Apache Hudi数据湖技术应用在网络打车系统中的系统架构设计、软硬件配置、软件技术栈、具体实现流程和关键代码
网络打车系统利用Hudi数据湖技术成功地解决了其大规模数据处理和分析的难题,提高了数据处理效率和准确性,为公司的业务发展提供了有力的支持。
Apache Hudi数据湖技术的一个典型应用案例是网络打车系统的数据处理场景,具体如下:
大型网络打车公司每天需要处理的数据量达到数千亿条,数据规模达到数百PB级别。网络打车系统使用Hudi数据湖技术来跟踪记录每一次打车过程的所有事件,包括打开打车应用、发起打车、上车、到达目的地下车以及对司机的评价打分等。
在这个场景中,网络打车系统选择使用Hudi的写时复制表(COW)来存储应用程序中用户交互的历史记录数据。这些数据一旦产生并不会发生追溯修改,因此适合使用COW表来存储。使用Hudi后,网络打车系统的写入效率相比之前的Spark作业提高了100多倍,同时满足了数据查询的性能和低延迟要求。
此外,网络打车系统还利用Hudi提供的多种视图能力来优化数据查询。例如,使用快照查询来获取某个时间点的数据快照,使用增量查询来只查询自上次查询以来的新数据。这些视图能力使得网络打车系统能够更加高效地处理和分析数据,进而优化其业务决策和运营效率。
根据网络打车系统的Hudi应用场景,以下是详细的架构设计与实现方案:
一、硬件配置方案
- 存储层:
- 分布式存储:10,000节点HDFS集群(或S3兼容对象存储)
- 存储类型:NVMe SSD(热数据)+ HDD(冷数据)
- 总容量:1.5EB(支持3副本)
- 网络:100Gbps RDMA网络
- 计算层:
- Spark/Flink集群:5000节点
- 配置:256核/节点,2TB内存/节点
- 本地SSD缓存:10TB/节点
- 网络架构:
- 东西向流量:Clos网络架构
- 延迟要求:计算节点间<1ms
- 带宽:数据节点间40Gbps专线
二、系统架构设计
三、软件技术栈
- 核心组件:
- 存储引擎:Apache Hudi 0.12.0
- 计算引擎:Spark 3.3 + Flink 1.16
- 资源调度:YARN 3.3 + Kubernetes 1.26
- 数据格式:Parquet + Avro
- 元数据管理:Hive Metastore 3.1.2
- 辅助组件:
- 数据采集:Flume 1.10 + Kafka 3.3
- 查询引擎:Trino 412
- 监控体系:Prometheus 2.43 + Grafana 9.4
四、具体实现流程
- 数据写入流程:
# 示例Spark写入代码(Scala)
val hudiOptions = Map[String,String]("hoodie.table.name" -> "ride_events","hoodie.datasource.write.recordkey.field" -> "event_id","hoodie.datasource.write.partitionpath.field" -> "event_date,event_type","hoodie.datasource.write.precombine.field" -> "event_ts","hoodie.upsert.shuffle.parallelism" -> "5000","hoodie.insert.shuffle.parallelism" -> "5000","hoodie.bulkinsert.shuffle.parallelism" -> "5000"
)val eventDF = spark.read.format("kafka").option("kafka.bootstrap.servers", "kafka-cluster:9092").option("subscribe", "ride-events").load().select(from_json(col("value"), schema).as("data")).select("data.*")eventDF.write.format("org.apache.hudi").options(hudiOptions).option("hoodie.datasource.write.operation", "upsert").mode("append").save("s3://data-lake/ride_events")
- 查询优化配置:
-- 创建Hudi表外部关联
CREATE EXTERNAL TABLE ride_events
USING hudi
LOCATION 's3://data-lake/ride_events';-- 快照查询(最新数据)
SELECT * FROM ride_events
WHERE event_date = '2023-08-01' AND event_type = 'payment';-- 增量查询(Java示例)
HoodieIncQueryParam incParam = HoodieIncQueryParam.newBuilder().withStartInstantTime("20230801120000").build();SparkSession.read().format("org.apache.hudi").option(HoodieReadConfig.QUERY_TYPE, HoodieReadConfig.QUERY_TYPE_INCREMENTAL_OPT_VAL).option(HoodieReadConfig.BEGIN_INSTANTTIME, "20230801120000").load("s3://data-lake/ride_events").createOrReplaceTempView("incremental_data");
五、关键优化技术
- 存储优化:
// Hudi表配置(Java)
HoodieWriteConfig config = HoodieWriteConfig.newBuilder().withPath("s3://data-lake/ride_events").withSchema(schema.toString()).withParallelism(5000, 5000).withCompactionConfig(HoodieCompactionConfig.newBuilder().withInlineCompaction(true).withMaxNumDeltaCommitsBeforeCompaction(5).build()).withStorageConfig(HoodieStorageConfig.newBuilder().parquetMaxFileSize(2 * 1024 * 1024 * 1024L) // 2GB.build()).build();
- 索引优化:
# hudi.properties
hoodie.index.type=BLOOM
hoodie.bloom.index.bucketized.checking=true
hoodie.bloom.index.keys.per.bucket=100000
hoodie.bloom.index.filter.type=DYNAMIC_V0
六、运维监控体系
- 关键监控指标:
# Prometheus监控指标示例
hudi_commit_duration_seconds_bucket{action="commit",le="10"} 23567
hudi_compaction_duration_minutes 8.3
hudi_clean_operations_total 1428
hudi_bytes_written_total{type="parquet"} 1.2e+18
七、性能调优参数
- Spark调优参数:
spark.conf.set("spark.sql.shuffle.partitions", "10000")
spark.conf.set("spark.executor.memoryOverhead", "4g")
spark.conf.set("spark.hadoop.parquet.block.size", 268435456) # 256MB
该架构设计可实现以下性能指标:
- 写入吞吐:>500万条/秒
- 查询延迟:点查<1s,全表扫描<5min/PB
- 数据新鲜度:端到端延迟<5分钟
- 存储效率:压缩比8:1(原始JSON vs Parquet)
实际部署时需要根据数据特征动态调整以下参数:
- 文件大小(hoodie.parquet.max.file.size)
- 压缩策略(hoodie.compact.inline.trigger.strategy)
- Z-Order索引字段选择
- 增量查询时间窗口策略
相关文章:

Apache Hudi数据湖技术应用在网络打车系统中的系统架构设计、软硬件配置、软件技术栈、具体实现流程和关键代码
网络打车系统利用Hudi数据湖技术成功地解决了其大规模数据处理和分析的难题,提高了数据处理效率和准确性,为公司的业务发展提供了有力的支持。 Apache Hudi数据湖技术的一个典型应用案例是网络打车系统的数据处理场景,具体如下: 大…...

TryHackMe: TryPwnMe Two
TryExecMe2 限制了直接进行系统调用,即syscall sysenter int 0x80,但是这样的限制是十分好绕过的,我们只需要通过异或生成syscall构造read再次写入shellcode即可 构造read shellcode asm(""" mov rdx, 0x100 mov r15, rdi…...

熵采样在分类任务中的应用
熵采样在分类任务中的应用 在机器学习的分类任务里,数据的标注成本常常制约着模型性能的提升。主动学习中的熵采样策略,为解决这一难题提供了新的思路。本文将带你深入了解熵采样在分类任务中的原理、应用及优势。 一、熵采样的原理(优化版) 熵,源于信息论,是对不确定…...

SmartPipe完成新一轮核心算法升级
1. 增加对低质量轴段的修正 由于三维图纸导出造成某些轴段精度较差,部分管路段的轴线段不满足G1连续,SmartPipe采用算法对这种情况进行了修正,保证轴段在一定精度范围内光滑连续。 2. 优化对中文路径的处理 SmartPipeBatch批处理版本优化…...

松灵机器人 scout ros2 驱动 安装
必须使用 ubuntu22 必须使用 链接的humble版本 #打开can 口 sudo modprobe gs_usbsudo ip link set can0 up type can bitrate 500000sudo ip link set can0 up type can bitrate 500000sudo apt install can-utilscandump can0mkdir -p ~/ros2_ws/srccd ~/ros2_ws/src git cl…...

WebForms DataList 深入解析
WebForms DataList 深入解析 引言 在Web开发领域,控件是构建用户界面(UI)的核心组件。ASP.NET WebForms框架提供了丰富的控件,其中DataList控件是一个灵活且强大的数据绑定控件。本文将深入探讨WebForms DataList控件的功能、用法以及在实际开发中的应用。 DataList控件…...
)
蓝桥备赛指南(6)
这篇文章非常简单!重点只有两个,而且都和set非常相似。 se集合 set简介 首先,set集合是一种容器,用于存储一组唯一的元素,并按照一定的排序规则进行排序,set中的元素是按照升序排序的,默认情…...

路径规划之启发式算法之二十九:鸽群算法(Pigeon-inspired Optimization, PIO)
鸽群算法(Pigeon-inspired Optimization, PIO)是一种基于自然界中鸽子群体行为的智能优化算法,由Duan等人于2014年提出。该算法模拟了鸽子在飞行过程中利用地标、太阳和磁场等导航机制的行为,具有简单、高效和易于实现的特点,适用于解决连续优化问题。 更多的仿生群体算法…...
 函数详解)
SQL NOW() 函数详解
SQL NOW() 函数详解 引言 在SQL数据库中,NOW() 函数是一个常用的日期和时间函数,用于获取当前的时间戳。本文将详细介绍 NOW() 函数的用法、参数、返回值以及在实际应用中的注意事项。 函数概述 NOW() 函数返回当前的日期和时间,格式为 Y…...

Android 进程间通信
Android 进程间通信(IPC,Inter-Process Communication)是Android操作系统中不同进程间交换数据和资源的一种机制。由于Android是多任务操作系统,每个应用通常运行在自己的进程中,以提高安全性和资源管理的效率。因此&a…...

【leetcode练习·二叉树拓展】快速排序详解及应用
本文参考labuladong算法笔记[拓展:快速排序详解及应用 | labuladong 的算法笔记] 1、算法思路 首先我们看一下快速排序的代码框架: def sort(nums: List[int], lo: int, hi: int):if lo > hi:return# 对 nums[lo..hi] 进行切分# 使得 nums[lo..p-1]…...

华为IoTDA平台两个设备之间通信的过滤条件如何设置
目录 引言 过滤规则 特定topic转发 特定设备转发 特定产品转发 特定数据转发 结语 参考资料 引言 前一篇博文介绍了如何在两个设备之间进行通信转发。和利用topic进行转发相比,华为的这种方法比较麻烦,但是它功能比较强,包括可以利用…...
Docker 安装详细教程(适用于CentOS 7 系统)
目录 步骤如下: 1. 卸载旧版 Docker 2. 配置 Docker 的 YUM 仓库 3. 安装 Docker 4. 启动 Docker 并验证安装 5. 配置 Docker 镜像加速 总结 前言 Docker 分为 CE 和 EE 两大版本。CE即社区版(免费,支持周期7个月)…...
-组合问题)
【LeetCode 刷题】回溯算法(1)-组合问题
此博客为《代码随想录》二叉树章节的学习笔记,主要内容为回溯算法组合问题相关的题目解析。 文章目录 77. 组合216.组合总和III17.电话号码的字母组合39. 组合总和40. 组合总和 II 77. 组合 题目链接 class Solution:def combinationSum3(self, k: int, n: int) …...

FreeRTOS从入门到精通 第十三章(信号量)
参考教程:【正点原子】手把手教你学FreeRTOS实时系统_哔哩哔哩_bilibili 一、信号量知识回顾 1、概述 (1)信号量是一种解决同步问题的机制,可以实现对共享资源的有序访问,FreeRTOS中使用的是二值信号量、计数型信号…...

pstricks PGFTikz 在CTeX套装中绘图Transparency或Opacity失效的问题
我在CTeX中画图的时候,习惯用Geogebra先画好,然后生成pstricks或PGFTikz代码: 这样不用插入eps或pdf之类的图片,也是一种偷懒的方法。以前往arXiv.org上面传论文也是这样:代码出图,就不用另外上传一幅eps或…...

FPGA学习篇——开篇之作
今天正式开始学FPGA啦,接下来将会编写FPGA学习篇来记录自己学习FPGA 的过程! 今天是大年初六,简单学一下FPGA的相关概念叭叭叭! 一:数字系统设计流程 一个数字系统的设计分为前端设计和后端设计。在我看来࿰…...

C++底层学习预备:模板初阶
文章目录 1.编程范式2.函数模板2.1 函数模板概念2.2 函数模板原理2.3 函数模板实例化2.3.1 隐式实例化2.3.2 显式实例化 2.4 模板参数的匹配原则 3.类模板希望读者们多多三连支持小编会继续更新你们的鼓励就是我前进的动力! 进入STL库学习之前我们要先了解有关模板的…...

llama.cpp LLM_CHAT_TEMPLATE_DEEPSEEK_3
llama.cpp LLM_CHAT_TEMPLATE_DEEPSEEK_3 1. LLAMA_VOCAB_PRE_TYPE_DEEPSEEK3_LLM2. static const std::map<std::string, llm_chat_template> LLM_CHAT_TEMPLATES3. LLM_CHAT_TEMPLATE_DEEPSEEK_3References 不宜吹捧中国大语言模型的同时,又去贬低美国大语言…...

【玩转 Postman 接口测试与开发2_014】第11章:测试现成的 API 接口(下)——自动化接口测试脚本实战演练 + 测试集合共享
《API Testing and Development with Postman》最新第二版封面 文章目录 3 接口自动化测试实战3.1 测试环境的改造3.2 对列表查询接口的测试3.3 对查询单个实例的测试3.4 对新增接口的测试3.5 对修改接口的测试3.6 对删除接口的测试 4 测试集合的共享操作4.1 分享 Postman 集合…...

Linux03——常见的操作命令
root用户以及权限 Linux系统的超级管理员用户是:root用户 su命令 可以切换用户,语法:su [-] [用户名]- 表示切换后加载环境变量,建议带上用户可以省略,省略默认切换到root su命令是用于账户切换的系统命令ÿ…...

w188校园商铺管理系统设计与实现
🙊作者简介:多年一线开发工作经验,原创团队,分享技术代码帮助学生学习,独立完成自己的网站项目。 代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹赠送计算机毕业设计600个选题excel文…...

leetcode——二叉树的最近公共祖先(java)
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的…...

基于FPGA的BT656编解码
概述 BT656全称为“ITU-R BT.656-4”或简称“BT656”,是一种用于数字视频传输的接口标准。它规定了数字视频信号的编码方式、传输格式以及接口电气特性。在物理层面上,BT656接口通常包含10根线(在某些应用中可能略有不同,但标准配置为10根)。这些线分别用于传输视频数据、…...

解锁数据结构密码:层次树与自引用树的设计艺术与API实践
1. 引言:为什么选择层次树和自引用树? 数据结构是编程中的基石之一,尤其是在处理复杂关系和层次化数据时,树形结构常常是最佳选择。层次树(Hierarchical Tree)和自引用树(Self-referencing Tree…...

本地快速部署DeepSeek-R1模型——2025新年贺岁
一晃年初六了,春节长假余额马上归零了。今天下午在我的电脑上成功部署了DeepSeek-R1模型,抽个时间和大家简单分享一下过程: 概述 DeepSeek模型 是一家由中国知名量化私募巨头幻方量化创立的人工智能公司,致力于开发高效、高性能…...

WAWA鱼2024年终总结,关键词:成长
前言 本来想着偷懒一下,不写2024年终总结了,因为24年上半年还在忙毕业,下半年在忙转正,其实没什么太多好写的。结果被an_da和学弟催更了,哈哈哈,感谢大家对我近况的关注,学校内容基本都忘的差不…...
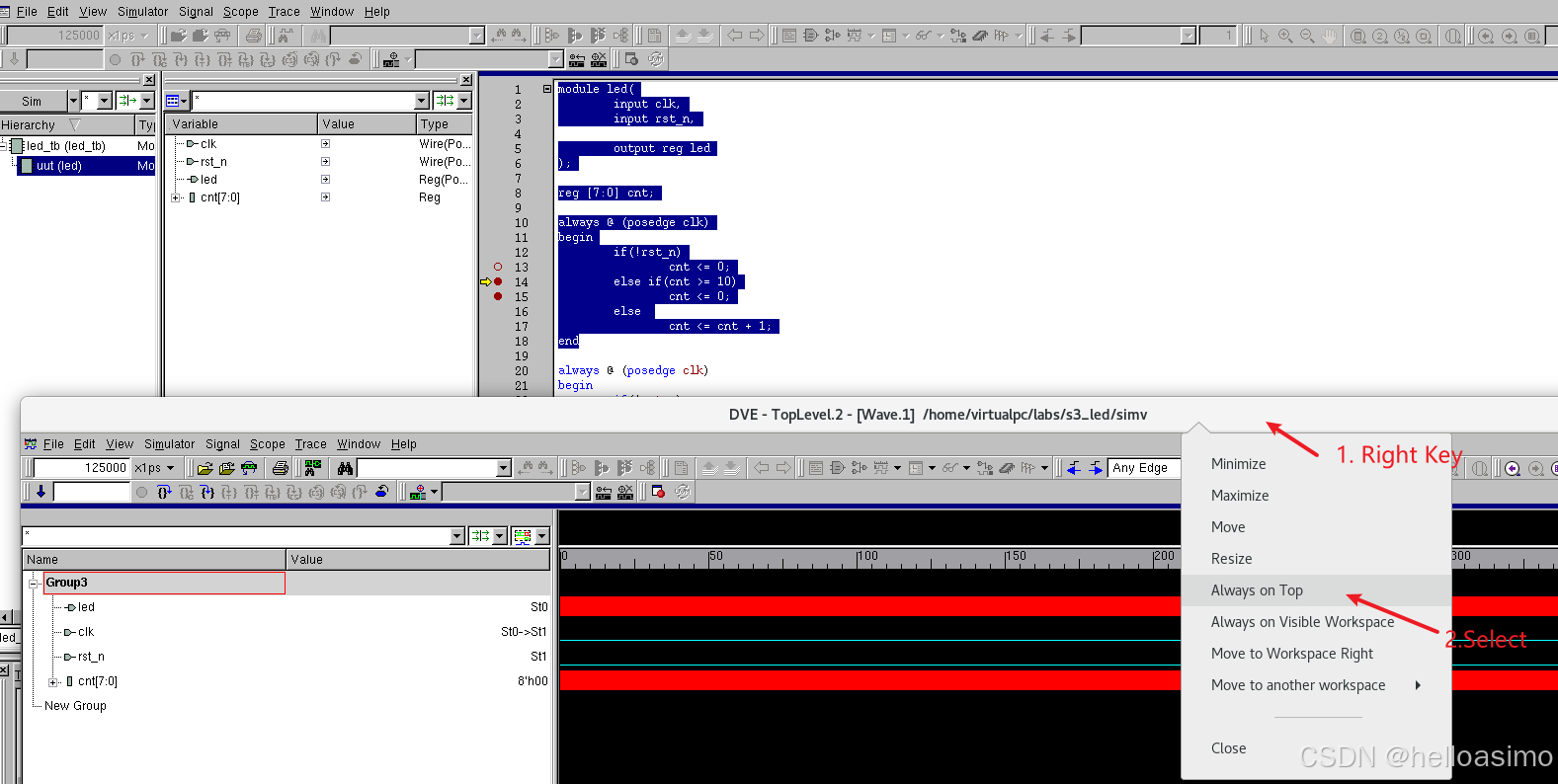
使用VCS进行单步调试的步骤
使用VCS对SystemVerilog进行单步调试的步骤如下: 1. 编译设计 使用-debug_all或-debug_pp选项编译设计,生成调试信息。 我的4个文件: 1.led.v module led(input clk,input rst_n,output reg led );reg [7:0] cnt;always (posedge clk) beg…...

【Elasticsearch】硬件资源优化
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

Elasticsearch 指南 [8.17] | Search APIs
Search API 返回与请求中定义的查询匹配的搜索结果。 http GET /my-index-000001/_search Request GET /<target>/_search GET /_search POST /<target>/_search POST /_search Prerequisites 如果启用了 Elasticsearch 安全功能,针对目标数据流…...