高并发、高可用的消息队列(MQ)设计与实战
目录
- 背景与历史
- 消息队列的核心功能
- 高并发、高可用的业务场景
- 消息队列的实用性
- 企业规模与消息队列的选择
- Java实战案例:基于RabbitMQ的高并发、高可用消息队列
- 6.1 环境准备
- 6.2 RabbitMQ的安装与配置
- 6.3 Java客户端集成
- 6.4 生产者与消费者实现
- 6.5 高并发处理
- 6.6 高可用性设计
- 6.7 性能优化与监控
- 总结
1. 背景与历史
消息队列(Message Queue, MQ)是一种在分布式系统中用于解耦、异步通信的重要组件。它的历史可以追溯到早期的企业应用集成(EAI)时代,当时企业需要将多个异构系统进行集成,消息队列应运而生。随着互联网的发展,尤其是电商、社交网络、金融等领域的崛起,消息队列逐渐成为高并发、高可用系统的核心组件之一。
早期的消息队列系统如IBM MQ、TIBCO等,主要面向企业级应用,功能强大但复杂度较高。随着开源文化的兴起,RabbitMQ、Kafka、RocketMQ等开源消息队列系统逐渐成为主流,它们不仅功能强大,而且易于使用和扩展,逐渐成为互联网公司的首选。
在高并发、高可用的场景下,消息队列的作用尤为突出。它能够有效地缓解系统压力,提升系统的吞吐量和响应速度,同时通过异步处理、流量削峰等功能,保证系统的稳定性和可靠性。
2. 消息队列的核心功能
消息队列的核心功能可以总结为以下几点:
2.1 解耦
消息队列通过将消息的发送者和接收者解耦,使得系统各模块之间的依赖关系降低。发送者只需要将消息发送到队列中,而不需要关心谁来处理这些消息。接收者则从队列中获取消息并进行处理,而不需要知道消息的来源。
2.2 异步通信
消息队列支持异步通信,发送者将消息发送到队列后,可以立即返回,而不需要等待接收者处理完毕。这种方式可以显著提升系统的响应速度,尤其是在高并发场景下。
2.3 流量削峰
在高并发场景下,系统的瞬时流量可能会远远超过其处理能力。消息队列可以通过缓存消息的方式,将流量峰值削平,避免系统因瞬时压力过大而崩溃。
2.4 消息持久化
消息队列通常支持消息的持久化,即使系统崩溃或重启,消息也不会丢失。这对于金融、电商等对数据一致性要求较高的场景尤为重要。
2.5 消息顺序性
某些业务场景下,消息的处理顺序非常重要。消息队列可以通过队列的顺序性,保证消息按照发送的顺序被处理。
2.6 高可用性
现代消息队列系统通常支持集群部署,能够通过主从复制、分区等方式实现高可用性。即使某个节点出现故障,系统仍然可以继续运行。
3. 高并发、高可用的业务场景
消息队列在高并发、高可用的业务场景中有着广泛的应用,以下是一些典型的场景:
3.1 电商系统
在电商系统中,订单创建、库存扣减、支付处理等操作通常需要高并发处理。通过消息队列,可以将这些操作异步化,提升系统的吞吐量和响应速度。同时,消息队列还可以用于处理订单状态变更、物流信息更新等业务。
3.2 社交网络
社交网络中的消息推送、通知、点赞、评论等操作通常需要实时处理。通过消息队列,可以将这些操作异步化,避免因瞬时流量过大而导致系统崩溃。
3.3 金融系统
金融系统中的交易处理、对账、风控等操作对数据一致性和可靠性要求极高。通过消息队列,可以保证这些操作的顺序性和持久性,避免因系统故障而导致数据丢失。
3.4 日志处理
在大数据场景下,日志的收集、存储和分析通常需要高并发处理。通过消息队列,可以将日志异步化处理,提升系统的吞吐量和响应速度。
4. 消息队列的实用性
消息队列的实用性主要体现在以下几个方面:
4.1 提升系统性能
通过异步处理和流量削峰,消息队列可以显著提升系统的吞吐量和响应速度,尤其是在高并发场景下。
4.2 增强系统稳定性
消息队列通过解耦和异步通信,可以降低系统各模块之间的依赖关系,避免因某个模块的故障而导致整个系统崩溃。
4.3 保证数据一致性
通过消息持久化和顺序性,消息队列可以保证数据的一致性和可靠性,避免因系统故障而导致数据丢失。
4.4 支持系统扩展
消息队列通常支持集群部署和水平扩展,能够随着业务的发展而动态扩展,满足不断增长的业务需求。
5. 企业规模与消息队列的选择
不同规模的企业对消息队列的需求有所不同,以下是一些常见的消息队列系统及其适用场景:
5.1 RabbitMQ
RabbitMQ是一个开源的消息队列系统,支持多种消息协议(如AMQP、MQTT等),适用于中小型企业的业务场景。它的特点是易于使用、功能丰富,但在高并发场景下性能相对较弱。
5.2 Kafka
Kafka是一个分布式的消息队列系统,适用于大数据场景下的高并发、高吞吐量需求。它的特点是高性能、高可用性,但在消息顺序性和延迟方面相对较弱。
5.3 RocketMQ
RocketMQ是阿里巴巴开源的消息队列系统,适用于电商、金融等对数据一致性和顺序性要求较高的场景。它的特点是高性能、高可用性,支持事务消息和顺序消息。
5.4 ActiveMQ
ActiveMQ是一个开源的消息队列系统,支持多种消息协议(如JMS、AMQP等),适用于中小型企业的业务场景。它的特点是易于使用、功能丰富,但在高并发场景下性能相对较弱。
6. Java实战案例:基于RabbitMQ的高并发、高可用消息队列
6.1 环境准备
在开始实战之前,我们需要准备以下环境:
- JDK 1.8或以上版本
- Maven 3.x
- RabbitMQ 3.8.x
- IntelliJ IDEA或Eclipse IDE
6.2 RabbitMQ的安装与配置
首先,我们需要安装RabbitMQ。可以通过以下步骤在Linux系统上安装RabbitMQ:
# 安装Erlang
sudo apt-get install erlang# 安装RabbitMQ
sudo apt-get install rabbitmq-server# 启动RabbitMQ
sudo systemctl start rabbitmq-server# 启用RabbitMQ管理插件
sudo rabbitmq-plugins enable rabbitmq_management# 创建用户并设置权限
sudo rabbitmqctl add_user admin admin
sudo rabbitmqctl set_user_tags admin administrator
sudo rabbitmqctl set_permissions -p / admin ".*" ".*" ".*"
安装完成后,可以通过http://localhost:15672访问RabbitMQ的管理界面,使用admin/admin登录。
6.3 Java客户端集成
接下来,我们需要在Java项目中集成RabbitMQ客户端。可以通过Maven添加以下依赖:
<dependency><groupId>com.rabbitmq</groupId><artifactId>amqp-client</artifactId><version>5.12.0</version>
</dependency>
6.4 生产者与消费者实现
6.4.1 生产者实现
生产者负责将消息发送到RabbitMQ队列中。以下是一个简单的生产者实现:
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;public class Producer {private final static String QUEUE_NAME = "test_queue";public static void main(String[] args) throws Exception {// 创建连接工厂ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");factory.setUsername("admin");factory.setPassword("admin");// 创建连接try (Connection connection = factory.newConnection();Channel channel = connection.createChannel()) {// 声明队列channel.queueDeclare(QUEUE_NAME, false, false, false, null);// 发送消息String message = "Hello, RabbitMQ!";channel.basicPublish("", QUEUE_NAME, null, message.getBytes());System.out.println(" [x] Sent '" + message + "'");}}
}
6.4.2 消费者实现
消费者负责从RabbitMQ队列中获取消息并进行处理。以下是一个简单的消费者实现:
import com.rabbitmq.client.*;public class Consumer {private final static String QUEUE_NAME = "test_queue";public static void main(String[] args) throws Exception {// 创建连接工厂ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");factory.setUsername("admin");factory.setPassword("admin");// 创建连接Connection connection = factory.newConnection();Channel channel = connection.createChannel();// 声明队列channel.queueDeclare(QUEUE_NAME, false, false, false, null);// 创建消费者DeliverCallback deliverCallback = (consumerTag, delivery) -> {String message = new String(delivery.getBody(), "UTF-8");System.out.println(" [x] Received '" + message + "'");};// 监听队列channel.basicConsume(QUEUE_NAME, true, deliverCallback, consumerTag -> {});}
}
6.5 高并发处理
在高并发场景下,我们需要对生产者和消费者进行优化,以提升系统的吞吐量和响应速度。
6.5.1 生产者并发优化
可以通过多线程的方式提升生产者的并发处理能力。以下是一个多线程生产者的实现:
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;public class ConcurrentProducer implements Runnable {private final static String QUEUE_NAME = "test_queue";private final String threadName;public ConcurrentProducer(String threadName) {this.threadName = threadName;}@Overridepublic void run() {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");factory.setUsername("admin");factory.setPassword("admin");try (Connection connection = factory.newConnection();Channel channel = connection.createChannel()) {channel.queueDeclare(QUEUE_NAME, false, false, false, null);for (int i = 0; i < 100; i++) {String message = threadName + " - Message " + i;channel.basicPublish("", QUEUE_NAME, null, message.getBytes());System.out.println(" [x] Sent '" + message + "'");}} catch (Exception e) {e.printStackTrace();}}public static void main(String[] args) {Thread t1 = new Thread(new ConcurrentProducer("Thread-1"));Thread t2 = new Thread(new ConcurrentProducer("Thread-2"));Thread t3 = new Thread(new ConcurrentProducer("Thread-3"));t1.start();t2.start();t3.start();}
}
6.5.2 消费者并发优化
可以通过增加消费者的数量来提升消息的处理能力。以下是一个多线程消费者的实现:
import com.rabbitmq.client.*;public class ConcurrentConsumer implements Runnable {private final static String QUEUE_NAME = "test_queue";private final String threadName;public ConcurrentConsumer(String threadName) {this.threadName = threadName;}@Overridepublic void run() {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");factory.setUsername("admin");factory.setPassword("admin");try {Connection connection = factory.newConnection();Channel channel = connection.createChannel();channel.queueDeclare(QUEUE_NAME, false, false, false, null);DeliverCallback deliverCallback = (consumerTag, delivery) -> {String message = new String(delivery.getBody(), "UTF-8");System.out.println(threadName + " [x] Received '" + message + "'");};channel.basicConsume(QUEUE_NAME, true, deliverCallback, consumerTag -> {});} catch (Exception e) {e.printStackTrace();}}public static void main(String[] args) {Thread t1 = new Thread(new ConcurrentConsumer("Thread-1"));Thread t2 = new Thread(new ConcurrentConsumer("Thread-2"));Thread t3 = new Thread(new ConcurrentConsumer("Thread-3"));t1.start();t2.start();t3.start();}
}
6.6 高可用性设计
为了保证系统的高可用性,我们需要对RabbitMQ进行集群部署。以下是一个简单的RabbitMQ集群配置步骤:
6.6.1 集群配置
假设我们有三台服务器,分别为node1、node2和node3。我们需要在这三台服务器上分别安装RabbitMQ,并将它们配置为一个集群。
在node1上执行以下命令:
# 停止RabbitMQ
sudo systemctl stop rabbitmq-server# 重置RabbitMQ节点
sudo rabbitmqctl reset# 启动RabbitMQ
sudo systemctl start rabbitmq-server
在node2和node3上执行以下命令:
# 停止RabbitMQ
sudo systemctl stop rabbitmq-server# 重置RabbitMQ节点
sudo rabbitmqctl reset# 加入集群
sudo rabbitmqctl join_cluster rabbit@node1# 启动RabbitMQ
sudo systemctl start rabbitmq-server
6.6.2 镜像队列配置
为了保证队列的高可用性,我们需要配置镜像队列。可以通过以下命令在RabbitMQ中配置镜像队列:
sudo rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
6.7 性能优化与监控
在高并发、高可用的场景下,性能优化和监控是非常重要的。我们可以通过以下方式对RabbitMQ进行性能优化和监控:
6.7.1 性能优化
- 消息持久化:将消息设置为持久化,避免因系统崩溃而导致消息丢失。
- 批量确认:通过批量确认的方式提升消息的处理效率。
- 预取计数:通过设置预取计数(prefetch count)来控制消费者的消息处理速度。
6.7.2 监控
- RabbitMQ管理界面:通过RabbitMQ的管理界面,可以实时监控队列的状态、消息的吞吐量等。
- Prometheus + Grafana:通过Prometheus和Grafana,可以对RabbitMQ进行更深入的监控和可视化。
7. 总结
消息队列在高并发、高可用的系统中扮演着至关重要的角色。通过解耦、异步通信、流量削峰等功能,消息队列能够显著提升系统的性能和稳定性。本文从背景历史、核心功能、业务场景、实用性等方面对消息队列进行了详细介绍,并通过Java实战案例展示了如何基于RabbitMQ实现高并发、高可用的消息队列系统。
在实际应用中,企业需要根据自身的业务需求和规模选择合适的消息队列系统,并通过集群部署、性能优化、监控等手段,确保系统的高可用性和高性能。希望本文能够为读者在实际项目中应用消息队列提供有价值的参考。
相关文章:
设计与实战)
高并发、高可用的消息队列(MQ)设计与实战
目录 背景与历史消息队列的核心功能高并发、高可用的业务场景消息队列的实用性企业规模与消息队列的选择Java实战案例:基于RabbitMQ的高并发、高可用消息队列 6.1 环境准备6.2 RabbitMQ的安装与配置6.3 Java客户端集成6.4 生产者与消费者实现6.5 高并发处理6.6 高可…...

数据库 - Sqlserver - SQLEXPRESS、由Windows认证改为SQL Server Express认证进行连接 (sa登录)
本文讲SqlServer Express版本在登录的时候, 如何由Windows认证,修改为Sql Server Express认证。 目录 1,SqlServer Express的Windows认证 2,修改为混合认证 3,启用sa 用户 4,用sa 用户登录 下面是详细…...

二分基础两道
Leetcode704: 给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。 示例 1: 输入: nums [-1,0,3,5,9,12], target 9 输出:…...

编程AI深度实战:AI编程工具哪个好? Copilot vs Cursor vs Cody vs Supermaven vs Aider
系列文章: 编程AI深度实战:私有模型deep seek r1,必会ollama-CSDN博客 编程AI深度实战:自己的AI,必会LangChain-CSDN博客 编程AI深度实战:给vim装上AI-CSDN博客 编程AI深度实战:火的编程AI,都在用语法树(AST)-CSDN博客 编程AI深度实战:让verilog不再是 AI …...

鸿蒙HarmonyOS Next 视频边播放边缓存- OhosVideoCache
OhosVideoCache 是一个专为OpenHarmony开发(HarmonyOS也可以用)的音视频缓存库,旨在帮助开发者轻松实现音视频的边播放边缓存功能。以下是关于 OhosVideoCache 的详细介绍: 1. 核心功能 边播放边缓存:将音视频URL传递给 OhosVideoCache 处理后…...

中间件漏洞之CVE-2024-53677
目录 什么是struts?CVE-2024-53677简介影响版本复现环境搭建漏洞利用修复 什么是struts? 在早期的 Java Web 开发中,代码往往混乱不堪,难以维护和扩展。比如,一个简单的用户登录功能,可能在不同的 Java 类…...

Python玄学
过年期间无聊的看了看DY直播,也是迷上玄学了。突然想着为啥要自己掐指算,我这🐷脑哪记得到那么多东西啊。然后,就捣鼓捣鼓了一些玩意儿。留个纪念。 注:就是一个玄学推动学习,部分内容不必当真,…...

16.1.STM32F407ZGT6-CAN基础概念
参考: https://blog.csdn.net/sunlight_vip/article/details/128639144 前言: 学习总结CAN的知识点: 1.can是什么,历史由来和背景 2.can的物理层,链路层 3.初始化的流程和关键点 4.波特率怎么设置 5.can id怎么过滤 6…...

记忆化搜索和动态规划 --最长回文子串为例
记忆化搜索 记忆化搜索是一种优化递归算法的方法,通过将已经计算过的子问题的结果存储起来(通常使用哈希表或数组),避免重复计算相同的子问题。 本质上是通过缓存中间结果来减少计算的重复性。 动态规划 动态规划是通过将问题分…...

【论文笔记】Fast3R:前向并行muti-view重建方法
众所周知,DUSt3R只适合做稀疏视角重建,与sapnn3r的目的类似,这篇文章以并行的方法,扩展了DUSt3R在多视图重建中的能力。 abstract 多视角三维重建仍然是计算机视觉领域的核心挑战,尤其是在需要跨不同视角实现精确且可…...
)
cf div3 998 E(并查集)
E : 给出两个简单无向图 (没有重边和自环)f g . 可以对f 进行 删边 和加边 的操作。问至少操作多少次 ,使得 f 和 g 的 点的联通情况相同(并查集的情况相同) 首先思考删边 : 对于 我 f 图存在边 e &#x…...
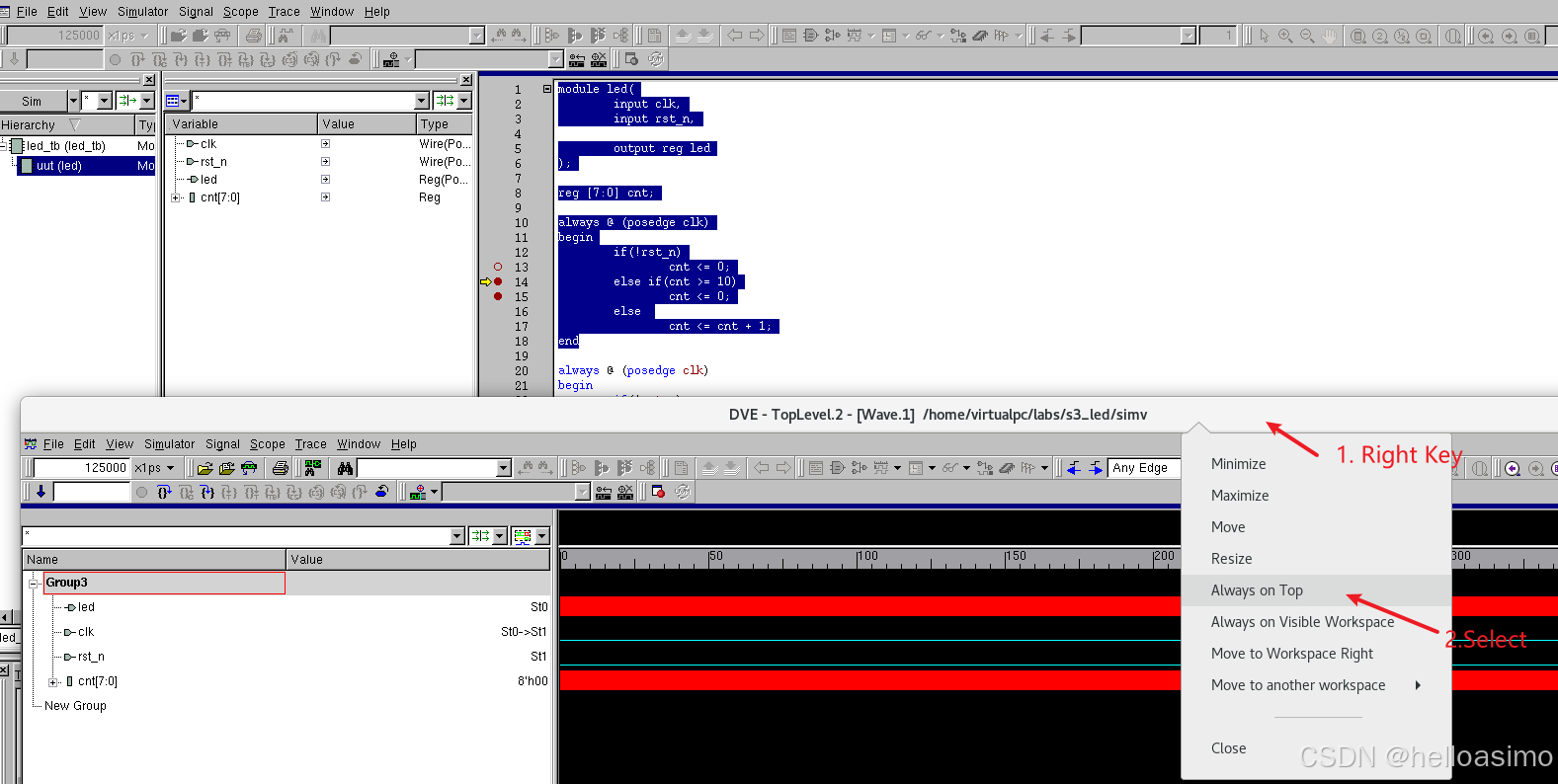
使用VCS对Verilog/System Verilog进行单步调试的步骤
Verilog单步调试: System Verilog进行单步调试的步骤如下: 1. 编译设计 使用-debug_all或-debug_pp选项编译设计,生成调试信息。 我的4个文件: 1.led.v module led(input clk,input rst_n,output reg led );reg [7:0] cnt;alwa…...

Pyside6异步通信测试
#第一种方式,借助qasync实现。使用pip install qasync安装。 from PySide6.QtWidgets import * from PySide6.QtCore import * from PySide6.QtGui import * import asyncio from qasync import QEventLoop, asyncSlotclass Form(QWidget):def __init__(self,paren…...

[ESP32:Vscode+PlatformIO]新建工程 常用配置与设置
2025-1-29 一、新建工程 选择一个要创建工程文件夹的地方,在空白处鼠标右键选择通过Code打开 打开Vscode,点击platformIO图标,选择PIO Home下的open,最后点击new project 按照下图进行设置 第一个是工程文件夹的名称 第二个是…...

如何使用 DeepSeek API 结合 VSCode 提升开发效率
引言 在当今的软件开发领域,API 的使用已经成为不可或缺的一部分。DeepSeek 是一个强大的 API 平台,提供了丰富的功能和数据,可以帮助开发者快速构建和优化应用程序。而 Visual Studio Code(VSCode)作为一款轻量级但功…...

自定义数据集 ,使用朴素贝叶斯对其进行分类
数据集定义: - data 列表包含了文本样本及其对应的情感标签。每个元素是一个元组,第一个元素是文本,第二个元素是标签。 特征提取: - 使用 CountVectorizer 将文本转换为词频向量。 fit_transform 方法在训练数据上拟合向量器…...
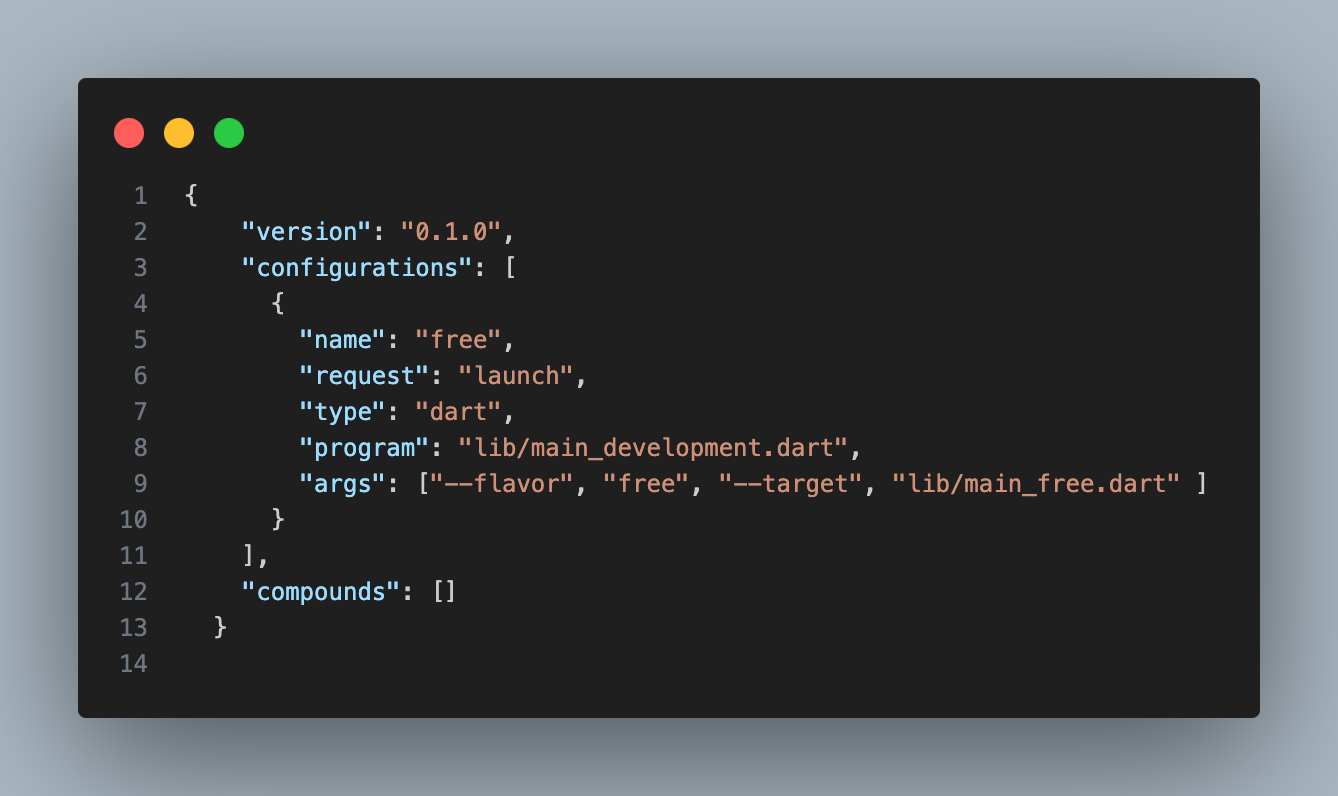
Flutter使用Flavor实现切换环境和多渠道打包
在Android开发中通常我们使用flavor进行多渠道打包,flutter开发中同样有这种方式,不过需要在原生中配置 具体方案其实flutter官网个了相关示例(https://docs.flutter.dev/deployment/flavors),我这里记录一下自己的操作 Android …...

C# lock使用详解
总目录 前言 在 C# 多线程编程中,lock 关键字是一种非常重要的同步机制,用于确保同一时间只有一个线程可以访问特定的代码块,从而避免多个线程同时操作共享资源时可能出现的数据竞争和不一致问题。以下是关于 lock 关键字的详细使用介绍。 一…...

C# 接口介绍
.NET学习资料 .NET学习资料 .NET学习资料 一、接口的定义 在 C# 中,接口是一种特殊的抽象类型,它定义了一组方法签名,但不包含方法的实现。接口使用interface关键字来声明。例如,定义一个表示形状的接口IShape: in…...

第三周 树
猫猫和企鹅 分数 10 全屏浏览 切换布局 作者 姜明欣 单位 河北大学 王国里有 nn 个居住区,它们之间有 n−1 条道路相连,并且保证从每个居住区出发都可以到达任何一个居住区,并且每条道路的长度都为 1。 除 1号居住区外,每个居…...

OpenAI 实战进阶教程 - 第四节: 结合 Web 服务:构建 Flask API 网关
目标 学习将 OpenAI 接入 Web 应用,构建交互式 API 网关理解 Flask 框架的基本用法实现 GPT 模型的 API 集成并返回结果 内容与实操 一、环境准备 安装必要依赖: 打开终端或命令行,执行以下命令安装 Flask 和 OpenAI SDK: pip i…...

Nginx 中文文档
文章来源:nginx 文档 -- nginx中文文档|nginx中文教程 nginx 文档 介绍 安装 nginx从源构建 nginx新手指南管理员指南控制 nginx连接处理方法设置哈希调试日志记录到 syslog配置文件测量单位命令行参数适用于 Windows 的 nginx支持 QUIC 和 HTTP/3 nginx 如何处理…...

Java 泛型<? extends Object>
在 Java 泛型中,<? extends Object> 和 <?> 都表示未知类型,但它们在某些情况下有细微的差异。泛型的引入是为了消除运行时错误并增强类型安全性,使代码更具可读性和可维护性。 在 JDK 5 中引入了泛型,以消除编译时…...

鲸鱼算法 matlab pso
算法原理 鲸鱼优化算法的核心思想是通过模拟座头鲸的捕食过程来进行搜索和优化。座头鲸在捕猎时会围绕猎物游动并产生气泡网,迫使猎物聚集。这一行为被用来设计搜索策略,使算法能够有效地找到全局最优解。 算法步骤 初始化:随机生成一…...

Hot100之堆
我们的PriorityQueue默认为最小堆,堆顶总是为最小 215数组中的第K个最大元素 题目 思路解析 暴力解法(不符合时间复杂度) 题目要求我们找到「数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素」。「数组排序后的第 k …...

KNIME:开源 AI 数据科学
KNIME(Konstanz Information Miner)是一款开源且功能强大的数据科学平台,由德国康斯坦茨大学的软件工程师团队开发,自2004年推出以来,广泛应用于数据分析、数据挖掘、机器学习和可视化等领域。以下是对KNIME的深度介绍…...

Office / WPS 公式、Mathtype 公式输入花体字、空心字
注:引文主要看注意事项。 1、Office / WPS 公式中字体转换 花体字 字体选择 “Eulid Math One” 空心字 字体选择 “Eulid Math Two” 2、Mathtype 公式输入花体字、空心字 2.1 直接输入 花体字 在 mathtype 中直接输入 \mathcal{L} L \Large \mathcal{L} L…...

[HOT 100] 2824. 统计和小于目标的下标对数目
文章目录 1. 题目链接2. 题目描述3. 题目示例4. 解题思路5. 题解代码6. 复杂度分析 1. 题目链接 2824. 统计和小于目标的下标对数目 - 力扣(LeetCode) 2. 题目描述 给你一个下标从 0 开始长度为 n 的整数数组 nums 和一个整数 target ,请你…...

建表注意事项(2):表约束,主键自增,序列[oracle]
没有明确写明数据库时,默认基于oracle 约束的分类 用于确保数据的完整性和一致性。约束可以分为 表级约束 和 列级约束,区别在于定义的位置和作用范围 复合主键约束: 主键约束中有2个或以上的字段 复合主键的列顺序会影响索引的使用,需谨慎设计 添加…...
Ubuntu20.04 磁盘空间扩展教程
Ubuntu20.04 磁盘空间扩展教程_ubuntu20 gpart扩容-CSDN博客文章浏览阅读2w次,点赞38次,收藏119次。执行命令查看系统容量相关的数据:df -h当前容量为20G,已用18G(96%),可用844M,可用…...