t = n e t ( x ) + t o r c h . m a t m u l ( x , t o r c h . m a t m u l ( l o r a a , l o r a b ) ∗ a l p h a ( 可能这里也会除以 r ) output=net(x)+torch.matmul(x,torch.matmul(lora_a,lora_b)*alpha(可能这里也会除以r) output=net(x)+torch.matmul(x,torch.matmul(loraa,lorab)∗alpha(可能这里也会除以r)
alpha或者alpha/r 是一个缩放因子,用于调整组合结果(原始模型输出加上低秩自适应)的大小。这平衡了预训练模型的知识和新的特定于任务的适应——默认情况下,alpha通常设置为 1。另请注意,虽然W A被初始化为小的随机权重,但WB被初始化为 0,因此训练开始时ΔW = WAxWB = 0 ,这意味着我们以原始权重开始训练。
Stable Diffusion 添加lora微调代码
Part1 添加lora.py文件 - 用于设置lora层以及替换
1. 引入相关库函数
# 该模块主要是实现lora类,实现lora层的alpha和beta通路,把输入的x经过两条通路后的结果,进行联合输出。
# 然后添加一个函数,主要是为了实现将原本的线性层换曾lora层。'''
# Part1 引入相关的库函数
'''
import torch
from torch import nn
from config import *
2. 定义LoraLayer的类
'''
# Part2 设计一个类,实现lora_layer
'''class LoraLayer(nn.Module):def __init__(self, target_linear_layer, feature_in, feature_out, r, alpha):super().__init__()# 第一步,初始化lora的一些参数,包含a矩阵,b矩阵,r秩.比例系数等等。self.lora_a = nn.Parameter(torch.empty(feature_in, r), requires_grad=True)self.lora_b = nn.Parameter(torch.zeros(r, feature_out), requires_grad=True)self.alpha = alphaself.r = r# 第二步对alpha进行初始化nn.init.kaiming_uniform_(self.lora_a)# 第三步,初始化原本的目标线性层self.net = target_linear_layerdef forward(self, x):output1 = self.net(x)output2 = torch.matmul(x, torch.matmul(self.lora_a, self.lora_b)) * (self.alpha / self.r) # 得到结果后,乘上比例系数(alpha/r)return output2 + output1
3. lora层的替换
'''
# Part3 定义一个函数,实现lora层的替换
'''def inject_lora(module, name, target_linear_layer): # 输入完整的模型,目标线性层的位置,目标线性层name_list = name.split('.') # 按照.进行拆分路径# 获取到目标线性层的模型的上一层所有参数和模型{模型name1:模型,模型name2:模型}for i, item in enumerate(name_list[:-1]):module = getattr(module, item)# 初始化需要替换进入的lora层lora_layer = LoraLayer(target_linear_layer,feature_in=target_linear_layer.in_features, feature_out=target_linear_layer.out_features,r=LORA_R, alpha=LORA_ALPHA)# 替换对应的层setattr(module, name_list[-1], lora_layer)
Part2 添加lora_finetune.py,用于参数微调训练得到lora参数.pt文件
1. 引入相关库函数
# 该模块主要实现对于模型的一些模块进行微调训练,只对lora里面的新增参数进行训练。
'''
# Part 1 引入相关的库函数
'''
import osimport torch
from torch import nn
from dataset import minist_train
from torch.utils import data
from diffusion import forward_diffusion
from config import *
from unet import Unet
from lora import inject_lora
2. 替换模型中的注意力机制里面的Wq, Wk, Wv,替换线性层
if __name__ =='__main__':'''# Part2 对需要训练的模型参数进行设置,将需要替换的线性层进行lora替换,并且只对lora进行训练'''# 首先第一步得先下载网络net = torch.load('unet_epoch0.pt')# 开始对所需的部分进行替换。# 首先,我们要对线性层进行lora替换,所以需要,输入inject_lora的参数包含(整个模型,路径,layer)for name, layer in net.named_modules():name_list = name.split('.')target = ['Wq', 'Wk', 'Wv']for i in target:if i in name_list and isinstance(layer, nn.Linear):# 替换inject_lora(net, name, layer)# 替换完之后,先看看需不需要添加之前的参数try:# 先下载参数lora_para=torch.load('lora_para_epoch0.pt')# 再填充到模型里面net.load_state_dict(lora_para,strict=False)except:pass# 替换完之后,需要对所有的参数进行设置,不是lora的参数梯度设置为Falsefor name, para in net.named_parameters():name_list = name.split('.')lora_para_list = ['lora_a', 'lora_b']if name_list[-1] in lora_para_list:para.requires_grad = Falseelse:para.requires_grad = True'''# Part3 进行训练'''epoch = 5batch_size = 50minist_loader = data.DataLoader(dataset=minist_train, batch_size=batch_size, shuffle=True)# 初始化模型loss = nn.L1Loss()opt = torch.optim.Adam(net.parameters(), lr=1e-3)n_iter = 0net.train()for i in range(epoch):for imgs, labels in minist_loader:imgs = imgs * 2 - 1# 先随机初始化batch_tbatch_t = torch.randint(0, T, size=(imgs.size()[0],))# 首先对清晰图像进行加噪,得到batch_x_tbatch_x_t, batch_noise = forward_diffusion(imgs, batch_t)# 预测对应的噪声batch_noise_pre = net(batch_x_t, batch_t, labels)# 计算损失l = loss(batch_noise, batch_noise_pre)# 清除梯度opt.zero_grad()# 损失反向传播l.backward()# 更新参数opt.step()# 累加损失last_loss = l.item()# 更新迭代次数n_iter += 1print('当前的iter为{},当前损失为{}'.format(n_iter, last_loss))print('当前的epoch为{},当前的损失为{}'.format(i, last_loss))# 保存训练好的lora参数,但是得先找到lora_dic = {}# 遍历net的参数for name, para in net.named_parameters():name_list = name.split('.')need_find = ['lora_a', 'lora_b']# 如果最后一个名字在需要找的参数里面if name_list[-1] in need_find:# 在存储的字典里面添加参数和名字lora_dic[name] = para# 先存储为临时文件torch.save(lora_dic, 'lora_para_epoch{}.pt.tmp'.format(i))# 然后改变路径,形成最终的参数(主要是为了防止写入出错)os.replace('lora_para_epoch{}.pt.tmp'.format(i), 'lora_para_epoch{}.pt'.format(i))
Part3 修改 denoise.py,修改测试的时候的lora参数加入
1. 引入相关库函数
# 该模块主要实现的是对图像进行去噪的测试。
'''
# 首先第一步,引入相关的库函数
'''import torch
from torch import nn
from config import *
from diffusion import alpha_t, alpha_bar
from dataset import *
import matplotlib.pyplot as plt
from diffusion import forward_diffusion
from lora import inject_lora
from lora import LoraLayer
2. 定义去噪的函数
'''
# 第二步定义一个去噪的函数
'''def backward_denoise(net, batch_x_t, batch_labels):# 首先计算所需要的数据,方差variance,也就公式里面的beta_talpha_bar_late = torch.cat((torch.tensor([1.0]), alpha_bar[:-1]), dim=0)variance = (1 - alpha_t) * (1 - alpha_bar_late) / (1 - alpha_bar)# 得到方差后,开始去噪net.eval() # 开启测试模式# 记录每次得到的图像steps = [batch_x_t]for t in range(T - 1, -1, -1):# 初始化当前每张图像对应的时间状态batch_t = torch.full(size=(batch_x_t.size()[0],), fill_value=t) # 表示此时的时间状态 (batch,)# 预测噪声# 修改第十四处batch_noise_pre = net(batch_x_t, batch_t, batch_labels) # (batch,channel,iamg,imag)# 开始去噪(需要注意一个点,就是去噪的公式,在t不等于0和等于0是不一样的,先进行都需要处理部分也就是添加噪声前面的均值部分)# 同时记得要统一维度,便于广播reshape_size = (batch_t.size()[0], 1, 1, 1)# 先取出对应的数值alpha_t_batch = alpha_t[batch_t]alpha_bar_batch = alpha_bar[batch_t]variance_batch = variance[batch_t]# 计算前面的均值batch_mean_t = 1 / torch.sqrt(alpha_t_batch).reshape(*reshape_size) \* (batch_x_t - (1 - alpha_t_batch.reshape(*reshape_size)) * batch_noise_pre / torch.sqrt(1 - alpha_bar_batch.reshape(*reshape_size)))# 分类,看t的值,判断是否添加噪声if t != 0:batch_x_t = batch_mean_t \+ torch.sqrt(variance_batch.reshape(*reshape_size)) \* torch.randn_like(batch_x_t)else:batch_x_t = batch_mean_t# 对每次得到的结果进行上下限的限制batch_x_t = torch.clamp(batch_x_t, min=-1, max=1)# 添加每步的去噪结果steps.append(batch_x_t)return steps
3. 测试-去噪
# 开始测试
if __name__ == '__main__':# 加载模型model = torch.load('unet_epoch0.pt')model.eval()is_lora = Trueis_hebing = False# 如果是利用lora,需要把微调的也加进去模型进行推理if is_lora:for name, layer in model.named_modules():name_list = name.split('.')target_list = ['Wk', 'Wv', 'Wq']for i in target_list:if i in name_list and isinstance(layer, nn.Linear):inject_lora(model, name, layer)# 加载权重参数try:para_load = torch.load('lora_para_epoch0.pt')model.load_state_dict(para_load, strict=False)except:pass# 如果需要合并,也就是把lora参数添加到原本的线性层上面的话,也就是把插入重新实现一遍,这次是把lora_layer换成linear。if is_lora and is_hebing:for name, layer in model:name_list = name.split('.')if isinstance(layer, LoraLayer):# 找到了对应的参数,把对应的lora参数添加到原本的参数上# 为什么要确定参数位置的上一层,因为setattr只能在上一层用,不能层层进入属性。cur_layer=modelfor n in name_list[:-1]:cur_layer=getattr(cur_layer,n)# 首先计算lora参数lora_weight = torch.matmul(layer.lora_a, layer.lora_b) * layer.alpha / layer.r# 把参数进行添加,线性层的权重矩阵通常是 (out_features, in_features),所以需要对lora矩阵进行转置layer.net.weight = nn.Parameter(layer.net.weight.add(lora_weight.T))setattr(cur_layer, name_list[-1], layer)# 生成噪音图batch_size = 10batch_x_t = torch.randn(size=(batch_size, 1, IMAGE_SIZE, IMAGE_SIZE)) # (5,1,48,48)batch_labels = torch.arange(start=0, end=10, dtype=torch.long) # 引导词promot# 逐步去噪得到原图# 修改第十五处steps = backward_denoise(model, batch_x_t, batch_labels)# 绘制数量num_imgs = 20# 绘制还原过程plt.figure(figsize=(15, 15))for b in range(batch_size):for i in range(0, num_imgs):idx = int(T / num_imgs) * (i + 1)# 像素值还原到[0,1]final_img = (steps[idx][b] + 1) / 2# tensor转回PIL图final_img = TenosrtoPil_action(final_img)plt.subplot(batch_size, num_imgs, b * num_imgs + i + 1)plt.imshow(final_img)plt.show()
参考
视频讲解:Lora微调代码实现_哔哩哔哩_bilibili
原理博客:手撕Diffusion系列 - 第九期 - 改进为Stable Diffusion(原理介绍)-CSDN博客,自学资料 - LoRA - 低秩微调技术-CSDN博客
相关文章:
手撕Diffusion系列 - 第十一期 - lora微调 - 基于Stable Diffusion(代码)
手撕Diffusion系列 - 第十一期 - lora微调 - 基于Stable Diffusion(代码) 目录 手撕Diffusion系列 - 第十一期 - lora微调 - 基于Stable Diffusion(代码)Stable Diffusion 原理图Stable Diffusion的原理解释Stable Diffusion 和Di…...

新版231普通阿里滑块 自动化和逆向实现 分析
声明: 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 逆向过程 补环境逆向 部分补环境 …...

[Effective C++]条款49-52 内存分配
本文初发于 “天目中云的小站”,同步转载于此。 条款49 : 了解new-handler的行为 条款50 : 了解new和delete的合理替换时机 条款51 : 编写new和delete时需固守常规 条款52 :写了placement new也要写placement delete 条款49-52中详细讲述了定制new和d…...

HTML一般标签和自闭合标签介绍
在HTML中,标签用于定义网页内容的结构和样式。标签通常分为两类:一般标签(也称为成对标签或开放闭合标签)和自闭合标签(也称为空标签或自结束标签)。 以下是这两类标签的详细说明: 一、一般标…...

Eureka 服务注册和服务发现的使用
1. 父子工程的搭建 首先创建一个 Maven 项目,删除 src ,只保留 pom.xml 然后来进行 pom.xml 的相关配置 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xs…...
白嫖DeepSeek:一分钟完成本地部署AI
1. 必备软件 LM-Studio 大模型客户端DeepSeek-R1 模型文件 LM-Studio 是一个支持众多流行模型的AI客户端,DeepSeek是最新流行的堪比GPT-o1的开源AI大模型。 2. 下载软件和模型文件 2.1 下载LM-Studio 官方网址:https://lmstudio.ai 打开官网&#x…...

《Origin画百图》之同心环图
《Origin画百图》第四集——同心环图 入门操作可查看合集中的《30秒,带你入门Origin》 具体操作: 1.数据准备:需要X和Y两列数据 2. 选择菜单 绘图 > 条形图,饼图,面积图: 同心圆弧图 3. 这是绘制的基础图形&…...

蓝牙技术在物联网中的应用有哪些
蓝牙技术凭借低功耗、低成本和易于部署的特性,在物联网领域广泛应用,推动了智能家居、工业、医疗、农业等多领域发展。 智能家居:在智能家居系统里,蓝牙技术连接各类设备,像智能门锁、智能灯泡、智能插座、智能窗帘等。…...

快速提升网站收录:避免常见SEO误区
本文转自:百万收录网 原文链接:https://www.baiwanshoulu.com/26.html 在快速提升网站收录的过程中,避免常见的SEO误区是至关重要的。以下是一些常见的SEO误区及相应的避免策略: 一、关键词堆砌误区 误区描述: 很多…...

简易计算器(c++ 实现)
前言 本文将用 c 实现一个终端计算器: 能进行加减乘除、取余乘方运算读取命令行输入,输出计算结果当输入表达式存在语法错误时,报告错误,但程序应能继续运行当输出 ‘q’ 时,退出计算器 【简单演示】 【源码位置】…...
)
再谈多组学(multi-omics)
再谈多组学(multi-omics) 李升伟 李昱均 概念 多组学(Multi-Omics) 是指结合多种“组学”技术,从不同层次和维度全面解析生物系统的复杂性。传统的单一组学研究通常关注基因组、转录组、蛋白质组、代谢组等某一特定…...

自动化运维的未来:从脚本到AIOps的演进
点击进入IT管理资料库 一、自动化运维的起源:脚本时代 (一)脚本在运维中的应用场景 在自动化运维的发展历程中,脚本扮演着至关重要的角色,它作为最初的操作入口,广泛应用于诸多日常运维工作场景里。 在系统…...

线程池以及在QT中的接口使用
文章目录 前言线程池架构组成**一、任务队列(Task Queue)****二、工作线程组(Worker Threads)****三、管理者线程(Manager Thread)** 系统协作流程图解 一、QRunnable二、QThreadPool三、线程池的应用场景W…...

联想拯救者R720笔记本外接显示屏方法,显示屏是2K屏27英寸
晚上23点10分前下单,第二天上午显示屏送到,检查外包装没拆封过。这个屏幕左下方有几个按键,按一按就开屏幕、按一按就关闭屏幕,按一按方便节省时间,也支持阅读等模式。 显示屏是 :AOC 27英寸 2K高清 100Hz…...

C++ deque(1)
1.deque介绍 deque的扩容不像vector那样麻烦 直接新开一个buffer 不用重新开空间再把数据全部移过去 deque本质上是一个指针数组和vector<vector>不一样,vector<vector>本质上是一个vector对象数组!并且vector<vector>的buffer是不一…...

深度剖析 PyTorch框架:从基础概念到高级应用的深度学习之旅!
目录 一、引言 二、PyTorch 简介 (一)诞生背景与发展历程 (二)核心特点 三、PyTorch 基础概念 (一)张量(Tensor):数据的基石 (二)自动微分&…...

【Pandas】pandas Series cumsum
Pandas2.2 Series Computations descriptive stats 方法描述Series.abs()用于计算 Series 中每个元素的绝对值Series.all()用于检查 Series 中的所有元素是否都为 True 或非零值(对于数值型数据)Series.any()用于检查 Series 中是否至少有一个元素为 T…...

EtherCAT主站IGH-- 23 -- IGH之fsm_slave.h/c文件解析
EtherCAT主站IGH-- 23 -- IGH之fsm_slave.h/c文件解析 0 预览一 该文件功能`fsm_slave.c` 文件功能函数预览二 函数功能介绍`fsm_slave.c` 中主要函数的作用1. `ec_fsm_slave_init`2. `ec_fsm_slave_clear`3. `ec_fsm_slave_exec`4. `ec_fsm_slave_set_ready`5. `ec_fsm_slave_…...
:让大模型“轻装上阵”的技术革新——从DeepSeek看下一代语言模型的高效之路)
多头潜在注意力(MLA):让大模型“轻装上阵”的技术革新——从DeepSeek看下一代语言模型的高效之路
多头潜在注意力(MLA):让大模型“轻装上阵”的技术革新 ——从DeepSeek看下一代语言模型的高效之路 大模型的“内存焦虑” 当ChatGPT等大语言模型(LLM)惊艳世界时,很少有人意识到它们背后隐藏的“内存焦虑”…...

Brightness Controller-源码记录
Brightness Controller 亮度控制 一、概述二、ddcutil 与 xrandr1. ddcutil2. xrandr 三、部分代码解析1. icons2. ui3. utilinit.py 一、概述 项目:https://github.com/SunStorm2018/Brightness.git 原理:Brightness Controlle 是我在 Ubuntu 发现上调…...

Java8_StreamAPI
Stream 1.创建流 1.1 集合创建流 List<String> list List.of("a", "b", "c"); Stream<String> stream list.stream(); stream.forEach(System.out::println);1.2 数组创建流 String[] array {"a","b",&qu…...

【架构面试】二、消息队列和MySQL和Redis
MQ MQ消息中间件 问题引出与MQ作用 常见面试问题:面试官常针对项目中使用MQ技术的候选人提问,如如何确保消息不丢失,该问题可考察候选人技术能力。MQ应用场景及作用:以京东系统下单扣减京豆为例,MQ用于交易服和京豆服…...

OpenEuler学习笔记(十六):搭建postgresql高可用数据库环境
以下是在OpenEuler系统上搭建PostgreSQL高可用数据环境的一般步骤,通常可以使用流复制(Streaming Replication)或基于Patroni等工具来实现高可用,以下以流复制为例: 安装PostgreSQL 配置软件源:可以使用O…...

Vue.js路由管理与自定义指令深度剖析
Vue.js 是一个强大的前端框架,提供了丰富的功能来帮助开发者构建复杂的单页应用(SPA)。本文将详细介绍 Vue.js 中的自定义指令和路由管理及导航守卫。通过这些功能,你可以更好地控制视图行为和应用导航,从而提升用户体验和开发效率。 1 自定义指令详解 1.1 什么是自定义…...

skynet 源码阅读 -- 核心概念服务 skynet_context
本文从 Skynet 源码层面深入解读 服务(Service) 的创建流程。从最基础的概念出发,逐步深入 skynet_context_new 函数、相关数据结构(skynet_context, skynet_module, message_queue 等),并通过流程图、结构…...

论文阅读(十一):基因-表型关联贝叶斯网络模型的评分、搜索和评估
1.论文链接:Scoring, Searching and Evaluating Bayesian Network Models of Gene-phenotype Association 摘要: 全基因组关联研究(GWAS)的到来为识别常见疾病的遗传变异(单核苷酸多态性(SNP)&…...

企业微信远程一直显示正在加载
企业微信远程一直显示正在加载 1.问题描述2.问题解决 系统:Win10 1.问题描述 某天使用企业微信给同事进行远程协助的时候,发现一直卡在正在加载的页面,如下图所示 2.问题解决 经过一番查找资料后,我发现可能是2个地方出了问题…...

人工智能 - 1
深度强化学习(Deep Reinforcement Learning) 图神经网络(Graph Neural Networks, GNNs) Transformer 一种深度学习模型 大语言模型(Large Language Models, LLMs) 人工智能 • Marvin Minsky 将其定义…...

留学生scratch计算机haskell函数ocaml编程ruby语言prolog作业VB
您列出了一系列编程语言和技术,这些可能是您在留学期间需要学习或完成作业的内容。以下是对每个项目的简要说明和它们可能涉及的领域或用途: Scratch: Scratch是一种图形化编程语言,专为儿童和初学者设计,用于教授编程…...

LeetCode题练习与总结:最长和谐子序列--594
一、题目描述 和谐数组是指一个数组里元素的最大值和最小值之间的差别 正好是 1 。 给你一个整数数组 nums ,请你在所有可能的 子序列 中找到最长的和谐子序列的长度。 数组的 子序列 是一个由数组派生出来的序列,它可以通过删除一些元素或不删除元素…...